Ad hoc網絡基于協同的可靠組播丟失恢復算法設計
2010-03-27 06:54:50黃夢潔張翼德
電子與信息學報 2010年9期
關鍵詞:信息
黃夢潔 馮 鋼 張翼德
(電子科技大學通信抗干擾技術國家級重點實驗室 成都 611731)
1 引言
在Ad hoc網絡的應用中,當存在多個接收者需要同時接收數據時,使用組播技術進行數據傳輸是很有效的方式。雖然一些應用,例如一個實時的多媒體組播通信,因為無法容忍丟失恢復產生的延時,就容忍組播傳輸過程中不可靠網絡帶來的數據丟失或者錯誤;但是其它的應用,例如在單點對多點的數據組播傳輸或者是軍事應用中,是無法容忍數據包的丟失的。因此要求組播傳輸需要具備可靠性。然而Ad hoc網絡中節點的能量和網絡的傳輸帶寬有限,并且網絡自身具有無結構性、節點頻繁移動,以及無線傳輸信道環境高的誤碼率和信道衰落特性,都影響了組播傳輸的可靠性。
到目前為止,已經提出了許多可靠組播協議,其中的PGM組播可靠傳輸協議是一個著名適用于有線組播網絡的可靠傳輸協議[1]。PGM適應于多個源端和多個接收端之間通信的可靠傳輸協議,它適用于組成員隨時加入或離開,但對于分組丟失不敏感的應用。另一方面,也提出了一些適用于Ad hoc網絡的組播傳輸通信協議[2?5]和基于Mesh網絡的協議[6]。這些協議通過不同的方式提高了Ad hoc網絡的組播通信可靠性。根據進行丟失恢復的不同位置,這些算法可以分類為:基于源節點的丟失恢復、基于接收節點的丟失恢復或者基于額外的恢復節點的丟失恢復。Gopalsamy等人提出的Reliable Multicast Algorithm(RMA)算法[2]是依靠發送節點進行丟失恢復,RMA算法通過發送端發送ACK來進行數據包確認。Chandra等人提出的Anonymous Gossip(AG)算法[4]則是在進行丟失恢復時隨機選擇一個節點作為恢復節點,但是在AG中隨機選擇的丟失恢復節點能否完成丟失恢復具有未知性。單純的依靠源節點,或者單純的依靠接收節點進行丟失恢復的設計,或者選擇某幾個節點作為恢復節點,都是將整個網絡的丟失恢復集中在這幾個節點上進行處理,這樣就會增加這幾個節點的處理負擔,并且無法避免大量重傳時恢復節點無法負荷而成為網絡瓶頸的情況發生。選擇劃分本地組的方式[5]雖然在NAK抑制和避免產生瓶頸方面有較好的表現,但是面對Ad hoc中節點頻繁的移動性,為了維護各個本地組的成員關系會增加很多的網絡開銷。
基于以上考慮,本文針對Ad hoc網絡的特點和已有算法的優缺點,將協同的設計思想[7,8]引入到丟失恢復設計中提出了新的基于協同的可靠組播丟失恢復算法(CoreRM)。CoreRM算法是基于樹狀的路由結構的,例如可以采用Ad hoc按需距離向量組播路由協議(MAODV)[9],目前還有基于分層樹狀結構的丟失恢復算法[10]。CoreRM選擇將一跳鄰居節點、組播路徑上游節點和發送節點協同進行恢復丟失。算法設計目標在于:各級協同,分散網絡中的丟失恢復,將網絡的丟失在最短的距離內得到恢復,最終增加Ad hoc網絡中組播傳輸的可靠性。對于無線網絡中的節點緩存控制和緩存管理我們已經有了一定的研究[11],因此在CoreRM算法的緩存策略設計上也提出了新的想法:節點上緩存的不僅僅是接收到的數據,還緩存了能夠幫助節點進行丟失恢復的路徑信息。應對重傳恢復中可能出現的NAK風暴,CoreRM算法使用隨機等待一定時間以后再發送NAK來避免競爭信道。針對Ad hoc網絡中節點的頻繁移動會造成拓撲結構的多變性,CoreRM算法通過周期性發送源路由信息(SPM),來及時獲知組播樹結構中的上一跳節點信息的變動。
2 協同可靠組播丟失恢復(CoreRM)
2.1 CoreRM算法概述
協同丟失恢復算法(CoreRM)是基于樹型路由(如MAODV)、NAK確認丟失的可靠組播協同丟失恢復算法。為了避免在某個節點負擔過多的丟失恢復處理,算法通過整個網絡中的所有節點間相互協同提供丟失恢復,使得丟失在最小的范圍內得到恢復,同時也使恢復負擔分布化。所有的組播樹成員節點(包括路由器節點和接收節點)在緩存中不僅存儲了傳輸的數據包,還存儲數據丟失恢復路徑向量(Loss Recovery Distance Vector,LRDV),LRDV主要是記錄進行丟失恢復的最短路徑信息。通過接收到的NAK或者NCF中攜帶的發送節點的數據恢復路徑信息DV向量(DV是LRDV的一部分)而得到此信息。由于LRDV中僅僅存儲了數據恢復的路徑信息,因此不會占用很大的空間。多播樹上每一個節點即使不能直接對丟失提供恢復,也可以通過自己的LRDV里存儲的恢復路徑信息來幫助其他節點獲得恢復路徑來進行丟失恢復。
總的來講,CoreRM算法的協同丟失恢復過程可概括為:
(1)單播恢復階段: 節點的LRDV中存在丟失數據的恢復路徑信息,直接單播發送NAK請求到該節點請求進行相應數據包的重傳。
(2)本地恢復階段: 對于無法通過LRDV進行單播恢復的丟失數據包,進入本地恢復階段進行丟失恢復。廣播NAK,DV附加在NAK包中進行傳輸。廣播的距離是一跳,目的在于發現周圍能夠提供協同恢復幫助的最近鄰居節點,接收到NAK請求的節點廣播NCF并且檢查緩存中是否存儲了該丟失的數據包,如果能夠提供丟失恢復就單播發送恢復數據包。否則超時后結束本地恢復,進入下一個丟失恢復階段。
(3)單播恢復階段:再次檢索節點的LRDV中是否存儲了丟失數據包的恢復路徑,如果存儲則直接單播恢復。因為在進行本地恢復的過程中,節點可能因為接收到的NAK數據包或者NCF數據包所攜帶的DV向量信息而獲知丟失數據包的恢復路徑,這樣就可以再次通過鄰居節點之間的協同幫助來進行丟失恢復處理。
(4)全局恢復階段:對于仍然無法恢復的數據包,進入全局恢復階段進行丟失恢復。沿著組播路徑向上游節點發送NAK,緩存中存儲了丟失數據包的節點廣播就發送恢復數據包,接收到恢復數據包的所有下游節點都能夠完成丟失恢復。如果所有的上游節點都無法提供協同恢復幫助,NAK數據包將最終被傳遞到發送端,發送端就針對丟失的數據包進行最終的丟失恢復重傳。
2.2 數據包緩存策略
CoreRM算法選擇在組播樹的每一個成員節點上都緩存接收到的數據包和恢復路徑信息。由于Ad hoc網絡是無結構的,每個節點同時具有轉發功能和接收功能。因此CoreRM算法充分發揮轉發節點的作用,設計轉發節點處也進行數據包的緩存。轉發節點往往接近于發送節點,相對于遠距離的接收節點出現丟失的可能性較小,當接收節點發生丟失請求恢復時,就可能在轉發節點處得到丟失恢復,不再需要匯聚到源節點處進行丟失恢復。并且由于轉發節點和接收節點的協同幫助,就將整個網絡的丟失恢復進行分布式處理,分布式處理雖然需要每個節點都進行數據包緩存操作,但是可以避免整個網絡由于某個節點處理能力有限而出現瓶頸。
接收節點者通過設立數據包接收序列來發現數據包的丟失。由于源端發送數據包是按序發送的,在規定的時間內沒有正確接收到相應的數據包或者出現了接收空隙,都意味著傳輸中發生了丟失。接收空隙產生的原因是在規定的時間內數據包沒有按序達到,在接收端建立最大接收序號累加算法,每當接收到按序達到的數據包時就遞加接收端接收到的最大序號。如果接收到的數據包序號小于最大的存儲序號則丟棄該數據包;如果接收到的數據包序號超過了接收端存儲的最大接收序號加1時,表示出現空隙有數據包發生了丟失。
2.3 恢復路徑信息緩存策略
在CoreRM中,每一個節點對于每一個組播組維護一個LRDV路由表用來存儲數據包的恢復路徑信息。每一個LRDV表具有表1的形式。

表1 LRDV數據包格式
Packet ID:數據包標識(數據包發送端的地址和序號),用于標識不同數據流中的不同數據包;Dst1:數據包的恢復節點地址;hops表示到達恢復節點的跳數;Ts是時間戳,在超過Tmax時間后LRDV中的內容被重設。同其他的距離向量算法一樣,在LRDV表中每一個向量只保留了最優的恢復節點地址,最優的節點地址就是指距離丟失節點跳數最少,即最近的節點。如果是正確接收的數據包,那么該數據包的向量中Dst1是本節點地址,其余參數都是初始值。
在LRDV中的距離信息的傳遞是通過NAK或者是NCF的廣播發送方式來傳遞的。每個NAK或者是NCF包的格式如表2所示。
TYPE是數據包的類型,NAK或者NCF;G是組播組地址;S是發送節點地址;RCV是接收節點地址,例如:NAK廣播時是廣播地址,NAK單播時可能是上游節點地址或者是恢復節點的地址;seqNo:請求重傳/回復請求的丟失數據包的序號;[DV]是發送NAK/NCF節點的數據包接收情況組成的向量,存儲了從丟失數據包序號seqNo開始向后的N個數據包的恢復路徑信息,因為丟失可能是因為數據包的亂序導致的,這也意味著序號后面可能存在正確接收到的數據包,相對于序號前面的數據這些數據更有可能被其它節點請求重傳。在[DV]中,[DV(i)]是數據包<S, seqNo + i>的向量。

表2 NAK/NCF數據包格式
LRDV中的信息在節點接收到DATA,NAK,NCF和RDATA時進行更新。
接收到數據包seqNo,節點A存儲數據包,建立或者更新LRDV信息。

當接收到到NAK或者是NCF時,節點A就根據其攜帶的[DV]中的信息更新LRDV表。注意到[DV(i)]影響到了A的LRDV中的<S, seqNo + i>。如果接收到的NAK/NCF中攜帶的第i個向量的序號和A節點的LRDV中存儲的序號相同,那么比較DV中的向量的hops和LRDV中的hops大小,如果DV小于LRDV,則將LRDV中的信息替換成DV[i]中的信息。如果接收到的同序號的DV信息在LRDV中仍沒有建立向量,則按照DV中攜帶的信息建立相關向量。
2.4 SPM數據包幀格式設計
SPM數據包的設計是為了適應Ad hoc網絡中節點頻繁移動造成的組播樹不斷重建的問題。SPM包是源路徑信息數據包。在發送數據包之前被廣播發送,用來幫助各個節點建立組播樹結構的上游節點信息;SPM在數據包發送間隔被廣播發送,用來應對網絡拓撲結構變動產生的上游節點變動。由于SPM僅僅用來監督網絡拓撲的變化,數據包長度很小,因此在網絡通信中也不會產生很大的網絡開銷。
SPM數據包的幀格式中包括:常用頭部信息、IP報頭信息和SPM報頭信息3部分。常用頭部信息包括4部分信息:Tsi,seqno,size和type。其中Tsi是數據包標識,因為網絡中可能存在很多的數據流,因此根據Tsi就可以區分不同的數據流。不同的Type值區分不同的數據包類型。例如:SPM數據包的type值是:PT_SPM。IP頭部信息(dst_addr)是存放數據包發送的目的節點地址。SPM頭部信息主要是存儲在spm_path中的源路由路徑信息,也就是在組播樹建立以后,節點的上游節點信息,這里通過節點地址來進行標識。源節點發送SPM數據包時,將spm_path地址設置成自己的地址,這樣接收到SPM數據包的節點就獲知上游節點是源節點。節點接收到SPM數據包以后改變spm_path為本節點的地址之后轉發SPM。這樣就通過發送SPM數據包,可以及時獲知上游節點是否發生變化。
2.5 NAK抑制策略設計
CoreRM中NAK抑制算法設計主要是為了避免生成NAK風暴設計的。NAK風暴產生的原因很多,主要是:不同的節點丟失同時請求相同序號的數據包,所有節點同時發送NAK,等待RDATA的過程中不斷發送重復的NAK。NAK風暴的出現很有可能導致整個網絡的瓶頸鏈路斷裂或者某個節點由于處理能力有限而癱瘓整個網絡,因此NAK抑制算法的設計是CoreRM中設計的重點。如圖1所示是CoreRM算法的狀態機轉換圖。當節點發現丟失數據包以后,進入到NAK_STATE狀態,隨機等待一段時間以后發送NAK,并且進入到WAIT_NCF_STATE狀態中等待接收NCF,在等待NCF的過程中節點停止重復發送NAK,只有當等待NCF超時以后再次進入NAK_STATE階段時,才再次發送NAK;如果接收到NCF以后進入到WAIT_DATA_STATE階段等待接收重傳的數據包。否則當等待重傳NCF的次數超過了MAX_NCF_RETIRES以后,或者等待RDATA的次數超過了MAX_DATA_RETIRES的次數以后結束本丟失恢復階段對數據包的丟失恢復。
3 CoreRM性能分析
本節使用一個簡化的網絡模型對比分析CoreRM和PGM可靠組播丟失恢復的性能。考慮一個發送端多個接收端的組播傳輸模型,發送端為S。組播通信是基于樹狀的路由結構,網絡中節點的密度為ρ,無線節點的傳輸半徑為r,組播樹成員節點到發送節點S之間的跳數為Hi。組播樹成員節點MHi存儲了數據包dj的概率為Pij。當組播通信需要進行丟失恢復時,如果丟失重傳的請求無法被組播組成員節點滿足就會一直傳遞到發送端。減少請求節點到提供丟失恢復節點之間的跳數Lj就能夠減少重傳的時延Tj,節約帶寬和能量損耗,因為這樣就會引入很少的成員節點到丟失重傳的處理中。丟失恢復延時Tj:是指從發現丟失后發出丟失重傳請求開始到接收到重傳的數據包之間的延時。Tavg是整個組播丟失恢復過程中的平均丟失恢復延時。Lavg是整個組播丟失恢復過程中的平均跳數。由于CoreRM進行協同的丟失恢復時,經歷了本地恢復階段、全局恢復階段和源節點恢復階段3個階段。每個丟失恢復階段完成丟失恢復因為距離請求節點不同的跳數距離導致要經歷不同的延時,本地恢復階段的平均延時為Tz,全局恢復的平均延時為Tg,源端恢復的延時為Ts。CoreRM設計每次丟失恢復等待重傳的最大延時為Tr。因此CoreRM算法的丟失恢復跳數和丟失恢復時延為


圖1 CoreRM算法的狀態機轉換圖
為了分析CoreRM算法和PGM算法的丟失恢復跳數和丟失恢復延時的性能,本文通過一個簡單的例子來進行說明,例子的拓撲結構如圖2所示。為了方便計算,假設每一條鏈路上的丟包概率p相同,每個節點上的存儲概率P都可以根據該節點和發送節點之間的組播路徑的鏈路丟包率p來確定。組播樹上的每一個節點都對傳輸的數據包進行存儲,并且節點的緩存空間為無限大。發送節點S一定能夠提供請求數據包的重傳恢復。請求重傳的NAK和NCF數據包不會發生丟失。
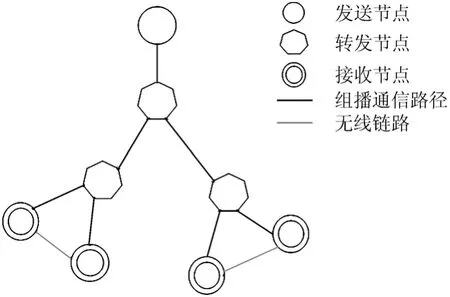
圖2 樹形結構的組播樹拓撲
使用PGM作為可靠組播通信協議:

圖3所示的是在圖2的樹形拓撲結構下的丟失恢復跳數。虛線為CoreRM算法的平均丟失恢復跳數,實線為PGM的平均丟失恢復跳數曲線。圖4所示的是在圖3的樹形拓撲結構下平均恢復延時曲線。由于PGM使用的是發送端重傳,每次重傳都需要發送端重傳才能完成,并且根據傳輸鏈路上的丟包率,重傳的數據包有可能再次發生丟失。從圖3中可以看出,使用了CoreRM算法以后圖2的拓撲結構中發生了數據包丟失的接收節點,理論上可以在兩跳范圍內完成丟失恢復,而使用PGM算法時重傳跳數就已經超出了3跳。使用了CoreRM算法以后的丟失恢復延時曲線增長幅度隨著鏈路丟包率的增長也要小于PGM,因此可以看出CoreRM算法的優勢。
4 計算機仿真與性能評估
本文使用NS2作為Ad hoc網絡的仿真平臺來估計CoreRM的性能。使用MAODV組播路由協議產生組播樹拓撲。仿真中,分布16個節點在670 m×670 m的范圍內,選取一個節點作為源節點,通過CBR流量生成器產生整個網絡仿真的數據,數據包長為210 Byte。仿真中使用MAODV組播路由協議作為路由層協議,802.11 作為MAC層協議。已有的PGM是針對有線網絡設計的基于NAK的可靠組播協議,根據本文的仿真需要我們對PGM做了一定的改進,以適應于Ad hoc網絡的傳輸環境。PGM協議具有丟失恢復功能;當組播組成員發生分組丟失時,向源節點發送NAK請求進行丟失恢復。
本文采用性能指標主要是網絡的吞吐量和平均丟失恢復延時。
平均吞吐量:每個節點在單位時間內接收到的數據量。
平均丟失恢復時延:數據包丟失發現到數據包丟失恢復的時延。
圖5和圖6是存在信道損耗的靜態網絡中的性能仿真結果。圖中橫坐標表示的是傳輸丟包概率,也就是不同的信道損耗。圖5所示的是網絡的吞吐量曲線,圖6所示的是丟失恢復延時曲線。由于CoreRM和PGM對于數據包重傳次數做了限制,有些數據包可能因為超過了重傳的最大次數而被放棄恢復,這些數據包不會被計入到丟失恢復重傳延時中。由于UDP是面向無連接的傳輸協議,對于發生丟失的數據包不采取任何措施進行恢復,因此UDP的性能下降的最快。PGM協議的性能優于UDP協議,然而由于使用的是發送節點進行丟失恢復,PGM丟失恢復延時和吞吐量性能要差于CoreRM算法。CoreRM算法在不同的信道損耗情況下始終能夠保持較高性能,因為CoreRM算法使用了最短距離的丟失恢復,將整個網絡的丟失恢復進行了分布式處理,因此在信道傳輸情況變差時,仍然能夠通過較短時間完成丟失恢復,保持較高的吞吐量。圖7和圖8所示的是在移動網絡中的性能仿真結果。圖7中顯示的是網絡的平均吞吐量曲線。圖8中顯示的是丟失恢復時延曲線。隨著節點移動速度的加快,網絡的拓撲變換更加的頻繁,這樣就增加的數據包丟失的概率,所以隨著節點移動速度的加快,數據包請求重傳的次數增加,整個網絡的正確投遞率也隨之下降。由于PGM使用的是源端重傳而延長了丟失恢復的時延,并且基于源節點的重傳恢復增加了網絡傳輸的控制開銷,影響到整個網絡數據包的正確投遞和吞吐量性能,導致性能差于CoreRM。CoreRM算法使用了最短距離丟失恢復設計,丟失節點周圍的鄰居節點協同幫助恢復,使得丟失重傳的數據包的傳輸范圍縮小,避免了隨著節點移動速度加快而產生的丟失恢復時延急劇增長。

圖3 鏈路丟包率影響下的丟失恢復跳數

圖4 鏈路丟包率影響下的平均恢復時延

圖5 信道損耗影響下的吞吐量
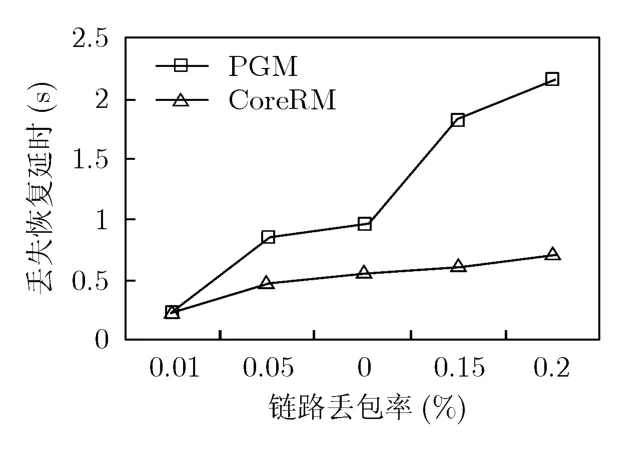
圖6 信道損耗下的丟失恢復延時

圖7 移動速率影響的平均網絡吞吐量

圖8 移動速率影響下的丟失恢復延時
5 結束語
在本文中提出了一個適用于Ad hoc網絡的可靠組播協同丟失恢復算法CoreRM。CoreRM是基于NAK確認的協同丟失恢復算法,鄰居節點通過提供丟失數據重傳或者是數據恢復路徑信息,盡力而為地協同幫助丟失數據的恢復;組播路徑上的上游節點和源節點在本地恢復無法完成丟失恢復時,提供丟失恢復幫助。CoreRM算法使用周期性發送SPM包來應對Ad hoc網絡中拓撲的頻繁變動,使用NAK抑制策略來避免NAK風暴。算法的設計主要目的是將Ad hoc網絡中產生的丟失恢復在整個網絡中分散處理,盡量使用最短的距離和最短的時間完成丟失恢復。 通過仿真各種Ad hoc網絡環境,對比其它兩種非協同式的組播傳輸協議算法性能,發現使用了協同恢復的CoreRM的性能在各種仿真環境中可靠性要高于非協同恢復算法。我們計劃在未來的設計中,將基于窗口或者基于速度的擁塞控制機制引入到CoreRM算法中,進一步的提高算法的可靠性。
[1] Gemmell J, Montgomery T, Speakman T, Bhaskar N, and Crowcroft J. The PGM Reliable Multicast Protocol. IEEE Digital Object Identifier 10.1109/MNET.2003.Volume 17,Issue1, Jan-Feb. 2003: 16-22.
[2] Gopalsamy T, Singhal M, Panda D, and Sadayappan P. A reliable multicast algorithm for mobile ad hoc networks. 22nd International Conference on Distributed Computing Systems,Vienna, Austria, July 2-5, 2002: 563-570.
[3] Ouyang.B and Hong Xiao-yan, and Yi Yun-jung. A comparison of reliable multicast protocols for mobile ad hoc networks. Proceeding IEEE, SoutheastCon, 2005, April 8-10,2005: 339-344.
[4] Chandra R, Ramasubramanian V, and Birman K P.Anonymous gossip: improving multicast reliability in mobile ad-hoc networks. Distributed Computing Systems, Arizona,USA, 2001, April 16-19, 2001: 275-283.
[5] Fung Alex and Sasase Iwao. Hybrid local recovery scheme for reliable multicast using group-aided multicast scheme.WCNC2007, Hong Kong China, March 11-15, 2007:3478-3482.
[6] Koutsonikolas D, Hu Y C, and Wang Chih-Chun. Pacifier:high-throughput, reliable multicast without“crying babies”in wireless mesh networks. IFOCOM 2009. The 28th Conference on Computer Communications. Rio de Janeiro,Brazil. April 19-25, 2009: 2473-2481.
[7] Fen Hou, Cai L X, Ho Pin-han, Shen Xuemin, and Zhang Junshan. A cooperative multicast scheduling scheme for multimedia services in IEEE 802.16 networks. Wireless Communications, ISSN: 1536-1284, March 2009: 1508-1519.
[8] Alay O, Pan Xin, Erkip E, and Wang Yao. Layered randomized cooperative multicast for lossy data: a superposition approach.. CISS 2009.43rd Annual Conference,Baltimore, MD, March 18-20, 2009: 330-335.
[9] Zhu Yufang and Kunz T. MAODV implementation for NS-2.26. systems and computing engineering, Carleton University, Technical Report SCE-04-01, January 2004.
[10] Saikia L P and Hemachandran K. Reliable multicast protocol adopting hierarchical tree-based repair mechanism. ICACT 2009.11th International Conference, Gangwon-Do, South Korea, Feb. 15-18, 2009: 1969-1973.
[11] Feng Gang, Zhang Jing-yu, and Xie Feng. Efficient buffer management scheme for loss recovery for reliable multicast[C]. Proceedings of IEEE Globecom 2004, Dallas,USA, 2004: 1152-1156.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
