智能化中文機械分詞組件的設計
2009-09-27 06:10:28齊忠琪
中國教育技術裝備 2009年21期
齊忠琪
摘要 分詞是計算機系統(tǒng)對自然語言處理的第一步,分詞的方法與準確率將顯著影響自然語言的處理效果。在分析機械分詞技術的基礎上,提出構建智能化機械分詞組件的思想,論述構建智能化中文分詞組件的基本思路與方法,指出智能化中文機械分詞組件在中文信息處理領域中的應用前景。
關鍵詞 中文處理;機械分詞;組件設計
中圖分類號:TP391.43 文獻標識碼:B 文章編號:1671-489X(2009)21-0095-02
Design of Intelligent Mechanical Segmentation Module for Chinese Word//Qi Zhongqi
Abstract The first step of natural language processing (NLP) on computer is the segmentation for word. It affects the effect of NLP evidently that which segmentation method is used and what its precision is. In this paper, based on the comparison of several commonly used segmentation methods for Chinese word, we propose the idea of building the intelligent mechanical segmentation module. We present the basic idea and methods of the intelligent mechanical segmentation module, and forecast its prospect of application in Chinese information processing.
Key words Chinese language processing; mechanical segmentation of words; module design
Authors address Education and Science Academy of Xinjiang Normal University, Urumqi, 830053, China
文字是人類用來交際和學習知識的符號系統(tǒng),在20世紀80年代之前,人們對中文文字的認識與應用僅僅停留在以紙張為媒介的書面文字階段。計算機技術和通信技術的飛速發(fā)展,為中文文字的數字化處理搭建了一個全新的平臺。但由于中文文字屬于表意文字,且數量驚人,如何能讓計算機智能化處理中文文字,提高人們獲取知識的效率,則成為計算機文字處理研究領域研究的一個熱點[1-2]。
1 機械分詞法
機械分詞法[3]有時也被稱為基于字符串匹配的分詞方法。該方法主要是按照一定策略,將待分析的漢字串與事先做好的詞典中的詞條進行匹配,從而得到分詞結果。根據匹配的策略不同,該分詞法存在幾種不同的實現方式,其中常用的有正向最大匹配、逆向最大匹配、最少切分等。無論采用哪種方式來實現機械分詞,必須要有分詞詞典的支持,并且詞典的完備程度將大大決定分詞的準確度。
該分詞法的優(yōu)點是:算法簡單且容易實現,出錯幾率較低。其缺點是:效率和準確性受到詞庫容量的約束,存在歧義切分的問題。
2 在信息檢索與智能化產品開發(fā)中應用機械分詞法的優(yōu)點
2.1 技術要求相對比較簡單機械分詞法對程序設計人員的綜合技術水平要求較低,更容易被大多數程序設計人員所接受。若采用基于統(tǒng)計的分詞方法[4],開發(fā)人員必須具有一定數學建模經驗,并能理解有關數學模型,還必須對漢語言知識有所研究,有一定語言學的基礎。
2.2 產品開發(fā)成本低機械分詞法的算法復雜度較低,實現起來較為容易,且有較多可供參考的成果。這樣可以大大降低產品開發(fā)成本。
2.3 分詞詞典構建難度低分詞詞典的構建與語料庫和知識庫的構建相比較為容易。目前有一些中文輸入法已經公開其詞庫,分詞詞典可以基于這些詞庫進行制作。
由此得出的結論是:在實際產品開發(fā)中,采用機械分詞法較為可行。
3 智能化產品中機械分詞組件的設計
3.1 組件整體設計在信息檢索、機器翻譯、自動應答等基于自然語言處理應用系統(tǒng)的開發(fā)中,首先必須實現分詞功能,該功能是后續(xù)功能實現的前提條件。鑒于這個特點可以將分詞功能模塊提取出來單獨設計,做成一個具有通用性的模塊。這樣可以將該模塊復用到大多數基于自然語言處理的應用系統(tǒng)當中。
3.2 組件類型設計綜合組件通用性及實現的難易程度可從2方面考慮,本文將分詞組件設計成動態(tài)鏈接庫的形式。在對組件進行組裝時,只需要清楚如何調用鏈接庫的接口函數,而不用關心函數內部實現。動態(tài)庫的代碼不需要重新被編譯,只在目標對象鏈接時引入即可。另外,當分詞算法被改進,需要重新對算法進行設計時,只要接口函數形式不變,使用動態(tài)鏈接庫的應用系統(tǒng)就不需重新設計,只修改函數內部實現即可。圖1表示動態(tài)鏈接庫與應用系統(tǒng)之間的關系。
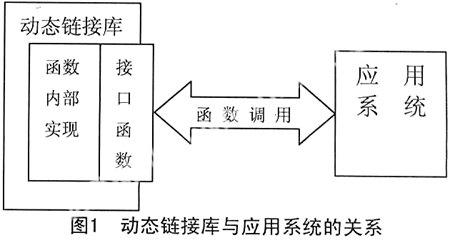
動態(tài)鏈接庫的實現是較為容易的。若在windows平臺下構建動態(tài)庫,可以在VC++6.0中創(chuàng)建Win32 Dynamic-Link Library工程,在創(chuàng)建好的工程項目中直接添加代碼即可。在Linux平臺下構建動態(tài)庫,也有現成的規(guī)則,只需按照規(guī)則書寫相關MakeFile文件即可。
3.3 組件接口設計在本文中組件被設計為動態(tài)鏈接庫的形式,組件接口則為動態(tài)鏈接庫提供外部函數,組件組裝過程即為函數調用過程。由此可見,函數的設計需要考慮到調用的復雜性及接口的通用性。除此之外,更要考慮到接口功能的可擴展性。
鑒于以上特點,接口函數的設計從2方面入手。第一,函數參數。在這里參數為待分詞的內容,在實現過程中,不妨利用字符串變量來存儲該內容。由于待分詞的內容均為文字信息,因此利用C++中的字符串對象String來存儲該信息是最為方便的。第二,函數返回值。分詞后的結果為一個個獨立的單詞,在實現過程中可考慮使用數組進行存儲。在這里每一個單詞可以看做是數組中的一個元素。考慮到分詞處理只是初步,在自然語言處理中對于分詞結果還需后續(xù)處理,因此可以建立一個結構體來保存單詞,單詞結構體中可以包含詞性、詞義等單詞相關信息,從而可為后續(xù)處理提供更多可用信息。每一個單詞對應一個結構體實例,分詞結果即為單詞結構體數組。在具體實現中,數組可以直接采用C++ STL中的vector模板來實現,這樣會大大降低開發(fā)復雜度。
3.4 分詞過程設計整個分詞過程的設計是以機械分詞中的最大正向匹配算法為基礎的,其設計重點主要集中在2個方面:最大正向匹配算法的實現與分詞詞典的設計。
1)最大正向匹配算法的實現。該算法的基本思想是:假設所用的分詞詞典中,最長的一個詞所含有的漢字個數為L,則從待分詞的內容中取出前L個漢字作為匹配字串,接著在詞典中查找該匹配字串,如果能找到,說明該字串可以組成一個詞,被切分出來;如果詞典中不存在該字串,則將字串中的最后一個字刪除構成新的字串,再進行同樣的匹配過程,直至匹配成功。由此完成第一個詞的切分,繼續(xù)這樣的循環(huán)直至所有詞被切分出來為止。
從算法的基本思想來看,整個過程是以循環(huán)迭代處理為主,這正符合計算機處理問題的特點,下面將闡述如何實現該算法流程。
①假設:S為待分詞的字符串,S=C1C2C3…Cn(Ci為單字);L為分詞詞典中最長詞所含的漢字個數;W為存放單詞的臨時變量;R為最終分詞結果,即W的集合;i、j為臨時變量,i=1。②j=min(i+L-1,n);轉到③。③W=Ci…Cj;W在詞典中是否存在?是,轉到④;否,轉到⑤。④W為一個單詞,將W存入R中;i=j+1;i 在上述流程中需要注意的是:在分詞詞典中不存在的詞,最終會被切分成逐個單字。但前提是待分詞的內容是由單個漢字組成的字符串,而編程語言中并沒有為漢字設定變量類型,因此在實現時應做一定的轉碼處理。 2)分詞詞典的設計。分詞詞典在計算機中就是存放單詞信息的文本文件或二進制數據文件,具體文件格式可以自由設定。為了文件讀取方便,可以采用一行一個詞條的格式,每個詞條包含2部分內容——單詞本身及其詞性,二者之間以空格相隔。 評價機械分詞算法實現得好壞的重要因素就是詞典查找效率。為提高效率,在分詞時會將詞典先加載到內存中,再從內存中進行搜索,因此詞典在內存中的存儲形式將大大影響查找效率。由于詞典文件格式被設計為每個詞條包含單詞本身及詞性2部分內容,詞本身決定其詞性,二者類似于鍵值對關系。因此本文提出將詞典以STL中Map的形式存儲。 4 智能化中文機械分詞組件的實際應用 智能化中文機械分詞組件基于系統(tǒng)集成的思想,將功能實現隱藏在固定接口之內,從而為中文信息處理類軟件的設計和不斷完善提供方便。用此組件開發(fā)中文信息處理類軟件,具有周期短、開發(fā)成本低、通用性強等特點。 將此組件嵌入網站應用程序中,可以在普通網站中構建簡潔、實用的中文搜索引擎,方便一般網站中的信息檢索;將此組件嵌入語音合成系統(tǒng)中,可以提高文語轉換的效率,降低普通級語音合成系統(tǒng)的開發(fā)成本;將此組件嵌入智能化產品中,可以方便產品的更新?lián)Q代與內核升級…… 本文作者提出的分詞組件的設計思想,雖然不是計算機自動分詞的最佳方法,但在具體應用方面,則具有一定的價值。 參考文獻 [1]王曉龍,關毅,等.計算機自然語言處理[M].北京:清華大學出版社,2005 [2]郭慶琳,樊孝忠.自然語言理解與智能檢索[J].信息與控制,2004,33(1):120-123 [3]周文帥,馮速.漢語分詞技術研究現狀與應用展望[J].山西師范大學學報:自然科學版,2006,20(1):25-29 [4]瞿鳳文,赫楓齡,左萬利.字典與統(tǒng)計相結合的中文分詞方法[J].小型微型計算機系統(tǒng),2006,27(9):1 766-1 771
