基于邊界信息的自適應過采樣算法
2025-01-01 00:00:00杜睿山靳明洋孟令東宋健輝
鄭州大學學報(理學版) 2025年1期





摘要: 針對人工少數類過采樣(synthetic minority over-sampling technique,SMOTE)算法存在樣本合成區域狹小,容易將少數類泛化到多數類及引入噪聲的問題,提出一種基于噪聲過濾、邊界點自適應采樣的過采樣算法。首先,該算法使用K近鄰算法進行噪聲過濾,接著確定邊界點并在邊界點中尋找合適的點作為根樣本點,并以其K近鄰點中與其同類且歐氏距離最遠的點作為候選樣本點。然后,根據根樣本點所攜帶的邊界信息確定該點所合成的樣本數量,并根據根樣本點和候選樣本點生成一個N維球體作為樣本的合成區間。最后,對合成樣本進行判斷以確定其是否滿足條件。通過實驗證明,該算法生成的樣本質量要優于SMOTE及其常見變種算法。
關鍵詞: SMOTE; KNN; 過采樣算法; 數據不均衡; ISMOTE
中圖分類號: TP391
文獻標志碼: A
文章編號: 1671-6841(2025)01-0023-08
DOI: 10.13705/j.issn.1671-6841.2023160
Adaptive Sampling Algorithm Based on Border Information
DU Ruishan1,2, JIN Mingyang1, MENG Lingdong2, SONG Jianhui1
(1.Department of Computer and Information Technology, Northeast Petroleum University,
Daqing 163318, China; 2.Key Laboratory of Oil and Gas Reservoir and Underground Gas Storage
Integrity Evaluation, Northeast Petroleum University, Daqing 163318, China)
Abstract: In order to address the issues of limited synthetic region, potential generalization of minority class to majority class, and introduction of noise in the synthetic minority over-sampling technique (SMOTE) algorithm, a oversampling method based on noise-filtering and boundary-point adaptive sampling was proposed. Firstly, the K-nearest neighbors algorithm was utilized for noise filtering. Next, the boundary points were identified and appropriate points among them were selected as root samples, with the candidate samples being chosen as the farthest points in the K-nearest neighbors of the same class with the root samples based on the Euclidean distance. Subsequently, the number of synthetic samples to be generated for each root sample was determined based on the boundary information carried by the root samples. An N-dimensional sphere was created using the root samples and the candidate samples as the synthesis interval for the samples. Finally, the synthesized samples were assessed to ensure their compliance with the conditions. Experimental results demonstrated that the proposed method yielded samples with higher quality compared to SMOTE and its common variants.
Key words: SMOTE; KNN; oversampling algorithm; unbalanced data; ISMOTE
0引言
分類問題是機器學習領域中的一個重要問題。在處理分類問題時,傳統分類算法往往會假設不同類別的樣本數量大致是相同的。但在實際數據中,不同類別的樣本數量往往存在著巨大差異[1]。
少數類樣本數量較少,不能很好地表征少數類的特征。傳統分類算法為了追求整體的分類準確率,會將重點放在多數類而忽略對少數類特征的學習,這會導致少數類被誤分類。而大多數情況下,精準識別少數類才是研究人員所追求的目標。
針對數據不均衡問題,現行的解決方法大致可分為兩個層面[2]:數據層面和算法層面。本文將從數據層面解決數據不均衡問題。數據層面常見的方法包括過采樣、欠采樣[3]。過采樣方法可能會導致過擬合,而欠采樣方法可能會剔除部分有價值的數據。隨機過采樣[4]方法采用隨機復制少數類的方法擴充樣本,但是該算法容易將少數類特征具體化,產生過擬合。在諸多過采樣方法中,SMOTE[5]是其中經典的算法,至今仍有很多研究人員通過改進SMOTE來獲取良好的數據均衡效果。SMOTE通過尋找少數類樣本的K近鄰,將近鄰點和樣本點連接,在兩者之間確定合成的樣本點。然而,SMOTE在進行少數類樣本合成時,將所有少數類點的重要性一視同仁,忽略了樣本分布對合成數據的影響,可能會引入噪聲,增加學習少數類特征的難度。
針對SMOTE隨機選擇樣本點進行新樣本合成,并不能很好呈現出少數類邊界的問題,He等[6]提出了ADASYN算法。ADASYN通過學習少數類所攜帶的邊界信息自適應地生成少數類樣本。Han等[7]設計了Borderline-SMOTE算法,該算法將根樣本點放在少數類的邊界區域,通過樣本點K近鄰中多數類和少數類樣本所占比例合成樣本。針對SMOTE的樣本合成區間僅是在兩個少數類點的連線間的問題,許丹丹等[8]提出ISMOTE,使用兩個少數類點構成的N維球體作為樣本合成區間。楊思狄等[9]提出將ISMOTE和SVM結合構建分類模型,擴大了樣本的合成區間并取得了良好的分類效果。針對SMOTE合成樣本時易引入噪聲的問題,Yi等[10]提出ASN-SMOTE算法,首先使用KNN濾除噪聲,然后計算合成樣本難度并根據難度進行自適應過采樣。Arafa等[11]提出RNSMOTE,該算法將SMOTE和DBSCAN結合起來,首先直接使用SMOTE對數據進行合成,針對SMOTE合成的噪聲,使用DBSCAN進行檢測并清除。
生成對抗網絡[12](generative adversarial networks,GAN)在圖像增強[13]領域獲得了巨大的成功。隨著其發展,有學者提出使用基于GAN生成對抗網絡的方法合成結構化數據。張浩等[14]提出使用基于WGAN的數據均衡方法,首先對數據集特征進行劃分和提取,然后通過WGAN來進行數據均衡。Zheng等[15]將WGAN-GP和CGAN結合的方法對不均衡數據進行過采樣,并在15個數據集上進行實驗,證明了所提方法的優越性。但使用GAN及其改進方法進行數據均衡存在著模型收斂困難、所需計算資源較大等問題。使用SMOTE及其變種方法對不均衡數據進行均衡則不存在需要大量的計算資源和模型收斂等問題。故本文仍使用基于SMOTE的算法均衡數據。
上述算法對SMOTE進行了許多改進,但針對不均衡分類問題仍顯得有些不足。本文提出一種基于SMOTE和邊界點自適應采樣的過采樣RDSMOTE算法。本算法使用基于K近鄰的噪聲過濾算法去除噪聲,然后選擇邊界點作為根樣本點,在根樣本點的K近鄰點中選擇距離根樣本點歐氏距離最遠的同類別點作為候選樣本點,最后將樣本合成區域擴大為以根樣本點為球心,以上述距離為半徑的N維球體。在確定每個少數類實例合成樣本數量時,對每個少數類點采用自適應算法進行樣本合成,然后對合成的少數類樣本再次進行噪聲過濾,直至合成的樣本數量滿足所需為止。
1相關工作
1.1ADASYN
相比與SMOTE,ADASYN引入了自適應合成樣本數量的思想。其關鍵步驟如下。
輸入:數據集D。
輸出:均衡后數據集D。
Step1定義不均衡率r,
r=m/m,
其中:m、m分別為少數類和多數類的數量;
r′為判定數據集是否均衡的不均衡率閾值;
當r<r′時,進入Step2,否則視為均衡數據,不進行過采樣。
Step2計算樣本達到均衡時,少數類需要合成的數量n,
n=(m-m)×β,β∈(0,1],
其中:β表示期望達到的數據均衡率,當β為1時,均衡后的少數類數量和多數類相同。
Step3根據x的K近鄰樣本中多數類的個數,計算每個少數類樣本x的不均衡率,x為少數類的任意一個樣本,
r=Δ/K,i=1,…,m,
其中:K表示少數類的K近鄰數;Δ表示x的K近鄰樣本中多數類的數量。
Step4對r進行歸一化,
=r∑mi=1r。
歸一化之后, 滿足∑mi=1=1。
Step5計算每個少數類點x合成的樣本數量g,
g=×n。
Step6按照SMOTE算法進行樣本合成,
xnew=x+rand(0,1)×(x-x),
其中:xnew為合成的新樣本;rand(0,1)返回0~1之間的隨機數;x代表x的一個K近鄰樣本。
1.2ISMOTE
ISMOTE采用的思想和原始的SMOTE基本是一致的,都是采用選擇少數類中的兩個點進行樣本合成。但ISMOTE以一個少數類點為球心,以球心的一個近鄰樣本構成一個N維球體,在該球體內合成少數類樣本。其關鍵步驟如下。
輸入:數據集D。
輸出:均衡后數據集D。
Step1確定根樣本點。計算每個少數類樣本點的K近鄰,若其K近鄰都是少數類,則標記為根樣本點。
Step2確定候選樣本點。將根樣本點的K近鄰作為該根樣本點所對應的候選樣本點。
Step3合成樣本。假設數據集維度為n,x為一個根樣本點,x為x的一個候選樣本點,x為點x在第m維的值,由x和x合成的新樣本xnew則應滿足
Edis(xnew,x)≤Edis(x,x),
xnew=x+rand(0,1)×(b-a),
a=x-x-x,
b=x+x-x,
其中:Edisfbee748cd1fe87137d5152db04159e301708d235c5d0e1ed86187e945b56edbf()返回兩者間的歐氏距離。
2本文算法
傳統SMOTE雖然能處理數據不均衡問題,但合成少數類樣本的空間狹小,可能會模糊多數類與少數類的邊界。針對傳統SMOTE存在的問題,本文提出了RDSMOTE算法,該算法結合了自適應過采樣算法和ISMOTE算法,擴大了樣本的合成區間,可以合成質量較高的少數類樣本。本算法步驟可分為噪聲過濾、確定合格樣本、確定樣本合成數量、樣本合成。
本文將樣本數量最多的類記為多數類,其他類記為不同類別的少數類。首先給出形式化定義:總體樣本表示為D;總體樣本數量為N;多數類表示為D;多數類數量為N;所有的少數類表示為D,所有少數類的數量為N,少數類共有c種,單個少數類表示為D(i=1,…,c),單個少數類的數量為N,樣本的維度為n。
2.1噪聲過濾
在處理實際數據時,噪聲數據的存在不可避免。噪聲不僅會影響過采樣算法的合理性和所合成樣本的質量,還會影響分類器的準確性。在此階段,本文提出了一種基于最近鄰的噪聲過濾算法,以濾除少數類中的噪聲,提高合成樣本質量。本算法通過每個少數類樣本點的最近樣本點來篩選噪聲并濾除。
對于D中的一個隨機樣本x,計算x到D中每個樣本的歐氏距離。如果距離最近的樣本與其不屬于同一類別,則將該點視為噪聲并刪除。
算法1噪聲過濾算法
輸入:D,D,A,其中A為合格樣本集。
輸出:D,D。
Step1初始化A。
Step2計算x與D中各個點的歐氏距離,并找出與x距離最近的點。
Step3若x與x不是同一類別,則將x視為噪聲點。否則視為合格樣本點并添加至A。
Step4根據A更新D和D。
2.2確定合格樣本
用于合成樣本點的少數類(根樣本點)及其近鄰點(候選樣本點)對合成樣本的質量有很大的影響。原始的SMOTE算法采用隨機選擇根樣本點和候選樣本點來合成樣本,這種做法可能會導致合成樣本點落在多數類區域。為此,本文提出一種基于邊界信息的樣本選擇策略。
首先,求出x在D中的K近鄰點。統計x的K近鄰樣本中與x屬于同一類別的樣本數目并記為num,若2/K≤num≤K,則將x定義為邊界點,將邊界點作為根樣本點。在其K近鄰點中,找到距離x最遠的同類別點x,將x記為根樣本點,將x記為x對應的候選樣本點。最后將二者分別記錄下來。
算法2樣本選擇算法
輸入:D,D。
輸出:B,C。
Step1初始化B,C,其中B、C分別為根樣本集和候選樣本集。
Step2使用KNN算法計算x的K近鄰,并計算近鄰點中與x同類別的點的個數num。若2/K≤num<K,則將其標記為邊界點。若為邊界點則執行step3。
Step3在邊界點x的K近鄰中,找出與x同類別且歐氏距離最大的點x,并將x添加至B,并將x添加至C中。
2.3確定樣本合成個數
在合成樣本時,單個樣本點所攜帶信息各不相同,單個少數類所合成樣本的數量對樣本質量有重要的影響。本算法在確定單個少數類點合成樣本數量時主要參考邊界點的不均衡率,即少數類點的K近鄰點中其他類別樣本點數量與K的比值。主要思想是對某個少數類D,首先根據D與多數類樣本個數的差值確定需要合成的樣本數量S。然后針對x計算不均衡率,對D中所有點的不均衡率進行歸一化。歸一化之后,所有的不均衡率之和為1。x所需要合成的樣本點數量為其不均衡率乘以S。
算法3確定合成樣本數量算法
輸入:B,C,D,D。
輸出:n。
Step1設定不均衡閾值r′,分別計算每個少數類和多數類樣本數量的比例。若比例高于r′,則不對該少數類進行過采樣。若比例低于r′,則執行step2。
Step2計算D需要合成的樣本數量S,
S=β×(N-N),
其中:當β=1時,樣本合成之后少數類和多數類的數量相等。
Step3確定D中每個點的不均衡率r,
r=Δ/k,
其中:Δ為x的K近鄰中多數類的個數。
Step4對不均衡率進行歸一化,
=r∑Ni=1r。
Step5計算每個少數類樣本點所需要合成樣本的數目n,
n=S×。
2.4樣本合成
針對SMOTE樣本合成區間狹小的問題,本算法使用以根樣本點為球心、根樣本點和候選樣本點之間的歐氏距離為半徑的N維球體作為樣本的合成區間。考慮根樣本點和候選樣本點所形成的球體之間存在其他類,為優化合成樣本的質量,對合成的樣本進行篩選,篩選算法同噪聲過濾算法相同。若距離合成點最近的點為其他類點,則刪除該點并重新合成樣本點。
算法4樣本合成算法
輸入:B,C,D,D,n。
輸出:D。
Step1根據根樣本點和半徑生成樣本,所合成的樣本應符合
Edis(xnew,x)≤Edis(x,x),
a=x-x-x,
b=x+x-x,
xnew=x+rand(b-a),
其中:m表示少數類的第m維,1<m<n;
x為x的第m維的值;
Edis()返回兩點間的歐氏距離。
Step2使用算法1進行判斷合成的樣本點是否合理,合理則保留,不合理則重新生成。
Step3Step2合成的樣本與D合并為最終樣本集D。
RDSMOTE算法流程如下。
Step1使用算法1刪除噪聲點。
Step2使用算法2篩選出每個少數類的根樣本點和與其對應的候選樣本點。
Step3使用算法3計算出每個少數類需要生成的樣本數量,及每個少數類中每個樣本點需要生成的樣本數量。
Step4使用算法4合成樣本,對合成樣本是否合格進行驗證。合格則保留該點,不合格則重新合成,直至合成的樣本數量達到所需數量。
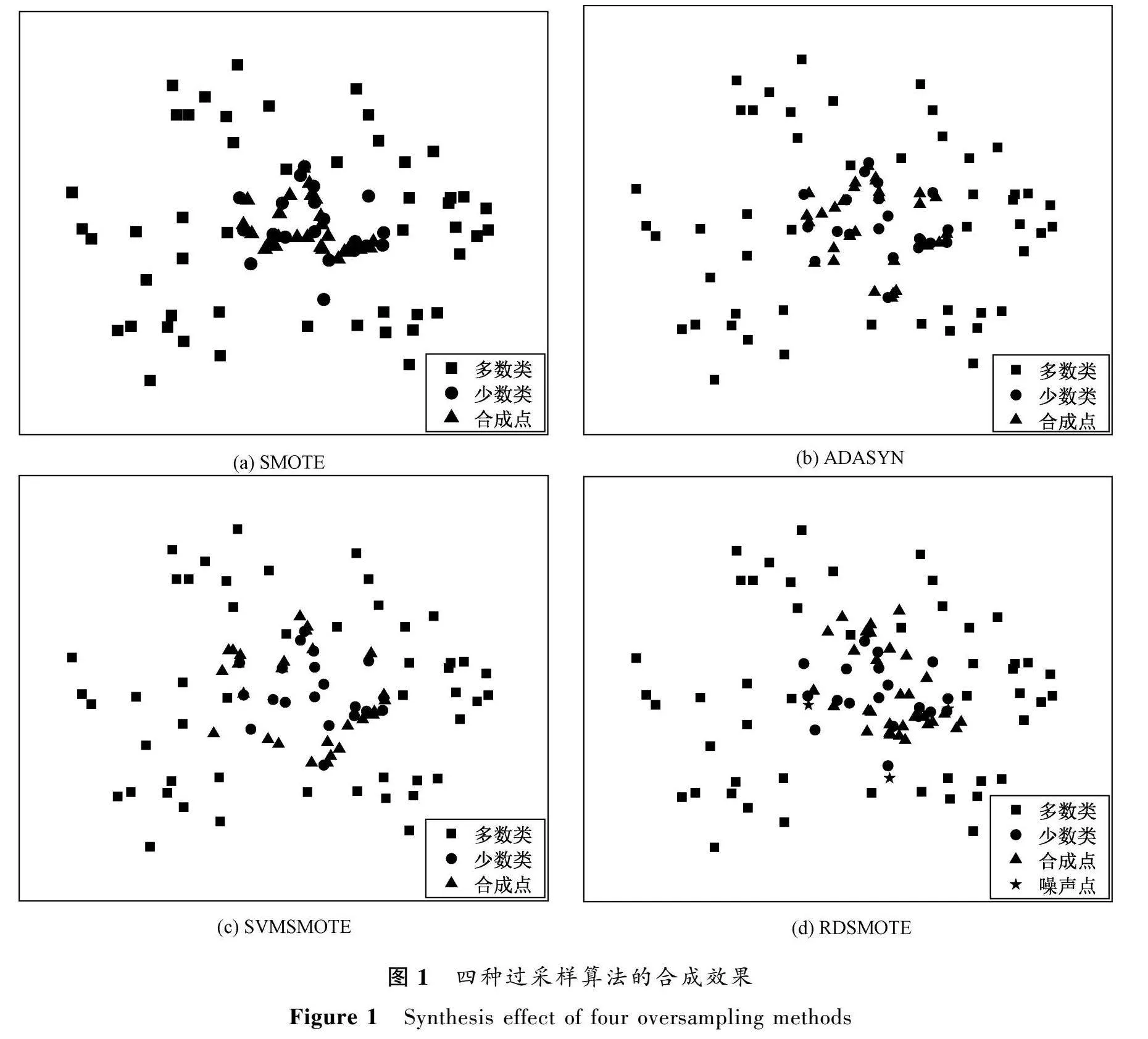
圖1為使用SMOTE算法、SVMSMOTE算法、ADASYN算法、RDSMOTE算法在二維數據上進行數據處理的結果。
所使用的數據由sklearn庫中的make_circles()函數生成,是一個在二維平面上形狀如內圓和外圓的數據集。本文共生成100個樣本,噪聲為0.3,內側圓和外側圓之間的空隙比為0.2,多數類和少數類之間的比例為4∶1。通過圖1可以看出,SMOTE所合成點主要在少數點的內部,沒有很好地采集刻畫出少數類樣本的分布特征。ADASYN和SVMSMOTE的采樣結果比SMOTE更關注邊界信息,但合成樣本的多樣性不足。RDSMOTE同時關注了少數類內部和邊界信息,較好地表現出樣本的分布特征,所合成新樣本的多樣性也有所提高。
3實驗
3.1數據集介紹
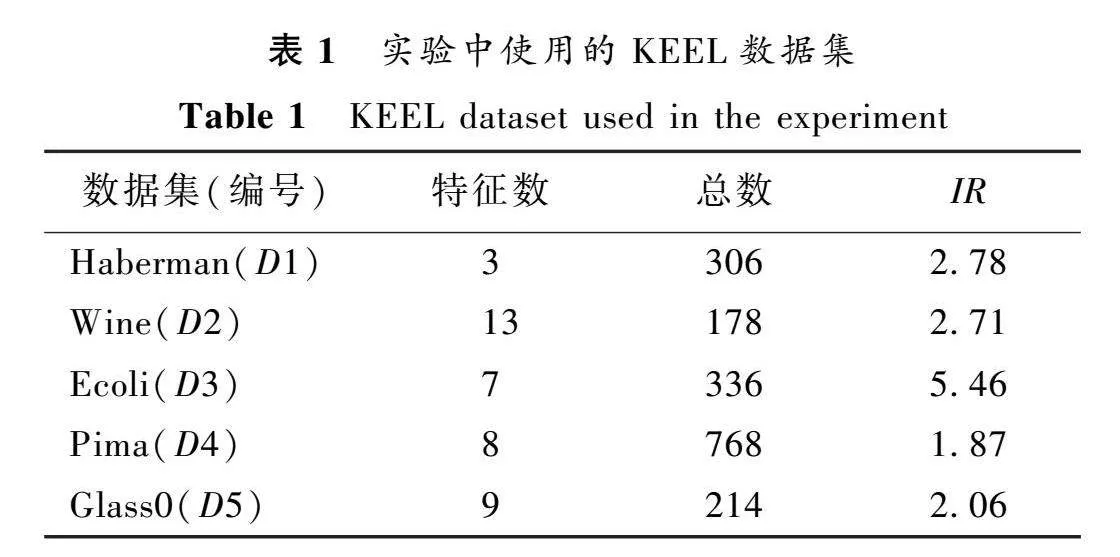
為了評估本算法的性能,本文使用來自KEEL中的5個公共數據集作為實驗數據。這些數據集中既有二類數據集又有多類數據集。數據集的樣本數量為178~768。數據集的不均衡比(IR)為1.87~5.46。在實驗中,將每個數據集里數量最多的數據作為多數類,其余數據按照不同的類別分為不同的少數類。將每個數據集按照70%的訓練集和30%的測試集進行劃分。所使用數據集如表1所示。
3.2評價標準
分類準確度不適用于不平衡數據集[16],而混淆矩陣統計了各類樣本的分類情況,是衡量分類型模型性能最直觀的方法。本文中少數類定義為正類,多數類定義為負類。當正類樣本被預測為正類時記為TP,正類樣本被預測為負類時記為FN,負類樣本被預測為正類時記為FP,負類樣本被預測為負類時記為TN。
查準率:
Precision=TPTP+FP。
召回率:
Recall=TPTP+FN。
特異度:
Specificity=TNTN+FP。
F1值:
F1=(1+β2)×Precision×Recallβ2×Precision+Recall。
Gmean:
Gmean=TPTP+FN×TNTN+FP。
F1值是查準率和召回率的調和平均,F1值越高意味著算法對少數類樣本的識別性能越好。Gmean兼顧召回率和特異度,為二者的幾何平均,可以綜合評價多數類和少數類的分類情況。AUC是ROC曲線的面積,可以綜合比較分類器對多數類和少數類的分類能力,是數據不均衡情況下衡量分類器的最佳評價模型。
MG[17]和MAUC分別是在二類評價Gmean和AUC的基礎上擴展的多類不平衡學習的評價指標。
MG=∏ci=1Recall1c,
MAUC=2c(c-1)∑i<j
[M(i,j)+M(j,i)]2,
其中:β一般取1;M(i,j)為類i和類j之間的AUC。
本算法著重于多類不均衡問題的分類問題,為此采用F1、MG、MAUC作為評價指標來體現算法的性能。
3.3結果與分析
3.3.1結果分析
本文使用SMOTE、SVMSMOTE、ADASYN作為對比算法,使用隨機森林(random forest,RF)作為分類算法。為了統一標準,所有算法均采用默認參數。實驗中對每個數據集進行了10次隨機劃分,將3種評價指標的均值作為最終結果。
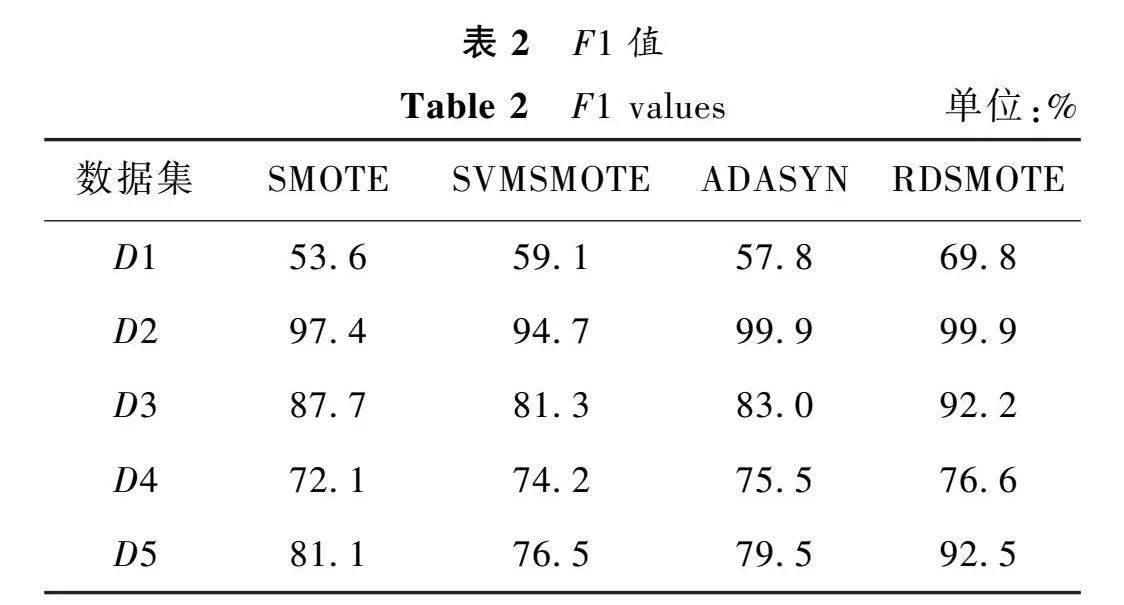
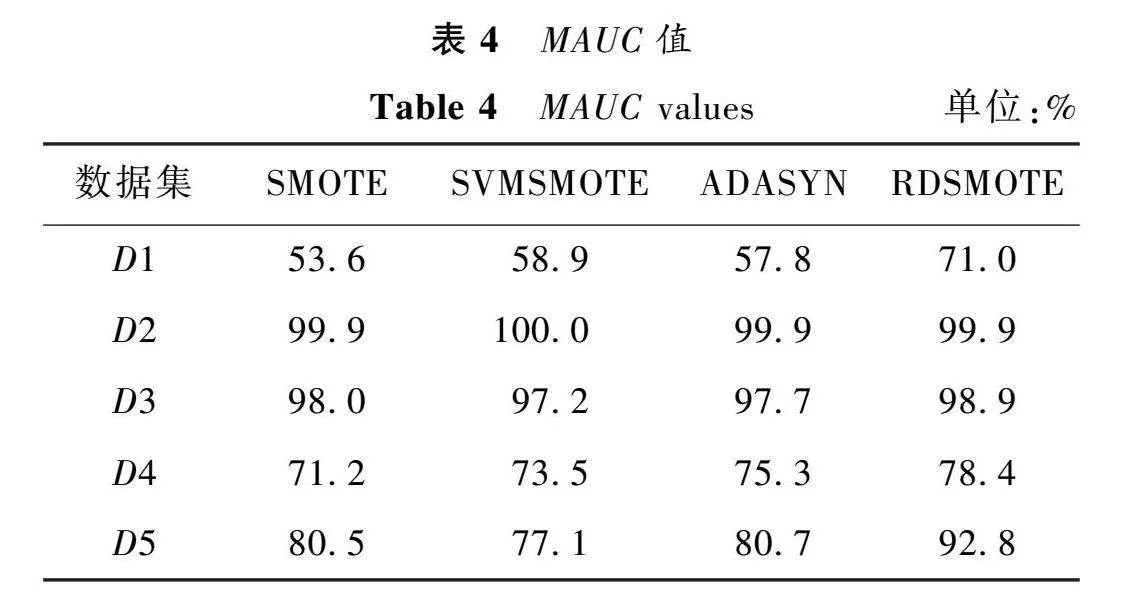
表2~4給出過采樣后的數據集在RF上的表現。
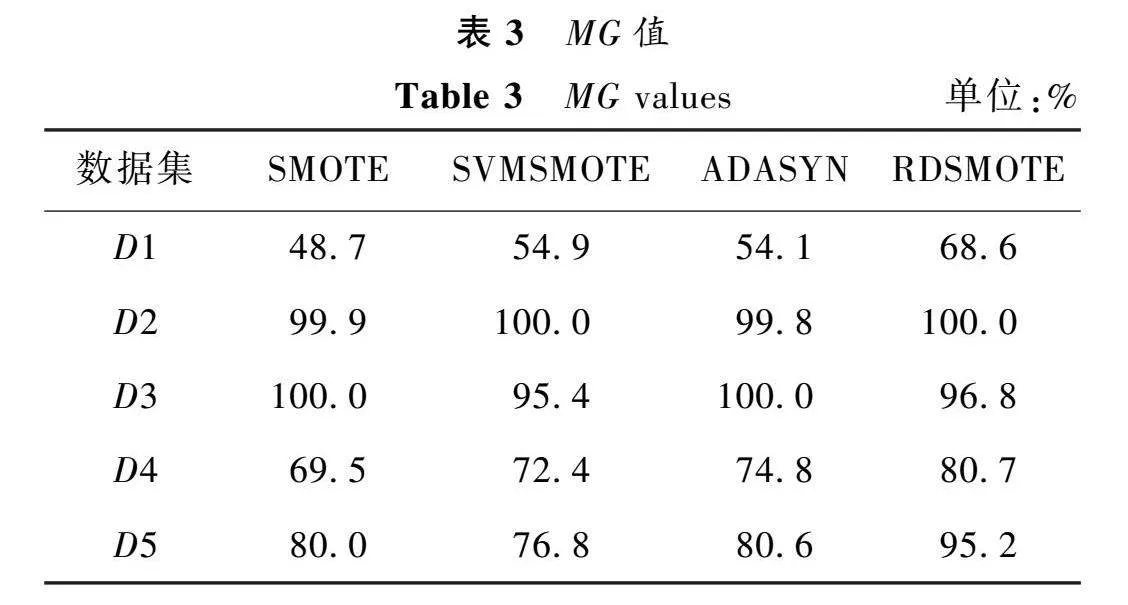
從表2~4可以看出,本文在5個數據集中均取得了較好的結果。在F1方面,本文在所有數據集中都取得了最優值。尤其在Haberman數據集中,比表現最差的SMOTE算法提高了16.2%,比表現最好的SVMSMOTE也提高了10.7%。在MG方面,本文算法在4個數據集中都取得了最佳表現,在Glass0中比SVMSMOTE提高了18.4%,比ADASYN提高了14.6%。在MAUC方面,在4個數據集中均取得了最優值,在Haberman數據集中,比最差的SMOTE提高了17.4%,比SVMSMOTE提高了12.1%。從以上數據可以看出,本文算法可以很好地處理二分類和多分類的數據不均衡問題。這是因為本文算法首先對數據進行了噪聲過濾,避免引入噪聲。然后,只對少數類的邊界點進行采樣,可以較好地學習少數類的邊界信息,避免邊界混淆。最后,將N維球體作為樣本合成區間,使得合成樣本的分布更加均勻,有效地提高了合成樣本的質量以及合理性,從而提高了算法的總體性能。
3.3.2參數討論
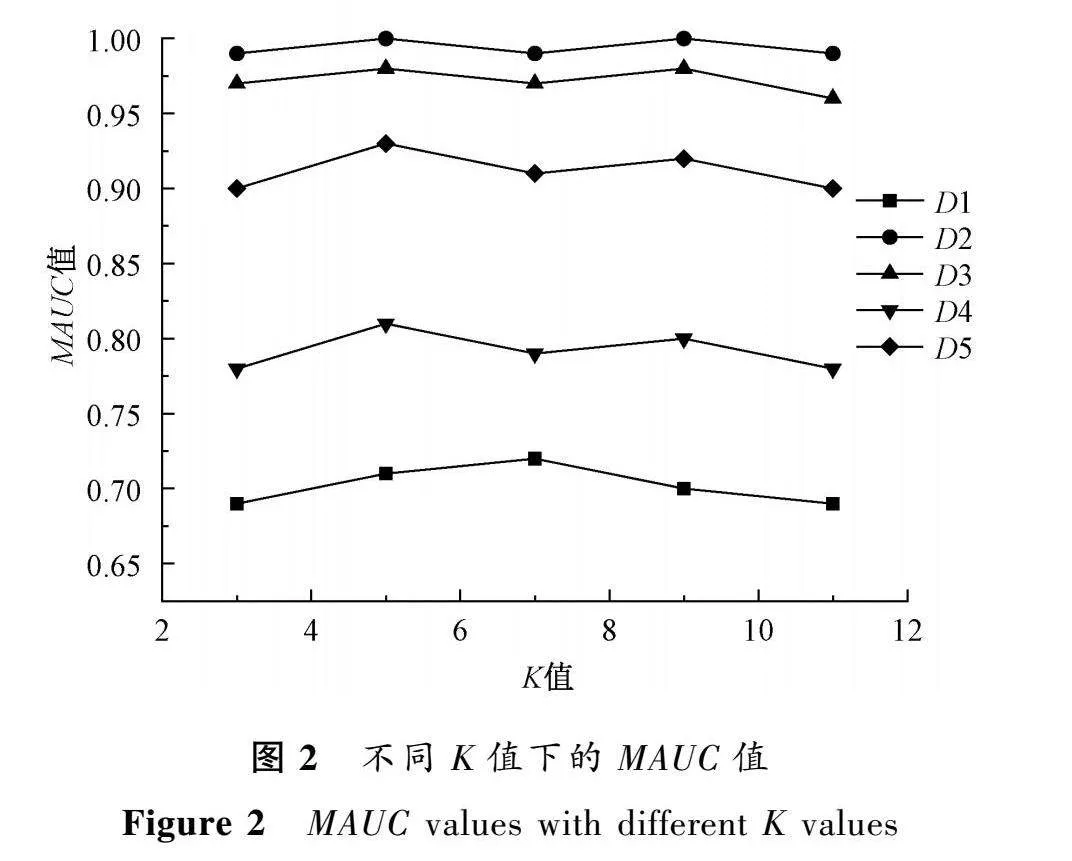
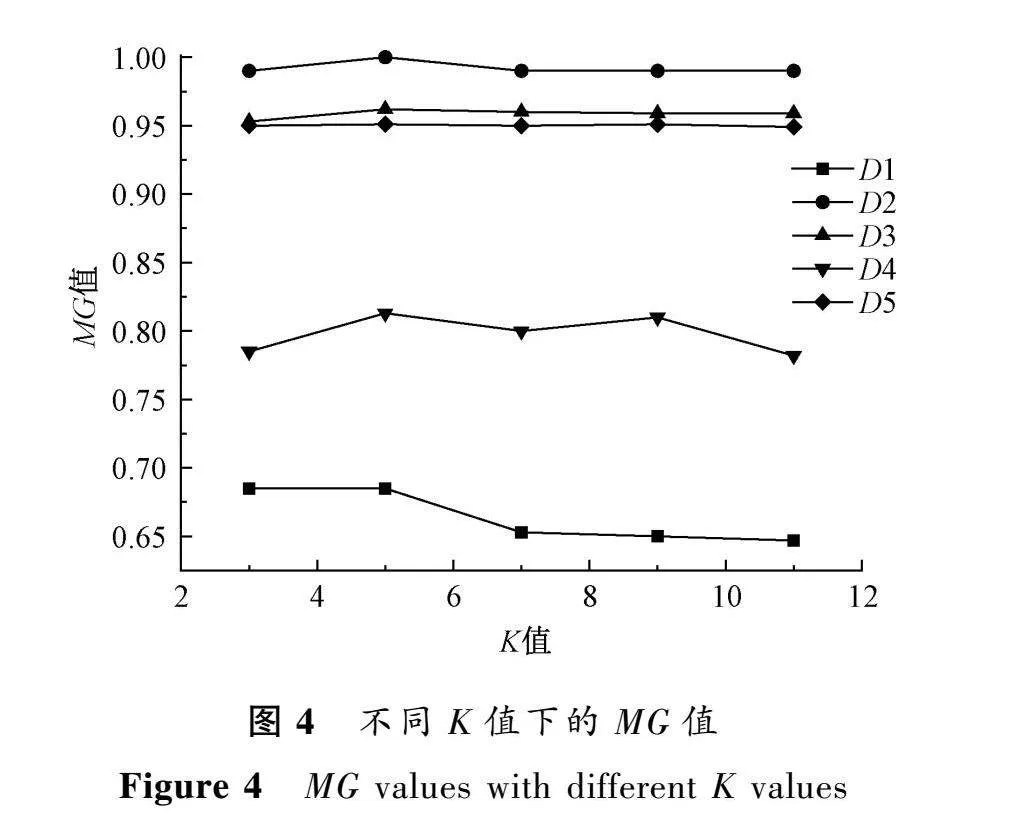
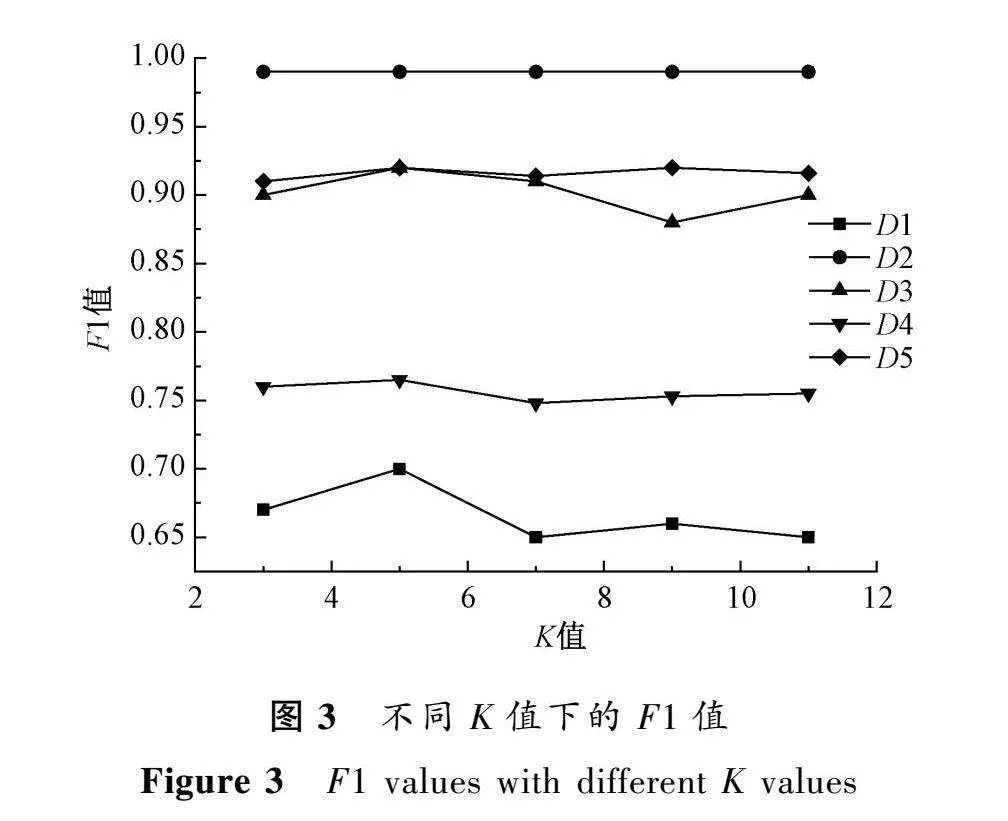
在本文算法中,K值對算法有著巨大的影響。為此,本文選擇3,5,7,9,11這5個奇數作為K值,通過對比RDSMOTE在不同K值下,MAUC、F1、MG的表現來確定K值。圖2~4為不同K值下的MAUC、F1、MG值。
可以看出,本文算法結果隨著K值的改變而改變。在K=5時,大多數數據集的F1、MG、MAUC都取得了最優解,且隨著K值的增加,性能有下降的趨勢。這是因為本文算法在合成少數類樣本時,使用邊界點作為根樣本點,隨著K值的增加,符合條件的根樣本點會隨之減少,在總的生成樣本量不變情況下,單個根樣本點合成樣本數量會隨之增加,這可能會使得分類器學到虛假的少數類特征,進而造成算法性能的下降。
4結論
本文提出了一種基于邊界點采樣的多類不均衡過采樣算法來處理多類不均衡問題。首先,對少數類點與距其歐氏距離最小的點進行判斷。若兩點不是同類別點,則將近鄰點作為噪聲并過濾。然后,對少數類樣本點進行邊界點篩選,將邊界點作為根樣本點,將根樣本點的K近鄰中距離根樣本點最遠且與其屬于同類別的點作為候選樣本點。根據根樣本點的邊界信息確定該點應該合成的樣本數量。在樣本合成階段,將樣本合成區間擴大為以根樣本點為球心,以根樣本點和候選樣本點為半徑的一個N維球體,有利于樣本的均勻分布并提高合成樣本的質量。最后,將本文算法和三種常見的過采樣算法進行對比實驗。實驗結果表明,在大多數的數據集中,本文算法表現更優。
下一步工作將圍繞以下方面展開:
1) 將本文算法所適用的數據集從數值型數據集擴大到非數值型數據集和混合型數據集。
2) 在合成樣本時,考慮將單個根樣本點合成樣本數量與同樣本權重結合,以便更合理地合成少數類。
參考文獻:
[1]王樂, 韓萌, 李小娟, 等. 不平衡數據集分類方法綜述[J]. 計算機工程與應用, 2021, 57(22): 42-52.
WANG L, HAN M, LI X J, et al. Review of classification methods for unbalanced data sets[J]. Computer engineering and applications, 2021, 57(22): 42-52.
[2]李昂, 韓萌, 穆棟梁, 等. 多類不平衡數據分類方法綜述[J]. 計算機應用研究, 2022, 39(12): 3534-3545.
LI A, HAN M, MU D L, et al. Survey of multi-class imbalanced data classification methods[J]. Application research of computers, 2022, 39(12): 3534-3545.
[3]于艷麗, 江開忠, 王珂, 等. 改進K均值聚類的不平衡數據欠采樣算法[J]. 軟件導刊, 2020, 19(6): 205-209.
YU Y L, JIANG K Z, WANG K, et al. Improved unbalanced data undersampling algorithm for K-means clustering[J]. Software guide, 2020, 19(6): 205-209.
[4]HE H B, GARCIA E A. Learning from imbalanced data[J]. IEEE transactions on knowledge and data engineering, 2009, 21(9): 1263-1284.
[5]CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002, 16: 321-357.
[6]HE H B, BAI Y, GARCIA E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]∥IEEE International Joint Conference on Neural Networks. Piscataway: IEEE Press, 2008: 1322-1328.
[7]HAN H, WANG W Y, MAO B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C]∥Proceedings of the 2005 International Conference on Intelligent Computing. Berlin: Springer Press, 2005: 878-887.
[8]許丹丹, 王勇, 蔡立軍. 面向不均衡數據集的ISMOTE算法[J]. 計算機應用, 2011, 31(9): 2399-2401.
XU D D, WANG Y, CAI L J. ISMOTE algorithm for imbalanced data sets[J]. Journal of computer applications, 2011, 31(9): 2399-2401.
[9]楊思狄, 王亞玲. 面向不均衡數據集的過抽樣數學模型構建[J]. 計算機仿真, 2021, 38(5): 472-476.
YANG S D, WANG Y L. Construction of an over-sampling mathematical model for unbalanced data sets[J]. Computer simulation, 2021, 38(5): 472-476.
[10]YI X K, XU Y Y, HU Q, et al. ASN-SMOTE: a synthetic minority oversampling method with adaptive qualified synthesizer selection[J]. Complex & intelligent systems, 2022, 8(3): 2247-2272.
[11]ARAFA A, EL-FISHAWY N, BADAWY M, et al. RN-SMOTE: reduced noise SMOTE based on DBSCAN for enhancing imbalanced data classification[J]. Journal of King Saud university-computer and information sciences, 2022, 34(8): 5059-5074.
[12]GOODFELLOW I J,POUGET-ABADIE J,MIRZA M ,et al. Generative adversarial nets [C]∥Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal: MIT Press,2014:2672-2680.
[13]張敏情, 李宗翰, 劉佳, 等. 基于邊界平衡生成對抗網絡的生成式隱寫[J]. 鄭州大學學報(理學版), 2020, 52(3): 34-41.
ZHANG M Q, LI Z H, LIU J, et al. Generative steganography based on boundary equilibrium generative adversarial network[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(3): 34-41.
[14]張浩, 康海燕. 基于特征優化生成對抗網絡的在線交易反欺詐方法研究[J]. 鄭州大學學報(理學版), 2022, 54(1): 69-74.
ZHANG H, KANG H Y. An generative adversarial network of online transaction anti-fraud method based on feature optimization[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(1): 69-74.
[15]ZHENG M, LI T, ZHU R, et al. Conditional Wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification[J]. Information sciences, 2020, 512: 1009-1023.
[16]ZHU T F, LIN Y P, LIU Y H. Synthetic minority oversampling technique for multiclass imbalance problems[J]. Pattern recognition, 2017, 72: 327-340.
[17]SUN Y M, KAMEL M S, WANG Y. Boosting for learning multiple classes with imbalanced class distribution[C]∥International Conference on Data Mining. Piscataway: IEEE Press, 2007: 592-602.
