融合深度強化學習與算子優化的流式任務調度
2025-01-01 00:00:00郭陳虹王菁鞏會龍郭浩浩張睿軒
鄭州大學學報(理學版) 2025年1期



摘要: 針對實時性要求高和作業量大的流處理作業執行過程中,多個作業之間存在的相同處理片段可能會導致流處理引擎重復計算、資源浪費和處理性能低下的問題,提出了融合深度強化學習與算子優化的流式任務調度方法。首先利用算子優化算法將多個復雜的作業去重、重構,其次將重構得到的作業輸入循環神經網絡中得到任務的調度策略,最后利用強化學習模型進行調度策略的優化。所提方法利用算子優化減少了每個作業中創建的算子實例,結合深度強化學習自動發現最優的調度策略,有效地避免了因大量實例運行而造成的系統資源不足、數據擁塞等問題。對比實驗結果表明,所提方法在吞吐量和延遲方面的表現更優異。
關鍵詞: 流處理作業; 任務調度; 算子優化; 深度強化學習
中圖分類號: TP18
文獻標志碼: A
文章編號: 1671-6841(2025)01-0015-08
DOI: 10.13705/j.issn.1671-6841.2023159
Stream Processing Task Scheduling Integrating Deep Reinforcement
Learning and Operator Optimization
GUO Chenhong1,2, WANG Jing1,2, GONG Huilong1,2, GUO Haohao1,2, ZHANG Ruixuan1,2
(1.School of Information, North China University of Technology, Beijing 100144, China;
2.Beijing Key Laboratory of Large-scale Streaming Data Integration and Analysis Technology
(North China University of Technology), Beijing 100144, China)
Abstract: Aiming at the problems of high real-time requirements and large workload during the execution of stream processing jobs, the same processing fragments among multiple jobs might lead to repeated calculations of stream processing engines, waste of resources, and low processing performance, a scheduling method for stream processing tasks that integrated deep reinforcement learning and operator optimization was proposed. Firstly, the operator optimization algorithm was used to deduplicate and reconstruct multiple complex tasks. Secondly, the reconstructed tasks were fUkXwAsx4LNglHN0AoE+wQ==input into a recurrent neural network to obtain the scheduling strategy for the tasks. Finally, the scheduling strategy was further optimized using a reinforcement learning model. The proposed method reduced the number of operator instances created in each task through operator optimization. By combining deep reinforcement learning, the method automatically discovered the optimal scheduling strategy, effectively avoiding issues such as insufficient system resources and data congestion caused by a large number of instances running. The comparative experimental results showed that the proposed method performed better in terms of throughput and latency.
Key words: stream processing job; task scheduling; operator optimization; deep reinforcement learning
0引言
流處理引擎可以從連續產生的數據流中實時地提取有用的信息,具有較快的響應速度和更好的實時性。然而,面對大量的實時產生的數據,流處理引擎需要在硬件設備等其他限制條件下快速地處理數據[1]。因此,提高流處理的性能和效率迫在眉睫。提高其性能可以考慮優化流處理作業中任務調度策略的方式[2-4],然而確定任務調度策略是一個NP難的問題。
目前,已有一些啟發式和深度強化學習的算法對如何確定任務調度策略進行了優化,考慮了流處理作業中算子的特征、計算資源同構或者異構等多種影響因素,盡可能地優化任務的調度執行。其中,算子是作業中的基本操作單元,而任務是由多個算子按照一定的順序和依賴關系組合而成的可執行單元。但是,確定任務調度策略還存在一些可以改善的地方。例如在大規模流數據到來之后,待處理的作業量很龐大,需要為一些小的作業單獨創建多個作業實例,一定程度上消耗了過多的資源。同時,這些計算作業之間有很多重復的算子組合片段,導致了處理引擎的重復計算,浪費了計算資源。
相較于一些傳統的啟發式算法,深度強化學習算法[5]可以動態地調整任務調度策略,不需要預先指定規則即可發現最優調度策略,并且能靈活設置優化目標。本文提出一種融合深度強化學習與算子優化的流式任務調度方法(stream processing task scheduling integrating deep reinforcement learning and operator optimization),簡稱為DRLAOO。該方法首先采用有向無環圖表示流處理作業的任務執行圖,采用連通圖表示計算資源的特征。其次,利用圖卷積神經網絡提取作業和計算資源的特征,把這些特征輸入循環神經網絡(recurrent neural network,RNN)中,利用注意力機制得到每個作業中任務的調度結果。最后,利用強化學習模型優化任務的調度策略。在對比實驗中,DRLAOO方法獲得了較低的延遲和較大的吞吐量,節約了計算資源的使用。
1相關工作
1.1任務調度級別優化
在任務調度算法方面,有傳統的調度算法以及深度強化學習算法。Agrawal等[6]提出一個基于度量的并行實時任務模型,并針對相應的實時調度問題,提出一種基于任務最大響應時間的調度策略。Blamey等[7]研究了混合云/邊緣部署設置中對CPU成本和消息大小敏感的調度流處理,目的是在有限的邊緣資源下最大限度地提高吞吐量。Li等[8]研究了3種調度策略,其中有關基于分解的并行任務調度是把多核機器上順序任務開發的調度算法作為黑盒,每個并行任務被分解為一組順序任務,然后使用一些已知的調度器對多核機器上的順序任務進行調度。Ni等[9]研究了在分布式系統中對連續數據流進行實時處理的流處理中的資源分配問題,提出一個圖感知編碼器-解碼器框架來學習一種廣義的資源分配策略。Huang等[10]在此研究基礎上進行了優化,在計算資源和網絡資源是異構的情況下設計了一個通用的基于深度強化學習的資源感知框架,利用圖嵌入和注意力機制對資源進行建模,預測任務分配的位置。但是,上述這些工作關注于單個任務級別的優化調度,很少考慮作業的復雜性和作業之間的算子重復片段導致的流處理引擎的重復計算問題。
1.2算子級別優化
王亞等[11]提出了基于匹配結果共享的方法來優化流數據的處理,利用已經計算出結果序列的共享子序列來構造新的結果序列。該方法不必對結果序列的每個候選算子實例都進行計算,在一定程度上提高了計算的效率。Bok等[12]考慮了對來自傳感器的流數據的相似操作和冗余操作,將作業中的相似算子轉換為虛擬算子,將相同任務中的冗余算子轉換為單個算子。使用轉換后的算子重構作業,通過這種方法降低了相似算子和冗余算子的計算成本,從而降低了整體處理成本。He等[13]提出了劃分和聚類算法來優化流數據的處理,針對作業中存在的相同作業處理片段,用劃分算法消除一些重復,減少了重復計算。Higashino等[14]提出一種屬性圖重寫AGeCEP方法,針對復雜事件處理任務中的算子問題,提出了算子共享的概念,即單個算子實例被兩次或多次出現的算子共享的能力。上述這些工作考慮了算子級別優化,針對的是單個作業的優化,未考慮流處理引擎執行過程中的任務調度問題。
2任務調度方法DRLAOO
2.1定義
定義1流處理作業任務執行圖G。G用于表示作業中各個算子之間的依賴關系,定義G=(V,E),其中:V表示將要被分配到計算資源上的算子;E表示算子V之間傳遞的數據流。
定義2算子V。V是流處理作業的基本功能單元,從輸入消耗數據,對它們進行計算后輸出數據做下一步的處理,其中:V=(id,operator_type,cpu,memory,is_source,is_sink)。
定義3異構設備資源圖G。一個G表示一組計算資源的設備,使用全連通圖G=(V,E)表示,其中:V表示放置任務的最小單位。
2.2任務調度方法原理
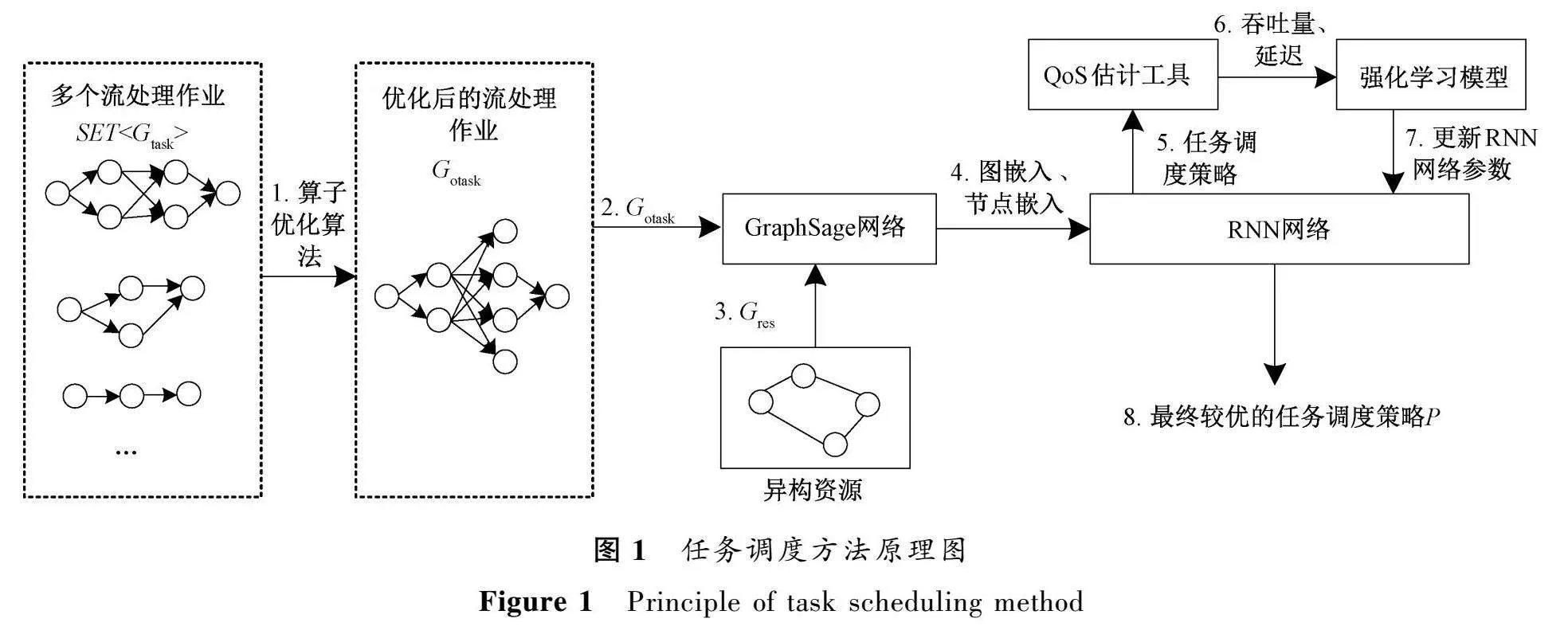
融合深度強化學習與算子優化的流式任務調度是一個用于優化流處理作業執行的調度方法。任務調度方法原理圖如圖1所示。
該方法的基本思路是將多個作業抽象為SET<G>,利用算子優化算法將多個作業去重、重構。處理之后的圖命名為G,G不改變流處理作業的數據源和處理邏輯等信息,保證去重、重構之后的數據源和處理邏輯是一樣的。
將G和G輸入深度強化學習的任務調度模型中,深度學習模型根據輸入的作業和計算資源的特征信息得到任務調度策略,強化學習模型根據得到的獎勵值不斷地更新深度學習模型的參數,最終得到較優的任務調度策略P。
該任務調度方法由以下2個部分組成。
1)算子優化算法。該模塊用于調度前對多個作業進行處理。當SET<G>到來之后,利用算子優化算法將其進行去重、重構,最終得到G參與后續的任務調度階段。
需要強調的是,經過算子優化算法得到的G包含了去重優化之前的所有處理邏輯。
2)任務調度階段。該任務調度階段由GraphSage網絡、RNN網絡以及強化學習模型組成。組合調度算法的輸入是上一步得到的G以及G,這些算法模型的組合運作方式如下。
① 利用GraphSage網絡提取作業和計算資源中的圖嵌入和節點嵌入的信息,例如,圖嵌入捕捉了V之間的整體結構和關系,節點嵌入捕捉了每個V的特征屬性。
② 將提取到的信息輸入RNN中,其中向前傳播的隱藏狀態可以用來存儲當前已經執行的V的調度策略。將V的調度策略輸入RNN中進行訓練,得到相應的調度策略以及每個調度策略所對應的吞吐量、延遲、CPU和內存。
③ QoS屬性估計:將吞吐量、延遲、CPU和內存作為調度策略的評價指標,估計每個任務調度策略對應的仿真情況下的吞吐量、延遲、CPU和內存。
④ 以評價指標作為強化學習算法的獎勵來優化任務調度策略,此算法的輸入是上述的RNN以及每個任務調度策略對應的QoS屬性估計值。采用策略梯度算法進行訓練,更新RNN的參數,得到較優的任務調度策略P。
2.3算子優化算法
基于文獻[14]中的Processing+Source算子實例共享策略,提出了算子優化算法。該算法中的算子實例共享策略表示為輸入源相同以及執行相同的數據處理情況下的共享算子實例。
舉例說明,假設有2個作業都包括4個算子:數據源、數據過濾、映射和輸出算子。它們的處理過程非常相似,只是在輸出算子上不同。作業1的輸出算子是File,作業2的輸出算子是Kafka。利用算子優化算法對這2個作業進行算子合并、重構的過程包括:遍歷每個作業中的所有算子;作業的合并和重構。
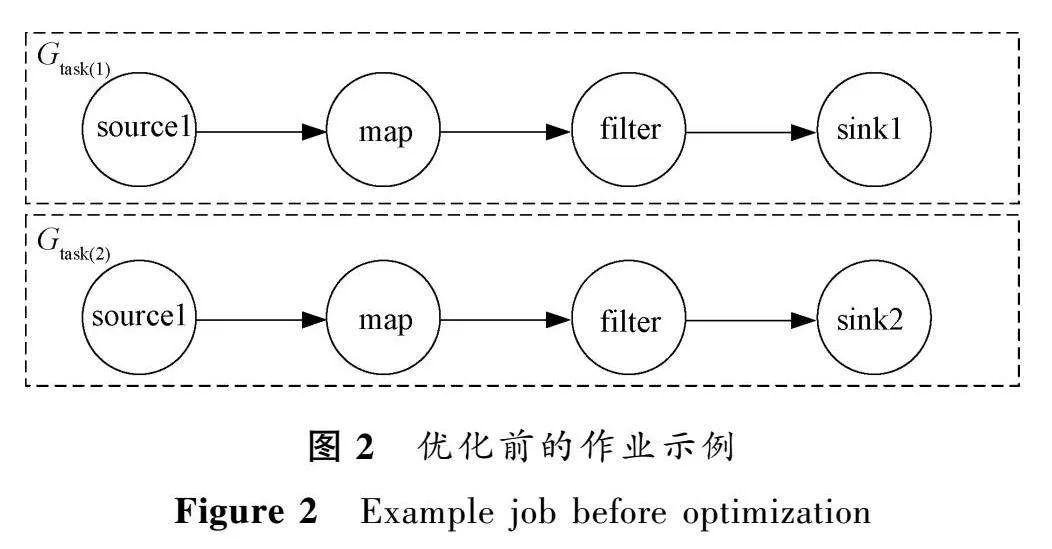
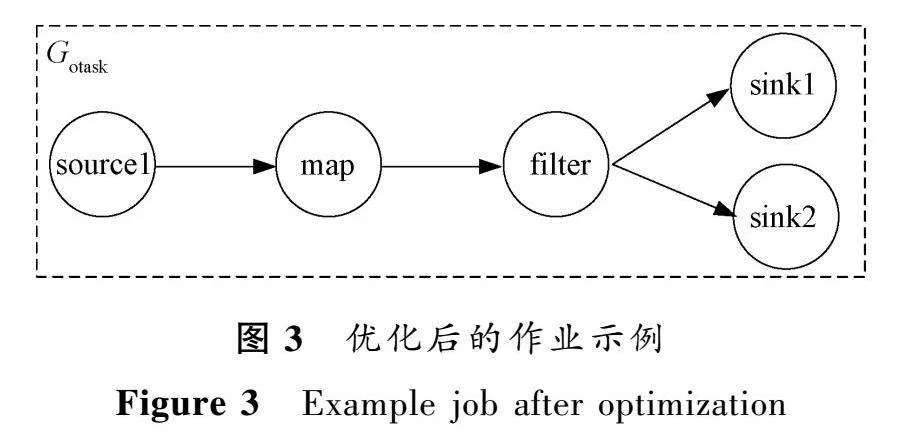
優化前的作業示例如圖2所示。2個作業除了輸出算子,其他算子都是相同的,在這樣的情況下需要創建2個作業實例。經過算子優化處理之后的作業示例如圖3所示。
將作業優化之后,只需要創建1個作業實例即可。如果存在大量的相互之間有重復片段的作業,利用算子優化算法可以發現多個作業之間相同的算子組合片段,將它們合并、重構之后再參與后續的處理。算子優化算法遍歷了每一個任務執行圖,迭代地將任務執行圖兩兩合并。合并方式如下。
第1步判斷算子類型是否為源算子。如果是源算子且兩者類型相同,則合并為一個源算子;
如果不相同,則保留兩個源算子。
第2步遍歷處理算子。如果兩個任務執行圖中算子片段相等,則合并類型相同的算子;如果不完全相同,則只合并相同的算子,增加分支構造圖即可。
第3步判斷輸出算子類型是否相同。相同則合并,不相同不進行合并,而是保留多個輸出算子。
該算法的具體步驟如下。
算法1算子優化算法(OOA)
輸入: 多個流作業任務執行圖SET<G>。
輸出: 算子優化之后的任務執行圖G。
1. while len(SET<G>)>1
2.for i in range(0, len(SET<G>),2)
3.if i+1 < len(SET<G>) then
4.mergedGraph=mergeGraphs(G,G)
5.G=mergedGraph
6.SET<G>.pop(i+1)
7. end if
8.end for
9. end while
算法2合并流處理作業任務執行圖算法mergeGraphs
輸入: 兩個任務執行圖G,G。
輸出: 經過算法mergeGraphs合并后的任務執行圖mergedGraph。
1. mergedGraph=Graph()
2. mergedGraph.sources=mergeSources(G.sources, G.sources)
3. mergedGraph.operators=mergeOperators(G.operators,G.opertors)
4. mergedGraph.sinks=mergeSinks(G.sinks, G.sinks)
5. return mergedGraph
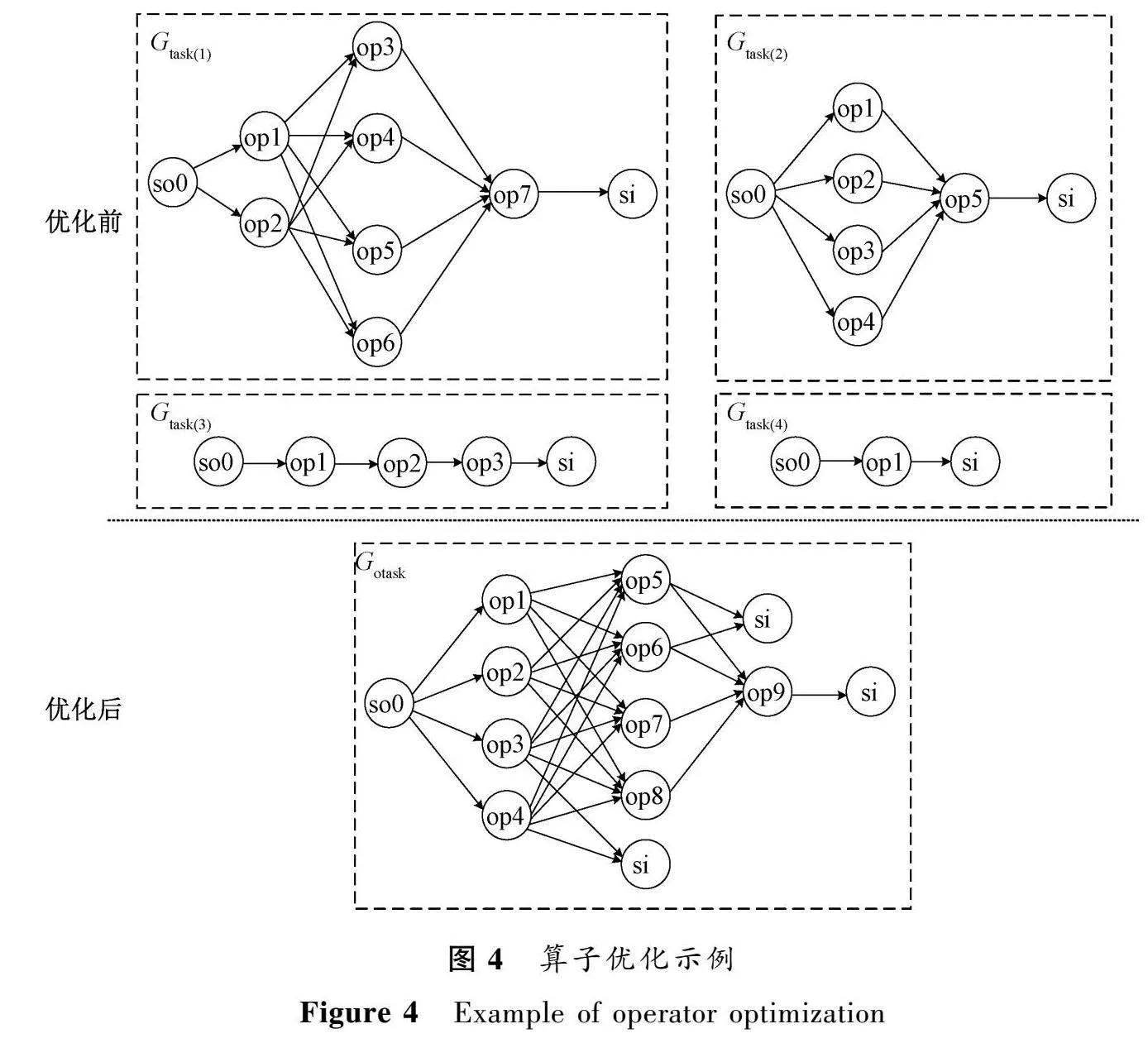
圖4是一個算子優化示例,該例子簡單描述了數據源和源節點類型相同的4個作業的合并、重構優化的過程。
2.4深度強化學習任務調度算法
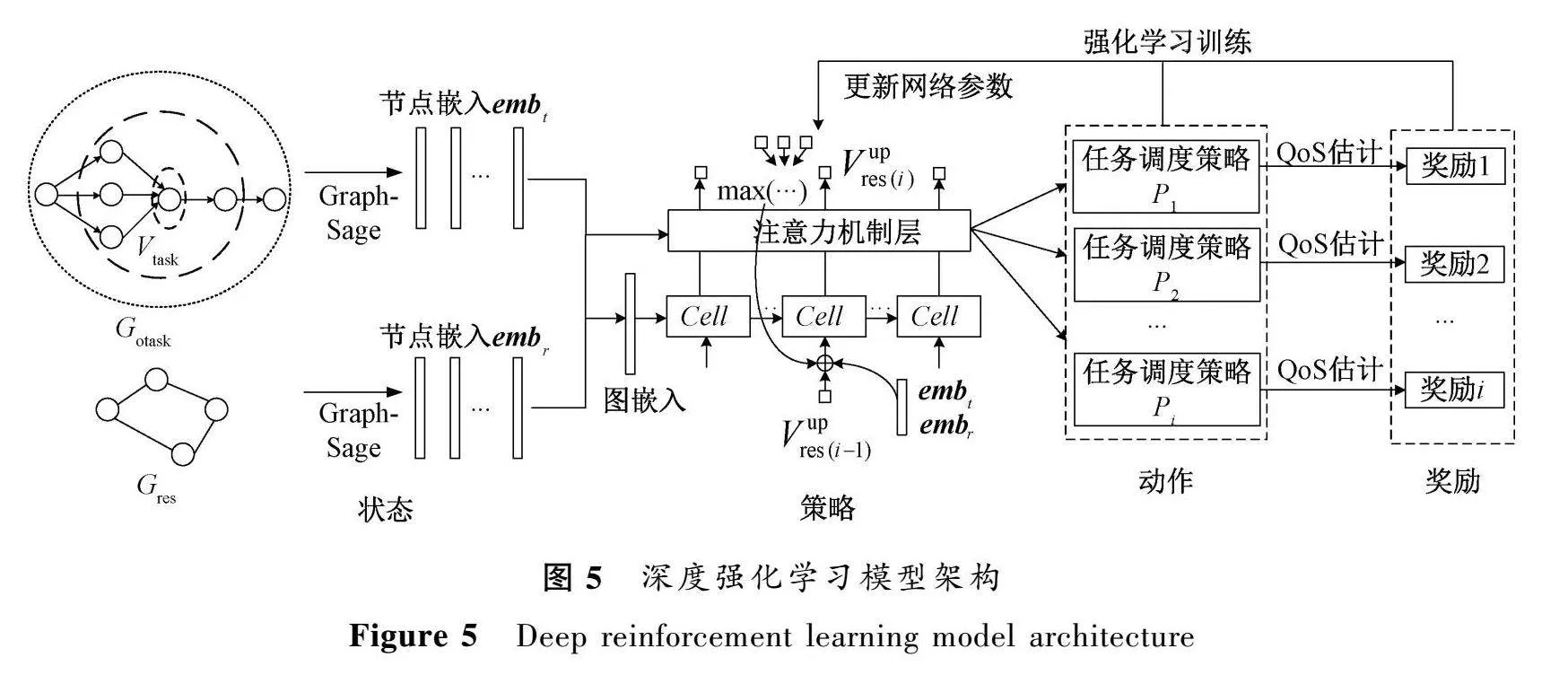
作業被重構優化之后得到的G,將參與后續的任務調度。圖5展示了深度強化學習模型架構。
該模型由GraphSage網絡提取G中V以及G的特征信息,交由RNN生成每個V所對應的任務調度策略P。同時,強化學習模型使用訓練期間觀察到的獎勵對神經網絡參數執行梯度下降來更新RNN的參數。
2.4.1GraphSage網絡
GraphSage是圖卷積神經網絡中的一種,可以在大規模圖上學習圖嵌入和節點嵌入的信息[15]。
GraphSage網絡首
先對鄰居節點隨機采樣,然后生成目標節點嵌入,最后將節點嵌入作為全連接層的輸入,預測目標節點的標簽。具體公式表示為
hk=mean(hk-1,u∈N(v)),
hk=σ(wk·Concat
(hk-1,hk)),(1)
式中:k表示當前層數;hk-1是第k-1層中節點u的向量表示。將節點v在k-1層的多個鄰居節點通過mean函數(即平均池化)得到節點v的鄰居表示hk。然后將hk和該節點在第k-1層的表示hk-1進行拼接,進而通過一個全連接神經網絡(即wk)得到節點v在第k層的向量表示hk。
將G、G經過預處理之后輸入GraphSage網絡中,得到V、V的嵌入向量分別定義為emb、emb。
2.4.2RNN
使用RNN來跟蹤計算過程中的狀態[16],將每個算子V分配到V上,當前節點的分配策略P由G、G和所有上游節點分配的資源節點的情況Vup計算得到。即
PG,G=
∏
ΠiP(Vi
Vup,G,G)。
(2)
結合RNN的注意力機制,通過學習狀態表示S來記憶依賴項,編碼與Vup和G相關的信息,在每一步中,輸入向量emb將在Vup中添加新的資源節點的嵌入特征emb,
S=LSTM_Cell(emb,S,Vup)。(3)
每個算子的調度策略將根據當前狀態和任務的相關信息計算得到,重復執行該過程,模型最終得到所有算子對應的調度策略P。
2.4.3強化學習Policy-Gradient網絡
使用策略梯度函數進行訓練[17-18],根據訓練期間的獎勵對神經網絡參數執行梯度下降,不斷地更新RNN模型的參數。將所有參數表示為θ,所有可能的放置方案的分布表示為π,模型的最大化目標為
J(θ)=∑pπ(P)r(P),(4)
式中:r表示獎勵,范圍為0~1。
接著使用REINFORCE算法計算策略梯度,學習網絡參數θ,
ΔJ(θ)=1N∑Nn=1
Δlogπ(P)[r(P)-b],(5)
式中:b為N個樣本的平均獎勵,用于降低策略梯度的方差;Δθlogπ(P)提供了一個方向來增加選擇P的概率。
將學習率表示為α,參數θ通過θ←θ+αΔJ(θ)進行更新,可以增加選擇到獎勵高于平均水平的調度策略P的概率。
3實驗與分析
3.1實驗準備
3.1.1數據集
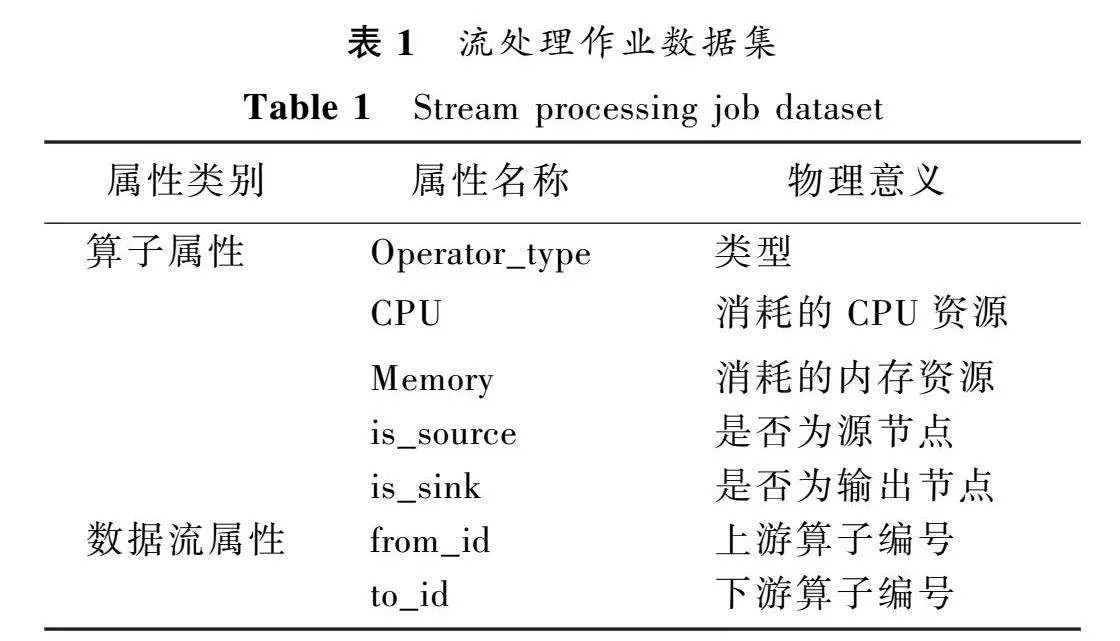
為了驗證本文提出的融合深度強化學習與算子優化的流式任務調度方法DRLAOO的有效性,在文獻[10]的基礎上改造了表示作業的數據集,加入了算子類型的特征屬性,更適用于所提出的問題場景。
結合表示計算資源特征的數據集構建了相應的訓練集、測試集和驗證集。其中,1個表示作業的任務執行圖和1個表示一組計算資源的圖構建為1個數據集樣本,構建完的數據集樣本共有1 500個。
實驗用到的流處理作業數據集和計算資源數據集描述見表1和表2。
3.1.2實驗設備
實驗部分采用了以下2臺設備。
設備1: 用來訓練構建好的算法模型,型號為CentOS6,32 GB。
設備2: 用來構建算法模型以及加載設備1上訓練好的模型,并驗證模型的輸出結果,型號為Windows11,16 GB。
2臺設備上安裝的第三方庫版本為Python3.8.16,Pytorch1.8.0。
3.2對比實驗
選取Flink、Storm流處理引擎默認的調度方式以及吞吐量感知的任務放置框架(TATA)[10]進行對比實驗。
Flink默認的調度策略:按照數據源的分布情況優先考慮將任務調度到距離其最近的執行器上執行,以利用本地計算資源和緩存減少數據傳輸和網絡開銷。但是,在計算資源節點性能相差較大的異構集群中,該策略會導致一些計算資源較弱的節點長時間運行任務,帶來局部負載不均衡的問題。
Storm默認的調度策略:基于輪詢的機制,將任務均衡地分配到可用的計算資源上,每個計算資源在同一時間只處理1個任務。這種調度策略適用于較小規模的集群和任務。
吞吐量感知的任務放置框架(TATA):綜合考慮作業中任務的特征和異構計算資源的特征,使得任務合理地分配到相應的計算資源節點上,但是不太適合具有大規模任務的流處理作業。
3.3結果分析
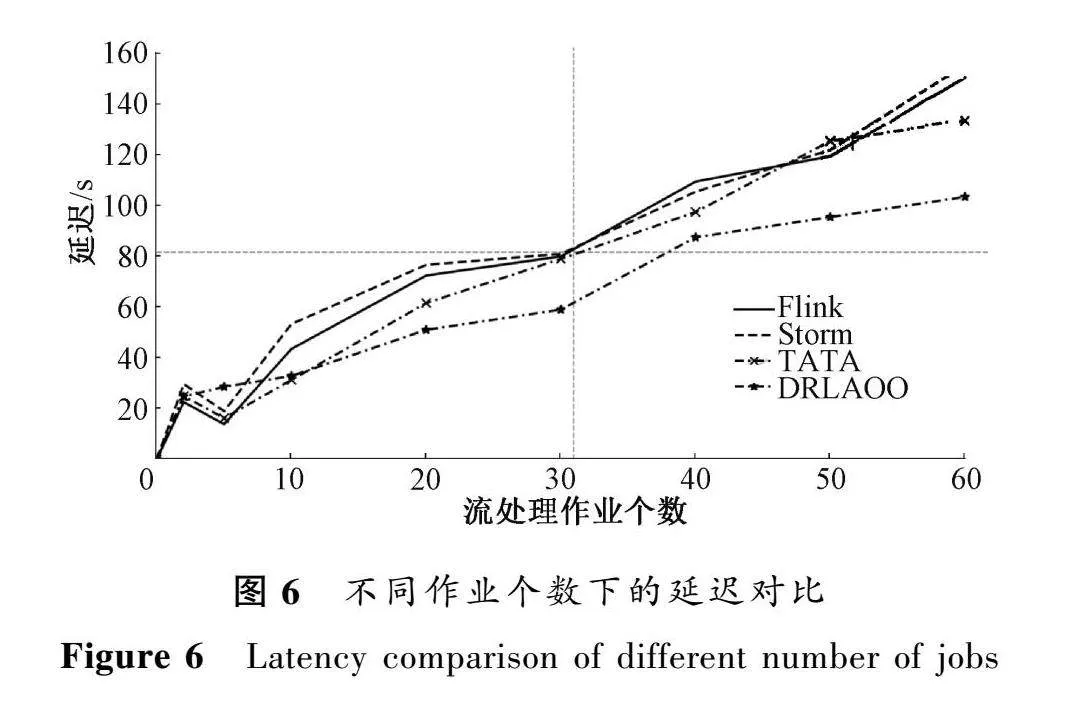
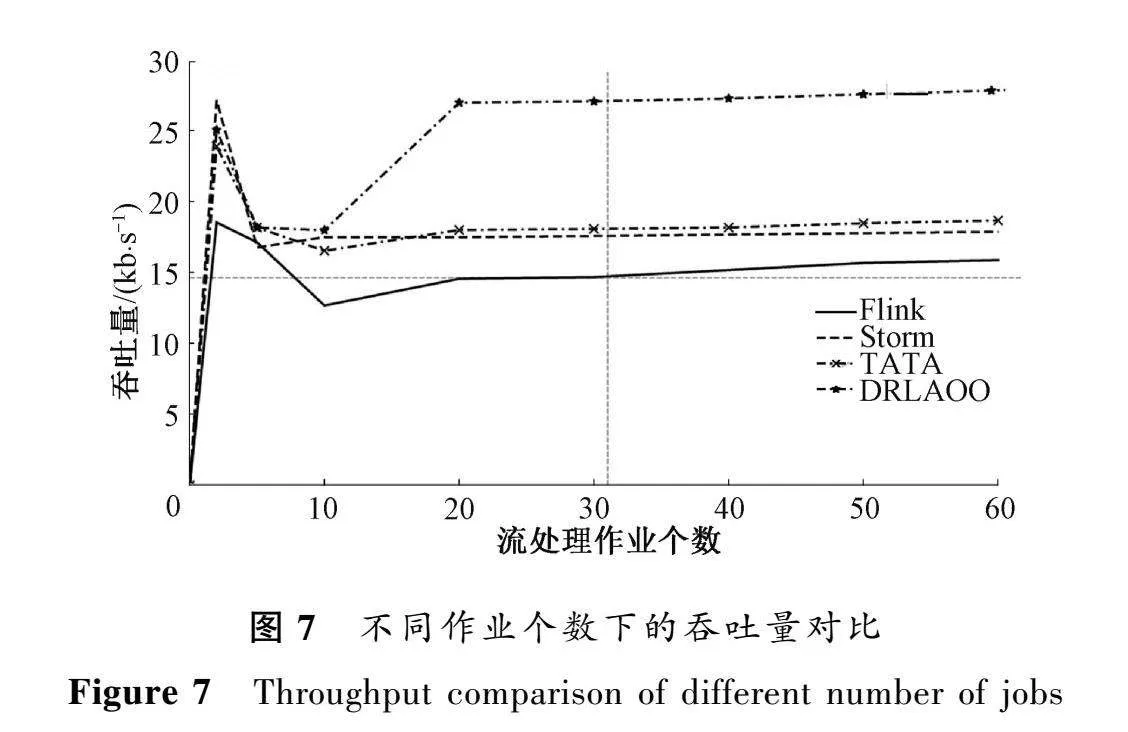
圖6和圖7分別比較了DRLAOO方法與其他3種調度策略在不同作業個數下的延遲和吞吐量。
從圖6可以看出,隨著作業個數的增多,4種調度策略下作業的延遲不斷增加;DRLAOO方法在總體上相較于其他調度策略的延遲較低。Flink默認的調度策略是將相關的上下游任務放置在相同的計算資源中;Storm默認的調度策略是將任務平均分配給集群內的所有主機,未考慮任務之間的依賴關系;TATA將簡單相關的任務放在計算資源少的位置上。而DRLAOO方法是對基于TATA的工作進行了改進,提出的算子優化算法達到一種算子共享的效果,減少了創建的算子實例個數,因此具有較低的延遲。
從圖7可以看出,隨著作業個數的增多,4種調度策略下的吞吐量在不斷增加后趨于平穩。這是因為計算資源的限制和網絡帶寬的限制等因素會導致吞吐量的增長趨于緩慢甚至停止增長,最終趨于平穩。DRLAOO方法在一定程度上減少了作業之間相同的處理片段造成的流處理引擎重復計算的問題,節約了資源的使用,進而給其他任務預留了資源,增大了吞吐量。
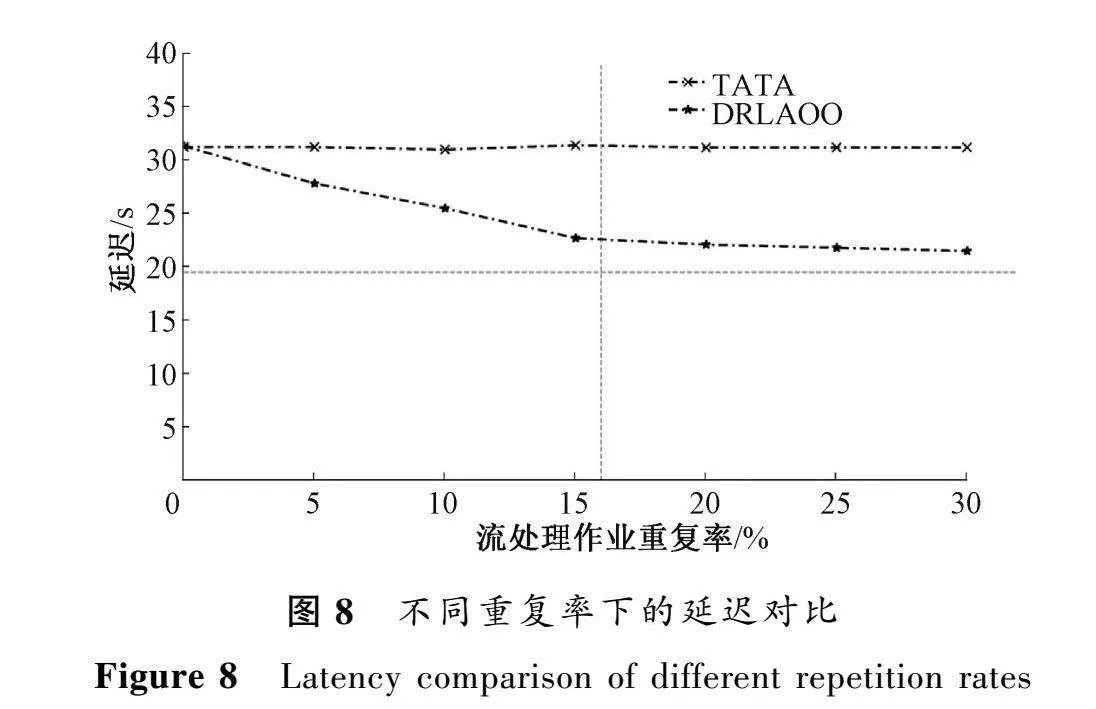
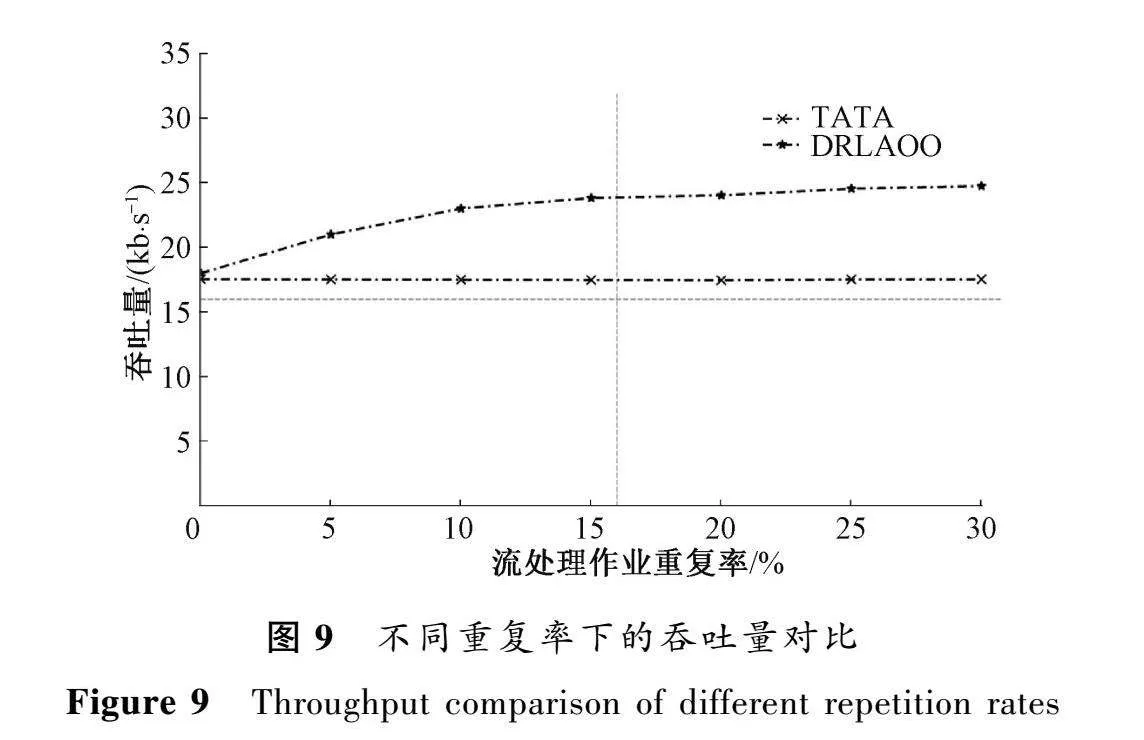
圖8和圖9分別比較了10個作業參與執行,不同重復率下DRLAOO方法與TATA的延遲和吞吐量。
由圖8和圖9可知,當多個作業之間的重復率為0時,2種調度策略下的延遲和吞吐量相差不大。這是因為當重復率為0時,用算子優化算法對多個作業進行優化,由于不存在可以合并的算子,所以未能減少需要創建的作業實例的個數,因此不能在延遲和吞吐量的指標上有更好的表現。
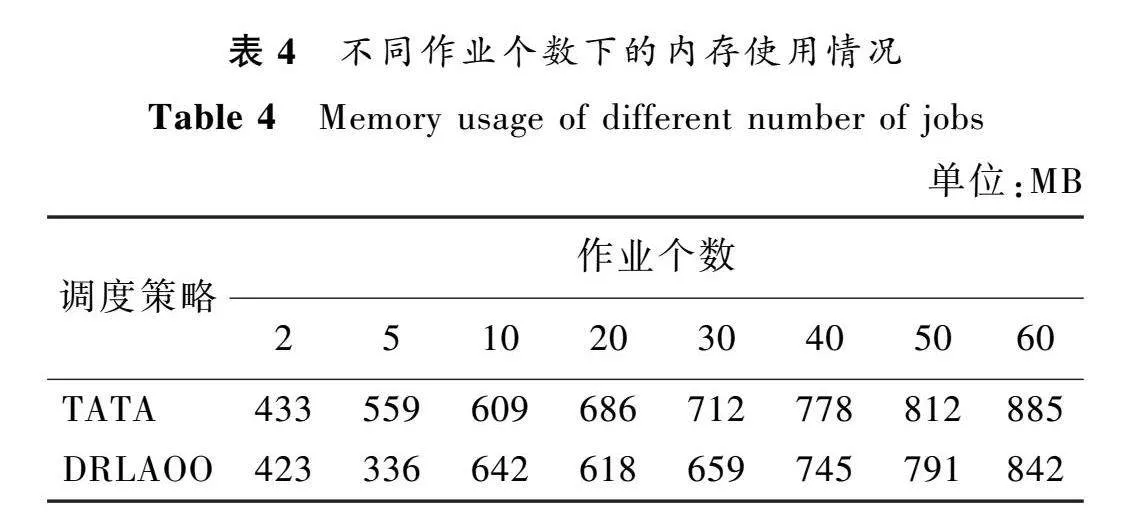
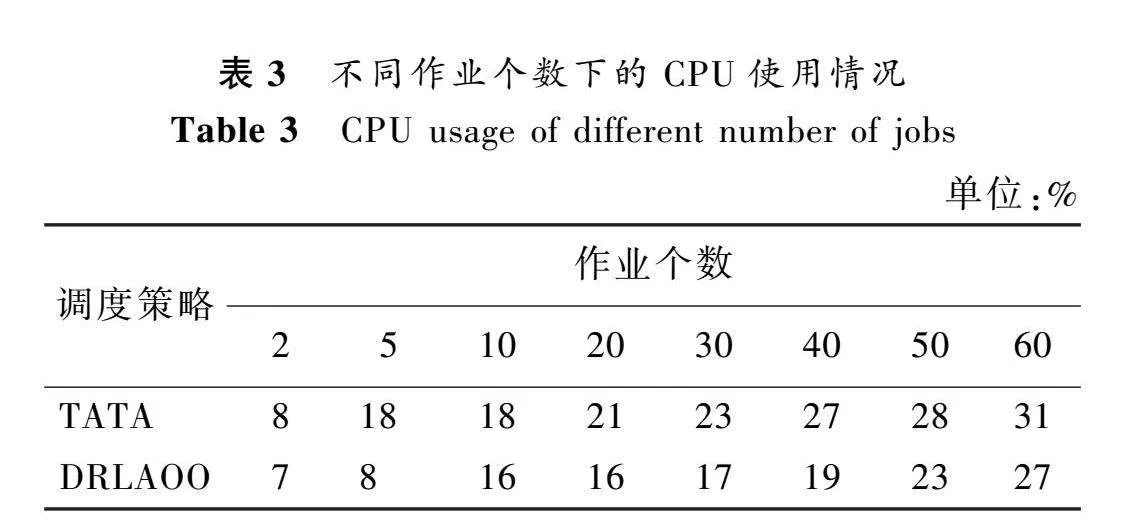
在不同作業個數下的CPU使用情況和內存使用情況。由于是在仿真環境,所以數值僅供參考,但是可以看出大致的趨勢是DRLAOO方法將會消耗更少的資源。
4結語
本文提出了一個融合深度強化學習與算子優化的流式任務調度方法DRLAOO,該方法針對大量的有重復片段作業的情況,可以盡可能地利用算子優化減少每個作業中需要創建的算子實例,結合深度強化學習自動發現最優的調度策略,進而獲得了較低的延遲和較大的吞吐量,提高了處理效率,節約了計算資源的使用。但是,本研究還存在一些可以改進的地方:一是利用算子優化時可考慮更多的特征,例如算子之間的通信延遲。同時,考慮對算子優化算法進一步優化以處理擁有多個數據源的作業的合并。二是將考慮結合圖論,采用更貼合實際的方法來表示異構資源,使得調度策略更準確。
參考文獻:
[1]DONGEN G, DEN P D. Influencing factors in the scalability of distributed stream processing jobs[J]. IEEE access, 2021, 9: 109413-109431.
[2]LI C L, LIU J, LI W G, et al. Adaptive priority-based data placement and multi-task scheduling in geo-distributed cloud systems[J]. Knowledge-based systems, 2021, 224: 107050.
[3]CHEN L S, WU D P, LI Z D. Multi-task mapping and resource allocation mechanism in software defined sensor networks[C]∥International Conference on Wireless Communications and Signal Processing. Piscataway:IEEE Press, 2020: 32-37.
[4]GELDENHUYS M K, SCHEINERT D, KAO O, et al. Phoebe: QoS-aware distributed stream processing through anticipating dynamic workloads[C]∥IEEE International Conference on Web Services. Piscataway:IEEE Press, 2022: 198-207.
[5]劉全, 翟建偉, 章宗長, 等. 深度強化學習綜述[J]. 計算機學報, 2018, 41(1): 1-27.
LIU Q, ZHAI J W, ZHANG Z Z, et al. A survey on deep reinforcement learning[J]. Chinese journal of computers, 2018, 41(1): 1-27.
[6]AGRAWAL K, BARUAH S, EKBERG P, et al. Optimal scheduling of measurement-based parallel real-time tasks[J]. Real-time systems, 2020, 56(3): 247-253.
[7]BLAMEY B, SINTORN I M, HELLANDER A, et al. Resource-and message size-aware scheduling of stream processing at the edge with application to realtime microscopy[EB/OL].(2019-12-19)[2022-12-23]. https:∥doi.org/10.48550/arXiv.1912.09088.
[8]LI J, AGRAWAL K, LU C Y. Parallel real-time scheduling[M]∥Handbook of Real-time Computing. Berlin: Springer Press, 2022: 447-467.
[9]NI X A, LI J, YU M, et al. Generalizable resource allocation in stream processing via deep reinforcement learning[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 857-864.
[10]HUANG X, JIANG Y, FAN H, et al. TATA: throughput-aware task placement in heterogeneous stream processing with deep reinforcement learning[C]∥IEEE International Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking. Piscataway: IEEE Press, 2021: 44-54.
[11]王亞, 孟耀偉. 基于匹配結果共享的復雜事件檢測方法[J]. 計算機應用研究, 2014, 31(8): 2338-2341.
WANG Y, MENG Y W. Method of complex events detection based on shared matching results[J]. Application research of computers, 2014, 31(8): 2338-2341.
[12]BOK K, KIM D, YOO J. Complex event processing for sensor stream data[J]. Sensors, 2018, 18(9): 3084.
[13]HE S Q, CHENG B, HUANG Y Z, et al. Proactive personalized services in large-scale IoT-based healthcare application[C]∥IEEE International Conference on Web Services. Piscataway:IEEE Press, 2017: 808-813.
[14]HIGASHINO W A, EICHLER C, CAPRETZ M A M, et al. Attributed graph rewriting for complex event processing self-management[J]. ACM transactions on autonomous and adaptive systems, 2016, 11(3): 1-39.
[15]白鉑, 劉玉婷, 馬馳騁, 等. 圖神經網絡[J]. 中國科學: 數學, 2020, 50(3): 367-384.
BAI B, LIU Y T, MA C C, et al. Graph neural network[J]. Scientia sinica: mathematica, 2020, 50(3): 367-384.
[16]SHERSTINSKY A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network[J]. Physica D: nonlinear phenomena, 2020, 404: 132306.
[17]劉建偉, 高峰, 羅雄麟. 基于值函數和策略梯度的深度強化學習綜述[J]. 計算機學報, 2019, 42(6): 1406-1438.
LIU J W, GAO F, LUO X L. Survey of deep reinforcement learning based on value function and policy gradient[J]. Chinese journal of computers, 2019, 42(6): 1406-1438.
[18]趙沛堯,黃蔚.基于動態優先級的獎勵優化模型[J].鄭州大學學報(理學版),2022,54(1):62-68.
ZHAO P Y, HUANG W. Constrained reward optimization with dynamic preferences[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(1): 62-68.
