基于BiGRU-attention的中文微博評論情感分析
2024-12-31 00:00:00薛嘉豪黃海孫宜琴
軟件工程 2024年7期




關鍵詞:情感分析;微博評論;注意力機制;門控循環單元
0 引言(Introduction)
自21世紀以來,情感分析已經成為自然語言處理(NaturalLanguage Processing,NLP)領域中備受關注的研究方向之一。隨著互聯網大數據時代的到來,對網絡大數據中的文本信息進行精準分類和辨析顯得愈發重要。在互聯網環境中,人們每天在社交媒體上發表對事件的觀點、對他人的評價或者獲取他人的意見。然而,由于數據量巨大,網絡上的媒體網站監視、查找和提取其中的信息成為一項艱巨的任務[1]。微博[2]作為目前國內比較受歡迎的社交平臺之一,時刻承載著海量的信息交互。通過對微博評論進行情感分析,可以了解消費者對產品、服務、品牌等的情感傾向;通過監測社交媒體、新聞報道等渠道中的輿論情緒,可以幫助政府、企業和組織把握公眾對特定事件或話題的態度與反應。
1 研究背景及其意義(Research backgroundand significance)
傳統方法通常用機器學習對情感問題進行分類,例如支持向量機(Support Vector Machine, SVM)、樸素貝葉斯分類器及最大熵等算法和技術。DAUD等[3]通過建立支持向量機模型,并通過超參數調優對模型進行優化,使SVM 分類器的準確率提高了20.81%。HADDI等[4]使用SVM 分類器進行情感分析,通過構建特征之間的關系網絡衡量和選擇屬性的貢獻度,利用屬性之間的相關性和重要性評估每個屬性對于情感分類任務的價值,從而減少特征空間的維度,提高分類模型的效果,并降低計算成本。然而,基于機器學習的傳統方法有許多不足之處,在處理長文本和復雜語境時面臨巨大挑戰。傳統方法高度依賴人工設計,需要人工進行特征工程、模型選擇和參數調整等。這些步驟不僅需要人工付出大量的時間和精力,而且結果可能受到人為因素的影響。傳統方法通常無法捕捉到文本的語義信息,它們主要依賴于淺層的特征表示。
除了傳統的機器學習方法,深度學習在情感分類問題中的應用近年來也比較受關注。陶林娟等[5]介紹了一種GRUCNN(Gate Recurrent Unit-Convolution Neural Networks)網絡模型,從詞語表征和上下文編碼模型兩個方面改進,在情感分析問題上使模型準確率提高了許多。李洋等[6]用卷積神經網絡(Convolution Neural Networks,CNN)提取文本向量局部特征,用BiLSTM(Bi-directional Long Short-Term Memory)提取與文本上下文相關的全局特征,兩者互補解決文本情感分析中容易忽略上下文語義的問題。何穎剛等[7]基于FastText構建文本向量,將特征輸入多尺度深層金字塔卷積神經網絡(DPCNN)進行情感分類。卷積神經網絡在處理文本時存在一些限制,對長文本的全局語義理解能力較弱。并且,對于詞序信息的處理不夠靈活,無法捕捉到詞語之間的順序關系。YANG等[8]介紹了目標相關長短期記憶神經網絡(TD-LSTM),對目標字符串上下文進行建模,通過捕捉這些信息提高情感分類的準確率。HAMEED 等[9]使用SBi-LSTM(Single-layeredBiLSTM)模型,并采用了一種標準且高度實用的無監督嵌入方法進行權重初始化,通過單層雙向LSTM 網絡訓練模型,該模型在情感分析問題上相較于其他模型更具有競爭力。孔繁鈺等[10]基于改進的雙向LSTM 模型,結合Word2Vec的評教文本情感分析方法對評教文本進行情感分析。LSTM 模型在處理非常長的序列時,仍然存在計算復雜性高和消耗內存的問題。相比之下,GRU是LSTM的改進版本,它的參數調節量更少,網絡的結構也更加簡單,在處理文本情感問題時的表現更好一些。
本文提出一種基于雙向門控循環單元和注意力機制BiGRU-attention的方法來完成情感分析任務,通過jieba分詞,把所有的詞匯總做出詞表Vocab,并進行詞向量轉化;使用模型提取句子的詞向量,并結合上下文詞向量內容獲取更多特征信息;采用softmax函數得出情感分類結果;通過混淆矩陣,使用精確率(Accuracy)、精準率(Precision)、召回率(Recall)、F1值(F1 Score)評估模型性能。
2 GRU模型和自注意力機制(GRU model andself-attention mechanism)
2.1 GRU模型
GRU[11]由重置門Rt、更新門Zt 組成,GRU結構圖如圖1所示。重置門Rt 是由隱藏狀態Ht-1 與輸入Xt 拼接后與權重矩陣Wr 乘積,再通過Sigmoid函數將數據維持在0~1,如公式(1)所示。更新門接收的數據與重置門是一樣的,由輸入Xt 和隱藏狀態Ht-1 負責t 時刻更新門的輸入,如公式(2)所示。
候選隱藏狀態Ht 是由輸入Xt 拼接重置門Rt 與隱藏狀態的hadamard乘積(矩陣相同位置上的元素進行乘積),再乘以權重矩陣Wh,通過激活函數tanh將值固定在-1~1的范圍,如公式(3)所示。
總體來看,GRU 模型與循環神經網絡(Recurrent NeuralNetwork,RNN)可學習的參數是一樣的,可學習的權重矩陣是RNN網絡的3倍。與LSTM 相比較,GRU結構更加簡單,門的數量少一個,參數數量少了很多。
2.2Self-attention自注意力機制
注意力機制[12]是一種能夠根據輸入序列中各個元素之間的相關性,對序列進行加權求和的方法。通過計算元素之間的相關性,注意力機制可以捕捉輸入序列中不同元素之間的依賴關系,從而更好地理解和處理序列數據。這種機制有助于網絡在訓練過程中處理長期依賴性。
注意力機制有Q、K、V 三個參數,其中Q 是查詢向量,K是標簽向量,V 是標簽對應的信息的向量。分別計算Q 與每一個K 之間的相似度α,一般有點積模型、縮放點積模型、雙線性模型、加性模型等,本文采用縮放點積模型,如公式(5)所示。dk 是K 向量的長度,對其開平方的目的是防止維度太大。α 經過歸一化函數softmax處理后作為V 的權重,這些權重用于加權求和V。
3 GRU-attention模型(GRU-attention model
與普通GRU模型相比,雙向門控循環單元(BiGRU)是由兩個互相獨立的GRU組成,分別為正向GRU 和反向GRU。正向GRU處理輸入序列,負責從序列起始位置捕捉上下文信息。反向GRU從序列末尾處理輸入數據,由序列逆序捕捉上下文信息。相比于單向GRU從前向后的傳播更能反映過去和未來時刻對當前時刻的影響[13]。加入自注意力機制后,能夠對輸入序列中更關鍵的部分賦予更大的權重,從而更好地捕捉上下文信息,并減少了信息的丟失,保留了輸入序列中重要的信息,提高了模型的性能。GRU模型可以有效地解決長依賴問題,并且在處理序列數據時表現出色。注意力機制可以幫助模型集中關注輸入序列中最重要的部分,從而提高模型的精度。GRU-attention結構圖如圖2所示,GRU-attention模型的實現步驟如下。
第一步:對本實驗數據集進行數據處理。首先,去掉無意義的字符和英文符號,留下中文,防止這些無效信息增大計算機的負載,幫助加快模型運算速度。其次,使用jieba庫[14]對數據進行分詞操作,得到分詞后的文本數據集;結合百度去停用詞表和哈工大去停用詞表構成去停用詞表,分詞后的文本語句不要過長;對文本數據集去停用詞;對所有詞統計詞頻,按照詞頻排序和以詞的形式進行索引。最后,將詞和編號對應起來制作成一個有序詞典;根據有序詞典把每個單詞作為特征,把文本數據集的文本轉化為詞向量。
第二步:將詞向量序列輸入BiGRU層。GRU網絡不僅可以增加網絡的整體深度,還能提高模型訓練的性能和效率,通過雙向GRU提取文本信息的全局特征,有助于擴展前向和后向文本的情感分析,利于模型訓練。公式(8)、公式(9)分別是前向GRU和后向GRU,其中Ht 是隱藏狀態。
第三步:經過GRU層,詞向量序列變為隱藏狀態序列,再把它們加入注意力層。注意力層能夠計算文本中每個詞的注意力概率,將每個詞向量劃分出Q、K、V 三個部分。經過一系列計算和加權處理,賦予詞向量不同部分不同的權重,使得模型更好地關注當前任務的相關部分。
第四步:通過全連接層,將得到的詞向量序列與輸出特征相結合,提高模型的預測結果,為了確保注意力機制得到的詞向量序列權重之和為1,需要使用softmax函數對這些注意力權重進行歸一化處理,其計算公式如下:
4 實驗過程與分析(Experimental process andanalysis)
4.1 實驗環境
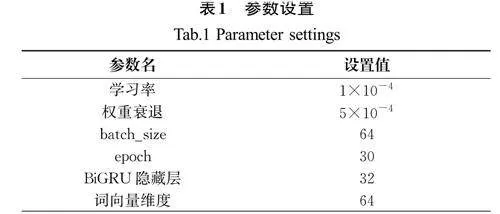
本實驗采用的是Windows10操作系統,處理器型號為Intel(R) Core i5-7 300H,運行內存為16 GB。編程語言為Python3.7,通過pycharm 平臺開發,使用深度學習框架Pytorch 1.13、numpy 1.21.6、jieba 0.42.1等進行實驗。參數設置如表1所示。
4.2 數據集
本文采用的是公開的微博情感分析數據集Weibo[15],一共有119 988條微博評論數據,分為積極情緒和消極情緒,標簽為“1”代表積極情緒,標簽為“0”代表消極情緒。將數據集按照6∶2∶2的比例劃分為訓練集、測試集和驗證集。所有數據首先用jieba分詞庫[14]進行分詞,其次按詞頻排序構造有序字典,詞頻大的在字典前面,識別不了的詞用“”標記,空格用“”標記,并排在字典后面,再將詞元映射成其在字典里的索引。
4.3 評價指標
情感分析實驗的評價指標能幫助研究人員了解模型在情感分類任務中的性能表現,并進行模型比較、調優和選擇。本實驗使用的評價指標有準確率(Accuracy,A)、精確率(Precision,P)、召回率(Recall,R)、F1值。
(1)準確率
準確率是為了評估模型在整體樣本預測正確的比例,準確率能反映模型的分類準確率,計算公式如下:
(2)精確率
精確率是評估模型預測為正例的樣本中實際為正例的比例,計算公式如下:
(3)召回率
召回率又稱查全率,召回率是評估模型預測為正例的樣本中實際為正例的比例,即預測為正例并且實際也為正例的樣本占所有類別樣本預測為正例的比值,計算公式如下:
(4)F1值
F1值是精確率與召回率的調和平均數,綜合考慮了兩個因素。F1值能綜合評估模型性能,特別適用于樣本不平衡的情況,計算公式如下:
4.4 對比實驗與結果分析
4.4.1 消融實驗
消融組a:不使用注意力機制,僅使用GRU處理序列。
消融組b:不使用注意力機制,僅使用雙向GRU 處理序列。
消融組c:使用注意力機制,并且使用雙向GRU 處理序列。
消融實驗結果如表2所示。從表2中的數據可以看出,BiGRU的表現比GRU 的表現略好,加入注意力機制的BiGRU比BiGRU 的準確率和F1值分別高1.22百分點和1.01百分點。雙向GRU 整體的表現比單向GRU 的表現更好。
4.4.2 與已有的文本情感分析方法進行實驗對比
(1)CNN。基于文獻[6]使用卷積神經網絡提取文本局部特征,并構建了一個基礎的文本分類模型。采用Weibo[15]數據集。
(2)RNN。基于文獻[16]中的RNN模型,通過RNN建模對情感分析問題進行研究。采用Weibo[15]數據集。
(3)LSTM。LSTM是在RNN的基礎上加入了門限控制,這里采用文獻[17]中提到的方法。采用Weibo[15]數據集。
(4)BGRU。基于文獻[18],將BRNN隱藏層神經元換成GRU記憶單元。采用Weibo數據集。
(5)Text-CNN。文獻[19]提出了一種新穎的文本注意卷積神經網絡Text-CNN。采用Yahoo Answers數據集[20]。
(6)UCRNN。用戶屬性卷積和遞歸神經網絡[21],使用了基于用戶屬性的CNN和基于文本的RNN。采用MicroblogPCU數據集[21]。
(7)TD-LSTM。目標相關長短期記憶神經網絡[8](TDLSTM)對目標字符串周圍上下文建模,使兩個方向都可以作為情感分類的特征表示。采用Twitter數據集[22]。
(8)TC-LSTM。目標連接長短期記憶神經網絡[8](TCLSTM)加入了目標連接組件擴展了TD-LSTM,該組件在構建句子表示時利用目標詞和每個上下文詞之間的連接,來提高對句子中目標詞相關信息的捕捉能力。采用Twitter[22]數據集。
(9)fastText-CNN。fastText嵌入CNN模型[23]。采用MR數據集[24]。
(10)fastText-BiLSTM。fastText嵌入單層BiLSTM模型[23]。采用MR數據集[24]。
(11)fastText-BiGRU。fastText嵌入的單層雙向門控循環單元(BiGRU)模型[23]。采用MR數據集[24]。
(12)Singal-layered Bi-LSTM(SBi-LSTM)。單層Bi-LSTM模型[9],與fastText嵌入結合有更好的分類效果。采用MR數據集[24]。
不同模型下的實驗結果如表3所示。
通過表3中的數據可以看出,相較于CNN[6]、RNN[16]、LSTM[17]、BGRU[18]4個神經網絡模型,BiGRU-attention模型在評價指標上展現出了顯著的優勢。具體分析如下。
CNN模型和RNN模型都使用word2vec將文本轉化為對應的詞向量,CNN對卷積操作得到的局部特征采用最大池化的方法以提取值最大的特征代替整個局部特征。RNN通過其循環結構捕捉序列化文本上下文語義信息,生成包含文本深層次含義的表示。實驗結果表明,CNN模型和RNN模型在處理長文本語義時存在一定局限性,無法充分理解文本語義和上下文關系,在情感分析任務上不如本文提出的模型。
LSTM針對RNN的態度消失和梯度爆炸問題進行了改進。本文模型在準確率上比LSTM模型高4.42百分點,由于在處理非常長的文本序列時,LSTM難以捕捉長期的依賴關系,在長序列的信息傳遞中可能會虛弱,所以情感分類的準確率難以提高。
BGRU模型是在雙向RNN模型的基礎上將BRNN中的隱藏層神經元替換成GRU 記憶單元。BiGRU-attention模型的準確率和F1值分別提高了2.58百分點和2.24百分點。BiGRU-attention在處理前向和反向序列時,相較于僅使用一個GRU單元的BGRU,表現更為出色。同時,加入注意力機制對不同詞向量特征分配了新的權重,突出了文本重要的特征,有效地提高了模型對正例樣本和負例樣本的識別能力,提高了模型的情感分類能力。實驗表明,基于BiGRU-attention的情感分類模型在文本情感分類數據集上的表現更好。
5 結論(Conclusion)
本文基于BiGRU神經網絡,結合注意力機制,設計了一種文本的情感分析模型BiGRU-attention。該模型通過BiGRU網絡提取文本的全局特征,捕捉上下文信息;用注意力機制進行了特征權重的分配,對輸入序列中更關鍵的部分賦予了更大的權重,減少了有效信息的丟失,提高了模型的性能。通過與其他情感分析模型進行實驗對比,結果表明,本文模型提高了情感分析的準確性。未來,將繼續優化attention機制的計算方法,減少其對模型運算效率的影響,進一步提高模型的情感分析性能,將該模型應用于其他場景中。
