基于分布式麥克風陣列的室內拾音系統設計
2024-12-31 00:00:00花嶸劉元龍黃澤源
軟件工程 2024年7期

關鍵詞:分布式麥克風陣列;聲源定位;TDOA;GCC
0 引言(Introduction
麥克風是一種拾取聲音信號的傳感器。通過對麥克風聲音信號的拾取調查可知,環境噪聲和混響對單個麥克風的收音效果影響頗大[1]。目前,對語音識別、聲源定位及語音增強的研究,主要聚焦于麥克風陣列技術。分布式麥克風陣列相比于傳統的單麥克風陣列,在聲源定位時具有更高的探測精度和更大的覆蓋面積,并且系統的穩定性更強。隨著人工智能技術和互聯網技術的迅速發展,越來越多的語音交互場景出現在人們的日常生活中,在理想環境下,智能語音系統能夠識別用戶的語音指令并與其進行交互。因此,設計一種對室內環境具有較強適應性的分布式麥克風陣列拾音系統,對后續進行語音增強等操作具有重要的意義。
1 背景知識(Background knowledge)
1.1 分布式麥克風陣列
麥克風陣列技術的實現原理是利用聲波抵達陣列中每個拾音點之間的微小時差,通過某些算法,實現聲源定位、聲音降噪,使得麥克風陣列能獲得比單個麥克風更高的指向性,也就能夠區分聲源的方向,并對感興趣方向上的聲音進行特別的增強或抑制。
分布式麥克風陣列是由多個麥克風陣列有序地組合在一起的,與傳統麥克風陣列相比,分布式麥克風陣列沒有規則的拓撲結構,在空間中的擺放位置也更加隨意且靈活,因此分布式麥克風陣列表現形式正朝著多樣化的方向發展,分布式麥克風陣列的信號處理方法比傳統麥克風陣列的信號處理方法更加通用和靈活。
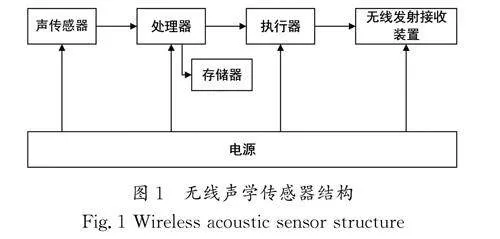
1.2 無線聲學傳感器
無線聲學傳感器是一個低功耗器件,它由一個或多個聲傳感器、處理器、存儲器、電源、無線發射接收裝置及執行器組成[2]。聲傳感器主要用于感知和測量環境信息;處理器和存儲器用于對數據進行有限的處理與存儲;電源一般由電池構成,是分布式麥克風陣列的主要能量來源,并且能量有限;無線發射接收裝置用于信息傳輸;執行器主要用于進行某種局部判別。無線聲學傳感器結構如圖1所示。
2 傳統聲源定位算法的介紹(Introduction to traditional sound source localization algorithms)
隨著麥克風技術與陣列信號處理技術的不斷發展和完善,研究者逐漸將這兩種技術運用于聲源定位,從而得到多種聲源定位方法。傳統的聲源定位算法可以分為3種,分別為基于可控波束形成的聲源定位算法[3]、基于高分辨率空間譜估計的聲源定位算法[4]及基于到達時間差估計的聲源定位算法[5]。
2.1 基于聲源到達方向的算法
基于聲音信號到達入射角(Direction Of Arriva, DOA)的聲源定位方法,是最早取得廣泛應用的一種定位技術,其中比較常見的是波束形成(Beam Forming)算法。波束形成技術的核心是波束形成器,其本質是一個空間濾波器,通過對特定的波束模式進行構造,可以對空間中不同方向的信號進行不同程度的增益,從而增大目標方位信號,抑制其他方位信號。時延-求和(Delayand-Sum, DS)波束形成器是一種傳統的波束形成器,每個麥克風的傳播延遲和聲音到達的時間差決定了每個權重。
為了讓波束形成器方向定位更準確,需要將麥克風間距變大,使主瓣盡可能地窄。但是,麥克風間距不能無限變大。
其中:d 為麥克風間距,c 為聲速,f 為聲源信號的頻率。d 不應大于輸入信號波長的一半,否則會出現多個功率最大的主瓣,對波束形成器的搜索造成干擾,導致聲源定位失敗。受麥克風陣列結構的限制,不易通過增加麥克風數量和增大麥克風陣列間距的方法提高算法的分辨率,而且在室內環境中該算法容易受到多徑效應的影響,造成聲音波形的失真,從而影響定位結果。但是,該算法具有較快的計算速度,并且對麥克風陣列的數量和布局要求也相對較低。
2.2 基于高分辨率空間譜估計的算法
高分辨率空間譜估計算法也是一種計算DOA的估計方法,其中代表性的算法是R.O.Schmidt等人提出的多重信號分類(Multiple Signal Classification, MUSIC)算法,該算法基于信號的空間譜分析,通過計算信號在不同方向上的功率譜密度,找到信號源的角度信息,從而實現對信號源的準確定位。MUSIC算法的關鍵步驟包括構建協方差矩陣、計算空間譜估計、尋找峰值和估計信號源的角度。
MUSIC算法具有較高的分辨率、較高的穩健性,并且對陣列結構適用面比較廣。但是,與基于波束形成的定位方法類似,當陣元間距大于輸入信號波長的一半時,空間譜同樣會在信號源方向外的其他方向出現虛假譜峰,從而對定位造成干擾,降低準確率。MUSIC算法需要對整個空間進行搜索,同時搜索設計協方差運算,雖然此算法定位精度高,但是也帶來了較高的計算復雜度,影響了算法的靈活性。
2.3 基于到達時間差的算法
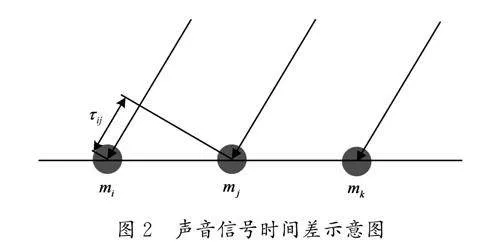
基于到達時間差(Time Difference of Arrival, TDOA)的聲源定位算法是目前研究最為廣泛的一種兩步定位法。為了便于分析,將麥克風陣列模型簡化為均勻線性陣列,聲場模型按照遠場波進行傳輸,即每個麥克風接收到的聲音信號為平行線。如圖2所示,τij 為兩個麥克風陣列mi 和mj 接收到的聲音信號時間差。
時間差估計常見的算法是廣義互相關算法(GeneralizedCross-Correlation, GCC),算法主要分為兩個步驟:首先對每個接收器接收到的聲音信號進行時延估計,其次根據得到的時延結合陣列空間排布推算出聲源位置。
在現實環境中,由于麥克風陣列會受到混響的影響,陣列的互相關函數波形會出現多個峰值,對時延的判斷產生影響。因此,需要在頻域引入加權函數φ,應用相位變換加權函數PHAT[6],其表達式為
加權函數φ 的作用是舍棄幅度信息,保留相位信息,使互相關函數的真實峰更加突出,最終求出經過加權的互相關函數取最大值對應的τ,即兩個麥克風陣列之間的時延。需要特別注意的是,GCC-PHAT(權值為PHAT的廣義互相關)算法是應用在近場模型的,因此聲源定位模型只關注聲源信號到達麥克風陣列的角度。
TDOA算法可以實現較高的聲源定位精度,尤其在室內環境中表現出色,并且該算法對環境噪聲和雜音的抑制能力較強,通過對多個麥克風陣列接收到聲音信號的時間差進行分析,以有效區分聲源信號和噪聲信號,提高定位的準確性。但是,TDOA算法需要3個或更多麥克風陣列測量聲波到達的時間差,這在一定程度上增加了硬件成本和系統復雜性,并且各個陣列的擺放位置需要進行精確的測量與布局,增大了實際應用的難度。
3 系統設計(System design)
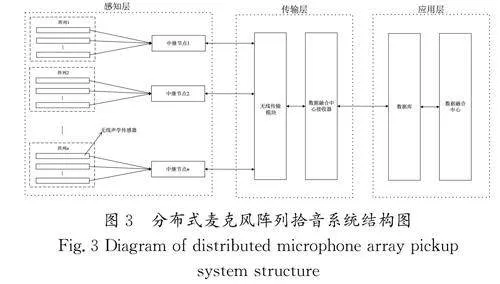
室內分布式麥克風陣列拾音系統主要的應用場景為客廳、臥室及廚房等室內環境,該系統由感知層、傳輸層和應用層組成,分布式麥克風陣列拾音系統結構圖如圖3所示。
3.1 系統各部分的組成及功能
感知層:主要由多個無線聲學傳感器陣列及中繼節點組成,每個陣列包含多個無線聲學傳感器,這些無線聲學傳感器負責采集環境中的聲音信息,并且都配備有無線接口,用于陣列內彼此間的通信。每個傳感器都只能有限地處理信息或數據,并將處理之后的信息傳輸至中繼節點,由中繼節點將信息通過無線網絡上傳至應用層數據庫,以便進行后續處理。
傳輸層:主要由無線傳輸模塊和數據融合中心接收器組成,無線傳輸模塊負責上傳感知層采集的環境中的語音數據和數據融合中心接收器下發的控制命令,而數據融合中心接收器則負責接收無線傳輸模塊上傳的環境中的語音數據和下發應用層的控制命令。
應用層:主要由數據庫和數據融合中心組成,數據庫主要用于存放各個無線聲音傳感器陣列上傳的語音數據及陣列的狀態,數據融合中心負責將各個陣列上傳的語音數據進行融合,便于后續進行聲源定位、語音增強等操作。
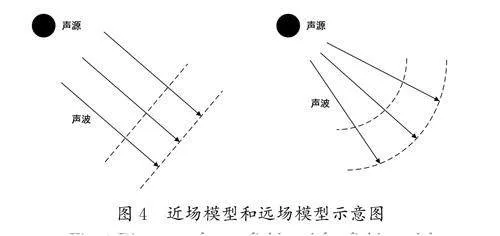
3.2 近場模型和遠場模型
根據聲源與麥克風距離之間的關系,聲源產生的聲場模型可分為近場模型和遠場模型[7],不同聲場模型的聲音傳播特性有很大的不同。當聲源與陣列距離較近或麥克風陣列尺寸較大時,麥克風之間的距離對接收聲源有較為明顯的影響。聲源以球面波的形式向外輻射傳播,聲源到達各個麥克風的相對位置有明顯差異。當聲源與陣列距離較遠或麥克風陣列尺寸較小時,麥克風直徑可以忽略不計,此時麥克風陣列被稱為小型陣列,并且可以認為聲波信號被各個麥克風以相同入射角接收,即平行入射。此時,對聲源入射角的確定是聲源定位的主要問題。結合房間與麥克風陣列的普遍設置,室內環境以近場小型陣列模型作為研究對象。近場模型和遠場模型示意圖如圖4所示。
分布式麥克風陣列中陣元間距必須滿足空間采樣定理,因此需要對陣元間距加以控制,保證陣元間距不超過采樣信號波長的長度,避免采樣信號出現空間混疊的情況。
3.3 麥克風指向性選擇
麥克風的指向性也是麥克風的重要屬性之一[8]。常見的麥克風可分為4種指向性,分別為全指向、心形指向、超心形指向及雙指向。其中,全指向麥克風對于不同角度聲音的靈敏度基本相同,但容易接收到環境噪聲。心形指向麥克風對于來自特定方向的聲音有最佳的收音效果,而對于其他方向的信號有衰減效果。超心形指向麥克風作為心形指向麥克風的一種變形,對于側面方向聲音的衰減更多,從而降低了回音嘯叫的風險。雙指向麥克風可以接收麥克風前方和后方的聲音,其在側面的靈敏度最低。因此,在系統麥克風陣列的選擇上,房間中央位置選擇全指向麥克風,這種選擇可以最大限度地覆蓋整個房間,并且能夠均勻地接收到來自各個方向的聲音,確保聲音的均衡與一致,避免聲音在房間中的某個特定區域過于強烈或弱化;房間角落選擇超心形指向麥克風,以有效捕捉來自前方聲源的聲音,并且減少來自房間其他方向的背景噪聲和回聲干擾;房間邊緣則選擇雙指向麥克風,以有效捕捉來自房間中央或前方的聲音,并減少來自房間其他方向的背景噪聲和回聲干擾。
3.4 麥克風陣列之間的連接方式
在分布式麥克風陣列中,各個陣列之間的信息交換一般是通過直接相連的節點完成的,而各個節點之間的連接方式分為全向連接和部分連接。本系統則采用全向連接方式,每個麥克風陣列都可以和相同房間下的其他麥克風陣列直接通信,即同一房間中的所有麥克風陣列是相互連接的。
由于無線聲學傳感器的能量有限,所以各個麥克風陣列可選擇使用預測喚醒模式。在此模式下,無線傳感器網絡中的陣列選擇性地喚醒與本陣列數據處理最相關的陣列,通過陣列的連接信息和算法需求,選擇下一時刻需要喚醒的某個或某些陣列,此種方式能得到較低的陣列能量損耗和較快的信息處理速度。
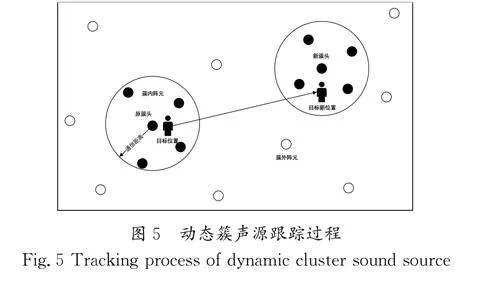
3.5 動態簇聲源跟蹤
分布式麥克風陣列中陣列數目眾多,若所有陣列都對目標聲源進行定位和跟蹤,勢必會帶來龐大的計算量負擔。分布式麥克風陣列是一種特殊的無線傳感網絡,根據動態成簇理論,在分布式麥克風陣列初期的聲源跟蹤方法應用中,一旦聲源靠近分布式麥克風陣列,該目標附近遇到陣列檢測信號后,就開始組建動態簇,以提升分布式麥克風陣列系統的運行速度和聲源定位的效率及促進數據融合。動態簇聲源跟蹤過程如圖5所示。
分布式麥克風陣列在聲源跟蹤的整個過程中,每一個陣列都會有一個跟蹤結果,所以分布式麥克風陣列的數據在融合過程中,需要將簇內各陣列的數據按照一定的邏輯算法進行融合處理,以求得最精確的結果。本系統會根據聲源所在房間,激活當前房間的所有麥克風陣列組建動態簇以進行聲源跟蹤。
4 測試與測試結果(Testing and the results)
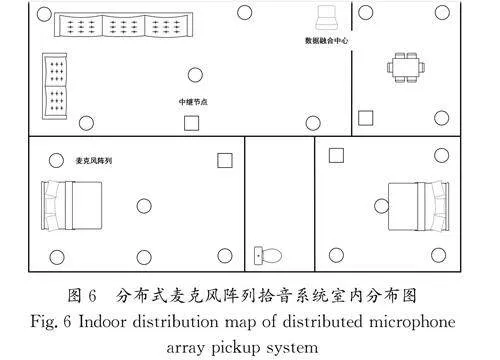
在室內將麥克風陣列按照矩形排布,具體的分布式麥克風陣列拾音系統室內分布圖如圖6所示。
測試在長為15 m、寬8 m、高3 m的房間進行,聲源定位抽象示意圖如圖7所示。
具體的測試方案如下。
以圖7左下角為坐標原點O 建立坐標軸,聲源參考點記作點A,OA 與x 軸的夾角為θ,測量聲源點實際坐標和3種算法計算得到的聲源點坐標。
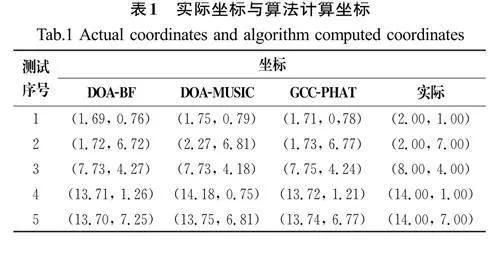
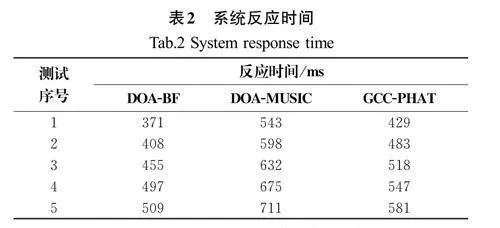
將DOA-BF算法、DOA-MUSIC算法、GCC-PHAT 算法分別應用在該系統中進行測試,每個算法測試5組,并統計系統給出的定位結果及反應時間,系統測試數據如表1和表2所示。
反應時間為系統接收到聲源的聲波信號到給出定位結果的時間,反應時間越短,表明系統的反應速度越快。由表1和表2的測試結果可知,各個算法的測試最大誤差不超過0.4 m,最大反應時間不超過1 s。DOA-BF算法的系統反應時間快,但是定位精度較低,DOA-MUSIC算法定位精度高,但是系統反應時間較長,而GCC-PHAT算法定位精度較高且系統反應時間較短。綜合各方面因素考慮,GCC-PHAT算法性能表現更均衡,因此選擇該算法作為系統所應用的算法。
5 結論(Conclusion)
本文主要實現了室內環境的分布式麥克風陣列拾音系統的設計,從系統的分層設計到無線聲學傳感器的選擇,再到聲源定位算法的選擇,均與室內環境有較高的適配性,但系統未給信號做降噪的預處理,因此在嘈雜的環境下,系統的整體精度稍有下降。在當今設備的使用環境中,聲源定位只是其中的一個方面,環境中的人員與攜帶麥克風陣列設備的交互、不同位置的人員通過語音控制不同的功能,這背后除了聲源定位,還需要應用語音增強技術,并對系統的功能模塊做進一步的完善,以滿足更多的需求。
