基于改進實用拜占庭容錯的可信分布式區塊鏈信任機制研究
2024-12-31 00:00:00張英豪肖滿生陳大鵬周榮燁
軟件工程 2024年7期
關鍵詞:區塊鏈技術;PBFT;信譽模型;信任機制
0 引言(Introduction)
《中華人民共和國國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要》中明確指出要發展云計算、大數據、物聯網、工業互聯網、區塊鏈、人工智能、虛擬現實和增強現實七大數字經濟重點產業。在此背景下,區塊鏈技術[1]再次得到社會各界的廣泛關注與深入應用。實用拜占庭容錯算法,作為區塊鏈共識算法[2-4]中最廣泛應用于聯盟鏈的投票類算法,有效地解決了節點間通信可能出現的拜占庭將軍問題[5],進一步提升了區塊鏈技術的穩定性和可靠性。但是,實用拜占庭容錯算法存在主節點選取隨機性大、缺乏信譽機制、易遭受Sybil女巫攻擊[6]及節點間的通信次數過多等問題,導致整個系統的共識效率低與鏈上空間存儲冗余。
針對上述問題,對PBFT共識算法進行研究,設計信用模型[7-9]和投票機制,用于動態更新用戶狀態,并根據節點的行為達成共識,提出具有分組評分機制和人工蜂群優化共識過程的算法[10-12],緩解網絡節點通信的驟增,降低惡意節點的影響。TANG等[13]通過引入信任公平評分機制,動態調整共識節點列表,簡化共識過程,優化共識效率。
基于上述研究,本文提出一種改進PBFT算法設計的可信分布式信任機制,即TM-PBFT。首先,該機制設計了多因素分權節點信譽模型,通過分層共識優化其三階段協議中一致性協議的預準備階段。其次,采用IPFS星際文件系統實現節點數據的分布式存儲。通過與其他模型進行對照實驗,結果證明TM-PBFT在通信效率上具有顯著優勢。
1 改進PBFT分布式信任機制設計(Distributedtrust mechanism design based on improved PBFT)
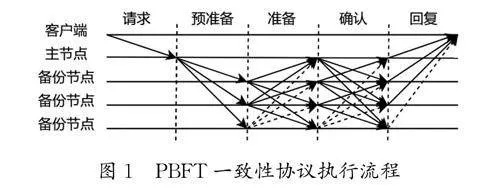
PBFT共識算法的本質是一種狀態機副本復制算法,為了保證節點在分布式系統內達成共識,需要3種協議以滿足算法的安全性與活性,即一致性協議、檢查點協議和視圖更換協議。一致性協議作為PBFT共識算法的核心協議,執行順序分為5個步驟(圖1)。
如圖1所示,一致性協議包含5個節點,自上而下分為1個客戶端節點、1個主節點和3個備份節點,其中最底端的備份節點為拜占庭節點。垂直線表示過程分界線,水平線表示各節點,箭頭線表示消息廣播由一個節點發送到另一個節點,虛線箭頭代表惡意節點的錯誤信息或不傳遞信息。
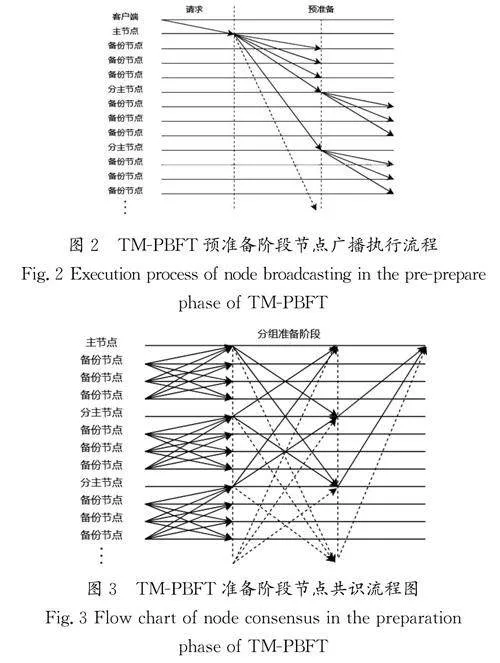
PBFT的一致性協議是一種相對高效和安全的共識算法,但節點的信息傳輸與備份節點共識的并發操作仍然存在改進和優化的空間。每個節點都需要廣播自己的消息給其他節點,會造成通信時延與復雜度過高,每個操作都必須經過3個階段(預準備、準備和提交)才能達成一致。因此,本研究提出一種節點預準備分層共識對協議進行優化,改進后的TM-PBFT預準備階段節點廣播執行流程如圖2所示。
在請求階段,客戶端向主節點傳輸信息并進行分發;在預準備階段,對節點進行分組,圖2中的虛線箭頭線代表未畫出的其他分組分主節點。
PBFT中的每個節點都需要廣播自己的消息給其他節點,這會造成大量的消息傳輸,可以通過壓縮、合并和篩選消息減少傳輸的數據量,從而提高網絡的效率。準備階段引入分組并發共識機制,使節點能夠并行地處理請求。TM-PBFT準備階段節點共識流程圖如圖3所示。
圖3中,實線箭頭代表預準備階段之后,節點進行廣播共識;虛線箭頭代表遭受Sybil女巫攻擊的惡意節點的虛假信息或者不進行廣播的節點信息,將傳統PBFT算法的準備階段分成3個部分,主節點分組并發共識,有效地解決了原始拜占庭容錯[5]算法效率不高的問題,將節點之間兩兩確認共識的復雜度從O(n2)降低至O(log n)。
2 信譽模型設計(Design of reputation model)
為了解決PBFT共識算法中節點選取隨機性高、優劣節點混雜的問題,設計節點信譽模型用于評估參與節點行為質量,將節點分為3種類型:正常節點、故障節點、惡意節點。引入節點獎懲機制,信譽模型使用歷史數據和參與者之間的交互數據計算每個參與者的信譽分數,以評估參與節點的可信度和價值,旨在通過激勵節點積極性,進而提升系統共識效率。
設每個加入區塊鏈的節點的初始信譽分數Rinit 為50分,低于40分的節點Rbad 不參與共識,信譽分數最高的節點Rmax為100,到達100分即不再增加。
節點信譽分數的增減由多種因素共同決定,如節點魯棒性、節點投入成本、通信成功率、節點間的投票數及參與共識輪次等。
節點魯棒性評估:在每個節點加入區塊鏈系統參與共識前,對自身穩定性與算力進行評估,剔除垃圾節點,防止Sybil女巫攻擊,評估指標為交易吞吐量Tt 與響應能力Rb,節點魯棒性評估公式Nr 為(α1,α2 為評估系數):
節點投入成本:節點加入區塊鏈系統需要根據上述評估結果提交對應比例的保證金Pn 作為置信憑證,保證金的數量與Nr 成反比,但不影響節點信譽分數評估,若所有節點保證金總和為PSum,則節點保證金對節點信譽分的影響P 為
通信成功率:每一次成功通信,節點的置信度都會提高,總通信成功率C 為通信成功次數Csuc 除以總通信次數Csum,其計算公式如下:
節點間的投票數:為提高各個節點間的參與度,給節點賦予投票權,給每個與本節點參與過信息交互的節點進行投票。規定每個節點可以給任意除自身外的交互過的節點投票,每個節點有1票,在每輪共識結束后統計票數,票數高的節點參與主節點選舉,避免主節點共識輪數過多而產生中心化特征,增加共識成功概率,提升可信度。設有n 個節點,Vi 代表節點i對節點j 的投票,Vj 代表節點j 的總票數,計算節點間投票數的公式如下:
參與共識輪次:節點的可信度與節點參與的共識輪次呈正相關,參與輪次越多,說明節點共識安全越值得信賴。因此,給節點信譽模型引入衰退函數,當節點n 參與了前i 輪次的共識且不被標記為拜占庭節點,則(i+1)輪次的信譽分數不受衰退函數的影響;當節點n 未參與前i 輪次的節點,則使用如下衰退函數f(n)計算(θ 為衰退指數,s 為節點總共識輪次),計算參與共識輪次的公式如下:
結合上述多層次因素考慮,可以得出信譽分數的增減機制,主節點的選舉則與節點信譽分數呈正相關,節點信譽分數Ri 的計算公式如下(β1,β2,β3,β4,β5 分別為節點信譽權重):Ri=Rinit+β1Nr+β2P+β3C+β4Vj-β5f(n),Ri∈[0,100]
在上述信譽模型中,節點計算信譽分數會產生額外的時間與算力成本,進而降低系統共識效率,但不計算節點信譽分數又會導致系統出現受Sybil女巫攻擊、節點產生中心化特征、備份節點產生惰性等問題,因此系統設定每進行3次共識則計算1次信譽分數,每計算3次信譽分數則進行1次主節點選舉,這種方法極大地提高了參與節點的共識積極性,確保了系統的安全與高效。
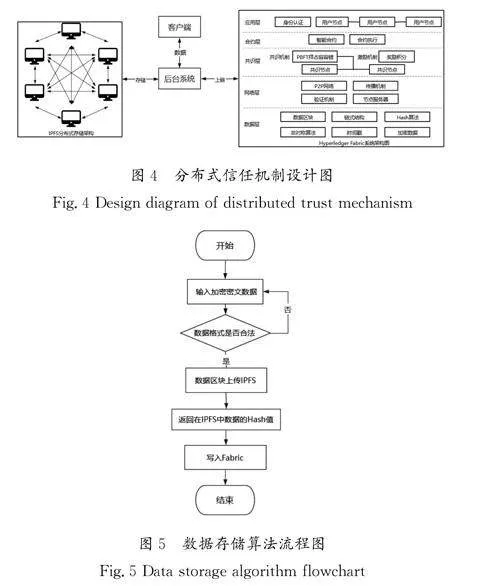
本設計以后臺服務開發為核心,將所設計的后臺系統作為連接客戶端、IPFS及Fabric區塊鏈的服務部件。分布式信任機制設計圖如圖4所示。數據存儲算法流程圖如圖5所示。
IPFS存儲文件的過程是分布式的,文件不是存儲在單個中心化服務器上,而是分布在多個節點上。因此,IPFS在存儲和傳輸文件方面具有較高的可靠性、安全性和效率。IPFS與區塊鏈結合,為構建可信的分布式信任機制提供了一種創新的解決方案,并在未來的數字經濟中得到了廣泛應用。
當大量數據需要可靠實時地存儲和驗證時,必須將數據以某種形式存入區塊鏈。傳統區塊鏈系統的數據存儲容量與速率非常低,無法存放大規模數據。基于此,利用“區塊鏈+分布式存儲”的方式可以解決大規模數據上鏈的問題,將原始數據存儲于分布式文件管理系統中,并將源文件的地址存儲于區塊鏈,用戶可以通過區塊鏈上文件的地址信息隨時獲取這些數據。同時,為了保證IPFS上的數據不被篡改,必須將文件的指紋(哈希算法結果)也一并存入區塊鏈,這樣用戶可以對鏈上數據進行驗證,以確定數據的完整性與可靠性。
3 理論與實驗分析(Theoretical basis andexperimental analysis)
實驗采用Java編程語言設計開發出一個多節點高并發的區塊鏈系統,在吞吐量、共識時延及通信開銷等方面與文獻[14]中的C-PBFT共識算法進行實驗對比分析,系統開發配置信息為Intel(R) Core(TM) i5-7300HQ CPU@2.50GHz雙CPU和16 GB運行內存,開發軟件使用操作系統的版本為Ubuntu 20.04,Node.js的版本為10.16.0,通過Docker搭建Hyperledger Fabric分布式集群和IPFS。
3.1 吞吐量
吞吐量對比是指通過在同一設備單位時間內完成交易傳輸數據的數量,即TPS(Transaction Per Second),其公式如下:
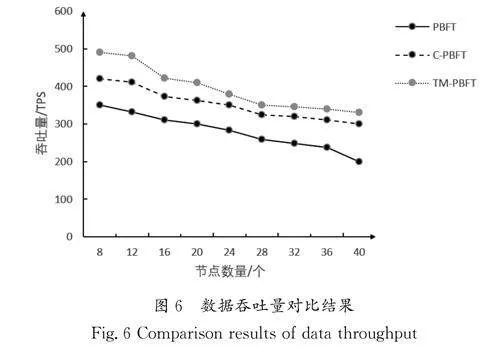
其中:Transaction 為單位時間內傳輸數據的數量,Δt 為傳輸數據所用的時間,吞吐量通常與硬件因素密切相關,因此在相同硬件條件下,所設計的系統吞吐量越大,則表示系統共識效率越高。數據吞吐量對比結果如圖6所示。
圖6的橫坐標代表節點數量,縱坐標代表數據吞吐量。隨著節點數量的增加,3種算法的吞吐量都有一定幅度的減少,而在相同的節點數量下,TM-PBFT 的吞吐量明顯高于傳統PBFT算法的吞吐量,略微高于對照實驗的C-PBFT算法的吞吐量。并且,隨著節點的增加,即增加共識次數,改進后的TMPBFT算法在吞吐量方面有明顯的優勢。
3.2 共識時延
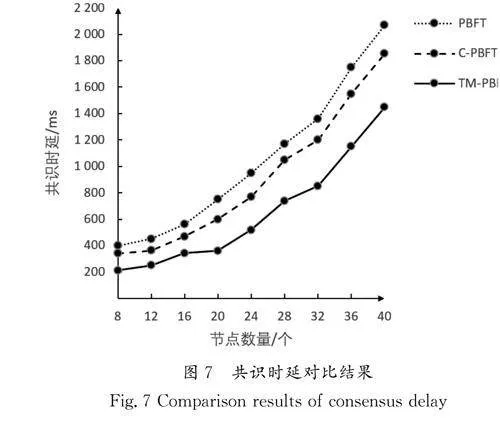
共識時延對比是指不同共識算法在相同網絡架構下的共識過程所需的時間延遲對比。通過對步長為4的節點數量進行增加,確保實驗的準確性。不同節點數量重復10次實驗,將10次實驗的時延總和的平均值作為最終結果,確保實驗的一般性。共識時延對比結果如圖7所示。
由圖7可知,共識時延與節點數量呈正相關,即節點數量越多,則共識時延越久。優化了一致性協議的TM-PBFT算法與C-PBFT算法和傳統PBFT算法相比,在共識時延方面具有顯著優勢。
3.3 通信次數
通信次數是指各節點之間兩兩進行信息傳遞的次數。通常情況下,通信次數越多,共識效率越低,傳統PBFT共識算法通信次數計算公式如下:
其中,K 為對節點進行分組的簇數。對于本文設計的TMPBFT算法,同樣對節點進行分簇處理,通過公式(10)計算得到通信總次數:
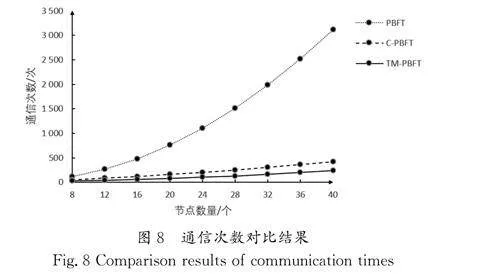
利用公式(8)和公式(9)得到3個階段的通信次數對比結果如圖8所示。
實驗結果表明,在節點數量相同的情況下,分層對組內節點進行共識相比于原始的PBFT算法,通信次數大大降低,而在40個節點時,相較于傳統PBFT 算法,通信次數下降了85.8%,相較于C-PBFT算法,通信次數下降了27.7%,呈現出節點越多,TM-PBFT算法與傳統PBFT算法和C-PBFT算法的通信次數相差越大的趨勢。
4 結論(Conclusion)
通過對PBFT算法的深入研究,將改進的PBFT共識算法同IPFS星際文件系統相結合,提出一種效率優化的分布式信任機制。改進后的共識算法有效地優化了PBFT共識算法存在的通信復雜度高和通信效率低等問題;結合IPFS星際文件系統,降低了鏈上存儲壓力;引入節點信譽模型避免了受到Sybil女巫攻擊、惡意節點充當主節點及替補節點積極性不高等問題。對比實驗數據發現,在共識時延、通信開銷、系統吞吐量及系統安全性等方面,本文提出的模型的表現明顯優于傳統PBFT算法和C-PBFT算法,有效地提升了系統的共識效率、安全性和可靠性。但是,該模型仍有許多不足之處,后續將進一步對節點的動態調整副本組成與分層分組進行優化,最大限度地降低通信復雜度。
