基于網格過濾的局部線性嵌入法在商業大數據高維離群點檢測中的應用研究
2024-11-22 00:00:00葉晟
電腦知識與技術 2024年26期



關鍵詞:商業大數據;網格過濾;高維數據;離群點;局部線性嵌入法
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)26-0067-04開放科學(資源服務)標識碼(OSID) :
0 引言
在目前的信息新時代,大數據是生產要素,也是國家的基礎性戰略資源。商業大數據以海量的數據集合為特征,它在商業營銷、決策等方面有著廣泛的用途。根據相關數據及其預測,從2015年至2025年,中國企業級的數據量將得到大幅度的增長。伴隨著信息技術的發展,企業數量的增加以及應用場景的不斷豐富,商業大數據將會有一個大幅度的增長。
商業大數據應用主要是指相關數據服務組織將采集到的原始數據經過專業的數據分析工具的清洗、修剪、整理及分類后變為結構化的信息。然后專業技術人員又將這些結構化的信息經過數據挖掘轉變為相關的專業數據集,形成專業數據集后,專業技術人員將這些數據集根據不同的應用進行數學建模。相關的數學模型建立了以后,也就意味著某種具體的商業應用形成了相關的數據資產。專業技術人員通過挖掘數據資產背后所隱藏的價值,賦能給各行各業,為信用評級、風險管理、營銷決策等提供附加價值。
商業大數據的應用根據客戶類型及使用形式,可以分為企業端基礎數據服務、企業端標準數據服務、企業端場景化數據服務等形式。
目前,商業大數據的應用主要是集中在電信、金融等領域。但是隨著技術的發展及商業大數據應用的普及,政務、工業、公檢法等領域也逐漸越來越適應利用大數據進行相關業務的管理及決策。另外,在一些傳統行業,比如電力、鐵路、石化等,這些行業中的一些龍頭企業也不斷地利用其自身雄厚的經濟實力,不斷完善自身的大數據的建設、管理和應用的能力。商業大數據的應用越來越向實體行業滲透已經是一個不爭的事實。
1 商業大數據中高維數據離群點檢測的必要性
隨著大數據技術在商業應用上的成熟,需要對大量商業應用的相關數據進行卓有成效的采集。因為高維數據往往更能準確地反映商業應用中不同數據單元的相互聯系,所以對高維數據的數據挖掘則顯得尤其具有重要意義。而在對高維數據的挖掘中,離群點的檢測對于數據異常的判斷具有重要的參考作用[1-2]。離群點檢測的主要內容就是通過數據挖掘發現與正常數據維度偏差比較大的數據點,從而進行相應的降噪處理從而達到將采集的數據恢復正常的目的。離群點產生的原因有很多,譬如隨著商業應用的深入, 商業應用中所采集用戶的大數據的維度變得越來越高階,相關的數據結構也變得越來越復雜。所以若要對這些由相關應用所產生的大數據進行有效的利用,那么對數據中離群點的檢測則變得至關重要了起來。
國內現有很多專家對高位數據離群點的檢測進行了很多卓有成效的研究。楊曉玲[3]等利用對象區域密度和臨近區域間的相互關系,通過計算得到兩者間的相對距離,然后對應最小生成樹結構,將離群簇和離群點進行一個分割,從而實現對離群點的檢測。但這種方法的缺點是對機器內存的占用跟數據維度的增加成正比,所以應用的實踐性不強。邱華[4]等則預先對已產生的海量數據進行處理,然后對這些處理過的數據利用極限學習機進行訓練,經過訓練之后會得到一個對于局部離群因子閾值的預測,之后再利用WLOF 閾值對數據進行聚類處理,從而檢測出離群點。但這種方法效率比較低,同樣應用的實踐性不強。
針對以上問題,提出面向高維數據檢測的局部線性嵌入法。通過劃分網格對高維數據進行預處理。然后將預處理過的數據中的高維離群點,利用角度方差進行一個自動化的檢測。經過實驗測試表明,在實踐中這種方法不僅可以大幅提高內存的使用率,還可以極大地減少檢測的時間,并且還能保證檢測結果的精度。
2 局部線性嵌入法對高維數據的檢測
2.1 劃分網格
為了實現對高維數據離群點的檢測,首先要進行網格劃分的處理,而處理的依據則來自這些高維數據的空間維度。對應的維數空間可以表示為公式(1) :
2.2 處理高維數據集
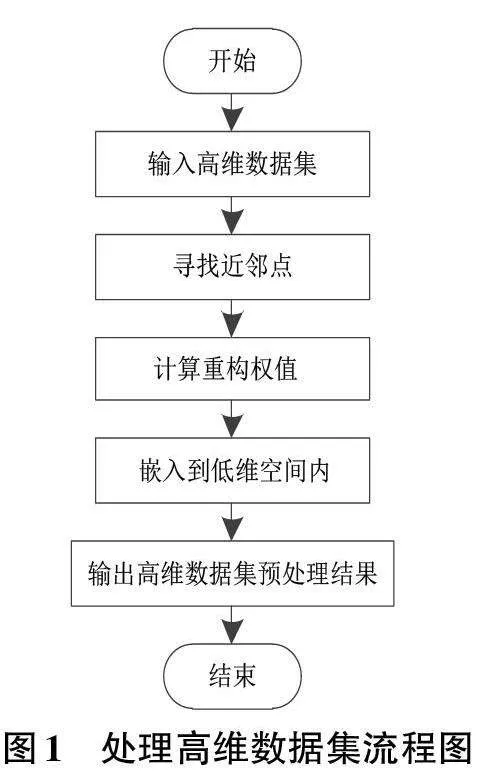
在檢測離群點的過程中,對于高維數據集的處理是關鍵的步驟,為了準確地描述它的數據結構,我們采用局部線性嵌入法對它來進行處理,通過分析數據點的不同組合的特性后,從而得出高維數據的數據結構。處理高維數據集的流程圖如圖1所示:
(1) 輸入高維數據集,然后利用相關算法獲取最近鄰點。
(2) 通過重構誤差獲取高維數據點及其鄰近的數據點的權值。
(3) 通過相關公式獲得鄰近的數據點經過變換后的重構權值,同時將高維數據集進行降維處理。
(4) 將降維后的數據集重新通過公式進行計算,得到一系列具有相關特性的數據點。
(5) 將這一系列的數據點根據權值特性劃分成符合要求的數據聚類,輸出相關結果,完成高維數據集的處理。
2.3 高維數據離群點的采集
在高維數據集離群點的采集過程中,真正能對商業應用提供重要意義的數據點實際只占全部數據集合的一小部分,大部分數據點的信息對于數據挖掘的過程起到的只是干擾作用,并且這部分信息的存在還會影響到處理結果的準確性。
前后文信息是數據離群點的重要組成部分。它不僅可以體現離群數據和其他數據的一致性關系,除此以外,它還可以提供更具參考意義的信息,比如離群數據的具體含義和不同之處。
在這里,我們可以利用MapReducc模型來進行高維數據離群點的采集。MapReducc模型是一個廣泛應用于不同領域的大數據模型。MapReducc模型的數據邏輯在于可以將一個大的編程任務劃分成不同的,然后進行分布式處理,這樣不僅執行效率高,而且對于硬件資源的占用也會比其他數據模型低得多。MapReducc模型在處理數據的過程中主要分成以下幾個步驟,分別為:
(1) 切割數據:根據不同應用的不同需求,將高維數據進行切割,得到對應的待處理的輸入數據。
(2) 負載均衡:通過集群聚類計算不同節點的處理效率,然后再根據計算結果從宏觀上來分配不同節點的計算資源,使之得到最佳的調度處理。
(3) 處理錯誤信息:對不同節點計算后的結果進行核對處理和統計,統計它們的錯誤情況,并將全部節點的錯誤信息進行收集,并根據具體情況作出是否要發出警告信息的判斷。
(4) 通信處理:對于高維數據集當中需要通信的全部節點進行高效的管理,確保每個數據節點間都能正常通信,而且在通信過程中保證數據的有效性、可靠性和安全性。
通過如上所述分析,可以得出高維數據離群點采集的詳細流程如下:
(1) 輸入經過處理的高維數據集。
(2) 經過分布式運算處理,得出不同子空間的離散程度。
(3) 通過分布式計算得出不同數據子集的維度信息,從而得出不同數據對象的離散程度。
(4) 根據不同的離散程度形成不同的稀疏矩陣。
(5) 根據不同的離散程度通過運算得出具有特異性的因子,然后將這些因子按照從小到大的順序排列,然后從這些順序排列中得出我們想要的關于高位數據離群點的采集結果。
2.4 檢測高維數據離群點
在高維數據集中,正常數據和離群數據的比值如果比較懸殊,而在維度比較低的空間中又存在分布比較密集的區域,則我們對于差異因子的取值利用密度分布來進行描述則顯得比較適宜。
對于網格化后的數據集,我們選取其中體積最大的網格來作為我們的標準網格。其中我們可以利用數據點和鄰近對象之間的矢量距離來作為測量半徑,根據半徑的大小來作為劃分網格的依據,以效避免過度稀疏情況的產生。
由于分布稀疏是高維數據集的分布特性,所以劃分網格時,有可能會產生不包含任何數據的空白網格單元。因此在對網格劃分的前期,在進行類型判斷時,應先采用方法將這些空白的網格單元予以過濾,這樣既可以節省空間資源,對時間復雜度又能進行有效降低。
另外,對于算法復雜度影響比較大的因素還有網格的存儲結構。因此,針對高維大數據的稀疏特點,我們可以利用哈希表來完成網格單元的存儲工作。利用哈希表的既有優點,我們可以在大大節省系統存儲資源的同時,還可以有提高查詢和遍歷的效率。網格單元信息利用哈希表來進行存儲,利用網格及其相鄰的網格關系,對不同子空間進行劃分映射處理后,可以形成一張數據表。
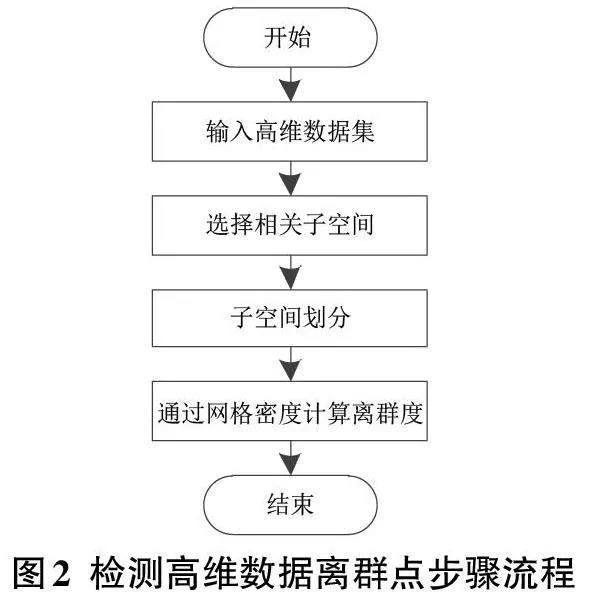
如上所述,利用角度方差來對高位數據離群點進行數據檢測,步驟如圖2所示。
(1) 通過密度分布矩陣來對相關屬性進行相應的處理,構建形成不同的數據子空間,從而完成對高維數據集的預處理。
(2) 確定標準網絡,然后確定數據子空間內進行測量的矢量維度半徑。對于前期已經完成處理的網格,需要先刪除其中已經確定的空白網格,然后將剩余部分利用哈希表進行存儲,并進行遍歷計算。另外,已經確定好的標準網絡即作為中心網絡,以此作為依托對鄰近網絡進行數據處理。同時,利用稀疏矩陣選擇網格,并經過一定的數據處理后得到正常運行的網絡。
(3) 經過網格劃分后形成候選網格,然后利用角度方差因子進行分布式計算。其中,將網格密度設為重要指標,分別對比不同子空間的角度方差因子和離群度,經過降序排列后,輸出排名高的數據對象將其作為離群點,從而完成對高維數據離群點的檢測。
3 仿真實驗
為了驗證所提面向高維數據離群點檢測的局部線性嵌入法的有效性,我們需要進行仿真實驗以進行驗證。
(1) 測試環境:實驗所使用的計算機操作系統為Windows 11,配置Intel i5處理器和128GB運行內存,同時使用Matlab軟件作為驗證平臺。
(2) 測試結果:實驗分別對本文所提方法以及文獻[3]方法展開高維數據離群點的相關檢測,根據測試需要,先假定好空間維數,然后根據不同的數據密度閾值分別進行數據訓練,然后得到不同情況下的時間執行效率。
從得出的實驗結果進行分析可知,在密度閾值發生變化的情況下,兩種方法的執行效率產生了明顯的差異。本文所提方法的執行效率會隨著數據密度閾值的增加而提升,而文獻 [3]方法對于數據的執行效率則基本保持不變。由此可以看出,在限定時間的情況下,本文所提方法的執行效率會比較高。
我們進一步通過實驗分析在不同數據集下,這兩種方法在執行時間上的變化。由實驗結果可知,隨著測試數據集變得越來越復雜,這兩種方法的執行時間也會變得越來越長。但是對比另外一種方法,本文所提方法明顯執行時間更短,所以這也可以證明本文所提方法的執行效率更高。
其次,為了檢測對于高維數據離群點的檢測準確性,我們將檢測精度作為檢測指標,通過不同數據集進行相關的數據訓練,實驗結果的準確性越高,說明所用方法的檢測精度越高。
從實驗數據可知,本文所提方法在不同的數據集下的輸出精度一直都保持穩定,且精度均值也比較高。而文獻[3]的方法在同樣的條件下進行數據訓練,輸出結果精度明顯偏低,同時該方法的輸出結果明顯還會受到數據集復雜度的影響。因此,本文所提方法對于檢測高維數據離群點的準確性而言具有明顯的優勢。
最后,我們再來分析一下在進行不同數據集訓練時,不同檢測方法對于系統內存資源的占用情況。由實驗得出的實驗數據結果可知,隨著所采用的實驗數據集的維數增高,不同檢測方法對于內存資源的占用也會隨之升高。在進行對比的兩種檢測方法中,本文所提方法對于內存的占用一直比較低,而文獻[3]的方法對于內存的占用情況則明顯偏高。據此,本文所提方法在進行高維數據離群點的檢測時能有效降低內存資源的占用情況。
4 結論
針對商業大數據的數據挖掘中高維數據離群點的檢測,提出了基于網格過濾的局部線性嵌入方法。在進行網格維度劃分時,我們利用數據子空間的概念,先利用相關算法將子空間進行劃分,然后使用局部線性嵌入法進行檢測。局部線性嵌入法在保證商業數據精度的同時,還能夠大幅地降低系統資源及數據檢測的執行時間,這一點已經在實踐中得到了證明。
