基于空間相關和Informer網絡的風電功率預測方法
2024-10-23 00:00:00孫旭劉界廷
電腦知識與技術 2024年25期

關鍵詞:空間表征;功率預測;Informer網絡;稀疏概率自注意力機制;深度學習
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)25-0094-03
0 引言
風電作為一種可再生的清潔能源,其技術相對成熟,是目前應用最廣泛的新能源發電方式之一。截至2021年底,全球風電累計裝機容量中陸上風電占比超過93%,陸上風電新增裝機容量占比超過77%[1]。但由于外在條件的間歇性和隨機性,風電滲透率的快速增長對電力系統的調度和規劃提出了新的挑戰,因此對風電場輸出功率進行準確的預測是降低風電輸出功率不確定性的最有效手段,為大規模風電的有效消納提供重要支撐。
風電功率預測是一項具有挑戰性的任務,因為風力發電受到與風和環境相關的多種因素的影響,以及風力渦輪機的物理條件和特性[2]。在過去的時間里,風電功率預測技術取得了很大進步,例如,GO Kaya混合了經驗模態分解(EMD) 和隨機森林回歸(RFR) 兩種算法,并在土耳其的真實風電數據上進行了實驗[3];Han L等[4]采用變分模態分解方法將風電數據分解為3 個組成模態,并利用長短期記憶網絡深入學習這些模態的特征,提出一種變分模態分解長短期記憶(VMDLSTM)預測方法。近年來,人工智能方法以其高效性和良好的非線性學習能力在風電功率預測領域受到越來越多的關注[5]。Li等[6]結合空間依賴性并通過門控遞歸單元(GRU) 來提取時間趨勢,提出了一種基于編碼器-解碼器結構的風力發電預測深度學習方法。
不同的方法在不同的測試場合中表現出各自的優勢,上述方法雖然能夠擬合真實值,但通常缺乏對空間特征的考慮或對時間序列依賴性處理不足。為了解決這些問題,本研究從空間和時間的維度出發,通過K近鄰算法融合來自周圍風力渦輪機的數據以增強風況知識,完善風電功率預測的物理屬性。同時,引用Informer網絡模型解決模型對時間序列依賴性不足的問題,其中多頭概率稀疏自注意力機制使得模型能夠集中關注與當前時間步驟相關的輸入數據部分,從而減少對整個輸入序列的處理,提高計算效率和模型性能。
在時間維度上,對時間信息進行編碼,將每個時間點上的時間單位的值映射到區間上的標準化值。最終,將時間特征向量、空間特征、氣壓和風向特征合并為歷史特征數據,并對其進行時間窗口劃分。
2.2 模型
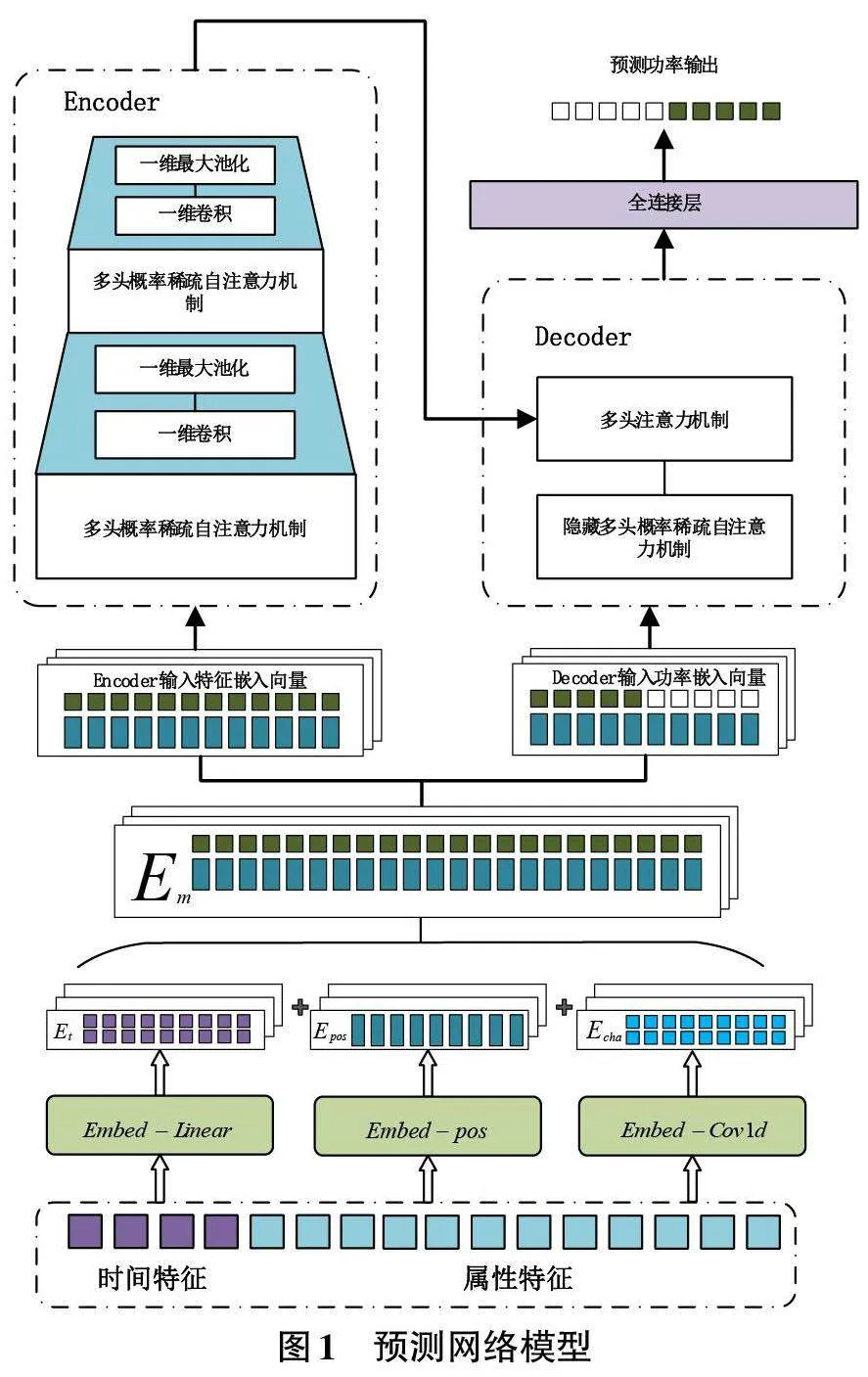
預測模型結構如圖1所示。為了使模型能夠更好地捕捉歷史特征數據與未來時刻輸出發電量之間的關系,將輸入的特征數據轉化為模型的特征嵌入向量。時間特征向量和屬性特征向量會分別經過線性層和一維卷積層,被映射為與模型輸入和輸出維度相匹配的嵌入向量E, E;同時,屬性特征向量還會通過計算正弦和余弦函數的組合[8]來生成位置編碼向量E,最終合并這些向量以獲得模型的嵌入向量E。
Informer網絡模型[7]包括編碼器和解碼器兩個部分。編碼器負責捕捉歷史時間段內的屬性特征,其中功率特征向量將作為解碼器的輸入。與傳統的注意力機制Q,K,V 矩陣計算不同,Informer的獨特之處在于其稀疏概率注意力機制,它通過與均勻分布進行比較,計算某一時刻與其所在時間區間內其他時間點的相關性分布。差異越大,則該時間點在其所在的時間區間內越相關,反之則越不相關。
在編碼器中,相鄰的注意力模塊之間采用了卷積與池化操作,以對特征進行下采樣。這是由于稀疏概率自注意力機制的特殊計算方法可能導致冗余的注意力分數,因此通過這種蒸餾操作來不斷捕捉重要特征。
對于Informer的解碼器,輸入序列的預測部分用0作為mask掩碼進行填充。對于概率稀疏注意力中對q 的填充方式,不同于編碼器使用V 的均值進行填充,解碼器采用累加求和的方式,以防止模型關注未來時刻的功率量。
為了使模型的預測序列與實際觀測序列盡可能接近,需要通過計算輸出值與實際值之間的誤差,使用反向傳播算法來調整網絡的參數。
3 實驗
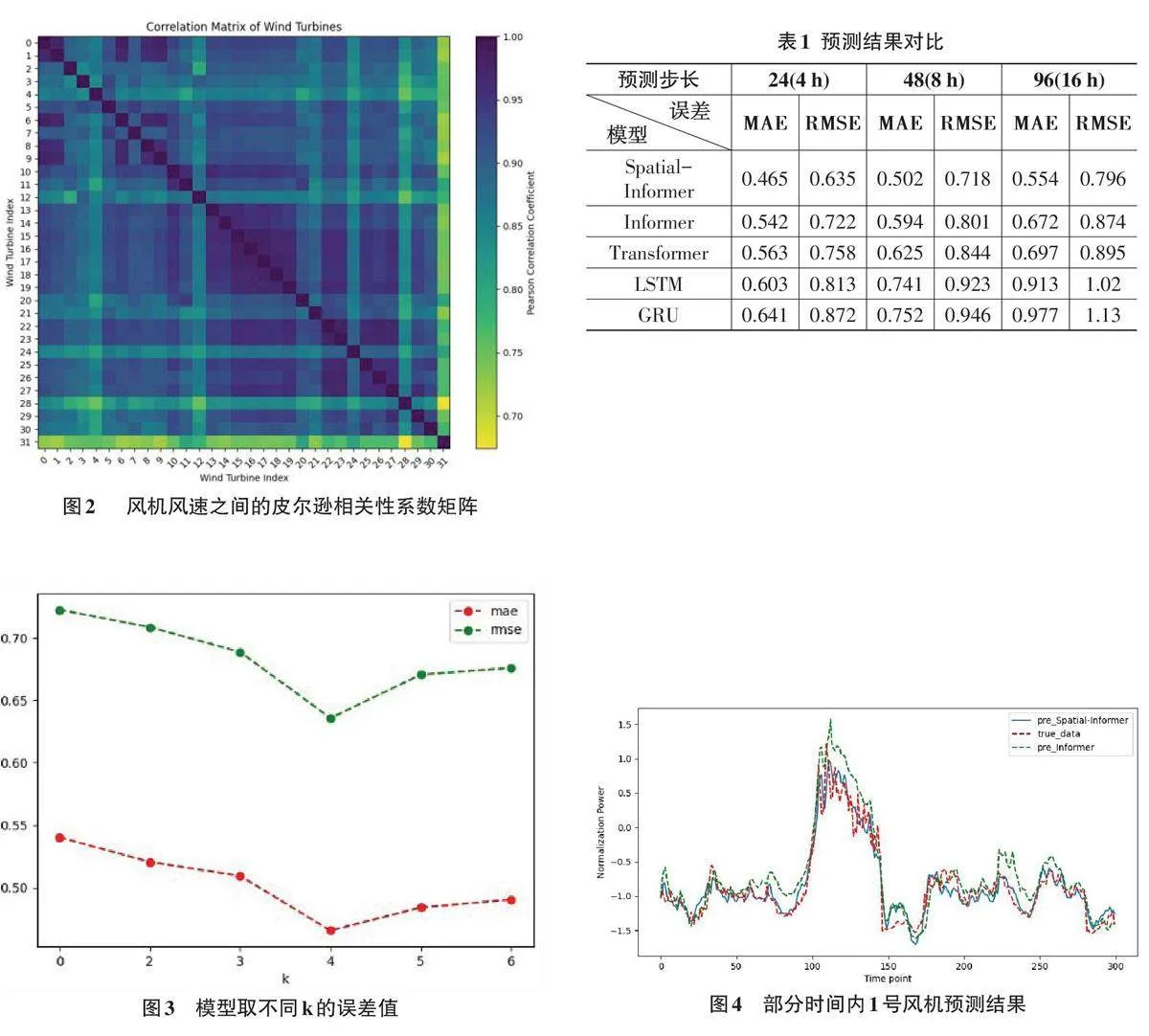
在本節中,將說明所提出的模型在真實數據集上的表現。該數據集來源于位于巴西東北海岸的Be?beribe風電場(UEBB) 。數據集包括從2013年8月至2014年7月32臺風力發電機的SCADA數據,采樣間隔為10分鐘[9]。其中,70%作為訓練集,30%作為測試集,預測結果將基于測試集進行評估。圖2展示了每臺風機風速特征之間的皮爾遜相關性系數矩陣,可以看出機組與機組之間存在一定的潛在聯系,這也為空間相關性分析做好了鋪墊。
基于該數據集,將所提出的模型Spatial-Informer 與原模型Informer進行了對比,以驗證空間特征的有效性。通過引入空間相關性特征,隨著近鄰機組數量的增加,預測結果的準確性有所提高,但如果近鄰機組數量k 選擇不合理,也會對預測結果的準確性造成影響。如圖3所示,當融合4個近鄰機組作為目標風機的空間特征時,誤差達到了最低。這表明適當的空間特征融合可以顯著提升模型的預測能力。
與經典模型,包括GRU 和LSTM,進行了對比。表1展示了這些模型的性能比較。預測結果使用平均絕對誤差(MAE) 和均方根誤差(RMSE) 進行評估。
圖4展示了風電場中1號風機在某些時間段內測試集上的表現,預測步長為24(4小時)。在圖中,紅色虛線表示真實值,綠色虛線表示沒有引入空間表征的Informer模型的預測值,藍色實線表示引入空間表征的Spatial-Informer模型的預測值。可以看出,與原先的Informer模型相比,Spatial-Informer模型的MAE降低了7.7%,RMSE降低了8.7%。這說明引入空間表征的Spatial-Informer模型在準確性上具有顯著提升,更好地捕捉了空間相關性,從而提高了預測性能。
4 結束語
在本次工作中,提出了一種基于空間相關性和In?former網絡模型的風電功率預測方法。通過融合目標的近鄰屬性,并嵌入至Informer網絡模型中,該方法能夠有效集成空間特征和時間依賴性,更好地捕捉歷史特征數據與未來時刻輸出發電量之間的預測關系。與原Informer模型和經典模型相比,該方法提高了預測精度。然而,在本次實驗中,僅考慮了目標風機的分布,而現實中的氣象特征變化與地理位置之間依然存在不確定性因素,因此仍有不足之處。對于未來的工作,將進一步評估空間分布相關性,以提高預測結果的準確性。
