基于多模態融合的視頻自動剪輯算法的設計與研究
2024-10-23 00:00:00王煥祥
電腦知識與技術 2024年25期


關鍵詞:視頻自動剪輯;多模態特征融合;Transformer;自注意力機制
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)25-0040-04
0 引言
視頻作為生活中交互信息的載體,人們已經通過一系列設備錄制眾多視頻,但是對視頻的瀏覽與剪輯仍需要耗費一定時間。能從一段長視頻自動剪輯出它最重的部分或者自動生成視頻摘要將是一件省時省力的工作。這不僅是對視頻剪輯者是一件更有效率的工作,對于視頻閱讀者亦然如此。因此筆者采用了多模態(視覺、聲音、文字)的方式對視頻的信息盡可能地提取,從而精準地生成原視頻的摘要視頻[1]。
如今,已經提出一些基于深度學習模型多模態自動視頻摘要的生成方法[2]。其中利用RNNs模型[3],但RNN模型難以捕捉長時間的依賴關系和難并行化,這對長視頻依賴關系的捕捉產生負面影響,從而影響準確性。本文舍棄傳統的RNNs模型,采用了基于自注意力機制的Transformer基準模型(base-line model) [4],并在此基礎上進行改進。
自注意力機制和多模態已經被廣泛地應用于視頻摘要任務中。如文獻[5]通過位置編碼將局部自注意力和全局自注意力相結合,有效地將局部特征和全局特征相結合。文獻[6]中,通過分層次的自注意力機制,充分地將多個模態進行特征級融合。
本文針對多頭自注意力機制特征融合程度不夠深的問題,提出了一種基于跨模態特征交互和編碼器-解碼器結構框架的視頻摘要模型。本文算法提取原始視頻幀的特征,利用注意力模塊將多個模態進行融合,最后通過預測頭對各個片段進行評分,得到一組連續鏡頭作為視頻的摘要。
1 研究方法
1.1 模型總體結構
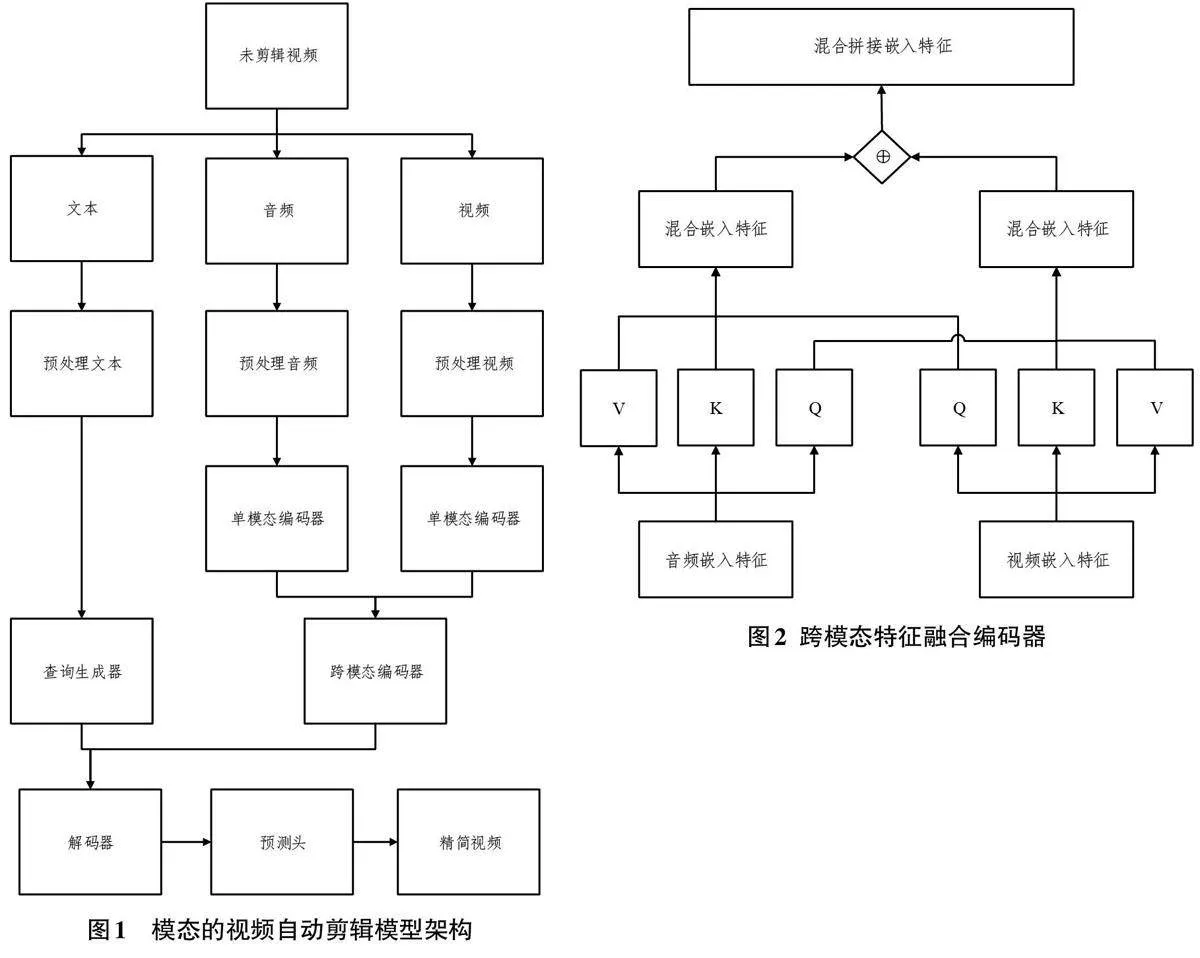
圖1展示了本文提出的基于多模態的自動剪輯算法設計框架流程圖。文中的模型由單模態編碼模塊,跨模態編碼模塊,查詢器生成模塊,解碼模塊和預測頭模塊。各個模態會通過不同的預訓練模型提出特征,然后視頻和音頻會先通過跨模態交互得到兩者的編碼,再基于音頻特征生成查詢序列,最后通過解碼并且預測頭生成視頻摘要。
1.3 跨模態特征融合編碼器
此模塊的跨模態是基于跨自注意力的基礎上實現跨模態。此前文獻[7]已經證明跨模態和跨自注意力有助于特征融合。因此,在單模態編碼之后,還需要使用一個額外的跨模態編碼器來捕捉跨模態的全局相關性。在跨模態編碼器中,將兩個視覺模態和音頻模態的信息進行交互并融合,能夠形成視覺語言共同注意力。跨模態編碼器的計算流程和單模態編碼器的計算流程一樣,但兩種模態計算注意力塊時的query相互交換。在處理視覺模態以聲音條件進行多頭自注意力計算,在處理聲音模態以視覺為條件進行多頭自注意力計算。最后再將兩個混合后的特征進行拼接操作(concatenation) 如圖2。
1.4 查詢生成器
由于Transformer最初是為語言翻譯任務而引入的,因此輸入和輸出序列的長度可能不盡相同。輸出序列的長度由輸入Transformer的查詢嵌入決定。輸出序列的長度由輸入解碼器的查詢嵌入決定。當Transformer延展到視覺任務時,查詢嵌入會在訓練過程中隨機初始化和學習。查詢嵌入應自然而然地指導表示解碼過程。因此,該模型引入了一個查詢生成器,以根據自然語言輸入自適應地生成時間對齊的時刻查詢。該模塊也是由多頭注意力層構建的,其中視覺和聽覺混合特征充當query,文本特征是key 和value。我們的假設是,通過計算視頻片段和文本查詢之間的注意力權重,每個片段可以了解它是否包含文本中描述的哪些概念,并預測一個查詢嵌入,該查詢嵌入可用于對所學信息進行解碼,以滿足不同需求。
2 實驗與結果分析
2.1 數據集
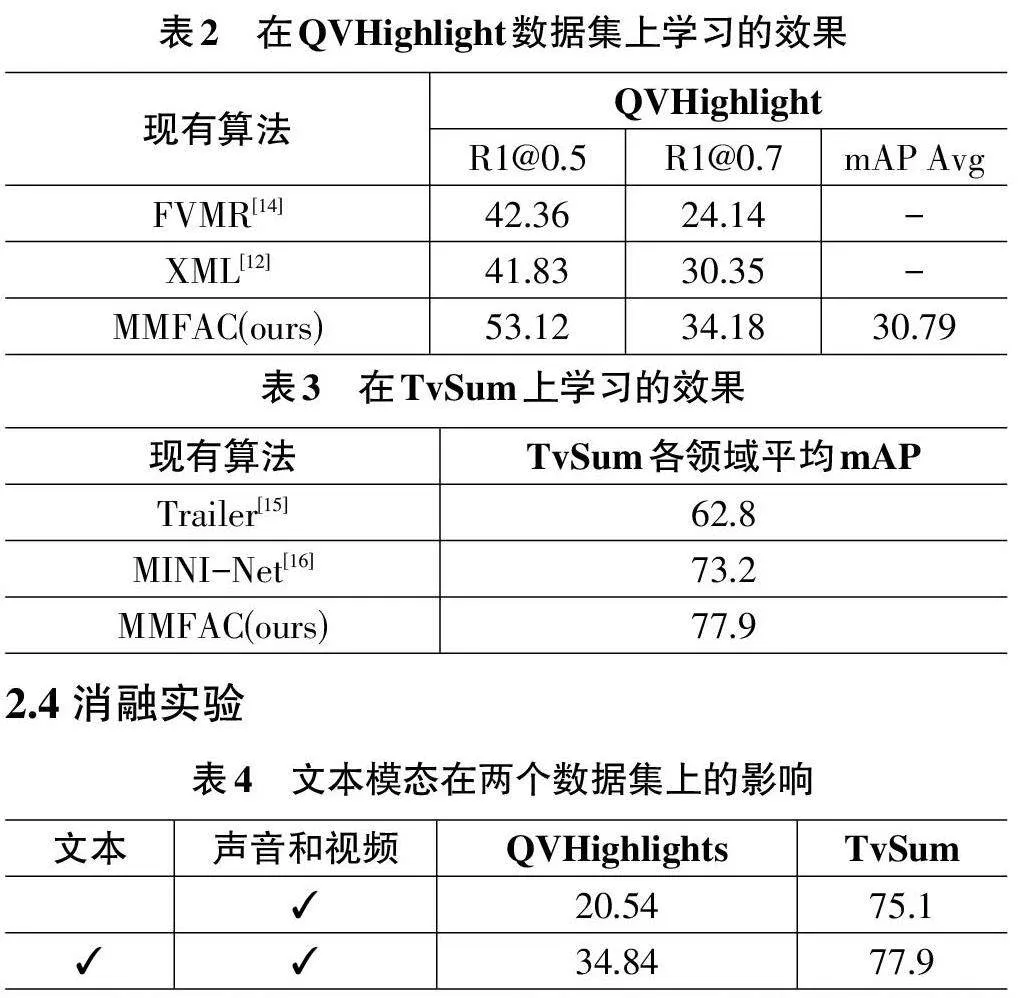
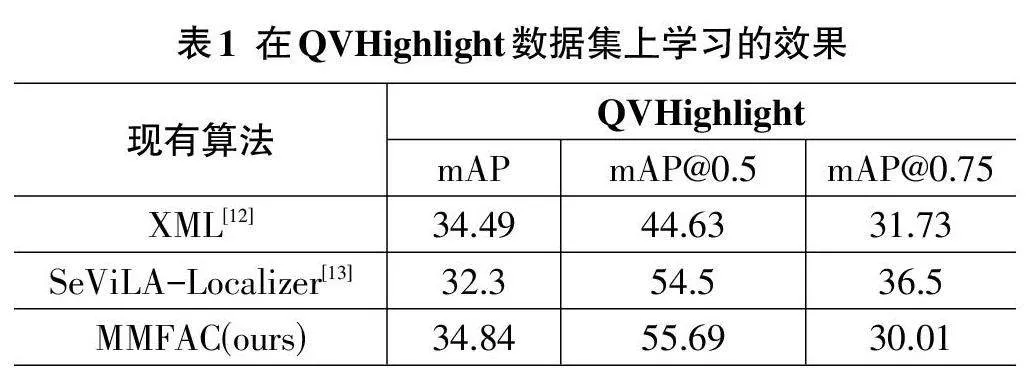
該實驗的訓練集使用QVHightlights[10]數據集進行訓練并使用TVSum[11]數據集驗證。QVHightlights數據集包含裁剪成10 148個短片段(150個長片段)的視頻,每個片段至少有一個描述其相關時刻的文本查詢注釋。每個查詢平均約有1.8個不相關時刻,注釋在不重疊的2秒長片段上。TVSum包括10個領域,每個領域有5個視頻。我們按照傳統隨機0.8/0.2的比例進行訓練和測試。
2.2 評定方法
該實驗使用了IoU閾值為0.5和0.7的Recall@1、IoU閾值為0.5和0.75 的平均精度(mAP)以及一系列IoU 閾值[0.5:0.05:0.95]的平均mAP來進行檢索。這些方法衡量摘要效果都是分數越高該方法摘要效果越好。
2.3 對比實驗
2.4 消融實驗
從表4得知,通過預訓練得到的文本模態,確實有更好的表現。
3 結束語
本文提出一種基于多模態特征融合的自動剪輯算法。該模型分別通過單模態特征提取、跨模態特征融合、中心點和窗口的片段選取進一步提高準確度。在QVHighlight 和TvSum數據集下的實驗結果證明,本文提出的MFFAC視頻自動剪輯算法優于其他同類型的算法。
