聚合近似最近鄰殘差向量描述符
2024-10-23 00:00:00陶勇余久久
電腦知識與技術 2024年25期
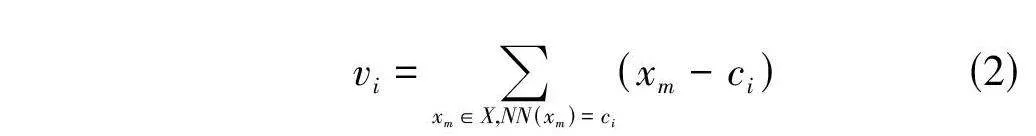




關鍵詞:圖像檢索;圖像描述符;近似最近鄰向量;殘差向量;碼書訓練
中圖分類號:TP18 文獻標識碼:A
文章編號:1009-3044(2024)25-0036-04
0 引言
基于內容的圖像檢索(Content-Based Image Re?trieval,CBIR) 在計算機視覺領域引起了廣泛關注,這是由于人們對網絡上多媒體數據的興趣日益濃厚。此外,由于每天上傳的圖像和視頻數量龐大,因此存在許多相似或接近重復的圖像,視覺搜索、電子商務、版權保護和圖像標注等應用都對基于內容的圖像檢索提出了更高的需求。
在視覺特征工程時期的圖像檢索一般采用單一描述圖像特征的描述符,如紋理特征、顏色直方圖等。這一時期提出的描述符為早期的圖像表示作出了很大貢獻,為圖像描述符研究提供了方向和思路。如統計圖像局部區域的梯度方向直方圖描述符[1]、描述局部紋理的描述符[2],以及面向稠密特征提取的描述符[3]等。在此基礎上,研究者將方向梯度直方圖和局部二值模式結合,形成新的描述符[4],大幅提升了描述符用于圖像檢索的準確度。按照描述符提取方式,可以將描述符劃分為局部特征描述符和全局特征描述符。局部特征描述符關注的是圖像細粒度更高的局部特征,判別不同圖像往往根據其局部細微差別。因此,研究者們沿著這一方向不斷突破,提出了一系列局部特征描述符以執行計算機視覺方面的任務。其中,一種尺度不變性局部特征描述符(Scale Invariant FeatureTransform,SIFT) [5]具有生成速度快、表征能力強的優點。該描述符的維度適中,可大大減輕存儲壓力;能快速檢索匹配,且可提取圖像局部特征點的位置、尺度、旋轉角度等關鍵信息,在視角變化、光線強度和噪聲干擾的影響下仍能保持較高的穩定性,在大規模圖像數據集的檢索與識別任務中被廣泛使用。在此描述符的基礎上繼續研究,Bay等[6]使用Haar小波來近似SIFT方法中的梯度操作,提出了一種性能與SIFT 相當但速度更快的SURF特征。
隨著圖像規模的增大,局部特征描述符的弊端也逐漸顯現。局部特征生成的圖像描述符在進行圖像檢索時會因圖像規模龐大而導致維度爆炸災難,給計算機的存儲和查詢帶來很大的負擔。研究者通過對局部描述符進行加工,生成了一種維度小、表示能力強的圖像全局描述符(Vector of Locally Aggregated De?scriptor, VLAD) [7],利用局部特征在訓練類心的殘差和近似表示局部特征,基于聚類中心串聯所有殘差和形成圖像的全局表示向量。生成的全局描述符僅使用隸屬于聚類中心的殘差向量進行圖像檢索,就能獲得較高的檢索精度,較大程度減小了運算和存儲的開銷。
隨著機器學習與深度學習的研究興起,通過卷積神經網絡學習圖像的深度特征所形成的局部和全局描述符在計算機視覺領域被廣泛應用。針對圖像檢索任務,經過改進的基于YOLO的神經網絡被用于船舶圖像的檢索識別[8],結合深度哈希算法與注意力機制的花卉圖像檢索在公開數據集Oxford 17 Flowers上表現突出[9]。王彪等[10]微調VGG16網絡,優化損失函數后采用遷移學習的方式生成面料特征,所開發的面料檢索系統性能優秀。大量研究文獻證明,深度卷積神經網絡能夠有效學習圖像特征,為計算機視覺的發展提供了方向,并在人工智能領域被廣泛應用。相比于深度學習的特征描述符,傳統手工特征的生成速度快,構造方式簡單,且在一定場景的檢索識別任務中仍能滿足檢索精度要求,進而被深入研究。
基于聚合局部殘差的描述符(Vector of Locally Ag?gregated Descriptor, VLAD) [7]能夠全局表示圖像,有效區別圖像的差異特征,且訓練速度快,計算開銷不高,在檢索和識別任務中不斷被改進和使用。本文結合該描述符的研究基礎,分析聚類中心的空間分布位置,改進聚類中心的選擇方式,引入均值等分向量以近似最近鄰的聚類中心累積殘差向量。生成的描述符被命名為近似最近鄰類心圖像描述符(ApproximateNearest Neighbor Centroid,ANNC-VLAD) 。改進的描述符重新定義了每個局部特征的最近鄰類心,從空間距離上說明近似的最近鄰類心擁有更接近的特征表示,證明了描述符性能提升的可靠性。
1 聚合局部殘差和的特征描述符VLAD
VLAD(Vector of Locally Aggregated Descriptors) 算法由Jégou等[7]提出,是一種通過聚合局部特征與聚類中心的殘差來表示圖像全局特征的描述符算法。該算法可以分為三個階段:訓練碼書、計算殘差向量和累積殘差。
2 近似最近鄰類心圖像描述符ANNC-VLAD
研究聚合局部殘差的描述符VLAD時發現,描述符的性能與碼書的大小相關。聚類中心數量越多,描述符的維度越大,檢索精度越高。然而,聚類中心的訓練需要時間,數量越多訓練時間越長,且描述符的維度越高,歐式距離運算的匹配速度越慢,也會增加存儲壓力。因此,在保證維度一定的情況下,提高描述符的精度是研究的目標。本文提出了一種利用近似最近鄰聚類中心生成的圖像描述符方法,在空間中找到每個局部特征歐式距離比最近鄰類心更近的一個向量。此向量并不是通過訓練得到的,即圖像描述符ANNC-VLAD選擇的是空間中比聚類中心歐氏距離更近的向量來計算殘差,該向量被命名為近似最近鄰向量。同時,為了不增加累積殘差的計算量,將殘差向量累積在隸屬于最近鄰的聚類中心。因此,該描述符不需要訓練更多的聚類中心,碼書生成速度快,計算的描述符維度緊湊,且在平均檢索精度上具有一定的優勢。
3 實驗
在INRIA Holidays [7]、UKBench [11] 和Holidays_Flickr1M [7]三個國際公開的圖像檢索數據集上測試ANNC-VLAD描述符的性能,并與VLAD描述符進行比較。
3.1 數據集的介紹
INRIA Holidays 數據集包含1 491 張圖片,其中500張用于查詢,其余991張作為查詢圖片的關聯圖片。利用平均檢索精度(mean average precision, mAP) 作為該數據集的評價指標。UKBench數據集由2 550 個物品分別從4個不同角度拍攝的10 200張圖片組成,分辨率為640×480,采用查全率Recall@4作為該數據集的評價指標。每個物體抽取一張圖像作為查詢圖像,數據集所有圖片作為圖像庫,從中找尋關聯圖片。
3.2 聚類中心數目對檢索結果的影響
本節實驗對比了VLAD描述符與近似最近鄰類心圖像描述符ANNC-VLAD在不同數目的聚類中心時,在兩個數據集上的平均檢索結果。實驗顯示,訓練更多的聚類中心,可以將特征的聚類空間劃分得更為細致,保留的局部特征的類別數目越多,兩種描述符的性能越好。然而,從描述符的形成過程和聚類中心的訓練方法來看,類心數目的增加會帶來更大的開銷,形成的描述符維度越大。存儲類心向量與近似最近鄰向量的殘差向量所需的空間越大,同時描述符維度越高,相似性計算也更耗時。
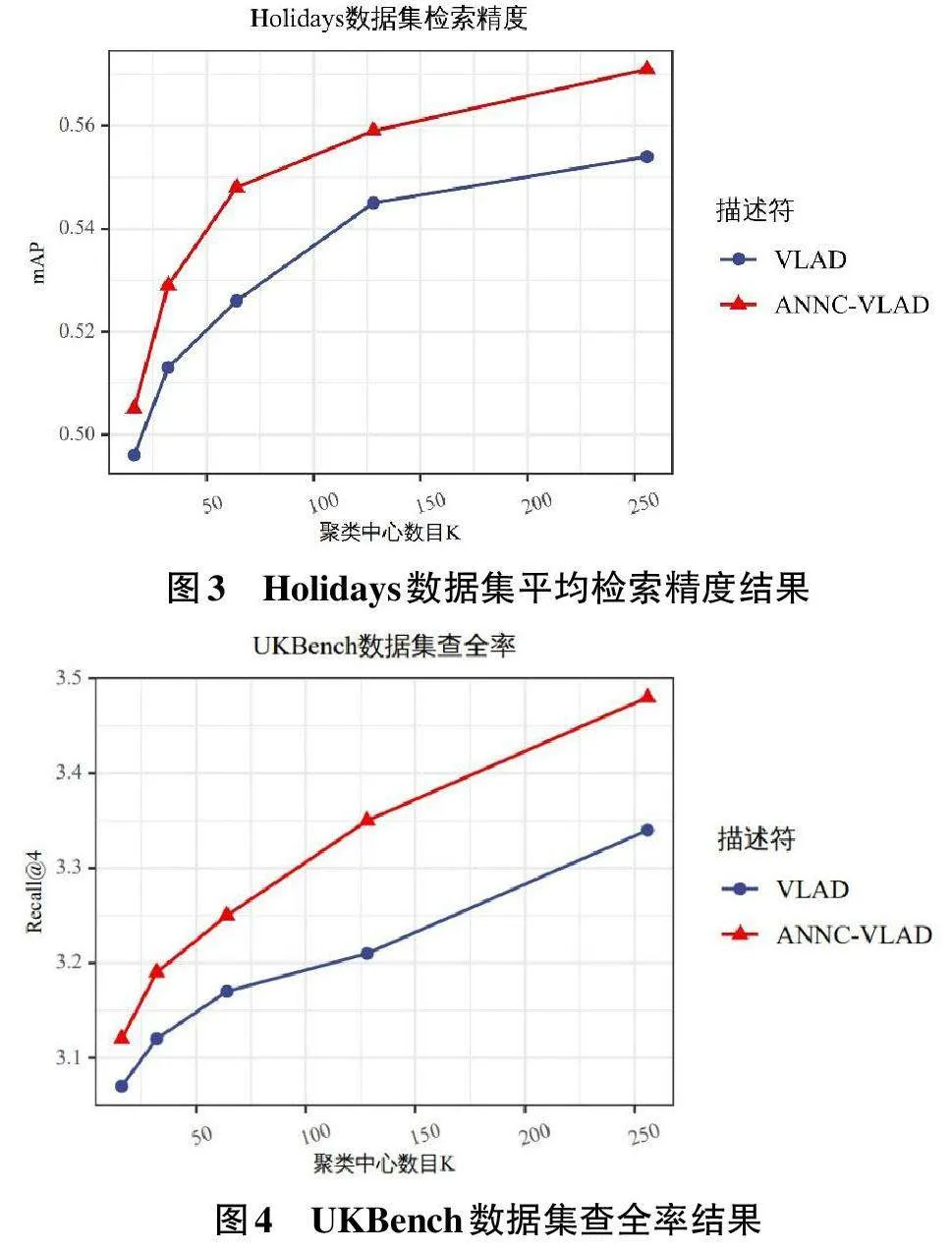
為更好地比較分析描述符的性能,本節實驗在訓練相同數據集時,使用相同的聚類中心數目對兩種描述符進行檢索驗證,即K=16、32、64、128、256。繼續增大聚類中心數目后,描述符性能提升效果并不明顯,且訓練時間成本和檢索成本會大幅提升,不滿足圖像數據集即時檢索的需求。圖3展示了兩種描述符在Holidays數據集上的平均檢索精度的比較,圖4展示了兩種描述符在UKBench數據集的平均查全率的比較。
結果顯示,兩種描述符在訓練相同的聚類中心時,描述符向量維度一致。本文提出的聚合近似最近鄰殘差向量的圖像描述符ANNC-VLAD在Holidays數據集上的平均檢索精度和UKBench數據集的查全率均優于聚合局部特征殘差的描述符VLAD,且隨著訓練聚類中心數目的增大,ANNC-VLAD與VLAD描述符的性能都有一定的提升。
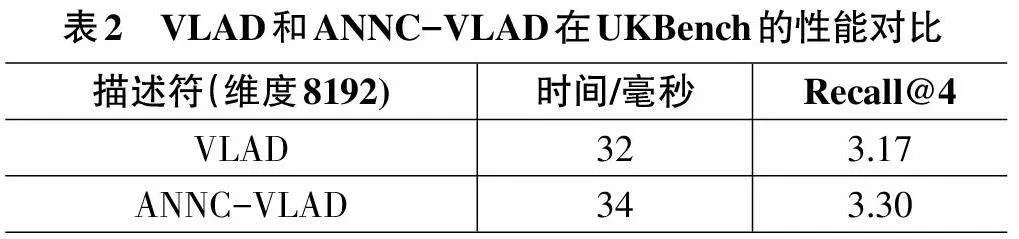
3.3 ANNC-VLAD 和VLAD 的開銷比較
訓練碼書階段,兩種描述符訓練相同大小的碼書,且訓練方法相同,因此碼書的生成時間一致。在計算描述符向量時,由于ANNC-VLAD描述符需要使用K近鄰算法找到最近鄰和次近鄰碼字,并通過這兩個碼字計算四分之一點作為候選近似最近鄰向量,此過程略微增加了計算量。因此,在兩個數據集上的計算開銷略微增大,但在合適維度下仍能較快給出響應結果,并提升描述符的性能。在保證碼書大小均為64 且描述符的維度均為8192維時,對兩種描述符的生成時間進行測試,表1與表2分別列出了在兩個數據集下描述符的檢索結果和生成時間。由于數據集圖像的分辨率大小不同,Holidays數據集是高清圖像,平均整體生成時間比UKBench數據集圖片生成時間略長,但總體上,兩種描述符都能滿足大規模圖像檢索的快速召回要求。
4 結論
本文基于聚合局部殘差描述符VLAD算法,在進行K近鄰量化特征時,通過計算局部特征的最近鄰碼字和次近鄰碼字的四分之一等分向量來獲得近似最近鄰向量。然后,將近似最近鄰向量與最近鄰碼字比較歐式距離,以決定量化局部特征的選擇。通過使用近似最近鄰向量來累積殘差,這一方法減小了最近鄰碼字在量化特征時產生的誤差損失。通過國際公開的檢索數據集驗證了描述符性能的提升效果。當碼書大小均為64 時,近似最近鄰向量殘差描述符在Holidays數據集上的平均檢索精度相比VLAD描述符提升了4.18%,在UKBench數據集上的查全率提升了4.10%,證明了該改進描述符的可行性。
