基于案例推理的通用案例檢索模型研究
2024-10-23 00:00:00張潔葉穎張洪勝方厚加
電腦知識(shí)與技術(shù) 2024年25期





關(guān)鍵詞:案例推理;文本詞頻;檢索模型
中圖分類(lèi)號(hào):TP391 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2024)25-0011-05
0 引言
案例推理(Case-Based Reasoning, CBR) 技術(shù)起源于美國(guó)耶魯大學(xué)Roger Schank 于1982 年在其專(zhuān)著《Dynamic Memory》中的描述,是人工智能領(lǐng)域中較新興的一種重要的基于知識(shí)的問(wèn)題求解和學(xué)習(xí)方法[1-10]。隨著人們對(duì)CBR研究的不斷深入,CBR的應(yīng)用領(lǐng)域不斷拓寬,已涉及機(jī)器故障診斷、醫(yī)藥醫(yī)療診斷、企業(yè)咨詢(xún)決策、法律案例評(píng)估和天氣預(yù)報(bào)等多個(gè)領(lǐng)域。因此,程序設(shè)計(jì)者難以獲取并表達(dá)專(zhuān)業(yè)知識(shí)的問(wèn)題日益突出,因此,對(duì)基于案例推理的通用案例檢索模型的需求不斷上升。
1 基于案例推理的通用案例檢索模型框架
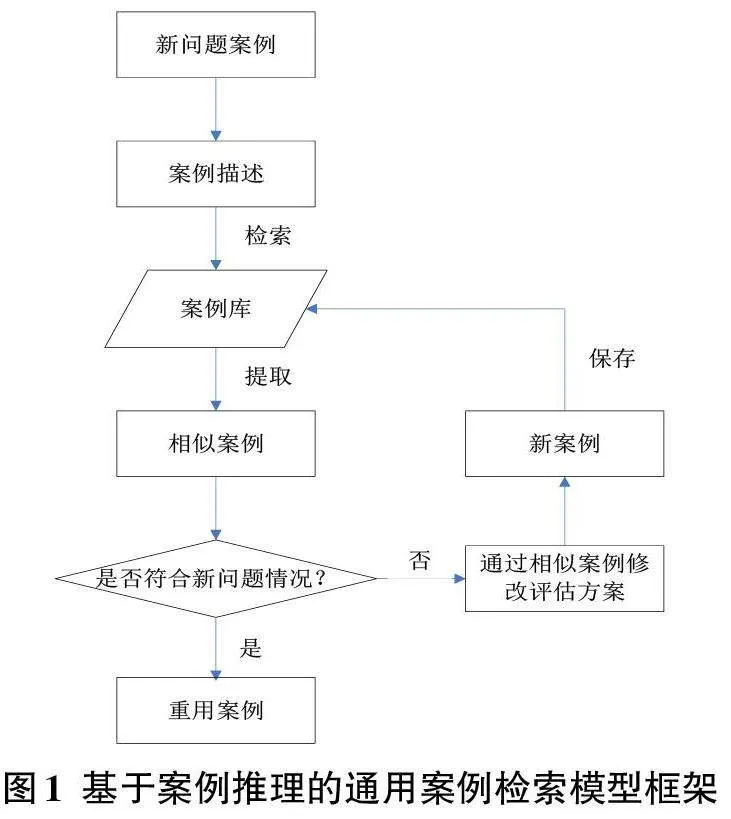
通過(guò)對(duì)不同領(lǐng)域中引入案例推理技術(shù)進(jìn)行案例檢索的比較,提出一個(gè)基于案例推理的共用案例檢索模型框架,如圖1所示。
在基于案例推理的通用案例檢索模型中,首先要對(duì)案例進(jìn)行標(biāo)準(zhǔn)化描述,以特征向量的形式來(lái)映射各屬性,通過(guò)檢索來(lái)查找案例庫(kù)中與新問(wèn)題案例最接近的匹配案例。如果找到相同或相似度在閾值范圍內(nèi)的案例,則可以直接重用舊案例的知識(shí);否則,根據(jù)最相似的若干匹配案例重新修改評(píng)估方案,形成新案例,并將其保存進(jìn)入案例庫(kù)。
2 基于案例推理的通用案例檢索模型關(guān)鍵技術(shù)
案例推理過(guò)程主要包括案例知識(shí)表示、案例檢索、案例重用/案例修改以及案例學(xué)習(xí)4個(gè)關(guān)鍵技術(shù)。
2.1 案例知識(shí)表示
隨著社會(huì)經(jīng)濟(jì)的發(fā)展、CBR研究的不斷深入以及數(shù)據(jù)量的急劇增加,CBR的應(yīng)用領(lǐng)域越來(lái)越廣泛。但在使用CBR之前,首先要進(jìn)行數(shù)據(jù)的清洗和整理。我國(guó)各行各業(yè)各個(gè)機(jī)構(gòu)都存有大量的可用數(shù)據(jù),但由于地方性差異,很多數(shù)據(jù)除了在時(shí)間aqNyNxllI03MFKOajguWkQ==和空間上分散外,還存在存儲(chǔ)結(jié)構(gòu)、評(píng)價(jià)內(nèi)容和屬性特征等方面的差異,因此很多數(shù)據(jù)很難在同一個(gè)平臺(tái)上進(jìn)行比較。
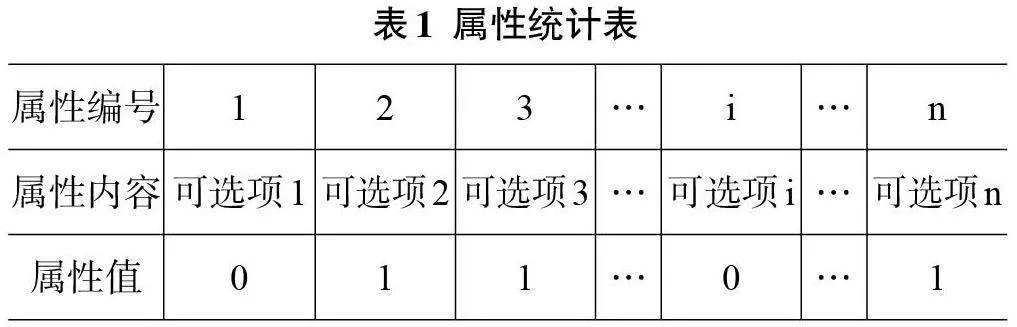
在這里,筆者借助布爾型特征向量來(lái)進(jìn)行案例知識(shí)的表示。由于不同領(lǐng)域的評(píng)估側(cè)重點(diǎn)不同,且數(shù)據(jù)大多為非結(jié)構(gòu)化數(shù)據(jù)。因此,首先建立一個(gè)屬性統(tǒng)計(jì)表,即將某些行業(yè)某些領(lǐng)域的評(píng)估指標(biāo)進(jìn)行整合,并分解為一些可選項(xiàng)。并建立如表1所示的屬性統(tǒng)計(jì)表。
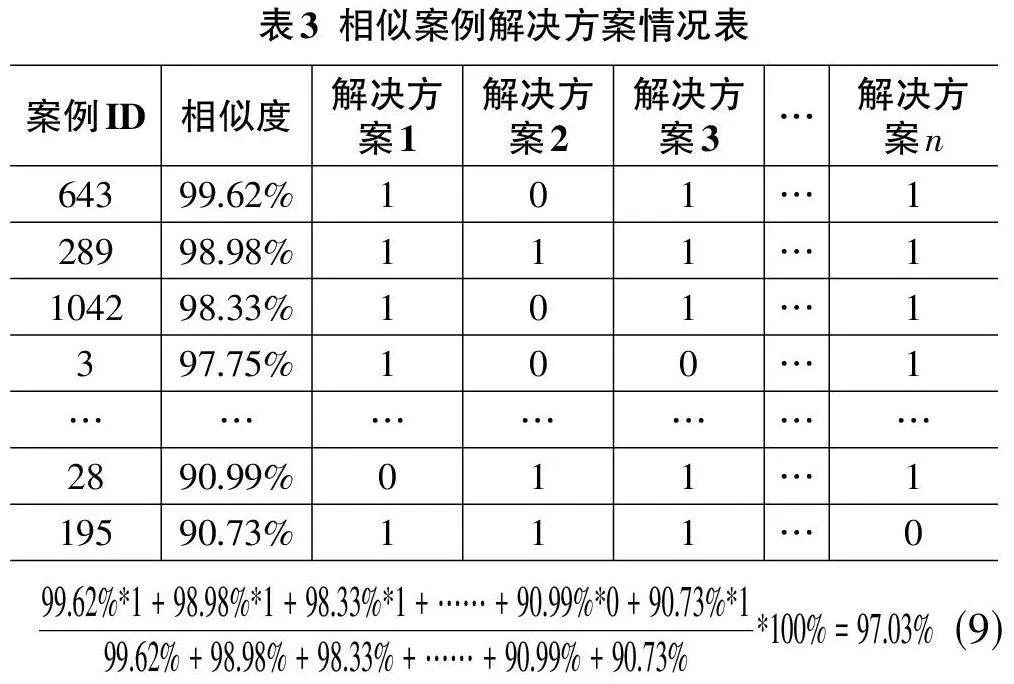
假設(shè)在案例庫(kù)中,所有案例的診療方案經(jīng)過(guò)綜合并分解后,可得到n 條可選的布爾型解決方案。通過(guò)案例檢索,我們找到了與當(dāng)前未知案例情況最相似的前50條相似案例,其相似案例與新案例的相似度及相似案例的解決方案如表3所示:
當(dāng)新案例的所有解決方案采用率都計(jì)算出來(lái),并經(jīng)過(guò)人工干預(yù)給出案例采用率的閾值后,新案例的解決方案即可確定。例如:經(jīng)過(guò)人工干預(yù),設(shè)定解決方案采用率在95%以上的為必要解決方案,新案例解決方案采用率在80%~95%為可選解決方案,新案例解決方案采用率在60%~80%為參考解決方案等。即如果新案例的某個(gè)解決方案采用率大于等于95%,則直接作為新案例的解決方案;若該解決方案采用率在80%~95%,則作為新案例的推薦解決方案;若該解決方案采用率在60%~80%,則作為新案例的可選解決方案,而采用率小于60%的解決方案則不推薦給用戶(hù)使用。由此可以得到新案例的個(gè)性化輔助決策方案,對(duì)于推薦和可選方案,可以將采用率附在后面,為用戶(hù)決策提供參考。
2.4 案例學(xué)習(xí)
在案例個(gè)性化干預(yù)過(guò)程中,除了提供新案例的輔助決策方案之外,還可以用于擴(kuò)充案例庫(kù)。如果在案例相似度檢索過(guò)程中,新案例與案例庫(kù)中的案例相似度均低于某個(gè)閾值(例如:相似度均低于95%) ,則新案例的輔助決策案經(jīng)過(guò)人工干預(yù)后可以作為案例庫(kù)的新案例被添加到案例庫(kù)中。通過(guò)這樣的不斷操作,逐步完善案例庫(kù)。當(dāng)新的案例加入案例庫(kù)中時(shí),整個(gè)案例庫(kù)的權(quán)重向量需要進(jìn)行調(diào)整。權(quán)重向量中的每一個(gè)權(quán)重均是通過(guò)log(D/Di)計(jì)算得出。
3 方法測(cè)試
為了驗(yàn)證本文所提出的基于案例推理的通用案例檢索模型的準(zhǔn)確性,選用Visual Studio 2010作為開(kāi)發(fā)平臺(tái),C#為開(kāi)發(fā)語(yǔ)言,案例保存在SQL Server 2010中,對(duì)方法的準(zhǔn)確性進(jìn)行簡(jiǎn)單測(cè)試。
在測(cè)試過(guò)程中,模擬了1500條老年人健康評(píng)估案例,其中1300條為訓(xùn)練案例,200條為測(cè)試案例。在測(cè)試中,我們首先根據(jù)調(diào)研來(lái)的案例建立了如下表4所示的老年人健康評(píng)估表。
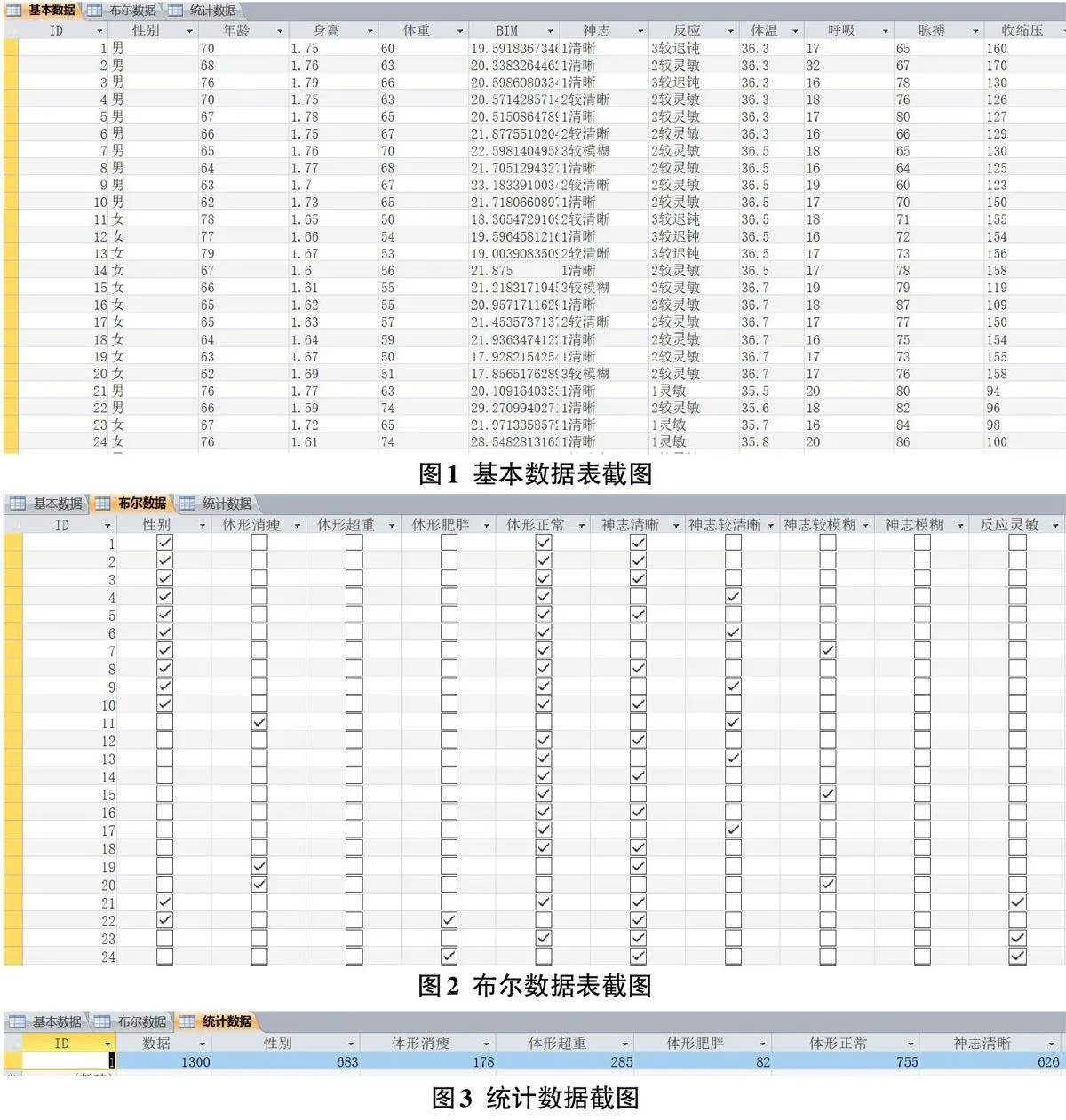
隨后,我們根據(jù)訓(xùn)練案例及相應(yīng)的測(cè)評(píng)標(biāo)準(zhǔn),在SQL Server 2010中建立了一個(gè)包含24個(gè)屬性(不包括診斷結(jié)果或結(jié)局方案屬性)、1300個(gè)元組的基本數(shù)據(jù)表,如圖1所示。
通過(guò)對(duì)屬性進(jìn)行分類(lèi),建立了一個(gè)包含82個(gè)分類(lèi)屬性的布爾型數(shù)據(jù)表,如圖2所示。
根據(jù)對(duì)分類(lèi)屬性的統(tǒng)計(jì)結(jié)果(如圖3所示),我們可以計(jì)算出每個(gè)分類(lèi)屬性的權(quán)重,如表5所示。
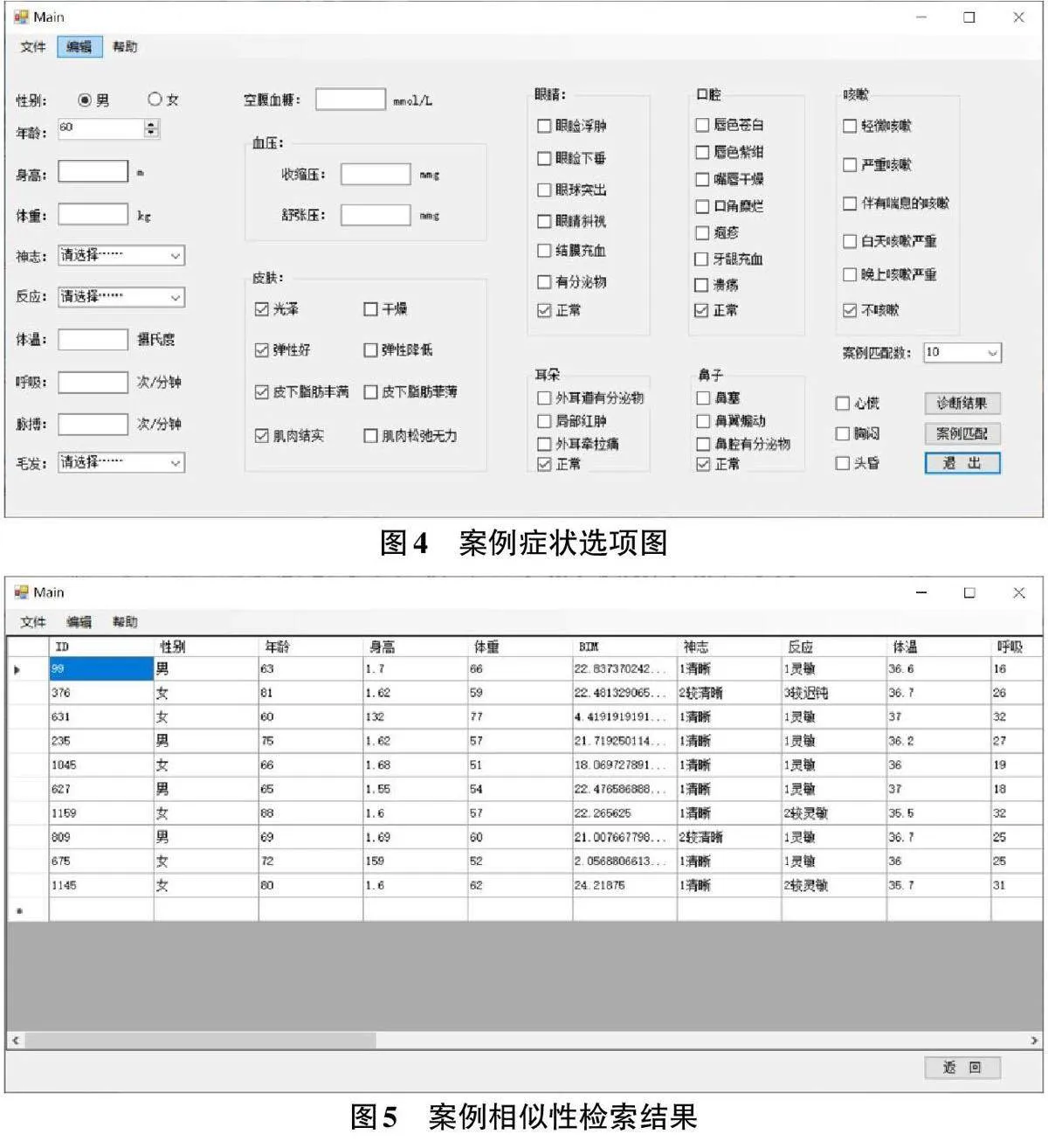
完成以上準(zhǔn)備工作后,即可根據(jù)圖4所示的案例癥狀選項(xiàng)圖對(duì)新案例的癥狀進(jìn)行描述。
描述后的案例將被表示為帶權(quán)向量,并與案例庫(kù)中的案例進(jìn)行相似度檢索,檢索結(jié)果如圖5所示。
測(cè)試結(jié)果顯示,案例檢索的準(zhǔn)確性在90%以上。
4 結(jié)束語(yǔ)
本文提出了一種基于案例推理的通用案例檢索模型,并介紹了推理過(guò)程中的幾個(gè)關(guān)鍵技術(shù)。該模型具有通用性,在應(yīng)用過(guò)程中只需將案例屬性進(jìn)行轉(zhuǎn)換,對(duì)應(yīng)到模型中的相關(guān)屬性上即可進(jìn)行案例推理。例如:在測(cè)試過(guò)程中,我們將健康指標(biāo)對(duì)應(yīng)為相應(yīng)屬性,從而將該通用模型轉(zhuǎn)化為老年人健康評(píng)估模型。此外,該模型的建立方法簡(jiǎn)單易懂,且實(shí)現(xiàn)較為簡(jiǎn)單,經(jīng)過(guò)實(shí)驗(yàn)驗(yàn)證,具有較高的準(zhǔn)確性。然而,此次測(cè)試僅單純驗(yàn)證了方法的準(zhǔn)確性,其在實(shí)際系統(tǒng)應(yīng)用中的有效性尚待檢驗(yàn),并且在幾個(gè)關(guān)鍵技術(shù)上仍有一些問(wèn)題需要解決。
首先,通過(guò)將各個(gè)案例整合并分解為一個(gè)個(gè)可選項(xiàng)的方法進(jìn)行案例知識(shí)表示。這種知識(shí)表示方法簡(jiǎn)單易行,適用于大多數(shù)可選項(xiàng),但對(duì)于一些有參考數(shù)據(jù)的指標(biāo)(例如數(shù)值型、文本型等),其適用性較差。
其次,在用特征向量表示知識(shí)時(shí),由于所分解的多個(gè)可選項(xiàng)常常是一個(gè)指標(biāo)中分解出來(lái)的,因此在同一案例中只能選擇一項(xiàng),結(jié)果是所用的特征向量實(shí)際上是一個(gè)稀疏向量。此外,案例重用技術(shù)中提到的閾值t 也需要專(zhuān)業(yè)人士進(jìn)行設(shè)定,這無(wú)疑增加了人工干預(yù)的程度。因此,在實(shí)際應(yīng)用中,如何在保證有效性的基礎(chǔ)上通過(guò)稀疏矩陣的運(yùn)算法則簡(jiǎn)化現(xiàn)有算法,以及如何盡可能降低人工干預(yù)的程度以提高工作效率,都是今后的研究方向之一。
最后,算法應(yīng)用過(guò)程中的有效性與案例庫(kù)的大小相關(guān)。然而,隨著案例庫(kù)的不斷擴(kuò)張,案例相似度檢索將會(huì)變得越來(lái)越復(fù)雜。因此,提高算法效率也是今后研究的一個(gè)方向。

- 電腦知識(shí)與技術(shù)的其它文章
- 人工智能時(shí)代背景下ChatGPT輔助JavaEE應(yīng)用開(kāi)發(fā)課程教學(xué)探索
- 智慧教育背景下師范生信息技術(shù)應(yīng)用能力培養(yǎng)策略研究
- 高職院校移動(dòng)互聯(lián)專(zhuān)業(yè)專(zhuān)創(chuàng)融合課程建設(shè)與實(shí)踐探索
- 人工智能時(shí)代下的數(shù)字圖像處理課程教學(xué)改革研究
- 一流專(zhuān)業(yè)引領(lǐng)下的計(jì)算機(jī)專(zhuān)業(yè)人才培養(yǎng)質(zhì)量評(píng)價(jià)系統(tǒng)構(gòu)建與應(yīng)用
- 基于信息化與項(xiàng)目化相融合的電子工程課程教學(xué)改革探索