基于圖神經網絡的苦味分子預測方法研究
2024-10-23 00:00:00顏淑婷陳佳彤周小露鄧偉紀凱麗劉惠瓊
電腦知識與技術 2024年25期


關鍵詞:苦味分子;圖神經網絡;GIN;食品開發(fā);制藥工程
中圖分類號:TP183 文獻標識碼:A
文章編號:1009-3044(2024)25-0005-03
0 引言
味覺是影響消費者選擇食物的關鍵因素。苦味常被定義為一種不愉快的味道,其產生源于苦味分子與受體的相互作用。許多苦味物質被認為是有毒化合物,苦味的感知可能與機體進化的預警系統(tǒng)有關,該系統(tǒng)通過防止攝入高濃度有毒化合物,避免對機體產生不良影響。因此,在食品和制藥行業(yè),預測苦味劑和構建識別人類苦味受體的平臺具有重要的研究意義。
與甜味預測主要集中于甜度不同,苦味預測的分類模型更側重區(qū)分苦味和非苦味分子。苦味分子具有高度可變的化學結構,包括生物堿、多酚、多肽、鹽、脂肪酸和皂苷[1]。前期研究主要利用分子特征符,結合機器學習或深度學習進行苦味預測,這需要深厚的藥物化學背景及對分子特征符的大量篩選。
圖神經網絡(Graph Neural Network, GNN) 已成為一種強大的深度學習(Deep Learning, DL) 模型,尤其在預測分子性質和相互作用方面[2]。GNN被廣泛應用于分子性質的回歸任務,例如溶解度、親脂性、滲透性等,并在藥物靶標聯(lián)系等分類任務中有出色表現[3]。Liu等[4]使用定向消息傳遞神經網絡(Directed MessagePassing Neural Networks, D-MPNN) 篩選出化學結構新穎的新型抗生素,其藥理性質表現為廣譜抗生素。
本文首次利用圖神經網絡模型進行苦味分子的預測。與基于特征符的機器學習或神經網絡方法相比,圖神經網絡因其在分子表征中的節(jié)點和邊的天然優(yōu)勢,免去了分子特征符的篩選與優(yōu)化。構建的四種圖神經網絡模型在識別的精準度上相較于前期研究均有提升,表明圖神經網絡在苦味預測中的優(yōu)越性和合理性。
1 算法設計
1.1 實驗數據
實驗數據主要來源于BitterDB、Fenaroli′s口味手冊和Rojas數據庫[5]。由于不同軟件對SMILES格式處理的差異,實驗中使用RDKit 讀取分子并統(tǒng)一為SMILES 標準格式,然后將數據存入MySQL,并通過SQL語句進行數據去重。最終,數據分為兩類:包含797個苦味分子,標簽為1;1 435個非苦味分子,標簽為2。采用10折交叉驗證方法進行訓練和驗證,即將數據分為10份,抽取其中9份用于訓練,余下一份用于驗證,整個過程重復10次。
1.2 實驗環(huán)境與參數設置
實驗環(huán)境基于Windows 11操作系統(tǒng),使用Python3.10.6編程語言,深度學習框架為PyTorch 2.3,圖神經網絡框架采用PyTorch Geometric 2.5.3,分子處理和分子物理參數使用RDKit 2024.03.01版本,ROC與AUC 計算使用Scikit-learn 1.4.2。運行平臺為Intel(R) Core(TM) i5-13600KF CPU和GeForce RTX 4090 Laptop GPU。
1.3 圖神經網絡模型的構建
分子由原子組成,相鄰的原子通過化學鍵連接,因此可用圖來表示,用公式表示為G = (V,E),其中V為節(jié)點集合,E為邊緣集合。分子中的每個原子被視為一個節(jié)點v ∈ V,分子的化學鍵被視為u 和v 相互連接的邊(u,v) ∈ E。
2.2 模型構建
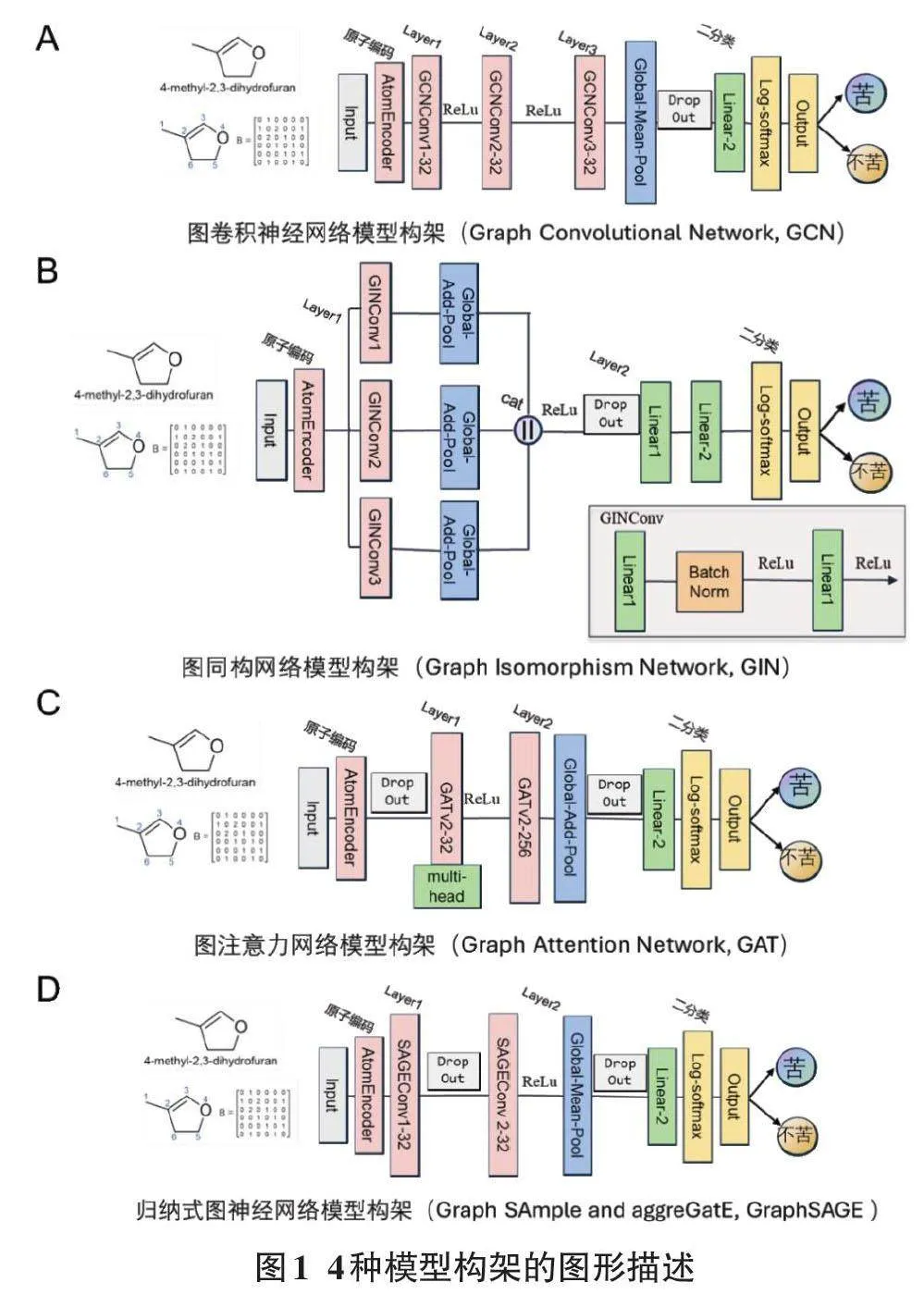
盡管現有基于機器學習的方法在預測苦味分子方面取得了良好效果,但仍存在局限性:機器學習需要仔細選擇分子特征,這是一項煩瑣且專業(yè)性很強的工作,同時難以達到最佳的預測效果。不同于傳統(tǒng)的機器學習方法,圖神經網絡能夠處理原始輸入數據,自動學習并重新分配每個特征的權重,從數據中提取高維特征。這種特性可能使其在解決上述問題時具備更優(yōu)越的性能。此外,圖神經網絡的可變性有助于靈活設計具體的模型結構。因此,本文采用圖神經網絡作為模型的關鍵算法。為了獲得更可靠的預測效果,選擇了圖神經網絡中的4種代表性模型——GCN、GIN、GAT 和 GraphSAGE 進行準確度比較,如圖1所示。分子在 SMILES 格式轉換后表現為帶有離散節(jié)點特征的類型,因此在模型輸入端使用原子編碼(AtomEncoder) 將輸入特征轉換為連續(xù)嵌入。
2.3 評估
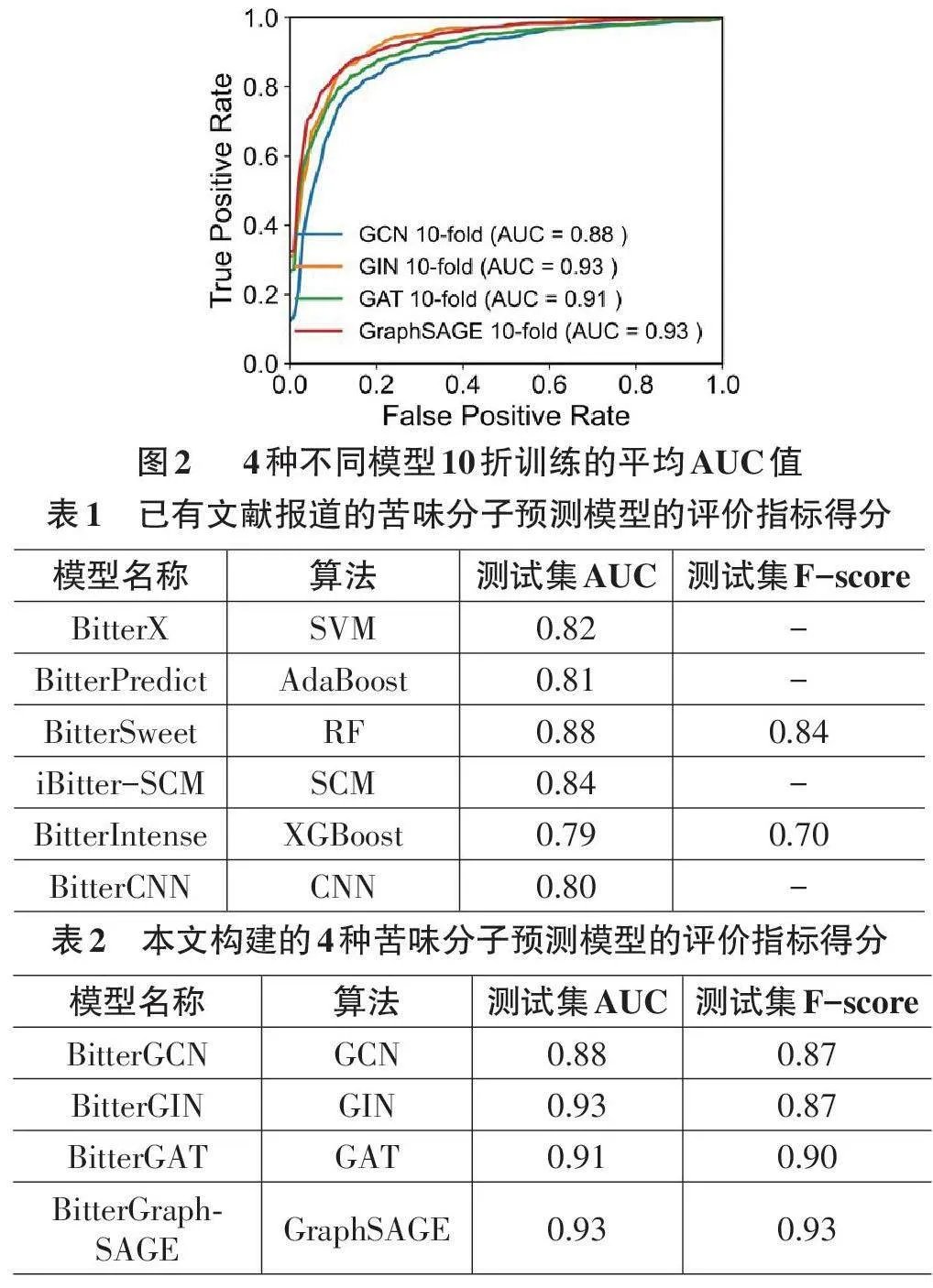
采用10折交叉驗證對4種模型進行評估,如圖2 所示,GCN、GIN、GAT、GraphSAGE等4種模型的AUC 值分別為0.88、0.93、0.91、0.93。盡管所有算法在該任務上表現良好,GIN和GraphSAGE方法顯示出最高的AUC值,這表明消息傳遞機制在基于分子的圖神經網絡中可能有最佳表現。GAT表現相對不突出可能是由于分子圖是無向圖,導致注意力機制無法發(fā)揮其最大優(yōu)勢。
苦味分子預測模型的平均指標得分如表1、表2 所示。與現有文獻所述方法相比,本文構建的4種模型在精度上均有所提高,但仍有進一步改進的空間[6-8]。研究中收集了797個正樣本和1 435個負樣本的數據集,對于圖神經網絡計算而言,這仍然是一個較小的數據集,限制了圖神經網絡從中學習更廣泛、更大規(guī)模信息的能力。此外,在基于分子的圖構建時僅提取了二維信息,而忽略了三維信息。同時,僅依靠分子識別可能缺乏對苦味分子與受體間相互作用信息的捕捉,這將成為未來研究工作的重點。
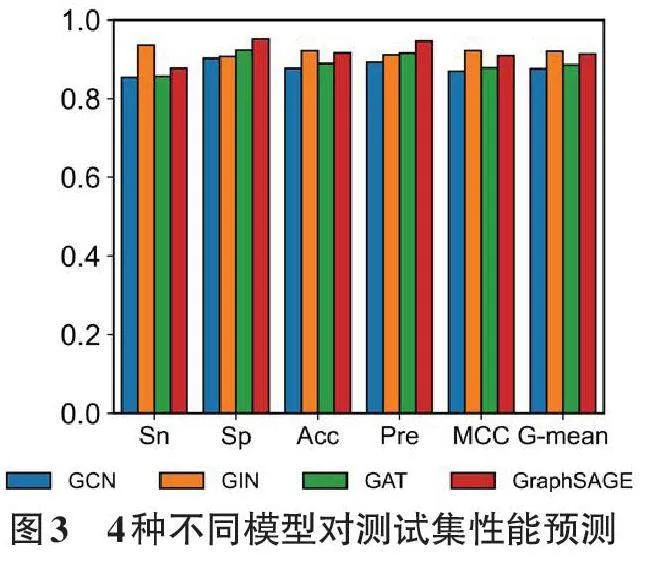
隨后,使用敏感性(Sn) 、特異性(Sp) 、準確度(Acc) 、精確率(Pre) 、馬修斯相關系數(MCC) 、幾何平均數(G-mean) 這6個指標對4種模型進行評價(如圖3 所示)。在Sn指標上,GIN模型優(yōu)于其他模型;在Sp 指標上,GraphSAGE模型表現最佳。這表明GIN模型在識別陽性(苦味)分子方面具有最好的預測精度,而GraphSAGE模型在識別陰性(非苦味)分子方面表現最佳。用戶可以根據任務需求選擇不同的模型。
例如,在兒童藥物設計中,需要排除更多的苦味分子,可以使用GraphSAGE模型;而在基于苦味受體靶點的藥物設計中,需要獲取更多的苦味分子進行深入分析,可以使用GIN模型。在其他指標方面,GIN模型也略占優(yōu)勢,因此在苦味預測任務中,GIN模型表現最優(yōu)。這個結果也可能推廣到其他分子預測模型中,為相關領域的研究提供借鑒和參考。
3 結果與討論
本文針對苦味分子的預測模型問題,提出了將圖神經網絡算法用于苦味分子的預測。與基于傳統(tǒng)機器學習或經典深度學習的方法相比,該模型無須獲取復雜的分子表征特征,從而簡化了流程,并能夠準確預測分子的苦味性質。該模型具有性價比高、準確率高、迭代次數少的優(yōu)勢。
本研究在基于苦味的食品工程和藥物設計方面,尤其是在兒童藥物設計中,具有廣闊的應用前景。通過提高苦味分子預測的準確性,可以幫助開發(fā)出更符合消費者和患者需求的產品,從而推動相關領域的發(fā)展。
