融合預訓練語言模型的知識圖譜在政務問答系統中的應用研究
2024-10-09 00:00:00張朝陽沈建輝葉偉榮
數字通信世界 2024年9期

摘要:該文針對當前政務問答系統面臨的復雜語境理解、政策法規解釋等問題,探討了如何將預訓練語言模型與知識圖譜進行有效融合,以實現更加精準、全面和個性化的政務信息問答服務,構建了政務問答系統框架,利用知識圖譜和大模型工具驗證了該方法在提高問答準確率、增強上下文理解能力方面的顯著優勢。
關鍵詞:知識圖譜;自然語言處理;預訓練語言模型;三元組;知識庫
doi:10.3969/J.ISSN.1672-7274.2024.09.063
中圖分類號:TP 3 文獻標志碼:A 文章編碼:1672-7274(2024)09-0-03
Research on the Application of Knowledge Graph Integrated with Pre-trained Language Models in Government Question-answering Systems
ZHANG Chaoyang, SHEN Jianhui, YE Weirong
(Zhejiang Public Information Industry Co., LTD., Hangzhou 310000, China)
Abstract: Aiming at the problems of complex context understanding and interpretation of policies and regulations faced by the current government question answering system, this paper discusses how to effectively integrate pre-trained language models and knowledge graphs, so as to realize more accurate, comprehensive and personalized government information question answering service. The framework of government question answering system is constructed, and the significant advantages of this method in improving the accuracy of question answering and enhancing the context understanding ability are verified by using knowledge graph and large model tools.
Keywords: knowledge graph; natural language processing; pre-trained language model; triple; knowledge base
0 引言
政務問答系統的核心在于如何更好地建模語言、理解和輸出文本信息,本文以政務服務垂直領域在線咨詢問答場景為例,探索預訓練語言模型與知識圖譜的融合應用。
1 理論基礎及相關工作
1.1 預訓練語言模型研究進展
預訓練語言模型[1]是近年來自然語言處理領域的重要突破,其核心思想是通過大規模無標簽文本數據進行自監督學習,從而獲得對語言深層次結構和語義的理解能力。2017年,谷歌團隊提出了Transformer模型。基于此,Devlin等人提出了BERT預訓練模型,極大地提高了機器閱讀理解模型的性能,BERT[2]采用了雙向Transformer編碼器,GPT系列則使用了單向Transformer解碼器。GPT-4[3]等后續模型則主要通過因果關系模型來預測下一個單詞。預訓練語言模型經歷了從ELMo[4]到BERT,再到GPT、T5、RoBERTa、ALBERT[5]等一系列迭代升級,涌現出諸多基于BERT模型的變體,如Macbert[6]、ALBERT和AMBERT等。國內科技公司和科研機構紛紛發力相繼推出了百度“文心一言”、騰訊“混元”大模型、阿里“通義千問”、華為盤古大模型、智譜清言、訊飛星火等一系列國產大模型。預訓練語言模型在數字政府領域應用場景涉及智能客服與問答、文檔理解和信息提取、輿情分析與事件監測、政務知識圖譜等。
1.2 知識圖譜在問答系統中的作用
1.2.1 政務問答系統的挑戰
政務問答系統在實現智能化即時互動的同時,面臨諸多挑戰。政務數據分布在不同部門和系統中,整合難度大。用戶咨詢的問題可能涉及復雜語境、多種表達方式,系統需具備高精度的自然語言處理能力,理解用戶的真實意圖。問答系統應能快速適應新出臺的法律條文,不斷引入AI、深度學習等前沿技術,降低維護成本并提高服務效能。
1.2.2 知識圖譜在問答系統中的作用
針對政務問答系統面臨的以上挑戰,利用知識圖譜技術能夠顯著提升問答系統的性能和智能化程度。知識圖譜提供了豐富的語義上下文和關系結構,使得問答系統能夠理解問題背后的復雜意圖,并通過關系推理來找到答案。基于知識圖譜,問答系統可以進行高效且精準的信息檢索,利用實體之間的關聯快速定位相關信息,從而給出準確的答案。
1.3 融合預訓練模型與知識圖譜的最新研究
張鶴譯[7]等提出,融合大型語言模型與專業知識庫基于提示學習的問答系統范式,并實證了該方法有助于解決專業領域問答系統數據+微調范式帶來的災難性遺忘問題。在醫學大模型BioLAMA和MedLAMA中,通過利用醫學知識圖譜來探索大語言模型中的醫學知識應用。醫療大模型華駝(本草)在參考中文醫學知識圖譜的基礎上,基于中文醫學知識的LLaMA微調模型,采用了公開和自建的中文醫學知識庫,使語言模型具備像醫生一樣的診斷能力。百度“文心一言”、通義千問等國產大模型在訓練過程中也融入了豐富的知識資源,增強了模型的知識理解和推理能力。
2 知識圖譜在政務領域的構建策略
2.1 政務知識庫
為滿足政務信息智能問答需求,需收集涵蓋各政府部門、公共服務機構及社會關注熱點的所有相關政策、法規、辦事指南、常見問題解答等信息,構建政務知識庫。統一知識條目的分類、編碼、格式等標準,便于檢索、管理和使用。
2.2 政務問答知識抽取與建模
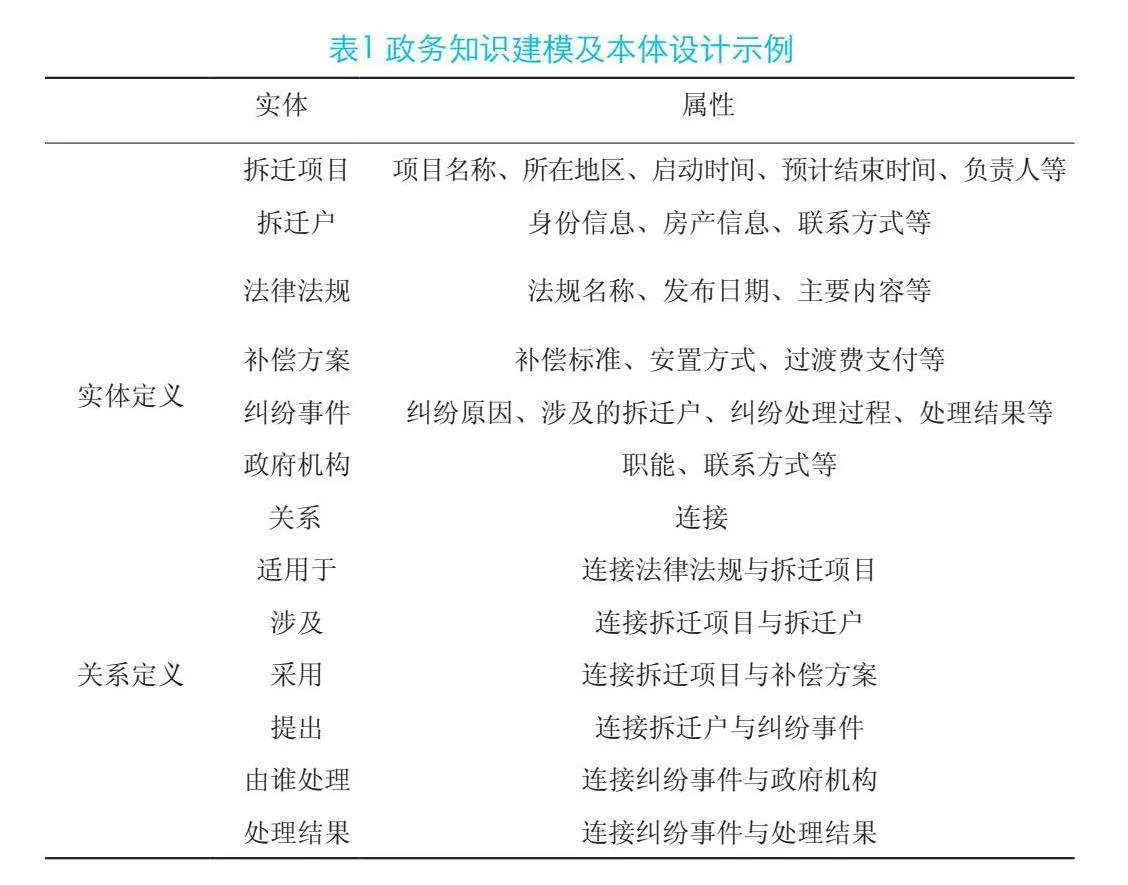
政務知識圖譜的知識建模與本體設計過程是將政務領域內的實體、屬性和關系以一種結構化和標準化的方式來表示。通過設計政務領域專屬本體,定義實體類別、屬性以及關系類型,構建適合政務場景的知識表示框架。將抽取出來的實體及其關系整合到知識圖譜中,通過鏈接和推理填補缺失信息,形成一個結構化的知識網絡,如表1所示。
3 融合大模型與知識圖譜的問答系統構建方法
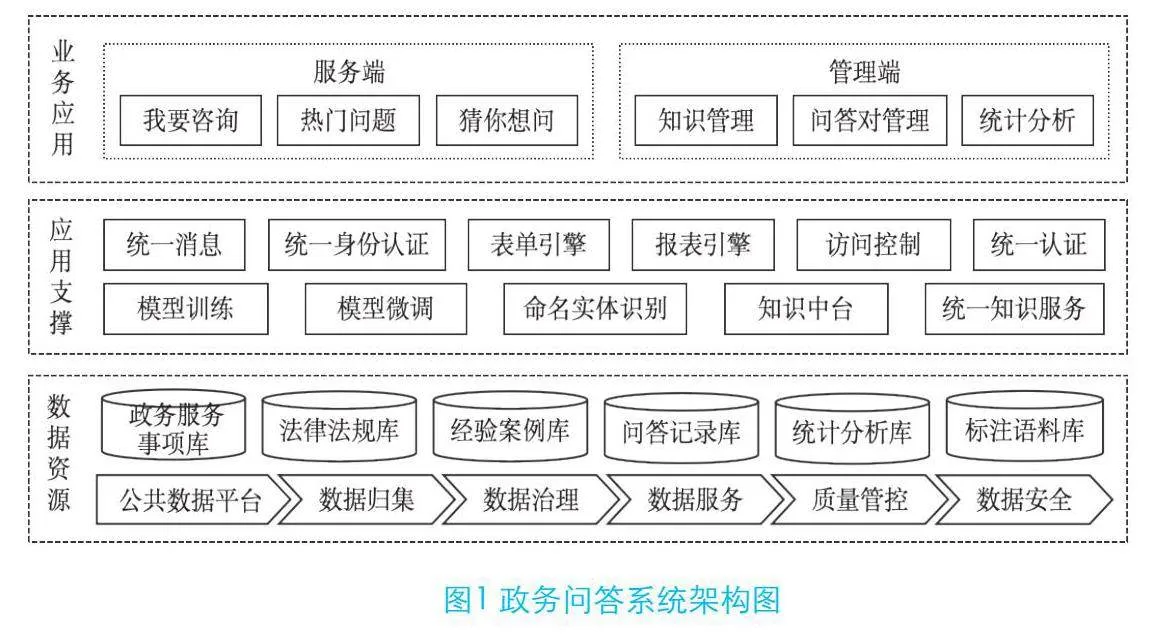
3.1 系統總體框架
政務問答系統基于政務知識庫,通過大模型和知識圖譜融合進行預訓練和微調,完成信息抽取、知識分類等任務,并通過知識推理、問答交互支撐服務端的在線咨詢交互場景。
3.2 融合預訓練模型與知識圖譜的問答機制
利用預訓練模型對政務知識進行知識抽取主要包括以下幾個主要步驟:
(1)選擇預訓練模型。大部分預訓練模型基于或參考了BERT的多層Transformer結構。標注語料經過BERT預訓練語言模型獲得相應的詞向量,之后再把詞向量輸入到BiLSTM模塊中做進一步處理,最終利用CRF模塊對BiLSTM模塊的輸出結果進行解碼,得到一個預測標注序列,然后對序列中的各個實體進行提取分類。
(2)數據集準備及預處理。數據集包括開源文本集、法規政策文件、權力事項清單、常用典型問答等,由業務專家輔以標注處理,對原始文本數據進行分詞、詞語切分、填充或截斷等預處理操作,使其符合預訓練模型的輸入格式要求。本文選擇開源中文本數據集和自有業務數據作為實驗數據,包括THUCNews數據集、MSRA數據集、PKU人民日報語料庫、法律法規、典型案例問答。
(3)模型微調。對選定的預訓練模型進行適應性訓練,加載預訓練模型權重;根據具體任務構建下游任務的模型架構,例如,在預訓練模型頂部添加額外的分類層或序列標注層,將預訓練模型應用于知識抽取任務的數據集上,通過反向傳播和優化算法更新模型參數,使模型能夠學習到抽取所需知識的規律。本文通過業務專家標注和注入專業知識庫方式增強回答的專業性。
(4)任務適配。對不同知識抽取任務進行任務適配,實體識別模型需要預測每個詞的標簽,標識出文本中的實體邊界及其類別,關系抽取模型需要同時考慮實體對及其上下文信息,預測實體之間的關系類型,事件抽取模型要識別事件觸發詞和事件角色。本文利用HanLP生成三元組數據用于構建知識圖譜,再將知識圖譜中的實體和關系轉化為向量表示,與語言模型進行融合。
(5)融合訓練、驗證及優化。將數據集劃分為訓練集、驗證集和測試集,在預訓練模型的基礎上添加知識圖譜嵌入層,讓模型在處理文本時能訪問知識圖譜中的信息。在語言模型的中間層插入知識圖譜嵌入層,使模型生成答案時考慮到知識圖譜提供的實體和關系信息。
4 實驗結果
本文選用具有62億參數的語言模型ChatGLM-6B,GeForce RTX 4090系列顯卡。將同一問題分別輸入以下三種問答工具:①基于傳統神經網絡算法的問答系統;②未注入專業知識的GLM-6B;③融合專業領域知識圖譜的GLM-6B,并根據三組輸出答案來評估相應工具的準確率、滿意度等。
綜合來看,知識圖譜能夠有效地輔助語言模型在處理問題時找到正確的答案,特別是在涉及事實性問題、領域專業知識和復雜推理的任務中,知識圖譜的作用尤為突出。
5 結束語
預訓練模型模型融合知識圖譜在政務問答系統的應用將朝著更智能、個性化、跨領域、多模態交互等方向發展,系統將能夠處理更復雜的查詢,包括多跳推理、語義理解等,結合用戶畫像和用戶歷史交互數據,政務問答系統將能夠提供更加個性化的服務。同時,政務問答系統應注重安全與隱私保護。在大模型多模態交互應用方面,有望支持多種交互方式,包括文本、語音、圖像等,提供更自然和便捷的用戶體驗。
參考文獻
[1] 王昀,胡珉,塔娜,等.大語言模型及其在政務領域的應用[J/OL].清華大學學報(自然科學版),2024,64(4):1-10.[2024-03-11]. https://doi.org/10.16511/j.cnki.qhdxxb.2023.26.042.
[2] DEVLIN J, CHANG M W, LEE K,et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Minneapolis, USA: Association for Computational Linguistics,2018:4171 4186.
[3] Openai.GPT-4 technical report [R/OL]. .https://arxiv.org/abs/2303.08774.2023.
[4] 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans, USA: Association for Computational Linguistics,2018:2227 2237.
[5] LANZZ,CHEN M D,GOODMANS,etal.ALBERT:A lite BERT for self-supervised learning of language representations[J/OL].arXiv.(2019-09-26)[2023-06-12].https://arxiv.org/abs/1909.11942.
[6] CUI Y, CHE W, LIU T, et al. Revisiting pre-trained models for Chinese natural language processing[EB/OL]. [2023-07-17]. http://arxiv.org/abs/2004.13922.
[7] 張鶴譯,王鑫,韓立帆,李釗,陳子睿.大語言模型融合知識圖譜的問答系統研究[J/OL].計算機科學與探索,2023,17(10):2377-2388.
