數據挖掘技術在計算機網絡病毒防御中的實踐應用
2024-10-09 00:00:00呂敬蘭
數字通信世界 2024年9期

摘要:隨著互聯網的普及和深入發展,計算機網絡病毒已經成為威脅網絡安全的重要因素。傳統的病毒防御方法,如防火墻、入侵檢測系統等,在面對復雜多變的網絡病毒時顯得力不從心。數據挖掘技術作為一種從海量數據中提取有用信息的方法,為計算機網絡病毒防御提供了新的思路。該文將從數據挖掘技術的原理、方法及其在計算機網絡病毒防御中的實踐應用等方面進行探討。
關鍵詞:數據挖掘;計算機網絡病毒;防御
doi:10.3969/J.ISSN.1672-7274.2024.09.048
中圖分類號:TP 393.08 文獻標志碼:B 文章編碼:1672-7274(2024)09-0-03
The Practical Application of Data Mining Technology
in Computer Network Virus Defense
LV Jinglan
(Guizhou Agricultural Vocational College, Guiyang 551403, China)
Abstract: With the popularization and in-depth development of the Internet, computer network viruses have become an important factor threatening network security. Traditional virus defense methods, such as firewalls and intrusion detection systems, appear inadequate when facing complex and ever-changing network viruses. Data mining technology, as a method of extracting useful information from massive data, provides new ideas for computer network virus defense. The article will explore the principles, methods, and practical applications of data mining technology in computer network virus defense.
Keywords: data mining; computer network viruses; defense
隨著信息時代的來臨,計算機網絡日益普及,極大地便利了數據的傳輸與分享,也為網絡病毒的傳播提供了更多的機會。網絡病毒復雜性不斷升級,使工作人員防范工作難度不斷加大。探討數據挖掘技術在計算機網絡病毒防范中的應用,能夠提升網絡安全性,有效應對不斷演變的病毒威脅[1]。
1 基于特征選擇的分類方法在病毒防御中的應用
1.1 特征選擇的概念和意義
特征選擇是機器學習和數據挖掘中的一項關鍵技術,旨在從原始數據集中挑選出最相關、最具代表性的特征子集,用于構建分類模型。在病毒防御中,特征通常指的是病毒或惡意軟件的各種靜態和動態屬性,如代碼片段、行為模式、網絡活動等。
隨著網絡技術的不斷進步,病毒和惡意軟件的復雜性也同步增長,使特征選擇技術也變得尤為重要。其不僅能顯著降低病毒數據的維度,剔除冗余信息,減少計算的復雜性和存儲需求,還能提高分類器的準確性,幫助分類器更專注于病毒行為的緊密相關特征。此外,它能夠增強模型的可解釋性,為安全專家提供更易理解的分析依據。在面對不斷變異的病毒威脅時,特征選擇有助于捕捉病毒的本質特征,保持對新型威脅的檢測能力。在實時病毒檢測中,特征選擇更是能夠優化性能,降低處理時間和資源消耗,使得實時防御成為可能,為網絡安全加固了防線。
1.2 基于特征選擇的分類方法的原理和流程
在網絡病毒防御中,特征選擇分類方法的核心思想是從大量病毒數據中篩選出最具區分能力的特征,用于訓練分類器以準確識別未知文件。這種方法強調“精益求精”,即使用少量但高質量的特征,而非全部特征,實現高效分類。通過特征選擇,進一步去除冗余和不相關的特征,降低數據維度,提高分類器的性能和效率。精心選擇的特征子集還能增強模型的可解釋性,使安全專家能夠更容易理解和信任模型的決策過程。在面對不斷演變的病毒威脅時,特征選擇的分類方法可提供一種有效的方式來保持防御系統的實時性和準確性,進而加固網絡安全的防線[2]。
1.3 實際案例分析:基于特征選擇的病毒識別模型的構建和應用
針對KDD數據集,特別是其20%的子集,特征工程的處理至關重要。由于數據集中每個樣本包含41個特征值,并且部分特征是字符型的,直接用于機器學習模型可能會導致性能不佳或結果不準確。對于KDD數據集,特別是含有字符型特征的數據,one-hot編碼常常被用于轉換這些特征,但是會導致特征空間的急劇增加,進而產生大量的冗余特征,增加計算的復雜性,導致過擬合,影響模型的泛化能力。為了有效解決這一問題,結合粒子群優化算法和決策樹的方法進行特征選擇是較為可行的方法。粒子群優化算法能夠智能地搜索特征空間,找出與輸出變量最相關的特征子集,而決策樹則能夠基于這些選定的特征構建分類模型,實現高效的檢測分類[3]。
one-hot編碼是一種將類別變量轉換為機器學習算法易于利用的格式的方法。具體來說,對于每一個字符型特征值,one-hot編碼都會創建一個新的二值特征。舉個例子,假設特征1包含“ABC”三種字符型特征值,采用one-hot編碼后,原始的特征1將被刪除,取而代之的是三個新的特征,即特征1_A、特征1_B和特征1_C。如果樣本在原始特征1上的值是A,那么在新的特征1_A上的值就是1,在特征1_B和特征1_C上的值就是0,即表示為100。同理,如果原始值是B或C,則分別表示為010和001。
經過對KDD數據集的one-hot編碼處理,雖然成功地將字符型特征轉換為數值型特征,但同時也導致特征維度的顯著增加,每個樣本的特征數由原來的41個增加到118個,增加了計算的復雜性,更重要的是其中包含大量的冗余和不相關特征,對分類器的性能產生負面影響,導致分類精度降低。為了解決這一問題,采用粒子群優化(PSO)算法進行特征選擇。PSO算法是一種模擬鳥群覓食行為的優化算法,通過粒子之間的信息共享和協作,能夠在復雜的搜索空間中找到最優解。在特征選擇中,每個粒子代表一個特征子集,通過不斷迭代更新粒子的位置和速度,搜索到一組最優特征子集,使基于這組特征子集的分類器能夠達到最高的分類精度[4]。
2 聚類分析在病毒防御中的應用
2.1 聚類分析的概念和算法
聚類分析在病毒防御中具有不可或缺的應用價值,核心理念是將相似或相關的對象集結成群,區分不同的數據模式。在網絡安全領域,它能夠高效識別網絡異常,為專家提供及時的威脅預警。具體而言,聚類分析在網絡流量監控中能夠識別不尋常的流量模式,進而揭示潛在的網絡攻擊。在惡意軟件檢測方面,聚類分析根據軟件的行為和代碼結構進行分類和識別,無論是已知還是未知的惡意軟件。此外,通過聚類分析可分析系統日志和用戶行為數據,能夠發現異常登錄和非法訪問等入侵行為。
在算法層面,聚類分析有劃分法、層次法,以及基于密度、基于網格和基于模型的方法等多種實現方法,其各有特色,適用于不同的數據和應用場景。在實際運用中,選擇哪種聚類算法取決于具體的數據特性和分析需求。可見,聚類分析憑借其強大的數據分類和模式識別能力,已成為病毒防御體系采用的關鍵技術,為網絡安全提供了有力的技術支撐。
2.2 實際案例分析:基于聚類分析的病毒家族發現與分析
Android平臺是智能手機上最流行的操作系統之一,其上有數百萬個應用程序供用戶選擇。這些應用豐富了用戶的生活,提供了便捷的服務和娛樂。然而,隨著其普及,Android手機也成為了惡意軟件的目標。由于Android允許用戶從多種來源安裝應用,如應用市場和論壇,導致惡意軟件易于傳播。根據報告,2022年惡意安裝包數量激增,是2021年的3倍多。盡管Android有權限系統限制惡意軟件的安裝,但用戶往往忽視權限請求的重要性,使這一安全措施的效果大打折扣。因此,惡意應用往往能繞過Android權限系統的限制,對用戶構成威脅。
3 關聯規則挖掘在病毒防御中的應用
3.1 關聯規則挖掘的概念和算法
在病毒防御中,項可以是網絡請求、系統調用或特定的文件操作,而頻繁出現的項集可能揭示了惡意軟件的特定行為模式。隨著網絡攻擊和惡意軟件的日益猖獗,病毒防御技術也在不斷演進。關聯規則挖掘作為一種重要的數據分析工具,被廣泛應用于識別和防御惡意行為。其中,Apriori和FP-growth是兩種代表性的算法。
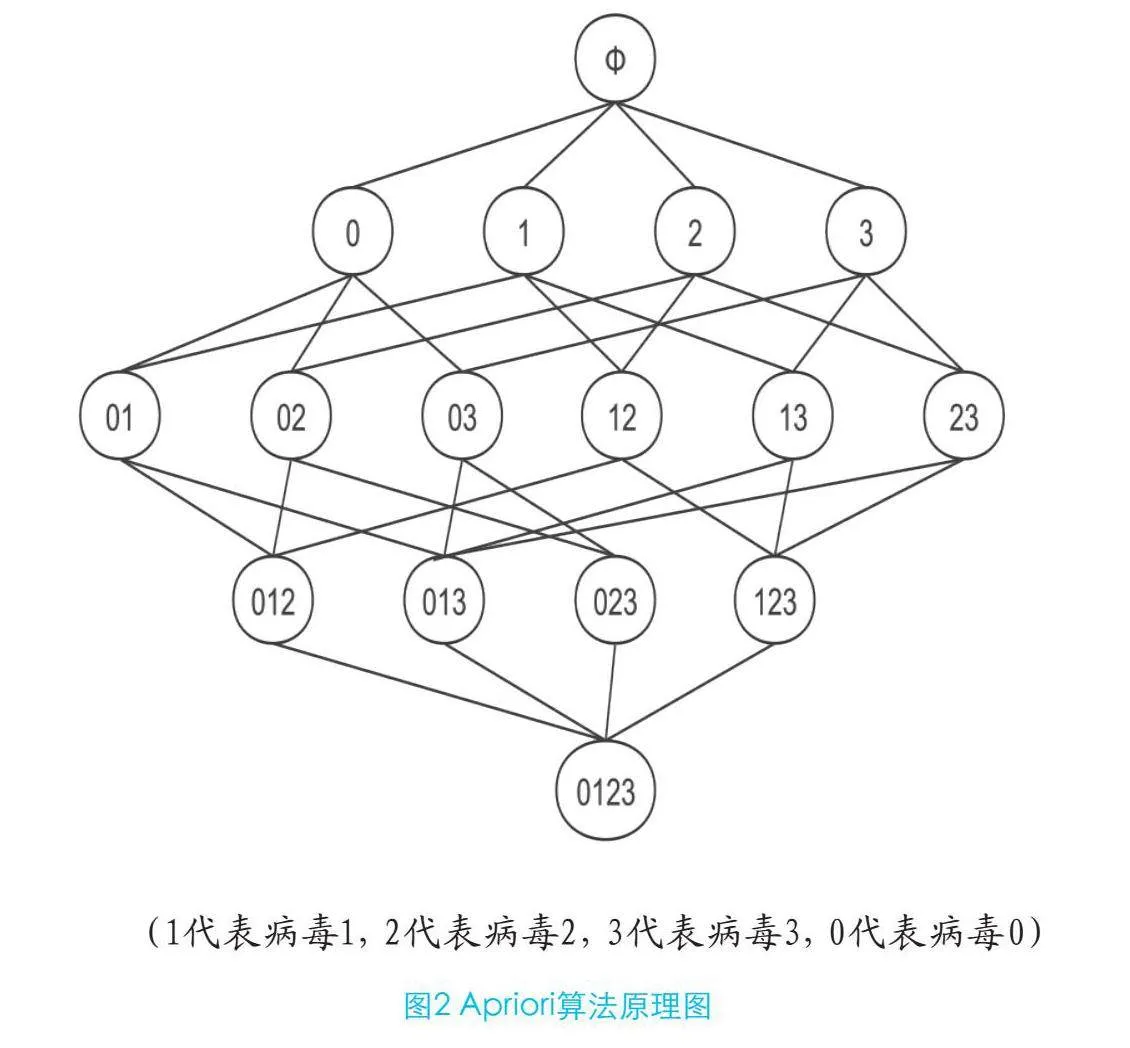
Apriori算法是關聯規則挖掘的經典之作,其工作原理是通過逐層搜索的迭代方法,從數據集中找出頻繁項集。這種方法基于一個核心性質,即如果一個項集是頻繁的,那么它的所有非空子集也必須是頻繁的。這一性質大大減少了搜索空間,提高了算法的效率。在病毒防御中,Apriori是幫助安全專家識別惡意軟件的常見行為模式,其原理如圖2所示。
在處理大量數據以尋找頻繁項集時,計算所有組合的支持度是一項巨大的任務。例如,僅考慮3個病毒,需計算15次不同組合的支持度。隨著病毒數量的增加,這種計算量將急劇上升,呈指數增長,這在計算上是非常不經濟的。
與Apriori不同,FP-growth并不直接生成候選項集,而是通過構建一棵稱為FP樹的數據結構來挖掘頻繁項集。這種方法不僅減少了數據庫掃描的次數,還通過共享前綴的方式壓縮了數據結構,從而顯著提高了算法的效率。在病毒防御中,FP-growth算法能夠迅速識別出隱藏在大量數據中的惡意行為模式,為安全專家提供及時的警報和應對建議。尤其是在面對不斷演變的惡意軟件和復雜的網絡攻擊時,FP-growth的高效性能為防御系統提供強大的支持。
3.2 關聯規則挖掘在病毒傳播路徑分析和異常行為檢測中的應用
關聯規則挖掘作為一種強大的數據挖掘技術,在病毒傳播路徑分析和異常行為檢測中發揮著重要作用。面對不斷變化的網絡威脅和惡意軟件攻擊,有效分析病毒傳播路徑和準確檢測異常行為對于保護信息安全至關重要。在病毒傳播路徑分析中,關聯規則挖掘能夠幫助安全專家發現惡意軟件在網絡中的傳播模式,分析感染主機之間的關聯關系,如通信記錄、共同訪問的惡意網站等,揭示出病毒傳播的路徑和趨勢,及時阻斷病毒的傳播鏈,防止感染范圍進一步擴大。
3.3 實際案例分析:基于關聯規則挖掘的病毒傳播路徑分析
近年來,隨著網絡技術的快速發展,惡意軟件的傳播方式和攻擊手段也變得越來越復雜。如在某次嚴重的病毒爆發事件中,關聯規則挖掘技術發揮了重要作用,幫助人們深入分析了病毒的傳播路徑。該病毒主要通過電子郵件附件和網絡下載進行傳播,感染用戶計算機后,會竊取用戶的敏感信息,并通過網絡將這些信息發送到攻擊者的服務器。為了有效應對這一威脅,安全團隊采用關聯規則挖掘技術對病毒的傳播路徑進行深入分析。
團隊收集了受感染主機的網絡通信記錄、系統調用序列等相關日志數據,利用關聯規則挖掘算法分析數據,尋找與病毒傳播相關的頻繁項集和關聯規則。在分析中,團隊發現一些有趣的模式。例如,受感染主機在感染前都曾經訪問過某個特定的惡意網站,并從該網站下載了惡意軟件。此外,這些主機在感染后的網絡通信行為也表現出一定的規律性,如定期向某個特定的IP地址發送數據。基于這些發現,團隊進一步構建病毒傳播路徑的可視化圖譜,清晰地展示病毒從感染源到目標主機的完整傳播鏈,幫助安全團隊快速定位并清除了感染源。
4 結束語
在信息化、網絡化時代,數據挖掘技術已經成為計算機網絡病毒防御的有力武器。關聯規則挖掘等技術,能夠幫助人們從海量的數據中提取出有價值的信息,及時發現和應對網絡威脅。新技術手段分析病毒的傳播路徑,準確檢測異常行為,為構建高效、智能的防御系統提供了強有力的支持。然而,隨著技術的不斷進步,惡意軟件的攻擊手段也在不斷演變,未來需要在數據挖掘的基礎上,結合深度學習、人工智能等其他先進技術,共同構建一個更加完善、智能的病毒防御體系。
參考文獻
[1] 劉娜.數據挖掘技術在計算機網絡病毒防御中的應用研究——評《數據挖掘概念與技術》[J].現代雷達,2021(13):98-99.
[2] 趙嬌,譚衛東.數據挖掘技術在計算機網絡病毒防御中的應用探討[J].信息與電腦,2023,35(10):43-45.
[3] 鄭剛.數據挖掘技術在計算機網絡病毒防御中的應用探討[J].信息與電腦,2022(3):98-99.
[4] 劉婉瑩.數據挖掘技術在計算機網絡病毒防御中的應用[J].科學技術創新,2022(10):76-77.
