基于RFECV特征選擇和隨機森林預測模型的應用與優化
2024-10-09 00:00:00孫晶
數字通信世界 2024年9期

摘要:該文基于隨機森林預測模型,提出RFECV特征選擇方法:首先對特征變量進行獨熱編碼,再利用RFECV內置的交叉驗證評估各特征子集性能,以確定最佳特征數量,并遞歸消除低重要性特征。實驗表明,該方法在隨機森林上訓練與預測更快,均方誤差更低,特征提取準確率高。
關鍵詞:隨機森林預測模型;獨熱編碼;遞歸特征消除;交叉驗證
doi:10.3969/J.ISSN.1672-7274.2024.09.039
中圖分類號:TP 391 文獻標志碼:B 文章編碼:1672-7274(2024)09-0-03
Feature Selection Based on RFECV and Application and Optimization of Random Forest Prediction Model
SUN Jing
(School of Computer Science and Technology, Taiyuan University of Science and Technology, Taiyuan 030000, China)
Abstract: Based on the random forest prediction model, this paper proposes the RFECV feature selection method: firstly, the feature variables are encoded with one-hot encoding, and then the built-in cross-validation of RFECV is used to evaluate the performance of each feature subset to determine the optimal number of features, and recursively eliminate low-importance features. Experiments show that this method achieves faster training and prediction on the random forest, lower mean squared error, and high accuracy in feature extraction.
Keywords: random forest prediction model; one-hot encoding; recursive feature elimination; cross-validation
0 引言
在數據量高速增長的今天,與數據對象相關的其他特征數據越來越多,在分析的過程中,不可避免要對這些特征數據的影響力進行計算并判斷,從而更好地理解數據對象,服務于后續流程。在特征量的選擇上,有研究提出了一種基于隨機森林的封裝式特征選擇算法RFSS,以隨機森林算法為基本工具,以分類精度作為準則函數,采用序列后向選擇和廣義序列后向選擇方法進行特征選擇[1]。針對基模型的優化,有研究提出了一種基于改進網格搜索的隨機森林參數優化算法,該方法能夠在一定程度上提高隨機森林算法的分類性能[2]。針對特征變量的分類值,有研究利用獨熱編碼對數據集中的原始網絡包進行編碼,維度重構后形成二維數據,最后訓練分類器模型進行檢測[3]。在特征消除研究上,有研究提供了在回歸模型上置換重要性測量的理論研究[4]。也有研究利用隨機森林變量選擇機制,針對不平衡問題,提出了一個不平衡隨機森林變量選擇方法(IBRFVS)[5]。
1 相關概念介紹
1.1 隨機森林模型
隨機森林(Random Forest)模型作為一種舉足輕重的機器學習算法模型,其應用廣泛且深受青睞。該模型的核心機制在于對訓練集數據構建多棵決策樹,并通過這些決策樹的預測結果進行平均(針對回歸任務)或投票(針對分類任務),以此來增強最終結果的準確性和模型的穩健性。正是這一機制,使得隨機森林模型在處理分類、回歸等多樣化任務時展現出卓越的性能。
隨機森林的構建精髓蘊含兩大關鍵步驟:隨機采樣與隨機特征選擇。隨機采樣意味著從原始訓練集中隨機抽取多個數據子集,每個子集獨立用于訓練不同的決策樹。這種訓練方式的獨立性極大地提升了模型的泛化能力,并有效降低了模型的方差。而隨機特征選擇則是指在每棵決策樹的構建過程中,隨機選取一部分特征作為最佳分裂節點,這一策略進一步增強了模型的多樣性,并提升了其后續的擬合能力。
盡管隨機森林模型以其強大的抗過擬合能力和廣泛的適用性而著稱,但仍存在一些不容忽視的缺點有待改進。其中,訓練時間和預測時間相對較長便是亟待解決的問題,特別是在決策樹數量較多的情況下,這一問題顯得尤為突出,增加了模型的復雜性和計算成本。因此,在實際應用中,需要權衡隨機森林的優勢與不足,并適時探索優化策略以提升其整體效能。
1.2 獨熱編碼
獨熱編碼(One-Hot Encoding)作為一種處理類別型數據中差異性問題的常用技術手段,其核心優勢在于能夠將非數值型的類別變量有效轉換為數值型數據,為后續的數據分析操作,如Jaccard距離計算等,奠定堅實的基礎。這種轉換機制對于提升機器學習算法的性能具有至關重要的作用,因為絕大多數機器學習模型都是基于數值型數據進行構建的,而直接處理類別型數據的能力相對有限。
然而,盡管獨熱編碼在數據處理中扮演著重要角色,但它也并非毫無瑕疵。一個顯著的缺點是,當變量的分類值較多時,獨熱編碼可能會導致數據維度急劇膨脹,這種維度的增加有時甚至會被視為災難性的。維度的急劇擴張不僅會大幅增加計算資源的消耗,還可能對模型的性能造成負面影響,如減緩訓練速度、降低預測精度等。此外,獨熱編碼生成的稀疏矩陣也可能導致某些機器學習算法在處理時效率下降,因為算法需要額外處理大量的零值。
獨熱編碼在處理類別型數據時雖然具有獨特的優勢,但其潛在的缺點也不容忽視。在實際應用中,需要根據數據的具體特性和機器學習算法的要求,審慎考慮是否采用獨熱編碼,以及是否需要探索其他更為合適的特征編碼方法,以期在保持數據有效性的同時,盡可能避免維度災難和計算負擔的加重。
1.3 遞歸特征消除算法
遞歸特征消除(Recursive Feature Elimination,RFE)是一種高效且實用的特征選擇算法,其核心思想基于遞歸策略,通過不斷評估特征的重要性,對特征進行精細排序。在此過程中,算法會逐步剔除那些對模型貢獻相對較小的特征,旨在實現模型的簡化與優化。這種方法不僅有助于減少模型的復雜度,還能夠顯著提升模型的泛化能力,使得模型在面對新數據時表現出更強的魯棒性和預測準確性。遞歸特征消除的優勢在于其能夠系統地識別并保留對模型預測最為關鍵的特征,同時去除冗余或噪聲特征,從而為構建更為精簡、高效的機器學習模型提供一種有力的工具。
RFE依賴于基模型來計算特征的重要性評分。以隨機森林為例,特征的重要性評分主要依賴于該特征在所有樹中的基尼不純度減少總和來計算。對于一個節點t處的基尼不純度公式如下:
(1)
式中,是屬于類別的樣本比例;是類別總數。
特征的重要性通過累加該特征在所有樹中貢獻的基尼不純度減少量來計算,公式如下:
(2)
式中,是節點t處的基尼不純度減少量;是特征是否用于節點t的分裂,T是所有樹的節點集合。
具體算法如下:
輸入:
①特征矩陣(形狀為,其中n是樣本數,m是特征數)。
②目標向量(長度為n)。
③基模型(例如,隨機森林、線性回歸等)。
④要選擇的特征數量k。
輸出:
選擇的最優特征子集
①初始化:將當前特征集設為所有特征;設定要選擇的特征數量k。
②使用當前特征集訓練基模型。
③根據公式(1)和(2)計算每個特征的重要性評分。
④根據重要性評分,對特征進行排序。
⑤移除重要性評分最低的特征。
⑥重復步驟②~⑤,直到剩余特征數量等于k。
⑦輸出最優特征子集,返回當前特征集。
RFE的優點在于它能夠顯著減少特征數量,從而降低模型的復雜度,提高模型的泛化能力。同時,通過消除不相關或冗余的特征,可以增強模型的解釋性。然而,RFE也有很多缺點及需要改進的地方。比如RFE需要多次訓練模型,從而會導致計算成本升高。
1.4 遞歸特征消除與交叉驗證
遞歸特征消除與交叉驗證(Recursive Feature Elimination Cross-Validation, RFECV)是一種融合了RFE的特征篩選機制與交叉驗證模型評估策略的高級方法。其核心優勢在于能夠自主確定應保留的最佳特征數量,這一過程無須用戶預先設定特征數量,而是通過內置的交叉驗證機制來全面評估各個特征子集的模型性能,進而精準定位最佳特征數量。
RFECV算法的顯著優點在于,它能夠基于數據本身的特點,更為合理地計算與分析特征數量,使得參數選擇更為科學,分析結果也更為準確。然而,該算法亦存在一些不足之處。例如,交叉驗證的過程可能耗時較長,特別是在處理大規模數據集時,算法的復雜性和計算需求可能會顯著增加,導致處理過程更為煩瑣。盡管如此,RFECV仍因其強大的特征選擇能力和模型優化潛力,在機器學習領域占據著重要的地位,是提升模型性能、深入挖掘數據價值的有力工具。
2 實驗結果和分析
本文基于數據集中多特征變量問題進行隨機森林算法分析。在常規算法中,對所有的屬性變量進行獨熱編碼,方便后面的計算。然后用隨機森林模型計算分析每一個特征變量對于因變量取值的重要性,最后計算算法的訓練時間、測試時間,以及均方誤差(MSE)值,從而判斷算法的性能。
在改進算法中,采用遞歸特征消除與交叉驗證(RFECV)算法先計算出合理的特征變量數目,然后遞歸地計算每個特征的重要性評分,之后將重要性評分進行排序,移除評分最低的特征。不斷減少對于因變量影響較少的特征變量,最后留下的特征變量即為所求。計算改進算法的訓練時間、測試時間,以及均方誤差MSE值,進而判斷當前算法的性能。
分析并比較常規算法與改進算法得到的模型復雜性、訓練時間、測試時間、以及能夠反映模型性能的均方誤差(MSE)值。
數據集采用的是Yelp平臺在美國賓夕法尼亞州所有餐廳的數據。數據集中共有514條記錄值,每條記錄代表了當地一家餐廳的所有信息。經過觀察分析,每條記錄的“attributes”(餐廳特征)變量中的子特征變量可能會對“stars”(餐廳的星級評價)產生影響,因此取前者中的子變量作為特征變量,后者作為因變量。提取“attributes”中的所有的34個子特征變量,刪去其中出現頻率較低的特征變量,最后留下“Alcohol”“BusinessAcceptsCreditCards”“GoodForMeal”“RestaurantsTableService”等18個常見標簽。
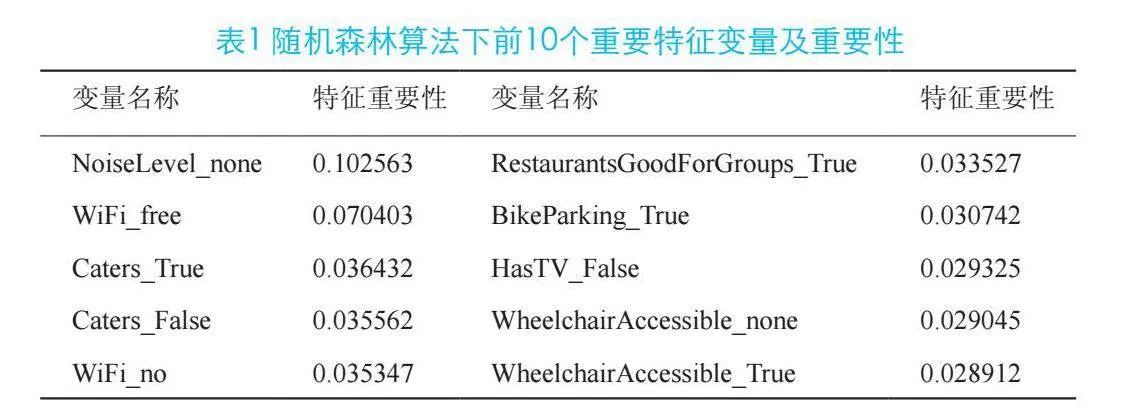
首先經過觀察分析,這18個自變量的取值都是分類值,因此考慮采用獨熱編碼對每個數據對象的自變量進行賦值。然后在常規定義下,使用隨機森林算法分析每個特征值的重要性,得到結果如表1所示。
經計算可得常規算法下,訓練時間約為0.159 s,預測時間約為0.004 s,交叉驗證(MSE)值為0.482。隨后,研究采用了基于遞歸特征消除(RFE)的隨機森林算法進行深度優化與交叉驗證,旨在細致分析每個特征變量的重要性。經過一系列嚴謹的篩選流程,最終確定了前10個最具影響力的特征變量,它們分別是:RestaurantsTableService_False、RestaurantsTableService_True、Alcohol_full_bar、Caters_False、Caters_True、HasTV_True、RestaurantsGoodForGroups_True、NoiseLevel_average、NoiseLevel_none以及WiFi_free。這些特征在模型中展現出了顯著的重要性,對于預測結果的準確性起到了關鍵作用。
通過對改進后的算法進行性能評估,發現訓練時間顯著降低至約0.111 s,而預測時間也大幅縮減至約0.003 s。同時,交叉驗證的均方誤差(MSE)值降低到了0.457,這表明模型的預測精度得到了顯著提升。因此,改進后的算法不僅在訓練與預測時間上實現了明顯下降,而且MSE值也有所減小,更為重要的是,重要特征變量的計算準確率高達85%,充分驗證了該算法在提升模型效率與準確性方面的有效性。這一研究成果為后續進一步優化模型性能、提高預測精度奠定了堅實基礎,并有望在實際應用中發揮重要作用。
3 結束語
本文著重探討了基于RFECV的特征選擇在隨機森林模型上的優化策略與改進措施。研究結果顯示,該方案在確保結果準確性的基礎上,顯著縮短了模型的訓練與預測時間,并成功降低了均方誤差(MSE)值,從而有效提升了模型的整體泛化能力。然而,值得注意的是,基模型的表現及其性能對RFECV特征選擇的效果具有深遠的影響。因此,進一步優化基模型以提升整體性能,成為后續研究的核心方向。具體而言,未來的研究可通過系統地調整超參數來優化基模型——隨機森林的各項參數,旨在探索更為精細的參數配置,以期在不犧牲模型準確性的前提下,進一步提升其效率與泛化能力。
參考文獻
[1] 姚登舉,楊靜,詹曉娟.基于隨機森林的特征選擇算法[J].吉林大學學報(工學版),2014,44(01):137-141.
[2] 溫博文,董文瀚,解武杰,等.基于改進網格搜索算法的隨機森林參數優化[J].計算機工程與應用,2018,54(10):154-157.
[3] 梁杰,陳嘉豪,張雪芹,等.基于獨熱編碼和卷積神經網絡的異常檢測[J].清華大學學報(自然科學版),2019,59(07):523-529.
[4] 吳辰文,梁靖涵,王偉,等.基于遞歸特征消除方法的隨機森林算法[J].統計與決策,2017(21):60-63.
[5] 尹華,胡玉平.基于隨機森林的不平衡特征選擇算法[J].中山大學學報(自然科學版),2014,53(05):59-65.
