基于TextCNN模型的電子期刊文獻推薦方法研究
2024-09-11 00:00:00刁羽薛紅
新世紀圖書館 2024年7期



摘 要 論文提出基于TextCNN模型的電子期刊文獻推薦方法,旨在更好地精確把握文獻內容的本質特征與用戶文獻需求的深層關系,實現電子期刊文獻推薦服務的個性化和精準化。使用word2vec對文獻題錄信息進行向量化,使用TextCNN模型訓練文獻推薦模型,最后主動將符合用戶需求的文獻推送給科研用戶。實踐證明,論文設計的推薦模型能夠為用戶推薦電子期刊文獻,效果良好。
關鍵詞 TextCNN;文本分類;電子期刊文獻推薦;行為數據
分類號 G250
DOI 10.16810/j.cnki.1672-514X.2024.07.009
Research on the Method of Electronic Literature Recommendation Based on TextCNN Model
Diao Yu, Xue Hong
Abstract This paper puts forward the method of electronic journal literature recommendation based on TextCNN model, aiming to better accurately grasp the deep relationship between the essential characteristics of literature content and the demands of users, and realize the personalization and precision of electronic journal literature recommendation service. The word2vec is used to vector quantify the literature title information, the TextCNN model is used to train the literature recommendation model, and finally the literature that meets user needs is actively pushed to scientific research users. Practice has proved that the recommendation model designed in this paper can recommend electronic journal literature for users with good results.
Keywords TextCNN. Text classification. Electronic literature recommendation. Behavior data.
0 引言
文獻推薦研究一直是圖書館學、情報學中的重要內容。Kuai H等[1]指出文獻推薦是緩解“信息過載”的有效途徑之一,可以提高科研用戶效率。電子期刊文獻推薦是指將高質量的電子期刊推薦給相關領域的用戶。現如今,由于基于傳統機器學習的電子期刊文獻推薦方法難以有效學習用戶文獻需求的深層特征,在應用和推廣上皆存在一定的局限性[2]。如何有效利用用戶訪問電子資源行為特征數據、待推薦文獻特征數據及兩者之間的交互數據實現電子期刊文獻推薦,已成為緩解當前“信息過載”時代用戶“信息需求焦慮”的重要途徑。因此,為了更精確地把握期刊文獻內容的本質特征與用戶文獻需求的相關關系,本文以高校數字圖書館中的電子期刊文獻資源與同一學科范疇下的用戶為研究對象,以推薦用戶需求期刊文獻為目的, 結合基于卷積網絡神經的文本分類的原理和方法,利用用戶在使用電子資源時產生的行為數據進行文獻推薦研究,旨在探索一條更加貼合用戶需求的電子期刊文獻推薦之路,并為其提供可靠的依據和發展方向。
1 研究綜述
當前,國內外將深度學習應用到文獻推薦的研究方興未艾。Shen X[3]等提出了一種學習資源推薦方法,該系統利用卷積神經網絡預測文本信息的隱語義。在訓練過程中,使用L1范數正則化解決過擬合問題。Saraswat M等[4]通過比較圖書書評之間詞向量的相似性進行推薦。同時,為了克服因詞語之間缺乏語義而導致推薦不理想的問題,引入了循環神經網絡(RNN)。如此一來,以前神經元的信息將得到維護,同時也將書評中的詞語關聯起來。劉愛琴、李永清等[5]利用SOM(Self-Organizing Maps)神經網絡聚類算法的無參數、精度高、客觀性強的特點對高校圖書館的借閱記錄進行聚類,將用戶個人特征信息、用戶行為數據及文獻數據庫等相關數據資源進行篩選整合,并結合語義檢索和屬性值匹配等技術來構建圖書館個性化推薦系統,在推薦精準度上有著較好的表現。電子期刊文獻作為電子文獻中一項重要組成部分,代表著各個研究領域的發展動向,體現了學者們最新的研究成果,是科研用戶獲取科研信息的重要來源。朱祥等[6]通過DPRel相關性度量算法計算作者與文獻間的相關性,并在此基礎上向作者推薦相關性高的文獻。Pan C等[7]利用協同過濾挖掘學術論文的主題相似性并進行推薦。Tao M等[8]通過LDA對論文進行主題和詞語的概率分布計算并提取關鍵詞。同時,利用word2dec表示主題向量,利用doc2vec表示論文向量,通過計算論文與主題的相似度得到與用戶輸入的主題最相似的top N篇論文,最后利用PageRank算法對選項重新排序并得到最終的推薦結果。李闊[9]針對電子文獻資源存在多種數據類型的情況,結合多源異構數據嵌入框架異質圖神經網絡(HetGNN),在用戶—文獻網絡中生成多種類型的節點,建立用戶—文獻關系和文獻—文獻內在聯系,為用戶推薦其感興趣的文獻資料。劉韻毅、梁樑[10]通過自建的在線論文評級系統收集用戶對基準集論文的評分,然后基于模糊聯想記憶神經網絡學習用戶的主題偏好,并通過學習的偏好為用戶推薦論文。從目前的研究成果來看,雖然將深度學習運用到電子期刊文獻推薦的研究已成為學術界突破傳統推薦方法局限性的重點方向,但鮮有將其理論與實踐相結合的深層次研究。利用深度學習的研究成果提取用戶、文獻的屬性特征及對兩者匹配程度建模的系統研究也尚處于探索階段。
除此之外,深度學習在學習文本內容的深層特征方面也具有顯著的優勢,如RNN、CNN、圖神經網絡、注意力機制等各種模型紛紛應用于文本分類,其中CNN在從空間序列的角度捕捉文本的關鍵短語上尤為出色[11]。Wu等[12]提出基于卷積神經網絡、循環神經網絡等深度學習的文本分類在文本情感分析、新聞分類、主題分類等方面皆有優異表現。Johnson R等[13]運用了一種詞級的深度金字塔狀卷積神經網絡進行文本分類,并使用無監督嵌入的文本區域嵌入提高模型精準度。Youssef ElErain等[14]介紹了使用深度學習算法進行文本分類的過程和方法,并強調了深度學習在處理文本數據時的優勢。Asudani等[15]探討了詞嵌入在文本表示和分析中的重要性,并闡述了使用深度學習算法來實現詞嵌入的方法。鑒于此,筆者認為只要能夠準確地對符合用戶需求的電子期刊文獻進行標注,則可將文獻推薦視為匹配用戶需求和不匹配用戶需求的文本內容的二分類邏輯回歸問題。圍繞這一思想,本文通過采選用戶訪問電子資源校外訪問系統行為數據,運用TextCNN文本分類模型構建電子期刊文獻推薦模型,并主動將匹配用戶需求的文獻推送給科研用戶,進而最大程度地促使圖書館電子資源能夠在電子期刊文獻推薦實際應用中發揮作用。
2 研究思路及關鍵技術
如何判斷文獻是否符合用戶需求是本研究的關鍵之一。為此,本研究的基本思路是:首先,將符合用戶需求的文獻數據視為正類數據,反之則為負類數據;其次,對題錄數據進行分詞和向量化;第三,運用卷積神經網絡進行訓練,學習文獻內容的深層特征與用戶需求的匹配程度之間關系的模型;第四,根據該模型預測文獻內容屬于是否符合用戶需求的類別。為挖掘用戶需求與文獻特性之間的關系,可根據Adomavicius G等歸納的推薦算法的形式化定義公式,表達如下[16]:
(1)
其中,c屬于用戶集合C,s屬于項目集合S,u為效用函數,可以衡量用戶需求與項目之間的匹配度,即u=C×S→R,R為全序集合。在推薦系統中,效用函數是通過評級的方式判斷用戶需求與文獻之間的匹配度。當匹配度達到某一閾值時則可將文獻劃分為符合用戶需求的類別。同理,文獻推薦算法可以通過效用函數確定待推薦文獻與用戶需求的關系,即用戶需求與文獻內容的匹配程度。具體來說,主要涉及以下關鍵技術。
2.1 根據用戶行為特征標注數據
用戶訪問電子資源校外訪問系統行為數據(以下簡稱“行為數據”)是用戶獲取電子文獻資源時與平臺自然產生的最為客觀的數據,它可以幫助推薦算法迅速挖掘出用戶或文獻的潛在共性特征,從而提高推薦性能[17]。該數據具體是指用戶在訪問電子資源過程中瀏覽、檢索、下載等歷史行為數據的集合。本文采選該數據來源的原因有二:一是筆者在前期研究成果已經實現了該數據的采集技術與方法[18],二是電子資源校外訪問系統詳細記錄了用戶的相關行為線索,如用戶瀏覽文獻URL或下載文獻的題名、責任者等,這些線索有助于獲取用戶實際感興趣的文獻題錄信息。高質量的數據標注能有效提高模型訓練的質量,以下則是根據用戶行為特征標注的數據分類。
2.1.1 正類數據
本研究將行為數據中記錄的用戶瀏覽、下載文獻數據作為正類數據的數據源。該類數據源自本校電子資源校外訪問系統的各類行為日志,并以JSON格式進行記錄。日志的主要元素及其取值的含義如下:(1)元素ACTION的子元素TYPE的值,代表用戶訪問電子資源時的操作類型。當TYPE的值等于1時,表示用戶的操作類型是瀏覽文獻;當其值等于2時,表示用戶的操作類型是檢索文獻;當其值等于3時,表示用戶的操作類型是下載文獻。(2)元素ACTION的子元素INFO的值,代表用戶操作時產生的具體數據。根據操作類型的不同,與TYPE取值為1、2、3時對應的INFO的值分別代表了用戶瀏覽文獻題錄信息時訪問的URL、用戶提交的檢索詞、用戶下載文獻的題名和責任者。(3)元素ACTION的子元素RID的值,代表用戶訪問的電子資源數據庫ID。結合這三種數據,則可以方便地從電子資源數據庫網站中抓取用戶瀏覽、下載文獻的題錄數據。
2.1.2 負類數據
本研究將用戶專業領域中的《中文核心期刊要目總覽》收錄期刊和“中文社會科學引文索引”(CSSCI)來源期刊中已經發表但未被用戶瀏覽、下載的論文作為負類數據源。該數據可通過各電子資源平臺提供的導出功能獲得。
2.2 確定推薦對象
眾所周知,陷入信息繭房中的個體受困于自己感興趣的同質信息,阻礙了他們接觸更多元化的信息,并在一定程度上限制了其研究視野。個性化推薦、個體特征、環境特征等是形成信息繭房的重要原因。雖然個性化電子期刊文獻推薦是一種基于用戶需求實現有效文獻分發的推薦服務,其推薦算法也有利于擴展個體對信息接觸的廣度和深度[19]。但是,為減輕信息繭房的負面效應,打破其中用戶與用戶之間的交流屏障,選取屬于同一學科范疇且用戶所在專業或研究領域具有“差異化”的群體作為電子期刊文獻的推薦對象,不僅有利于幫助用戶突破固定的信息圈,促進不同研究領域用戶之間的交流,還能幫助其拓寬研究思路,發掘新的研究方向。為此,本研究選擇同一學科范疇的用戶作為整體進行文獻推薦。
2.3 TextCNN模型
目前,卷積神經網絡(Convolutional Neural Network,CNN)廣泛應用于視覺處理和自然語言處理領域,它將較小的卷積核在較大的輸入特征矩陣上滑動并進行卷積運算,從而在不損失輸入數據信息的前提下提取其重要特征[20]。在CNN的基礎上,Kim Y提出了一種簡單可靠的文本分類模型[21]。該模型由四部分組成。(1)輸入層。輸入向量為矩陣,其中n為文本包含的單詞數量,k為詞向量維度。(2)卷積層。利用h的卷積核對輸入層的特征矩陣作卷積操作。(3)最大池化層。最大池化層的作用在于通過保留最大值以達到保留關鍵特征和降低維度的作用。(4)輸出層。使用壓扁后的全連接層和softmax函數對池化后的向量進行分類并輸出結果。根據實際場景的不同,在Kim Y的TextCNN模型的基礎上,出現了加入注意力機制、與其他神經網絡模型相結合等方案改進模型。因本研究涉及的數據量較少且數據結構相對簡單,故只對原始TextCNN模型進行了微調。
2.3.1 輸入層
神經網絡無法直接計算文本數據,因此需要使用數值表示文獻題錄的有效特征。目前,文本表示技術主要劃分為詞袋模型(Bag-of-Words,BOW)和詞嵌入模型(Word Embedding)兩個類別。因為BOW存在著維度災難、無法保留詞序信息及存在語義鴻溝等方面的問題[22],詞嵌入模型越來越受到自然語言處理(Natural Language Processing,NLP)領域研究者的重視。如,Po-Sen Huang等提出Word Hashing方法將英文單詞映射為向量。該方法基于n-gram模型,采用letter-trigram模式,統計單詞三分段后的詞頻,再將詞頻轉化為向量,最后通過詞向量計算單詞之間的相似度。該方法比one-hot模式的維度降低了四倍左右[23]。隨后,Word2Vec成為了此研究方向的主流。
word2vec[24]使用CBOW(Continuous Bag-of-Words)和Skip-Gram這兩種神經網絡模型分別實現了基于上下文預測中心詞和根據中心詞預測上下文。廣泛應用于NLP各類下游場景的詞向量,是word2vec在完成上述預測任務訓練神經網絡模型時隱藏層的參數矩陣。它在確保計算效率和運算結果的精確性的同時,解決了大規模數據集中詞的連續向量表示(Continuous Vector Representations)問題,同時word2vec的連續向量表示是基于分布式表示(Distributed Representation)假說,即相似詞具體相似的向量表示[25]。因此,word2vec可有效克服BOW的語義鴻溝難題,使語義相近的詞的詞向量在向量空間上具有相近的位置。研究結果證實,通過詞的word2vec詞向量之間的余弦距離,可以十分準確地預測出詞與詞之間的相似度。比如:vector(‘Paris’)-vector(‘France’)+ vector(‘Italy’)的運算結果與vector(‘Rome’)之間具有較高的相似度;vector(‘king’)-vector(‘man’) +vector(‘woman’)的運算結果與vector(‘queen’)之間具有較高的相似度[26]。同時,相較于BOW使用的離散表示方法,word2vec使用的分布式表示將詞映射到由實數構成的連續、低維和稠密的向量,克服了BOW的維度災難問題。
2.3.2 卷積層
在本研究中,文獻由摘要分詞后的詞條構成。由于文摘篇幅長短不一,故分詞后詞條的數量各不相同,而卷積神經網絡要求輸入的每篇文獻的特征值的維度必須統一才能進行計算,因此對它們作如下處理:首先,統一每篇文獻的摘要分詞的數量;其次,為了更加逼真地模擬圖像數據,將二維矩陣擴展為深度為1的三維矩陣。則有,設X為文獻摘要向量,M為文獻的單詞數量,N為每個單詞的word2vec詞向量,;設W為卷積核,U和V為卷積核的維度,則。一般情況下,卷積神經網絡使用互相關代替卷積運算,即不翻轉卷積核。邱錫鵬[27]對輸入的特征值進行卷積操作的互相關運算公式表達如下:
(2)
卷積運算后輸出的矩陣為:。
設卷積核的數量為p,卷積運算后的特征映射可表示為:
(3)
其中,表示卷積運算,為非線性激活函數,bp為偏置。
2.3.3 池化層
目前有兩種常見的池化層,即最大池化層和平均池化層。顧名思義,最大池化層的取值是子區域內神經元的最大活性值;平均池化層的取值是子區域內神經的平均活性值。因為word2vec詞向量的幾何意義是詞在向量空間的映射,其值大小與向量是否更能代表這個詞的語義沒有關系,所以本研究采用平均池化層,而非最大池化層。
2.3.4 輸出層
經過卷積層和池化層運算的特征值需要通過全連接層綜合所有的局部信息,便于CNN通過邏輯回歸進行分類。
3 實證研究
本研究以四川輕化工大學法學院研究生為研究對象,雖然他們所研究的專業領域有所不同,但同屬于相同的一級學科,且研究方向的種類較少,符合本研究推薦對象確定方式。與用戶需求匹配的數據是從校外訪問系統中提取法學院研究生2017—2021年的行為數據,并從中提取用戶的瀏覽文獻的URL,以及下載文獻的文獻名和責任者。最后,根據URL等信息從電子資源網站上爬取文獻的題錄信息。這些文獻視作與用戶的需求匹配,以Du表示。此類文獻的選取范圍既是2017—2021年法學專業期刊文獻,同時也是北大核心和CSSCI來源期刊文獻。從電子資源的網站上檢索出這些文獻并導出題錄數據,以Dr表示。
3.1 數據預處理
第一步,從Du和Dr剔除無用數據,如Du中的重復數據、無摘要的數據,Dr中的投稿指南、注釋體例等;第二步,數據標注。首先,Du為用戶瀏覽、下載的文獻,符合用戶需求,視為正類數據,以0標注;其次,從Dr中剔除與Du重合的數據。剩余數據為用戶未瀏覽、下載文獻,視為負類數據,以1標注;第三步,合并Du和Dr,形成新的數據集D。經過數據預處理后,D的數據分為了兩個類別,類別0表示符合用戶需求;類別1表示不符合用戶需求。
3.2 訓練word2vec詞向量
第一步,對文獻摘要進行分詞。摘要分詞的質量直接影響推薦模型的訓練質量。為保障專業名詞分詞準確性,本研究將論文中的關鍵詞和《清華大學開放中文詞庫》[28]分別作為第一和第二順位的自定義分詞詞典。同時,調用《百度停用詞表》《哈工大停用詞表》《中文停用詞表》和《四川大學機器智能實驗室停用詞庫》,去除虛詞、助詞、介詞等無意義的詞[29]。
第二步,訓練摘要的詞的word2vec詞向量。調用gensim.models.word2vec的word2vec類訓練詞向量,主要參數如下[30]。
(1)vector_size:此參數表示詞向量的維數,其實質是word2vec神經網絡模型隱藏層的神經元個數,本研究取值為100,訓練結束后單詞的詞向量維度為100;
(2)windows:當前詞與預測詞之間間隔的詞語數量,本研究取值為5;
(3)sg:模型訓練算法,本研究取值為0,表示采用CBOW模式,即通過一句話的上下文內容預測目標詞。
第三步,word2vec對象的save_word2vec_format
方法保存訓練好的word2vec詞向量模型,以備需要之時多次使用。
3.3 建立CNN模型
(1)輸入特征數據。對數據集中摘要分詞后的單詞的數量進行統計后可知,其中75%分位的數值為72,即有75%的文獻摘要單詞數量少于或等于72。因此,本研究將文獻摘要的單詞數量在72的基礎上稍微放大為100,將該數字作為每篇文獻包含的單詞個數。這樣既確保有86.29%的文獻能選取全部的摘要單詞進行運算;同時,又避免了因個別文獻的摘要單詞數過大(單詞數量超過1000的有7篇文獻,最多單詞數量達1606)影響計算精確度和運算效率。具體的處理辦法是,當單詞數量超過100時,就只選取前100個,截斷其余單詞;當單詞數量少于100時,則用10-10這個趨于0的數值進行填充,以模擬單詞的word2vec詞向量。其次,為了更加逼真地模擬圖像數據,使用numpy庫的expand_dims方法將二維矩陣擴展為三維矩陣。最終,論文P可表示為:。其中,第一個100代表每篇論文包含的單詞數量,第二個100代表每個單詞的word2vec詞向量維度,1代表輸入數據的通道為1。
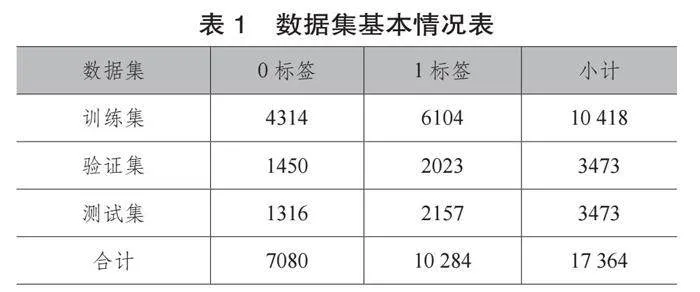
(2)拆分數據集。將數據集拆分為訓練集、測試集和驗證集。拆分后的數據集基本情況如表1所示。
表1 數據集基本情況表
數據集 0標簽 1標簽 小計
訓練集 4314 6104 10 418
驗證集 1450 2023 3473
測試集 1316 2157 3473
合計 7080 10 284 17 364
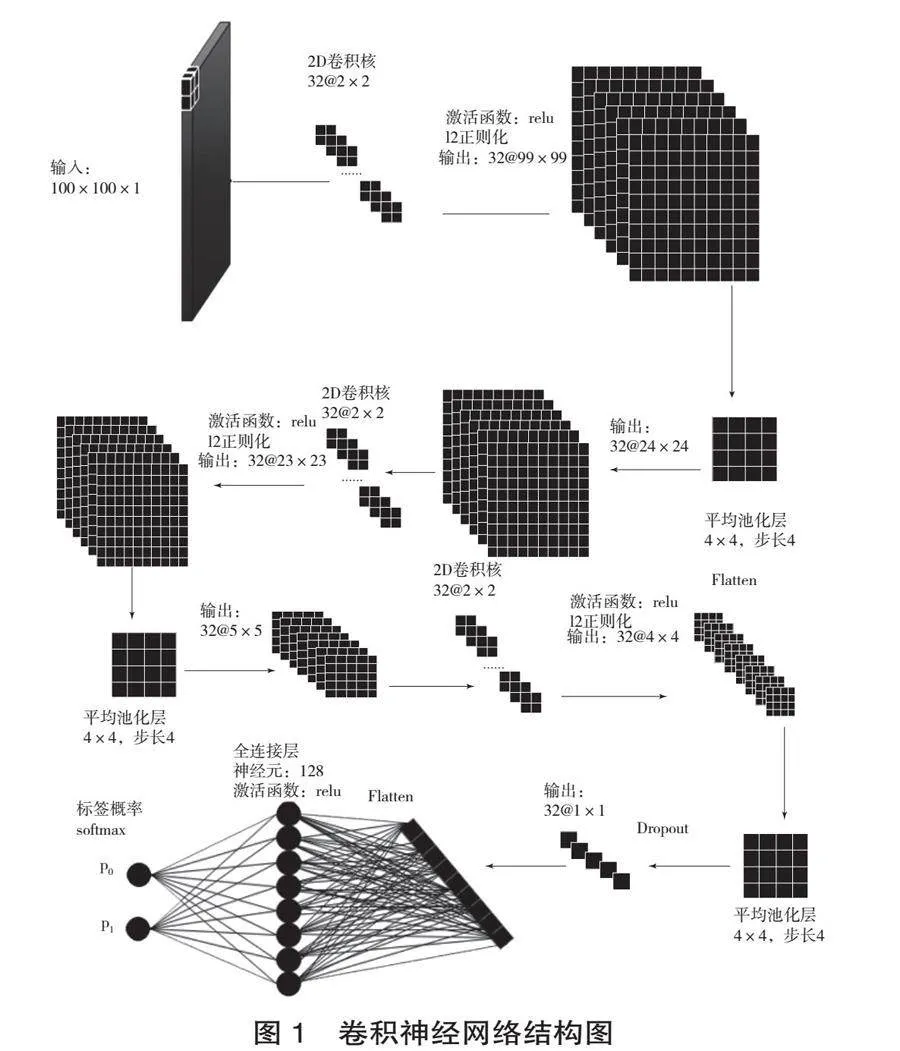
(3)TextCNN模型。如圖1,給定一篇論文,經過由32個的卷積核進行步長為1的卷積運算,激活函數采用如下公式:
(4)
公式具有有效緩解神經網絡中常見的梯度消失問題及提升神經元的激活率等優點[27]83。為防止出現訓練集過擬合問題,在卷積層使用L2正則化對損失函數進行懲罰,公式[31]表達為:
(5)
經過卷積運算后,提取到32幅的特征圖。卷積層后是步長為4的4×4平均池化層。經過3次卷積與池化計算后,在最后一個平均池化層之后對輸出的特征圖以概率為0.4進行Dropout操作,隨機刪除網絡中的部分節點,以進一步降低過擬合的可能性。隨后,將輸出的32幅特征圖轉換為1維數據,之后再經過一個由128個神經元并采用relu的全連接層綜合局部特征,最后經過softmax層計算輸入的數據處于標簽0(p0)或標簽1(p1)的概率。具體結構如圖1所示。
3.4 實證結果
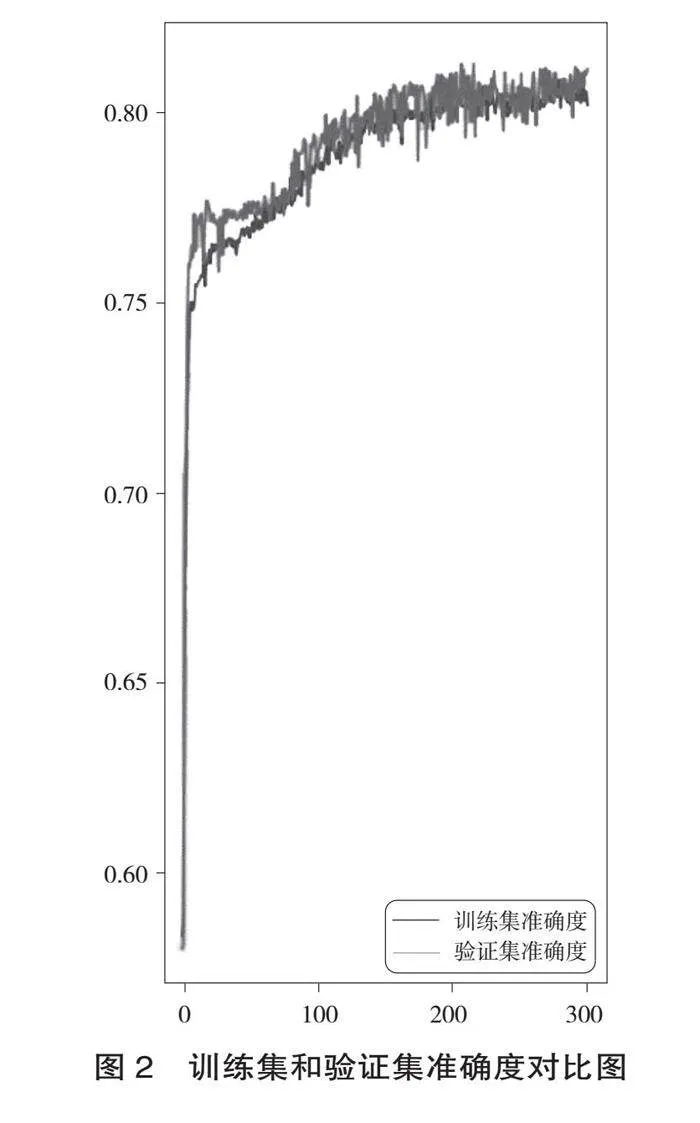
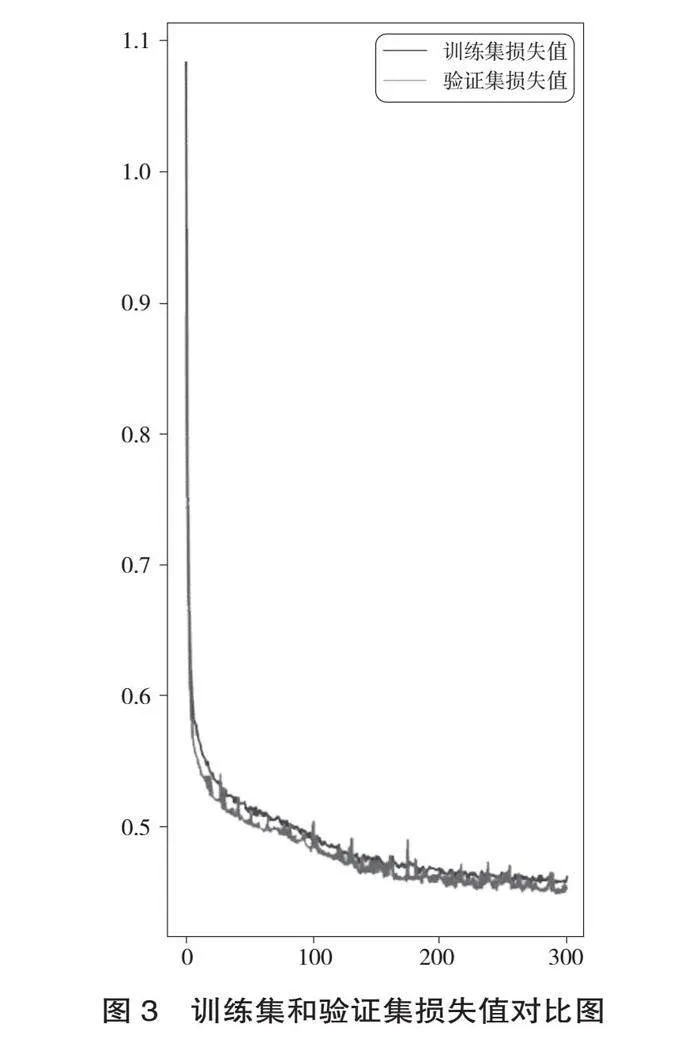
訓練集數據經過300輪訓練后,損失值和精度皆比較平穩且具有良好的效果。訓練集和驗證集的準確度、損失值對比圖如圖2、圖3所示。
訓練結果顯示,訓練集的精度達到79.99%,訓練集的損失值為0.4753;驗證集的精度達到79.9%,驗證集的損失值為0.4676。使用訓練成功后的模型對測試集數據進行預測,預測結果的精度達到了79.99%,損失值為0.4753,具體見表2。
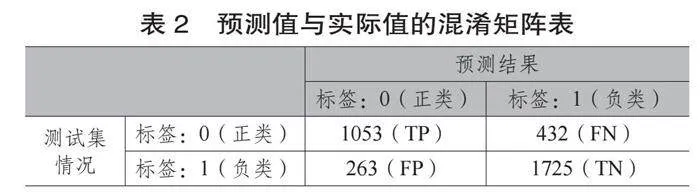
表2中,TP(True Positive)表示通過訓練模型預測的測試集中的正類數據(即將符合用戶需求的文獻標識為0)正確地識別為標簽0,即有1053條數據;FN(False Negative)表示通過訓練模型預測的測試集中的正類數據錯誤地識別為標簽1,即有432條數據。
同理,FP(False Positive)表示將負類預測為正類,即將與用戶需求相悖的文獻(標識為1) 錯誤地識別為標簽0,即有263條數據;TN(True Negative)表示將負類預測為負類,即將不符合用戶需求的文獻(標識為1)正確地識別為標簽1,即有1725條數據。
綜上所述,根據查準率的計算公式Precision=
TP/(TP+FP)100%,本研究在測試集上的查準率為:80.02%;根據召回率的計算公式Recall=TP/(TP+FN) *100%,本研究在測試集上的召回率為:70.91%。可見,本研究訓練的模型不論是在訓練集、驗證集還是測試集上都具有良好的精準度,該訓練模型可以應用于實際的電子期刊文獻推薦。
4 結語
在“十四五”時期倡導激活數據潛能,釋放數據要素價值,培育發展數字新動能的大背景下,本文立足關鍵技術與數據驅動服務相結合的新發展階段,貫徹創新理念,對深度學習視域下電子期刊文獻推薦方法進行深入研究,提出構建基于卷積網絡神經的文獻推薦模型,該方法實用性強,且能高效精準地滿足用戶文獻需求。在研究過程中,行為數據的規范采集及合理利用均涉及到用戶權益保障問題,與此同時,推薦模型的設計及超參數的取值等也需要隨著實際使用效果的變化而調整,為此,筆者后續還將對以上問題作進一步的完善和思考。總之,將本研究成果運用到圖書館的電子期刊文獻推薦的實際工作中,可以進一步豐富和完善文獻推薦方法的理論與實踐體系,同時對于形成可普及、推廣的文獻推薦范式具有重大意義。
參考文獻:
KUAI H, YAN J, CHEN J, et al. A knowledge-driven approach for personalized literature recommendation based on deep semantic discrimination[C]//Proceedings of the International Conference on Web Intelligence. 2017: 1253-1259.
黃立威,江碧濤,呂守業,等.基于深度學習的
推薦系統研究綜述[J].計算機學報,2018,41(7):
1619-1647.
SHEN X, YI B, ZHANG Z, et al. Automatic recommendation technology for learning resources with convolutional neural network[C]//2016 international symposium on educational technology (ISET). IEEE, 2016: 30-34.
SARASWAT M, SARASWAT R, BAHUGUNA R. Recommending Books Using RNN[M]//Recent Innovations in Computing. Springer, Singapore, 2022: 85-94.
劉愛琴,李永清.基于SOM神經網絡的高校圖書館個性化推薦服務系統構建[J].圖書館論壇,2018,38(4):95-102.
朱祥,張云秋,惠秋悅.基于學科異構知識網絡
的學術文獻推薦方法研究[J].圖書館雜志,2020,
39(8):103-110.
PAN C, LI W. Research paper recommendation with topic analysis[C]//2010 International Conference On Computer Design and Applications. IEEE, 2010, 4: V4-264-V4-268.
TAO M, YANG X, GU G, et al. Paper recommend based on LDA and PageRank[C]//Artificial Intelligence and Security: 6th International Conference, ICAIS 2020, Hohhot, China, July 17-20, 2020, Proceedings, Part III 6.xOLOuovdoGaoaA/sWsapb8et9dQiztSfYsnt6hl5dok= Springer Singapore, 2020: 571-584.
李闊.電子文獻資源的推薦方法研究[J].電子技術與軟件工程,2019(22):170-172.
劉韻毅,梁樑.基于用戶偏好的文獻推薦系統[J].情報理論與實踐,2007(1):61-63,25.
MINAEE S,KALCHBRENNER N, CAMBRIA E, et al. Deep learning-based text classification: a comprehensive review[J]. ACM computing surveys (CSUR), 2021, 54(3): 1-40.
WU H, LIU Y, WANG J. Review of text classification
methods on deep learning[J]. Comput Mater Contin,2020,63(3):1309-1321.
JOHNSON R, ZHANG T. Deep pyramid convolutional neural networks for text categoriza-tion[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Lin-guistics (Volume 1: Long Papers), 2017: 562-570.
YOUSSEF E. Deep learning for text classification: an overview[J]. Advances in Neural Information Processing Systems (NIPS), 2021,17(2):363-389.
ASUDANI D S, NAGWANI N K, SINGH P. Impact
of word embedding models on text analytics in deep learning environment: a review[EB/OL]. [2023-03-02]. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9944441.
ADOMAVICIUS G, TUZHILIN A. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions[J]. IEEE transactions on knowledge and data engineering, 2005, 17(6): 734-749.
刁羽,薛紅. 基于電子資源行為數據的TF-IDF
文獻推薦方法研究:以電子資源校外訪問系統為例[J].圖書館雜志,2022,41(12): 45-54.
刁羽,賀意林.用戶訪問電子資源行為數據的獲取研究:基于創文圖書館電子資源綜合管理與利用系統[J].圖書館學研究,2020(3):40-47.
楊雨嬌,袁勤儉.個性化推薦的隱憂:基于扎根理論的信息繭房及其前因后果探析[J].情報理論與實踐,2023,46(3):117-126.
MCGREGOR M. What is a convolutional neural
network? A beginner tutorial for machine learning and deep learning [EB/OL].[2022-03-21]. https://www.freecodecamp.org/news/convolutional-neural-network-tutorial-for-beginners/.
KIM Y. Convolutional neural networks for sentence classification[J]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014(8):1746–1751.
涂銘,劉祥,劉樹春.Python自然語言處理實戰核心技術與算法[M].北京:機械工業出版社,2018.
HUANG P S, HE X, GAO J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013: 2333-2338.
MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. arXiv preprint arXiv:1301.3781, 2013. https://arxiv.org/pdf/1301.3781.
Word2vec[EB/OL].[2022-04-23].https://code.google.com/archive/p/word2vec/.
MIKOLOV T, YIH W, ZWEIG G. Linguistic regularities in continuous space word representations
[C]//Proceedings of the 2013 conference of the north
american chapter of the association for computational
linguistics: Human language technologies, 2013: 746-751.
邱錫鵬.神經網絡與深度學習[M].北京:機械工業出版社, 2020.
孫茂松, 陳新雄, 張開旭, 等.THULAC:一個高效的中文詞法分析工具包[EB/OL].[2021-03-15].http://thuocl.thunlp.org/.
中文常用停用詞表[EB/OL].[2021-03-13].https://
github.com/goto456/stopwords.
Word2vec embeddings[EB/OL].[2022-04-10]. https://radimrehurek.com/gensim/models/word2vec.html.
陳云霽.智能計算系統[M].北京:機械工業出版社, 2020.
