低開銷的匿名通信群組威脅人物挖掘方法
2024-08-23 00:00:00霍藝璇趙佳鵬時金橋齊敏孫巖煒王學賓楊燕燕
四川大學學報(自然科學版) 2024年4期
關鍵詞:文本挖掘
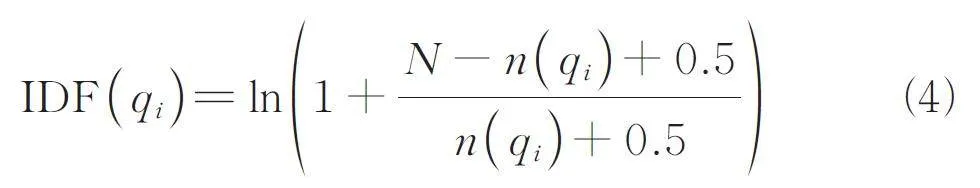
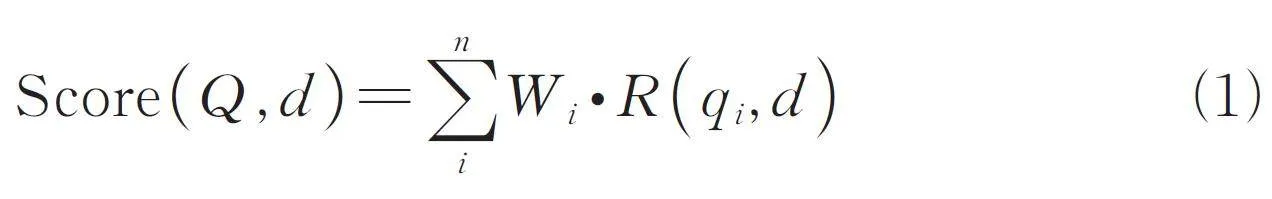
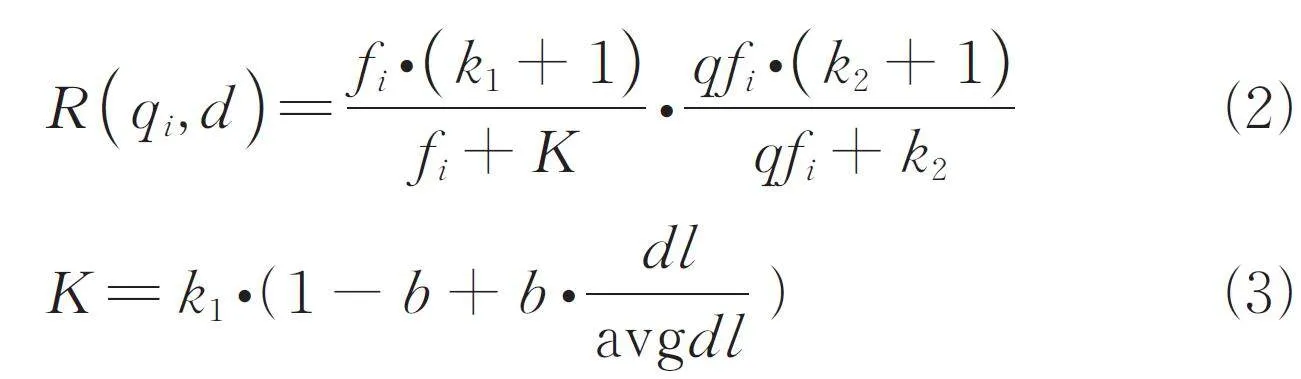
摘要: 深暗網因其強隱匿性、接入簡便性和交易便捷性,滋生了大量非法活動,如推廣網絡博彩、販賣毒品等. 隨著網絡社交方式的更新,加密即時通信工具Telegram 中的群組成為不法分子推廣黑灰產、買賣資源和工具的聚集地,大量不法分子利用Telegram 的匿名功能在對內容無限制、消息短、文字難理解的群組中推動業務而逃避監管,嚴重威脅國家社會穩定和網絡安全. 如果能夠基于對群組中大量低信息量內容的分析,挖掘大批量潛在威脅人物,將為監管、治理和打擊部門提供更多有價值的線索. 本文提出一種低開銷的匿名通信群組威脅人物挖掘方法,通過調整文本中網絡公害流行術語的重要程度優化內容分析質量,融合大語言模型的強大知識儲備和生成能力,對群組內容進行無監督的高質量動態時序主題提取與可視化統計分析. 實驗結果表明,與傳統分類做法相比,本文方法大大降低了人工標注成本,提升了威脅人物挖掘的數量和質量,加深了對網絡公害生態的理解,具有現實意義.
關鍵詞: 網絡公害; 文本挖掘; Telegram 群組; 主題建模
中圖分類號: TP391 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 040004
1 引言
萬維網由表層網和深網組成[1]. 表層網是指能被普通搜索引擎檢索到的網絡,約占互聯網總體的4%;深網是指無法使用標準搜索引擎索引的網絡,需要密碼、訪問權限等才可以訪問. 深網的內容大多是合法的,但其中存在一個網絡公害遍布的部分,即暗網. 暗網是一種基于匿名通信技術的覆蓋網絡,只能通過特殊軟件、代理配置或特殊協議才能訪問,起初是為了給用戶提供隱私和自由而建立的,然而伴隨著加密貨幣和匿名通信的發展[2],大量非法活動與服務在其上滋生. 不法分子在暗網交易市場、地下論壇和加密即時通信工具等深暗網隱匿社交應用上開展威脅活動,大肆傳播有害內容和違禁物品,包括走私軍火、販賣毒品、傳播惡意軟件、推廣博彩與色情網站和組織電信詐騙等,嚴重威脅國家安全和社會穩定.
作為最受歡迎的深暗網地下市場溝通渠道之一,加密即時通信應用Telegram 使用內部設計的加密協議MTProto[3],支持用戶端到端加密聊天、隱藏線上身份、消息閱后即焚、頻道無人數上限等功能,不法分子在其上可以更好地躲避電子和通信監管,散播有害內容和交易違禁品[4]. 其形式上類似于明網的即時通訊應用,如微信、QQ. 除了私密性這個特點,Telegram 上每天都有大量垃圾信息產生,比如發廣告、聊閑天等,高質量的群組難以發現,這些都增加了執法部門對威脅人物及威脅活動的識別難度.
不法分子在Telegram 上通過頻道或者群聊進行宣傳,再一對一私聊具體細節,如支付途徑、貨品種類等. 固然直接與發布敏感內容的不法分子私聊操作簡便,但Telegram 上用戶量巨大,從可疑群組入手,通過群組消息分析,過濾無用信息,批量找出可疑分子更具有現實意義. 基于以上觀察,本文通過分析可疑群組的聊天記錄來挖掘威脅人物. 然而,傳統的方法對用戶發言進行文本分類,不僅需要大量的人工標注,更需要預設類別,導致分類不全面.
2018 年開始,ELMo 模型[5]、GPT 模型[6]和BERT 模型[7]被相繼提出,大規模預訓練語言模型通過大量未標注的文本學習天然的語言知識,具有強大的語言表示能力,推動了多種領域不同任務的自動化,并帶來了效果提升. 2022 年末,強大的ChatGPT[8]問世,表現出驚人的語言理解、生成、知識推理能力,可以極好地理解用戶意圖,完成各種自然語言處理任務,徹底改變了人們對大模型的認知. 此后,大量的大語言模型應用如雨后春筍般涌現,尤其是在開源社區,如BLOOM[9]、Llama 2[10]、Gemma[11]等,這也為開展深暗網內容分析工作帶來了新方法.
本文提出了一種低開銷的匿名通信群組威脅人物挖掘方法,通過應用無監督主題建模技術提煉有時序特征的關鍵詞,根據無監督主題提取結果的分析和對黑灰產的預先知識設置種子關鍵詞,增加網絡公害特定領域下關鍵詞的重要程度,例如黑灰產流行黑話、不法分子常用動詞等,利用專家知識增加詞的可解釋性,完成主題建模的優化,結合大語言模型的理解和生成能力產生高質量的概括主題詞,并過濾噪聲關鍵詞. 得到主題詞后,使用關鍵詞-用戶關系映射算法處理消息來尋找活躍敏感用戶. 把標注消息類別的傳統有監督文本分類做法轉化為基于標注的主題詞映射到發布網絡公害相關信息的用戶,從而全面高效地挖掘威脅人物. 不但大大降低了人工標注成本,減少在大量無意義信息中搜集有價值可疑信息、發現可疑人物的精力和時間,還對群組內容進行了總結凝練,提高主題詞的質量,并通過多種分析方法多角度得到對網絡公害生態的理解,為有關部門進一步情報分析提供有力支持.
2 相關工作
深暗網內容分析研究的目的是從深暗網數據中挖掘出有價值的信息. 現有的分析工作有直接從加密貨幣和非法交易進行分析的思路. Foley等[12]研究加密貨幣的監測技術,發現約1/4 的比特幣用戶參與了非法活動. Wang 等[13]對基于詞嵌入發現中文黑灰產領域黑話的方法進行了實證研究. 另有工作[14]針對暗網中通過某些身份類別信息無法獲取足夠多訓練樣本的問題,引入少樣本學習任務,構建基于多任務的低資源條件下用戶身份信息聚合模型.
深暗網群組消息中混雜著大量無意義信息和毒品、槍支、色情等敏感數據,對于深暗網群組中大量雜亂無章的消息,內容分析研究的技術路線多是基于機器學習或主題建模等方法展開,將挖掘的線索轉換為可用情報,幫助相關人員了解與分析群組的實際交流內容[15]. Fang 等[16]提出一種識別活躍在不同主題下的黑客的方法,先通過主題建模分析得到中文暗網論壇的常見主題,再利用作者分析方法結合用戶發帖與回復行為,識別每個主題下的活躍黑客. Ghosh 等[17]通過主題建模方法對暗網網站進行分類,首先使用關鍵詞發現技術對網站內容進行分析,然后在標注數據充足和監督數據不足的情況下分別進行主題分類與聚類,都可準確地實現暗網網站的主題標簽分配.這些都給予本工作啟發,借鑒主題建模的路線,無需監督數據,直接對包含大量黑灰產信息的Telegram群組進行主題建模,得到不法分子之間交流的實時熱門主題,并根據主題詞來識別威脅人物.
3 方法描述
作為技術門檻最低的深暗網溝通渠道,Telegram因其極強的隱私保護機制和加密機制被不法分子濫用,每天都有大量威脅用戶在群聊和頻道傳播涉恐、涉毒等危害信息,分析Telegram 群組的特點是非常有必要的.
Telegram 群組在消息形式和內容上與傳統的即時通信平臺不同,有以下3 個特點:(1) 隱式的回復關系[18],用戶看到感興趣的消息不使用明確的回復標記,而是直接發布消息參與討論.(2) 群組中的信息短,特別是關于非法交易,不法分子警戒心很強,幾乎不會在群里向陌生人吐露關鍵信息.(3) 廣告垃圾信息過多,在大量無意義內容中獲取有價值的可疑信息、識別威脅人物猶如大海撈針.
此外,不同主題下的群組,其聊天風格也大不相同. 比如色情、賣數據的群組有大量廣告和代發;有關黑灰產、暗網的寬泛主題群組以買家提需求為主. 對于這些不同類別的網絡公害交流,可以結合大語言模型的知識和已有對網絡公害的理解,通過本文提出的基于時序主題模型的群組內容分析方法自動化監控威脅活動并深入理解網絡公害行業生態,通過本文提出的融合群組內容的威脅人物挖掘方法批量自動化篩選目標主題下的高威脅性活躍人物.
3. 1 基于時序主題模型的群組內容分析方法
關鍵詞是能夠表達文檔中心內容的詞語,提取關鍵詞的方法有3 類:基于統計特征的關鍵詞提取、基于詞圖模型的關鍵詞提取和基于主題模型的關鍵詞提取. Telegram 的群組一般是圍繞特定主題而建的群組,不會出現類似明網聊天軟件中的親友交流群. 因此,使用主題模型能夠挖掘Telegram 群組內容的關鍵詞,有助于了解群組內部實際談論的熱點話題,解決從較短的非結構化文本中提取有效信息的困難.
通過群組主題的時序分析,可以了解到隨著時間推移哪些主題逐漸縮減,哪些主題持續被關注,以及哪些主題是在某個時間段新出現的. 這有助于深入理解深暗網威脅活動內容并據此找出動態敏感話題下的活躍用戶.
常用的LDA[19]等傳統主題建模方法能夠取得不錯的效果,但是需要尋找最優超參數,十分耗費人力,并且這種詞袋模型忽略了詞之間的語義關系,不考慮句子中詞的上下文,影響主題標識效果. 文本嵌入技術可以表示單詞之間的語義關系,能夠解決上述問題. 2018 年Devlin 等提出的預訓練模型BERT[7]以及后續很多工作提出的BERT變體在生成上下文詞向量和句子向量上取得了巨大成功. BERTopic 基于BERT 的強大語言表征能力,可以對大量短文本數據進行高效的建模[20],非常適合提取Telegram 群組消息這種短且非結構化文本的主題.
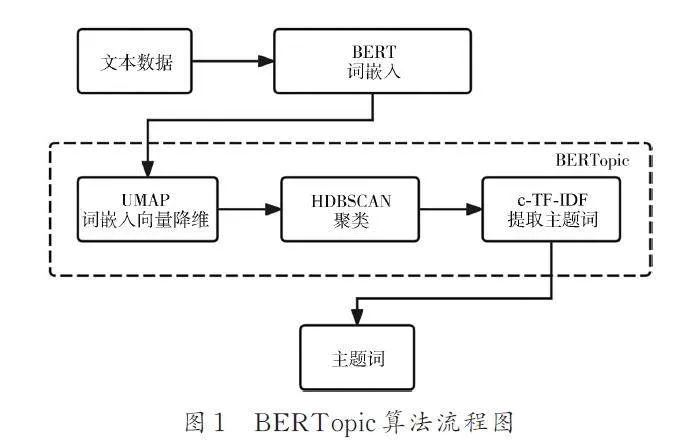
BERTopic 算法的具體流程步驟如圖1 所示.(1) 使用BERT 將文本轉換為密集的向量表示.(2) 降低文本嵌入的維數,然后創建語義相似的文本集群,使用UMAP 算法對詞嵌入向量進行降維,避免維度災難,提高后續聚類算法的效率;使用HDBSCAN 聚類算法對降維后的詞向量進行聚類.(3) 為了克服Top2Vec[21]的缺點,BERTopic單獨對文檔進行嵌入編碼,并不把所有文檔和單詞嵌入到同一空間. 在進行主題詞提取時,把同一主題下的所有文檔視作一個大文檔,通過基于類的詞頻逆文檔頻率(c-TF-IDF)算法,尋找詞頻最高的幾個詞來代表主題. 這3 個獨立的步驟支持了各種應用場景下的靈活建模.
與LDA 不同,BERTopic 不需要預先設定主題數,免去了復雜的超參數調優步驟;訓練時還可以根據實際需求減少主題數量,通過設置參數nr_topics 執行對相似主題的合并. 同時,BERTopic提供了多種可視化圖形,如交互式圖譜、層次縮減樹狀圖、特征詞分布條形圖和時序動態主題演變圖等,可以直觀展示主題提取情況和不同主題隨時間的演變情況. 后續BERTopic 還推出了各種優化版本,包括微調表示模型、聯合應用生成式人工智能、多模態主題建模、引導式主題建模等. 可以根據具體任務的領域特點和需求“定制”主題建模方案. 因此,本研究采用BERTopic 模型對群組消息主題進行提取,并基于此開展群組內容分析.
3. 2 融合群組內容的威脅人物挖掘方法
對于威脅人物的挖掘,傳統的做法為將用戶的群聊發言記錄進行文本分類,得到每個用戶對應的類別,再判斷其類別是否為目標威脅類別. 但這種方式需要大量人工標注,不僅費時費力,也被限制在預定義的類別里,很難完全地發現群組內容的全部類別.
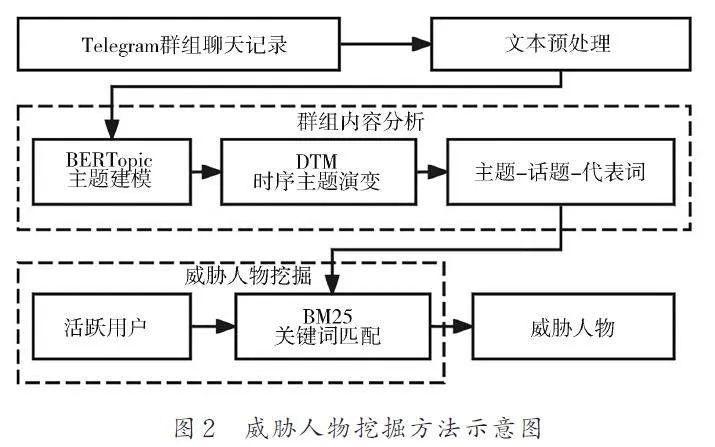
本文提出的威脅人物挖掘方法把對消息進行標注的傳統做法轉化為主題詞的標注,并通過標注的主題詞映射到散布威脅信息的用戶,如圖2 所示. 大大降低了人工成本,保留了群組原本的各種內容,使得威脅人物的挖掘更全面.
在得到群組消息的活躍主題,并從中提取出一些敏感詞后,可將這些敏感詞與活躍用戶的發言進行匹配,從而找出敏感話題下的活躍用戶,鎖定為可疑威脅人物.
BM25 算法最早應用在信息檢索領域[22],用于計算一個查詢句子與文檔集中每篇文檔的相關度,其沿襲了TF-IDF 模型“查詢相關度得分等于詞權重乘以詞相關度得分”的思想,其公式如下.
其中,R (qi,d ) 為查詢語句Q 中每個詞qi 與文檔d的相關度;Wi 是該詞的權重,最后將所有詞的相關度分數累加,即得到查詢語句與文檔d 的相關度.
TF-IDF 算法將文檔建模為詞袋模型,每個詞的重要性與其在文檔的出現頻數成反比. 而BM25 算法將詞相關度得分與詞頻的關系改成了非線性的. 每個詞與文檔的相關度值R (qi,d ) 公式如下.
其中,qfi 為詞qi 在查詢語句Q 中出現頻率;fi 為qi在文檔d 中的出現頻率;dl 為文檔d 的長度;avgdl為所有文檔的平均長度,意思是文檔相對越大、詞相關度越小. k1、k2 和b 為調節因子,b 越大則文檔長度對于相關度的影響越大,通常b=0. 75. 在絕大多數情況下,詞qi 在1 條查詢語句內只會出現1次,即qfi = 1,可以令k2 = 0,簡化上述公式.
在詞重要性權重上,BM25 算法認為文檔中每個特征詞出現是相互獨立的,且只有出現和不出現2 種情況. 權重Wi 一般為逆向文檔頻率,即詞語普遍重要性的度量,公式如下.
其中,N 為文檔總數;n (qi ) 是包含該詞的文檔數;0. 5 是調教系數,避免n (qi ) = 0 的情況. 當單詞只在某一些文檔上出現時,IDF 值比較大;如果在幾乎所有文檔都出現,那么IDF 值非常小,多為常用的無意義詞.
雖然諸如TF-IDF、BM25 等傳統檢索模型在語義檢索精細度上不如基于深度學習的檢索模型,但是在大規模批量篩選階段速度極快、可解釋性強,非常適合本研究通過敏感詞挖掘威脅人物.
文本分類是自然語言處理中的經典任務,此任務是將預定義的類別分配給給定的文本序列,其中一個重要的中間步驟是文本表示. 先前的工作使用各種神經網絡模型來學習文本表示,后來,預訓練語言模型出現,它可以有效學到通用語言表示. 其中,BERT 在多種自然語言理解任務上取得了驚人的效果,有工作[23]研究了如何最大限度地利用BERT 進行文本分類任務,取得了當時最先進的性能. BERT 提出后,又有一些研究提出了基于BERT 進行改進的變體預訓練模型,如ALBERT[24]、ELECTRA[25]等,與BERT 相比在不同的側重點上有所改進. 因而,目前常用的文本分類方法就是基于BERT 或BERT 變體預訓練模型,使用專門的數據集進行微調,再進行文本分類. 有研究表明RoBERTa-wwm-ext-large 是性能最好的中文預訓練語言模型之一[26]. 因此,后續實驗將基于此模型進行文本分類來進行對比實驗,將實驗結果與本文提出的威脅人物挖掘方法進行比較.
4 實驗
4. 1 基本設置
4. 1. 1 數據收集與處理
通過采集系統的帶內群組和帶外群組發現技術,得到了一批不同類別的高質量Telegram 群組,包含毒品、槍支、暗網、政治、加密貨幣等敏感主題. 通過在這些群組中獲取聊天記錄來進行后續內容分析. 其中,有來自暗網導航主題群組的2023 年4 月1 日至4 月16 日共4662 條消息記錄、時政主題群組的2023 年4 月11日至4 月16 日共12 739 條消息記錄、來自槍支和瞄準鏡群組的2023 年4 月6 日至4 月23 日共200條消息記錄、來自毒品群組的2023 年4 月21 日至4月23 日共200 條消息記錄、來自加密貨幣群組的2023 年4 月14 日至4 月18 日共59 283 條消息記錄. 由此可以看出,槍支、毒品群一般是不允許閑聊的,而暗網導航、時政、加密貨幣群組聊天頻次和內容多. 本文以暗網導航群組為例進行后續研究與分析.
在進行主題建模之前,需要對數據進行預處理,首先使用jieba 分詞將原始語料切分成類似英文的文本格式,即用空格間斷詞語;然后使用停用詞過濾方法剔除與一些常見的無意義詞語. 文本預處理是主題建模的重要環節,直接影響模型的效果.
4. 1. 2 模型設置
動態主題模型(DynamicTopic Model, DTM)引入了時間動態的概念,能夠建模不同主題隨時間的演變. 為了構建動態主題模型,除了群聊消息文本,還需要對應的時間戳. 在構建動態主題模型前,需要先初始化BERTopic模型,該模型會把所有時間段中出現的主題提前訓練識別出來. 因而,本文主題建模的順序為,先通過BERTopic 模型對全部消息內容進行主題提取并分析,結合無監督主題建模得到的關鍵詞和對黑灰產的預先知識設置種子關鍵詞,增加流行術語的權重,例如黑灰產流行黑話、不法分子常用動詞等,優化主題模型. 再調用大語言模型自動化為每個關鍵詞組生成主題詞,并過濾關鍵詞組中非相關的噪聲詞. 再在此基礎上構建動態主題模型,分析群組活躍話題隨時間的變化.
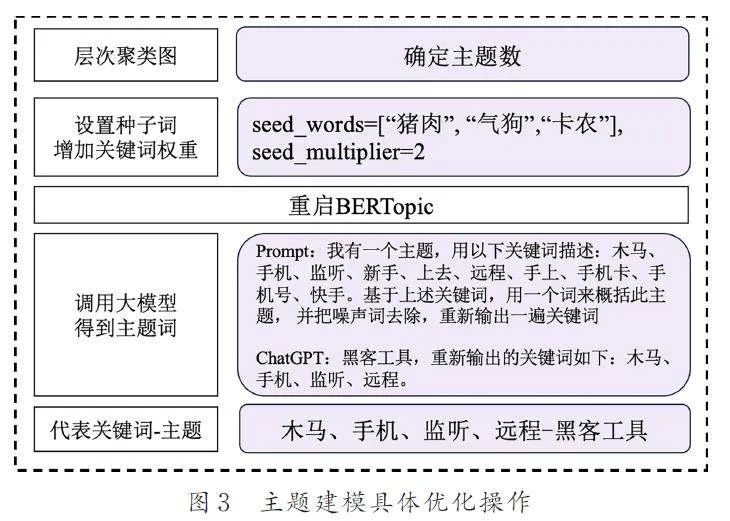
首先,將主題數量設置為“auto”,模型會自動將相似度超過0. 9 的主題對合并,迭代地減少主題數量. 因為本實驗的數據是多條簡短且非結構化的群聊消息,混雜了很多日常用語,每句話的主題性不強,需要尋找合適的主題數量. 使用主題距離圖(Intertopic Distance Map)和層次聚類圖(HierarchicalClustering)可視化主題之間的聯系,根據此確定適當的聚合主題數量,再進行訓練
將網絡公害流行術語加入種子關鍵詞列表,通過seed_multiplier 設置種子詞權重增加的倍數,提高其作為關鍵詞輸出的概率. 將BERTopic 模型提取出主題下的多個關鍵詞,即get_topics()函數返回的關鍵詞組輸入prompt 語句以調用Chat?GPT API,得到概括性的主題詞. 提示設置為:“我有一個主題,是用以下關鍵詞來描述的:[關鍵詞列表]. 基于上述關鍵詞,用一個詞來概括此主題,并把噪聲詞去除,重新輸出一遍關鍵詞”. 最終得到主題-話題-代表詞的對應關系,最后構建動態主題模型,分析主題的熱度演化. 除了ChatGPT,還可以調用其他大語言模型,比如Llama 2[10]、Mistral[27]等. 對BERTopic 模型具體的使用及優化操作如圖3 所示.
4. 2 基準模型
對于威脅人物的挖掘,本方法把對消息進行標注的傳統做法轉化為主題詞的標注,并通過標注的主題詞映射到散布威脅信息的用戶. 為了評估此方法的有效性,本文選用了在RoBERTawwm-ext-large 模型[28]上用人工標注的數據集進行微調得到的文本分類模型,在Ubuntu 18. 04 系統上使用GTX 2080Ti 的GPU 對群聊消息進行多分類,再根據分類結果得到不同類別下的威脅人物,與本文提出的方法進行對比.
4. 3 評價指標
以威脅用戶數量和精確率作為評價指標. 在多分類任務中,考慮某個類別的時候,將其余的類別視為負類,精確率表示預測結果中為正的樣本數目中有多少是真正的正樣本,公式如下.
Precision =TP/TP + FP (5)
其中,TP 為被正確預測的正樣本;FP 為被錯誤預測的正樣本.
4. 4 實驗結果與分析
4. 4. 1 主題建模效果分析
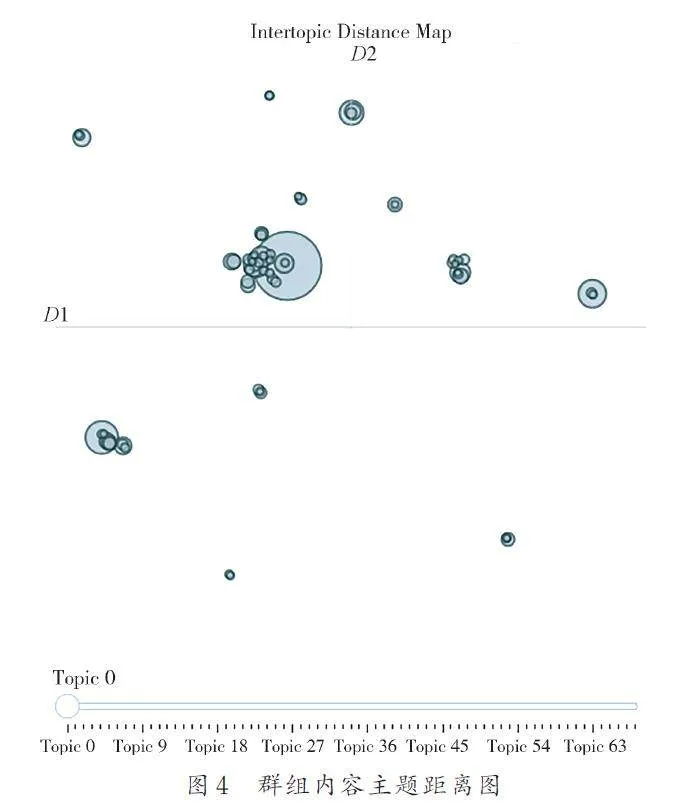
對暗網導航群組的聊天記錄進行主題建模,共生成了111 個主題,啟用自動縮減至86 個主題,可視化得到主題距離圖和層次聚類圖. 圖4 為主題距離圖,每個圓代表1個主題,坐標距離代表了主題間語義相似度,圓圈大小表示該主題在所有文檔中的出現頻率. 從圖4可以看出,此群組消息主題種類豐富,Topic0 是出現頻率最高的主題,有一些頻率較低的主題語義空間上相近,可以合并.
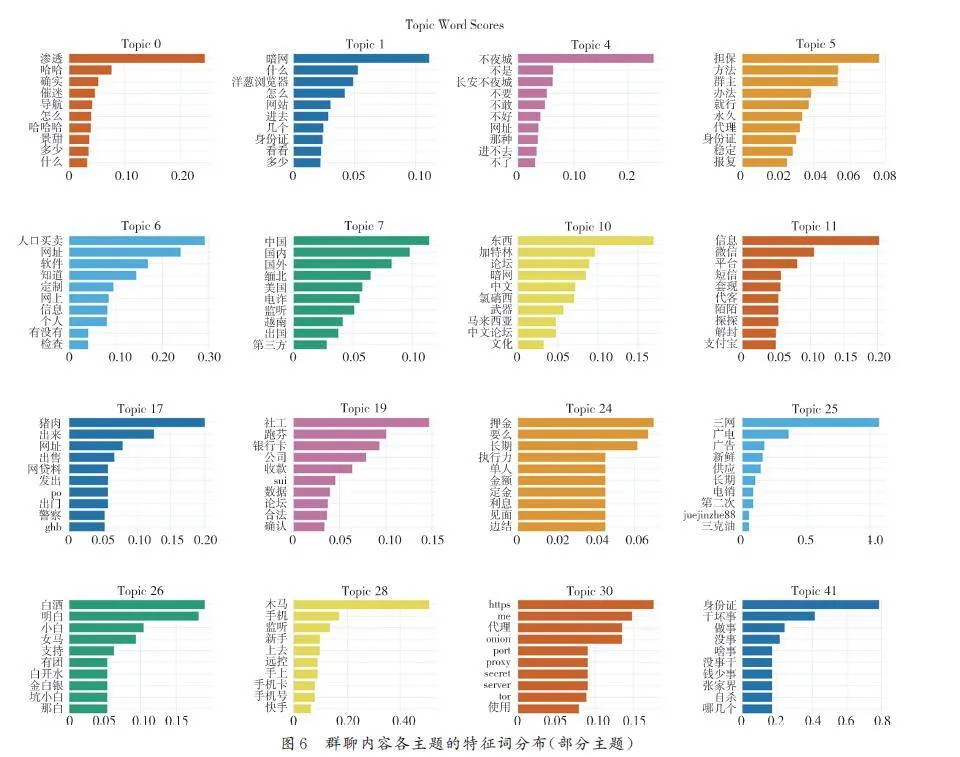
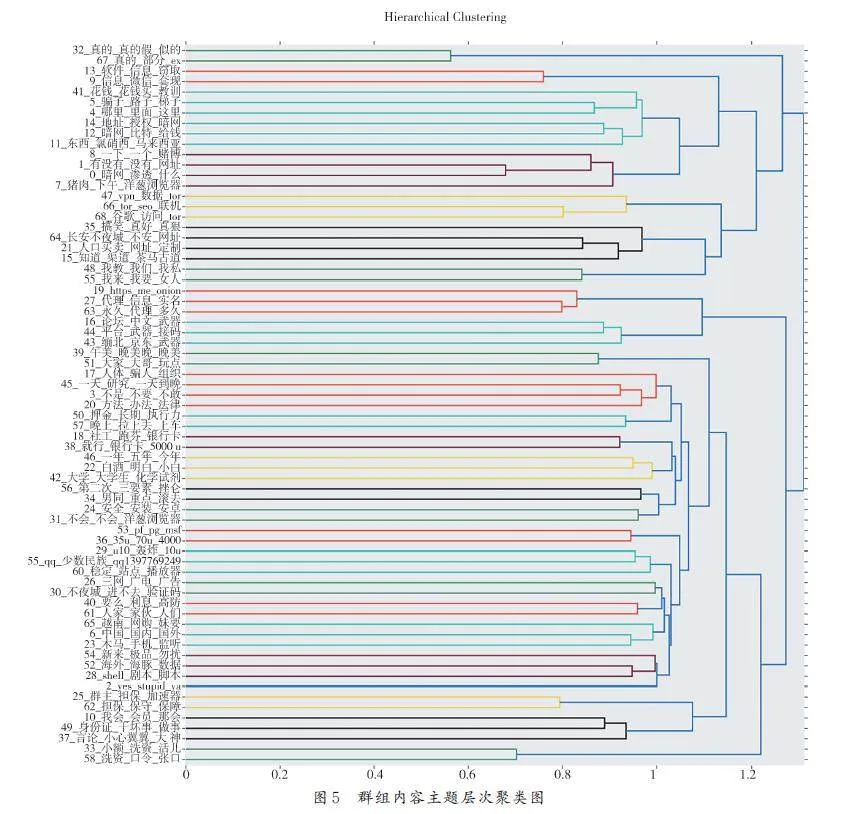
圖5 為主題層次聚類圖,表明了各個主題在不同層次上的關聯,比如Topic9( 社交平臺)和Topic13( 販賣隱私)有直接關聯,與Topic27( 代理)等有間接關聯. 從圖5 可以看出,此時的主題間關聯層次太多,可以大幅縮減,本實驗以折半數量為參照,結合多次嘗試的經驗,將主題數定為49個,并設置種子詞增加關鍵詞的權重,重新啟動BERTopic 模型. 圖6 以條形圖的形式展示了與網絡公害相關的部分話題特征詞,與未設種子詞時相比減少了大量無關噪聲詞,聚類更準確. 因為在威脅活動群組中,不法分子往往避免提及直接與威脅活動相關的詞,而是使用黑話表達有害含義,并且群聊發言頻次極低. 因而人為地融入專家知識,提高低頻但重要術語的權重,可以提高主題建模的質量.
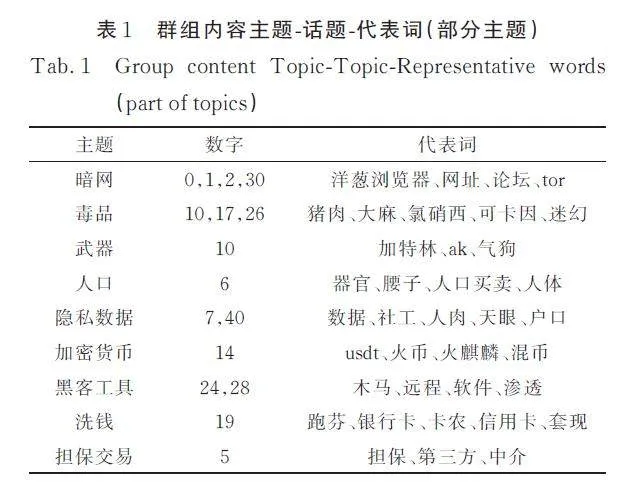
根據模型的輸出形成各話題的代表詞列表,調用大語言模型進行概括,得到精確的主題標簽,并過濾噪聲關鍵詞,以表1 形式展示. 同時可以看到,有“ 張家界自殺”、“ 文心一言”等時事話題出現,表明此群的活躍性,也再次從側面反映出Telegram群組中信息的雜亂. 選取其中的熱門代表詞,如“有沒有”、“usdt”、“跑芬”、“擔保”、“木馬”等詞作為鎖定可疑人物的關鍵詞,再使用BM25 算法找出這些關鍵詞下的活躍用戶.
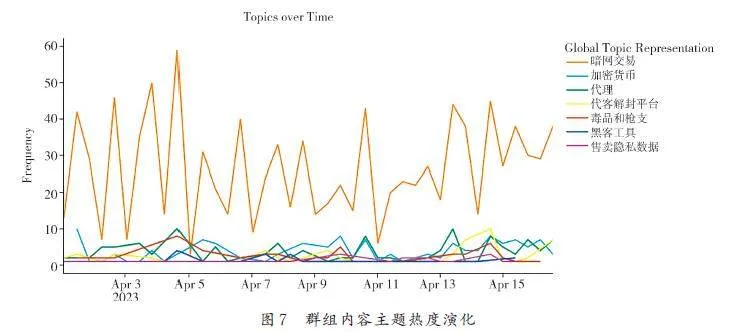
將大語言模型標注的代表性主題進行DTM建模得到圖7,進行主題熱度演化分析. 從圖7 可以看出,多種常見的黑灰產關鍵詞是持續被關注的,群組中討論最多的主題為暗網交易尋求資源.從此角度分析群組用戶組成,可知此群組的交互風格為買家拋出需求,賣家回復或私聊,其中有很多警惕性強的不法分子,消息頻次低、內容簡短或使用黑話.
基于對目標群組的內容分析,提取出具有時序性的活躍主題詞后,用這些關鍵詞匹配群組中的可疑人物. 觀察到Telegram 群組聊天記錄中的散消息現象比較普遍,即用戶習慣將1 條完整語義的消息內容分為多條消息發送,本實驗將同一用戶發表的所有消息拼接在一起,將其和威脅主題詞使用BM25 算法進行相關度計算,從而發現威脅人物.
4. 4. 2 威脅人物挖掘對比實驗結果與分析
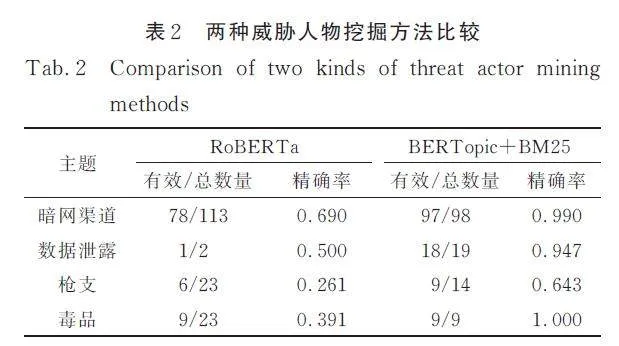
在4662 條消息記錄中,共有1020 名用戶發言,將每個用戶的消息拼在一起. 在中文預訓練模型RoBERTa-wwm-ext-large 上使用1025 條有標注的從高質量群組中獲取到的Telegram 黑灰產文本進行微調,定義類別分別為暗網渠道、數據泄露、槍支、毒品及其他,得到多分類模型,在這1020 名用戶中,共找到113 個暗網類的威脅人物、2 個數據泄露類的威脅人物、23 個槍支類的威脅人物、23 個毒品類的威脅人物. 文本分類方法和主題建模結合關鍵詞匹配方法各自找出的有效威脅用戶數量和精確率如表2 所示.
由實驗結果可知,本文提出的通過主題抽取和關鍵詞用戶映射的威脅人物挖掘方法與用戶消息文本分類方法相比,能夠找到更多數量的威脅人物,且精確率有所提升. 更關鍵的是,文本分類方法需要標注各個類別的文本,構造數據集訓練或微調模型,不僅耗費人工精力,還難以解決深暗網環境下有價值的數據少的問題;而本文提出的方法無需對文本進行標注,可以直接在雜亂的群組內容上挖掘主題詞,并映射到散布威脅信息的用戶,不僅效果得到了提升,還大大降低了成本、提高了效率. 此外,人工標注規則需要隨威脅活動的變化不斷動態變化,比如新興的黑話出現,標注者需要持續長期深入跟蹤威脅活動以獲得最新知識. 而本文提出的方法能夠直接得到最新群組聊天主題以及主題的演化,非常有實際應用價值.
5 結論
深暗網因其強匿名性、交易簡單性、易接入性,已成為散播恐怖主義、交易違禁品的“ 犯罪天堂”,對國家安全與社會穩定構成了嚴重威脅. 由于Telegram 群組對內容無限制且保護用戶隱私,被越來越多的犯罪分子用來傳播敏感消息或進行違禁品買賣.
本文提出了一種低開銷的匿名通信群組威脅人物挖掘方法,針對Telegram 群組消息雜亂、文本短、可用信息有限而導致的有效威脅人物挖掘困難,通過無監督主題建模提煉有時序特征的主題詞,根據無監督主題提取結果的分析和對黑灰產的預先知識設置種子關鍵詞,增加網絡公害特定領域下關鍵詞的重要程度,融合大語言模型提示微調產生高質量的概括主題詞并過濾關鍵詞組中非相關的噪聲詞,得到高質量主題-話題-代表詞組來映射活躍敏感用戶,從而完成威脅人物的批量挖掘. 與傳統的消息文本分類方法相比,大大降低了人工標注成本,保留了群組原本的各種內容,使得威脅人物的挖掘更全面,有效發現潛藏的可疑人物,有助于安全部門深入理解網絡公害生態,并對其參與的威脅活動做出預警干預等,以維護網絡空間安全和社會穩定.
Telegram 群組人員混雜,一次采集到的消息往往是表層且零碎的,還需要繼續深挖其中千絲萬縷的關聯、拼湊分析“蛛絲馬跡”. 未來,我們將探索其他的深暗網分析思路,如深暗網社交網絡關系結構分析、挖掘潛在用戶關聯、關聯用戶多賬號等,參考各領域高速發展技術的新應用,如網絡安全大模型展開進一步工作.
參考文獻:
[1] Alnabulsi H, Islam R. Identification of illegal forumactivities inside the dark net [C]//Proceedings of the2018 International Conference on Machine Learningand Data Engineering (iCMLDE).[S. l.]: IEEE,2018: 22.
[2] Moore D, Rid T. Cryptopolitik and the darknet [J].Survival, 2016, 58: 7.
[3] Setiaji H, Paputungan I V. Design of telegram botsfor campus information sharing [C]//IOP ConferenceSeries: Materials Science and Engineering.[S.l.]: IOP Publishing, 2018, 325: 012005.
[4] Zhu S. Study on comprehensive management strategyof dark net crime[ J]. Network Security Technologyand Application, 2024(3): 136.[朱帥. 暗網犯罪的綜合治理策略研究[J]. 網絡安全技術與應用,2024(3): 136.]
[5] Peters M, Neumann M, Iyyer M, et al. Deep contextualizedword representations [C]//Proceedingsof the Conference of the North American Chapter ofthe Association for Computational Linguistics. [S.l.]: NAACL, 2018: 2227.
[6] Radford A, Narasimhan K, Salimans T, et al. Improvinglanguage understanding by generative pretraining[EB/OL]. [2024-02-24]. https://openai.com/blog/language-unsupervised/.
[7] Devlin J, Chang M W, Lee K, et al. BERT: Pretrainingof deep bidirectional transformers for languageunderstanding [C]// Proceedings of the 2019Conference of the North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies.[S. l.]: ACL, 2019: 4171.
[8] OpenAI. ChatGPT [EB/OL]. [2024-02-24].https://openai. com/blog/chatgpt/.
[9] Workshop B S, Scao T L, Fan A, et al. Bloom: A176b-parameter open-access multilingual languagemodel [EB/OL].[2024-02-24]. https://arxiv. org/abs/2211. 05100.
[10] Touvron H, Martin L, Stone K, et al. Llama 2:Open foundation and fine-tuned chat models [EB/OL]. [2024-02-24]. https://arxiv. org/abs/2307.09288.
[11] Google DeepMind. Gemma [EB/OL]. [2024-02-24]. https://blog. google/technology/developers/gemma-open-models/.
[12] Foley S, Karlsen J R, Putnin? T J. Sex, drugs, andbitcoin: How much illegal activity is financed throughcryptocurrencies?[J]. The Review of Financial Studies,2019, 32: 1798.
[13] Wang C, Shen Y, Li Y, et al. A systematic empiricalstudy on word embedding based methods in discoveringChinese black keywords[J]. EngineeringApplications of Artificial Intelligence, 2023, 125:106775.
[14] Wang Y Y, Zhao J P, Shi J Q, et al. User identityinformation aggregation method for Darknet WebPage[J]. Computer Engineering, 2023, 49: 187.[王雨燕, 趙佳鵬, 時金橋, 等. 暗網網頁用戶身份信息聚合方法[J]. 計算機工程, 2023, 49: 187.]
[15] Yang Y F, Wang N Y. Dark Web Crime intelligenceanalysis[J]. Journal of Intelligence, 2023, 42:42.[楊亞飛, 王諾亞. 暗網犯罪情報分析研究[J]. 情報雜志, 2023, 42: 42.]
[16] Fang Z, Zhao X, Wei Q, et al. Exploring key hackersand cybersecurity threats in chinese hacker com ?munities[ C]//Proceedings of the 2016 IEEE conferenceon intelligence and security informatics (ISI).[S. l.]: IEEE, 2016: 13.
[17] Ghosh S, Porras P, Yegneswaran V, et al. ATOL:A framework for automated analysis and categorizationof the Darkweb Ecosystem [C]//Workshops atthe Thirty-First AAAI Conference on Artificial Intelligence.[S. l.]: AAAI, 2017.
[18] Zhang P, Qi Y, Li Y, et al. Identifying reply relationshipsfrom telegram groups using multi-featuresfusion [C]//Proceedings of the 6th InternationalConference on Data Science in Cyberspace (DSC).[S. l.]: IEEE, 2021: 321.
[19] Jelodar H, Wang Y, Yuan C, et al. Latent Dirichletallocation (LDA) and topic modeling: Models, applications,a survey [J]. Multimedia Tools and Applications,2019, 78: 15169.
[20] Grootendorst M. BERTopic: Neural topic modelingwith a class-based TF-IDF procedure [EB/OL].[2024-02-24]. https://arxiv. org/abs/2203. 05794.
[21] Angelov D. Top2vec: Distributed representations oftopics [EB/OL].[2024-02-24]. https://arxiv. org/abs/2008. 09470.
[22] Robertson S E, Walker S, Beaulieu M, et al. Okapiat TREC-7: Automatic ad hoc, filtering, VLC andinteractive track [J]. Nist Special Publication SP,1999( 500): 253.
[23] Sun C, Qiu X, Xu Y, et al. How to fine-tune bertfor text classification?[C]// Proceedings of the 18thChina National Conference on Chinese ComputationalLinguistics(CCL). Kunming, China: SpringerInternational Publishing, 2019: 194.
[24] Lan Z, Chen M, Goodman S, et al. Albert: A litebert for self-supervised learning of language representations[EB/OL].[2024-02-24]. https://arxiv. org/abs/1909. 11942.
[25] Clark K, Luong M T, Le Q V, et al. Electra: Pretrainingtext encoders as discriminators rather thangenerators [EB/OL].[2024-02-24]. https://arxiv.org/abs/2003. 10555.
[26] Xu L, Hu H, Zhang X, et al. CLUE: A Chinese languageunderstanding evaluation benchmark [EB/OL]. [2024-02-24]. https://arxiv. org/abs/2004.05986.
[27] Jiang A Q, Sablayrolles A, Mensch A, et al. Mistral7B[EB/OL].[2024-02-24]. https://arxiv. org/abs/2310. 06825.
[28] Liu Y, Ott M, Goyal N, et al. Roberta: A robustlyoptimized bert pretraining approach[EB/OL].[2024-02-24]. https://arxiv. org/abs/1907. 11692.
(責任編輯: 伍少梅)
基金項目: 國家重點研發計劃“網絡空間安全治理”專項(2023YFB3106600)
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
