價格引導雙流自注意力序列推薦模型
2024-07-01 10:04:43孫克雷呂自強
廊坊師范學院學報(自然科學版) 2024年2期
孫克雷 呂自強


【摘?? 要】?? 針對傳統序列推薦算法捕獲交互序列中的長期依賴性能力較弱,以及由于數據稀疏性導致推薦結果缺乏個性化的問題,提出了一種價格引導雙流自注意力序列推薦模型。通過融合項目價格信息分析用戶價格偏好并輔助計算項目相似度,提高推薦結果的個性化程度;將兩種信息輸入到兩個獨立的自注意力機制,學習不同位置的重要性、提取其特征,并將輸出進行拼接后輸入到門控單元學習時間依賴性,提高模型的長期依賴性建模能力。在三個公開數據集上驗證了模型的有效性,命中率和歸一化折損累積增益最低提升1.11%,最高提升5.34%。
【關鍵詞】?? 推薦算法;序列推薦;項目價格;自注意力機制;長期依賴性
Price-guided Dual Self-attention Sequential Recommendation Model
Sun Kelei, Lyu Ziqiang*
(Anhui University of Science and Technology, Huainan 232001, China)
【Abstract】??? Aiming at the problem that the traditional sequential recommendation algorithm has a weak ability to capture the long-term dependence in the interaction sequence, and the lack of personalization of the recommendation results due to data sparsity, this paper proposes a Price-guided Dual Self-attention Sequential Recommendation (PG-DSASR). By integrating item price information to analyze user price preference and assist in calculating item similarity, the personalized degree of recommendation results is improved. The two kinds of information are input into two independent self-attention mechanisms to learn the importance of different positions and extract their features, and the output is spliced and input into the gated unit to learn the time dependence, so as to improve the long-term dependence modeling ability of the model. The effectiveness of the model is verified on three public datasets. The hit rate and the cumulative gain of normalized loss are increased by 1.11% at the minimum and 5.34% at the maximum.
【Key words】???? recommendation algorithm; sequential recommendation; item price; self-attention mechanism; long-term dependence
〔中圖分類號〕 TP391????????????? ?? ????? ???〔文獻標識碼〕? A????? ???????????? 〔文章編號〕 1674 - 3229(2024)02- 0029 - 07
[收稿日期]?? 2023-10-27
[基金項目]?? 國家自然科學基金項目(61703005);安徽省高校科研重點項目(2022AH050821)
[作者簡介]?? 孫克雷(1980- ),男,博士,安徽理工大學計算機科學與工程學院副教授,研究方向:推薦系統。
[通訊作者]?? 呂自強(2000- ),男,安徽理工大學計算機科學與工程學院碩士研究生,研究方向:推薦系統。
0???? 引言
隨著互聯網的迅猛發展和廣泛應用,數據呈現爆炸性增長,為了有效處理海量信息,個性化推薦系統[1-2]迅速嶄露頭角。早期的推薦模型主要采用協同過濾[3]的方式來挖掘用戶交互序列中的靜態變化,然而隨著時間推移,用戶的興趣會逐漸演變。為了更準確地捕捉用戶在一段時間內的興趣變化,序列推薦模型[4]應運而生。從最初的馬爾可夫鏈模型[5]到基于循環神經網絡、卷積神經網絡以及自注意力機制[6]的模型,序列推薦領域百花齊放。目前,基于自注意力機制的序列推薦模型成為該領域的研究熱點,但仍然存在一些問題。數據稀疏一直是序列推薦領域難以回避的難題。單一的交互序列嵌入輸入的信息受限,難以有效支持網絡中大量參數的更新,從而影響推薦精度。在自注意力機制中,直接拼接輔助信息與項目嵌入則可能引入額外噪聲。此外,獨立的自注意力網絡難以很好地捕獲交互序列中的長期依賴性。
基于以上分析,考慮到用戶在購物時通常關注商品的性價比,而價格與用戶期望不符的商品在一定程度上可視為噪聲,價格信息作為一種重要的輔助信息能夠有效反映用戶的興趣偏好,可以通過引入價格信息來緩解數據稀疏性問題。為了避免直接拼接異構信息引入額外噪聲的問題,設計了雙流自注意力網絡,分別用于學習項目和價格的轉換模式。隨后,將雙流自注意力網絡與GRU進行融合,提高模型對用戶序列中長期依賴性的捕獲能力,提出一種價格引導雙流自注意力序列推薦模型(Price-Guided Dual Self-Attention Sequential Recommendation Model,PG-DSASR)。為了證明模型的有效性,在三個公共數據集上進行了對比試驗,證明模型在命中率和歸一化折損累積增益的4個指標上有一定的提高。
1???? 相關工作
序列建模的目的是分析用戶歷史交互數據并從中提取特征和規律,從而實現符合用戶偏好的推薦。早期的基于馬爾科夫鏈的模型假設用戶的下一次交互受到前一個或者前幾個交互的影響,這使得它能夠捕獲序列中的短期相關性。然而基于這種假設,它在捕獲用戶-項目交互的復雜的長序列關系時存在較大的局限性。進入深度學習時代,神經網絡被引入到序列推薦領域,它們不僅可以挖掘數據中更深層次的信息,而且具有十分靈活的網絡結構特征。基于循環神經網絡的序列推薦算法[7]能夠從全局的角度考慮整個交互序列,在對用戶的長期偏好進行建模方面具有較大優勢,然而RNN無法很好地長期記憶,它會遺忘之前的信息。受到卷積神經網絡的啟發,將交互序列的嵌入看成圖像并進行卷積操作從而達到提取項目之間局部依賴關系的目的,進而提出了Caser模型[8]。自注意力機制會給那些與下一個交互相關性較大的物品分配較大的注意力權重,反之則分配較小的權重。基于自注意力機制,Kang等[9]提出了SASRec模型。后來Sun等[10]進一步利用雙向Transformer和掩碼預測任務,提出了BERT4Rec模型用于序列推薦。Li等[11]提出TiSASRec模型,在SASRec的基礎上添加了項目的時間間隔信息。除此之外,一些模型針對點擊注意力機制的計算局限進行了改良,例如STOSA模型[12]使用沃瑟斯坦距離來衡量兩個項目之間的相似度。此外,Gholami等[13]提出可解釋性模型PARSRec,它通過融合自注意力機制和循環神經網絡,來挖掘物品之間的深層關系以提高推薦質量。
盡管上述序列推薦模型考慮到了引入輔助信息以緩解數據稀疏性的問題,但卻忽略了直接拼接異構信息可能帶來的額外噪聲,同時在捕獲交互序列的長期依賴性方面存在一定不足。因此,PG-DSASR通過將雙流自注意力網絡與GRU進行融合,不僅成功引入價格信息以緩解數據稀疏性問題,還有效解決了直接拼接異構信息可能產生的額外噪聲,同時提升了模型對長期依賴性的建模能力。
2???? 模型框架
PG-DSASR模型框架如圖1所示,模型的結構包括四個部分,分別為嵌入層、雙流自注意力網絡、長期依賴性建模以及預測層。其中嵌入層將模型輸入轉化為低維嵌入表征;雙流自注意力網絡通過使用兩個多頭自注意力模塊分別提取交互項目信息以及項目價格信息的嵌入表征,然后進行表征融合;長期依賴性建模則通過GRU的重置門將雙流自注意力網絡的輸出[vj]和上一層的隱藏狀態[?j]相結合,并通過更新門進行信息的更新;預測層根據輸出計算用戶下一項可能感興趣的項目。模型的外部結構采用串聯設計的方法,即每個模塊接收一個隱藏狀態和一個輸入,并產生一個輸出和下一個隱藏狀態。
2.1?? 問題定義
序列推薦的任務是利用用戶的歷史行為來預測未來可能感興趣的項目。為了便于表述,將I={[iu1,iu2,iu3,…,iu|I|]}定義為項目集,將P={[pi1,pi2],…,[pim]}定義為項目的價格信息合集,將U={[u1],[u2,u3,…,u|U|]}定義為用戶集。[|I|]表示數據集中不重復項目的數量,m表示價格信息的數量,[|U|]表示數據集中不重復用戶的數量。模型的目標是預測用戶在t+1時刻可能交互的項目。
2.2?? 雙流自注意力網絡
雙流自注意力網絡由兩個獨立的自注意力機制構成,因此可以通過學習兩個嵌入表示的相似性來識別對下一個商品產生重大影響的商品,而不用考慮它們之間的位置關系,且從表征的多個子空間學習比從單個表征學習更靈活。雙流自注意力網絡使用不同的多頭注意力機制處理不同類別的輸入信息,并將輸出的嵌入表征進行拼接,然后輸入到線性層以調整維度和壓縮語義,如圖2所示。
模型在計算鍵K、值V和查詢Q之間的點積的過程中,K和V是相同的,它們的行均是項目的嵌入和項目價格信息嵌入。然而矩陣Q是不同的,它是由用戶嵌入和上一個隱藏狀態拼接而成的。為了緩解過擬合,提高穩定性,并加快訓練過程,網絡架構添加了層歸一化(LN)和Dropout。
[MultiHead(Q,K,V)=FC(Concat(?eadl1,?eadl2,… ,?eadlh)⊙Concat(?eadp1,?eadp2,… ,?eadph))]???? ? (1)
[?eadi=Attention(QWQi,KWKi,VWVi)]????? (2)
[Attention(Q,K,V)=Softmax(QKTd/?)V]???? (3)
其中,FC是全連接層,[⊙]表示對多頭自注意力機制的輸出表征進行拼接,h表示head的數量,[WQi∈Rdq×dq],[WKi∈Rdk×dq],[WVi∈Rdv×dq]是模型學習得到的參數,[dk]是健和值的維度,[dq]是查詢的維度。第m行的健、值和查詢分別為:
[Q=Concat(EU,?j)]?????? (4)
[m_throw(KI)=m_throw(VI)=EIi(S)m]?????? (5)
[m_throw(Kp)=m_throw(Vp)=EPp(S)m]??? (6)
在處理多維稠密數據集中的豐富結構和互動關系時,單層的雙流注意力網絡的模型容量可能會受到限制,導致編碼和表示能力不足。通過引入更多的注意層,模型能夠逐步學習和捕捉數據中更豐富、更復雜的關系,可以很好地解決上述問題。每一層的注意力機制都可以專注于不同層次的特征和關聯,從而提供更全面的編碼和表示。具體而言,可以使用相同的查詢Q來堆疊多個注意層,并將上一層的輸出作為下一層的鍵K和值V,使模型可以建立起更深入的理解和上下文依賴。
2.3?? 長期依賴性建模
模型中將雙流自注意力網絡與門控循環單元相結合,有助于幫助模型更好地捕獲交互序列中的長期依賴關系。雙流自注意力網絡的輸出作為GRU模塊的輸入,并且將查詢Q作為隱藏狀態輸入到GRU內部,計算過程如公式(7)~(10)所示:
[zt=σ(Wz?[?t-1,vt])]???? (7)
[rt=σ(Wr?[?t-1,vt])]????? (8)
[?t=tanh (W?[rt⊙?t-1,vt])]?? (9)
[st=(1-zt)⊙st-1+zt⊙?t] (10)
其中,[σ]表示sigmoid激活函數,用該函數可以將數據映射到0到1之間的范圍,從而充當門控信號,[zt]和[rt]分別為更新門和重置門,[vt]是t時刻自注意力層的輸出,在此作為門控循環單元的輸入,[?t]是當前時刻的候選隱藏狀態,[st]代表了用戶在t時刻的偏好狀態。
隱藏狀態攜帶用戶信息和序列的當前狀態,為了確保它不會隨著數據的更新而消失,模型在每一步都將用戶嵌入連接到隱藏狀態。初始隱藏狀態對交互歷史進行編碼,這是用戶歷史操作中嵌入項目的加權平均值。隨后,將這些信息提供給GRU可以提高模型的預測精度,其中的更新門負責保存適量的記憶信息,重置門負責將記憶信息與雙流自注意力網絡的輸出信息融合。
2.4?? 預測層
在每一步使用GRU的輸出來預測下一個項目。將GRU的輸出乘以[EI],得到一個大小為|V|的相似向量。具有較高值的索引表示接下來更有可能與之交互的項,對這個向量進行排序,并在此基礎上進行下一個項目的推薦。模型采用交叉熵函數作為損失函數:
[L=-log(exp (y[target])kexp(y[k]))2]??? (11)
其中,y是輸出,target是要預測的真實項目[V'j+1]。
3???? 模型驗證
3.1?? 數據集
為了驗證模型的推薦效果,選取三個廣泛使用的公開數據集Yelp、Amazon Book和MovieLens-1M。Yelp是美國著名商戶點評網站,Yelp數據集由來自8大都市區域的約16萬商戶和800多萬條評論等數據構成;Amazon Book是從亞馬遜平臺收集來的商品評論數據集;MovieLens-1M 是廣泛使用在推薦系統中的基準數據集,包含上千用戶及其對各類電影的評價。為了方便起見,下文采用“Book”和“Ml-1M”作為簡稱。數據集詳細內容如表 1 所示。
3.2??? 評價指標
為了評估提出的模型的有效性,使用命中率HR@K(hit ratio)和歸一化折損累積增益 NDCG@ K(normalized discounted cumulative gain)作為評價指標,其中K為推薦列表的長度。評價指標的值越大,則表示模型的推薦性能越高。
(1)HR@K表示成功推薦的用戶在所有用戶中的比例,計算公式如下:
[HR@K=nN]? (12)
其中[n]表示推薦正確的項目的數量,[N]代表參與計算的項目數量。
(2)NDCG@K表示成功推薦的結果在推薦列表的排名,分值越高,排名越靠前。計算公式如下:
[NDCG@K=1|Z|U i=1k 2r(i)?1log2(i+1)]???? (13)
其中r(i)是第i個項目與正樣本之間的相關性分數,值為1和0,分別表示正樣本和負樣本。
3.3?? 對比模型
為驗證PG-DSASR模型的推薦性能,選取GRU4Rec、SASRec、TiSASRec和PARSRec四個模型進行了對比試驗,模型介紹如下:
(1)GRU4Rec[7] 基于循環神經網絡的深度學習推薦模型;
(2)SASRec[9] 首個使用純注意力機制進行序列推薦的模型;
(3)TiSASRec[11] 2020年提出的基于自注意力機制的序列推薦模型,引入顯性的交互時間間隔到Transformer網絡中;
(4)PARSRec[13] 2022年提出的融合自注意力機制和循環神經網絡的推薦模型。
3.4?? 實驗結果對比與分析
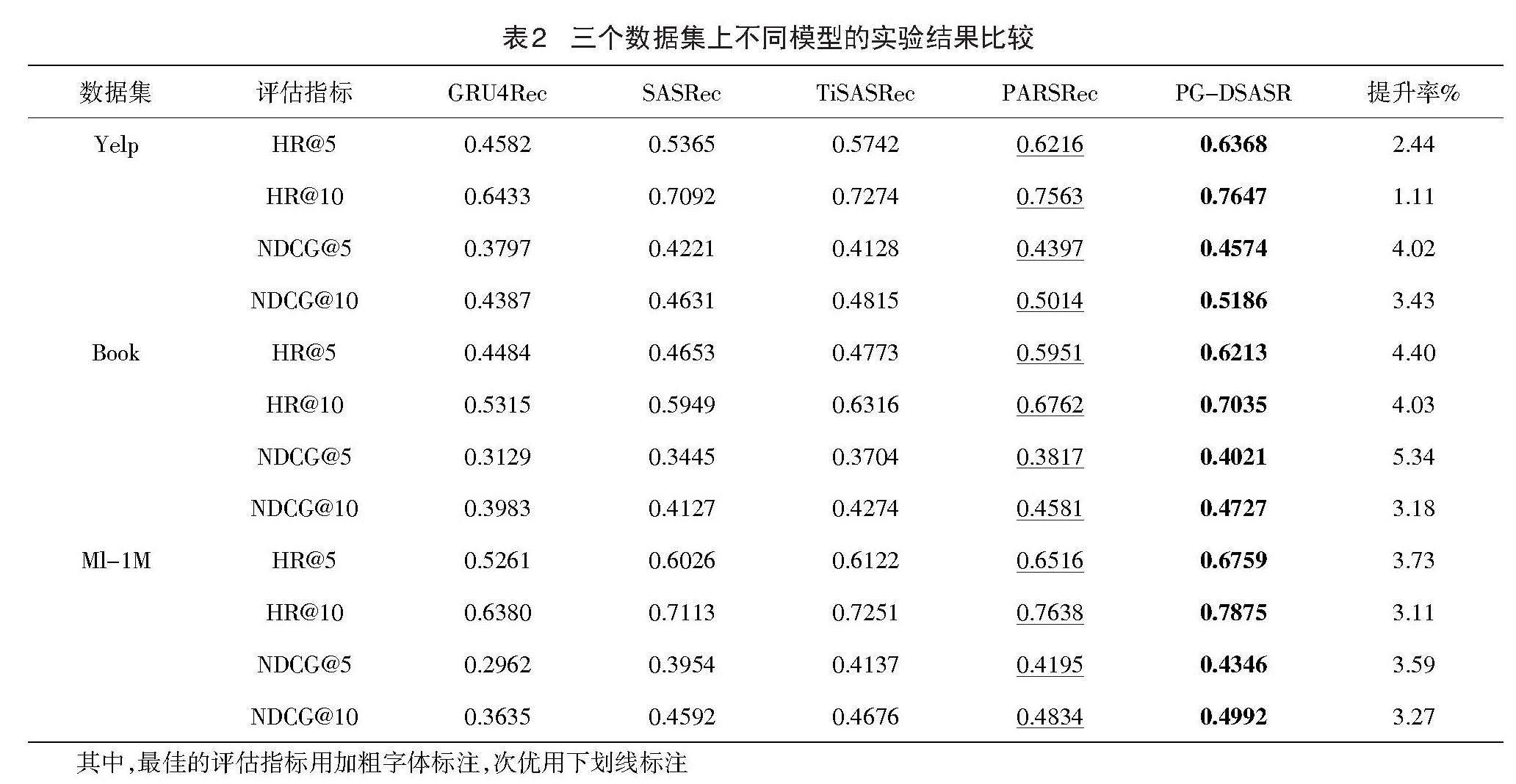
實驗中將數據集劃分為訓練集、驗證集和測試集,將樣本序列的最后一項用作測試,倒數第二項用于驗證,其余則為訓練使用。在訓練過程中采用學習率為0.001、[β1]=0.9、[β2]=0.999的Adam和Sparse Adam優化器進行優化,各項實驗參數采用原論文中的默認值,超參數根據實際情況調整,評估指標的K值分別取5和10。表2顯示了所有模型在三個數據集上的模型性能。實驗結果分析如下。
PG-DSASR模型在三個數據集上都展示出了最好的性能,在Yelp數據集中與次優模型相比,HR@5和HR@10分別提升了2.44%和1.11%,NDCG@5和NDCG@10分別提升了4.02%和3.43%;在Book數據集中與次優模型相比,HR@5和HR@10分別提升了4.40%和4.03%,NDCG@5和NDCG@10分別提升了5.34%和3.18%;在Ml-1M數據集中與次優模型相比,HR@5和HR@10分別提升了3.73%和3.11%,NDCG@5和NDCG@10分別提升了3.59%和3.27%。評估指標的提升說明:PG-DSASR模型使用雙流自注意力網絡分別提取交互項目信息和項目價格信息,避免了直接融合異構信息而產生噪聲,并且融合了門控循環單元的網絡結構,可以同時學習交互項目之間的時間依賴性和不同位置的重要性。GRU4Rec相比于PG-DSASR推薦效果不佳的原因是傳統的循環神經網絡架構參數較少,無法很好地捕獲序列特征,序列建模能力較弱。SASRec相比于PG-DSASR推薦效果不佳的原因是沒有解決數據稀疏問題,而且單純的自注意力網絡結構在捕獲交互序列中的長期依賴性方面效率較低。TiSASRec相比于PG-DSASR推薦性能不佳的原因是:直接將序列信息與時間間隔信息融合進行注意力計算會產生額外噪聲,并且網絡結構單一,無法很好地捕獲交互序列中的長期依賴性。PARSRec的推薦性能優于SASRec和TiSASRec的原因是:將自注意力機制與RNN融合,提高了模型在挖掘交互數據深層次信息方面的能力,但是它沒有考慮緩解數據稀疏問題,且RNN存在遺忘性無法很好地保留信息,最終導致推薦效果不佳。通過表2可以看出PG-DSASR在Book數據集上評估指標的提升最明顯,因為Book相比于Yelp和Ml-1M數據更稀疏,驗證了模型考慮價格信息對緩解數據稀疏性的有效性。
3.5?? 消融實驗
3.5.1??? 模型結構分析
為了了解模型的各個組成部分對整體性能的影響,進行了一系列的消融實驗。表3總結了最優模型和其變體在三個數據集上的性能,變體如下:
(1)PG-DSASR-P 去除價格信息輸入;
(2)PG-DSASR-D 使用單一的自注意力網絡;
(3)PG-DSASR-G 使用普通RNN代替門控循環單元。
通過對比結果,可以得知價格信息在反映用戶偏好方面起著關鍵作用。如果將價格信息排除在用戶畫像之外,可能導致用戶畫像的不完整,進而影響推薦結果的個性化程度。此外,去除價格信息后數據稀疏性問題變得更加突出,進而影響推薦結果的質量。因此,可以看出引入價格信息有助于提升模型的推薦能力。將價格信息與項目交互嵌入進行線性拼接,并輸入自注意力機制,發現最終模型性能下降,原因在于直接融合異構信息進行點積自注意力計算會引入額外的噪聲。因此,使用雙流自注意力機制分別提取異構信息可以顯著提高模型的推薦質量。
另外,采用普通的RNN模塊會導致模型性能下降,因為在實際運用中,RNN存在梯度爆炸的問題,導致忘記較遠的信息。相比之下,GRU通過其精妙的門結構,合理地遺忘和保留信息,信息能夠長期傳遞下去。因此,選擇GRU能夠有效解決梯度爆炸的問題,有助于提升模型的長期依賴建模能力。
3.5.2?? 模型各組件對評估指標的影響
測試模型中各個組件以及網絡設計的一些變化對模型性能的影響,結果如表4所示。
根據表4的數據可以得知,Dropout在降低過度擬合的風險、增強模型的泛化能力方面發揮了積極作用。另外,Layer Normalization(LN)的使用有助于減少不同樣本之間的浮動,提高模型的穩定性和訓練速度。數值表明,移除Dropout和LN都導致模型的總體性能下降,進一步證明它們的存在對提高推薦模型的質量起到關鍵作用。
此外,從LN中移除Q同樣會降低推薦性能。這是因為Q中包含了用戶的歷史記錄信息,而通過殘差操作將其添加到GRU輸入中有助于提升推薦性能。因此,可以看出Q的存在對于充分利用用戶的歷史信息、提高推薦性能至關重要。
3.5.3?? 雙流自注意力網絡層數對評估指標的影響
圖3展示了雙流自注意力網絡不同層數的設置對模型推薦性能的影響。對網絡層數從1到4分別進行了消融實驗,評估指標采用NDCG@10。
根據圖3的觀察結果,可以得知增加雙流自注意力網絡的層數對模型整體性能的影響并不十分顯著。當層數達到2時,評估指標達到峰值,相較于其他層數只有輕微的提升。這表明一層雙流自注意力網絡已經能夠捕獲大部分的數據信息,而增加到兩層時信息挖掘的能力已經趨于飽和。進一步增加層數反而可能導致性能下降,說明層數的繼續增加并不會帶來額外的正面效果。
4???? 結論
本文提出的價格引導雙流自注意力序列推薦模型通過引入價格信息成功緩解了數據稀疏問題。該模型采用了兩個獨立的自注意力機制,分別處理價格信息和序列信息,以避免產生額外的噪聲。通過將自注意力機制和門控循環單元融合,分別學習交互序列的時間依賴性和不同位置的重要性,從而對長期依賴關系進行有效的建模,最終提高了模型的個性化推薦能力。在三個真實數據集上的評價指標相較于近期提出的基線模型均取得了顯著的提升。未來的工作將著重研究如何更好地捕獲用戶的短期興趣,并將其融入模型,以進一步提升推薦性能。這個方向的深入研究將有助于模型更全面、準確地理解用戶興趣動態,從而更好地滿足個性化推薦的需求。
[參考文獻]
[1] 劉姍姍, 游健強, 史家朋, 等. 網絡信息爆炸時代消費行為決策的公眾評價效應分析——以大眾點評為例[J]. 內蒙古科技與經濟, 2022(13):64-66.
[2] 劉君良, 李曉光. 個性化推薦系統技術進展[J]. 計算機科學, 2020, 47(7):47-55.
[3] Linden G, Smith B, York J. Amazon. com recommendations: Item-to-item collaborative filtering[J]. IEEE Internet computing, 2003, 7(1):76-80.
[4] 于蒙, 何文濤, 周緒川, 等. 推薦系統綜述[J]. 計算機應用, 2022, 42(6):1898-1913.
[5]? Steffen? Rendle,? Christoph? Freudenthaler,? Lars? Schmidt-
Thieme. Factorizing personalized Markov chains for next-basket recommendation[A]. Proceedings of the 19th International Conference on World Wide Web[C]. New York: Association for Computing Machinery, 2010: 811-820.
[6] Ashish V, Noam S, Niki P, et al. Attention Is All You Need[A]. Proceedings of the 31st International Conference on Neural Information Processing Systems[C]. Red Hook:Curran Associates Inc, 2017:6000-6010.
[7] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint arXiv:1511.06939, 2015.
[8] Tang J, Wang K. Personalized top-n sequential recommendation via convolutional sequence embedding[A]. Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining[C]. New York:Association for Computing Machinery, 2018: 565-573.
[9] Kang W C, McAuley J. Self-attentive sequential recommendation[A]. 2018 IEEE International Conference on Data Mining (ICDM)[C]. Singapore:IEEE, 2018:197-206.
[10] Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations?? from Transformer[A]. Proceedings of the 28th ACM International Conference on Information and Knowledge Management[C]. New York:Association for Computing Machinery, 2019:1441-1450.
[11] Li J, Wang Y, McAuley J. Time interval aware self-attention for sequential recommendation[A]. Proceedings of the 13th International Conference on Web Search and Data Mining[C]. New York:Association for Computing Machinery, 2020:322-330.
[12] Fan ZW, Liu ZW, Yu W, et al. Sequential Recommendation via Stochastic Self-Attention[A]. Proceedings of the ACM Web Conference 2022[C]. New York:Association for Computing Machinery, 2022:2036-2047.
[13] Ehsan Gholami, Mohammad Motamedi, Ashwin Aravindakshan. PARSRec: Explainable Personalized Attention-fused Recurrent Sequential Recommendation Using Session Partial Actions[A]. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining[C]. New York:Association for Computing Machinery, 2022: 454-464.
