面向多核CPU/眾核GPU 架構的非結構CFD共享內存并行計算技術
2024-05-09 10:16:46張健李瑞田鄧亮代喆劉杰徐傳福
航空學報 2024年7期
張健,李瑞田,鄧亮,*,代喆,劉杰,徐傳福
1.國防科技大學 并行與分布計算全國重點實驗室,長沙 410073
2.中國空氣動力研究與發展中心 計算空氣動力研究所,綿陽 621000
計算流體力學(Computational Fluid Dynamics,CFD)在現代工業和科學中發揮著重要作用,可用于模擬和預測流體運動的物理和化學特性,有助于改進產品(例如汽車、飛機和建筑物等)的設計和制造。目前主流的工業CFD 軟件幾乎都采用非結構網格,主要是因為非結構網格比結構網格更適合處理復雜的幾何外形,而且可以自適應地調整網格大小和形狀,更好地適應流體流動的特征。此外,非結構網格能夠更好地處理移動邊界和多相流體等復雜問題,具有更好的可擴展性和靈活性。CFD 軟件的發展一直被高性能計算(High Performance Computing,HPC)技術推動,高性能計算能力的飛速發展可以用更精細的網格和更高保真的方法計算更復雜的飛行構型[1],比如大 渦模擬(Large Eddy Simulation,LES)或直接數值模擬(Direct Numerical Simulation,DNS)[2]、數值虛擬飛行[3]、真實物理/化學過程模擬[4]等。當前的高性能計算已邁進E 級時代[5-6],多核CPU(Central Processing Unit)/眾核GPU(Graphics Processing Unit)架構成為主流。截至2022 年末,世界Top 500 超級計算機的前10 名(除排名第2 的日本Fugaku 外)都是基于該類架構。近年來,中國在可擴展并行算法及并行應用方面取得世界領先成果[7],但是面臨新型高性能體系架構,必須轉變傳統的并行計算范式[8]。特別是,在當前工業軟件自主可控備受關注的背景下,實現自主工業軟件與國產高性能計算的深度融合是重要發展趨勢。
傳統的并行化方法是利用區域分解思想對計算網格進行剖分,采用MPI(Message Passage Interface)通信庫支持并行開發。然而隨著分區數的增多,不僅通信開銷加大、并行效率降低,而且算法收斂效率也急速下降。新型高性能體系架構下,應采用MPI+X 多層次并行編程模型,即計算節點間基于MPI 并行,而節點內采用統一的一種共享內存并行編程模型X,一般為OpenMP(Open Multiprocessing)、OpenACC(Open Accelerators)、CUDA(Compute Unified Device Architecture)或OpenCL(Open Computing Language)等。當前高性能計算系統的單節點計算能力已得到大幅提高,因此設計一種高效的節點內共享內存并行算法對提升多核CPU/眾核GPU 架構下非結構CFD 應用浮點效率顯得尤其重要。但是,這類非結構CFD 計算的共享內存并行化存在兩個方面的挑戰:一是大量的間接索引進行數據規約操作會引起數據競爭(data racing)問題,導致無法直接并行化;二是非規則、非連續數據訪存導致數據局部性差、浮點計算性能極低。應對這些挑戰的策略大致可分為兩類:第1 類直接對程序內的循環體進行并行,比如使用OpenMP 編程模型,通過添加簡單的pragmas 指令以實現循環級并行,其中數據競爭問題采用原子操作、著色或規約等方法來解決[9];第2 類是基于數據剖分加任務并行的策略,在MPI 進程內再次劃分任務子域,為每個任務創建線程,不同任務并行執行,并根據數據依賴關系設計合理的任務調度,避免數據競爭[10]。兩類方法在性能和平臺適應性方面各有優劣。循環并行最適合于規則化計算中的結構化并行,而任務并行最適合于不規則或遞歸算法中的非結構化并行[11]。相較于循環并行,眾核GPU 架構下任務并行的支持還不夠廣泛或成熟。多核CPU 架構下的并行編程模型雖然支持任務并行,但缺乏對應用的特性支持。需針對特定問題進行數據剖分。因此,需要結合非結構CFD 應用特點開展針對性研究。
NNW-FlowStar軟件[12](FlowStar)是由國家數值風洞工程資助建設的自主流體仿真工業軟件,核心求解器基于非結構有限體積方法和MPI 并行技術開發。為適應新型硬件發展趨勢,需要進一步發展MPI+X 多層次并行技術。王年華等基于原子操作開展了MPI+OpenMP 混合并行策略研究[13]。張曦等開展了面向GPU 的圖著色方法性能優化工作[14]。Gomes等在開源軟件SU2 上實現了多種循環并行策略,且支持在著色和規約方法之間自動切換,以平衡效率和魯棒性[15]。Al Farhan和Keyes 基于剖分復制方法在NASA(National Aeronautics and Space Administration)的PETSC-FUN3D 上實現了多核架構下的多線程并行[16]。Fournier 等在法 國電力 集團的程序Code_Saturne 上基于著色算法實現了兩種不同的循環并行算法[17]。綜上,目前針對非結構網格CFD 共享內存并行的研究主要集中在循環并行類的方法,任務并行方法的實踐還較少,僅在有限元軟件中開展了少量研究[10,18]。在多核CPU/眾核GPU 架構下,具體哪種方法適用于復雜的工業級CFD 軟件缺乏統一認識,同時現有方法在訪存優化方面仍有提升空間,需要進一步深入探索。
本文在FlowStar 軟件上實現多種循環并行和任務并行的方法,全面對比分析各個方法的優缺點以及平臺適配性,以期為面向多核/眾核架構下的非結構CFD 并行計算提供重要參考。同時,針對非結構網格CFD 計算訪存效率低下問題,集成網格重排序、循環融合、多級訪存等多種工程實用的優化策略。最后,通過M6 機翼和CHN-T1 飛機等三維非結構網格算例進行性能測試,驗證該方法的效果。
1 問題描述
1.1 格心型非結構網格有限體積方法
FlowStar求解的主控方程為雷諾平均N-S方程(Reynolds-Averaged Navier-Stokes,RANS),采用基于格心的有限體積法進行離散求解。
式中:t 為時間變量;Ω 為控制體的體積;?Ω 為控制體封閉面的面積;W 為守恒變量;Fc為無黏通量;Fv為黏性通量;S 為面積;Q 為源項。對于格心型有限體積方法,控制體就是網格單元體,流場變量與單元質心相關聯。對式(1)進行離散,得到對特定控制單元ΩI的形式為
式中:I 為序號,對應網格單元編號;NF為該網格單元擁有的面數目;ΔSm為第m 個網格面的面積。
對于結構網格,可以通過索引IJK 表示計算空間,直接對應于流場變量在計算機中的存儲方式,這種特性可以很方便地獲取網格實體(點、面、體)間的鄰接關系。而非結構網格不具備該屬性,網格實體通常沒有規則的排列順序,需要額外的數據結構來存儲網格拓撲信息。非結構網格數據結構可以抽象地視為點、面、體等網格實體的集合,物理量定義在這些集合上,并且需要顯式定義網格實體之間的連接性信息。對于格心型求解器,數值操作主要是在控制單元的表面,通過獲取相鄰單元中心的值來進行計算,因此采用基于面的數據結構是很自然的。例如,當求解離散化的控制方程式(2)時,必須提供控制體面心位置的通量。如圖1 所示,為計算面f0的通量,需要提供指向共享該面的兩個單元體(c0和c1)的索引指針,以訪問這兩個控制體的流場變量。
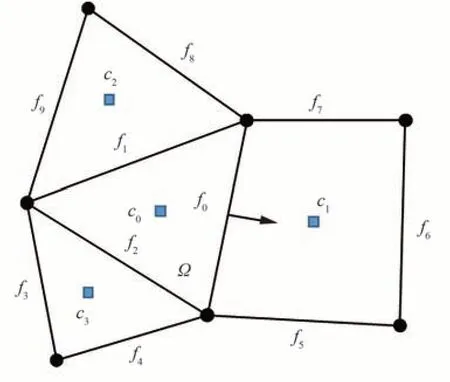
圖1 格心型求解策略網格拓撲數據結構Fig.1 Grid topology data structure of cell-centered scheme
在完成式(2)的右端項求解后,計算得到每個控制單元的殘差R,然后通過時間離散方法推進求解,逼近最終解。
式中:A 為系統矩陣;ΔW 為解的更新;Δt 為時間步長;n 為迭代步。
1.2 非規則訪存模式下的數據競爭問題
在非結構網格上的計算一般都是在網格實體集合上的循環,每一個網格實體執行相應的函數內核。在FlowStar中,右端項殘差的計算可以拆分成多個基于面或體循環的計算內核。如果一個集合上的循環只在執行內核期間寫入該集合上定義的數據,那么循環的每次迭代都可以并行運行。然而如果存在數據間接訪存的情況,可能有從多個集合的迭代同時更新相同內存位置數值的情況,從而造成數據競爭問題。這種存在間接訪存的循環在基于非結構網格的CFD 應用中很常見,如無黏通量的計算就屬于這類情景(算法1)。
在算法1中,面循環的計算遵循收集-分散(gather-scatter)的訪存模式。在計算面的通量時,首先需要從面左右兩端的體收集變量數據,計算完成后再完成相同體索引位置上的物理量更新。由于同一個面可能被多個體共享,如果不加以控制,不同線程同時更新可能導致數據沖突。以圖1 為例,f0、f1、f2如果分屬不同線程,在分別完成各自的通量計算后,可能同時更新c0的物理量,導致錯誤計算。因此,需要找到解決數據競爭問題的方案,實現非結構CFD 共享內存并行化。

2 非結構CFD 共享內存并行化方法
詳細介紹在FlowStar 上實現的5 種共享內存并行方法,其中原子操作、規約和著色方法屬于循環并行類,剖分復制、分治法屬于任務并行類。
2.1 原子操作
原子操作和鎖是典型的保證線程安全的解決方案,可用于保護對潛在沖突內存位置的訪問,其優點是幾乎不需要更改代碼,例如通過調用CUDA 內核的atomicAdd 實現聚合累加操作(算法2)。然而,當頻繁出現沖突時,方案的可擴展性有限。這是因為當多個原子更新同時應用到同一個內存位置時,每個單獨的更新都是串行的,且順序是任意的,這會降低原子更新的吞吐量[19]。

2.2 規約策略
規約策略(Reduction)的基本原理是將面循環計算的gather和scatter 過程分離。如算法3 所示,面循環計算得到物理量后不更新到體上而是先存起來,然后再進行體循環,完成物理量的規約。拆分出的兩個循環均無數據沖突,因此可以并行。規約策略除了需要耗費額外的內存外,另一個缺點是數據局部性較差,因為對循環進行了拆分,在讀取數據和寫入數據時都不能很好地重用數據。
2.3 面著色技術
面著色對相鄰面使用不同顏色(color)進行標記,屬于同一顏色的面之間不會產生任何數據沖突,從而保證同一顏色組內的計算可以并行開展,如圖2 所示。


圖2 對網格面進行著色Fig.2 Face coloring of meshes
算法4 給出了基于面著色技術的OpenMP 并行實現偽代碼。按照顏色順序進行計算,對每個顏色內的循環并行化。面著色技術比較通用,可以移植到其他硬件平臺上(比如GPU)[20],但缺點是在不連續的面上循環計算,數據局部性較差,甚至低于規約策略。

為改善圖著色算法的數據局部性,在Flow-Star 中進一步實現了分組著色的并行算法。與面著色處理單個面單元不同的是,分組著色處理的基本單元是擁有固定面數的分組。如圖3 所示,著色后同一種顏色的面中含有若干個groupsize的面分組,組與組之間不存在數據競爭。算法5給出了基于分組著色技術的OpenMP 并行實現偽代碼。為了完成細粒度并行任務調度,同一面分組內的面序號(faces)需要重排以實現連續存儲,其中調度模式schedule(static,groupsize)表明每個線程會處理groupsize 大小的面分組單元。事實上,當groupsize=1時,分組著色就退化成了普通的著色算法。分組著色的一個缺點就是groupsize 的大小選取經驗性強,需要根據具體網格大小和機器緩存進行優選,如果太大可能造成分組著色不成功,如果太小會導致數據局部性不夠,影響性能。在后續的性能測試中,根據多次測試優選,選取groupsize=512。

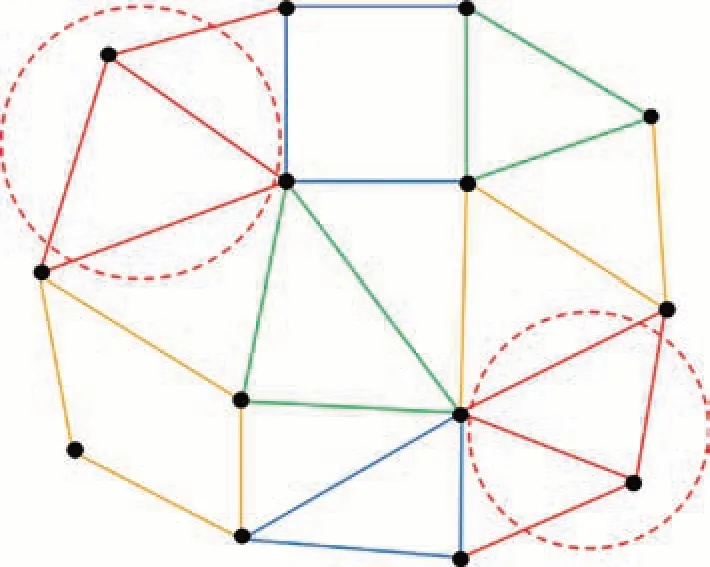
圖3 對網格面進行分組著色Fig.3 Face group coloring of meshes
2.4 剖分復制策略
剖分復制(Divide &Replication)策略是在為MPI 并行計算完成區域分解后,在進程內部根據線程數再進行一次分區,如圖4 所示。可以繼續使用圖分區工具METIS[21]進行分區保證負載均衡。對面循環或體循環的計算進行任務劃分,從而為每個OpenMP 線程分配面或體的所有權。與分組著色的思想類似,都是盡量讓單個線程處理一組內存位置相近的單元來提升線程內部的數據局部性,進而提升并行性能。不同的是,剖分復制策略的核心是通過工作復制來保證線程安全[16],而不是直接在循環上進行并行,因此更接近任務并行。如果兩個線程共享1 個面,那這兩個進程將復制這個面的工作。在寫回操作時,通過額外的邏輯判斷保證每個線程只負責自己分區內的體單元數據更新,從而避免數據沖突,如算法6 所示。剖分復制策略的優點是每個線程都使用其專用緩沖區,避免了工作線程之間進行全局同步的開銷,而且不用改變原始的變量存儲數據結構。但該策略如果應用于擁有成千上萬輕量級線程的GPU 平臺上,計算負載較小且存在大量的分支判斷,性能提升效果有限。

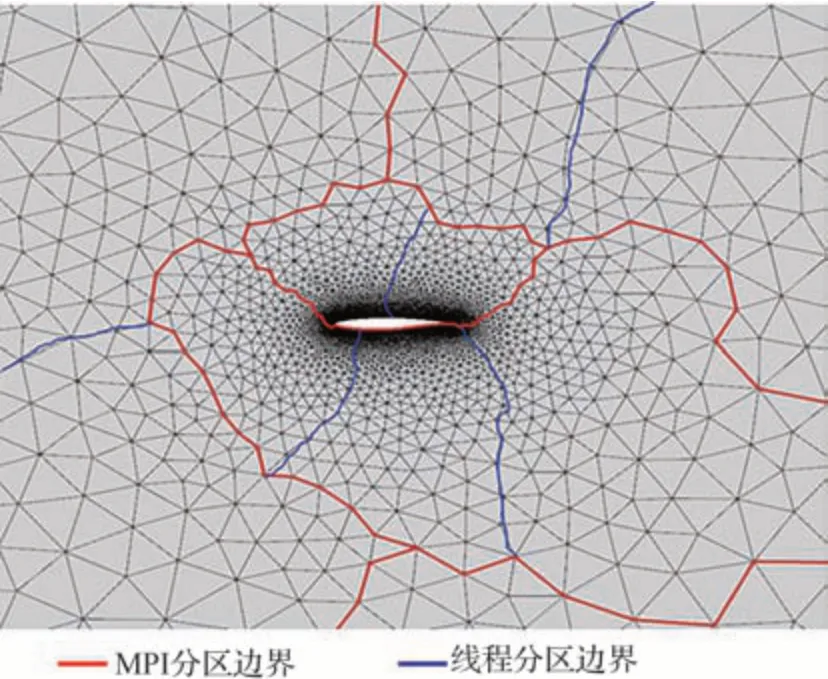
圖4 對計算網格進行多級分區Fig.4 Hierarchical partitioning on computational grid
2.5 基于分治法的任務級并行
分治法(Divide &Conquer,D&C)的思想和剖分復制策略類似,需要對MPI 進程內的網格進一步剖分,區別是遞歸地構建任務樹,并基于任務樹遍歷實現task 并行算法[18],如圖5 所示。在每個遞歸級別上,都會創建3 個子分區,包括兩個獨立的左右子分區和1 個分隔分區。其中,分隔分區由分區交界面上的網格實體所構成,這樣左右子分區不具備連通性,從而無數據依賴可并行執行。所有子分區(包括分隔分區)將繼續遞歸分下去,終止條件是葉子節點的網格單元數小于某個閾值,閾值大小一般選擇緩存區(Cache)大小,以發揮最大性能。
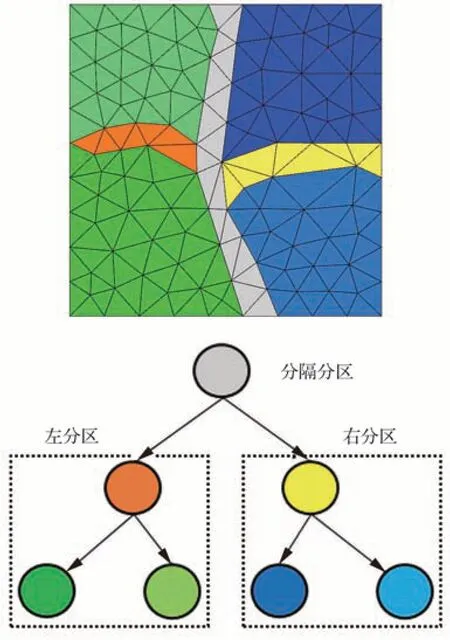
圖5 分治遞歸樹建立過程Fig.5 Building process of divide and conquer recursive tree
執行計算時,采用task 并行編程模型對樹節點進行遞歸遍歷執行(算法7):左分區和右分區并行執行,一旦它們同步,就執行分隔區,從而實現基于任務級的共享內存并行。這種并行方式適合于支持task 的并行編程模型,如OpenMP task、Cilk Plus等。分治法的優點是保持了良好的數據局部性,并將全局同步轉換成多個局部同步,減少了同步開銷。但通用GPU 編程模型(如OpenACC、CUDA、OpenCL 等)暫不支持細粒度任務調度機制,需要顯式地管理任務樹的調度,實現難度較大且應用效果有限。

3 非結構CFD 訪存優化技術
非連續數據訪存導致數據局部性差是影響非結構CFD 共享內存并行性能的主要障礙,引入3 種訪存優化技術以期進一步提升并行計算效率。
3.1 網格重排序
由于非結構網格單元大小和形狀的不規則性,相鄰網格單元之間的編號跨度很大,因此在對數據進行訪問時,緩存系統可能無法有效緩存所需的數據,訪存效率低下。可以考慮對網格單元體進行重排序,以改善數據局部性,提高緩存命中率。常見的排序算法包括Cuthill-McKee[22](CMK)、空間填充曲線(Space-filling curve)[23]、圖分區方法[24]等。分別實現了上述3 種排序算法,圖6 給出了使用不同算法對某個翼形網格重排序后得到的系統矩陣形式,其中矩陣的非零項塊子矩陣用填充矩形表示。可以看到,重排序后相鄰網格體之間編號更接近,矩陣的帶寬顯著降低,結構更規則。在第4.3 節還將詳細地對這3 種排序方法的應用效率進行對比。
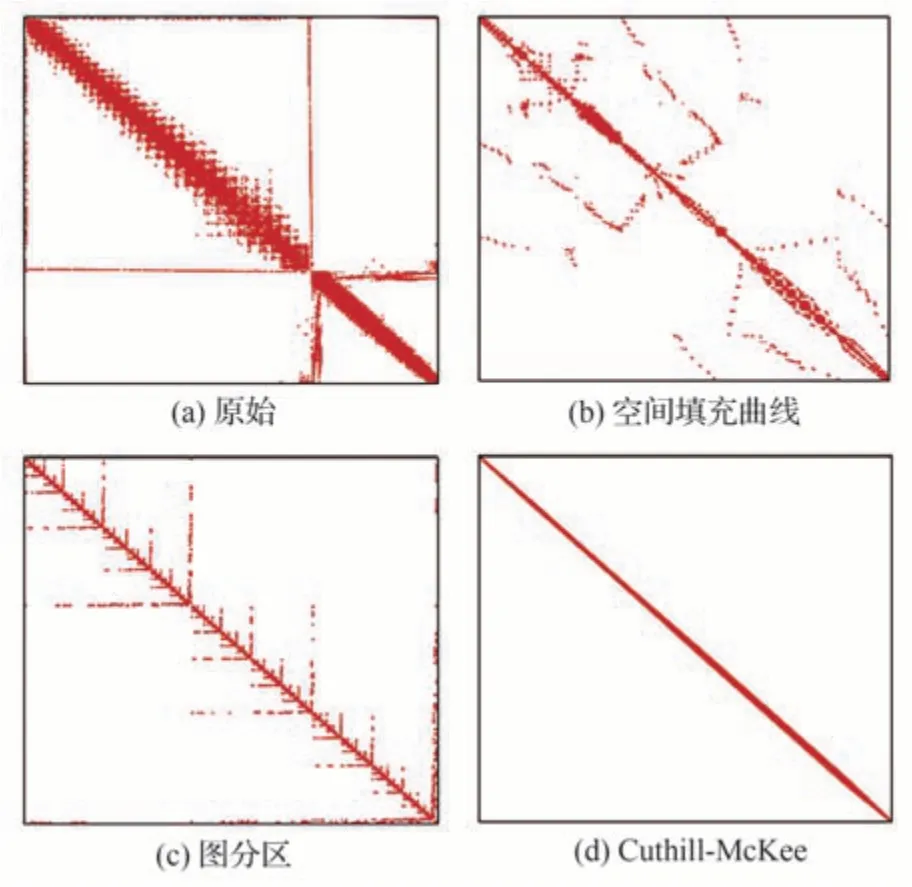
圖6 使用不同算法進行網格重排序后的系統矩陣Fig.6 System matrix after grid reordering using different algorithms
完成體單元排序后,再根據面左右的最小體編號,重新對面編號進行排序,以實現面循環計算中對面相鄰體單元近似最優的內存訪問,如圖7所示。所有排序算法的復雜度為O(N)或最多為O(N lg N),所以重排序的開銷是值得付出的[25]。
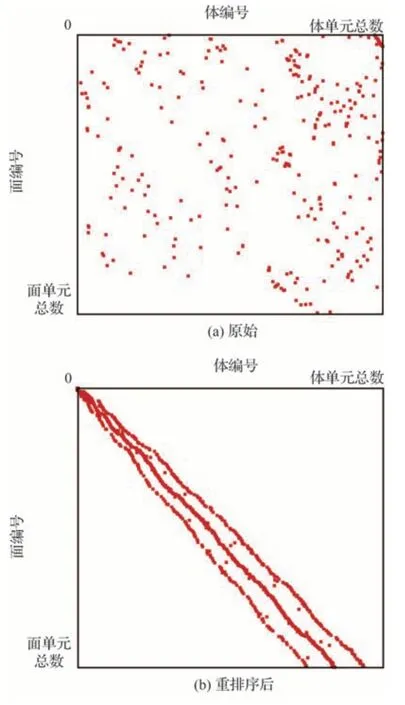
圖7 面循環中面對體的訪問關系Fig.7 Face-to-cell access in face-loop
3.2 循環融合
為了提高代碼的可讀性和模塊化水平,FlowStar 程序對一些包含大量循環的子程序進行了封裝,比如在無黏通量計算中,將加載變量、重構、通量計算、更新右端項等封裝成了單獨的函數。這種模式很可能導致數據局部性下降,因為同一個數組在前面的循環中被依次寫入,后面的循環中很可能會再次依次讀入。當數組長度很大時,需要讀取的數據已經不在緩存中,必須重新從內存加載。通常可采用循環融合的優化策略以改善數據局部性,如圖8 所示,將子程序的核函數提取到同一個循環內。這樣,被寫入的值可以被及時讀到,降低了緩存缺失(cache miss)的概率。此外,循環體數目的減少可消除循環并行時冗余的全局同步開銷,進一步提升計算效率。
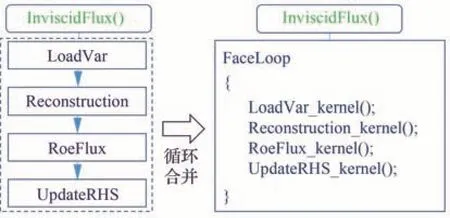
圖8 無黏通量計算函數進行循環融合Fig.8 Loop fusion on inviscid flux subroutine
3.3 GPU 共享存儲優化方法
非結構CFD 的非連續訪存行為使得其在GPU 上的性能表現不及預期,結合SMEM(Shared Memory)進行多級訪存是一種潛在的優化方法。GPU 的SMEM 是一種在block 內能訪問的內存,存儲硬件位于芯片上(on chip),訪問速度較快。SMEM 的控制與生命周期管理與L1緩存不同,SMEM 的使用受用戶控制,L1 受系統控制。因此,可以顯式管理SMEM,緩存一些需要反復讀寫的數據,提升訪存效率。文獻[14,26]嘗試基于著色算法進行非結構CFD 的SMEM 優化,但因著色本身會加劇訪存的不連續性,導致性能提升有限。提出了一種新的基于規約操作(算法3)的SMEM 多級訪存優化方法。GPU 核函數預先將體單元數據從全局存儲(global memory)加載到SMEM 單元,面到體的規約操作在SMEM 上完成,再將更新后的SMEM 數據寫回全局存儲,整個數據流如圖9 所示。在該示例中,對于三維非結構網格,每個體至少有4 個面單元,所以對同一內存位置要進行4次數據寫操作,SMEM 上的多次寫入可以增加其數據復用率,在抵消SMEM 初始加載和最終寫回全局存儲的開銷后,帶來額外的性能提升。一般來說,對于GPU 并行計算,流場變量或者幾何信息的存儲方式最好是結構體數組(Struct of Array,SoA),而不是數組結構體(Array of Struct,AoS)。因為在GPU 上并行執行的過程,其實是將調用同一個核函數的多個線程歸并在一個塊(block)當中,用SIMD(Single Instruction Multiple Data)的方式執行。因此按照塊進行數據組織的效率更高,也就是更傾向于SoA。由于規約策略保持了原有塊組織數據結構的連續性,且數據復用率更高,所以相比著色策略進行SMEM優化的效果會更好。
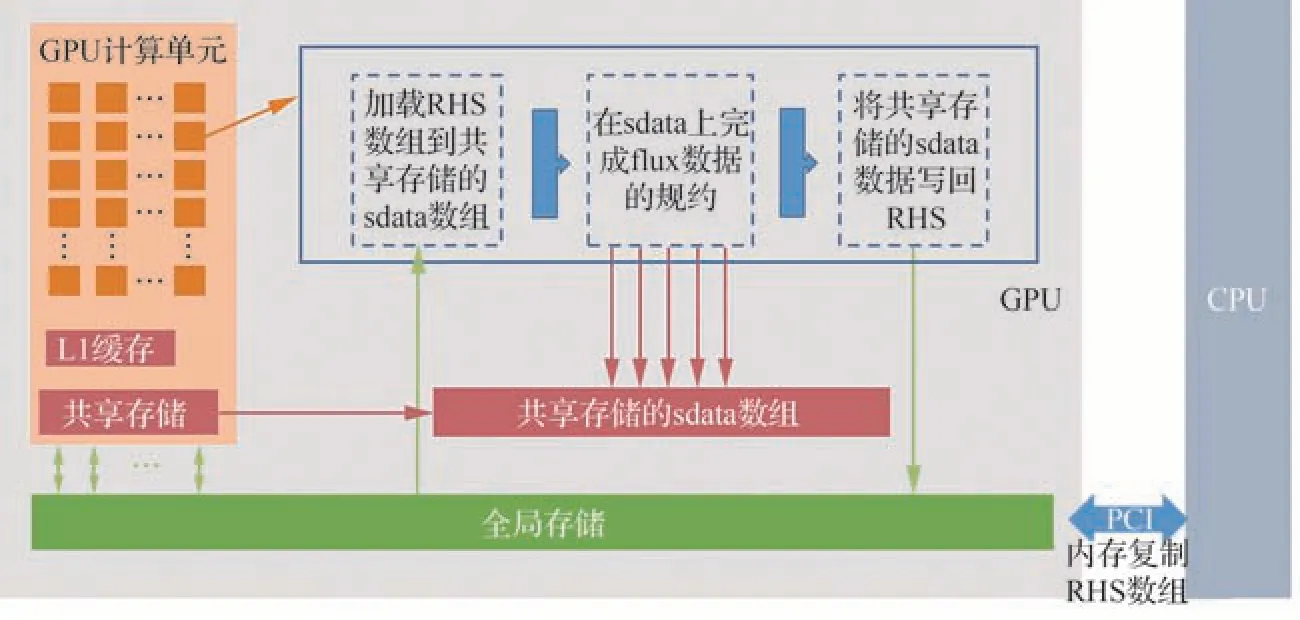
圖9 顯式管理SMEM 的數據流Fig.9 Data flow by explicit management of SMEM
4 實驗結果與分析
4.1 測試用例及環境
為了分析不同并行算法的性能及相關優化技術的效果,分別采用ONERA M6 機翼(圖10)及CHN-T1 運輸機標模[27](圖11)的三維非結構網格開展性能測試。其中M6 的測試網格按體單元數目規模分4 個層次:粗(12 萬)、中(80 萬)、細(360 萬)和極細(1 000 萬)。CHN-T1 的網格規模分粗(600 萬)和細(1 700 萬)兩個層次。

圖10 ONERA M6 機翼網格Fig.10 Computational grid of ONERA M6 wing

圖11 CHN-T1 民用客機標模網格Fig.11 Computational grid of civil passenger aircraft model CHN-T1
測試分別在國家超級計算濟南中心的x86 節點和中國空氣動力研究與發展中心的內部GPU 工作站開展。其中濟南中心x86 節點的CPU 為Intel?Xeon?Gold 6258R @2.70 GHz,每個節點兩路CPU,共58 個計算核心。GPU 工作站配置為Intel?Xeon?Platinum 8368 CPU @2.40 GHz 以及NVIDIA A100 PCIe 80G 加速卡。
4.2 一致性測試
理論上,不同的并行優化方法只會改變空間離散過程中通量計算和殘差更新的順序,不會對最終計算結果造成影響。所以在進行性能分析前,先進行一致性測試以驗證程序實現的正確性。選取對M6 機翼中等網格算例進行計算,計算狀態為來流馬赫數0.839 5、攻角3.06°、雷諾數1.814×107、溫度288.15 K。圖12 給出了利用不同方法進行計算得到的殘差隨迭代步收斂曲線,可以看到所有方法的收斂曲線完全重合,表1 給出了最終計算得到升阻力系數,也完全一致。測試結果驗證了所實現不同并行優化方法的正確性。
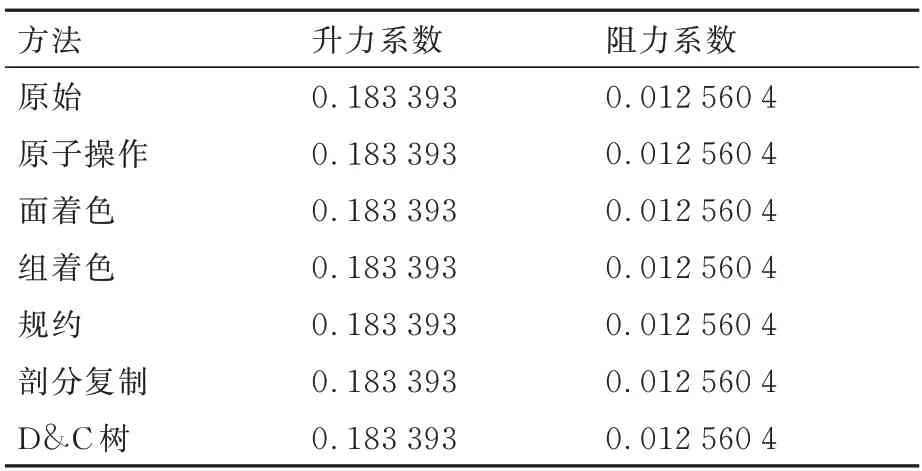
表1 不同并行優化方法計算得到的最終氣動力系數Table 1 Final aerodynamic coefficients computed using different parallel optimization methods
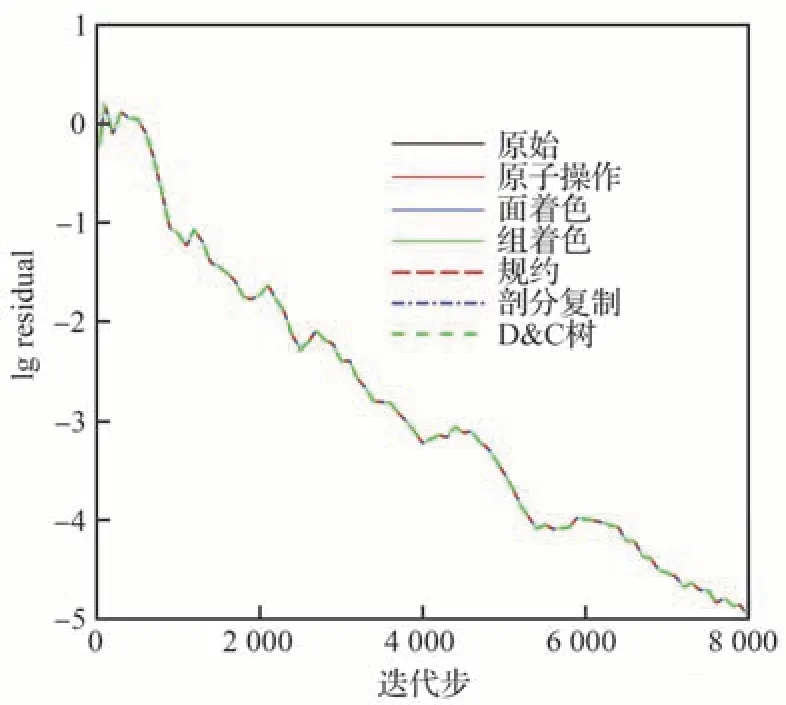
圖12 不同并行優化方法殘差隨迭代步收斂歷程比較Fig.12 Comparison of residual convergence process with iteration steps of different parallel optimization methods
4.3 訪存優化效果
圖13 給出了使用不同排序算法模擬M6 機翼粗網格算例的殘差收斂過程。所有計算都取相同的計算條件,CFL(Courant-Friedrichs-Lewy)數均設為100。縱坐標殘差取連續性方程對數刻度,橫坐標為程序執行墻鐘時間。可以看到,3 種排序方法中,CMK 方法的效果最好,相比原始沒有重排序的性能,殘差下降4 個量級時所需要時間要少10%左右。該結果符合預期,從圖6 可以看出,CMK 方法排序后數據局部性最好,系統矩陣帶寬最小。
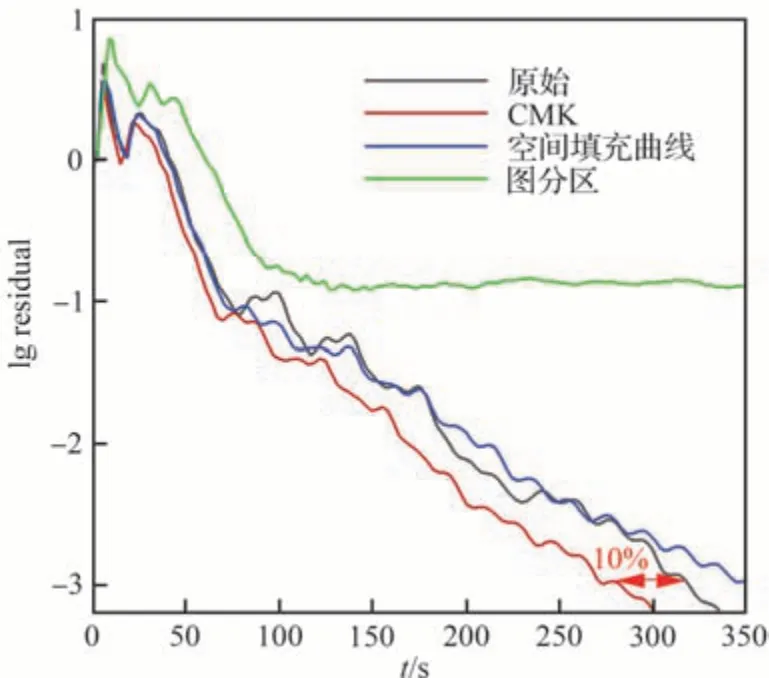
圖13 不同重排序算法的殘差收斂歷程比較Fig.13 Comparison of residual convergence histories using different renumbering algorithms
表2 給出了循環融合的優化效果,對M6 機翼兩套網格分別使用不同線程進行計算,統計了前100 步迭代的平均耗時。從結果來看,循環融合后的性能提升效果明顯,運行時間能夠縮短10% 左右。所以,在之后的測試中,默認采用CMK 網格重排序和循環融合的性能優化策略。
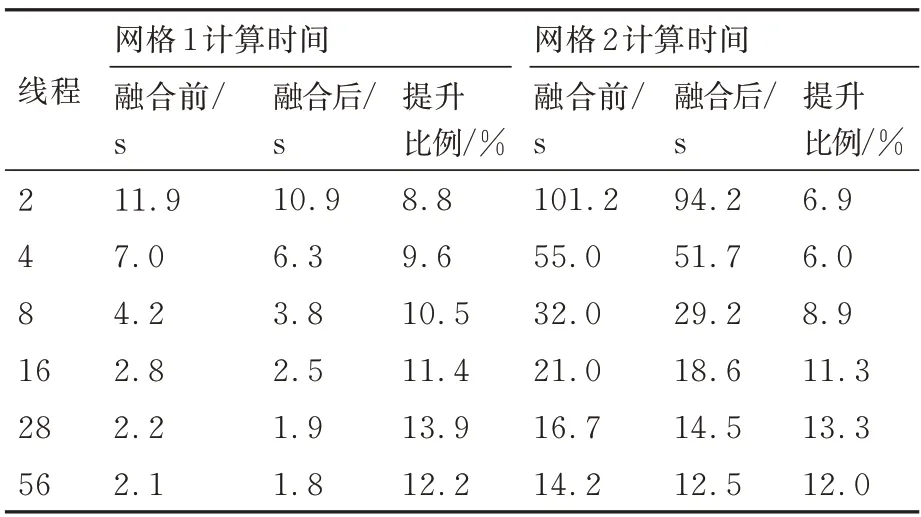
表2 循環融合前后計算時間(100 步)對比Table 2 Comparison of executing time(100 iterations)before and after loop merge
4.4 CPU 平臺并行計算性能分析
第2 節中描述了不同的共享內存并行方法,采用M6 機翼和CHN-T1 標模完成不同方法在CPU 平臺的性能對比。首先在單節點內使用不同OpenMP 線程對M6 機翼網格進行測試。由于單節點內存有限,選取粗、中兩個層次的網格進行了計算,得到并行效率數據,如圖14 所示。從結果來看,剖分復制策略的并行效率最高,可擴展性最好,規約策略次之,原子操作的效果最差。兩種著色策略對比,基于簡單著色的方案在線程數較少時要優于分組著色策略,然而隨著線程數增多,分組著色的并行效率保持更高,驗證了分組著色能夠通過改善數據局部性提升性能。基于D&C 樹的任務級并行效果不如剖分復制策略,可能是在遞歸創建任務樹的過程中,每個子分區的網格編號無法保持連續,導致訪存效率低下,因此還有性能提升空間。
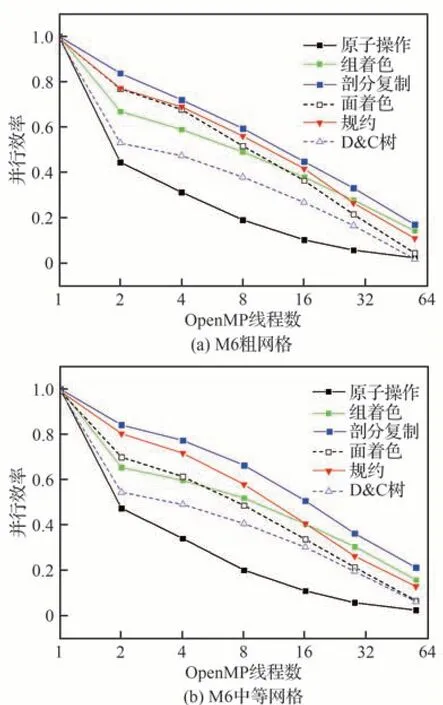
圖14 不同OpenMP 并行策略的并行效率對比Fig.14 Comparison of parallel efficiency of different OpenMP parallel strategies
圖15 展示了幾個典型狀態下使用不同并行策略模擬M6 中等網格計算前100 步迭代的平均耗時,結果規律和并行效率一致。
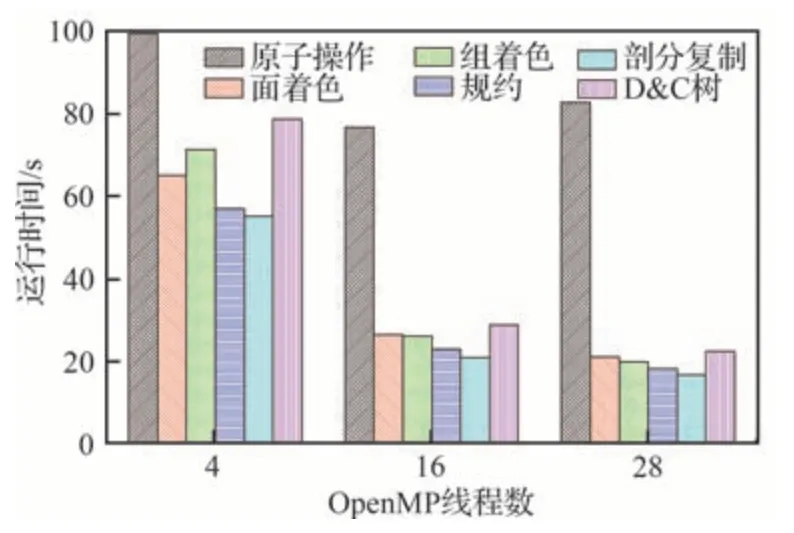
圖15 不同OpenMP 并行策略的運行時間對比Fig.15 Comparison of running time of different OpenMP parallel strategies
圖14和圖15 是純OpenMP 并行計算性能的測試,接下來利用CHN-T1 細網格算例開展跨節點性能測試。圖16 給出了純MPI 并行和MPI+OpenMP 混合并行模式下以單節點計算時間為基數的加速比曲線。測試所用的線程數和CPU核心數一致,混合并行每個節點使用2 個進程,OpenMP 并行采用性能最佳的剖分復制策略。如采用2 個節點(每個節點56 個核心)計算時,純MPI 模式就采用112 個MPI 進程,混合模式采用4 個MPI 進程以及每個進程28 個OpenMP 線程的組合。從結果來看,在小規模下,純MPI和MPI+OpenMP 混合模式的并行效率均非常高。超過16 個節點后加速比開始下降,這是因為隨著分區數增多,每個分區的網格的數量急速下降,通信開銷比例增大,降低了并行計算的效率。而MPI+OpenMP 混合模式的并行效率要高于純MPI 模式。分析其原因,同一節點內的兩個核心之間的通信比節點之間的通信帶寬更高、延遲更低,即使通過高速網絡互聯也是如此,采用混合模式的分區數要遠小于純MPI 模式,而且采用共享內存的并行減少了了大量跨節點通信的開銷,所以MPI+OpenMP 混合模式擴展性更好,更加適用于大規模算例的計算。
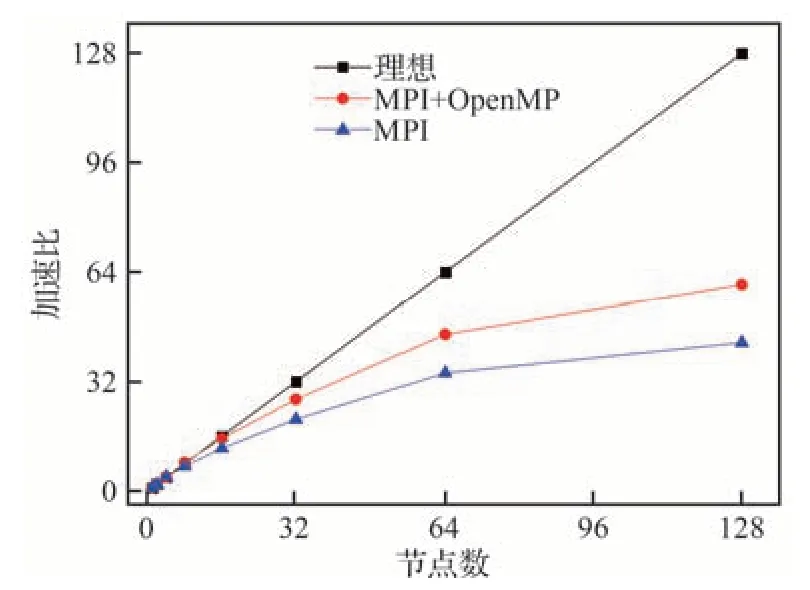
圖16 并行計算CHN-T1 的加速比Fig.16 Speed-up ratios of parallel computation of CHN-T1
4.5 GPU 平臺并行計算性能分析
如2.5 節中所述,由于通用GPU 并行編程模型對任務并行模式的支持能力較弱,通常需采用或者設計針對任務并行的GPU 運行時調度機制,開發工作難度大,且平臺/應用適用性較弱。因此,在FlowStar 上實現了原子操作、面著色、規約3 種基于循環并行的方法。首先利用M6 所有規模的網格算例進行了測試。對于存在寫沖突的子程序是GPU 并行的最大性能障礙,對這些子程序進行并行的加速比最能體現不同方法的性能優劣。圖17 給出了FlowStar 中UpdateRHS函數GPU 并行化后相比CPU 串行計算取得的加速比。可以看出,規約和面著色策略加速效果相差無幾,且均優于原子操作。此外,網格規模越大,加速效果越明顯,這是因為隨著問題規模的增加,GPU 計算負載提高,且CPU和GPU之間的數據移動的開銷比重降低,能夠充分發揮GPU眾核并行優勢。
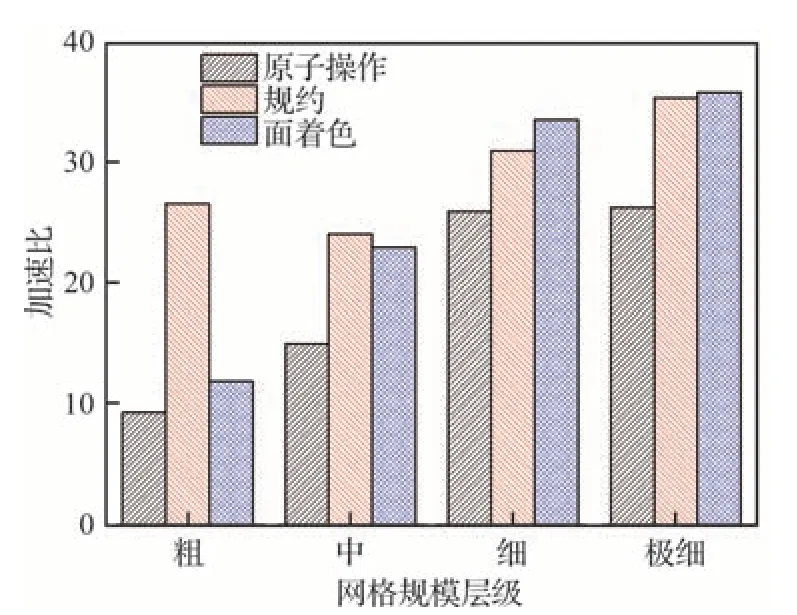
圖17 不同規模M6 算例UpdateRHS 函數加速比Fig.17 Speed-up ratios of UpdateRHS subroutine for different grid levels of M6 wing
3.3 節講述了通過顯式管理SMEM,緩存一些需要反復讀寫的數據可以進一步提升訪存效率。圖18 給出了SMEM 優化前后UpdateRHS函數計算加速比對比。可以看到基于面著色方法進行SMEM 優化的效果不明顯(圖中紅色曲線),結論和文獻[14]一致。進一步參考文獻[26],利用分組多級著色策略(黑色曲線)的加速效果同樣不好,文獻中取得較好性能加速的原因主要在于將AoS 的變量存儲方式改成SoA,而FlowStar 的數據結構已經是SoA。相比之下,基于規約策略(藍色曲線)的SMEM 優化效果非常好,優化過后可以進一步將性能提升3倍,驗證了所提方法的有效性。
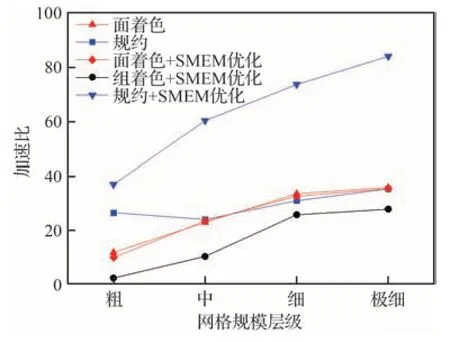
圖18 共享存儲優化前后UpdateRHS 計算加速比對比Fig.18 Comparison of speed-up ratios of UpdateRHS before and after shared memory optimization
最后,利用優化前后的GPU 并行程序對CHN-T1 粗細兩套網格進行了計算,統計了相比CPU 串行計算,各個子模塊以及程序整體運行時間的性能加速比,如圖19 所示。可以看到加速效果非常明顯,程序整體運行的加速比能達到127。特別是通量計算部分,子程序的加速比可以達到400 以上,因為通量計算部分大部分都是面循環,通過規約加SMEM 優化的策略在解決數據競爭問題的基礎上緩解了間接訪存情況,并且提升了數據局部性。LU-SGS 算法部分加速比略低,是因為隱式求解算法固有的串行屬性,這里采用了簡單的體著色并行策略,性能依然有提升空間,后續還將繼續深入研究。

圖19 CHN-T1 算例GPU 并行計算整體加速比Fig.19 Overall speed-up ratios of parallel computation of CHN-T1 on GPU
5 結論
針對非結構CFD 應用,在多核CPU 平臺和眾核GPU 平臺上分別實現了基于循環級與任務級的多種共享內存并行方法,設計了網格重排序、循環融合、多級訪存等性能優化技術。具體地,針對多核CPU 平臺,全面覆蓋了已有的5 種共享內存并行方法;針對眾核GPU 平臺,提出了基于SMEM 優化的規約策略,提升了GPU 并行計算性能。所有方法均在工業級CFD 軟件中進行了系統驗證評估,得到以下主要結論:
1)對于多核CPU 平臺,基于任務級并行策略(特別是剖分復制方法)的數據局部性更好,線程的全局同步開銷更小,性能更高;相比純MPI并行模式,MPI+OpenMP 的混合并行模式的規模擴展性更好,更加適用于大規模并行計算。
2)對于眾核GPU 平臺,實現了3 種基于循環的并行策略,其中面著色和規約策略均優于原子操作,基于SMEM 優化的規約策略加速效果明顯;相比串行CPU 計算,單GPU 并行計算能取得127 倍的加速比。
3)提高數據局部性在提升非結構CFD 計算性能中起著重要性的作用,采用Cuthill-McKee網格重排序以及循環融合技術能夠改善數據局部性,可以分別使整體性能提升10%;基于SMEM 優化的規約策略對于有數據競爭的熱點函數,性能可提升3倍。
在下一步工作中,將圍繞隱式求解方法開展更加深入的共享內存并行算法研究,進一步提升非結構CFD 軟件的并行計算效率和擴展性。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
