基于對抗學習的指針儀表自適應讀數識別算法
2024-05-03 20:13:43劉林馬云飛王荷生李寧
燕山大學學報 2024年2期
劉林 馬云飛 王荷生 李寧
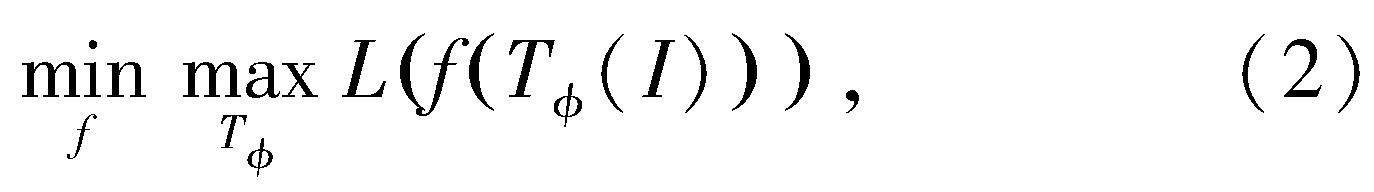
摘要:針對指針儀表采用人工讀數方式存在的成本較高、讀數不準確、時效性較差的問題,提出一種基于對抗學習的指針儀表位姿自適應讀數識別算法。該算法通過目標檢測模型識別圖像中的指針儀表的位置和姿態,將指針儀表進行校準后并利用數字圖像處理技術進行讀數識別。為了提升目標檢測模型對位姿不同的指針儀表圖像的識別效果,本文提出了基于對抗學習的數據增強技術,通過優化搜索模型識別不準的圖像旋轉角度、平移距離以及縮放比例構造訓練數據,提高目標檢測模型在指針儀表位姿發生變化時的準確率。以工礦企業中常用的SF6壓力儀表為實驗對象,實驗結果表明讀數識別的誤差在1%以內,證明了所提算法的有效性。
關鍵詞:指針儀表;讀數識別;目標檢測;位姿不變;對抗學習
中圖分類號: TP391.41文獻標識碼: ADOI:10.3969/j.issn.1007-791X.2024.02.007
0引言
隨著工業化的快速發展和生產規模的不斷擴大,以指針儀表為代表的精密儀器在諸如變電站等與工業生產密切相關的領域中發揮著重要作用。指針儀表具有結構簡單、使用壽命長、抗干擾能力強等優點。然而,目前大部分變電站采用人工讀數的方式,存在成本較高、讀數不準確、時效性較差等問題,因此如何自動、準確識別指針儀表的讀數成為工業生產中亟待解決的難題[1-4]。
近年來,隨著圖像處理與計算機視覺技術的快速發展,利用這些技術解決指針儀表的讀數識別問題成為了重要的研究方向。目前國內外已有研究大致可以分為基于傳統圖像處理技術和基于深度學習方法兩大類。傳統圖像處理方法通常采用邊緣檢測、霍夫變換、刻度識別、角度法等方式讀取指針儀表的讀數。文獻[1]利用改進的自適應中值濾波方法預處理指針儀表圖像,并利用刻度盤轉角與刻度之間的線性關系提出基于霍夫變換的指針儀表讀數方法。文獻[5]提出一種在HSV空間進行指針儀表讀數識別的方案,通過對比指針位置不同的兩幅圖像獲取參考儀表盤圖像,進而利用角度法進行讀數識別。這些基于傳統圖像處理的方法仍然需要手工設計圖像特征,并基于這些特征進行指針儀表的讀數識別,因此,這些方法的好壞很大程度上取決于特征設計的好壞,對于不同的應用場景較難適用。另一方面,基于深度學習的方法通過深度神經網絡自動檢測圖像中的指針儀表位置和讀數,可以在很大程度上緩解手動設計特征的困難。文獻[6]利用典型的目標檢測模型RCNN檢測圖像中指針儀表的位置,進而使用霍夫變換識別指針儀表中指針的位置,得到讀數。文獻[7]首先針對指針儀表圖像進行去噪處理,然后利用目標檢測模型Mask-RCNN對指針儀表進行定位和實例分割,最后采用角度法讀取指針讀數。文獻[8]提出基于YOLOv5的指針儀表檢測方法截取圖像中指針儀表,基于數字圖像處理技術進行讀數識別。然而,目前基于深度學習的方法泛化能力較差,對于訓練過程中沒有見到的姿態不同的物體無法準確識別[9-12]。
為了解決上述問題,本文提出基于對抗學習的指針儀表位姿自適應讀數識別算法,利用目標檢測模型預測圖像中指針儀表中心點的位置、大小和另外兩個關鍵點的位置,通過兩個關鍵點的相對位置可以計算出指針儀表的位姿,進而從圖像中截取指針儀表區域并對其進行旋轉校正,得到水平狀態下的指針儀表區域圖像,實現對圖像中的指針儀表進行自動檢測與讀數識別。為了提升目標檢測模型對位姿不同的指針儀表圖像的識別能力,本文進一步提出基于對抗學習的訓練方式,將目標檢測模型的訓練過程建模為最小最大化優化問題,其中內層最大化問題旨在搜索當前模型難以識別正確的指針儀表旋轉角度、平移距離與放縮比例,而外層最小化問題在搜索到的“最壞情況”下訓練模型,以提升模型在指針儀表位姿發生變化時的準確性。在得到校準后水平狀態下的指針儀表圖像后,通過數字圖像處理技術,從圖中提取指針儀表的邊緣信息,采用圓環檢測與線段檢測算法找到指針儀表的指針和刻度線位置,進而準確識別出指針儀表的讀數。
本文以變電站中常用的SF6壓力儀表為實驗對象,通過數據采集與標注訓練所提出的位姿不變目標檢測模型,在測試階段可以準確預測圖像中指針儀表的位置和姿態,進而得到指針儀表的讀數。實驗表明,本文所提算法的讀數識別誤差在1%以內,證明了算法的有效性。
1位姿自適應讀數識別算法設計方案
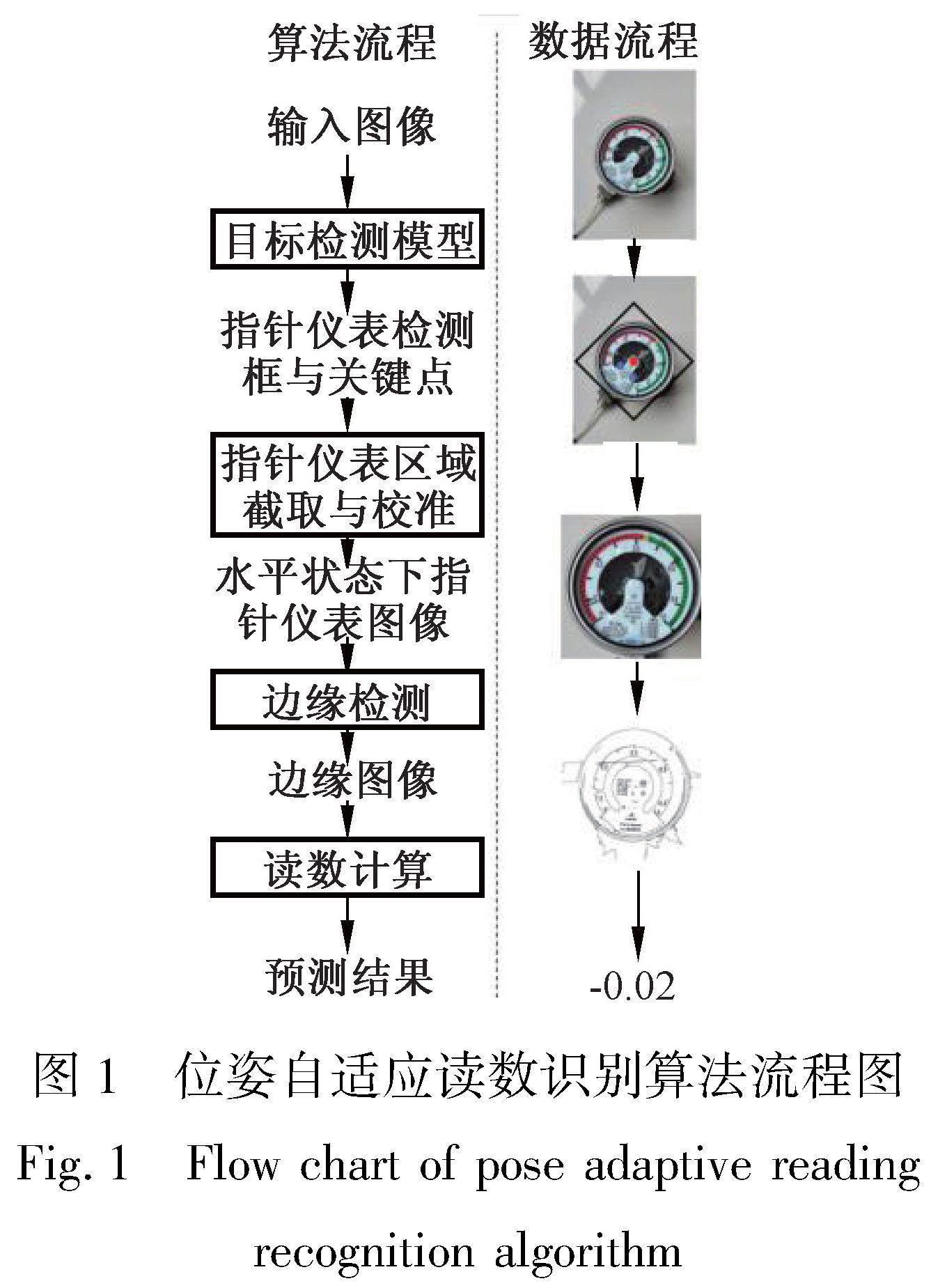
本文所提出的算法流程如圖1所示。給定指針儀表在任意視角下的拍攝圖像,算法首先利用位姿不變的目標檢測模型預測指針儀表中心點的坐標(紅點)、指針儀表的大小以及兩個關鍵點的坐標(藍點),基于關鍵點的相對位置,計算出指針儀表的位姿,進而得到其包圍框(黑框)。從圖像中截取包圍框中的指針儀表區域并對其進行旋轉校正后,可以得到水平狀態下的指針儀表圖像。進而通過數字圖像處理技術提取指針儀表的邊緣信息,并采用圓環檢測與線段檢測算法找到指針儀表的指針和刻度線位置,從而識別出指針儀表的讀數。
2位姿自適應讀數識別算法
目標檢測是計算機視覺中最基礎的任務之一,其目標是針對給定的輸入圖像,從中預測一個或多個物體的位置及其類別[13]。近年來,隨著深度學習的不斷發展,基于卷積神經網絡的目標檢測模型被廣泛應用于自動駕駛、機器人、缺陷檢測等多種實際場景中[14]。一般而言,目標檢測可以被分為兩大類:單階段目標檢測和雙階段目標檢測。以YOLO為代表的單階段目標檢測模型從輸入圖像中直接預測目標物體的位置和類別,其運行速度較快,更適用于邊緣設備[15]。以RCNN為代表的雙階段目標檢測模型首先從輸入圖像中預測出一組候選框,再針對這些候選框進行分類,其速度相比于單階段目標檢測模型更慢,但通常情況下精度較高[16]。針對本文所研究的指針儀表讀數識別任務,在一般情況下每張圖像中只會出現一個物體(即指針儀表),同時目標檢測模型需要被部署到邊緣設備中,因此本文采用單階段目標檢測模型。然而,雖然現有目標檢測算法性能優越,但是其難以在物體位姿出現變換的情況下準確識別到目標物體。針對這一問題,本文進一步提出基于對抗學習的訓練方式提升指針儀表位姿出現變化時的識別精度。
2.1網絡結構設計
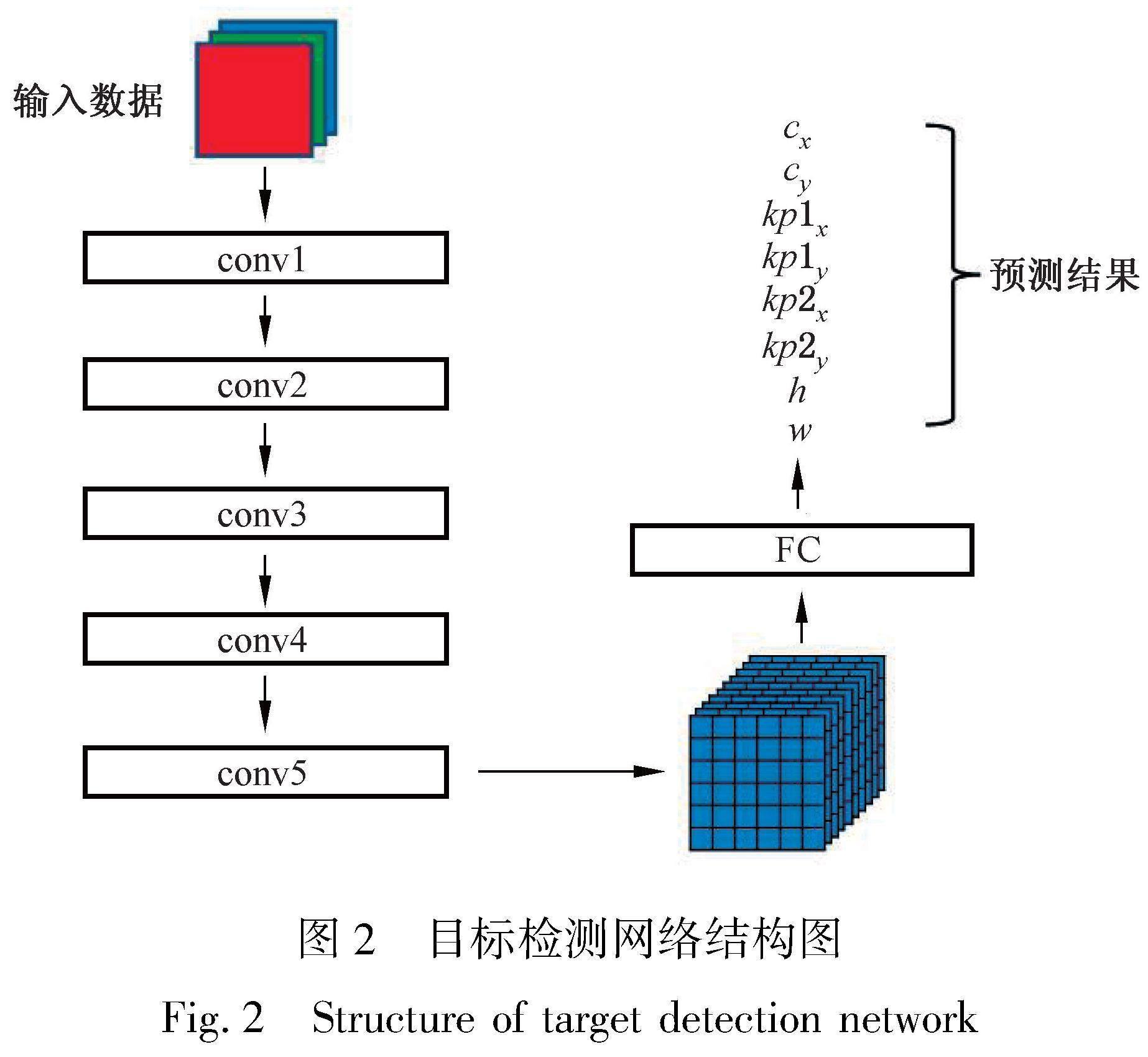
本文設計了基于經典卷積神經網絡的目標檢測網絡結構。為了提升計算速度,網絡總共包含5個卷積層和1個全連接層,如圖2所示。
如圖2所示,對于給定的輸入圖像,網絡首先對圖像進行卷積操作,從中提取圖像特征。網絡中共包含5層卷積層,在每個卷積層后使用歸一化操作和激活函數對特征進行處理,自下而上地提取圖像中的特征。在卷積層后,網絡首先利用池化操作將特征進行壓縮,得到圖像的向量表示形式,通常為512維的向量,進而再通過1層全連接層將512維圖像特征轉換為8維預測向量[cx,cy,kp1x,kp1y,kp2x,kp2y,h,w],其中[cx,cy]代表指針儀表中心點在圖像中的坐標;[kp1x,kp1y,kp2x,kp2y]為兩個關鍵點在圖像中的坐標;[h,w]為指針儀表區域在圖像中的寬度和高度,表示其大小。
本文所采用的網絡結構設計與一般的目標檢測模型存在以下三點不同。首先,本文設計的網絡結構只預測一個候選框的位置和大小,而一般的目標檢測網絡中會輸出多個候選框的位置、大小及其對應類別。本文采用簡化設計的主要原因是一般的指針儀表圖像中僅會出現一個儀表,因此沒有必要預測多個物體,采用此設計也可以極大地簡化算法流程,提升模型效果。其次,由于僅需要預測一個物體,本文設計的網絡結構沒有采用錨點的方式,也使得識別過程更加靈活,不需要手動設計錨點大小。最后,與一般的目標檢測模型不同,本文設計的網絡結構除預測目標物體的中心點坐標和包圍框大小外,還需額外預測兩個關鍵點的坐標,這也為后續算法流程中校準指針儀表圖像提供了便利。
2.2基于對抗學習的訓練算法
深度學習模型通常需要大量的訓練數據優化模型參數,從而取得較好的效果。然而,深度學習由于模型容量較大,同時采用數據驅動的學習方式,往往會出現泛化能力不足的問題。例如,文獻[9]發現深度神經網絡在圖像發生旋轉或平移變換的情況下準確率顯著降低,這也對深度學習的實際應用帶來了挑戰。對于本文所研究的指針儀表讀數識別任務而言,由于攝像機拍攝角度、指針儀表安裝位置等因素會發生變化,圖像中指針儀表的位姿也會存在差異。因此,如何提升目標檢測模型在位姿不同情況下對指針儀表的檢測效果是一個極大的挑戰。
針對這一問題,本文提出基于對抗學習的訓練方式。對抗學習通過優化模型在最差情況下的效果提升模型的穩定性。對于指針儀表讀數識別任務,訓練的目標是希望在指針儀表位姿發生變化時,目標檢測模型均能準確檢出目標物體。形式化地,給定輸入圖像I和位姿變換T,位姿不變目標檢測模型f需要達到的目標是f(T(I))=f(I),(1)即模型的預測結果不會隨著輸入數據的變換發生改變。對于位姿變換T,本文考慮圖像旋轉rθ(·)、圖像平移ta,b(·)和圖像縮放sw(·)三種變換,其中θ代表旋轉角度、a和b分別代表圖像沿兩個方向的平移距離、w代表圖像縮放比例。因此,位姿變換T可以表示為T(·)=rθ(ta,b(sw(·))),即三種圖像變換的組合,其中=[θ,a,b,w]代表變換的參數。
基于上述定義,對抗學習的訓練方式可以描述為一個最小最大化優化問題:
其中內層最大化問題通過最大化模型的損失函數L尋找模型無法正確預測的變換T,而外層最小化問題在內層最大化的解的基礎上訓練目標檢測模型f,提升模型在圖像變換下的穩定性。與一般的圖像變換方式不同,本文提出的對抗學習方法通過尋找最差情況下的圖像變換訓練模型,能夠更加高效地提升模型對于位姿不同的圖像的識別能力。通俗意義上而言,對抗學習方式通過尋找模型沒有學會的變換進行訓練,可以有效提升模型的泛化能力和穩定性。
為求解上述最小最大化優化問題,一般方式為:首先對內層最大化問題進行求解,再利用內層最大化的解求解外層最小化問題。對于本文所研究的目標檢測模型,首先通過梯度上升優化圖像變換的四個參數=[θ,a,b,w],尋找模型無法識別正確的圖像變換;進而利用此變換下的圖像訓練目標檢測網絡f得到位姿不變的目標檢測模型。
對于訓練目標檢測網絡的損失函數L,其總共包含以下三項:L=Lcenter+λ·Lkeypoint+μ·Lbbox,(3)其中,Lcenter為中心點的預測誤差,Lkeypoint為關鍵點的預測誤差,Lbbox為包圍框大小的預測誤差,λ和μ分別為平衡三項損失的超參數。具體而言,中心點的預測誤差定義為Lcenter=(cx-c*x)2+(cy-c*y)2,(4)其中,c*x和c*y為人工標注的中心點的真實坐標。關鍵點的預測誤差定義為Lkeypoint=(kp1x-kp1*x)2+(kp1y-kp1*y)2+(kp2x-kp2*x)2+(kp2y-kp2*y)2,(5)類似地,kp1*x、kp1*y、kp2*x、kp2*y為人工標注的兩個關鍵點的真實坐標。包圍框大小的預測誤差為Lbbox=(h-h*)2+(w-w*)2,(6)其中,h*和w*為包圍框的真實大小。通過優化上述損失函數L,可以使得網絡的預測結果和真實標簽更加接近,訓練后可以準確地提取圖像中指針儀表的特征,預測其關鍵點坐標和包圍框大小,得到準確的目標檢測結果,進一步幫助后續指針儀表讀數的識別。
2.3指針儀表校準
在目標檢測模型預測出指針儀表的坐標和包圍框大小后,算法流程的下一步是基于檢測結果從圖像中截取并校準目標物體,得到水平狀態下的指針儀表圖像。這個過程涉及到計算指針儀表的位姿。從圖1中可以看到,所定義的兩個藍色關鍵點為指針儀表中指針的最小刻度和最大刻度,其應該處于水平狀態。因此通過計算這兩個關鍵點的坐標的傾斜角度,即可得到指針儀表包圍框的旋轉角度。具體而言,通過目標檢測模型預測的兩個關鍵點坐標[kp1x, kp1y, kp2x, kp2y],可以計算得到指針儀表的旋轉角度為
通過指針儀表的中心位置[cx,cy],其大小[h, w]和旋轉角度α,就可以很容易地得到其包圍框的位置和旋轉角度,進而從圖片中直接截取包圍框中的部分,就可以得到水平狀態下的指針儀表圖像。
2.4讀數計算
通過目標檢測算法得到水平視角下的指針儀表圖片之后,算法的第二步是利用數字圖像處理中的技術識別指針儀表的讀數。從圖1中可以看到,指針儀表的指針和刻度線特征較為隱蔽,采用基于深度學習的算法難以精確估計指針儀表的讀數,會帶來較大的誤差。因此,本算法采用邊緣檢測算法從圖像中提取邊緣信息,并進一步利用圓環檢測和線段檢測算法識別指針和刻度線的位置,就能夠更加準確地讀取指針儀表的數字。
步驟1:采用自適應的邊緣檢測算法得到指針儀表的邊緣特征。由于指針儀表的圖像為彩色三通道圖片,首先對圖像進行二值化處理,將其轉變為黑白圖像。一般情況下,物體的邊緣會出現像素值明顯的變化,因此可以通過一個像素與其周邊的像素值的差異判斷出其是否是物體的邊緣。
步驟2:通過目標檢測算法檢測到指針儀表對應的圖片,并將其縮放為統一大小后,指針儀表的大小是基本固定的。因此通過找到圖中的圓弧以及圓心,就可以得到刻度線外的圓弧。對于圓環檢測,本文采用廣泛使用的霍夫圓變換算法。首先對于邊緣檢測得到的結果,計算其中每個邊緣點的切線,然而計算其垂直線。此后,通過判斷這些垂直線是否穿過圖像中的每個點找到圓心。在實際情況中,可能會出現計算不準出現偏差的情況,通過高斯濾波可以在一定程度上緩解此問題。在得到圓心后,計算圓心到邊緣點的距離,即為圓環的半徑。
步驟3:在此圓的內側,有11個刻度線,分別是-0.1、0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9。本文采取順時針掃描法來找到上面的11個短的刻度線。以霍夫算法找出的圓心為中心,以垂直向下為起點,順時針掃描整個圓面,凡是指向圓心的20個像素點左右的黑色線段,即為刻度線。第1個刻度線,即為-0.1,最后一個刻度,即為0.9。在找出刻度線的過程中,也可以找出指針的位置,與刻度線相比,指針的線更長,因此判斷出指針的位置。根據指針的位置,以及它處于哪兩個刻度線之間,進而計算出指針指向的位置,得到指針儀表的數字。
3實驗與分析
3.1硬件平臺
硬件平臺采用Raspberry Pi Zero2W嵌入式控制器。該控制器體積小、功耗低、性能強、價格低廉,可以搭載Linux操作系統適合在指針儀表的識別的現場應用。獲取指針表盤的攝像頭采用廣角500萬相素的樹莓派專用攝像頭。
3.2數據收集與標注
對變電站常見的SF6壓力表,獲取了不同角度、不同讀數的500副指針儀表圖像。在得到圖像后,首先通過人工標記的方法對每幅圖像中指針儀表的關鍵點和包圍框進行標注。然后將這500張圖像按照9∶1的比例分為450張訓練圖像數據和50張測試圖像數據。使用提出的基于關鍵點的目標檢測模型在這450張訓練數據上進行模型訓練。訓練結束后,在50張測試數據集預測指針儀表的讀數,驗證算法有效性。
3.3實驗結果與分析比較
本文采用絕對誤差作為評估指標。對于每張指針儀表圖像,首先人工標注指針的讀數作為真實值,然后分別利用本文所提出的對抗算法以及結合圖像預處理和霍夫圓算法[17],對數據進行預測和識別,用于評估算法的準確性。在對上述50個測試數據測試完成后發現,對抗算法預測誤差在0.01以內,相較于指針儀表的讀數范圍[0,1],僅有1%以內的誤差。而使用霍夫圓算法的預測數據,其誤差要大得多。
圖3展示了其中10張指針儀表照片。表1展示了這10個數據基于兩種算法的預測結果。
可見基于對抗學習的指針自適應識別算法優于霍夫圓算法。另外,本文所提出的方法選取了不同位姿下的圖片進行水平處理,使得處理結果更具有泛化性,更符合實際應用檢測場景。
4結論
針對指針儀表自動快速讀數識別的難點,本文提出了基于對抗學習的指針儀表自適應讀數識別算法。針對指針儀表的安裝位姿有較大隨機性的特點,采用了對抗學習中的數據增強技術,通過優化搜索模型識別不準的圖像旋轉角度、平移距離以及縮放比例構造訓練數據,提高目標檢測模型在指針儀表位姿發生變化時的準確率。
實驗以工礦企業中常用的SF6壓力儀表為研究對象,實驗結果表明讀數識別的誤差在1%以內,并與圖像預處理和霍夫圓檢測的方法作了比較,證明了所提出算法的有效性。
參考文獻
[1] HAN J, LI E, TAO B, et al. Reading recognition method of analog measuring instruments based on improved hough transform [C]//International Conference on Electronic Measurement & Instruments, Chengdu, China, 2011: 337-340.
[2] YANG B, LIN G, ZHANG W. Auto-recognition method for pointer-type meter based on binocular vision[J]. Journal of Computers, 2014, 9(4): 787-793.
[3] 侯玥,王開宇,金順福.一種基于YOLOv5的小樣本目標檢測模型[J].燕山大學學報,2023,47(1):64-72.
HOU Y, WANG K Y, JIN F S. A few-shot object detection model based on YOLOv5[J]. Journal of Yanshan University,2023,47(1):64-72.
[4] 韓紹超,徐遵義,尹中川,等.指針式儀表自動讀數識別技術的研究現狀與發展[J]. 計算機科學,2018, 45(6):54-57.
HAN S C, XU Z Y, YIN Z C, et al. Research review and development for automatic reading recognition technology of pointer instruments[J]. Computer Science, 2018, 45(6):54-57.
[5] 張志鋒,王鳳琴,田二林,等.基于機器視覺的指針式儀表讀數識別[J].控制工程, 2020, 27(3):581-586.
ZHANG Z F, WANG F Q, TIAN E L, et al. Machine vision based reading recognition for a pointer gauge[J]. Control Engineering of China, 2020, 27(3):581-586.
[6] LIU Y, LIU J, KE Y. A detection and recognition system of pointer meters in substations based on computer vision[J]. Measurement, 2020, 152(C): 107333.
[7] LIU J, WU H, CHEN Z. Automatic identification method of pointer meter under complex environment[C]//12th International Conference on Machine Learning and Computing, Shenzhen, China, 2020: 276-282.
[8] 王康,陸生華,陳潮,等.基于YOLOv5的指針式儀表檢測與讀數識別算法研究[J].三峽大學學報(自然科學版),2022,44(6):42-47.
WANG K, LU S H, CHEN C, et al. Research on detection and reading recognition algorithm of pointer instrument based on YOLOv5[J]. Journal of China Three Gorges University (Natural Sciences),2022,44(6):42-47.
[9] ENGSTROM L, TRAN B, TSIPRAS D, et al. Exploring the landscape of spatial robustness[C]//International Conference on Machine Learning, Long Beach, USA, 2019: 1802-1811.
[10] 王明,崔冬,李剛,等.融合判別區域特征與標簽傳播的顯著性目標檢測[J].燕山大學學報,2019,43(5):455-461.
WANG M, CUI D, LI G, et al. Salient object detection by integrating discriminative region feature and label propagation[J]. Journal of Yanshan University,2019,43(5):455-461.
[11] BAY H,TUYTELAARS T,GOOL L V.SURF: speeded up robust features [J].Computer Vision & Image Understanding,2006,110(3):404-417.
[12] CALONDER M,LEPETIT V,STRECHA C,et al. BRIEF:binary robust independent elementary features[C]//European Conference on Computer Vision, Grete, Greece,2010:778-792.
[13] ZOU Z, CHEN K, SHI Z, et al. Object detection in 20 years: a survey[J]. Proceedings of the IEEE, 2023, 111(3): 256-276.
[14] LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[15] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]//IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA,2016: 779-788.
[16] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]// Advances in Neural Information Processing Systems, Montreal, Canada,2015: 1-12.
[17] 許立輝,楊開元,徐東東.基于計算機視覺的指針儀表盤識別算法與系統設計[J].儀器儀表用戶,2023,30(2):56-60.
XU L H, YANG K Y, XU D D. Recognition algorithm and system design of pointer panel based on computer vision[J]. Instrument Users, 2023, 30(2): 56-60.
Adaptive reading recognition algorithm of pointer instrument
based on adversary learning
Abstract: To address the problems of high cost, inaccuracy, and low efficiency in manual reading of pointer instruments, a pose-invariant adaptive reading recognition algorithm of pointer instrument based on adversarial learning is proposed. This algorithm utilizes an object detection model to identify the position and attitude of the pointer instrument in the image, calibrates the pointer instrument and uses digital image processing technology for reading recognition. In order to improve the recognition effectiveness of the object detection model on pointer instrument images with different poses, a data augmentation technology based on adversarial learning is proposed, which constructs training data by optimizing rotation angles, translation distances, and scaled ratios of images that lead to inaccurate recognition, to improve the accuracy of the object detection model when the pointer instrument′s pose changes. The research focuses on the SF6 pressure instrument commonly used inindustrial and mining enterprises, and experimental results show that the error of reading recognition is within 1%, which proves the effectiveness of the proposed algorithm.
Keywords: pointer instrument; reading recognition; object detection; pose-invariant; adversarial learning
