基于串并行雙分支網絡的沖擊波信號重構方法
2024-04-11 01:38:04孫傳猛陳嘉欣裴東興馬鐵華
振動與沖擊 2024年6期
孫傳猛, 陳嘉欣, 原 玥, 裴東興, 馬鐵華
(1. 中北大學 省部共建動態測試技術國家重點實驗室,太原 030051;2. 中北大學 電氣與控制工程學院,太原 030051)
爆炸沖擊波[1]對有生目標的毀傷,是超壓峰值、比沖量、正壓作用時間等特征參量[2]綜合作用的結果。準確采集沖擊波信號的瞬態信息,是武器威力以及目標毀傷評估的重要途徑。然而,受爆炸場空間以及試驗成本限制,往往只能在特定角度、有限距離內布置有限數量的測壓裝置(如圖1所示),捕獲的數據十分稀疏。此外,當進行沖擊波超壓測試時,破片擊中、電磁干擾、高溫環境等惡劣狀況,極易造成瞬態信號采集終止,使得采集的信號不完整,出現殘缺現象(如圖2所示)。顯然,深入研究爆炸沖擊波信號重構技術,通過有限測點數據重建沖擊波場內壓力分布、通過殘缺數據重構完整的沖擊波壓力曲線,對武器威力以及目標毀傷評估具有重要價值。
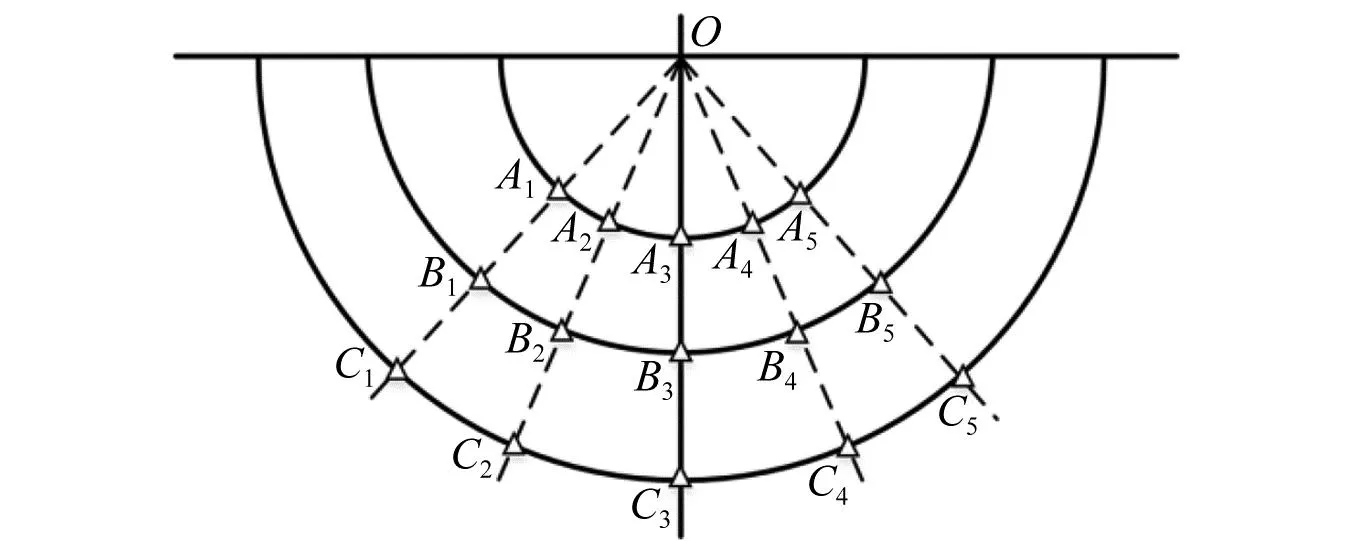
圖1 某沖擊波超壓測試測點布置示意[3]Fig.1 A shock wave overpressure test measurement point arrangement schematic
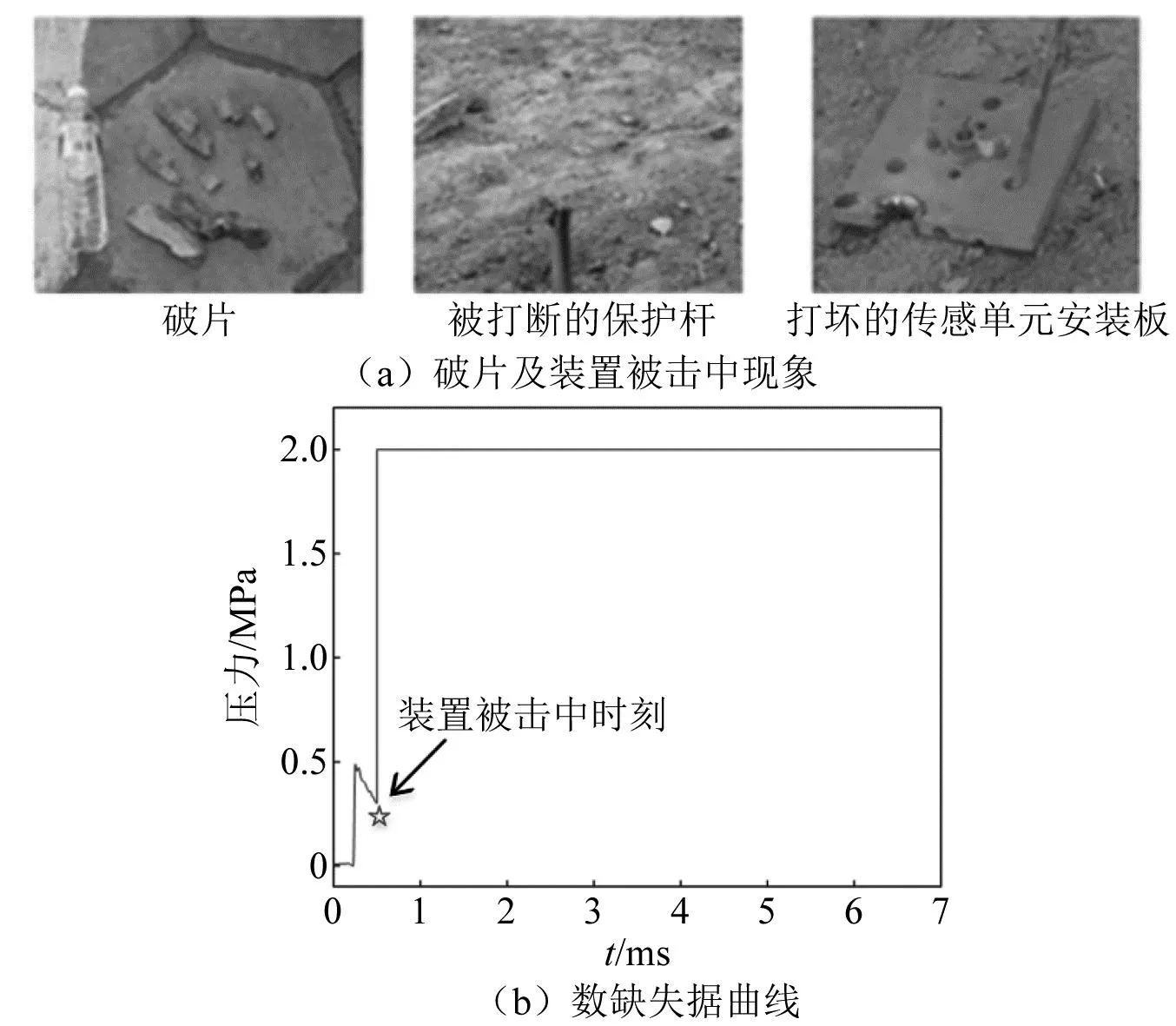
圖2 某沖擊波測試曲線Fig.2 A curve of a shockwave test
沖擊波超壓場重建方法主要包含兩種:第一種是射線追蹤方法[4]、走時線性插值法[5]、反相射線追蹤的走時線性插值法[6]、基于廣義逆算法改進的射線追蹤方法[7-11]等借鑒地球物理結構的方法;上述諸方法受測點數量少、射線路徑彎曲等因素影響,重建效果不夠理想。第二種是基于統計數據的沖擊波重建算法,包括以測點超壓峰值進行B樣條插值法[12]、基于迭代的幾何基的平面和空間三次均勻B樣條曲線插值法[13]、基于非均勻有理B樣條蛛網插值算法[14]、基于先驗信息的EM(expectation maximization)反演算法[15]、基于Zipple算法和高斯牛頓算法[16]以及三次樣條插值算法、Biharmonic樣條曲面插值算法和徑向基函數網絡插值算法[17]等;這些方法單純地使用完全相同的統計值或假設兩測量值間數據服從某種分布進而填充所有缺失數據可能是過于武斷的。
沖擊波殘缺信號重構技術則多關注于壓縮感知方法。將壓縮感知理論[18-23]應用于沖擊波信號重構中往往面臨苛刻的限制條件:稀疏矩陣選取必須合適;稀疏矩陣、觀測矩陣必須不相關;信號需滿足聯合稀疏先驗性等。基于機器學習[24]的信號重構方法是另一種可行方法,使用機器學習算法擬合整個訓練數據集的分布,以缺失值周圍數據的屬性值和整個數據集整體分布來定制生成重構值[25-26]。但是,機器學習算法沒有考慮數據集中的時序關系,難以學習時序數據的時間先后關系與數據變化規律。此外,采用平均值、中位數、眾數等統計數據來填充信號缺失值[27],也是應用較多的信號重構方法,但存在假設過于武斷等問題。
深度學習是對數據特征由低層到高層的逐步抽象和概念化過程,是一種自主學習識別方法,可以敏銳地捕捉信號高階特征信息[28],為沖擊波信號重構提供了潛在有效手段。然而,目前利用深度學習進行信號重構的研究較少,典型如王旭磊、王鑫[29]、羅永洪[30]利用生成對抗網絡對時序數據缺失值填充進行了探索性研究,然而生成對抗網絡存在難以訓練的問題,生成器和判別器在不斷博弈中達到均衡,過久的博弈過程可能會使生成器開始退化,總是生成相同的樣本點而無法繼續學習,這對于信號重構研究而言是難以控制的;豆佳敏[31]利用深度學習技術對沖擊波信號壓縮感知方法進行了探索性研究,該方法不需要大量數據對網絡模型進行訓練,而是對每一個信號進行單獨學習,進而實現端到端的恢復,規避了稀疏矩陣的設計環節,但該方法仍受限于壓縮感知方法,難以學習數據中潛在的高階特征;孫傳猛等利用一維卷積神經網絡(convolutional neural networks, CNN)結合BiLSTM(bi-directional long short-term memory)模型對數據特征進行上采樣實現沖擊波信號的重構,該方法是一種基于端到端的深度學習方法,綜合考量了信號的時序關系、頻譜特征、數據變化規律等特征信息,并在此基礎上對數據特征逐步抽象和概念化,從而自主學習信號中的高階特征信息。
綜上所述,目前爆炸沖擊波信號重構技術還存在諸多問題:①相關研究著重于局部特征(如超壓峰值)的分析,往往忽視了全局特性對沖擊波信號重構的影響;②已有重構技術對深度學習捕捉高階特征的能力利用不夠充分,僅建立了較為簡單的非線性映射關系;③已有重構技術缺少對信號時序特征和全局依賴關系的表征,難以掌握復雜的信號本征規律。因此,本文利用Res-GRU模塊捕捉沖擊波超壓信號時序依賴關系等局部特征,利用Trans模塊捕捉信號全局潛在特征,提出高階特征融合機制實現不同階段信息逐層互補,進而形成基于串并行雙分支網絡(簡記為G-TNet)的沖擊波信號重構技術。最后,利用模擬信號和實測信號開展沖擊波信號重構試驗研究,驗證本文方法的有效性和優越性。研究結果對爆炸沖擊波信號重構具有重要指導意義。
1 本文方法
1.1 串并行雙分支網絡(G-TNet)
在沖擊波信號重構過程中,無論是射線追蹤方法、統計數據方法,還是壓縮感知方法、機器學習方法,抑或當前熱門的深度學習方法,本質上都是利用某種“特征表示”來表征信號的本征特征進而進行信號填充或預測;不同在于該“特征表示”是人為設計的(傳統的射線追蹤方法、統計數據方法、壓縮感知方法、機器學習方法等諸方法),還是通過模型自動學習的(深度學習方法)。
對于沖擊波信號而言,無論峰值壓力高低、持續時間長短、噪聲干擾強弱,其本質都是一種在連續介質中傳播的力學參量發生階躍的擾動,是理想沖擊波信號(如圖3所示)對不同測試對象與環境的差異化表現。根據通用近似定理[32-33],一定存在某種深度學習網絡,能夠通過由底層到高層逐步抽象和概念化沖擊波信號特征,從而自動學習到其語義特征(本征特征)。而現有技術方案難以有效應對沖擊波超壓場綜合性不利因素的挑戰的主要原因在于,其特征表示要么是淺層的,不屬于語義特征(對傳統方法而言);要么是自動學習到的語義特征表示不夠準確(對深度學習方法而言),進行信號填充或預測時造成較大誤差。
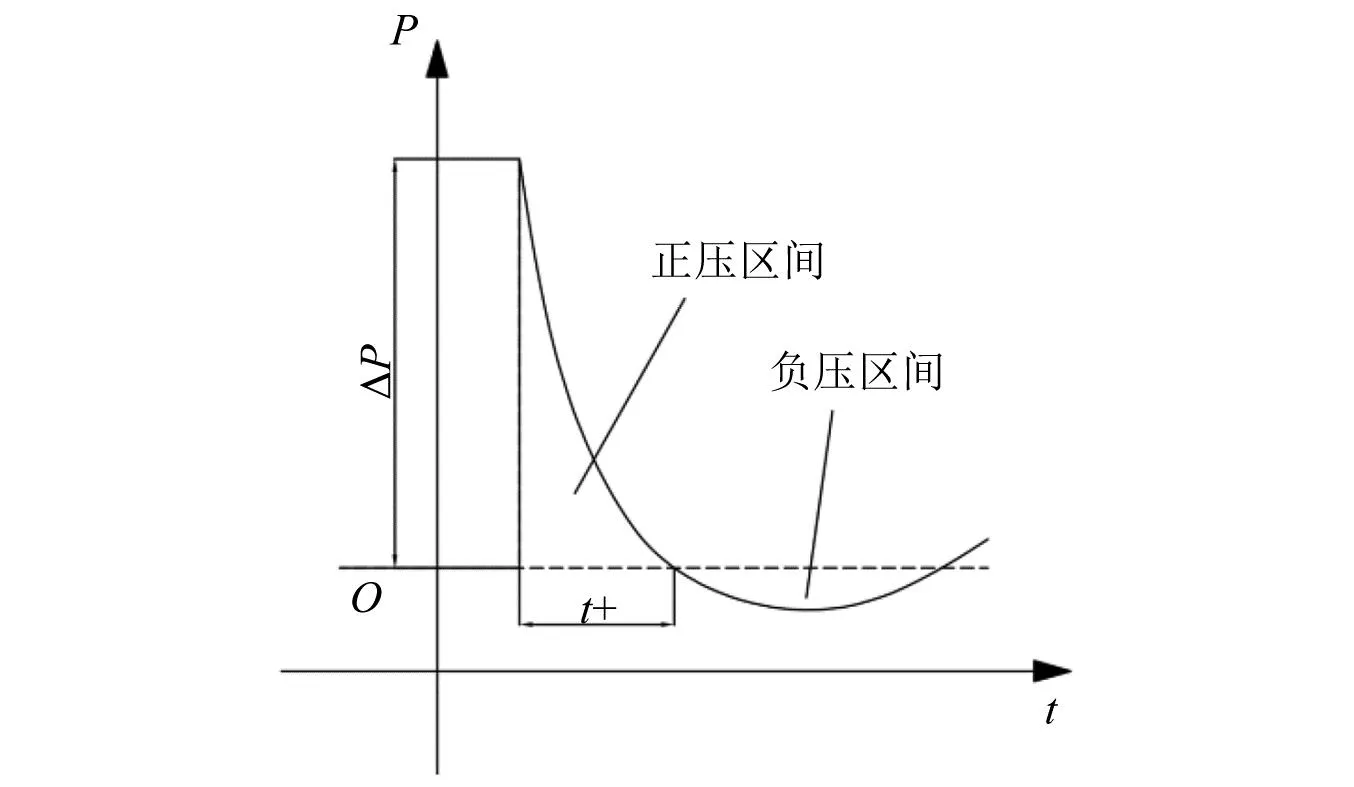
圖3 理想沖擊波時域波形Fig.3 The ideal time domain waveform of shock wave
顯然,沖擊波超壓場信號重構的難點在于:如何構建一種能有效表征沖擊波信號語義特征的深度學習模型,以及如何實現局部時序依賴關系與全局潛在特征之間的平衡。這里的“局部時序依賴關系”是指信號的時序數據的時間先后關系與數據變化規律,這是基于鄰域的、局部的聚焦性特征信息;而“全局潛在特征”是指各聚焦性特征之間的長距離依賴關系,是充分地利用“上下文”信息、建立在信號全局理解基礎之上的特征信息。
利用深度學習技術進行序列數據處理時有串行與并行兩種重要的處理方式。串行方式是指輸入序列的每個元素都依次被處理,并將前一個元素的狀態作為后一個元素的輸入。典型的如循環神經網絡(recurrent neural network, RNN),t時刻的輸出依賴t-1 時刻的計算結果。串行方式能夠適應于某一事物隨時間的變化狀態或程度,加強前后數據的關聯性。顯然,利用串行方式十分有利于時序依賴關系等局部特征的提取。并行方式則不依賴數據輸入的先后順序,典型的如Transformer模型。通過自注意力機制,Transformer模型可以同時處理整個序列,而無需像傳統的序列模型一樣依次處理每個元素。Transformer模型可以實現完全并行的計算,更好地捕捉長距離的依賴關系,計算全局的依賴關系,更容易地解釋預測結果,處理不定長序列。值得注意的是,RNN在學習過程中由于梯度消失或爆炸問題,很難建模長時間間隔的狀態之間的依賴關系,即長程依賴問題;門限循環單元(gated recurrent unit,GRU)引入更新門和重置門等門控機制來控制信息的累積速度,有助于解決長程依賴問題。
因此,針對爆炸沖擊波信號重構問題,本文提出了一個基于GRU和Transformer模型的串并行雙分支網絡(簡記為G-TNet)。G-TNet結構如圖4(a)所示,由Embedding層、雙分支結構、用于耦合分支的特征融合單元(feature merging unit,FMU)和用于輸出的線性層所組成。其中:
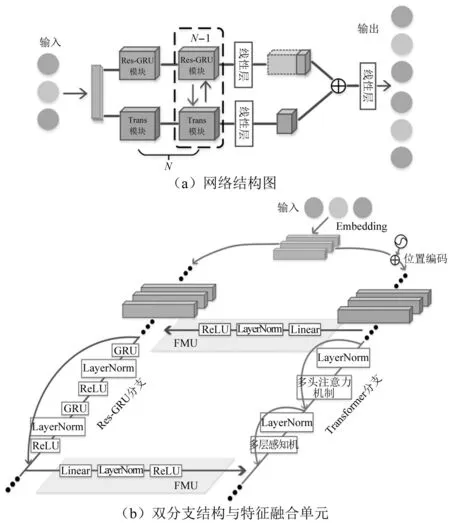
圖4 G-TNet網絡結構Fig.4 G-TNet model structure
(1) 鑒于沖擊波測試過程中采樣率、比例距離、測點位置、信號殘缺與否等不同導致的信號長度差異,G-TNet使用Embedding層來創建一個低維稠密向量以適應不同長度的輸入數據。經過Embedding層后每一輸入數據具有了相同維度的向量表示,其輸出結果可直接由Res-GRU分支進行處理,而對于Transformer分支對輸入數據并行處理的要求,則需增加位置編碼來區分沖擊波信號中相同數據所處的不同位置。
(2) 雙分支結構分為Res-GRU分支和Transformer分支。Res-GRU分支以串行方式捕捉沖擊波超壓信號時序依賴關系等局部特征,Transformer分支以并行方式捕捉信號潛在全局特征。G-TNet考慮到兩種特征的差異性與互補性,將全局上下文信息從Transformer分支逐漸傳遞至Res-GRU分支的特征映射中,以增強該分支的全局感知能力。同樣,Res-GRU分支所產生的局部特征信息也反饋到Transformer分支的特征映射中,以豐富該分支的局部細節信息。而FMU持續的融合特征實現了兩種信息的互補,如圖4(b)所示。
(3) 在雙分支結構中,Res-GRU分支與Transformer分支均由N個重復的Res-GRU模塊和Trans模塊組成。輸入信號經Embedding層后,首先經過一個Res-GRU模塊和Trans模塊提取初始特征;然后,FMU從第二個Res-GRU模塊和Trans模塊開始應用,連接Res-GRU分支中的局部特征和Transformer分支中的全局表示。這樣,G-TNet的雙分支結構可以最大限度地保留局部特征和全局特征,而FMU作為連接分支,在不同階段充分融合局部與全局特征,實現高階語義信息互補。
1.2 Res-GRU模塊
Res-GRU模塊結構如圖5(a)所示,包含了兩組GRU層、激活函數層和用于歸一化特征的LayerNorm層,并在每兩組網絡之間增加一個捷徑連接。GRU層為一個門控循環單元,結構如圖5(b)所示,利用更新門和重置門機制,有選擇性地增加新的信息和有選擇性地遺忘已有累積信息,即
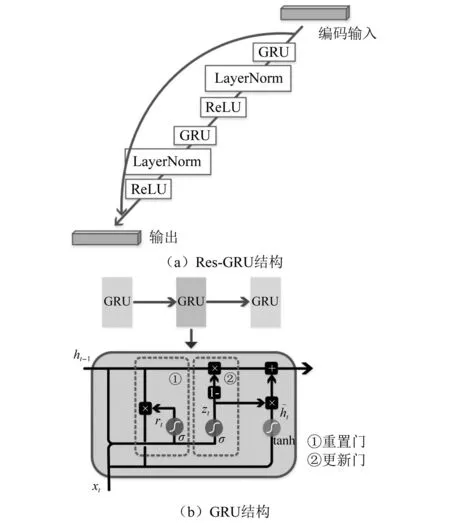
圖5 Res-GRU模塊Fig.5 Res-GRU block
(1)
式中:ht為GRU層當前時刻t的輸出;zt為更新門
zt=σ(Wzhht-1+Wzxxt)
(2)
式中:xt為GRU層當前時刻t的輸入;σ(·)為Logistic函數;Wzh和Wzx為更新門相關連接權重。
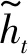
(3)
rt=σ(Wrhht-1+Wrxxt)
(4)
式中: tanh(·)為Tanh激活函數;Wrh和Wrx為重置門相關的連接權重。
Res-GRU模塊的捷徑連接是極為必要的。G-TNet共包含N個串聯的Res-GRU模塊,網絡層數是非常深的。G-TNet這種較深的網絡設計,一方面有助于高階特征的進一步抽象,使其進一步接近語義特征;而另一方面在學習過程中利用誤差反向傳播算法更新權重時存在著較大的梯度消失風險。捷徑連接將Res-GRU分支網絡近似逼近原始目標函數轉換為近似逼近殘差函數,而在實際中后者更容易學習[34]:①Res-GRU分支可能存在冗余,而捷徑連接的恒等映射機制保證經過該恒等層的輸入和輸出完全相同,解決了網絡深度冗余造成的模型性能退化現象;②在網絡輸出中增加了輸入項x,在利用誤差反向傳播算法更新權重時,該網絡對x求偏導時會增加值為1的常數項,使得梯度連乘不會造成梯度消失。
1.3 Trans模塊
Trans模塊主要借鑒Transformer的編碼塊結構,依次由LayerNorm層(用于歸一化特征)、Multi-head Self-attention 層(多頭自注意力機制)、LayerNorm層、多層感知機構成,并在每個LayerNorm層之前增加一個捷徑連接,如圖6(a)所示。Multi-head Self-attention 會并行地計算多個不同參數的self-attention值,并將各個self-attention 值拼接作為后續網絡的輸入。其中,self-attention 值計算通常采用QKV模式,如圖6(b)所示。
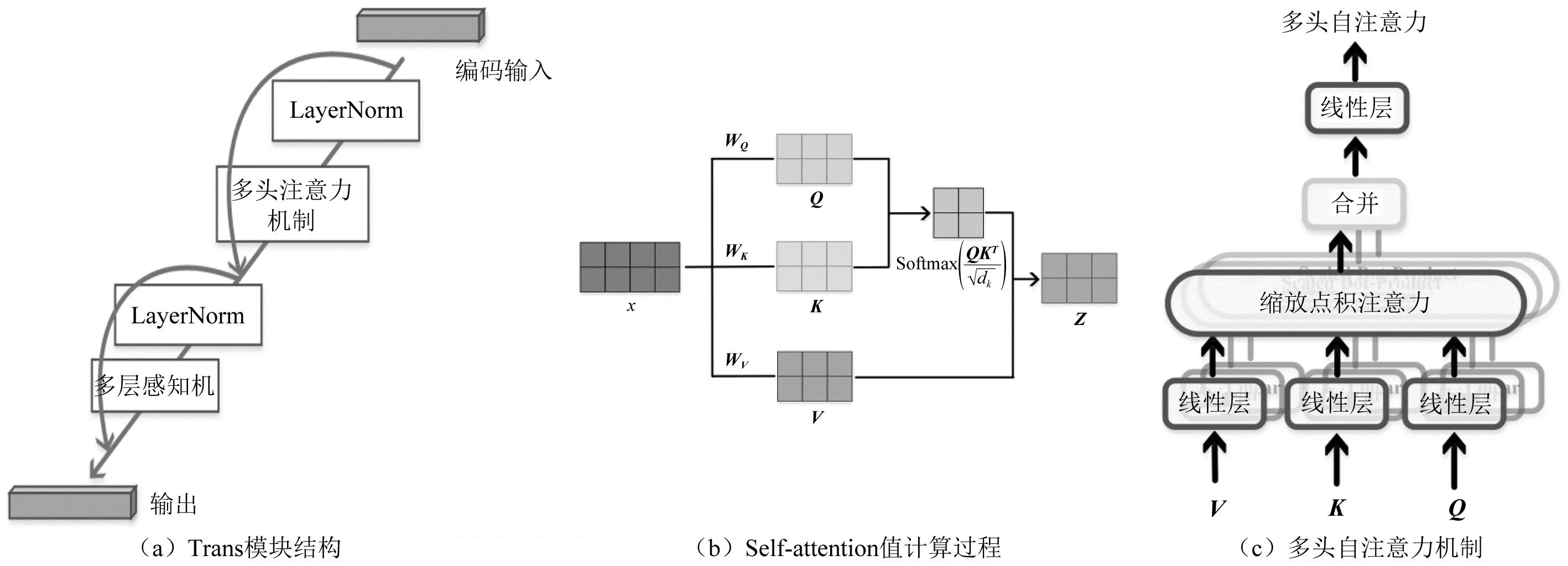
圖6 Trans模塊與多頭自注意力機制Fig.6 Trans block &Multi-head Self-attention mechanism
(1) 首先,將輸入數據X經線性映射分別獲得Q、K、V矩陣
(5)
式中,WQ、WK和WV分別為線性映射的參數矩陣。
(2) 然后,計算對序列中不同數據的關注程度Score
(6)
式中,dk為K的維度。
(3) 最后,使用縮放點積方法獲得最終的self-attention值Z
Z=Softmax(Score)·V
(7)
對于Multi-head Self-attention機制,則使用多組權重值來轉換不同的Q、K、V矩陣分別計算相應的自注意力值Z,最終將Z矩陣進行拼接,如圖6(c)所示。Multi-head Self-attention通過Q去查詢K當中比較重要的信息,得到相應的權重矩陣,再乘以V,讓V去關注更重要的信息,忽略更不重要的信息。這樣,Multi-head Self-attention機制可以從輸入的沖擊波信號中,有選擇地篩選出少量重要信息并聚焦到這些少量重要信息上,而忽略大多不重要的信息。
同樣,Trans模塊的捷徑連接也起著防止梯度消失和模型退化的作用。值得注意的是,GRU等前述串行網絡本身就是一種順序結構,天生包含了沖擊波信號各數據的位置信息;而Trans模塊對數據處理采用的是并行方式,即同一個沖擊波信號的所有數據一起輸入到網絡中進行并行訓練。這種并行訓練方式丟失了每個數據在沖擊波信號中的位置信息,這對沖擊波信號重構而言是不可接受的。一種行之有效的辦法是對輸入的數據進行位置編碼,以區分相同數據在信號中的不同位置。在沖擊波信號重構網絡訓練中,對Trans模塊采用正余弦編碼方式,如式(8)、式(9)所示。
PE(pos,2i)=sin(pos/10 0002i/dmodel)
(8)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel)
(9)
式中:PE為位置編碼;pos為前數據所處位置;dmodel為Embedding層的向量長度;i的取值范圍為0,1,…,dmodel。
1.4 特征融合單元
Res-GRU模塊按照串行的方式依次對信號的數據進行處理,利用過去的隱藏狀態來捕獲對先前數據的依賴性,保留了沖擊波信號局部時序依賴關系;而Trans模塊利用Multi-head Self-attention機制作為網絡的特征提取器,將信號作為整體處理,不依賴于過去的隱藏狀態來捕獲對先前數據的依賴性,從而允許并行計算,并減少由于長期依賴性而導致的性能下降。
可見,基于Res-GRU模塊的Res-GRU分支與基于Trans模塊的Transformer分支,分別利用串、并行方式提取了局部與全局等不同形式的信號語義特征,而這些語義特征是可能存在錯位風險的。因此,需要添加特征融合單元以消除語義特征錯位。本文構建了如圖4(a)所示的FMU,以互補交互的方式將局部信息和全局表示連續耦合。由Res-GRU模塊和Trans模塊性質可知,通過設定其模型節點數和Embedding層輸出大小則可控制中間層特征映射大小。因此,本文設定相同大小的向量長度以方便兩種信息融合。在G-TNet網絡中,從Res-GRU分支(Transformer分支)的第二個Res-GRU模塊(Trans模塊)開始使用FMU來消除語義特征錯位,在線性層、LayerNorm層和激活函數層分別對特征進行對齊,逐步填補各自分支的語義空白。
2 試驗研究
2.1 試驗方案
首先,建立沖擊波信號數據集,由兩部分構成:①根據經驗公式生成的模擬信號(其時序長度為1 000,混雜有均值為0、方差為0.001的高斯噪聲);②實測的沖擊波超壓信號。
然后,將數據集分為訓練集和測試集。利用訓練集完成重構模型對沖擊波信號特征的學習;利用測試集檢驗爆炸沖擊波信號重構模型的性能。
最后,基于本文所提G-TNet模型分別進行針對有限測點數據的沖擊波超壓信號重構試驗和針對殘缺數據的沖擊波超壓信號重構試驗;通過與最新的典型重構方法(GAN-GRU、BiLSTM[35]和CNN-BiLSTM方法)對比,并設置不同的消融試驗,以驗證本文方法的有效性和優越性。
2.2 試驗環境及超參數設置
本次試驗的硬件環境:Intel Xeon Gold 5218R CPU,256 GB內存,Nvidia RTX A6000 GPU 48 GB。軟件環境:操作系統為64位的Window10,開發環境是Pycharm 2022.2.3,開發語言為Python3.7.0+PyTorch1.7。
本次對比試驗及消融試驗設置相同的超參數:采用Adam優化器,初始學習率為0.001,共訓練60個Epochs,學習率分別在第30個和第50個Epochs處衰減0.5倍。Embedding層輸出向量長度為128,Trans模塊中heads設置為6。損失函數采用L1+L2損失。對于GAN-GRU模型,考慮其訓練方式不同,設置迭代次數為200個Epochs。
2.3 評價指標
考慮到沖擊波超壓信號通常以超壓峰值、正壓作用時間、比沖量作為毀傷威力的考核指標,本文選擇均方誤差(mean square error, MSE)、平均絕對誤差(mean absolute error,MAE)、平均峰值誤差、平均正壓時間誤差和平均比沖量誤差作為模型輸出結果的評價指標。
(1) MSE反映真實值與重構值之間差異平方的平均。
(2) MAE反映真實值與重構值之間差異絕對值的平均。
(3) 平均峰值誤差(EP),反映沖擊波真實信號與重構信號之間超壓峰值相對誤差的平均值
(10)
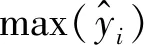
(4) 平均正壓時間誤差(ET),反映沖擊波真實信號與重構信號之間正壓時間的相對誤差平均值
(11)
式中:X為正壓區間的橫坐標值;XMAX、XMIN分別為正壓區間的終點和起點;
(5) 平均比沖量誤差(ES),反映沖擊波真實信號與重構信號之間比沖量的相對誤差平均值
(12)
(13)
式中:M為沖擊波信號正壓區間的長度;S為沖擊波信號的比沖量。
2.4 結果與討論
2.4.1 針對有限測點數據的沖擊波信號重構試驗
(1) 模擬沖擊波信號重構試驗結果與討論
針對有限測點數據的模擬沖擊波信號重構試驗,模型的輸入數據為不同測點與爆炸中心的比例距離值,輸出結果為重構的沖擊波信號,結果如圖7(因篇幅有限,僅展示部分數據)與表1所示。在圖7中,原始沖擊波信號為深色,重構沖擊波信號為淺色(下同);表1中: Parameters與FLOPs分別為深度學習網絡模型的參數量和計算量; 加粗數字表示相應指標下的最優值(下同)。

表1 模擬沖擊波信號的沖擊波場壓力分布重構試驗結果Tab.1 Experimental results of reconstructing pressure distribution in shock wave field by simulating shock wave signal
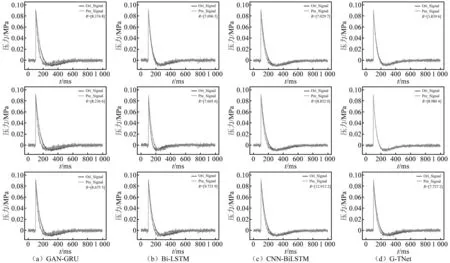
圖7 模擬沖擊波信號的場壓力分布重構結果Fig.7 Reconstruction results of field pressure distribution of simulated shock wave signals
由圖7可知: GAN-GRU、BiLSTM、CNN-BiLSTM和G-TNet(本文方法)均得到了較為理想的重構結果,而G-TNet重構曲線與原始曲線貼合最為緊密,表明G-TNet對沖擊波語義特征的捕捉能力最強,重構的沖擊波曲線最為準確。由表1可知:G-TNet重構信號的MSE、MAE、平均峰值誤差(EP)、平均正壓時間誤差(ET)、平均比沖量誤差(ES)均為最低值,取得了最優結果;G-TNet重構信號平均峰值誤差(EP)、平均正壓時間誤差(ET)、平均比沖量誤差(ES)分別為0.49%、15.62%、17.66%,滿足沖擊波場壓力重構指標要求;G-TNet模型的參數量和計算量分別為6.65 MB和6.66 MB,在時間復雜度、空間復雜度方面取得了較好的平衡。這表明G-TNet能夠較好地實現不同測點位置的沖擊波信號重構。
(2) 實測沖擊波信號重構試驗結果與討論
針對有限測點數據的實測沖擊波信號重構試驗結果如圖8(因篇幅有限,僅展示部分數據)與表2所示。由圖8可知:當輸入數據的特征較多時,GAN-GRU難以收斂,而BiLSTM、CNN-BiLSTM和G-TNet均實現了信號重構;而G-TNet重構曲線與原始實測曲線貼合最為緊密。由表2可知,G-TNet重構信號的MSE、MAE、平均峰值誤差(EP)、平均正壓時間誤差(ET)、平均比沖量誤差(ES)均為最低值,取得了最優結果;G-TNet重構信號平均峰值誤差(EP)、平均正壓時間誤差(ET)、平均比沖量誤差(ES)分別為27.01%、15.91%、19.33%,滿足沖擊波場壓力重構指標要求;G-TNet模型的參數量和計算量分別為31.43 MB和31.44 MB,在時間復雜度、空間復雜度上也較為平衡。這表明G-TNet對實測信號重構仍具有良好的適應性,能夠較好地實現不同測點位置的沖擊波信號重構。

圖8 實測沖擊波信號的場壓力分布重構結果Fig.8 Reconstruction results of the field pressure distribution of the measured shock wave signal
2.4.2 針對殘缺數據的沖擊波超壓信號重構試驗
(1) 模擬沖擊波信號重構試驗結果與討論
將模擬的殘缺數據沖擊波信號測試數據輸入到訓練好的爆炸沖擊波信號重構模型中,對殘缺信號進行重構以期獲得完整的沖擊波信號。沖擊波殘缺曲線重構試驗中的輸入數據為信號的前半段部分,本文選擇時序信號中的前130個數據(即認為在第130個數據點時沖擊波信號開始缺失),模型輸出結果為重構沖擊波信號的后半段部分,試驗結果如圖9(因篇幅有限,僅展示部分數據)和表3所示。由表3可知,G-TNet相對于其他方法達到了最優結果,MSE為5×10-6、MAE為0.001,對比其他方法有明顯提升,該結果表明G-TNet能夠較好地實現對沖擊波殘缺信號的重構。
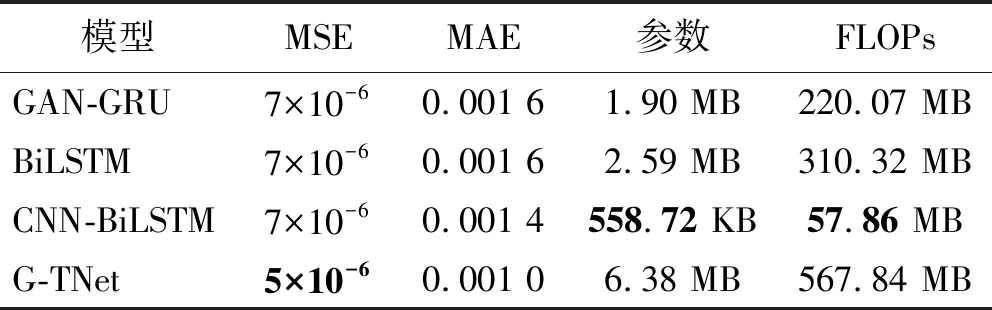
表3 模擬沖擊波信號的殘缺數據重構試驗結果
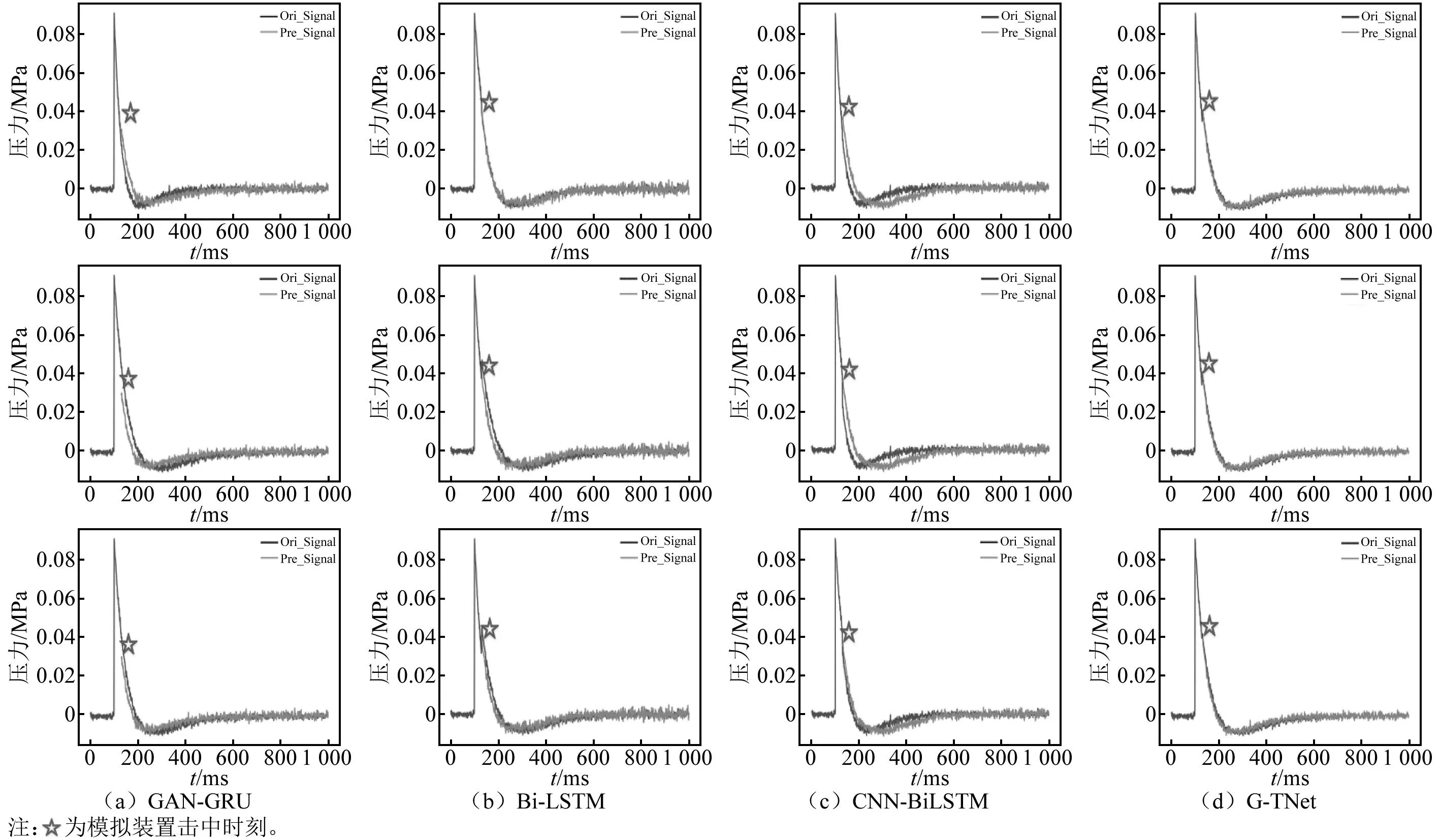
圖9 模擬沖擊波信號的殘缺數據重構結果Fig.9 The results of reconstructing the residual data of the simulated shock wave signals
(2) 實測沖擊波信號重構試驗結果與討論
利用實測沖擊波信號驗證爆炸沖擊波信號重構模型,選擇前3 000個數據作為模型的輸入(即認為在第3 000個數據點時沖擊波信號開始缺失),模型輸出結果為重構沖擊波信號的后半段部分,結果如圖10(因篇幅有限,僅展示部分數據)和表4所示。由圖10和表4可知, G-TNet 重構信號的MSE和MAE分別為0.000 5和0.017 1,表明G-TNet對實測信號重構仍具有良好的適應性。
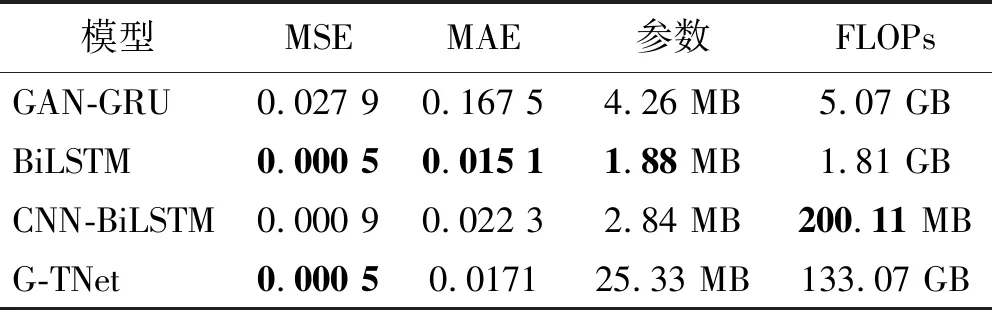
表4 實測沖擊波信號的殘缺數據重構試驗結果
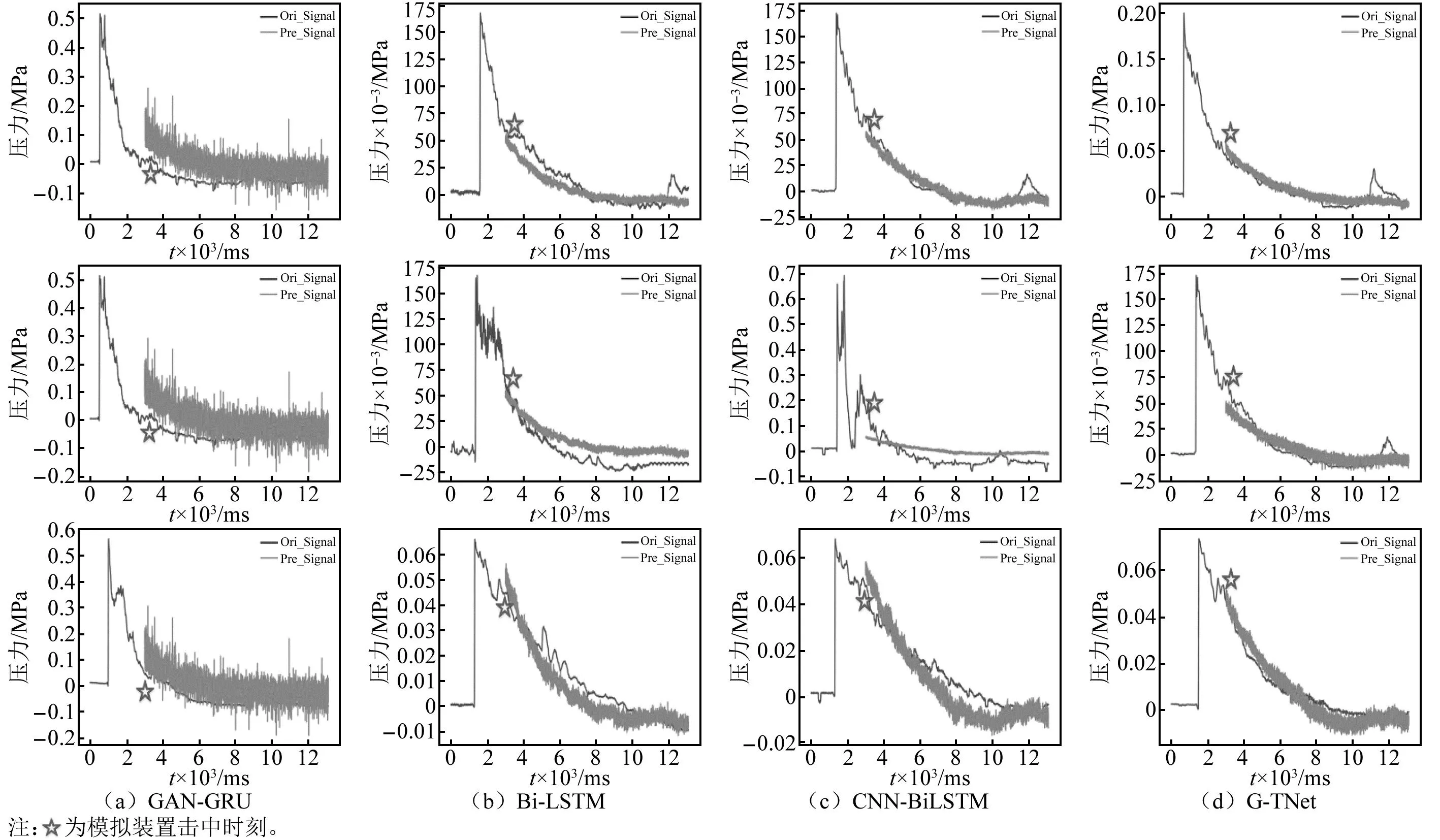
圖10 實測沖擊波信號的殘缺數據重構結果Fig.10 The results of the reconstruction of the residual data of the measured shock wave signal
2.4.3 消融試驗
為了進一步分析G-TNet的性能,設置兩組消融試驗:①屏蔽Res-GRU分支,僅保留Transformer分支,并加深該分支;②屏蔽Transformer分支,僅保留Res-GRU分支,并加深該分支。消融試驗結果如表5~表6所示,部分試驗圖像如圖11~圖12所示。

表5 模擬沖擊波信號重構消融試驗結果Tab.5 Test results of simulated shock wave signals reconstruction ablation
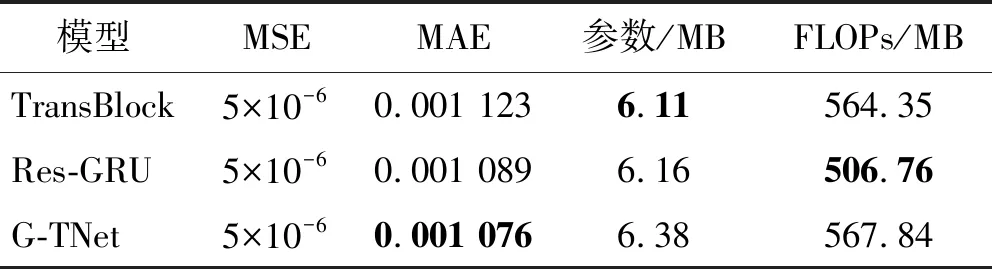
表6 模擬沖擊波信號殘缺數據重構消融試驗結果
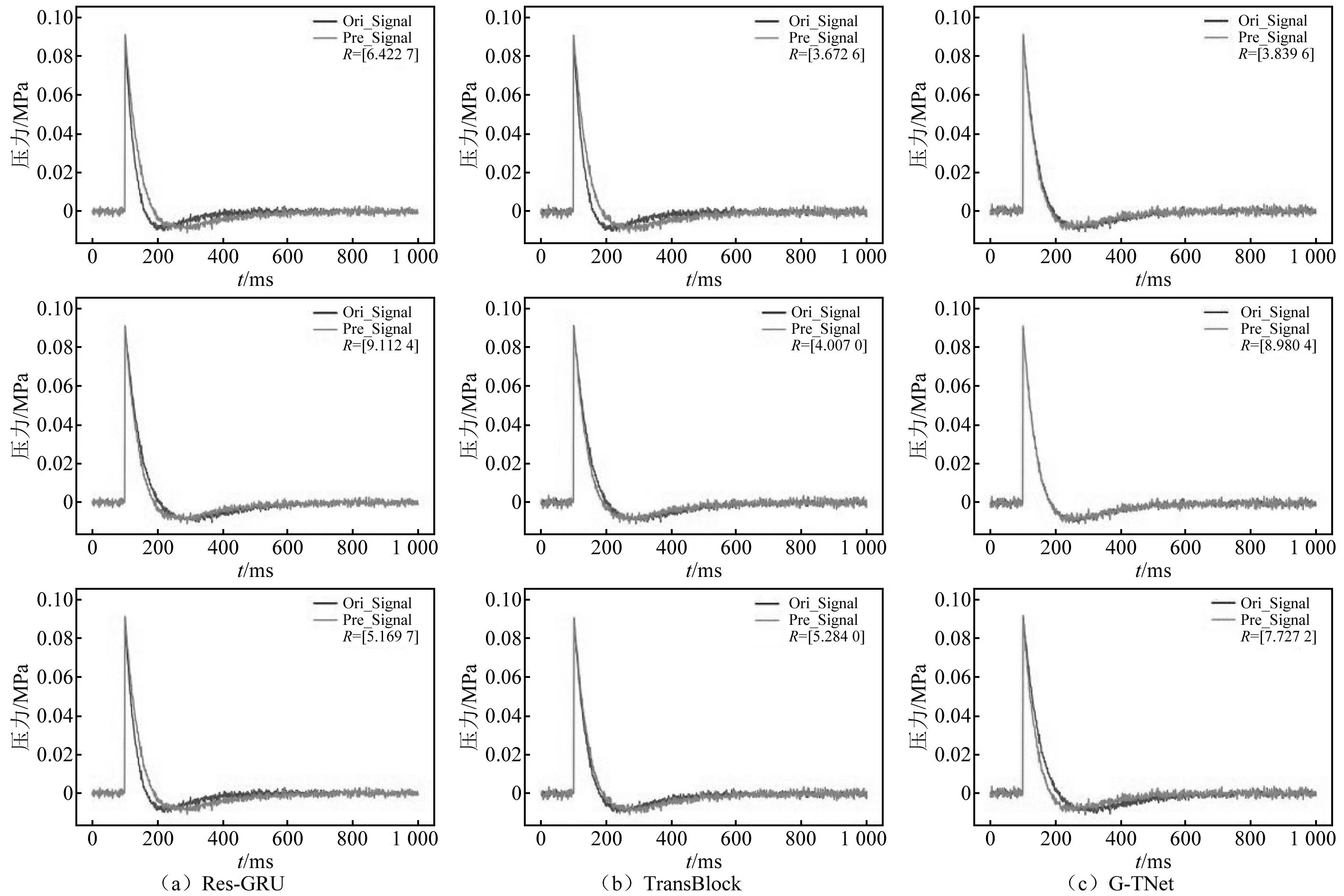
圖11 模擬沖擊波信號重構消融對比結果Fig.11 Comparison results of simulated shock wave signals reconstruction ablation
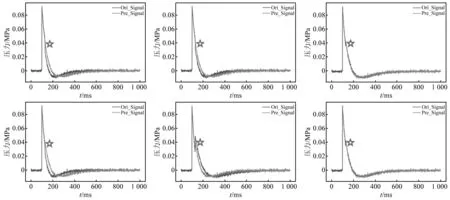
圖12 模擬沖擊波信號的殘缺數據重構消融對比結果Fig.12 Comparison results of reconstructed ablation of residual data from simulated shock wave signals
消融試驗結果表明:
(1) 在模型準確度方面,雙分支結構與特征融合單元是本文提高模型性能的關鍵,局部特征和全局信息的融合機制影響最大。
(2) Res-GRU分支所占據的參數量和計算量較少,但由于其串行處理數據的方式,缺少對全局特征的關注,導致了對信號峰值的預測能力較差。
(3) Transformer分支所占據的參數量和計算量與G-TNet相近,其以并行的方式處理數據,缺少對局部特征的關注,導致信號整體擬合效果較差。
綜上所述,在參數量和計算量相近的情況下,采用雙分支結構,逐層融合Res-GRU分支產生的局部特征和Transformer分支產生的全局信息,能夠極大改善單一分支所導致的特征分析不全面問題,且能夠滿足沖擊波超壓信號重構的多種指標要求。
3 結 論
(1) G-TNet利用Res-GRU分支以串行方式捕捉沖擊波超壓信號局部時序依賴關系,利用Transformer分支以并行方式分析信號全局潛在特征,利用特征融合單元進行高階特征融合,實現不同階段信息逐層互補,在沖擊波信號重構中綜合考量了信號的時序關系、數據變化規律等特征信息。
(2) G-TNet在基于有限測點數據的沖擊波場壓力分布重構試驗中,重建的模擬、實測超壓數據與原始值之間MSE分別為5.0×10-6、1.2×10-3,平均峰值誤差分別為0.49%、27.01%,平均正壓時間誤差分別為15.62%、15.91%,平均比沖量誤差分別為17.66%、19.33%;在基于殘缺數據的沖擊波壓力曲線重構試驗中,重構的模擬、實測信號的缺失值與原始值之間MSE分別為5.0×10-6和5.0×10-4,MAE分別為0.001 0和0.017 1;能夠滿足實際沖擊波場壓力重構的多種指標要求。
(3) 消融試驗表明,G-TNet融合不同分支所產生的全局信息和局部特征可以極大地提升模型性能,且模型的參數量和計算量不會產生過多增加。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
