基于數(shù)據(jù)增強(qiáng)的小樣本輻射源個(gè)體識(shí)別方法
2024-04-02 08:32:38王藝卉閆文君段可欣于楷澤
雷達(dá)科學(xué)與技術(shù) 2024年1期
王藝卉,閆文君,段可欣,3,于楷澤,3
(1.海軍航空大學(xué),山東煙臺(tái) 264001;2.31401部隊(duì),山東煙臺(tái) 264001;3.91423部隊(duì),山東煙臺(tái) 264001)
0 引 言
輻射源個(gè)體識(shí)別(Specific Emitter Identification,SEI)在通信對(duì)抗、頻譜資源監(jiān)測(cè)與管理、無線電干擾檢測(cè)與定位、無線電設(shè)備管理與維護(hù)等領(lǐng)域應(yīng)用廣泛[1],通過準(zhǔn)確識(shí)別輻射源個(gè)體可以鎖定惡意信號(hào)或入侵個(gè)體[2],提高頻譜利用率與無線電設(shè)備管理的有效性,確保通信系統(tǒng)的干擾沖突最小化。
在現(xiàn)實(shí)通信場(chǎng)景中,常常由于信號(hào)遮擋、長(zhǎng)距離傳輸、電磁干擾、不良天氣影響、信號(hào)加密等原因出現(xiàn)樣本數(shù)據(jù)難以獲取、捕捉樣本類別不全面等樣本數(shù)目不足的小樣本困境。
近年來,小樣本問題愈受關(guān)注,其問題的解決掣肘于數(shù)據(jù)量的缺乏。數(shù)據(jù)增強(qiáng)技術(shù)在圖像分類、目標(biāo)檢測(cè)、自然語言處理等領(lǐng)域應(yīng)用廣泛且表現(xiàn)突出,為小樣本困境的解決提供了可能。目前,較為主流的小樣本學(xué)習(xí)方法有基于度量學(xué)習(xí)、基于模型改進(jìn)和基于數(shù)據(jù)增強(qiáng)三種方法[3]。
基于度量學(xué)習(xí)的方法是通過距離度量樣本間的相似性,具有代表性的有構(gòu)造正樣本、負(fù)樣本和錨點(diǎn)來計(jì)算樣本對(duì)間距離的共享網(wǎng)絡(luò)參數(shù)孿生網(wǎng)絡(luò)、利用雙向長(zhǎng)短時(shí)記憶的元學(xué)習(xí)匹配網(wǎng)絡(luò)、以類別均值為中心的原型網(wǎng)絡(luò),其受限于缺乏數(shù)據(jù)而易受離群樣本和錯(cuò)誤標(biāo)注樣本的影響。基于模型改進(jìn)的代表性方法有借助附加的記憶模塊保存支持集中提取的特征信息進(jìn)行學(xué)習(xí)的記憶增強(qiáng)的神經(jīng)網(wǎng)絡(luò)算法[4]、跨任務(wù)訓(xùn)練尋優(yōu)的參數(shù)優(yōu)化方法[5]、引入掩碼變換網(wǎng)絡(luò)使得任務(wù)參數(shù)具體對(duì)應(yīng)子空間的高維網(wǎng)絡(luò)參數(shù)元學(xué)習(xí)算法[6]、引入注意力機(jī)制和互信信息的權(quán)重生成小樣本算法[7],顯然地,使用附加記憶模塊會(huì)提高計(jì)算成本和內(nèi)存間的需求,優(yōu)化模型或參數(shù)的方法使得難以平衡識(shí)別精度與學(xué)習(xí)速度。三者之中,數(shù)據(jù)增強(qiáng)策略更為直接。
數(shù)據(jù)增強(qiáng)(data augmentation)是一種通過擴(kuò)充樣本數(shù)量而直接有效解決樣本不足問題的方法。在圖像處理時(shí)常采用翻轉(zhuǎn)[8-9]、旋轉(zhuǎn)[10]、移位[11]、縮放[12-13]、噪聲擾動(dòng)[14]等實(shí)現(xiàn)數(shù)據(jù)擴(kuò)充的方法可以借鑒延用到無線電信號(hào)領(lǐng)域[15],這些微小的改動(dòng)雖然沒有直接增加特征信息,但使得擴(kuò)充數(shù)據(jù)集在特征空間的覆蓋范圍變大,細(xì)微差別的存在使神經(jīng)網(wǎng)絡(luò)將其視為不同的樣本,是更加有助于分類面的選擇和魯棒性的提高。
基于此,本文提出基于數(shù)據(jù)增強(qiáng)的小樣本輻射源個(gè)體識(shí)別算法。首先,通過時(shí)域翻轉(zhuǎn)、振幅反轉(zhuǎn)、振幅縮放和噪聲處理等方法對(duì)小樣本數(shù)據(jù)集進(jìn)行數(shù)據(jù)集擴(kuò)充;其次,將噪聲序列和類別標(biāo)簽輸入生成器進(jìn)一步生成“以假亂真”的生成樣本,提高生成樣本的多樣性并通過輔助分類器同步完成真假樣本判別和類別預(yù)測(cè);最后,根據(jù)判別器動(dòng)態(tài)反饋漸進(jìn)式調(diào)整損失函數(shù)權(quán)值,重點(diǎn)關(guān)注高質(zhì)量樣本進(jìn)一步優(yōu)化網(wǎng)絡(luò),提高識(shí)別準(zhǔn)確性。
1 數(shù)據(jù)預(yù)處理
1.1 數(shù)據(jù)特點(diǎn)
本文采用ADS-B 1090 MHz S 模式擴(kuò)展電文數(shù)據(jù)鏈進(jìn)行分析,其最大下行數(shù)據(jù)長(zhǎng)度達(dá)112 位,數(shù)據(jù)率可達(dá)1 Mbit∕s。如圖1 所示,ADS-B 消息主要由前導(dǎo)脈沖(preamble)部分和數(shù)據(jù)(data block)部分組成,消息的前導(dǎo)脈沖位置在消息的前端即信號(hào)的前8 μs 時(shí)間,是信息頭部分,總共有4 個(gè)脈沖。數(shù)據(jù)部分共112 位,表征下行鏈路格式、通信能力、飛機(jī)唯一標(biāo)識(shí)符、地表位置、空中位置和速度等信息。
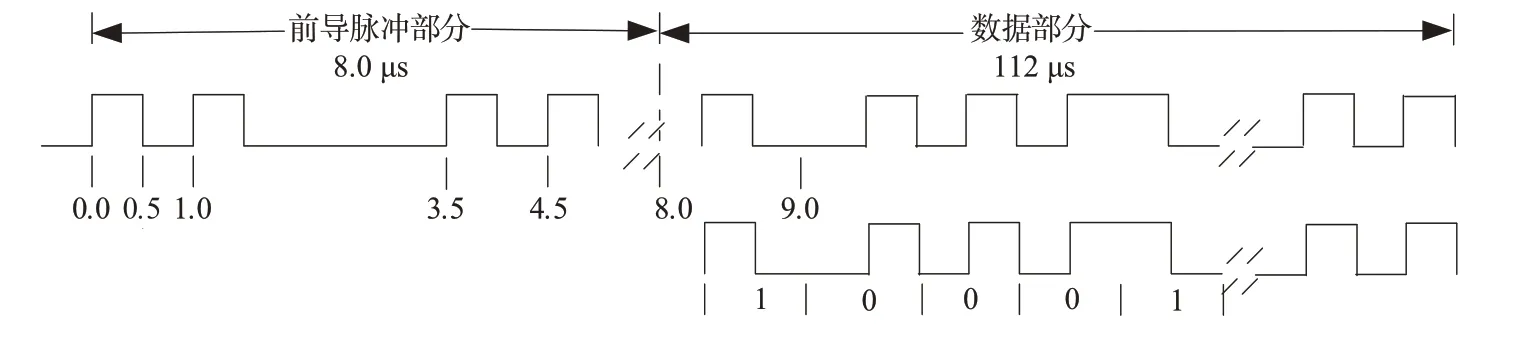
圖1 ADS-B 1090ES信息數(shù)據(jù)塊格式及數(shù)據(jù)位PPM調(diào)制
ADS-B 信號(hào)采用脈沖位置調(diào)制(PPM)實(shí)現(xiàn)數(shù)據(jù)位報(bào)文編碼后在數(shù)據(jù)鏈路中傳播,其基帶PPM信號(hào)為
式中,bm表示第m個(gè)二進(jìn)制符號(hào),p(t)表示一個(gè)脈沖寬度為Ts= 0.5 μs的矩形脈沖。
1.2 數(shù)據(jù)增強(qiáng)
聚焦樣本不足的核心問題,借鑒圖片分類算法中常用的翻轉(zhuǎn)、平移、拼接等方法對(duì)電磁信號(hào)進(jìn)行時(shí)域翻轉(zhuǎn)、振幅反轉(zhuǎn)、振幅縮放和噪聲擾動(dòng)實(shí)現(xiàn)數(shù)據(jù)擴(kuò)充。
1.2.1 時(shí)域翻轉(zhuǎn)
由圖2可知,時(shí)域翻轉(zhuǎn)是將信號(hào)的時(shí)間軸進(jìn)行翻轉(zhuǎn),對(duì)于ADS-B 信號(hào)這一離散信號(hào)S(n)而言,時(shí)域翻轉(zhuǎn)可表示為
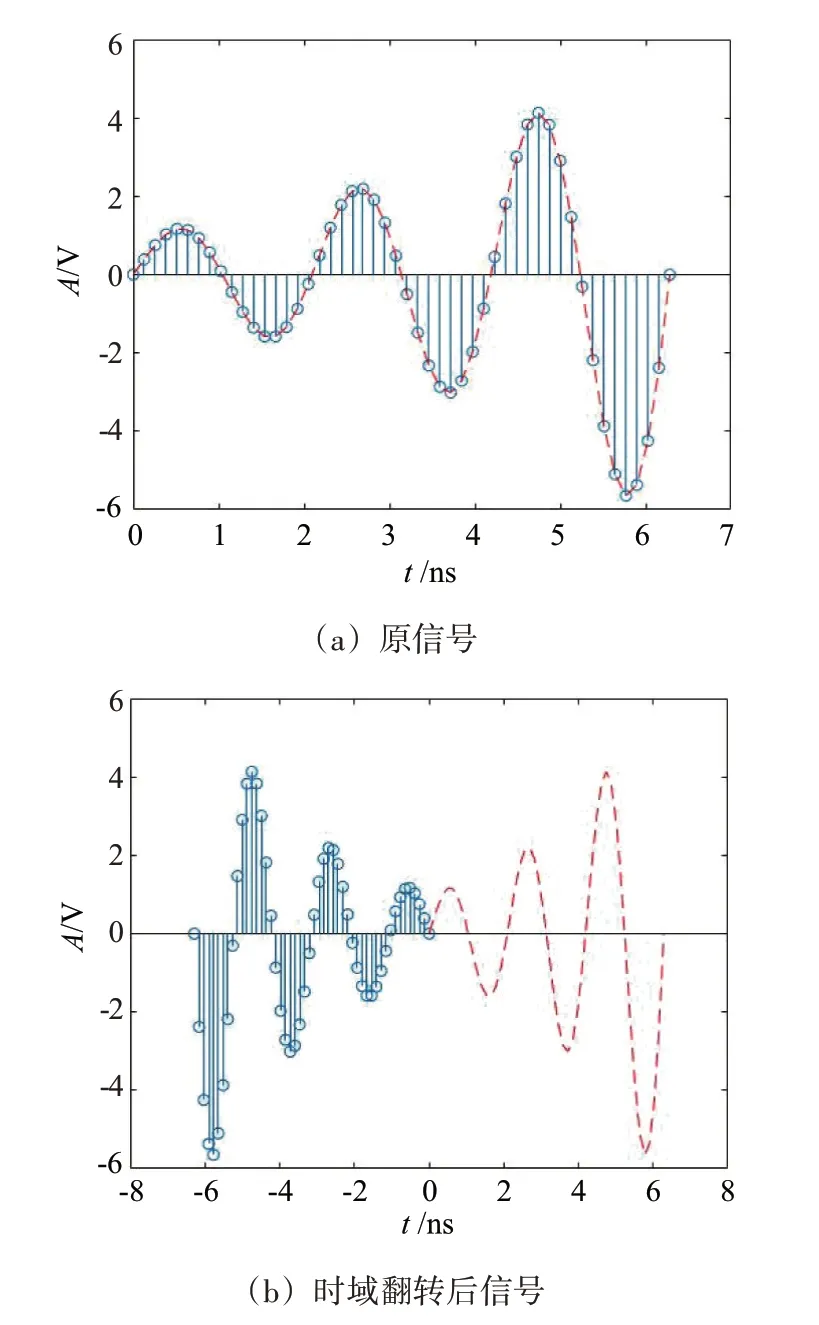
圖2 時(shí)域翻轉(zhuǎn)處理
式中:N為信號(hào)長(zhǎng)度;n為時(shí)間索引,取值范圍為[0,N-1]。
1.2.2 振幅反轉(zhuǎn)
由圖3可知,振幅反轉(zhuǎn)是將信號(hào)沿時(shí)間軸進(jìn)行反轉(zhuǎn),對(duì)于ADS-B 信號(hào)這一離散信號(hào)S(n)而言,振幅反轉(zhuǎn)可表示為
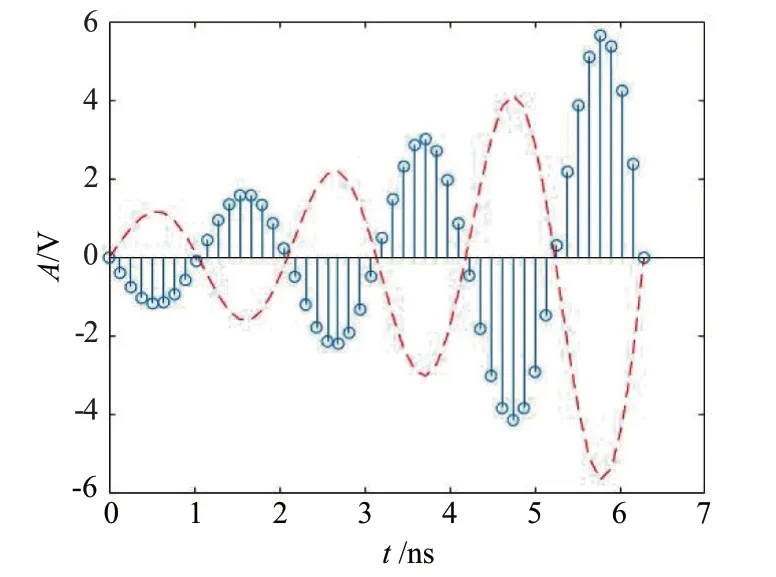
圖3 振幅反轉(zhuǎn)處理
式中,n為時(shí)間索引,Sf(n)為振幅反轉(zhuǎn)后的信號(hào)。
1.2.3 振幅縮放
由圖4可知,振幅縮放是通過縮放因子調(diào)整信號(hào)的幅度特征,對(duì)于ADS-B 信號(hào)這一離散信號(hào)S(n)而言,振幅縮放可表示為
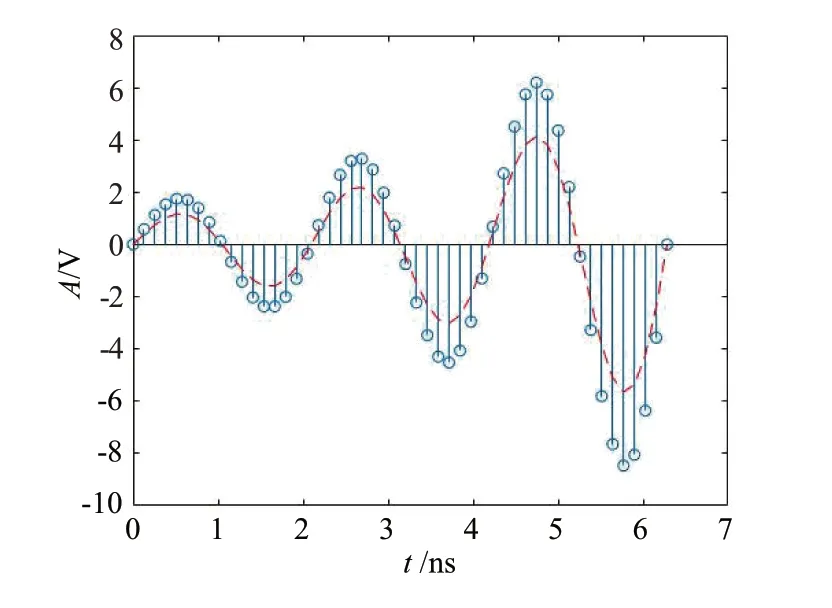
圖4 振幅縮放處理
式中,n為時(shí)間索引,Ss(n)為振幅縮放后的信號(hào),α為縮放因子。當(dāng)將超參數(shù)α設(shè)置為大于1 時(shí)振幅增大,小于1 時(shí)振幅縮小,但過小或過大的縮放因子會(huì)造成信號(hào)截?cái)嗟刃盘?hào)溢出或失真的影響,在后續(xù)實(shí)驗(yàn)中選取α= 1.4。
1.2.4 加噪處理
對(duì)ADS-B 信號(hào)這一離散信號(hào)S(n)加入高斯噪聲可以表示為
式中:n為時(shí)間索引,Sn(n)為添加高斯噪聲后的信號(hào),N是服從均值為0、方差為σ2的高斯分布的隨機(jī)數(shù),如圖5所示。
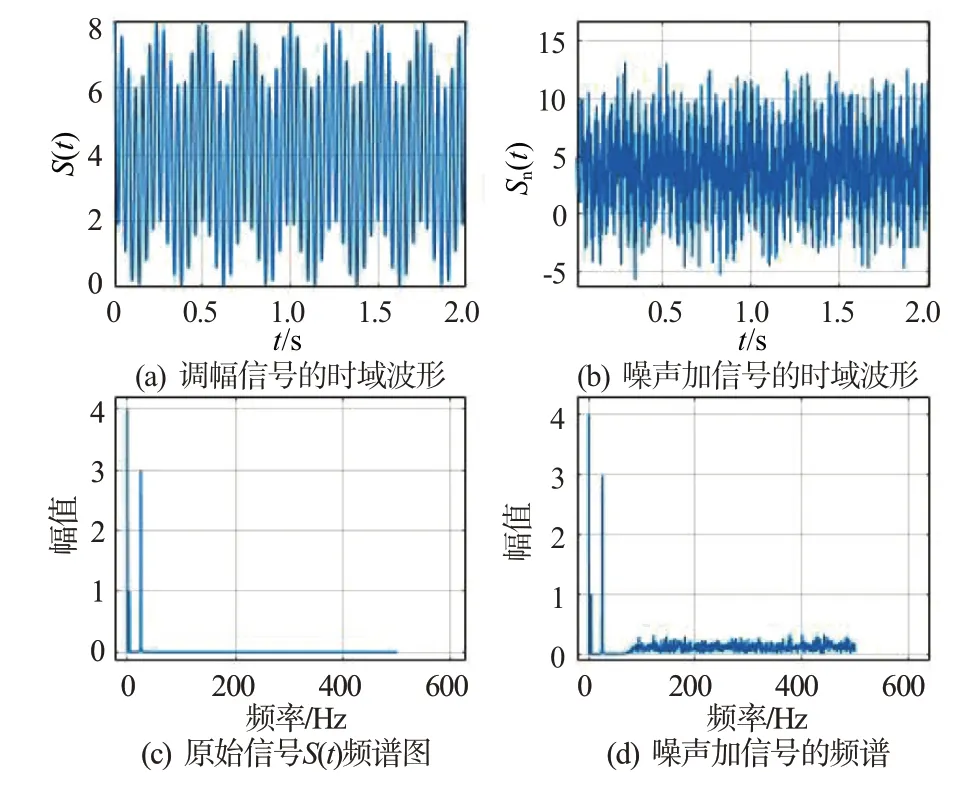
圖5 加噪處理
2 基于數(shù)據(jù)增強(qiáng)的輻射源個(gè)體識(shí)別方法
2.1 輔助分類生成對(duì)抗網(wǎng)絡(luò)
Augustus 等在文獻(xiàn)[16]中以GAN 為基礎(chǔ)提出了可同時(shí)實(shí)現(xiàn)樣本分類預(yù)測(cè)和真假樣本判別的輔助分類生成對(duì)抗網(wǎng)絡(luò)(Auxiliary Classifier GAN,ACGAN),其損失函數(shù)分為判別是否為真實(shí)樣本的損失LS和分類準(zhǔn)確性的損失LC兩部分:
式中:x真實(shí)樣本對(duì)應(yīng)類別標(biāo)簽為yx,z和y為輸入生成器的噪聲序列和標(biāo)簽,生成樣本為G(z,y);x~Pdata(x)表示樣本x服從真實(shí)樣本分布,將樣本x判別為真實(shí)樣本的概率為DS(x),將輸入的G(z,y)判別為真實(shí)樣本的概率為DS(G(z,y)),LD表示為分類損失,故而AC-GAN判別器損失為
生成器損失為
2.2 漸進(jìn)式權(quán)值調(diào)整的AC-GAN
AC-GAN 在創(chuàng)造性地實(shí)現(xiàn)樣本真假判別和分類雙重任務(wù)的同時(shí),可通過輔助分類器有效控制生成樣本的類別,聯(lián)合生成器損失、判別器損失和分類器損失加強(qiáng)模型訓(xùn)練穩(wěn)定性,但在實(shí)際應(yīng)用中仍存在以下不足:
1)AC-GAN 在訓(xùn)練數(shù)據(jù)較少時(shí)易引發(fā)生成樣本多樣性不足的問題。
2)AC-GAN 平等地關(guān)注判別結(jié)果參差不同的樣本,限制了模型的識(shí)別能力。
基于此,本文提出漸進(jìn)式動(dòng)態(tài)調(diào)整損失函數(shù)權(quán)重的輔助分類生成對(duì)抗網(wǎng)絡(luò)(PW-ACGAN)的輻射源個(gè)體識(shí)別算法,合理利用1.2 節(jié)中對(duì)原始樣本進(jìn)行時(shí)域翻轉(zhuǎn)、振幅反轉(zhuǎn)、振幅縮放及噪聲擾動(dòng)等方法產(chǎn)生的擴(kuò)充樣本提高原數(shù)據(jù)集的特征覆蓋情況,使得模型能更好地獲得數(shù)據(jù)的分布,提高生成樣本的多樣性;根據(jù)反饋動(dòng)態(tài)調(diào)整損失函數(shù)的權(quán)重,更加關(guān)注將輸入的生成樣本G(z,y)判別為真實(shí)樣本和將輸入真實(shí)樣本x判別為假的“顛倒是非”的理想欺騙狀態(tài),有效降低低質(zhì)量生成樣本對(duì)模型的影響[17-18],具體步驟如下:
1)定義權(quán)值調(diào)整因子與權(quán)重初始化:定義介于0到1之間的權(quán)值調(diào)整因子γ以控制生成器的損失函數(shù)權(quán)重,表示生成器損失函數(shù)的相對(duì)權(quán)重。起初,將生成器和鑒別器損失函數(shù)的權(quán)重設(shè)置為相等的值,實(shí)現(xiàn)初始權(quán)重平衡。
2)關(guān)注判別結(jié)果動(dòng)態(tài)調(diào)整γ:在訓(xùn)練過程中記錄生成樣本被判別為真實(shí)樣本(DS(G(z,y)) →1)和真實(shí)樣本被判別為生成樣本(DS(x) →0)的判別概率,在理想情況下,每次判別器輸出的概率值為1∕2,即判別器無法區(qū)分真實(shí)數(shù)據(jù)和生成數(shù)據(jù)。
故以1∕2為界,當(dāng)PDS(G(z,y))→1大于1∕2或PDS(x)→0的判別概率小于1∕2 時(shí),將判別概率與權(quán)值調(diào)整因子γ比較大小,若判別概率P大于γ則將P賦值給γ,調(diào)整并更新?lián)p失函數(shù)。
PW-ACGAN判別器損失為
PW-ACGAN 生成器損失函數(shù)保持不變,判別器損失函數(shù)為
3)權(quán)值平衡與穩(wěn)定:過度重視生成樣本的逼真程度會(huì)降低生成樣本的多樣性,過強(qiáng)的生成器會(huì)造成模型崩潰,過強(qiáng)的判別器會(huì)引起梯度消失。通過以1∕2 為界,γ= max(γ,P)將權(quán)值調(diào)整因子限制在0.5 至1 之間,保持生成樣本多樣性與逼真性的平衡。
2.3 實(shí)現(xiàn)步驟
如圖6所示,信號(hào)樣本經(jīng)過數(shù)據(jù)增強(qiáng)處理后形成擴(kuò)充數(shù)據(jù)集,按設(shè)置比例劃分成訓(xùn)練集和測(cè)試集,隨機(jī)抽取m個(gè)訓(xùn)練樣本x;在PW-ACGAN 中,隨機(jī)生成m個(gè)滿足正態(tài)分布的噪聲序列z和生成樣本標(biāo)簽y經(jīng)過生成器G輸出生成樣本G(z,y)。將樣本x和G(z,y)一同送入判別器D 判別,并通過反向傳播調(diào)整優(yōu)化生成器與判別器。
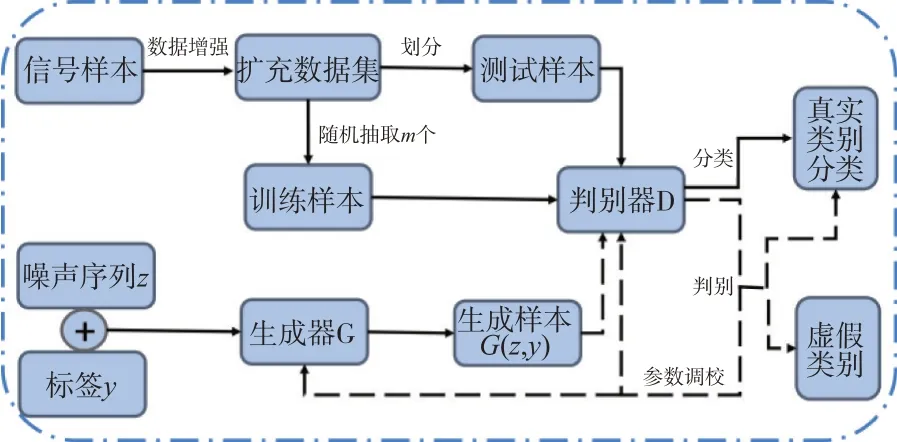
圖6 PW-ACGAN整體結(jié)構(gòu)
3 仿真實(shí)驗(yàn)
3.1 仿真條件
3.1.1 數(shù)據(jù)采集及數(shù)據(jù)集設(shè)置
為采集ADS-B 信號(hào)架設(shè)工作頻率設(shè)置為20 MHz,采樣頻率2 MHz, 接收增益為80 的USRPB210 作為信號(hào)接收裝置采集1 090 MHz ADS-B S模式響應(yīng)信號(hào),信號(hào)采集過程如圖7所示。在航班密集程度不同的時(shí)間段和地點(diǎn)采集ADS-B 射頻信號(hào)并進(jìn)行抗混疊濾波和步進(jìn)增益,將信號(hào)解調(diào)至中頻,經(jīng)轉(zhuǎn)換與解碼處理后得到ADS-B 報(bào)文,其中部分ADS-B信號(hào)如圖8所示。
圖7 數(shù)據(jù)采集場(chǎng)景
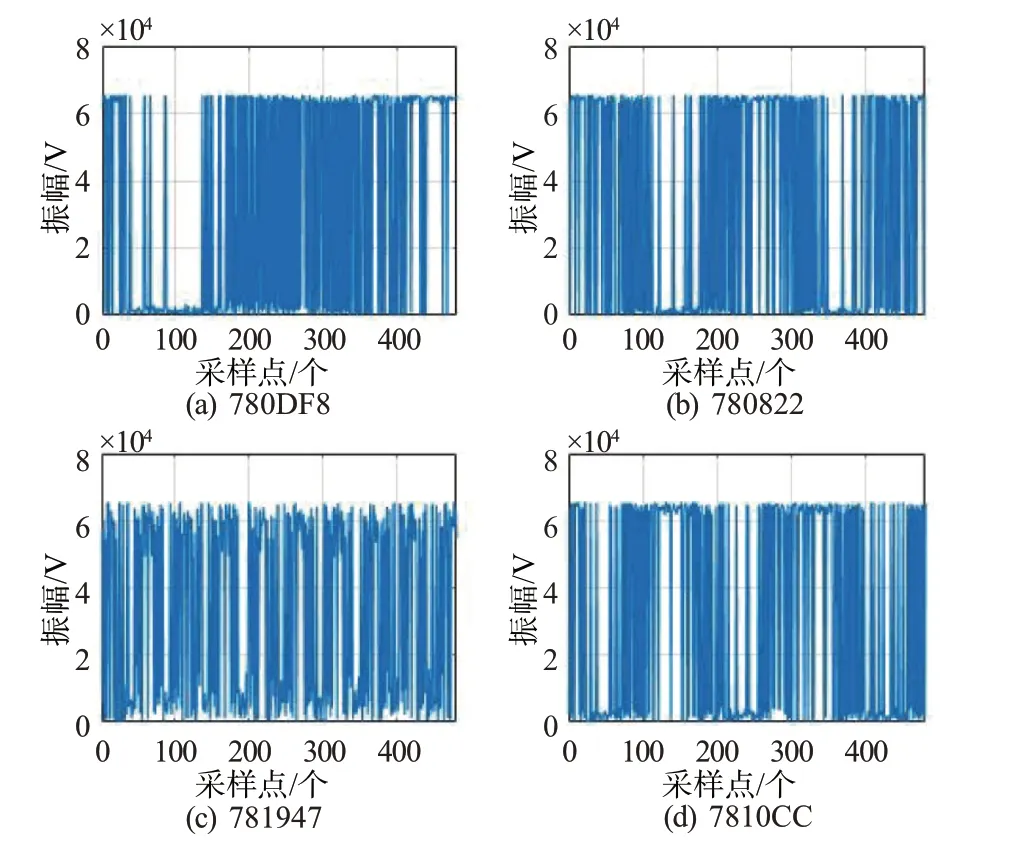
圖8 部分ADS-B采集信號(hào)
為分析類別數(shù)目與樣本數(shù)目對(duì)識(shí)別結(jié)果的影響,現(xiàn)設(shè)置多個(gè)數(shù)據(jù)集,其中訓(xùn)練集與測(cè)試集比為3∶1。DATA 設(shè)置類別數(shù)量為8,單類別樣本數(shù)為32,時(shí)域翻轉(zhuǎn)和振幅反轉(zhuǎn)根據(jù)真實(shí)樣本最多只能1∶1 生成,故而依1.2 節(jié)中數(shù)據(jù)增強(qiáng)方法擴(kuò)充數(shù)據(jù)集時(shí),人為將擴(kuò)充樣本比例設(shè)定為1倍。
3.1.2 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)基于TensorFlow 的keras框架網(wǎng)絡(luò)模型的設(shè)計(jì)與訓(xùn)練過程采用Pycharm 軟件完成,硬件配置為Intel(R)Core(TM)i9-9900K CPU,運(yùn)行內(nèi)存16 GB,主頻3.6 GHz。輸入判別器數(shù)據(jù)尺寸統(tǒng)一為1×1 000 格式,模型訓(xùn)練過程采用Adam 優(yōu)化器進(jìn)行權(quán)值優(yōu)化,每次迭代樣本數(shù)為32,訓(xùn)練次數(shù)設(shè)置為30,學(xué)習(xí)率為0.01。
3.1.3 網(wǎng)絡(luò)模型搭建
深度卷積生成對(duì)抗網(wǎng)絡(luò)(Deep Convolution GAN,DCGAN)的提出創(chuàng)造性地將卷積神經(jīng)網(wǎng)絡(luò)引入了生成對(duì)抗網(wǎng)絡(luò)[19],優(yōu)化了模型的生成質(zhì)量和穩(wěn)定性。PW-ACGAN 以DCGAN 網(wǎng)絡(luò)結(jié)構(gòu)為基礎(chǔ),生成器和判別器網(wǎng)絡(luò)模型設(shè)計(jì)如表1和表2所示。

表2 PW-ACGAN判別器網(wǎng)絡(luò)模型
3.2 實(shí)驗(yàn)結(jié)果分析
3.2.1 不同數(shù)據(jù)增強(qiáng)方法對(duì)識(shí)別效果的影響
為驗(yàn)證不同增強(qiáng)方法對(duì)識(shí)別效果的影響,選用與PW-ACGAN 的判別器結(jié)構(gòu)相同但去除輸出層判別概率分支的CNN 網(wǎng)絡(luò)模型為識(shí)別網(wǎng)絡(luò)。不同的增強(qiáng)方法在訓(xùn)練樣本時(shí)取8 種類型的信號(hào)樣本各32 個(gè),分別將未經(jīng)增強(qiáng)的原始樣本記為None、Time domain flipping、Amplitude reversal、Gaussian noise 與組合使用增強(qiáng)方法的混合增強(qiáng)樣本Mix 在不同信噪比條件下進(jìn)行識(shí)別效果比較。
由圖9可知,不同增強(qiáng)方法的識(shí)別準(zhǔn)確率在不同信噪比條件下均有不同程度的提高,在信噪比較低的情況下,識(shí)別準(zhǔn)確率穩(wěn)步提升,在達(dá)到8 dB時(shí)識(shí)別準(zhǔn)確率趨于穩(wěn)定;單一增強(qiáng)方法中時(shí)域翻轉(zhuǎn)的增強(qiáng)方法表現(xiàn)最佳,加噪處理的增強(qiáng)方法表現(xiàn)最為遜色,振幅縮放增強(qiáng)方法的識(shí)別準(zhǔn)確率稍微優(yōu)于振幅反轉(zhuǎn);而混合增強(qiáng)方法優(yōu)于單一增強(qiáng)方法,為優(yōu)化實(shí)驗(yàn)效果后續(xù)實(shí)驗(yàn)采用混合增強(qiáng)方法產(chǎn)生增強(qiáng)樣本。
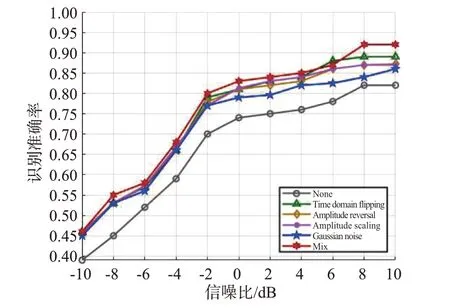
圖9 不同增強(qiáng)方法的識(shí)別準(zhǔn)確率比較
3.2.2 小樣本條件下識(shí)別效果分析
為對(duì)比CNN、ACGAN 及PW-ACGAN 在小樣本條件下的識(shí)別效果,在SNR=2 dB 條件下對(duì)混合增強(qiáng)樣本Mix 進(jìn)行20 次蒙特卡羅實(shí)驗(yàn)并記錄識(shí)別準(zhǔn)確率,繪制盒子圖可知其最大最小值、上下四分位數(shù)和中位數(shù)及分布情況。
由圖10 可知,以圖中紅色橫線標(biāo)注的中位線為標(biāo)準(zhǔn),PW-ACGAN 的識(shí)別準(zhǔn)確率明顯優(yōu)于CNN和ACGAN 算法;PW-ACGAN 的識(shí)別準(zhǔn)確率分布最為集中,表明其平衡了生成樣本的穩(wěn)定性與多樣性,更好地突破了訓(xùn)練集數(shù)目少易引發(fā)的測(cè)試集易過擬合的小樣本限制,進(jìn)一步證明了PW-ACGAN算法的有效性。
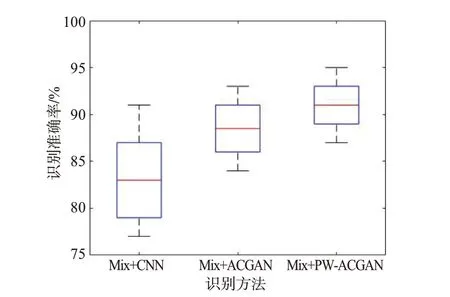
圖10 不同識(shí)別方法的識(shí)別準(zhǔn)確率
3.2.3 不同識(shí)別方法比較
為進(jìn)一步說明本文算法在小樣本輻射源個(gè)體識(shí)別中的優(yōu)勢(shì),采用通過對(duì)比實(shí)驗(yàn)進(jìn)行分析。其中,Augmented data with screening 是以文獻(xiàn)[20]中基于粗細(xì)粒度篩選的生成對(duì)抗網(wǎng)絡(luò)數(shù)據(jù)增強(qiáng)方法;Meta Learning 是以文獻(xiàn)[21]中基于元學(xué)習(xí)的跨任務(wù)信號(hào)識(shí)別方法;LDCGAN+SVM 是以文獻(xiàn)[22]中基于深度卷積生成對(duì)抗網(wǎng)絡(luò)擴(kuò)充樣本后利用支持向量機(jī)進(jìn)行分類識(shí)別方法。
由圖11 可知,本文所提識(shí)別算法在不同的信噪比條件下均優(yōu)于其他三種對(duì)比算法,尤其在-10~-2 dB 低信噪比條件下,不同識(shí)別算法的識(shí)別效果差異顯著,本文所提基于混合數(shù)據(jù)增強(qiáng)和PW-ACGAN 較將LDCGAN 生成數(shù)據(jù)映射到高維特征空間利用支持向量機(jī)分類識(shí)別的方法提高了15%左右,表明本文算法對(duì)低信噪比環(huán)境有較好的適應(yīng)性。
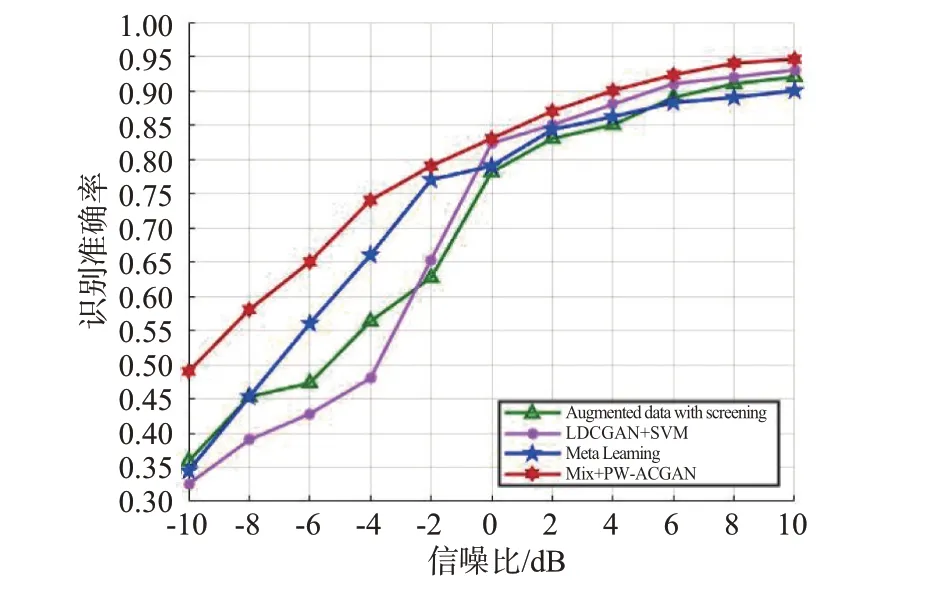
圖11 不同算法的識(shí)別準(zhǔn)確率
3.2.4 樣本數(shù)量對(duì)識(shí)別效果的影響
小樣本學(xué)習(xí)旨在解決樣本不充足、不全面的條件限制問題,但訓(xùn)練樣本數(shù)量仍在一定程度上影響識(shí)別結(jié)果。首先在信噪比為8的條件下,設(shè)置不同的每個(gè)類別樣本數(shù)量進(jìn)行識(shí)別準(zhǔn)確率比較,查看數(shù)據(jù)增強(qiáng)在不同數(shù)量的小樣本條件下的作用效果。由圖12 橫向?qū)Ρ瓤芍S著每個(gè)類別樣本數(shù)目的增加,識(shí)別準(zhǔn)確率明顯提升,表明充足的訓(xùn)練樣本對(duì)模型的擬合能力至關(guān)重要;縱向來看,在樣本數(shù)目較少的情況下,數(shù)據(jù)增強(qiáng)通過擴(kuò)充樣本數(shù)量提高樣本的特征覆蓋率,更好地使模型學(xué)習(xí)數(shù)據(jù)特征,從而實(shí)現(xiàn)了小樣本條件下識(shí)別準(zhǔn)確率的躍升,但當(dāng)樣本數(shù)量較為充足并能夠支撐分類器獲得較好的分類面時(shí),數(shù)據(jù)增強(qiáng)的作用效果微弱。
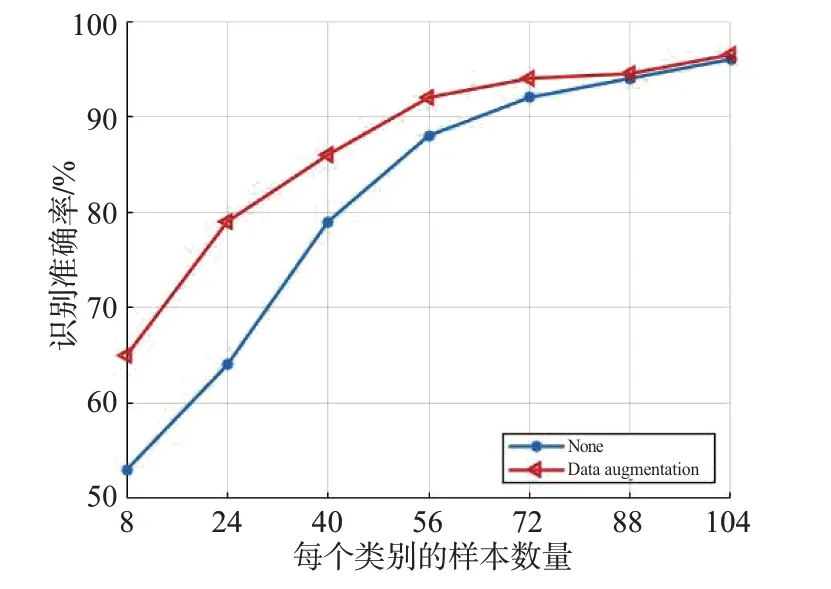
圖12 不同數(shù)量樣本的識(shí)別準(zhǔn)確率
為進(jìn)一步驗(yàn)證小樣本條件下增強(qiáng)樣本數(shù)量對(duì)識(shí)別準(zhǔn)確率的影響,取不同數(shù)量的增強(qiáng)樣本進(jìn)行多次實(shí)驗(yàn),取平均識(shí)別準(zhǔn)確率進(jìn)行比較。由表3可知,隨著增強(qiáng)樣本數(shù)量的增加,識(shí)別準(zhǔn)確率穩(wěn)步提升,當(dāng)達(dá)到增強(qiáng)樣本數(shù)量與原始樣本一致時(shí),識(shí)別準(zhǔn)確率提升近23%。
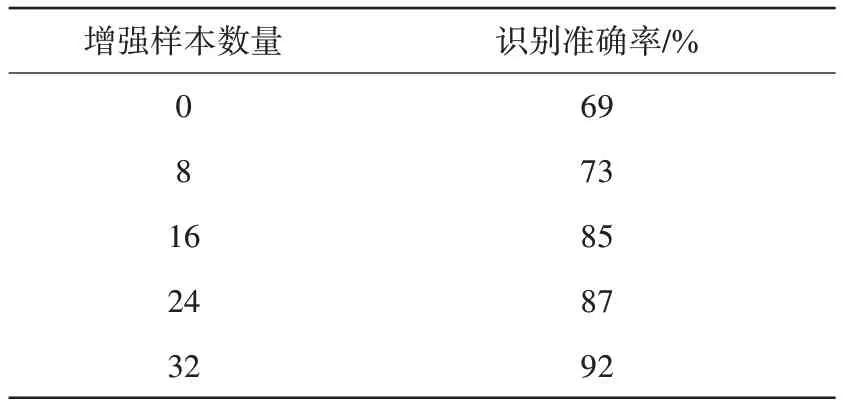
表3 各類增強(qiáng)樣本在不同數(shù)量下的識(shí)別準(zhǔn)確率
4 結(jié)束語
針對(duì)復(fù)雜電磁環(huán)境中缺少高質(zhì)量、數(shù)量充足訓(xùn)練樣本的困境,提出基于數(shù)據(jù)增強(qiáng)的小樣本輻射源個(gè)體識(shí)別方法。首先,通過數(shù)據(jù)增強(qiáng)擴(kuò)充樣本集,提高原數(shù)據(jù)集的特征覆蓋情況,使得模型能更好地獲得數(shù)據(jù)的分布;然后,將噪聲序列和類別標(biāo)簽輸入生成器進(jìn)一步生成“以假亂真”的生成樣本,提高生成樣本的多樣性并通過輔助分類器同步完成真假樣本判別和類別預(yù)測(cè);最后,根據(jù)判別器動(dòng)態(tài)反饋漸進(jìn)式調(diào)整損失函數(shù)權(quán)值,重點(diǎn)關(guān)注高質(zhì)量樣本進(jìn)一步優(yōu)化網(wǎng)絡(luò),提高識(shí)別準(zhǔn)確性。實(shí)驗(yàn)結(jié)果表明,本文算法在不同數(shù)量樣本下和不同信噪比條件下均表現(xiàn)出較為穩(wěn)定的識(shí)別能力,尤其對(duì)低信噪比條件具有較好的適應(yīng)性,為復(fù)雜信道條件下的小樣本輻射源個(gè)體識(shí)別提供了可能。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機(jī)械氣動(dòng)工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
