基于多模態(tài)共享網(wǎng)絡的自監(jiān)督語音-人臉跨模態(tài)關聯(lián)學習方法
2024-04-01 07:30:46李俊嶼卜凡亮譚林周禹辰毛璟儀
科學技術與工程 2024年7期
李俊嶼, 卜凡亮*, 譚林, 周禹辰, 毛璟儀
(1.中國人民公安大學信息網(wǎng)絡安全學院, 北京 100038; 2.公安部第一研究所, 北京 100048)
隨著信息技術的飛速發(fā)展和人類對全方位感知的需求不斷增加,多模態(tài)數(shù)據(jù)處理[1-5]已經(jīng)成為了人工智能和計算機視覺領域的研究熱點。在多模態(tài)數(shù)據(jù)的廣泛應用領域中,音頻和圖像作為人類最常用的兩種信號傳輸模式,承載著豐富的信息。圖像可以直觀地傳達其中包含的顏色、形狀和紋理等信息,而音頻則包含了豐富的音調(diào)、音色和振幅等特征,能夠間接地反映人的性別、年齡和情緒狀態(tài)。語音和人臉作為廣泛應用的兩種模態(tài),吸引了越來越多的學者來探索兩者之間的潛在關聯(lián)。認知科學的研究證明,語音和人臉的神經(jīng)認知通路具有相似的結構[6],這使得人類能夠將個體的語音和與之對應的人臉相聯(lián)系起來[7]。此外,生物學和統(tǒng)計學的研究也發(fā)現(xiàn)個體的年齡、性別、種族以及面部骨骼結構等特征在語音和人臉中都能夠得到反映[8]。因此,基于語音和人臉的跨模態(tài)交互關聯(lián)具有一定的可行性。
語音-人臉跨模態(tài)關聯(lián)學習作為新興的研究領域,主要通過人工智能和計算機視覺的相關技術,挖掘語音與人臉模態(tài)間的潛在聯(lián)系,實現(xiàn)跨模態(tài)驗證、匹配和檢索等關聯(lián)學習任務。通過對語音與人臉之間的語義關聯(lián)進行深入探索,為語音生成人臉[9-10]、深度偽造視頻檢測[11]、說話人跟蹤[12]等領域的研究提供了有力支持,在公共安全領域更是具有廣泛的應用前景。例如,在電信詐騙、綁架勒索和經(jīng)濟糾紛等涉及語音證據(jù)的案件中,警方可以通過采集到的語音數(shù)據(jù)與人臉數(shù)據(jù)庫進行匹配,有助于預防和打擊犯罪活動,避免進一步的人身安全和財產(chǎn)損失。在公共場所或事故災難現(xiàn)場,搜尋人員可以利用收集到的語音或人臉圖像,通過現(xiàn)場監(jiān)控或錄像進行檢索,以尋找失蹤人口。在身份驗證、門禁控制和智能家居領域,用戶還可以通過語音與人臉的匹配來獲得受限區(qū)域的訪問權限,提高系統(tǒng)的整體安全性。語音-人臉跨模態(tài)關聯(lián)方法在公共安全領域的應用也存在一定限制,錄音設備在不同場所下使用的局限性對語音數(shù)據(jù)的收集產(chǎn)生了一定的影響。
近年來,人們在語音-人臉跨模態(tài)關聯(lián)學習上的研究可以分為基于分類的方法和基于度量學習的方法。基于分類的方法是把語音-人臉跨模態(tài)關聯(lián)學習看作一個分類任務來處理。Nagrani等[13]是最早對語音與人臉進行跨模態(tài)生物特征匹配的研究者,提出了一種多分支卷積神經(jīng)網(wǎng)絡結構,可以分別讀取語音頻譜圖和人臉圖像,并對兩者進行強制匹配,該模型在數(shù)據(jù)集上的表現(xiàn)超過了人類。Wen等[14]提出了一個不相交映射網(wǎng)絡(disjoint mapping network, DIMNet),該模型從性別、種族、ID等公共變量中獲取監(jiān)督信號來學習語音和人臉的共同嵌入,通過多個不同的公共變量提供的多種標簽信息來評估最終嵌入的匹配性能。基于度量學習的方法旨在通過學習一個度量損失函數(shù),使得在公共特征空間中相似的語音與人臉特征向量距離更近,不相似的語音與人臉特征向量距離更遠。Nagrani等[12]提出了一種基于Curriculum的無監(jiān)督策略來構造困難負樣本,該模型學習到的表征不再局限于強制匹配,而是引入了跨模態(tài)驗證和檢索任務,通過對比損失來約束語音與人臉特征向量的距離。Kim等[15]利用三元組損失來學習語音和人臉的特征嵌入,論證了該模型所學習到的特征向量包含了個體的性別、年齡、種族、是否是大鼻子、是否是雙下巴等特征。Horiguchi等[16]采用雙流網(wǎng)絡的架構來提取語音和人臉的特征向量,通過N-pair損失對兩個模態(tài)特征的距離度量進行優(yōu)化。Nawaz等[17]提出了一個單流網(wǎng)絡(single stream network, SSNet)和一種新的損失函數(shù)中心損失來學習彌合兩種模態(tài)間的距離。Wang等[18]提出了一種雙向五元組約束,可以更好地學習語音與人臉的聯(lián)合嵌入,拉近屬于同一身份的語音和人臉特征。
近期,隨著數(shù)據(jù)集規(guī)模的不斷擴大,標注大量數(shù)據(jù)所需的人力和時間成本急劇增加,這給有監(jiān)督的跨模態(tài)關聯(lián)學習方法帶來了巨大的挑戰(zhàn)。因此,研究無監(jiān)督的跨模態(tài)關聯(lián)學習方法具有重要意義。Chen等[19]提出了一種無監(jiān)督學習模型(self-lifting, SL),結合聚類和度量學習來探索無監(jiān)督的語音與人臉之間的特征關聯(lián)。Zhu等[20]提出了一種跨模態(tài)原型對比學習模型(cross-modal prototype contrastive learning, CMPC),采用對比學習的方法實現(xiàn)了無監(jiān)督的語音與人臉模態(tài)的關聯(lián)學習,并利用噪聲對比估計損失(info noise contrastive loss, InfoNCE loss)實現(xiàn)了跨模態(tài)驗證、匹配和檢索的關聯(lián)學習任務。朱明航等[21]提出了一種基于雙向偽標簽的自監(jiān)督學習方法,將一種模態(tài)下生成的偽標簽作為唯一的監(jiān)督信號去監(jiān)督另一種模態(tài)的特征學習,實現(xiàn)了雙向偽標簽關聯(lián),促進了語音與人臉的跨模態(tài)相關性學習。
上述工作并未有效地解決不同模態(tài)特征之間的異構性,對語音和人臉高層語義一致特征的挖掘還不夠充分。此外,大多數(shù)方法仍依賴于標記數(shù)據(jù)進行訓練,這導致了時間和人力成本耗費大,實際應用價值低。
為了解決上述工作存在的問題,提出一種基于多模態(tài)共享網(wǎng)絡的自監(jiān)督語音-人臉關聯(lián)學習方法。其主要工作如下:首先,通過多模態(tài)共享網(wǎng)絡的共享全連接層、非線性激活函數(shù)以及殘差連接,模型能夠更好地挖掘到語音與人臉之間的關聯(lián)性,使得它們在公共空間中的嵌入特征更具有語義一致性。然后,引入自監(jiān)督學習,為度量學習提供監(jiān)督信息,降低無標簽數(shù)據(jù)的標注成本,提高模型的泛化能力。最后,將多相似性損失函數(shù)和均方誤差損失函數(shù)相結合,對特征向量進行距離度量,從而實現(xiàn)在四種語音-人臉跨模態(tài)關聯(lián)學習任務上的全面評估和測試。這種方法可以增加多模態(tài)數(shù)據(jù)在特征空間中的關聯(lián)性,為實現(xiàn)更好的語音-人臉跨模態(tài)關聯(lián)學習提供有力支持。
1 自監(jiān)督語音-人臉跨模態(tài)關聯(lián)學習方法
本文所提出的自監(jiān)督語音-人臉跨模態(tài)關聯(lián)學習方法的總體框架如圖1所示,其中包含兩個主要的網(wǎng)絡模塊,即多模態(tài)共享模塊和自監(jiān)督學習模塊。首先,模型采用雙流網(wǎng)絡的架構,包括語音流和人臉圖像流兩個權重獨立的編碼器。接著,提取到的語音和人臉嵌入向量通過多模態(tài)共享模塊,在公共特征空間中增強了不同模態(tài)之間的語義關聯(lián)。然后,自監(jiān)督學習模塊將特征向量聚類成簇得到偽標簽。最后,利用生成的偽標簽作為監(jiān)督信息,指導了對特征向量進行度量學習的過程,提高了模型的表征學習能力。

圖1 語音-人臉跨模態(tài)關聯(lián)學習方法的總體框架Fig.1 Overall framework of the proposed voice-face cross-modal association learning method
1.1 基本定義

1.2 多模態(tài)共享模塊
采用雙流網(wǎng)絡的架構,用獨立的兩條語音流和人臉圖像流網(wǎng)絡提取各自模態(tài)特有的特征,以充分學習語音與人臉特征之間的異構性。然而,現(xiàn)有的語音-人臉關聯(lián)學習方法往往通過在雙流網(wǎng)絡的頂端引入權重共享的單一全連接層來構建公共特征空間,該全連接層限制了不同模態(tài)特征的公共表示能力,無法充分地挖掘語音和人臉特征之間的語義一致性。
為此,設計了一個多模態(tài)共享模塊來增強語音與人臉數(shù)據(jù)在跨模態(tài)公共特征空間上的語義關聯(lián)。本文所提出的方法是受殘差網(wǎng)絡(ResNet)[22]的啟發(fā),ResNet是一種深度神經(jīng)網(wǎng)絡架構,通過引入殘差連接,將輸入直接加到輸出上,解決了訓練過程中的梯度消失和表達能力受限的問題。多模態(tài)共享模塊的網(wǎng)絡結構由一個改進的殘差塊和一層共享全連接組成。改進的殘差塊包含三個權重共享的全連接層,每個全連接層之后加入批歸一化層和ELU激活函數(shù),最后通過跳躍連接將殘差塊的輸出與輸入進行元素級相加。該網(wǎng)絡充分考慮了殘差塊在提取稀有特征方面的關鍵作用,通過保留原始特征并建立非線性相關性,能夠在特征提取過程中更好地關聯(lián)兩種模態(tài)的信息,實現(xiàn)更強的特征表示能力。
在深度學習中,模型的輸入和矩陣的運算都是線性的,然而實際情況中輸入數(shù)據(jù)和輸出數(shù)據(jù)的關系通常是非線性的。為了更好地適應和擬合這種非線性關系,對于具有多個隱藏層的神經(jīng)網(wǎng)絡,使用非線性激活函數(shù)來提高神經(jīng)網(wǎng)絡的性能,充分利用其多層非線性變換的能力,使其能夠更好地挖掘和表示復雜的非線性數(shù)據(jù)關系。
在設計多模態(tài)共享模塊時,對ResNet原殘差塊的激活函數(shù)進行了優(yōu)化改進,用ELU激活函數(shù)替換了其中的ReLU激活函數(shù)。ELU激活函數(shù)具備更好地處理和表示負數(shù)輸入的能力,對噪聲和異常值具有一定的魯棒性,有助于殘差塊更好地學習和擬合復雜的數(shù)據(jù)。
ReLU激活函數(shù)的表達式為
(1)
ReLU激活函數(shù)的導數(shù)為
(2)
式中:x為輸入特征。由式(1)、式(2)可得出,當輸入特征為正值和0時,輸出等于輸入,梯度為1,不存在梯度消失問題;當輸入特征為負值時,輸出和梯度都為0,ReLU硬飽和。
ELU激活函數(shù)的表達式為
(3)
ELU激活函數(shù)的導數(shù)為
(4)
式中:x為輸入特征;α為超參數(shù),取值通常為1。由式(3)、式(4)可得出,當輸入特征為正值時,輸出等于輸入,梯度為1,不存在梯度消失問題;當輸入特征為0時,ELU函數(shù)的輸出也為0,并且梯度為1。與ReLU函數(shù)不同的是,ELU在輸入為0時的梯度不為0,這是ELU相比于ReLU函數(shù)的一個優(yōu)勢;當輸入特征為負值時,ELU函數(shù)的輸出為指數(shù)增長的負值,無限趨近于-α,梯度為ex,接近于0但不為0,不存在硬飽和問題。


圖2 多模態(tài)共享模塊的網(wǎng)絡結構圖Fig.2 Structure of multi-modal shared module
(5)


(6)
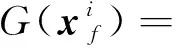
(7)
最后,將殘差塊的輸出向量經(jīng)全連接層映射到嵌入空間,得到最終的128維輸出可分別表示為
(8)
(9)
式中:wi為全連接層的權重;bi為對應的偏置;γ為激活函數(shù)ELU;輸入與輸出向量的維度均為256。
1.3 自監(jiān)督學習模塊
自監(jiān)督學習是一種特殊的無監(jiān)督學習方法,它通過設計預測任務來生成偽標簽,并將這些偽標簽作為監(jiān)督信號來訓練模型。現(xiàn)有的大多數(shù)語音-人臉跨模態(tài)關聯(lián)學習方法[13-18]都是采用有監(jiān)督的方式,難以有效地建立語音與人臉在潛在語義上的關聯(lián)。本文在自監(jiān)督學習框架SL的基礎上進行改進,能夠從語音和人臉數(shù)據(jù)中學習到有意義的特征表示,實現(xiàn)跨模態(tài)的自監(jiān)督學習,從而充分挖掘語音與人臉之間的結構和語義關聯(lián)。
特征向量級聯(lián)是將兩個或多個特征向量按照一定順序拼接在一起形成一個更長的向量,有助于模型捕捉到更多的語義信息。當其中一種模態(tài)數(shù)據(jù)的質(zhì)量較低時,例如,語音數(shù)據(jù)有環(huán)境噪聲干擾或圖像數(shù)據(jù)有極端光照條件照射等情況,可以利用另一種模態(tài)的數(shù)據(jù)來獲取補充信息,從而提高聚類算法對復雜場景和低質(zhì)量數(shù)據(jù)的魯棒性和精度。如圖3所示,將語音和人臉的高層語義特征向量進行級聯(lián),將生成的視頻特征向量ei作為自監(jiān)督學習模塊的輸入。公式為

圖3 特征向量級聯(lián)圖Fig.3 Feature vector concatenation diagram

(10)
式(10)中:⊕為向量的級聯(lián)。
給定一組輸入數(shù)據(jù)E={e1,e2,…,eN},其中ei表示第i個樣本,N表示樣本數(shù)量。通過K均值聚類算法(K-means)[23]將這些樣本點劃分為k個簇,迭代優(yōu)化直至聚類中心不再發(fā)生變化或達到預定的迭代次數(shù),實現(xiàn)聚簇內(nèi)的樣本點相似度最大,聚簇間的樣本點相似度最小。
如圖4所示,首先,隨機初始化k個聚類中心向量Μ={μ1,μ2,…,μk},計算每個樣本點ei與每個聚類中心點μj之間的距離;其次,將ei劃分到距離最近的聚類中心點μj所屬的聚類Cj中,并更新聚類中心點的向量μj,將其設為聚類Cj中所有樣本點的均值;最后,迭代直至收斂,得到每個樣本點所屬的聚類偽標簽Y={y1,y2,…,yk},其中yi為第i個簇中視頻特征向量的偽標簽。

圖4 自監(jiān)督學習框圖Fig.4 Block diagram of self-supervised learning
歐式距離計算公式為
(11)
K-means聚類的目標函數(shù)的公式為
(12)
中心向量矩陣的計算公式為
(13)
式(13)中:|Cj|為聚類Cj中樣本點的數(shù)量。
1.4 度量學習
度量學習是表征學習的一種方法,旨在學習一個合適的相似度度量,以在特征空間中衡量樣本對的距離。度量學習需要標簽作為引導來定義樣本之間的相似性,對于無標簽數(shù)據(jù),可以將自監(jiān)督學習生成的偽標簽作為監(jiān)督信號進行訓練,學習偽標簽的語義關系,從而提高模型的表征學習能力。本文中采用多相似性損失函數(shù)[24]衡量語音和人臉特征向量之間的相似度。

(14)
式(14)中:‖zi‖和‖zj‖分別為向量zi和zj的L2范數(shù)。
首先,如果{zi,zj}是負樣本對,則條件為

(15)
如果{zi,zj}是正樣本對,則條件為

(16)
其次,將通過以上方式挖掘到的正樣本集和負樣本集分別表示為Pi和Ni。
最后,利用多相似性損失函數(shù)來實現(xiàn)度量學習的過程。公式為

(17)
式(17)中:α、β、λ為超參數(shù)。通過梯度下降法對式(17)進行優(yōu)化。
1.5 模型訓練
模型的總體迭代策略是通過自監(jiān)督學習模塊生成偽標簽引導度量學習,度量學習再使用偽標簽計算損失函數(shù),通過反向傳播計算梯度并更新模型參數(shù),以使模型逐步優(yōu)化,學習到的語音和人臉的特征表示能夠更好地滿足度量學習的目標。
本文提出方法的整體損失函數(shù)形式為
L=LMS+ηLmse
(18)
式(18)中:Lmse為均方誤差損失函數(shù)(MSE Loss),用于計算語音與人臉嵌入向量之間的差異。權重系數(shù)η設置為0.5。
MSE Loss的公式為
(19)
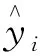
將每批次訓練的樣本數(shù)設置為256,并選擇Adam[25]方法作為優(yōu)化模型。訓練學習率設置為10-3,迭代次數(shù)設置為250。設置為0.1,α設置為2,β設置為50,λ設置為1,K-means算法中簇數(shù)k設置為1 000。
2 實驗結果與分析
本文在Voxceleb1[26]數(shù)據(jù)集上驗證自監(jiān)督語音-人臉跨模態(tài)關聯(lián)學習方法的有效性,具體實驗詳情如下。
2.1 數(shù)據(jù)集
Voxceleb1是一個來源于YouTube的大規(guī)模視聽人類語音視頻數(shù)據(jù)集,其中包含1 251位名人,他們有不同的年齡、職業(yè)和口音。VGGFace[27]是一個大規(guī)模的人臉識別數(shù)據(jù)集,其中包含2 622位名人。在實驗中,選擇了這兩個數(shù)據(jù)集的交集,同時為了保證實驗評測的有效性,將交集數(shù)據(jù)集中的1 225個身份進行劃分,生成了不含身份信息重疊的訓練集、驗證集和測試集,身份個數(shù)分別為924,112、189。
2.2 實驗設置
本文的實驗平臺與環(huán)境配置如表1所示。語音編碼器采用在VoxCeleb2[28]數(shù)據(jù)集上預訓練的ECAPA-TDNN[29]模型;人臉編碼器采用在VGGFace2[30]數(shù)據(jù)集上預訓練的Inception-v1[31]模型。最終輸出256維的語音和人臉特征向量。

表1 實驗平臺與環(huán)境Table 1 Experimental platform and environment
2.3 評價指標
為了驗證本文方法的有效性,實驗從以下4種語音-人臉跨模態(tài)關聯(lián)學習任務上進行評估。
(1)跨模態(tài)驗證。跨模態(tài)驗證是指給定一組語音片段和人臉圖像,判斷樣本對是否屬于同一身份。評價標準采用受試者工作特征曲線(receiver operating characteristic, ROC)下面積(area under curve, AUC)值為量化指標,ROC曲線是以假陽率為橫軸,以真陽率為縱軸的曲線,故AUC值越高表示模型在驗證任務上的性能越好。
(2)1∶2匹配。跨模態(tài)1∶2匹配包括語音-人臉(voice-face, V-F)和人臉-語音(face-voice, F-V)兩種情景。V-F情景下的1∶2匹配是指給定一段語音和兩張人臉圖像,判斷這段語音和其中的哪一張人臉圖像屬于同一身份。F-V情景下的1∶2匹配反之,是指給定一張人臉圖像和兩段語音,判斷這張人臉圖像和其中的哪一段語音屬于同一身份。評價標準均采用準確性(accuracy,ACC)值為量化指標,ACC值表示正確匹配的樣本數(shù)與總樣本數(shù)之比,故其值越高表示模型在匹配任務上的性能越好。
(3)1∶N匹配。跨模態(tài)1∶N匹配是在1∶2匹配的基礎上進行擴展,將待選樣本的總數(shù)增加到N,從N個樣本中判斷與待匹配樣本屬于同一身份的唯一正例。同樣的,1∶N匹配也包括V-F和F-V兩種情景,評價標準均采用準確性ACC值為量化指標。
4)跨模態(tài)檢索跨模態(tài)檢索是指給定一種模態(tài)的一個樣本,從另一種模態(tài)的樣本庫中檢索與之屬于同一身份的正例,并根據(jù)樣本對之間的相似度進行排序。評價標準采用平均準確率均值(mean average precision, mAP)為量化指標,mAP綜合考慮了準確率和排名質(zhì)量,數(shù)值越高表示模型在檢索任務上的性能越好。
2.4 消融實驗與對比實驗
2.4.1 消融實驗
為了明確兩個主要的網(wǎng)絡模塊和兩個距離度量損失函數(shù)對最終實驗評估的影響,利用Voxceleb1數(shù)據(jù)集在原實驗環(huán)境和參數(shù)下進行消融實驗,以語音-人臉跨模態(tài)驗證的實驗結果為參考進行分析。
自監(jiān)督語音-人臉跨模態(tài)關聯(lián)學習網(wǎng)絡模型主要由多模態(tài)共享模塊、自監(jiān)督學習模塊和度量學習模塊組成,其中度量學習用到了多相似性損失函數(shù)和均方誤差損失函數(shù)。由于度量學習中多相似性損失函數(shù)是必要的,因此保留該函數(shù),然后分別刪除兩個模塊和均方誤差損失函數(shù)進行消融實驗,實驗結果如表2所示。

表2 Voxceleb1數(shù)據(jù)集消融實驗結果Table 2 Ablation experiment results of Voxceleb1 dataset
從表2中可以看出,當刪除其中任何一個模塊或者均方誤差損失函數(shù),與完整模型相比,跨模態(tài)驗證AUC值均有一定程度的下降。當沒有多模態(tài)共享模塊時,AUC值下降了0.3%;沒有自監(jiān)督學習模塊時,AUC值下降了0.1%;尤其是沒有均方誤差損失函數(shù)的情況下,AUC值下降了0.7%,下降比例最大。經(jīng)過對實驗結果的分析,多模態(tài)共享模塊、自監(jiān)督學習模塊以及均方誤差損失函數(shù)對最終結果都有一定的優(yōu)化。
2.4.2 對比實驗
1)跨模態(tài)驗證
本文對測試集引入性別約束,按2個分組進行測試,分別是未分層組(U)和按性別分層組(G)。按性別分層組(G)指的是給定的一組語音片段和人臉圖像性別相同。跨模態(tài)驗證的結果對比如表3所示。

表3 跨模態(tài)驗證任務上的AUC值Table 3 AUC values on cross-modal verification task
經(jīng)過對實驗結果的分析,本文方法在兩個測試組上的量化指標均有提升。其中,“U”分組比Bi-Pcm-FST方法提升了1.9%,比CMPC方法提升了2.3%,“G”分組比Bi-Pcm-FST方法提升了3.8%,比CMPC方法提升了3.4%。實驗結果明確表明,本文所提出的方法在跨模態(tài)驗證任務上優(yōu)于現(xiàn)有的幾種方法。
2)1∶2匹配
1∶2匹配的結果對比如表4所示,包含“V-F”和“F-V”2種情景。

表4 跨模態(tài)1∶2匹配任務上的準確率Table 4 Accuracy(ACC) on cross-modal 1∶2 matching task
經(jīng)過對實驗結果的分析,本文方法在兩個測試組上的量化指標均有一定的提升。其中,準確率最高的是“F-V”情景下的“U”分組,準確率達到了86.42%,比DIMNet-IG方法提升了2.39%,比CMPC方法提升了1.52%,比Bi-Pcm-FST方法提升了0.59%。實驗結果明確表明,本文所提出的方法在跨模態(tài)1∶2匹配任務上優(yōu)于現(xiàn)有的幾種方法。
3)1∶N匹配
1∶N匹配的結果對比如圖5所示,在實驗中增加了隨機情況下(Chance)的實驗結果進行對比。

圖5 跨模態(tài)1∶N匹配結果對比Fig.5 Comparison on cross-modal 1∶N matching task
經(jīng)過對實驗結果的分析,可以觀察到隨著樣本庫中樣本總數(shù)的增加,兩種模態(tài)樣本之間的匹配難度也相應增加,匹配精度持續(xù)下降。實驗結果明確表明,本文所提出的方法在不同的N值條件下仍然表現(xiàn)出優(yōu)于現(xiàn)有其他方法的性能。
4)跨模態(tài)檢索
如圖6和表5所示,跨模態(tài)檢索結果包含“V-F”和“F-V”2種場景。其中,圖6是跨模態(tài)檢索的可視化實驗結果,已將語音片段和人臉圖像屬于同一身份的結果用綠色方框標注,不屬于同一身份的結果用紅色方框標注。

表5 跨模態(tài)檢索任務上mAP的性能表現(xiàn)Table 5 Performance mAP on cross-modal retrieval task

圖6 跨模態(tài)檢索結果Fig.6 Cross-modal retrieval results
經(jīng)過對實驗結果的分析,本文所提出的方法的平均mAP為7.52,在現(xiàn)有方法的基礎上提升了1.3%。 實驗結果明確表明,基于本文模型所提取的特征表示在處理大規(guī)模數(shù)據(jù)檢索任務時表現(xiàn)出更高的準確性。在跨模態(tài)檢索任務中,由于樣本庫中的樣本數(shù)量龐大、樣本的復雜多樣性以及語音和人臉之間的模態(tài)差異,使得任務的難度顯著增加,因此現(xiàn)有方法在此任務上仍然面臨巨大的挑戰(zhàn)。
3 結論
本文提出了一種基于多模態(tài)共享網(wǎng)絡的自監(jiān)督語音-人臉關聯(lián)學習方法。該方法學習到的特征向量可有效地應用于4種語音-人臉跨模態(tài)關聯(lián)學習任務。首先,在雙流網(wǎng)絡的頂端設計了一個多模態(tài)共享模塊,充分挖掘特征之間的非線性數(shù)據(jù)關系,增加了語音與人臉在公共特征空間上的語義關聯(lián)。然后,引入自監(jiān)督學習,利用生成的偽標簽作為監(jiān)督信號來指導度量學習的過程。實驗結果表明,本文提出的方法在跨模態(tài)驗證、匹配、檢索任務上的表現(xiàn)均優(yōu)于現(xiàn)有方法。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
人大建設(2020年4期)2020-09-21 03:39:12
學苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
人大建設(2017年2期)2017-07-21 10:59:25
讀者(2017年5期)2017-02-15 18:04:18
人大建設(2017年9期)2017-02-03 02:53:31
湖北經(jīng)濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
浙江人大(2014年4期)2014-03-20 16:20:16
計算物理(2014年2期)2014-03-11 17:01:39
