基于遙感圖像道路提取的全局指導多特征融合網絡
2024-03-29 09:00:22宦海盛宇顧晨曦
浙江大學學報(工學版) 2024年4期
宦海,盛宇,顧晨曦
(1.南京信息工程大學 人工智能學院,江蘇 南京 210044;2.南京郵電大學 集成電路科學與工程學院,江蘇 南京 210003)
遙感圖像道路分割可以應用于地圖生成、汽車自動駕駛與導航等多個場景[1].相較于一般的分割任務,遙感圖像道路分割有其獨特性和困難性:1)在遙感圖像中,目標道路占據的畫幅比例普遍偏小;2)如河流、鐵路的分類對象與道路過于相似,人眼難以判別;3)道路分岔連通情況較復雜,對道路提取的識別精度有較高要求[2].
運用分割算法提取道路由計算機視覺(computer vision,CV)的圖像分割技術發展而來.圖像分割方法大致可以分為傳統算法和深度學習算法.傳統算法主要有Gabor 濾波器[3]、Sobel 算子[4]、分水嶺算法[5]等,還有較先進的機器學習方法,如支持向量機[6](support vector machine,SVM)和隨機森林[7](random forests,RF).這些方法通過提取遙感圖像中的特征,如紋理、邊緣、形狀等,進行圖像分割從而實現目標提取.在遙感圖像中,道路表現為具有連通性的狹窄線條,有些線條覆蓋整幅圖像且多條道路可能存在交叉連通,待提取的特征復雜且豐富,干擾也較多,因此傳統的圖像分割方法很難用于道路提取.深度學習技術在計算機視覺研究領域發展迅速,該方法自動獲取圖像的非線性和層次特征,可以更好地解決其他道路提取方法存在的問題.語義分割是深度學習在圖像分割領域中的主要研究方向,它能較全面地利用卷積神經網絡(convolutional neural networks,CNNs)[8]從輸入圖像中提取圖像的淺層和深層特征,實現端到端的像素級圖像分割,具有較高的分割精度和效率.
學者針對高分辨率的道路圖像提取提出的深度學習研究方法不少,但類間相似度高、噪聲干擾多、狹窄道路難提取等難點仍有待克服[9].Long等[10]提出不包含全連接層的全卷積網絡(fully convolutional networks,FCN).FCN 將CNN 最后的全連接層替換為卷積層,稱為反卷積,利用反卷積對最后一個卷積層的特征圖進行上采樣,使最后一個卷積層恢復到輸入圖像相同的尺寸,在預測每個像素的同時保留空間信息.FCN 可以適應任意尺寸輸入圖像,并且通過不同層之間的跳躍連接同時確保了網絡的魯棒性和精確性,但是FCN 不能充分提取上下文信息,語義分割精度較差.基于FCN 改進的U-Net[11]采用編解碼的網絡結構,它可以充分利用像素的位置信息,在訓練集樣本較少時仍可保持一定的分割精度.殘差神經網絡(deep residual networks,ResNet)[12]避免了因增加網絡深度造成的模型過擬合、梯度消失和梯度爆炸問題,被廣泛應用于特征提取網絡中.Zhao 等[13]提出的金字塔場景解析網絡(pyramid scene parsing network,PSPNet)使用金字塔池化模塊,Chen 等[14]提出的DeepLabV3+網絡使用空洞空間金字塔池化(atrous spatial pyramid pooling,ASPP)獲取并引入解碼模塊恢復便捷信息,這2 個網絡均提取多尺度的語義信息進行融合,提高了分割精度,但它們只關注宏觀的空間位置信息,對細節方面的信息關注不足.
注意力機制使神經網絡具備專注于輸入圖像的某些重點部分的能力.Hu 等[15]提出擠壓激勵網絡(squeeze-and-excitation networks,SE-Net),將通道注意力機制加入主干網,提升了特征提取的效率.Woo 等[16]提出卷積塊注意模塊(convolutional block attention module,CBAM),此模塊將全局最大池化加入SE 模塊,同時引入空間注意力機制,有效地提取了特征圖內的位置相關信息.Fu 等[17]提出的雙重注意網絡(dual attention network,DANet)使用2 種類型的注意力模塊,分別模擬空間維度和通道維度中的語義相互依賴性,通過對局部特征的上下文依賴關系進行建模,顯著改善了分割結果.Zhang 等[18]提出上下文先驗網絡移動語義分割的令牌金字塔轉換器,設計金字塔形式的視覺轉換器,平衡了分割精度與速度,減少了數據量,完成了困難樣本的較快速分割.
在分割道路時使用現有的語義分割網絡的效果欠佳,為此本研究提出全局指導多特征融合網絡(global guide multi-feature fusion network,GGMNet),并應用于遙感圖像的道路提取.GGMNet 包含自適應全局通道注意力模塊(adaptive globe channel attention module,AGCA)和多特征融合模塊(multifeature fusion module,MFM).
1 數據集
采用3 個數據集進行訓練與測試,分別為CITY-OSM 數據集[19]、DeepGlobe 道路提取遙感地圖數據集[20]和CHN6-CUG 數據集[21].CITYOSM 數據集使用柏林和巴黎的谷歌地圖高分辨率RGB 正射影像,共有825 幅圖像,每幅圖像為2 611×2 453 像素.按照4∶1 的比例隨機抽取,其中660 幅圖像作為訓練集,剩余165 幅圖像作為測試集.CITY-OSM 數據集有背景、建筑物和道路3 個類別.DeepGlobe 道路提取遙感地圖數據集共有6 226 幅遙感圖像,每幅圖像為1 500 × 1 500 像素,按照4∶1 的比例隨機抽取,其中4 981 幅圖像作為訓練集,剩余1 245 幅圖像作為測試集.該數據集的圖像拍攝于泰國、印度、印度尼西亞等地,圖像場景包括城市、鄉村、荒郊、海濱、熱帶雨林等,數據集有道路和背景2 個類別.CHN6-CUG 數據集是中國代表性城市大尺度衛星影像數據集,遙感影像底圖來自谷歌地球.在該數據集中,根據道路覆蓋的程度,標記道路由覆蓋道路和未覆蓋道路組成;根據地理因素的物理角度,標示道路包括鐵路、公路、城市道路和農村道路等.CHN6-CUG數據集共有4 511 幅遙感圖像,每幅圖像為512×512 像素,按照4∶1 的比例隨機抽取,其中3 608 幅圖像作為訓練集,剩余903 幅圖像作為測試集.
2 全局指導多特征融合網絡
2.1 網絡的整體結構
GGMNet 的整體結構如圖1 所示.網絡的主干部分采用ResNet-50-C[22]來提取輸入圖像的特征.網絡保留階段Res-1~Res-4 的4 個結果,并對Res-2~Res-4 的結果進行上采樣,獲得3 個與Res-1 結果的尺度相同的結果,分別為F1、F2、F3、F4.將Res-4 的結果輸入ASPP,以提取深層特征圖中的全局信息和多尺度信息.再將ASPP 的輸出作為AGCA 的輸入,利用AGCA 提取特征圖的類別信息.對AGCA 的結果進行上采樣并與之前的4 個結果進行融合,得到多層特征(multi-layer features,MF).分別將F1、F2、F3、F4與 M F 作為MFM 的輸入,得到4 個結果,分別為.融合這4 個結果并進行上采樣,得到最終的分割結果.
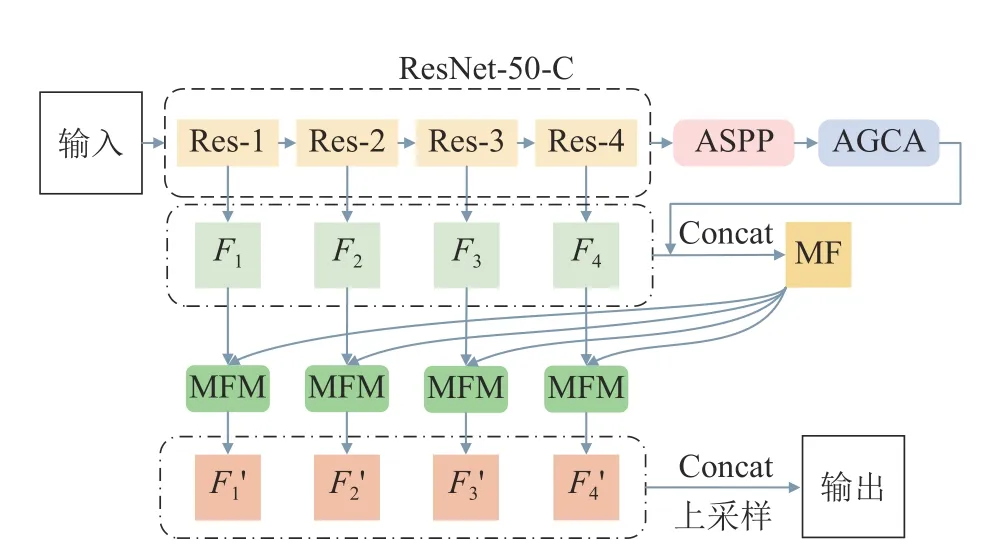
圖1 全局指導多特征融合網絡的整體結構Fig.1 Overall structure of global guide multi-feature fusion network
2.2 自適應全局通道注意力模塊
影響道路分割精度的主要原因在于網絡將與道路類似的類別錯誤識別為道路,降低了道路的交并比(intersection over union,IoU).道路周邊的像素對道路影響很大,充分提取道路及其周邊的局部信息可以提高分割精度從而降低誤分割率.本研究設計全局通道注意力模塊,模塊針對每個像素的上下文信息,從全局入手,指導局部信息的權重,在保證類別準確的同時,提高每條道路目標的位置準確率.
AGCA 的整體結構如圖2 所示.在上分支,對輸入特征圖X進行全局平均池化,得到全局信息的特征向量Xc,第m個數據Xcm的計算式為

圖2 自適應全局通道注意力模塊的整體結構Fig.2 Overall structure of adaptive globe channel attention module
式中:Fa為平均池化,Xm為第m列的所有H×W個數據.將此向量進行維度擴展,恢復成H×W×C的尺寸,再與輸入特征圖X相加.將此結果經過1×1卷積進行通道維度的改變,并經過Sigmoid 激活變為H×W×s2的尺寸,得到X1.再將X1轉化成HW×s2的二維矩陣Ac.在下分支中,將輸入特征X進行自適應平均池化,得到尺寸為s×s×C的Xs特征圖,再將此特征圖轉化為s2×C的矩陣As.將2 個矩陣相乘得到尺寸為HW×C的矩陣A,再將A轉換成尺寸為H×W×C的Xa,利用殘差思想,將X與Xa相加,得到自適應全局通道注意力模塊的輸出Z,此過程表示為上分支的全局平均池化提取特征圖X的全局信息,特別是通道中的類別信息;下分支通過自適應平均池化使圖像劃分為s×s個區域,每個區域包含此區域的位置信息.上分支中的全局信息將HW個s2維的向量作為權重,指導下分支的局部信息,再通過訓練可以提升網絡對于道路的提取能力,最終預測語義標簽.當道路的信息在圖像的不同位置時,它周邊的地物如建筑物、河流、軌道對其影響不同,導致全局的特征對其影響的權重不一致,為此將圖像分為s2個部分進行分割,并且包含全局信息的HW個權重向量分別對這s2個區域進行指導,s為可變參數,在消融實驗中進行討論,以找到最適合道路提取的取值.
2.3 多特征融合模塊
深層特征和淺層特征具有不同權重的信息,淺層特征的位置信息更加豐富,深層特征的類別信息更加豐富,往往利用注意力融合模塊融合深層和淺層特征.GGMNet 采用MFM 融合4 個層的特征圖.將4 層的特征圖以及被AGCA 處理過的第4 次特征圖進行Concat 操作得到多層特征 MF,此操作的目的是收集并進一步提取多層特征圖的信息,使這些信息的利用率達到最高,從而提高網絡的分割精度.再將4 層的特征圖通過MFM分別與 MF 進行融合,這個融合過程使4 層特征圖中的局部信息與全局的信息進一步合并,在訓練過程中全局信息可以給每張特征圖中的信息進行指導.最后將4 個與 MF 融合后的特征圖進行Concat 操作,結果包含豐富的位置信息與類別信息,使網絡的分割結果中位置更加準確,誤分割率降低.
如圖3 所示為MFM 的整體結構.將 MF 和第i層的結果Fi進行Concat 操作,經過卷積層和批量標準化(batch normalization,BN)層,然后經過ReLU 層進行激活.再經過Softmax 層得到特征圖Y,以更好地進行像素分類.將Y與 M F 相乘后與Fi進行Concat 操作,再經過 1×1 卷積降維,得到多特征融合模塊的輸出.
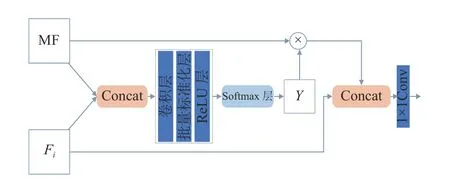
圖3 多特征融合模塊的整體結構Fig.3 Overall structure of multi-feature fusion module
3 結果與分析
3.1 實驗環境及參數設置
實驗在Centos7.8 系統的Pytorch 框架下完成,實驗平臺硬件為Intel I9-9900KF CPU、64-GB 內存和2 張具有11 GB 顯存的NVIDIA 2080Ti 顯卡,使用Mmsegmentation 語義分割開源工具箱.訓練過程使用隨機梯度下降優化算法作為優化器,學習衰減策略為Poly 學習率衰減策略,初始學習率為0.01,最低學習率為0.000 4,損失函數為交叉熵,最大迭代次數為120 000.
3.2 試驗評價指標
平均交并比(MIoU)是語義分割領域中衡量圖像分割精度的重要通用指標,是對每一類交并比求和平均的結果.IoU 為預測結果和實際結果的交集和并集之比,即分類準確的正類像素數和分類準確的正類像素數與被錯分類為負類的正類像素數以及被錯分類為正類的負類像素數之和的比值.評價指標的計算式分別為
式中:TP 為預測正確的正樣本,FP 為預測錯誤的負樣本,FN 為預測錯誤的負樣本,n為類別數.
3.3 結果與分析
3.3.1 超參數的取值對比 超參數s的大小影響局部特征的尺寸,也影響全局特征對局部特征的指導效果.在基準網絡的ASPP 模塊之后添加取不同數值s的自適應全局通道注意力模塊,以測試不同取值s的模塊性能.考慮到隨機誤差的影響,所有消融實驗都進行5 次重復實驗,文中表格所列數據為平均值.
基于CITY-OSM 數據集設置s的實驗結果如表1 所示.可以看出,添加AGCA 后,網絡的結果均有提升.在添加s=1 的模塊時,道路的IoU 提升了0.76 個百分點,網絡的MIoU 提升了1.31 個百分點;在添加s=4 的模塊時,網絡的提升達到最大,道路的IoU 提升了0.86 個百分點,網絡的MIoU 提升了1.95 個百分點.s=2 和s=5 時的提升較小,道路的IoU 分別提升了0.58 個百分點和0.21 個百分點,網絡的MIoU 分別提升了1.38 個百分點和1.49 個百分點.實驗結果表明,AGCA 可以幫助網絡進行更精細的道路提取,對道路周邊的類別識別效果有所改善,減少了誤分割率;可以觀察到,背景類別與建筑物類別在添加模塊之后的精度也有所上升,這些提升說明道路周邊的類別被識別為道路的概率也有所下降,使道路提取的準確率得到提高.實驗的視覺結果對比如圖4 所示.可以看出,基準網絡對于道路的識別不到位,邊緣模糊,且比標簽圖中的道路細,說明基準網絡在受到道路的周圍有相似地物影響時,分割性能較差.在添加AGCA 后,道路的分割情況得到明顯改善,道路的粗細更加接近標簽圖,且在s=4 時,道路分割最為準確,誤分割率最低,與標簽圖最接近.這與表1 的數據結果一致.

表1 基于CITY-OSM 數據集的自適應全局通道注意力模塊超參數取值對比Tab.1 Comparison of hyperparameter values for adaptive globe channel attention module based on CITY-OSM dataset %

圖4 基于CITY-OSM 數據集的超參數取值可視化結果對比Fig.4 Comparison of hyperparameter-value visualization results based on CITY-OSM dataset
基于DeepGlobe 數據集設置s的結果如表2所示.可以看出,所有添加AGCA 的網絡均優于基準網絡.其中s=4 時,道路的IoU=62.80%,比基準網絡高0.56 個百分點,網絡的MIoU=80.45%,比基準網絡高0.30 個百分點,結果最好.實驗結果表明,當s=4 時,網絡具有最好的性能,全局信息對局部信息的指導最充分,分割精度最高.實驗的視覺結果對比如圖5 所示.由方框標識的區域可以看出,大部分添加自適應全局通道注意力模塊的網絡在進行道路分割時,誤分割情況得到改善.s=4 的方框區域與標簽圖最接近,幾乎沒有誤分割的道路,也未將背景類別識別為道路,說明當s=4 時,自適應全局通道注意力模塊的效果最好,證明了模塊的有效性.這與表2 的數據結果一致.
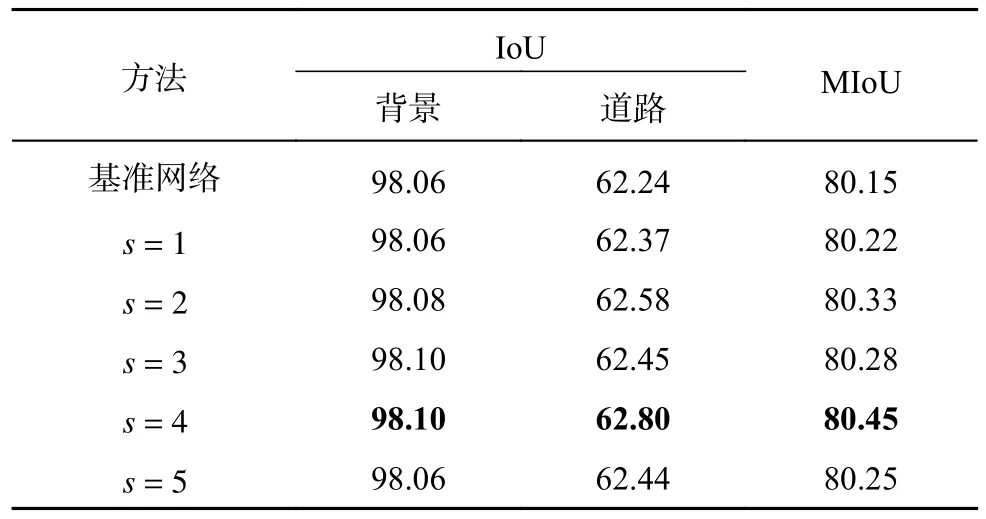
表2 基于DeepGlobe 數據集的自適應全局通道注意力模塊超參數取值對比Tab.2 Comparison of hyperparameter values for adaptive globe channel attention module based on DeepGlobe dataset %
基于CHN6-CUG 數據集設置s的結果如表3所示.可以看出,所有添加AGCA 的網絡結果均優于基準網絡.其中s=4 時,道路的IoU=61.94%,比基準網絡高1.81 個百分點;網絡的MIoU=79.62%,比基準網絡高0.99 個百分點,結果最好.實驗結果表明,當s=4 時,網絡對道路的提取能力最好,精確度最高.實驗的視覺結果對比如圖6 所示.可以看出,基準網絡分割出的道路邊緣不清晰,形狀也與標簽圖相差較大,在添加AGCA 之后,道路的邊緣與粗細都與標簽圖較接近,在s=2、3、5時,都有將背景類別識別為道路的情況,在s=1、4 時誤分割率較小.實驗結果表明,自適應全局通道注意力模塊的有效性,并且在s=4時性能最好,這與表3 的結果一致.
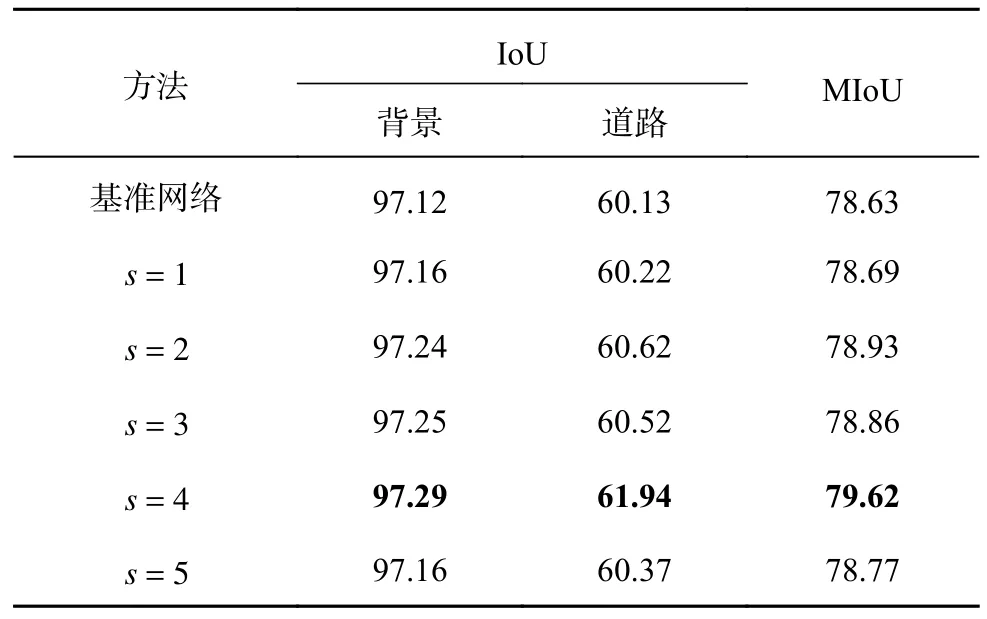
表3 基于CHN6-CUG 數據集的自適應全局通道注意力模塊超參數取值對比Tab.3 Comparison of hyperparameter values for adaptive globe channel attention module based on CHN6-CUG dataset %

圖6 基于CHN6-CUG 數據集的超參數值可視化結果對比Fig.6 Comparison of hyper parameter-value visualization results based on CHN6-CUG dataset
由3 個數據集的實驗結果可以看出,當設置s=4 時,AGCA 擁有最好的性能.此時AGCA 可以幫助網絡利用圖像的全局信息指導局部信息,并且分析道路周邊的像素類別以減少誤分割率,提高分割準確率.
3.3.2 模塊有效性分析 以ResNet50-C 加上ASPP 模塊的網絡作為基準網絡進行模塊有效性分析.在基準網絡以后添加AGCA 和解碼器中的MFM 后,測試模塊的有效性.設置3 個消融實驗來測試模塊有效性.實驗1 在基準網絡的基礎上添加AGCA.實驗2 在實驗1 的基礎上添加MFM,但只融合Res-1 和Res-4 的特征圖(淺層特征和深層特征).實驗3 在實驗1 的基礎上,將4 個階段的特征圖全部進行融合,形成最終的全局指導多特征融合網絡.實驗中統一設置s=4,如表4 所示為基于CITY-OSM 數據集對基準網絡分別添加不同模塊時的分割精度.可以看出,在添加AGCA和MFM 之后,網絡的精度變高,道路提取效果變好.實驗1 中,相比于基準網絡,道路的IoU 提高了0.86 個百分點,網絡的MIoU 提高了1.95 個百分點,證明了AGCA 的有效性,也證明該模塊可以幫助網絡識別與道路類間相似度高的其余類別,提高網絡精度.實驗2 中,道路的IoU 相較于實驗1 提高了0.02 個百分點,網絡的MIoU 提高了0.29 個百分點,提升較少,但證明了深層特征與淺層特征融合可以提高網絡精度,增加準確率.實驗3 中,道路的IoU 相較于實驗1 提高了0.52個百分點,網絡的MIoU 提高了0.93 個百分點,證明了將ResNet-50-C 的4 個階段進行特征融合的有效性,也證明了多特征融合模塊的有效性.將4 個階段特征融合可以充分利用每個階段中包含的位置信息和類別信息,減小誤分割率,優化網絡性能.實驗的可視化結果對比結果如圖7 所示.可以看出,隨著模塊的增加,道路的分割效果逐步變好,基準網絡的誤分割率很高,網絡常將背景類別與建筑物類別識別為道路,使分割效果變差,在模塊添加后誤分割的情況明顯改善,道路的完整度與粗細也與標簽圖更加接近.這與表4 的數值結果一致.

表4 基于CITY-OSM 數據集的模塊有效性分析Tab.4 Module validity analysis based on CITY-OSM dataset %
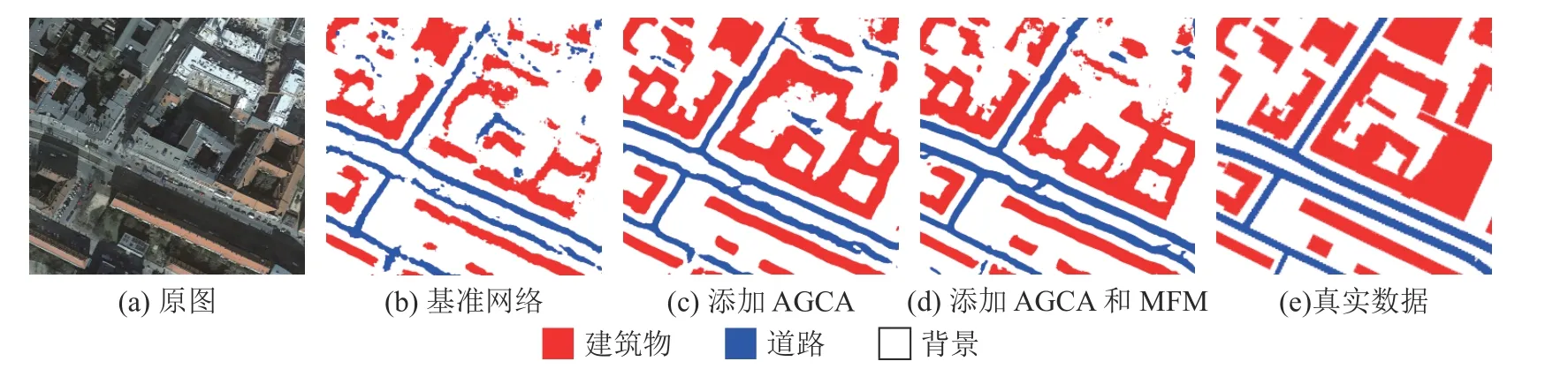
圖7 基于CITY-OSM 數據集的模塊有效性分析可視化結果對比Fig.7 Comparison of visualization results for module validity analysis based on CITY-OSM dataset
如表5 所示為基于DeepGlobe 數據集對基準網絡分別添加不同模塊時的分割精度.實驗1 中,在添加AGCA 后,相比于基準網絡,道路的IoU提高了0.56 個百分點,網絡的MIoU 提高了0.30 個百分點,證明了AGCA 的有效性.實驗2中,道路的IoU 相較于實驗1 提高了0.12 個百分點,網絡的MIoU 提高了0.06 個百分點,證明了融合深層特征與淺層特征可以幫助網絡提高精度.實驗3 中,道路的IoU 相較于實驗1 提高了0.31 個百分點,網絡的MIoU 提高了0.18 個百分點,此結果說明多特征融合可以充分利用特征圖中的位置信息和類別信息,提升網絡的分割性能.實驗的可視化結果對比結果如圖8 所示,在添加AGCA 后,道路更加鮮明,邊緣更加清晰,道路誤分割率降低;在添加MFM 后,分割結果更接近標簽圖,誤分割比重進一步減少,這與表5 的數值結果一致.

表5 基于DeepGlobe 數據集的模塊有效性分析Tab.5 Module validity analysis based on DeepGlobe dataset %
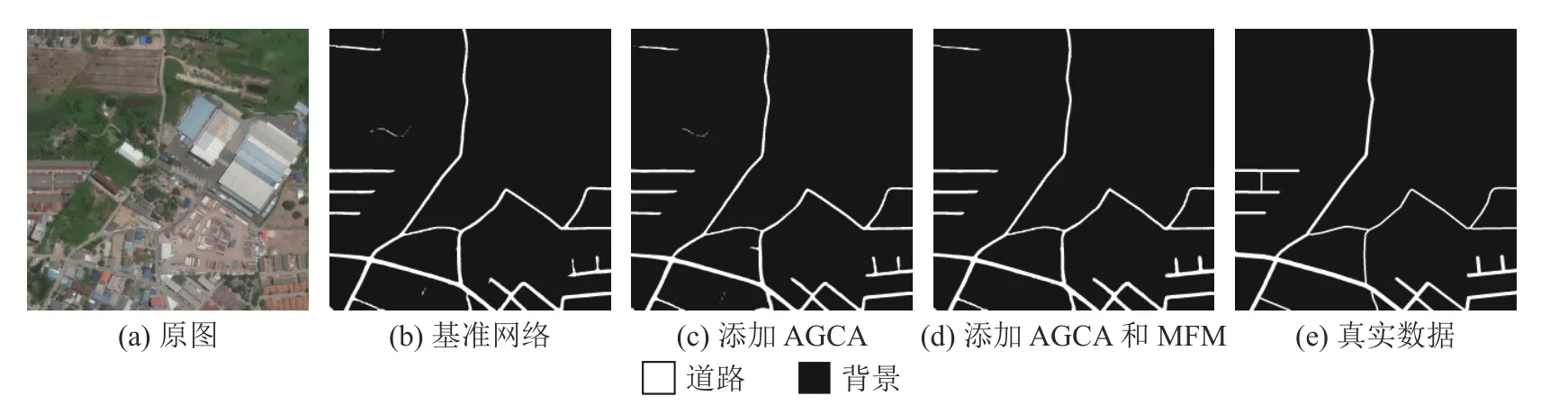
圖8 基于DeepGlobe 數據集模塊的有效性分析可視化結果對比Fig.8 Comparison of visualization results for module validity analysis based on DeepGlobe dataset
如表6 所示為基于CHN6-CUG 數據集對基準網絡分別添加不同模塊時的分割精度.實驗1 中,在添加AGCA 后,相比于基準網絡,道路的IoU提升了1.81 個百分點,網絡的MIoU 提高了0.99個百分點,證明了此模塊的有效性.實驗2 中,道路的IoU 相較于實驗1 提高了0.22 個百分點,網絡的MIoU 提高了0.10 個百分點,證明了深層特征與淺層特征的有效性,也證明了MFM 的有效性.實驗3 中,道路的IoU 相比于實驗1 提高了1.27 個百分點,網絡的MIoU 相比于實驗1 提高了0.67 個百分點,證明了融合4 個階段的特征可以幫助網絡收集更豐富的位置信息與類別信息,提升分割的精確度.實驗的可視化結果對比結果如圖9 所示.可以看出,基準網絡的道路比標簽圖粗,誤分割道路較高,在添加AGCA 后,道路形狀更接近標簽圖,道路邊緣更清晰;在添加MFM后,誤分割情況更少,這與表6 的數值結果一致.
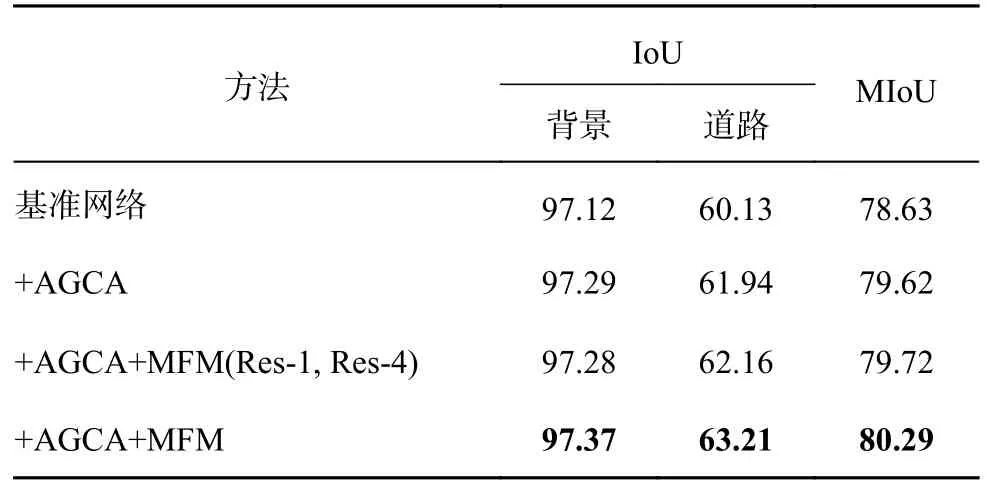
表6 基于CHN6-CUG 數據集的模塊有效性分析Tab.6 Module validity analysis based on CHN6-CUG dataset %

圖9 基于CHN6-CUG 數據集模塊的有效性分析可視化結果對比Fig.9 Comparison of visualization results for module validity analysis based on CHN6-CUG dataset
由以上3 個數據集的實驗結果可以看出,AGCA可以利用全局信息指導局部信息,減少誤分割率;MFM 可以融合4 個階段的特征以利用特征圖中的位置信息和類別信息提升網絡的分割準確率.
3.3.3 網絡對比與分析 對比不同網絡在道路提取中的性能,使用DeepLabV3[23]、APCNet[24]、CCNet[25]、DANet、EMANet[26]、DNLNet[27]、CRANet[28]、SANet[29]與所提網絡進行對比.APCNet 融合多尺度、自適應和全局指導局部親和力3 個要素設計網絡,道路分割性能較好;DANet 通過建模通道注意力和空間注意力來提取特征;EMANet 設計期望最大化注意力機制(EMA),摒棄在全圖上計算注意力圖的流程,轉而通過期望最大化(EM)算法迭代出一組緊湊的基,在這組基上運行注意力機制,大大降低了復雜度;DNLNet 設計解耦non-local 模塊,增加通道間的位置信息的交互,增加了道路分割的精確度和效率;CRANet 通過使用級聯的殘差注意力模塊來提取遙感圖像中邊界細化的道路,該結構利用多尺度特征上的空間注意殘塊來捕獲長距離關系,并引入通道注意里模塊來優化多尺度特征融合,并且設計輕量級編碼器-解碼器網絡,以自適應優化提取的道路邊界.
基于CITY-OSM 數據集的網絡分割性能對比結果如表7 所示.GGMNet 的道路IoU=77.68%,MIoU=72.33%,優于其他的語義分割網絡,與SANet 的分割效果接近.GGMNet 的另外2 個類別的IoU 也高于其他網絡.GGMNet 的道路IoU 比DNLNet 的高0.56 個百分比,比EMANet 高0.65 個百分比,證明了網絡在道路提取方面的有效性.實驗結果表明,網絡整體分割效果好,從圖像中提取的信息豐富,可以更好地進行特征融合.實驗的可視化對比結果如圖10 所示.可以看出,GGMNet的道路分割情況優于其他網絡,比SANet 的分割情況略好.在參與對比的網絡中,GGMNet 的道路最為清晰,連通狀況最好,其余網絡的誤分割情況較為嚴重,將零散的背景類中顏色較深的陰影錯誤識別為道路,GGMNet 的誤分割情況最少,分割結果最好,這與表7 的數據結果一致.

表7 基于CITY-OSM 數據集不同網絡的分割性能對比Tab.7 Segmentation performance comparison of different networks based on CITY-OSM dataset %

圖10 不同網絡基于CITY-OSM 數據集的分割結果對比Fig.10 Segmentation results comparison of different networks based on CITY-OSM dataset
基于DeepGlobe 數據集的網絡分割性能對比結果如表8 所示.可以看出,GGMNet 的MIoU=80.63%,是最優結果,道路的IoU=63.11%,也是最優結果;SANet 的道路MIoU 次優,道路的IoU 也為次優.這些結果證明了GGMNet 的有效性,GGMNet在道路提取方面比其他網絡精度更高,通過全局信息指導局部信息,并融合位置信息與類別信息使分割結果更準確.實驗的可視化對比結果如圖11 所示.在標簽圖中,方框區域沒有道路,觀察原圖可以發現,此區域為農田與農田邊界,農田邊界與道路的相似度極高,極易被誤分割為道路.在其他網絡的分割結果中,農田邊界都被判定為道路,而GGMNet 未出現誤分割情況.GGMNet中的AGCA 通過全局信息對局部信息的指導,識別出農田邊界為背景類別而非道路類別,提高了分割精確性.這與表8 的數據結果一致.

表8 基于DeepGlobe 數據集不同網絡的分割性能對比Tab.8 Segmentation performance comparison of different networks based on DeepGlobe dataset %

圖11 不同網絡基于DeepGlobe 數據集的分割結果對比Fig.11 Segmentation results comparison of different networks based on DeepGlobe dataset
基于CHN6-CUG 數據集的網絡分割性能對比結果如表9 所示.可以看出,GGMNet 的表現最好,擁有最優的分割結果.GGMNet 的道路IoU=63.21%,MIoU=80.29%,比次優的SANet 稍好,優于其他分割網絡的結果.說明針對道路提取,GGMNet 可以充分利用特征圖的信息以獲得更精確的分割結果.實驗的可視化對比結果如圖12 所示.可以看出,SANet,DNLNet,GGMNet 的分割效果較好,其余道路都有較嚴重的道路斷連情況和形狀問題.GGMNet 中的道路連通性最好、最完整,也與標簽圖中的道路形狀最接近,證明了GGMNet 在道路提取方面的有效性與優越性.這與表9 的數據結果一致.
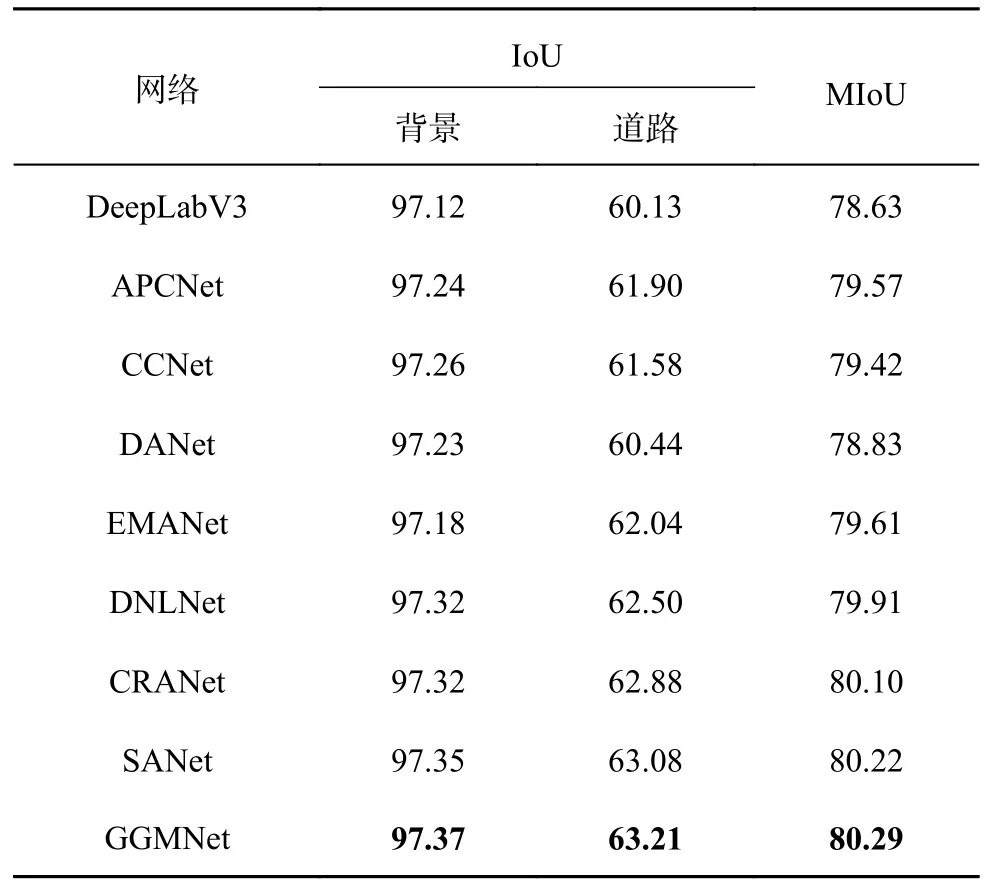
表9 基于CHN6-CUG 數據集不同網絡的分割性能對比Tab.9 Segmentation performance comparison of different networks based on CHN6-CUG dataset %

圖12 不同網絡基于CHN6-CUG 數據集的分割結果對比Fig.12 Segmentation results comparison of different networks based on CHN6-CUG dataset
通過以上3 個數據集的實驗結果可以看出,在參與對比的網絡中,GGMNet 可以在其他網絡誤分割率較高的情況下,維持較低的誤分割率,并且保證道路的連通性,道路尺度也更接近標簽圖,可以完成分辨率較高的遙感圖像道路提取任務.
4 結語
本研究就遙感圖像道路提取任務提出全局指導多特征融合網絡GGMNet,有效解決了道路提取誤分割率高的問題.詳細介紹了GGMNet 的網絡結構和設計思路,以及各個模塊的主要作用.設計了自適應全局通道注意力模塊(AGCA),利用全局上下文信息指導局部特征對各類別地物的特征提取;設計了多特征融合模塊(MFM)來融合多階段特征圖的特征.將多階段特征圖與被AGCA處理后的Res-4 階段的特征圖用MFM 進行融合,使每階段的位置信息與類別信息得到充分利用,提高分割精度.在CITY-OSM 數據集、DeepGlobe道路提取數據集和CHN6-CUG 道路數據集上的實驗結果表明,GGMNet 的分割性能優秀,可以將圖片中道路較為完整地提取出來,誤分割率低,在參與對比的網絡中分割性能最好.本研究在訓練語義分割網絡時,對輸入圖像進行了簡單的預處理(如旋轉、翻折),在處理道路相關的數據時,這些操作有可能使特征沒有被充分利用.在未來的工作中,將嘗試利用如形態學、圖像直方圖的圖像處理算法進行訓練圖像的預處理,提升特征提取網絡對特征的利用效率,以提高分割精度.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
