基于灰狼算法和極限學(xué)習(xí)機(jī)的風(fēng)速多步預(yù)測
2024-03-09 02:51:16張文煜馬可可郭振海邱文智
鄭州大學(xué)學(xué)報(工學(xué)版) 2024年2期
張文煜, 馬可可, 郭振海, 趙 晶, 邱文智
(1.鄭州大學(xué) 地球科學(xué)與技術(shù)學(xué)院,河南 鄭州 450001;2.鄭州大學(xué) 計算機(jī)與人工智能學(xué)院,河南 鄭州 450001;3.中國科學(xué)院大氣物理研究所 大氣科學(xué)和地球流體力學(xué)數(shù)值模擬國家重點實驗室,北京 100029)
風(fēng)能作為一種清潔的可再生能源,開發(fā)潛力巨大。近年來,中國風(fēng)電裝機(jī)總?cè)萘垦杆僭黾?但由于風(fēng)具有間歇性和波動性[1-3],當(dāng)大規(guī)模風(fēng)電接入電網(wǎng)時,將給電網(wǎng)調(diào)度帶來困難,解決這一問題的有效方式之一是對未來風(fēng)速變化的準(zhǔn)確預(yù)測。隨著人工智能的發(fā)展,人工神經(jīng)網(wǎng)絡(luò)(artificial neural networks,ANN)因具有強大的非線性數(shù)據(jù)擬合能力在風(fēng)速時間序列的建模和預(yù)測中頗具優(yōu)勢[4]。
已有研究大多是對風(fēng)速進(jìn)行一步或少數(shù)幾步預(yù)測,而對于大步長風(fēng)速預(yù)測的研究還處于初級階段,特別是用于風(fēng)電場的4 h、16步預(yù)測[5]。Liu等[6]使用一種基于譜聚類和回聲狀態(tài)網(wǎng)絡(luò)的方法預(yù)測未來16步風(fēng)速。Zhao等[7]建立了16個一維卷積神經(jīng)網(wǎng)絡(luò)來預(yù)測未來16步風(fēng)速,提供了16步風(fēng)速預(yù)測的一種可行思路,但計算開銷較大。
鑒于此,本文使用極限學(xué)習(xí)機(jī)(extreme learning machine,ELM)[8]作為風(fēng)速時間序列的預(yù)測模型,并使用多輸入-多輸出策略建立ELM。ELM是一種特殊的單隱層前饋神經(jīng)網(wǎng)絡(luò),與傳統(tǒng)的前饋網(wǎng)絡(luò)使用梯度下降和誤差反向傳播進(jìn)行網(wǎng)絡(luò)更新的方式不同,ELM隨機(jī)地生成隱含層的權(quán)值和偏置并解析地計算隱含層到輸出層的權(quán)值參數(shù)。因此,ELM具有計算速度快、泛化性能強等優(yōu)點,適用于風(fēng)速預(yù)測問題[9]。一些研究表明,使用人工智能優(yōu)化算法求解最優(yōu)隱含層參數(shù)可以降低ELM的輸出誤差[10]。Mirjalili等[11]的研究結(jié)果顯示,與粒子群優(yōu)化、遺傳算法等經(jīng)典的啟發(fā)式算法相比,灰狼優(yōu)化(grey wolf optimization, GWO)算法[12]在求解單峰和多峰函數(shù)問題時都更具優(yōu)勢。因此,本文采用GWO算法搜索ELM隱含層參數(shù)的最優(yōu)值,并進(jìn)一步計算輸出層權(quán)值。
另一方面,風(fēng)速序列本身具有復(fù)雜的非線性特征,單一模型很難取得滿意的預(yù)測結(jié)果。使用信號分解方法將原始數(shù)據(jù)序列分解成若干具有不同數(shù)據(jù)特征的子序列的集合,是改進(jìn)模型預(yù)測結(jié)果的有效方法。常用的分解方法有經(jīng)驗?zāi)B(tài)分解(empirical mode decomposition, EMD)[13]、變分模態(tài)分解[14]和奇異譜分析等。其中,EMD是應(yīng)用最為廣泛的方法,它能夠根據(jù)數(shù)據(jù)自身的時間尺度特征來識別信號中包含的振動模態(tài),并將復(fù)雜的原始信號分解為有限個本征模態(tài)函數(shù)(intrinsic mode function, IMF)。與小波分解等方法不同,EMD不需要預(yù)先設(shè)定任何基函數(shù),在處理非平穩(wěn)及非線性數(shù)據(jù)時具有優(yōu)勢,但EMD存在模態(tài)混疊現(xiàn)象。為了解決模態(tài)混疊現(xiàn)象,具有自適應(yīng)噪聲的完全集成經(jīng)驗?zāi)B(tài)分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)[15]算法在分解過程的每個階段自適應(yīng)地加入白噪聲,并計算唯一的余量信號,其重構(gòu)誤差極低,而且能夠產(chǎn)生更好的模態(tài)分離結(jié)果。韓宏志等[16]使用CEEMDAN分解原始風(fēng)速信號,將分解結(jié)果作為回聲狀態(tài)網(wǎng)絡(luò)的輸入并建立預(yù)測模型。Ren等[17]建立CEEMDAN與ANN的混合風(fēng)速預(yù)測模型,并與EMD-ANN、EEMD-ANN等模型進(jìn)行比較,結(jié)果表明:CEEMDAN-ANN模型具有更高的預(yù)測精度。
基于以上分析,本文構(gòu)建了CEEMDAN-GWO-ELM混合模型,用于風(fēng)速時間序列的多步預(yù)測。使用CEEMDAN算法將原始風(fēng)速分解為若干具有不同數(shù)據(jù)特征的子序列的集合,在各子序列上建立GWO優(yōu)化的ELM模型并進(jìn)行多步預(yù)測,最終的預(yù)測結(jié)果由各子序列的預(yù)測重構(gòu)生成。將提出的CEEMDAN-GWO-ELM模型應(yīng)用于實際風(fēng)電場的4 h風(fēng)速預(yù)測問題,進(jìn)行了預(yù)測步長為16的模擬試驗和模型比較試驗,用于驗證該模型在大步長的風(fēng)速預(yù)測問題中的有效性和適用性。
1 數(shù)據(jù)預(yù)處理與特征選擇
1.1 數(shù)據(jù)預(yù)處理
1.1.1 具有自適應(yīng)噪聲的完全集成經(jīng)驗?zāi)B(tài)分解(CEEMDAN)
CEEMDAN通過在每個分解階段為唯一的余量信號添加高斯白噪聲后再進(jìn)行EMD分解,其分解過程具有完整性[18],能以較低的計算成本提供原始信號的精確重建和更好的模式頻譜分離。定義操作符Mk(·)為通過EMD算法得到的第k個模態(tài)分量;vi(t)為符合標(biāo)準(zhǔn)正態(tài)分布的高斯白噪聲;ε為高斯白噪聲的標(biāo)準(zhǔn)差。CEEMDAN的計算過程如下。
步驟1 設(shè)s(t)為原始信號,對信號s(t)+ε0vi(t)進(jìn)行I次試驗,通過EMD獲取第一個模態(tài)分量:
(1)
步驟2 在第1階段(k=1),計算唯一的殘差項:
r1(t)=s(t)-IMF1(t)。
(2)
步驟3 以r1(t)作為新的原始信號,進(jìn)行I次試驗,每次試驗使用EMD算法分解新構(gòu)建的r1(t)+ε1M1(vi(t))信號,計算第2個模態(tài)分量:
(3)
步驟4 對其余各階段即k=2,3,…,K,與步驟2和步驟3的計算過程一致。首先計算第k個殘差項rk(t),再計算第k+1個模態(tài)分量IMFk+1(t):
rk(t)=rk-1(t)-IMFk(t);
(4)
(5)
步驟5 重復(fù)執(zhí)行步驟4,直至殘差項無法滿足分解條件。此時原始信號s(t)被分解為
(6)
(7)
式中:K為分解得到的模態(tài)個數(shù);R(t)為最終的殘差項。
1.1.2 歸一化
使用最大最小歸一化法將模態(tài)分量的值z=[z1,z2,…,zi,…,zn]歸一化到[0,1]內(nèi),如下式:
(8)
式中:zi′為歸一化后的元素值;zmax和zmin分別為模態(tài)分量中的最大值和最小值;n為模態(tài)分量的序列長度。
1.2 輸入數(shù)據(jù)的特征選擇
輸入數(shù)據(jù)的窗口大小影響模型的預(yù)測水平,這是因為窗口過大會引入冗余信息,而窗口太小會丟失部分有用的信息[19]。本文使用偏自相關(guān)函數(shù)(partial autocorrelation function, PACF)[20]確定模型輸入數(shù)據(jù)的窗口大小。
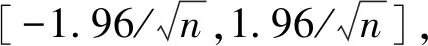
2 灰狼算法優(yōu)化的極限學(xué)習(xí)機(jī)模型
2.1 極限學(xué)習(xí)機(jī)(ELM)
ELM是一種單隱層前饋神經(jīng)網(wǎng)絡(luò),假設(shè)它的隱含層節(jié)點數(shù)為L,輸出層的節(jié)點數(shù)為m,對于輸入樣本(xi,yi),i=1,2,…,N,N為樣本總數(shù),xi=[xi1,xi2,…,xid]T為d維輸入數(shù)據(jù),yi=[yi1,yi2,…,yim]T為m維輸出數(shù)據(jù),ELM隱含層的輸出可表示為
(9)
式中:G為隱含層節(jié)點的激活函數(shù),通常使用sigmoid函數(shù);wk=[wi1,wi2,…,wid]T為輸入節(jié)點與隱含層節(jié)點間的權(quán)值向量;bk為隱含層節(jié)點的偏置;βk=[βi1,βi2,…,βim]T是隱含層節(jié)點與輸出層節(jié)點間的權(quán)值向量。
令ELM的輸出值零誤差地逼近給定的N個樣本,即
(10)
也就是說,存在βk、wk、bk使得
(11)
式(11)可以簡化為
Hβ=Y。
(12)
式中:H為ELM的隱含層輸出矩陣;β為隱含層與輸出層之間的權(quán)值矩陣;Y為ELM的理想輸出,分別表示為
(13)
(14)
(15)
ELM的訓(xùn)練過程相當(dāng)于求解出β矩陣,其解可表示為
(16)
式中:H+為H的摩爾-彭羅斯(Moore-Penrose)廣義逆矩陣。
2.2 灰狼優(yōu)化算法(GWO)
GWO是一種元啟發(fā)式算法,其靈感來源于灰狼,本質(zhì)上模仿了灰狼的領(lǐng)導(dǎo)階層和狩獵機(jī)制。GWO將每一匹狼作為一個解,設(shè)α為全局最優(yōu)解,γ和δ為全局第二和第三優(yōu)解,其余候選解記為ω。ω狼(搜索代理)在α、γ及δ狼的帶領(lǐng)下進(jìn)行搜索和狩獵,主要過程可表示為
D=|C·Xp(e)-X(e)| ;
(17)
A=2ar1-a;
(18)
C=2r2;
(19)
(20)
式中:X和Xp分別為搜索代理和獵物的位置向量;D表示搜索代理與獵物的距離;e為當(dāng)前迭代次數(shù);A和C為系數(shù)向量;r1和r2為[0,1]隨機(jī)數(shù);E為最大迭代次數(shù);a為收斂因子,在迭代過程中從2線性減小至0。
搜索代理X與α、γ及δ狼的距離確定為
(21)
則搜索代理在下一次迭代的位置由下式更新。
(Xδ(e)-A3Dδ)]。
(22)
2.3 極限學(xué)習(xí)機(jī)的參數(shù)優(yōu)化
本文使用GWO選取使得網(wǎng)絡(luò)輸出誤差最小的隱含層權(quán)值和偏置,通過搜索最優(yōu)化的隱含層權(quán)值和偏置,進(jìn)一步改進(jìn)ELM模型的多步預(yù)測結(jié)果。基于GWO優(yōu)化的ELM模型的具體步驟如下。
步驟1 初始化GWO參數(shù)。其中,最大迭代次數(shù)E=2 000,搜索代理的數(shù)量C=5,α、γ、δ狼的適應(yīng)度值Fα、Fγ、Fδ設(shè)置為+∞,使用[0,1]中的隨機(jī)數(shù)初始化每個搜索代理的位置向量X。
步驟2 對于第c個搜索代理(c=1,2,…,C),用其位置向量Xc初始化ELM的隱含層權(quán)重和偏置,在訓(xùn)練集上求解隱含層與輸出層之間的權(quán)值矩陣β。在驗證集上,計算該灰狼的適應(yīng)度函數(shù)值Fc:
(23)
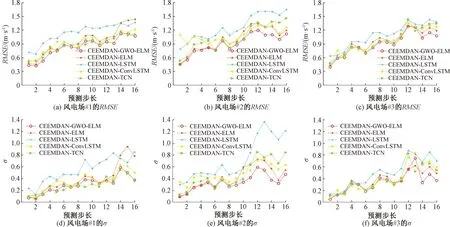
如果該搜索代理的Fc滿足Fc 步驟3 對于第c個搜索代理(c=1,2,…,C),使用式(21)和式(22)更新位置向量Xc。 步驟4 重復(fù)執(zhí)行步驟2和步驟3,直到達(dá)到最大迭代次數(shù)E,輸出α狼的位置向量Xα作為ELM的最優(yōu)隱含層權(quán)重和偏置。 本文提出的風(fēng)速預(yù)測模型是由CEEMDAN、GWO及ELM組成的混合模型,記為CEEMDAN-GWO-ELM,圖1為混合預(yù)測模型流程圖。具體步驟如下。 圖1 CEEMDAN-GWO-ELM混合預(yù)測模型流程圖 步驟1 通過CEEMDAN將原始風(fēng)速序列分解為K個IMF子序列和一個殘差項。 步驟2 對分解得到的子序列進(jìn)行最大最小歸一化。 步驟3 計算各子序列在不同滯后階數(shù)下的PACF值,并對模型輸入特征進(jìn)行選擇。 步驟4 在每個子序列上,分別建立GWO優(yōu)化的ELM模型,模型輸入由步驟3確定。對未來4 h的風(fēng)速變化情況進(jìn)行預(yù)測,即16步預(yù)測,并對預(yù)測結(jié)果進(jìn)行反歸一化。 步驟5 對各子序列的預(yù)測結(jié)果進(jìn)行重構(gòu),得到原始風(fēng)速序列的混合預(yù)測結(jié)果。 CEEMDAN將風(fēng)速序列分解為若干不同頻率特征的子序列,以削弱風(fēng)速序列的非線性[22],從而提高模型的預(yù)測水平。由于ELM的隱含層權(quán)值和偏置是隨機(jī)產(chǎn)生的,因此可以使用GWO尋找ELM的最優(yōu)隱含層權(quán)值和偏置,提高ELM預(yù)測的精度和穩(wěn)定性。 本文使用的數(shù)據(jù)來自中國山東省3個風(fēng)電場時間間隔為15 min風(fēng)速觀測資料,如圖2所示,它們的統(tǒng)計特征如表1所示。對每一個風(fēng)電場,將原始數(shù)據(jù)按照7∶2∶1劃分為訓(xùn)練集、驗證集及測試集,其中訓(xùn)練集用于建立模型,測試集用于模型評價,而在GWO優(yōu)化ELM參數(shù)過程中,將根據(jù)ELM在驗證集上的適應(yīng)度值來選擇ELM的隱含層參數(shù)。 表1 風(fēng)速序列的統(tǒng)計特征 圖2 3個風(fēng)電場的風(fēng)速序列 本文使用均方根誤差(RMSE)和誤差方差σ來評價預(yù)測模型的準(zhǔn)確性和穩(wěn)定性。其表達(dá)式為 (24) (25) 分別使用3個風(fēng)電場的數(shù)據(jù)集建立圖1中的預(yù)測模型,進(jìn)行4 h風(fēng)速預(yù)測,即16步預(yù)測。 為了驗證本文建立的CEEMDAN-GWO-ELM模型的有效性和適用性,選取了4個不同的比較模型。具體地,選取ELM和CEEMDAN-ELM作為CEEMDAN-GWO-ELM的關(guān)聯(lián)模型,用于驗證基于CEEMDAN的序列分解方法和基于GWO的參數(shù)優(yōu)化方法對提高ELM模型預(yù)測水平的有效性。此外,選擇了基于CEEMDAN分解的LSTM[23]、卷積LSTM和時域卷積網(wǎng)絡(luò)(temporal convolutional network,TCN)[17],分別記為CEEMDAN-LSTM、CEEMDAN-ConvLSTM和CEEMDAN-TCN,用于與CEEMDAN-GWO-ELM的對比分析。上述模型的參數(shù)設(shè)置如表2所示。 表2 模型的參數(shù)設(shè)置 以風(fēng)電場#1為例進(jìn)行分析。首先使用CEEMDAN對原始風(fēng)速序列進(jìn)行分解,得到11個IMFs和一個殘差項。其中,殘差項的值域約為[-3.553×10-15, 3.553×10-15],其數(shù)量級遠(yuǎn)小于原始序列取值的數(shù)量級,對預(yù)測結(jié)果幾乎沒有影響,因此,不對該殘差項進(jìn)行建模預(yù)測。 計算原風(fēng)速序列和11個IMFs的偏自相關(guān)函數(shù)值,選擇偏自相關(guān)函數(shù)值超出95%置信區(qū)間的滯后階數(shù)所對應(yīng)的變量作為輸入特征,如表3所示。由表3可以看出,對不同的IMF子序列,模型所選擇的輸入特征也是不同的。 表3 輸入變量選擇結(jié)果 根據(jù)表3中確定的輸入特征,在每一個IMF子序列上建立GWO-ELM模型,并對子序列的預(yù)測結(jié)果進(jìn)行重構(gòu)。 圖3給出了使用CEEMDAN-GWO-ELM模型在風(fēng)電場#1的4個仿真案例,左邊為未來16步風(fēng)速的實際值與CEEMDAN-GWO-ELM模型的預(yù)測值,右邊為每步預(yù)測值與實際值的誤差。圖3中4個仿真案例的預(yù)測起始時間分別為2019-04-05T06:00:00、2019-04-05T02:00:00、2019-04-05T22:00:00和2019-04-06T10:00:00。由圖3可以看出,該方法能夠較好地預(yù)測未來4 h的風(fēng)速變化情況,且隨著預(yù)測步長的增加,模型的預(yù)測偏差始終保持在一定的范圍內(nèi)。這表明本文建立的模型在大步長的風(fēng)速預(yù)測問題中能夠產(chǎn)生可靠的預(yù)測結(jié)果。 圖3 CEEMDAN-GWO-ELM預(yù)測風(fēng)電場#1的仿真案例 表4對比了不同模型對3個風(fēng)電場進(jìn)行預(yù)測的誤差指標(biāo)情況。首先,比較ELM和CEEMDAN-ELM模型的預(yù)測結(jié)果。可以看出,使用CEEMDAN對原始風(fēng)速序列進(jìn)行分解能夠顯著提高模型的預(yù)測水平。具體地,相比于ELM,CEEMDAN-ELM在風(fēng)電場#1的RMSE下降了37.6%,在其他風(fēng)電場上的預(yù)測精度也有相當(dāng)大的提升。同時,相比于ELM模型,CEEMDAN-ELM在風(fēng)電場#1~#3的誤差方差分別降低了52.7%、75.1%和72.9%,這表明CEEMDAN分解方法能夠在降低模型預(yù)測誤差的同時提高預(yù)測的穩(wěn)定性。這是因為風(fēng)速時間序列具有復(fù)雜的非線性特征,使用單一模型時通常難以取得滿意的預(yù)測結(jié)果。CEEMDAN將原始風(fēng)速序列分解為若干具有不同頻率特征的子序列,使得預(yù)測模型能夠更好地描述各數(shù)據(jù)序列的變化特征,從而提高模型預(yù)測水平。 表4 不同模型對3個風(fēng)電場的預(yù)測結(jié)果 在對CEEMDAN-GWO-ELM和CEEMDAN-ELM的比較中能夠發(fā)現(xiàn),通過搜索ELM的最優(yōu)隱含層權(quán)值和偏置,模型的預(yù)測水平得到了進(jìn)一步提升。結(jié)果顯示,基于GWO的參數(shù)優(yōu)化使得3個風(fēng)電場的RMSE分別下降了13.8%、9.3%和5.5%,σ分別下降了26.9%、18.8%和8.9%。這表明與隨機(jī)初始化ELM隱含層的權(quán)值和偏置相比,優(yōu)化選取的隱含層參數(shù)值能夠改進(jìn)ELM的網(wǎng)絡(luò)性能。本文使用的GWO算法提供了搜索上述最優(yōu)化參數(shù)的有效途徑。 進(jìn)一步分析基于CEEMDAN分解的LSTM、ConvLSTM及TCN在16步風(fēng)速預(yù)測中的表現(xiàn)。表4顯示,CEEMDAN-ConvLSTM和CEEMDAN-TCN的預(yù)測結(jié)果整體上優(yōu)于CEEMADN-LSTM,這表明在處理風(fēng)速時間序列的多步預(yù)測問題時,卷積網(wǎng)絡(luò)具有一定的優(yōu)勢,這與文獻(xiàn)[5]和[7]的結(jié)果一致。與本文提出的模型相比,CEEMDAN-TCN在風(fēng)電場#1的誤差方差略低于CEEMDAN-GWO-ELM,表現(xiàn)出更強的穩(wěn)定性。除此之外,本文提出的CEEMDAN-GWO-ELM模型對3個風(fēng)電場的全部評價指標(biāo)均優(yōu)于所有的比較模型,表明該混合模型在風(fēng)速時間序列的多步預(yù)測問題中具有較強的適用性。 使用統(tǒng)計模型進(jìn)行多步預(yù)測時,隨著預(yù)測步長的增加,模型的預(yù)測精度和穩(wěn)定性通常會逐漸下降。這是因為統(tǒng)計模型是基于歷史數(shù)據(jù)集的內(nèi)在統(tǒng)計規(guī)律建立的,并對未來變化進(jìn)行預(yù)估。在多步預(yù)測過程中,模型所產(chǎn)生的預(yù)測值與真實值之間的偏差會隨預(yù)測步長的增加不斷累積,導(dǎo)致預(yù)測誤差逐漸增大甚至發(fā)散。分析誤差隨預(yù)測步長的變化情況,對討論多步預(yù)測模型在實際應(yīng)用中的有效性和適用性是頗具意義的。圖4直觀展示了不同預(yù)測模型對3個風(fēng)電場的RMSE和σ隨預(yù)測步長的變化情況。 圖4 不同模型在3個風(fēng)電場的誤差指標(biāo)隨著預(yù)測步長的變化趨勢 整體來看,在3個風(fēng)電場中,所有模型的RMSE和σ都隨著預(yù)測步長的增加而逐漸增大。以RMSE為例,在風(fēng)電場#1的預(yù)測結(jié)果中,各模型的RMSE誤差曲線較為集中,且CEEMDAN-TCN和CEEMDAN-GWO-ELM的σ更小。特別地,在預(yù)測步長大于12步的情況下(即大于3 h的預(yù)測),本文提出的CEEMDAN-GWO-ELM模型在RMSE和σ的比較中都更具優(yōu)勢。在風(fēng)電場#2和#3的預(yù)測結(jié)果中,各模型之間具有明顯差異。例如在風(fēng)電場#2中,CEEMDAN-GWO-ELM對未來第4 h風(fēng)速預(yù)測的RMSE和σ分別為1.116 4和0.470 7,分別比排名第二的CEEMDAN-ELM降低了6.4%和14.1%;而在風(fēng)電場#3中,CEEMDAN-GWO-ELM對未來第4 h風(fēng)速預(yù)測的RMSE和σ分別為1.073 8和0.371 1,分別比排名第二的CEEMDAN-ELM降低了9.8%和24.2%。從圖4(b)~4(f)也可以看出,在大于3 h的預(yù)測中,CEEMDAN-GWO-ELM模型幾乎在所有的預(yù)測步長上都有更低的RMSE和σ。這表明,所提出的CEEMDAN-GWO-ELM模型能夠更好地描述風(fēng)速時間序列的復(fù)雜變化特征,能夠在大步長的預(yù)測問題中產(chǎn)生可靠的結(jié)果。 (1)利用CEEMDAN將原始風(fēng)速序列分解為若干具有不同頻率特征的子序列能夠降低模型的預(yù)測難度。 (2)利用GWO搜索ELM的最優(yōu)隱含層權(quán)值和偏置能夠提高ELM的預(yù)測精度和穩(wěn)定性。 (3)在3個風(fēng)電場進(jìn)行模型比較實驗中,提出的CEEMDAN-GWO-ELM混合模型都具有最高的預(yù)測水平,驗證了該模型具有一定的適用性。 在本文的研究中,CEEMDAN的分解結(jié)果存在高頻子序列,一定程度上影響模型的預(yù)測精度,因此,下一步將在降低高頻子序不規(guī)則性的基礎(chǔ)上改進(jìn)預(yù)測模型。3 CEEMDAN-GWO-ELM混合預(yù)測模型
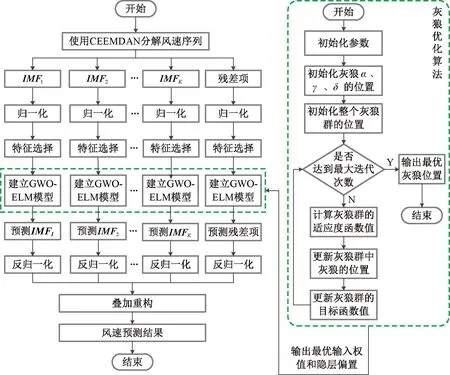
4 算例分析
4.1 數(shù)據(jù)集

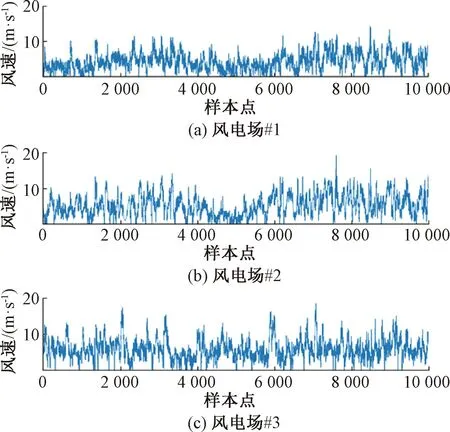
4.2 模型評價指標(biāo)
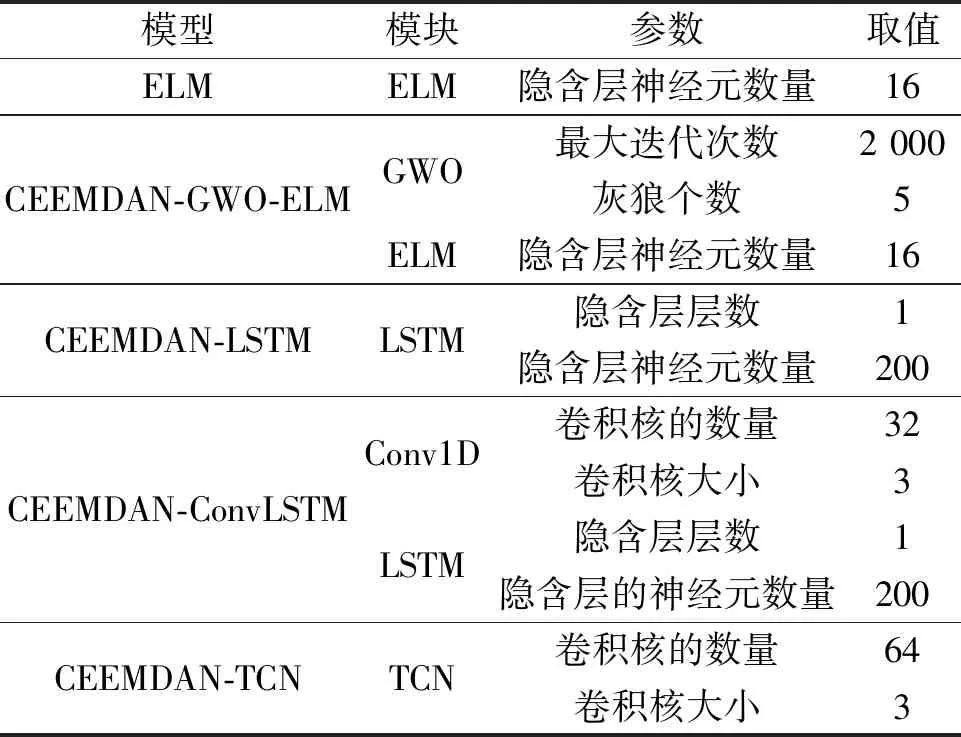
4.3 試驗設(shè)置
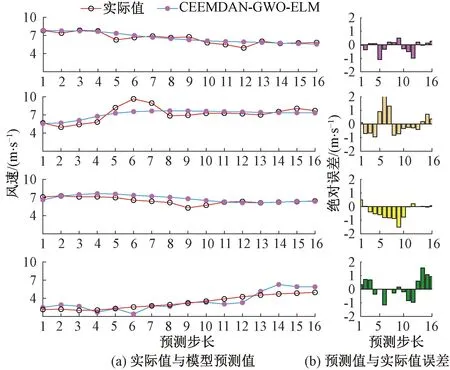
4.4 個例分析
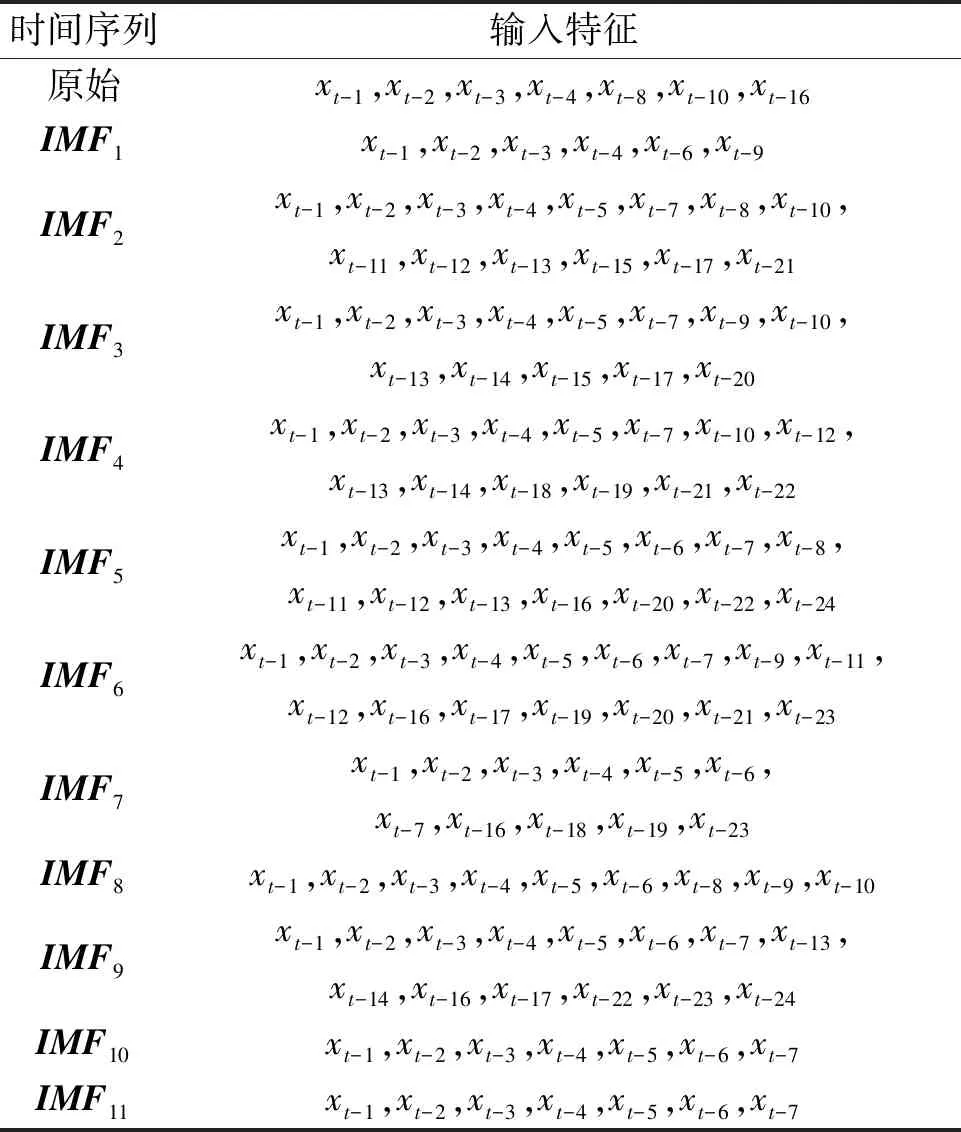
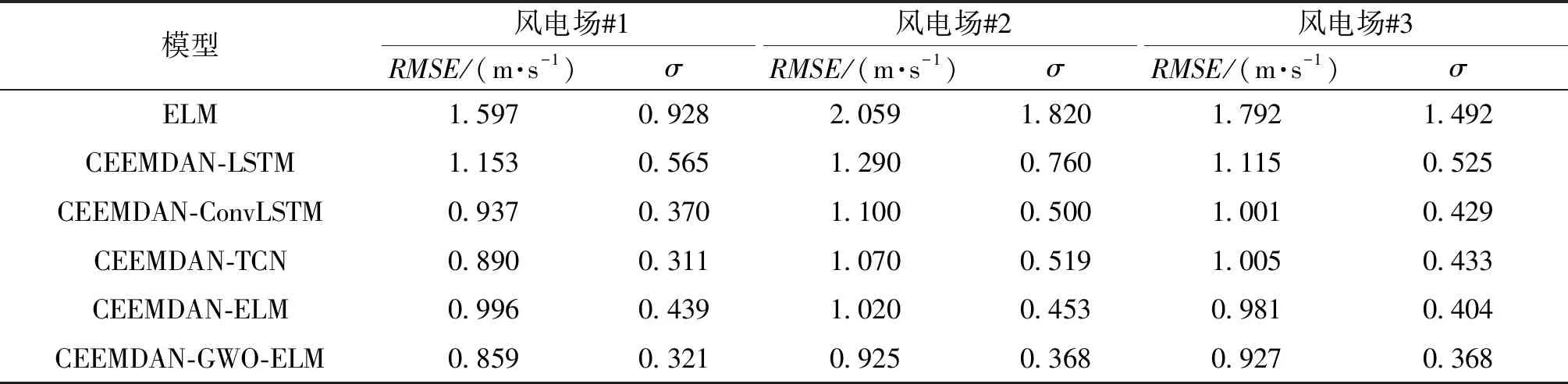
4.5 模型比較分析
4.6 模型的預(yù)測性能隨預(yù)測步長的變化分析
5 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
電機(jī)與控制應(yīng)用(2021年12期)2021-02-28 07:55:52
海洋通報(2020年5期)2021-01-14 09:26:54
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
西南交通大學(xué)學(xué)報(2016年4期)2016-06-15 20:29:37
湖北經(jīng)濟(jì)學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
電網(wǎng)與清潔能源(2015年3期)2015-02-28 16:03:31
上海電機(jī)學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
