基于改進VMD與BiLSTM的滾動軸承剩余壽命預測模型
2024-02-27 04:42:58潘磊,皋軍,邵星
電子設計工程 2024年4期
潘 磊,皋 軍,邵 星
(1.鹽城工學院信息工程學院,江蘇鹽城 224051;2.鹽城工學院機械工程學院,江蘇鹽城 224051)
滾動軸承是現代工業設備的必備零件[1],軸承如果突然出現故障,可能會導致設備停止運轉,嚴重的話會造成不可預估的后果[2-4]。
目前,國內外已有許多學者將振動信號的特征提取與時序預測相結合,并在軸承剩余壽命預測中取得了較好的效果。韓林潔等利用一維卷積神經網絡自動提取特征,證明了該方法可以有效地應用于滾動軸承剩余使用壽命預測[5]。Liu 等將一維時域信號作為輸入,先進行故障診斷再進行壽命預測[6]。全航等將二維卷積網絡提取一維振動信號的特征作為模型的輸入進行剩余使用壽命預測[7]。
該文基于PSO 優化VMD 的BiLSTM 的模型,采用VMD 對軸承的橫向振動信號進行分解,利用PSO對VMD 進行優化,解決VMD 中需要手動選取懲罰因子α及模態分量數目K的問題。利用BiLSTM 可以充分利用過去的時間序列信息對未來的信息進行預測的特點;該文以XJTU-SY 軸承數據集為例,驗證該文模型的有效性。
1 基礎理論
1.1 LSTM基礎理論
LSTM 是Hochreiter 在循環神經網絡的基礎上改進而來的網絡模型,是一種相對于循環神經網絡具有更加復雜神經元的網絡[8]。長短時記憶網絡的內部結構如圖1 所示。
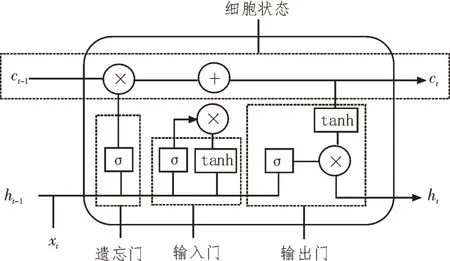
圖1 LSTM結構
由圖1 可知,LSTM 網絡相對于循環神經網絡,增加了遺忘門、輸入門以及輸出門三種門結構和細胞狀態[9]。
遺忘門決定遺忘信息的比例,xt為直接輸入;ht-1表示上一個時間點的輸出;σ為sigmoid 函數。
細胞狀態中保存了輸入門篩選后的信息,ct表示新的細胞狀態;tanh 為雙曲正切函數。輸出門決定了當前輸出的信息。
1.2 BiLSTM 基礎理論
BiLSTM 是LSTM 的一種擴展。BiLSTM 是由前、后向LSTM 組合而成,BiLSTM 的預測結果比LSTM的預測結果更優[10]。雙向長短時記憶網絡結構如圖2 所示。
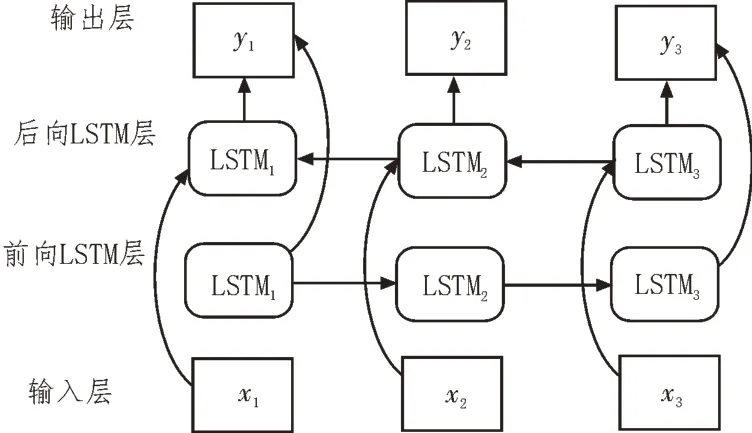
圖2 BiLSTM結構
如圖2 所示,BiLSTM 能夠同時利用前后兩個方向的LSTM 處理時間序列,兩個方向都具有獨立的隱藏層,可以提高網絡的預測性能[11]。
1.3 VMD算法基本原理
VMD 是時頻分析方法之一,其分解過程本質上是對變分問題的求解過程,是基于HilBert 變換與外差調節等理論的分解方法[12]。
1.4 PSO原理
PSO 是一種并行優化的方法,不需要梯度信息,方便實現,其基本原理是,每一粒子都能通過不斷地更新自己的速度與位置找到它們的局部極值和整體極值,從而達到最優的全局尋優[13]。
2 預測模型
2.1 模型搭建
搭建基于PSO 優化VMD 的BiLSTM 壽命預測模型,通過PSO 算法對VMD 進行優化,解決了影響VMD 分解精度的兩個重要參數需要人為設定的問題,提取出更加準確的壽命變化的特征。BiLSTM 能同時學習過去與未來狀態對當前狀態的作用,極大地提高了模型對前后依賴關系時序數據的學習能力。BiLSTM 網絡能同時了解當前狀態和過去狀態對當前狀態的影響,可以獨立地將時間序列數據進行前向后向兩個層次的處理,并將兩個階段的處理結果同時反饋到輸出層。其流程圖如圖3 所示,具體操作如下:
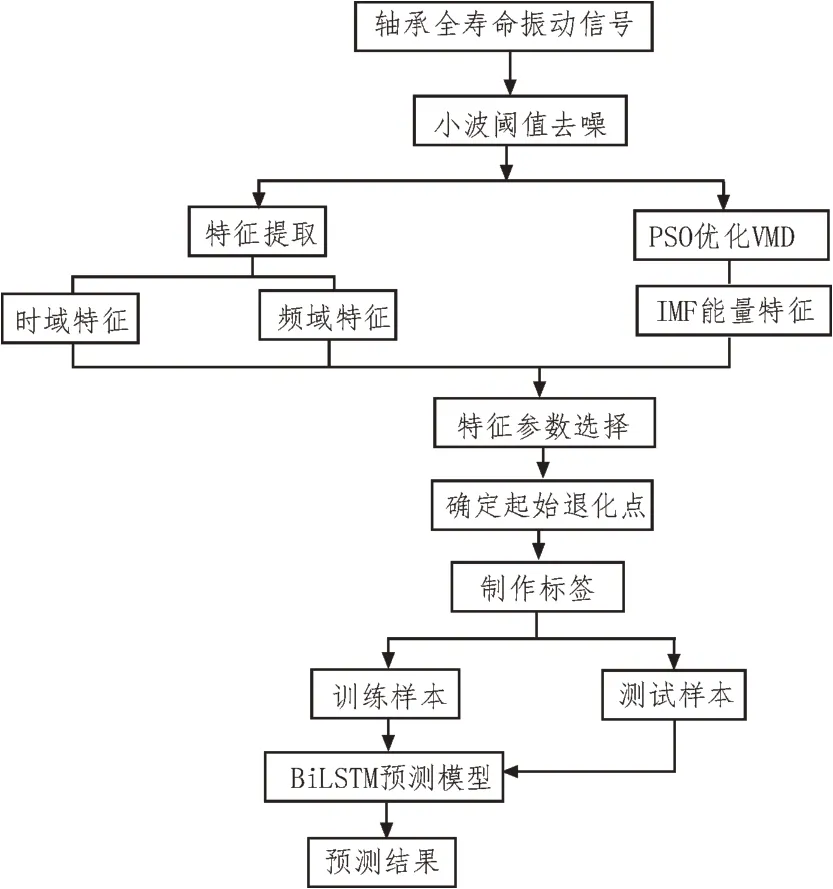
圖3 PSO優化VMD的BiLSTM流程圖
1)信號預處理。利用小波降噪進行降噪處理。
2)特征提取。提取時域、頻域以及IMF 特征。
3)選取特征參數。根據特征參數的單調性選取能夠表征軸承退化狀態的特征,構建退化特征參數集作為后續模型訓練的特征輸入。
4)確定起始退化點。根據選取的特征判斷起始退化點,并制作標簽。
5)訓練階段。根據BiLSTM 結構獨特的特點,對選擇的特征進行訓練,建立預測模型。
6)測試階段。使用預測模型對已經劃分好的測試數據進行測試。
2.2 性能度量
3 實驗驗證
為了驗證該文模型可以有效應用于滾動軸承剩余壽命預測,采用XJTU-SY 軸承數據集進行實驗。
在驗證過程中,選用第一種工況的第一組數據集,該數據集共有123 個樣本,每個樣本中橫向和縱向振動信號數據,試驗過程中的作用力為徑向力,橫向的振動信號相比縱向的振動信號更能反映滾動軸承的退化程度[14]。所以該文將所有樣本的橫向振動信號作為研究對象,首先將數據長度設置為4 096 個,將123 個樣本劃分為984 組,計算每一組樣本數據的時域、頻域特征共14 種,作為振動信號特征提取后的特征數據集。
懲罰因子α和模態分量個數K對VMD 分解效果有較大影響[15-16]。在常規的VMD 分解中,僅考慮參數K對VMD 分解的影響,不能獲得比較好的結果。該文利用PSO 優化的方法可以一起尋找參數α和K的最優解。
3.1 特征提取
3.1.1 提取時域特征
時域特征可以直接體現滾動軸承的當前運行狀態,該文通過時域分析提取了10 個常見的時域特征,分別是均值、均方根、標準差、偏度、峭度、峰值指標、脈沖指標、裕度指標、偏斜度指標方差。
3.1.2 提取頻域特征
頻域可以表示信號的功率,頻域發生明顯變化時,說明滾動軸承出現問題,為了判斷滾動軸承的退化程度,使用提取頻域特征的方法。該文提取了四個常見的頻域特征,分別是平均頻率、中心頻率、頻率標準差、頻率均方根。
3.1.3 IMF能量特征提取
懲罰因子α和模態分量個數K是影響VMD 分解精度的兩個主要參數。利用PSO 的優化方法來實現VMD 的參數α和K一起尋優。
設定種群規模L=10;學習因子s1=2,s2=2;慣性權重w=1;Xmax=Vmax=1,以包絡熵作為適應度函數。PSO 優化參數K、α的步驟如下:
1)算法所需的參數由經驗確定,人工選取優化過程的適應性函數,也就是包絡熵值函數。
2)粒子的位置是[K,α]組合,并將其視為每一個粒子的運動速率。
3)計算適應度,選擇合適的極值。
4)比較適應度值的大小,并持續更新極值。
5)不斷更新粒子的頻域和頻率。
6)循環迭代,如果沒有達到最優的結果,則返回步驟3),迭代完成后,得到優化結果中各參數的值。
通過PSO 算法求得在K=4,α=2 800 時VMD 表現最優,然后進行VMD 分解,提取4 個IMF 能量。
3.2 特征篩選
該文選取均方根、方差、標準差、平均頻率、中心頻率、頻率標準差、頻率均方根、IMF1 和IMF3 來構建退化特征參數集。
3.3 選擇預測起點
滾動軸承的使用壽命較長,選擇合適的預測起點可以起到縮小誤差和縮短預測時間的效果。
用3.2 節選取的9 個特征來表示軸承的退化狀態,并通過這個來確定軸承退化模型的開始預測點。選擇的特征在整個生命周期早期比較穩定,后期波動比較大,說明該階段軸承出現了故障。將篩選的9 個特征進行融合,確定起始退化點為第615 組數據處,將其作為BiLSTM 模型的開始預測點。從615組數據開始訓練,將615~885 作為訓練集,885~984作為測試集。
3.4 定義網絡訓練標簽
把軸承起始時刻作為預測起點,將3.3 節選取的預測起點到軸承完全失效的時間作為軸承剩余壽命,把剩余壽命歸一化到(0,1)之間作為BiLSTM 網絡的訓練標簽。
3.5 基于BiLSTM的RUL預測
采用3.3 節劃分好的訓練數據集對模型進行訓練,測試集數據作為預測實際輸入,輸入到訓練后的BiLSTM 中,預測結果如圖4 所示。
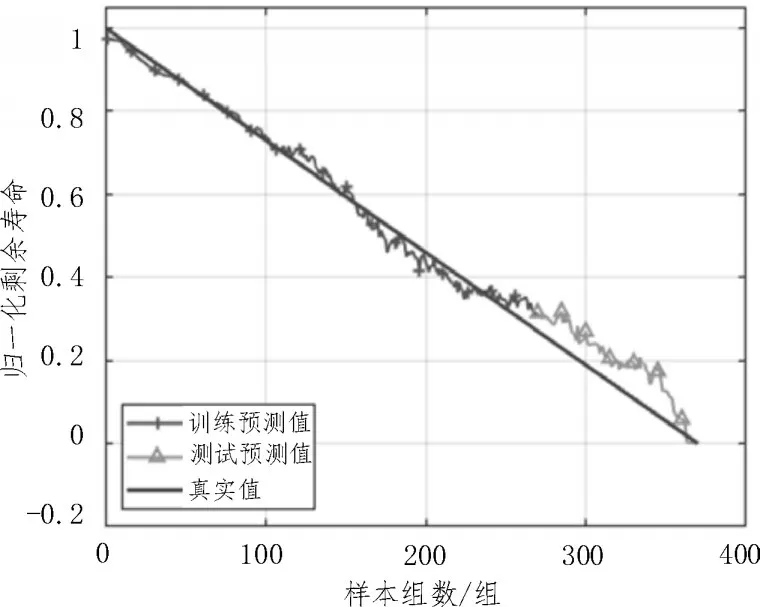
圖4 PSO-VMD的BiLSTM預測結果
3.6 對比分析
為了驗證BiLSTM 可以將滾動軸承的歷史退化特征充分利用,將PSO-VMD-DBN、PSO-VMD-LSTM、PSO-VMD-RNN 以及無PSO-VMD 的BiLSTM 作對比,四種模型的預測結果如圖5 所示。
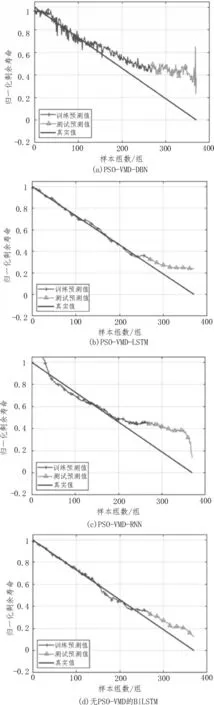
圖5 不同模型預測結果對比
通過五種模型的預測結果對比,計算其三種誤差如表1 所示。
由 圖5 可 知,PSO 優 化VMD 的DBN、RNN、LSTM 以及無PSO 優化VMD 的BiLSTM 模型在軸承后期與真實值出現了較大的偏差,PSO 優化后的VMD 的BiLSTM 模型與這四種模型相比有較好的擬合性。
由表1 可知,PSO 優化VMD 的DBN、RNN、LSTM以及無PSO 優化VMD 的BiLSTM 模型的三種誤差均大于PSO 優化VMD 的BiLSTM 模型,該文方法能較精確地對滾動軸承剩余使用壽命進行預測。
4 結論
該文采用一種基于PSO 優化VMD 的BiLSTM滾動軸承剩余使用壽命預測的模型,得到以下結論:1)利用選取的軸承全壽命周期內9 個特征的趨勢圖,選擇合適的預測起始點,提高了預測的準確性、減少了預測時間。2)PSO 優化后的VMD,解決了VMD 中需要手動選取懲罰因子α及模態分量數目K的問題,提取出更為準確的壽命特征,將提取到的時域、頻域特征與VMD 提取到的特征相結合,BiLSTM 可以較好地利用時間序列信息的特點,能更加準確地預測剩余壽命。3)經過對比發現,基于PSO優化VMD 的BiLSTM 預測方法的誤差均小于其他四種方法。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
