激光誘導擊穿光譜對U的定量分析
2024-01-13 13:57:04舒開強許應銅高智星樊慶文段憶翔林慶宇
中國無機分析化學 2024年2期
舒開強 許應銅 高智星 樊慶文 段憶翔* 林慶宇*
(1.四川大學 機械工程學院,成都 610065;2.中國原子能科學研究院 核物理所,北京 102413)
核電是一種清潔、高效的能源,使用核電可以減少對化石燃料的依賴,有利于改善環境污染狀況以及早日實現碳達峰、碳中和。鈾是核能發電的主要燃料,預計在2021年至2030年期間全球對鈾資源的需求將增長27%[1]。鈾資源主要來源于鈾礦冶煉,因此,鈾礦的準確勘探和成分快速檢測對鈾資源的供給意義重大[2]。為實現鈾礦的快速檢測,核領域迫切需要一種樣品制備簡單、操作安全、檢測快速且準確的分析技術,以達到快速完成勘探優質礦產資源的目的。
傳統元素分析方法主要有滴定法、分光光度法、電感耦合等離子體質譜法、X射線熒光光譜法等,它們大多需要復雜樣品制備過程,對檢測環境有較高要求,檢測耗時較長,傳統分析方法更勝任實驗室精準分析場景,對目標元素的現場快速檢測能力略顯不足[3]。激光誘導擊穿光譜(Laser-induced breakdown spectroscopy,簡稱LIBS)是一種基于激光等離子體的原子發射光譜技術,具有樣品制備簡單、分析速度快[4]、多元素同時檢測[5]、遠程分析[6]等突出優點,廣泛應用于材料科學、生命科學、地質學、生物醫學等諸多科學領域[7-9]。LIBS探測鈾的可行性于1987年由 WACHTER等[10]首次進行了報道,當前LIBS在核工業中已被用于核材料檢測(如礦石、氧化鈾、裂變產物等)[11]、同位素分析[12]、鋼及合金分析[13]、核聚變設施檢測[14]等方面。近年來,極限學習機、人工神經網絡、支持向量機、隨機森林等機器學習算法被用于LIBS定性和定量分析,在諸多場景都展現出了良好的效果[15]。
本工作以自行搭建的LIBS系統為實驗平臺,結合機器學習對鈾礦中U進行了定量分析。采用偏最小二乘(Partial least squares,PLS)和隨機森林(Random forest,RF)算法優化建立定量模型,通過綜合對比兩種模型在鈾礦中對U的定量效果,建立并優化適合U定量分析的機器學習算法,以期望達到快速、準確定量目的。本工作的數據處理和模型構建均基于Python(3.8.8版)的Scikit-learn(1.2.2版)機器學習模塊完成。
1 實驗部分
1.1 儀器與材料
LIBS系統采用Nd:YAG激光器(Litron lasers,Nano100,UK)作為激發源,激光波長1 064 nm、脈沖寬度6 ns、脈沖頻率10 Hz。光譜儀采用中階梯光譜儀(Aryelle 200,Lasertechnik Berlin GmbH,Germany),光譜范圍194 ~ 840 nm,分辨率為λ/Δλ= 9000,配備ICCD相機(iStar DH334T,Andor,UK)。激光束經10倍聚焦物鏡聚焦到樣品表面,等離子體光譜由準直透鏡和光纖傳輸到光譜儀。在采集光譜數據時,將光譜儀延遲時間設置為2.0 μs,激光能量為100 mJ。
鈾礦粉末標準樣品,編號分別為GBW04101、GBW04103及GBW04104,來自核工業部北京第五研究所(中國北京)與湖南鈾廠(中國衡陽)。實驗樣本由粉末標樣按一定比例配制,再經壓片機16 MPa壓強壓制成直徑為20 mm的片狀樣本,一共壓制12組實驗樣本,標號為1#~12#,樣本中U質量百分數如表1所示。光譜采集過程中,為減小激光脈沖能量波動的影響,每一個光譜由脈沖激光燒蝕樣本200次,每個樣本采集15個光譜。
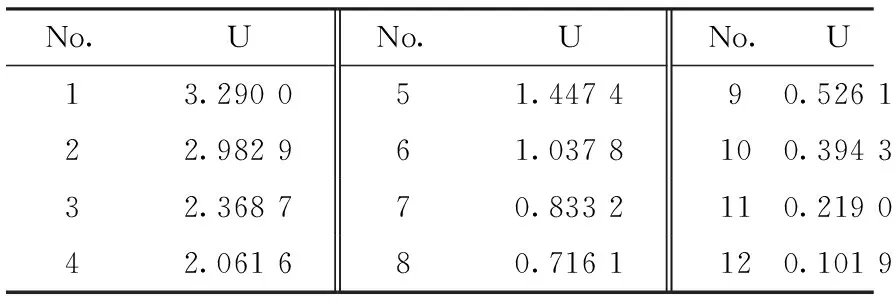
表1 樣本中鈾元素質量百分比Table 1 Mass percentage of U in the sample /%
1.2 算法與指標
PLS算法結合了主成分分析、典型相關分析和多元線性回歸分析的優點,能夠有效克服多重共線性問題。RF是集成學習算法的典型代表,在分類和回歸問題上都有較好表現。本工作在構建鈾礦中U的LIBS定量模型時,首先對PLS和RF兩種機器學習算法的超參數進行優化,再用合適的超參數建立PLS模型和RF模型。
模型的定量效果用預測決定系數(The coefficient of determination,R2)、預測均方根誤差(Root mean square error of prediction,RMSEP)、相對偏差(Relative standard deviation,RSD)和相對誤差(Relative error,RE)等作為評判指標[16],評估出適用于鈾礦中鈾元素的定量模型,以到達快速、準確定量目的。
2 結果與討論
采用PLS和RF兩種算法構建定量模型時,將表1中3#、6#及9#三個樣本設為驗證集,不參與模型的訓練,只用于驗證兩個模型的定量效果;其余所有樣本設為訓練集,主要被用于兩種算法的超參數優化以及定量模型訓練。在前期對鈾的定量研究中[17],構建定量模型時采用全部光譜數據作為輸入特征矩陣,數據維度龐大,致使參數優化耗時較久,因此,本工作選用波長350 ~ 450 nm的光譜數據作為輸入特征矩陣,共7 427個特征值,極大降低了輸入數據維度的同時,充分保留U的特征峰,對U進行定量分析具有較好的代表性,該波段內的光譜如圖1所示。
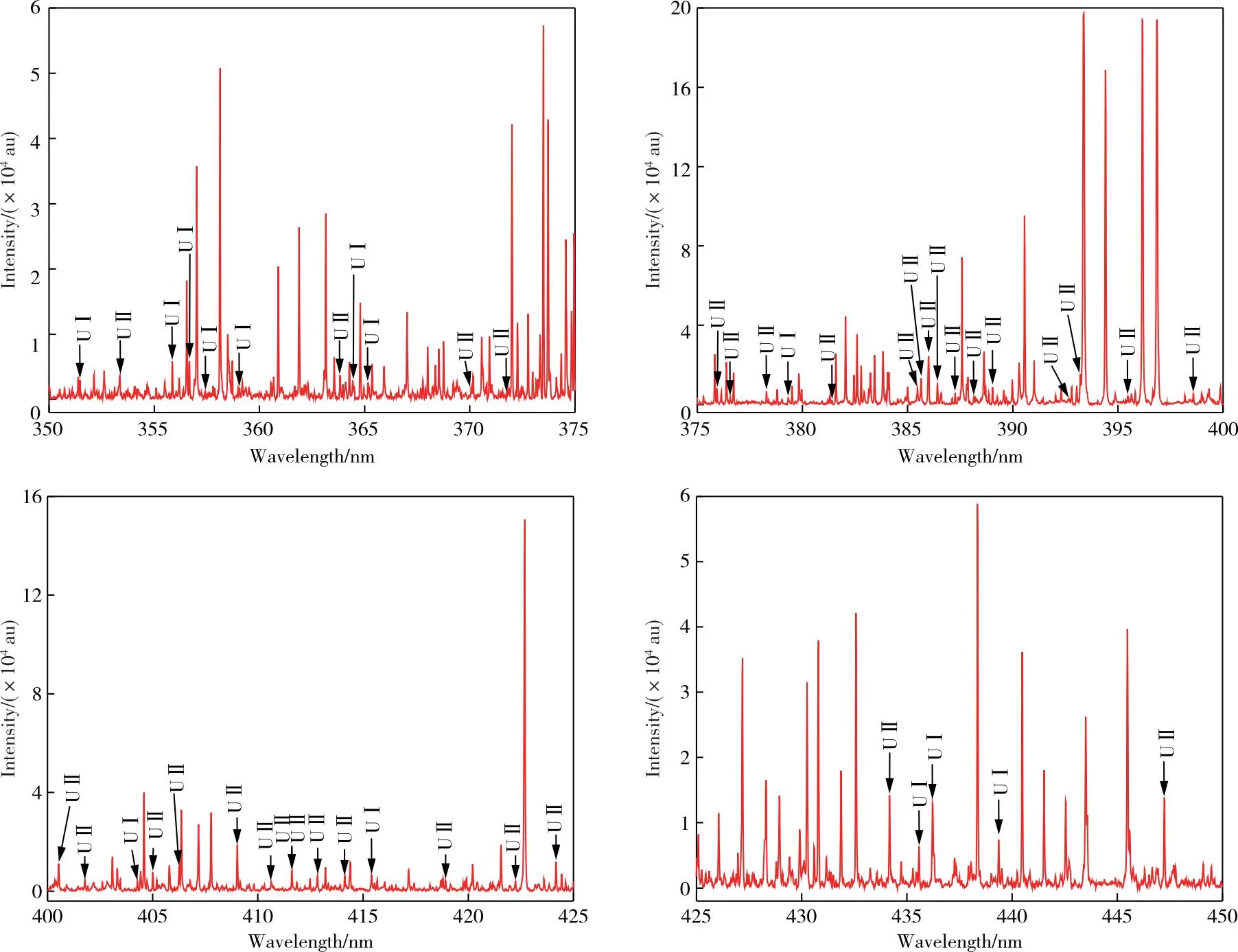
圖1 波長350 ~ 450 nm的U特征光譜圖Figure 1 Spectral diagram in the wavelength 350—450 nm.
主成分數是影響PLS模型定量效果的關鍵因素,過多或過少的主成分數都會影響定量準確度;而影響RF模型定量結果的主要超參數則是模型中樹的數量,恰當數量的樹可以提升模型定量準確度。在參數優化過程中,采用10折交叉驗證方法,以交叉驗證均方根誤差(Root mean square error of cross validation,RMSECV)為評估指標,最終選擇RMSECV最小時所對應超參數作為模型參數。RMSECV表達式如下:
(1)
(2)
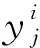
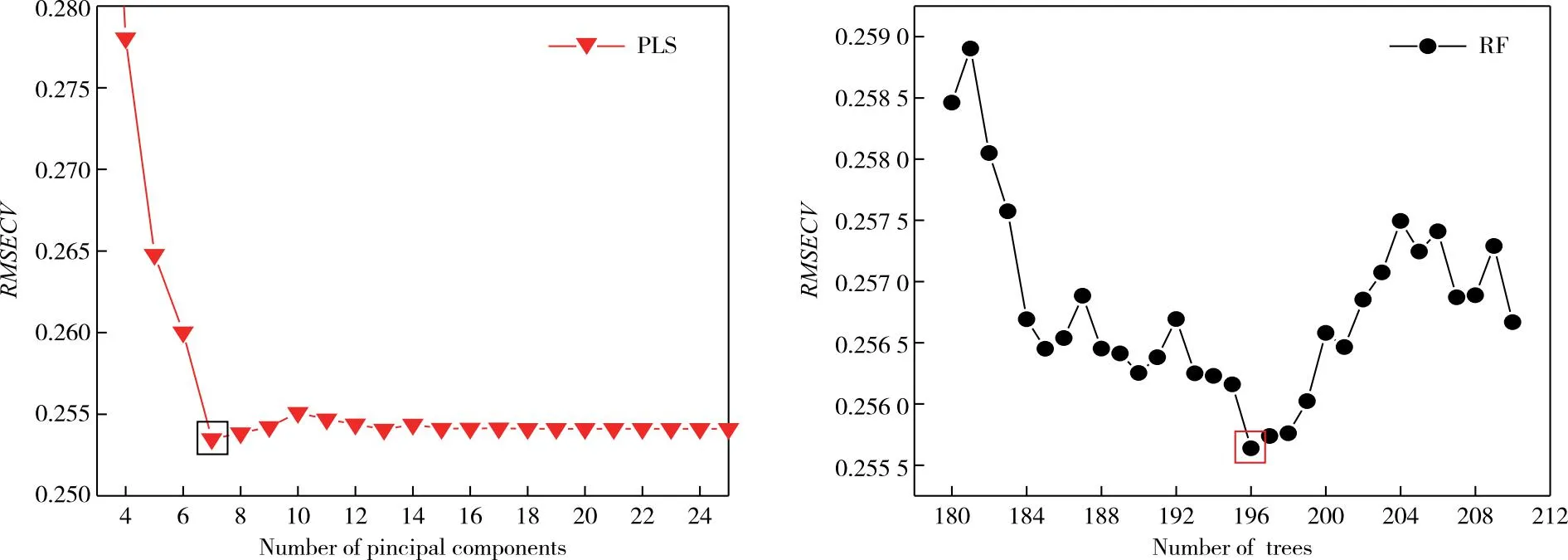
圖2 基于交叉驗證均方根誤差的偏最小二乘和隨機森林模型參數優化Figure 2 Parameter optimization of PLS and RF based on cross-validation RMSECV.
基于PLS和RF兩種機器學習算法的超參數優化結果,構建U的LIBS定量模型,模型校準曲線如圖3所示。PLS模型和RF模型的線性相關系數分別達到了0.997和0.996,展現出兩種定量模型均具有較好的線性相關性。圖3的誤差棒結果顯示,訓練集預測值的RSD均較小,表明兩個模型均具有良好的模型穩定性。
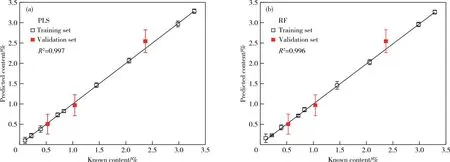
圖3 U元素預測含量與真實含量的定標曲線圖Figure 3 Calibration curves of predicted and true content of U.
使用三個驗證集數據對PLS模型和RF模型的定量效果進行驗證,結果如表2所示。對于三個驗證集,兩種模型計算出的RMSEP都較高,表明兩種模型對驗證集中U的15次預測含量與真實含量之間具有一定的偏差;三個驗證集RMSEP指標方面,RF模型在低含量時表現稍好,RMSEP為24.76%,PLS模型則是在中高含量時表現稍強,RMSEP分別為26.76%和33.05%。此外,驗證集預測含量值的RSD整體稍高,表明同一個驗證集的15次預測含量值比較分散,這種結果是由于LIBS采集到的光譜數據本身就具有較大波動性造成的,這也是LIBS仍需攻克的難題之一。在定量準確度方面,PLS模型對三個驗證集的RE分別是4.33%、6.63%和6.85%,RF模型的RE分別為22.33%、12.79%和12.04%,驗證結果表明PLS模型對驗證集15次預測含量的平均值與真實值更為接近,定量準確度更高。另一方面,超參數優化過程中,RF模型所消耗的時間遠多于PLS模型,這主要是因為兩種定量算法本身復雜度不同而造成的。

表2 PLS和RF定量模型驗證結果Table 2 Results of PLS and RF quantitative model validation
綜合對比PLS模型和RF模型,發現兩種模型都具有較好的穩定性,在驗證集定量準確度方面,PLS模型效果更好,并且PLS模型的超參數優化過程更快速,因此,在本研究中PLS模型更適合用于鈾礦中U的現場快速定量分析。
3 結論
本工作結合機器學習開展了鈾礦中U的LIBS定量分析方法研究,對比了PLS和RF兩種算法對U的定量效果。結果顯示,PLS模型比RF模型獲得了更好的定量準確度,同時PLS算法的檢測速率更快,因此,PLS比RF更適合在鈾礦中U的LIBS定量分析。本工作為后續研發鈾礦中U的LIBS現場分析儀器奠定了理論基礎,后續將面向不同鈾礦基質,開展復雜基質中如何提高LIBS信號穩定性和定量準確度的相關研究工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
