微表情面部肌電跨模態(tài)分析及標(biāo)注算法
2024-01-09 09:28:21王甦菁王儼李婧婷東子朝張建行劉燁
心理科學(xué)進(jìn)展 2024年1期
王甦菁 王儼 李婧婷 東子朝 張建行 劉燁
摘 ?要??長(zhǎng)久以來(lái), 微表情的小樣本問(wèn)題始終制約著微表情分析的發(fā)展, 而小樣本問(wèn)題歸根到底是因?yàn)槲⒈砬榈臄?shù)據(jù)標(biāo)注十分困難。本研究希望借助面部肌電作為技術(shù)手段, 從微表情數(shù)據(jù)自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注和無(wú)標(biāo)注三個(gè)方面各提出一套解決方案。對(duì)于自動(dòng)標(biāo)注, 提出基于面部遠(yuǎn)端肌電的微表情自動(dòng)標(biāo)注方案; 對(duì)于半自動(dòng)標(biāo)注, 提出基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注; 對(duì)于無(wú)標(biāo)注, 提出了基于肌電信號(hào)的跨模態(tài)自監(jiān)督學(xué)習(xí)算法。同時(shí), 本研究還希望借助肌電模態(tài), 對(duì)微表情的呈現(xiàn)時(shí)間和幅度等機(jī)理特征進(jìn)行拓展研究。
關(guān)鍵詞??圖像標(biāo)注, 微表情分析, 遠(yuǎn)端面部肌電, 微表情數(shù)據(jù)標(biāo)注
分類號(hào)??B841
1??問(wèn)題提出
正如俗語(yǔ)“知人知面不知心”所說(shuō), 要洞察他人的心理狀態(tài)是十分困難的。隨著深度學(xué)習(xí)技術(shù)的發(fā)展, 人臉識(shí)別技術(shù)的性能得到了顯著提升, 其準(zhǔn)確率已經(jīng)超過(guò)了人類的能力。除了人的身份識(shí)別之外, 通過(guò)面部的微表情分析他人的心理狀態(tài)的研究在近些年正在興起, 并且具有很高的挑戰(zhàn)性。微表情可以被廣泛地應(yīng)用于國(guó)家安全、公安審訊、心理疾病預(yù)診、學(xué)校教育、衛(wèi)生防疫等領(lǐng)域。
微表情產(chǎn)生機(jī)理可以追述到1872年查爾斯·達(dá)爾文(Charles Darwin)在他的著作《人與動(dòng)物的情感表達(dá)》(Darwin, 1872)中指出, 一些面部表情是無(wú)法抑制的, 即便有極大的主觀努力也無(wú)法做到完全抑制。后來(lái)神經(jīng)心理學(xué)研究發(fā)現(xiàn), 自主和非自主表情受兩種不同的神經(jīng)通路控制。同時(shí), 心理學(xué)家Paul Ekman (Ekman & Friesen, 1969)也假設(shè)微表情是自主表情與非自主表情之間對(duì)抗的產(chǎn)物(Rinn, 1984)。它可能是表達(dá)情緒之前的自主抑制過(guò)程中的泄漏, 或者是在表情呈現(xiàn)后的截?cái)唷R虼耍?從理論上講, 微表情(Micro-expression)是一種短暫、微小且局部的面部表情, 通常會(huì)在強(qiáng)烈的情緒體驗(yàn)下出現(xiàn)(Yan et al., 2013)。這使得微表情具備出現(xiàn)時(shí)間短、運(yùn)動(dòng)幅度小和不對(duì)稱性的三個(gè)特征。
當(dāng)前標(biāo)注微表情的時(shí)間成本和人力成本都非常高, 并且需要編碼人員接受面部動(dòng)作編碼系統(tǒng)(Facial Action Coding System, FACS)的專業(yè)知識(shí)訓(xùn)練。該面部動(dòng)作的編碼系統(tǒng)由Paul Ekman制定, 基于解剖學(xué)相關(guān)知識(shí)對(duì)面部運(yùn)動(dòng)進(jìn)行分析, 可用于描述任意面部運(yùn)動(dòng)并定位其動(dòng)作單元, 是當(dāng)前最為常用的面部編碼系統(tǒng)。為了提高人們檢測(cè)和識(shí)別微表情的效率, Paul Ekman還在2002年開(kāi)發(fā)了一個(gè)微表情訓(xùn)練工具(Micro-Expression Training Tool, METT) (Ekman, 2004)。然而, 即使是經(jīng)過(guò)專業(yè)培訓(xùn)的專家, 其在識(shí)別微表情方面的人工準(zhǔn)確率也不到50%。因此, 為了在實(shí)際場(chǎng)景中充分發(fā)揮微表情的潛在應(yīng)用價(jià)值, 當(dāng)前迫切需要進(jìn)行智能微表情分析的研究。
對(duì)于微表情分析算法來(lái)說(shuō), 需要大量的、有標(biāo)注的微表情數(shù)據(jù)來(lái)訓(xùn)練模型。而對(duì)微表情數(shù)據(jù)進(jìn)行標(biāo)注, 不僅需要專業(yè)知識(shí), 而且耗時(shí)耗力, 這導(dǎo)致的小樣本問(wèn)題一直束縛著微表情分析的快速發(fā)展。提高微表情數(shù)據(jù)標(biāo)注的效率已經(jīng)成為微表情分析領(lǐng)域中迫切的需求。本研究通過(guò)計(jì)算機(jī)和心理學(xué)的交叉研究, 基于面部肌電生理信號(hào)和面部表情視覺(jué)信號(hào)進(jìn)行跨模態(tài)分析, 從自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注和無(wú)標(biāo)注三個(gè)方面, 來(lái)提高微表情數(shù)據(jù)標(biāo)注的效率。
2??研究現(xiàn)狀
2.1??國(guó)內(nèi)外微表情智能化分析研究現(xiàn)狀及發(fā)展動(dòng)態(tài)分析
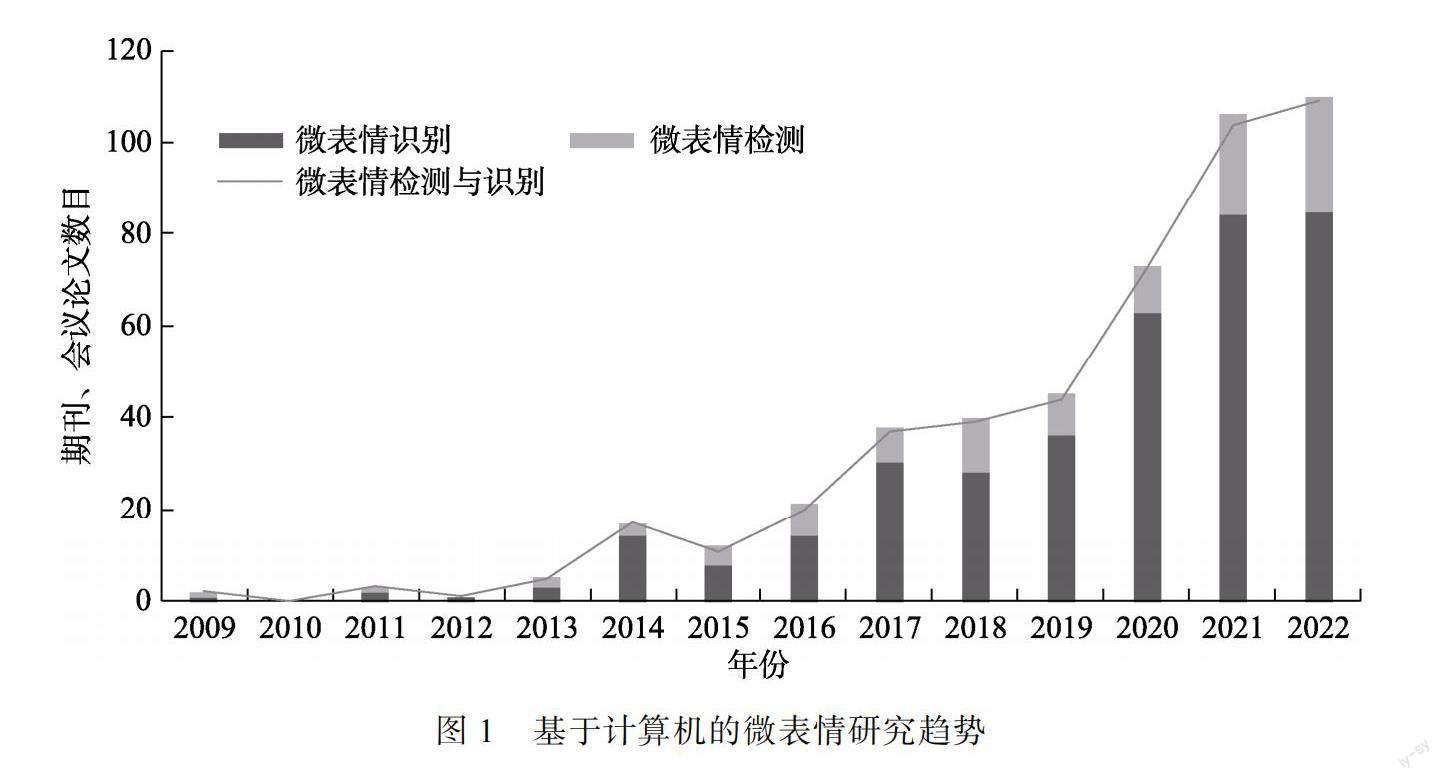
近10年來(lái), 除了在大眾媒體領(lǐng)域獲得關(guān)注, 微表情研究也逐漸受到科學(xué)領(lǐng)域的重視。如圖1所示, 通過(guò)計(jì)算機(jī)科學(xué)與心理學(xué)的結(jié)合, 學(xué)者們不斷研發(fā)智能微表情分析技術(shù), 從而幫助人們更有效地通過(guò)微表情來(lái)識(shí)別其中的隱藏情緒。
然而, 由于微表情樣本的人工標(biāo)注十分費(fèi)時(shí)費(fèi)力, 目前常用的自發(fā)微表情數(shù)據(jù)庫(kù)只有7個(gè), 分別是中國(guó)科學(xué)院心理研究所發(fā)布的CASME系列(Li, Dong, et al., 2022; Qu et al., 2018; Yan et al., 2014; Yan et al., 2013, April), 芬蘭奧盧大學(xué)發(fā)布的SMIC (Li et al., 2013, April)以及最新的4DME (Li, Cheng, et al., 2022), 英國(guó)曼徹斯特城市大學(xué)發(fā)布的SAMM (Davison et al., 2018)和山東大學(xué)發(fā)布的MMEW (Ben et al., 2021), 總樣本量超過(guò)2600個(gè)。然而, 目前大數(shù)據(jù)驅(qū)動(dòng)的深度學(xué)習(xí)在許多領(lǐng)域被廣泛使用, 但是基于深度學(xué)習(xí)的微表情分析卻受限于微表情小樣本問(wèn)題, 相關(guān)算法/應(yīng)用的性能的提升十分有限。
因此, 本研究針對(duì)微表情數(shù)據(jù)標(biāo)注問(wèn)題, 分別從自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注和無(wú)標(biāo)注三方面來(lái)解決這一問(wèn)題。本節(jié)將首先介紹微表情檢測(cè)與識(shí)別的相關(guān)方法的研究現(xiàn)狀, 然后對(duì)微表情標(biāo)注的困難進(jìn)行分析, 最后對(duì)本研究中應(yīng)用到的技術(shù)理論和方法的國(guó)內(nèi)外研究現(xiàn)狀進(jìn)行綜述。
2.1.1??微表情分析的研究現(xiàn)狀
微表情分析一般包括微表情檢測(cè)和微表情識(shí)別兩部分, 也就是對(duì)微表情數(shù)據(jù)的標(biāo)注與分析。微表情檢測(cè)是在長(zhǎng)視頻中準(zhǔn)確定位微小短暫的微表情片段。微表情識(shí)別是指根據(jù)特定的情緒類別, 對(duì)微表情片段進(jìn)行分類。無(wú)論是微表情檢測(cè), 還是微表情識(shí)別都離不開(kāi)大量的、有標(biāo)注的數(shù)據(jù)。微表情檢測(cè)方法的研究主要的兩個(gè)思路是比較視頻幀的特征差和機(jī)器學(xué)習(xí)對(duì)表情幀分類。
基于特征差的微表情檢測(cè)方法在早期的研究中占據(jù)主流, 該方法通常通過(guò)滑動(dòng)窗口劃分長(zhǎng)視頻, 然后在整個(gè)視頻中設(shè)定合適的閾值, 從而檢測(cè)出較為明顯的面部運(yùn)動(dòng)。當(dāng)前常用的特征包括:芬蘭奧盧大學(xué)趙國(guó)英團(tuán)隊(duì)提出的時(shí)空局部二值模式(LBP?TOP) (Moilanen et al., 2014, August)、馬來(lái)西亞多媒體大學(xué)的梁詩(shī)婷團(tuán)隊(duì)提出的使用光流以及光應(yīng)變的特征(Liong et al., 2016, November)、筆者使用的主方向最大光流特征(MDMO) (Wang et al., 2017)、英國(guó)曼徹斯特城市大學(xué)Moi Hoon Yap團(tuán)隊(duì)使用的3D?HOG (Davison et al., 2018, May)等。基于特征差的微表情檢測(cè)方法可以在微表情持續(xù)時(shí)間的時(shí)間窗口內(nèi)對(duì)幀特征進(jìn)行比較, 但特征差異方法并不具備區(qū)分微表情和其他頭部動(dòng)作的能力。這就導(dǎo)致在較為復(fù)雜的長(zhǎng)視頻中,?基于特征差的檢測(cè)方法會(huì)檢測(cè)到許多宏表情或頭動(dòng)等高于閾值的面部動(dòng)作, 最終誤檢率較高。
為了提升檢測(cè)方法區(qū)分微表情與其他面部動(dòng)作的能力, 基于機(jī)器學(xué)習(xí)/深度學(xué)習(xí)的微表情檢測(cè)方法逐漸得到了研究人員的關(guān)注。剛剛興起的深度學(xué)習(xí)的微表情檢測(cè)方法目前只有20余篇相關(guān)論文發(fā)表。例如本文作者在2021年提出的長(zhǎng)視頻中多尺度檢測(cè)微表情片段的神經(jīng)網(wǎng)絡(luò)(MESNet) (Wang et al., 2021)、電子科技大學(xué)李永杰團(tuán)隊(duì)提出的雙流卷積神經(jīng)網(wǎng)絡(luò)(Yu et al., 2021, October)、北京科技大學(xué)謝倫團(tuán)隊(duì)提出的時(shí)空卷積注意力神經(jīng)網(wǎng)絡(luò)(Pan et al., 2021, October)、中國(guó)電子科技集團(tuán)電子科學(xué)研究院謝海永團(tuán)隊(duì)構(gòu)建的基于光流的LSTM網(wǎng)絡(luò)(Ding et al., 2019, September)以及KDDI綜合研究所楊博等人提出的基于面部動(dòng)作單元(Action Unit, AU)的微表情檢測(cè)神經(jīng)網(wǎng)絡(luò)(Yang et al., 2021, October)等。但當(dāng)前基于機(jī)器學(xué)習(xí)/深度學(xué)習(xí)的微表情檢測(cè)方法仍面臨著小樣本的限制, 導(dǎo)致近年來(lái)該方法的性能提升并不顯著, 而難以運(yùn)用到實(shí)際場(chǎng)景中。
同時(shí), 結(jié)合深度學(xué)習(xí)的微表情識(shí)別技術(shù)已經(jīng)成為了主要趨勢(shì), 并且識(shí)別率在不斷提升, 開(kāi)始有研究團(tuán)隊(duì)通過(guò)引入遷移學(xué)習(xí)的方法來(lái)增強(qiáng)神經(jīng)網(wǎng)絡(luò)提取微表情下特征的性能, 這在一定程度上解決了微表情小樣本問(wèn)題對(duì)深度學(xué)習(xí)微表情識(shí)別的限制。例如, 本文作者通過(guò)遷移長(zhǎng)期卷積神經(jīng)網(wǎng)絡(luò)來(lái)解決微表情的小樣本問(wèn)題(Wang et al., 2018)、中國(guó)科學(xué)技術(shù)大學(xué)陳恩紅團(tuán)隊(duì)將宏表情訓(xùn)練得來(lái)的網(wǎng)絡(luò)用于微表情的識(shí)別任務(wù), 也提升了神經(jīng)網(wǎng)絡(luò)的識(shí)別性能(Xia et al., 2020, October)。北京師范大學(xué)孫波等人提出的從AU中提煉和轉(zhuǎn)移多只是用于微表情識(shí)別的知識(shí)遷移技術(shù)(Sun et al., 2020; Xia et al., 2020, October)。然而, 引入遷移學(xué)習(xí)的方法也只能對(duì)微表情的識(shí)別性能做到一定程度的提升, 并不能從根本上解決微表情小樣本問(wèn)題的限制。若要將微表情檢測(cè)與識(shí)別的性能進(jìn)一步突破, 還是需要大量的微表情樣本以供訓(xùn)練, 足見(jiàn)該研究方向?qū)鉀Q微表情數(shù)據(jù)標(biāo)注難題的迫切期望。
2.1.2當(dāng)前微表情數(shù)據(jù)標(biāo)注面臨的困難
對(duì)于微表情數(shù)據(jù)標(biāo)注是非常費(fèi)力費(fèi)時(shí)的。由于微表情是一種短暫的、微小的、局部的面部運(yùn)動(dòng), 微表情的標(biāo)注者需要通過(guò)慢放或者回放等操作對(duì)視頻逐幀觀察并進(jìn)行標(biāo)注。特別是標(biāo)注起始幀和終止幀時(shí), 需要反復(fù)觀看相應(yīng)時(shí)間段, 同時(shí)反復(fù)對(duì)比幀與幀之間的細(xì)微變化。因?yàn)橄噍^于宏表情來(lái)說(shuō), 微表情并不明顯, 很難通過(guò)肉眼檢測(cè)到。微表情的標(biāo)注者需要經(jīng)過(guò)專業(yè)培訓(xùn)。前人的研究(Torre et al., 2011, October)中也表示對(duì)于表情樣本的起始幀和終止幀的標(biāo)注用時(shí), 會(huì)占總體用時(shí)的一半, 可見(jiàn)微表情數(shù)據(jù)標(biāo)注的困難。針對(duì)這個(gè)難題, 在本研究擬采用:
(1)使用面部肌電信號(hào), 對(duì)微表情數(shù)據(jù)進(jìn)行自動(dòng)標(biāo)注;
(2)借鑒時(shí)序動(dòng)作定位的思想, 對(duì)微表情數(shù)據(jù)和的起始幀和終止幀進(jìn)行定位, 從而實(shí)現(xiàn)對(duì)微表情數(shù)據(jù)進(jìn)行半自動(dòng)標(biāo)注;
(3)把自監(jiān)督學(xué)習(xí)引入微表情分析, 實(shí)現(xiàn)微表情分析中對(duì)無(wú)標(biāo)注的微表情數(shù)據(jù)的應(yīng)用。
下面幾節(jié), 本文分別介紹面部肌電的研究現(xiàn)狀, 時(shí)序動(dòng)作定位的研究現(xiàn)狀和自監(jiān)督學(xué)習(xí)的研究現(xiàn)狀。
2.1.3面部肌電的研究現(xiàn)狀
面部肌電的一種常見(jiàn)用途是研究由面部表情體現(xiàn)的情緒反應(yīng)。一般來(lái)說(shuō), 評(píng)估面部表情的方法可以分為兩類, 一類是人為主觀評(píng)估, 包括表情分類、表情維度評(píng)分和基于FACS系統(tǒng)的肌肉運(yùn)動(dòng)單元編碼; 另一類是客觀評(píng)估, 包括基于肌電測(cè)量的表情評(píng)估方法(Hess, 2009)。Mehrabian和Russell提出的情緒維度模型PAD對(duì)情緒從愉悅度(Pleasure)、激活度(Arousal)和優(yōu)勢(shì)度(Dominance)的三個(gè)維度描述, 并編制了PAD量表以測(cè)量情緒狀態(tài)。李曉明等人對(duì)該量表進(jìn)行了漢化, 編制了中文版PAD量表(李曉明?等, 2008)。其中愉悅度(Pleasure)也叫效價(jià)(valence), 可以通過(guò)對(duì)不同部位的面部肌電信號(hào)進(jìn)行度量, 并以此確定面部肌電數(shù)據(jù)與情緒效價(jià)、激活度以及優(yōu)勢(shì)度之間的聯(lián)系(H?fling et al., 2020)。早在2014年, Gruebler等人設(shè)計(jì)了一款可穿戴的面部肌電采集設(shè)備來(lái)通過(guò)面部肌電信號(hào)判斷正性表情(Gruebler & Suzuki, 2014)。最近, 日本京都大學(xué)的Sato等人也設(shè)計(jì)可穿戴面部肌電采集設(shè)備來(lái)測(cè)量情緒的效價(jià)(Sato et al., 2021)。與傳統(tǒng)的使用8組電極的面部肌電測(cè)量相比, Schultz等人只用4組電極(前額皺眉肌、額肌、顴骨大肌和咬肌), 而表情的識(shí)別率只減少了不到5% (Schultz & Pruzinec, 2010)。雖然識(shí)別率有所降低, 但是減少一半的電極數(shù)量, 可以讓更多的表情展示出來(lái), 這使得使用面部肌電對(duì)微表情數(shù)據(jù)進(jìn)行自動(dòng)標(biāo)注成為可能。進(jìn)而Hamedi等人(2013)通過(guò)3組電極, 分別放在額肌和顳肌上, 使用通用橢圓基函數(shù)神經(jīng)網(wǎng)絡(luò)來(lái)區(qū)分10種面部動(dòng)作, 準(zhǔn)確率達(dá)87%。這些面部動(dòng)作包括對(duì)稱或不對(duì)稱的微笑, 揚(yáng)起眉毛, 皺起眉頭等。Monica等人(Perusquía-Hernández et al., 2021, December)在電極完全不遮擋面部的情況下, 利用遠(yuǎn)端(distal)肌電信號(hào)實(shí)現(xiàn)對(duì)微笑的檢測(cè)。
2.1.4時(shí)序動(dòng)作定位的研究現(xiàn)狀
時(shí)間動(dòng)作定位(Temporal action localization, TAL)需要在視頻中檢測(cè)包含目標(biāo)動(dòng)作的時(shí)間區(qū)間。對(duì)于一個(gè)未經(jīng)修剪的長(zhǎng)視頻, 時(shí)間動(dòng)作定位主要解決兩個(gè)任務(wù), 即識(shí)別和定位。它提供了計(jì)算機(jī)視覺(jué)應(yīng)用所需的最基本信息, 即是什么動(dòng)作, 且動(dòng)作何時(shí)發(fā)生。時(shí)間動(dòng)作定位與我們的生活息息相關(guān), 在很多領(lǐng)域具有廣泛的應(yīng)用前景和社會(huì)價(jià)值, 例如視頻摘要(Lee et al., 2012, June)、公共視頻監(jiān)控(Vishwakarma & Agrawal, 2013)和技能評(píng)估(Gao et al., 2014, September)等。
2014年之前, 時(shí)間動(dòng)作定位的方法主要基于傳統(tǒng)的手工特征提取。之后, 隨著深度學(xué)習(xí)的發(fā)展, 時(shí)間動(dòng)作定位的相關(guān)研究有了顯著的進(jìn)展。目前主流的兩種方法主要是分別基于全監(jiān)督學(xué)習(xí)和弱監(jiān)督學(xué)習(xí)。基于全監(jiān)督學(xué)習(xí)的TAL主要是基于視頻級(jí)別和幀級(jí)別的標(biāo)注, 對(duì)模型進(jìn)行訓(xùn)練(Chao et al., 2018, June; Long et al., 2019, June)。與此同時(shí), 由于在實(shí)際生活中, 幀級(jí)別的標(biāo)注十分困難而且容易受到標(biāo)注者的主觀影響, 基于弱監(jiān)督學(xué)習(xí)的TAL方法逐漸受到研究者們的歡迎(Lee et al., 2020, April; Liu et al., 2019, June)
2.1.5自監(jiān)督學(xué)習(xí)的研究現(xiàn)狀
LeCun、Bengio和Hinton于2015年聯(lián)合在“Nature”雜志發(fā)表的關(guān)于深度學(xué)習(xí)的綜述文章(LeCun et al., 2015)中指出, 實(shí)現(xiàn)像人類視覺(jué)系統(tǒng)那樣的無(wú)監(jiān)督深度學(xué)習(xí)是未來(lái)的一個(gè)重要方向。其中, 自監(jiān)督學(xué)習(xí)作為無(wú)監(jiān)督學(xué)習(xí)的一種(Jing & Tian, 2020), 已經(jīng)成為一個(gè)熱門(mén)的研究方向。自監(jiān)督學(xué)習(xí)利用大量無(wú)監(jiān)督數(shù)據(jù), 通過(guò)設(shè)計(jì)輔助任務(wù)來(lái)獲取監(jiān)督信號(hào), 并用它來(lái)訓(xùn)練網(wǎng)絡(luò), 使網(wǎng)絡(luò)能夠?qū)W習(xí)到有利于下游任務(wù)的特征信息。自監(jiān)督算法相比手工構(gòu)建特征和標(biāo)注數(shù)據(jù), 能夠節(jié)省時(shí)間和人力, 提高深度學(xué)習(xí)網(wǎng)絡(luò)的效率和實(shí)用性。自監(jiān)督學(xué)習(xí)已經(jīng)在許多任務(wù)中實(shí)現(xiàn)了利用無(wú)監(jiān)督數(shù)據(jù)構(gòu)造自身監(jiān)督信息, 并取得了可以和監(jiān)督學(xué)習(xí)媲美的性能表現(xiàn)(Doersch et al., 2015; Fernando et al., 2017, July; Larsson et al., 2017, July; Li et al., 2019; Pathak et al., 2016, June)。
2.2本文貢獻(xiàn)
隨著近年來(lái)深度學(xué)習(xí)技術(shù)的發(fā)展, 很多理論研究已經(jīng)開(kāi)始落地應(yīng)用, 例如人臉識(shí)別已經(jīng)從消費(fèi)級(jí)別應(yīng)用擴(kuò)展到安全級(jí)別的應(yīng)用, 而這些應(yīng)用的背后有著大量的標(biāo)注數(shù)據(jù)作為支持。對(duì)于人臉識(shí)別的標(biāo)注, 其技術(shù)含量低, 標(biāo)注時(shí)間快, 標(biāo)注人員不需要過(guò)多的專業(yè)知識(shí)培訓(xùn)。而對(duì)于微表情數(shù)據(jù)標(biāo)注, 標(biāo)注人員需要具有FACS編碼的專業(yè)知識(shí), 同時(shí)在標(biāo)注時(shí), 標(biāo)注人員需要逐幀進(jìn)行觀察, 耗時(shí)耗力。為了解決微表情數(shù)據(jù)標(biāo)注困難這個(gè)問(wèn)題, 本研究嘗試使用自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注及無(wú)標(biāo)注的方法。
在理論方面, 本研究通過(guò)面部肌電信號(hào)對(duì)微表情的表達(dá)機(jī)理進(jìn)行進(jìn)一步的研究, 對(duì)微表情的三個(gè)特征進(jìn)行更加客觀的量化, 還為之后使用肌電和腦電之間的相關(guān)性來(lái)進(jìn)一步研究微表情的腦機(jī)制提供支持, 并有望將結(jié)果應(yīng)用在表情識(shí)別、行為識(shí)別等領(lǐng)域。同時(shí), 在實(shí)踐方面, 針對(duì)微表情數(shù)據(jù)標(biāo)注困難的問(wèn)題, 本研究從微表情數(shù)據(jù)自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注和無(wú)標(biāo)注三個(gè)方面各提出一套解決方案, 從一定程度上緩解微表情數(shù)據(jù)標(biāo)注困難。
3??研究構(gòu)想
3.1??基礎(chǔ)理論和模型的研究構(gòu)想
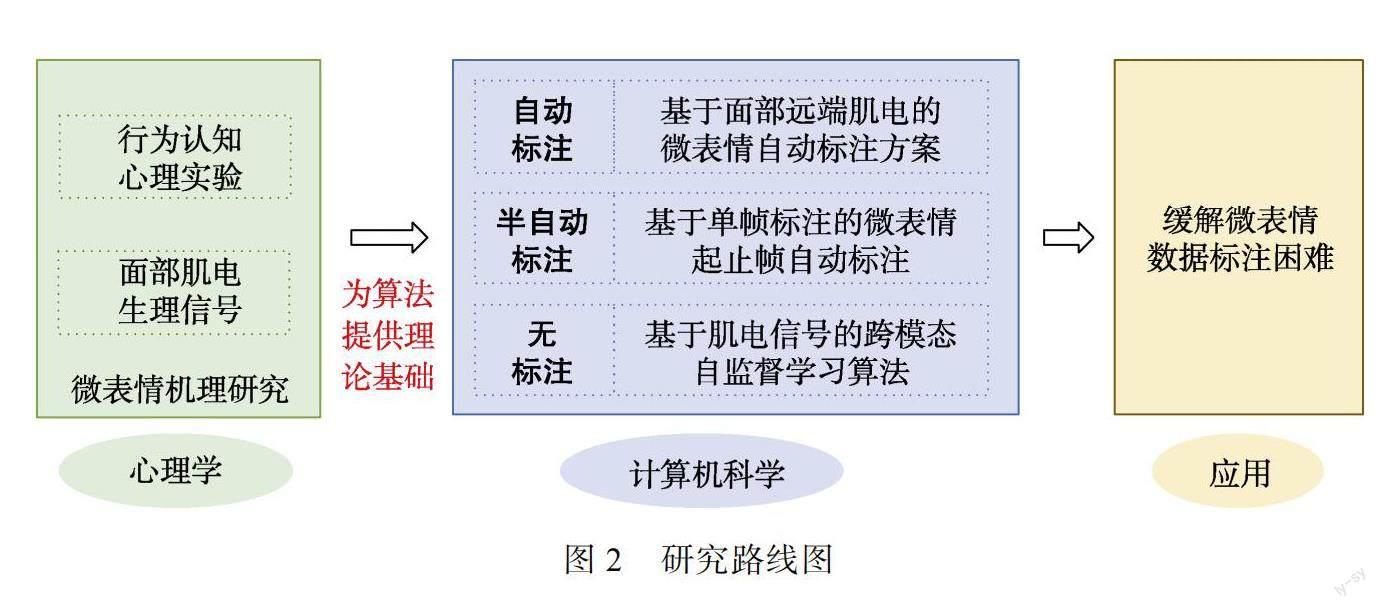
針對(duì)微表情動(dòng)作幅度不明顯導(dǎo)致的數(shù)據(jù)標(biāo)注困難這一問(wèn)題, 本研究從生理心理學(xué)方法和模式識(shí)別相結(jié)合, 開(kāi)展基于面部表情圖像和面部肌電跨模態(tài)分析的微表情數(shù)據(jù)標(biāo)注問(wèn)題研究。具體研究路線如圖2所示, 首先對(duì)心理學(xué)實(shí)驗(yàn)中的面部肌電信號(hào)進(jìn)行微表情機(jī)理研究, 為計(jì)算機(jī)自動(dòng)識(shí)別算法提供理論基礎(chǔ); 其次, 在自動(dòng)識(shí)別算法中分別從自動(dòng)標(biāo)注、半自動(dòng)標(biāo)注和無(wú)標(biāo)注三個(gè)方面進(jìn)行深入的研究; 最后推廣應(yīng)用以緩解微表情數(shù)據(jù)標(biāo)注的困難。
3.1.1??研究基于面部肌電信號(hào)的微表情機(jī)理
本文通過(guò)生理心理學(xué)方法, 將面部肌電生理
信號(hào)和行為認(rèn)知心理實(shí)驗(yàn)相結(jié)合, 來(lái)研究微表情機(jī)理。具體的, 研究記錄了面部肌肉或肌肉群組收縮時(shí)的信號(hào)頻率和振幅, 并用相關(guān)指標(biāo)來(lái)對(duì)微表情的三個(gè)特征(呈現(xiàn)時(shí)間短、運(yùn)動(dòng)幅度小和不對(duì)稱性)進(jìn)行更精確的量化, 為后續(xù)研究提供理論基礎(chǔ)。
在采集設(shè)備方面, 肌電采集設(shè)備在面部放置時(shí), 電極會(huì)對(duì)面部造成一定程度的遮擋, 進(jìn)而影響傳統(tǒng)的FACS編碼。為解決這一問(wèn)題, 本研究在研制多通道、可穿戴的面部肌電采集設(shè)備同時(shí), 還提出了一個(gè)遠(yuǎn)端面部肌電電極的部署方案。在不遮擋面部表情表達(dá)和對(duì)面部表情采集的情況下, 把肌電電極部署在臉部周圍, 使其可以重構(gòu)出其鄰近區(qū)域特定的肌肉收縮情況, 從而實(shí)現(xiàn)對(duì)微表情數(shù)據(jù)的自動(dòng)標(biāo)注。同時(shí)本研究設(shè)計(jì)誘發(fā)面部肌肉運(yùn)動(dòng)的心理學(xué)范式, 并以微表情的肌電信號(hào)機(jī)理為基礎(chǔ), 設(shè)計(jì)基于遠(yuǎn)端面部肌電的微表情數(shù)據(jù)自動(dòng)標(biāo)注的算法。
3.1.2??研究基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注
本文研究微表情的時(shí)間動(dòng)作定位, 為基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注算法找出可以借鑒的知識(shí)。本文從研究微表情視頻片段內(nèi)部幀與幀之間的距離度量, 使用具有單調(diào)性的度量去構(gòu)造損失函數(shù), 搭建微表情起止幀自動(dòng)標(biāo)注的深度學(xué)習(xí)網(wǎng)絡(luò)。
微表情的動(dòng)作強(qiáng)度在從起始幀到高峰幀的區(qū)間上是單調(diào)增加的, 而從高峰幀到終止幀的區(qū)間上是單調(diào)下降的。構(gòu)造出符合這種規(guī)律的幀之間的距離度量, 即可實(shí)現(xiàn)基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注。
3.1.3研究基于肌電信號(hào)的跨模態(tài)自監(jiān)督學(xué)習(xí)算法
本文研究了面部肌電與面部表情的對(duì)應(yīng)關(guān)系, 為無(wú)標(biāo)注的人臉視頻提供時(shí)域監(jiān)督信息; 設(shè)計(jì)一個(gè)基于Transformer的跨模態(tài)對(duì)比學(xué)習(xí)無(wú)監(jiān)督模型, 利用肌電信號(hào)增強(qiáng)網(wǎng)絡(luò)學(xué)習(xí)針對(duì)微表情動(dòng)作變化模式的特征。具體而言, 利用面部肌電信號(hào)和面部表情的對(duì)應(yīng)關(guān)系, 通過(guò)Transfomer網(wǎng)絡(luò)有效學(xué)習(xí)面部動(dòng)作的時(shí)空特征; 并在樣本有限的情況下, 通過(guò)對(duì)比學(xué)習(xí), 利用大量的宏表情、其余頭部動(dòng)作以及中性人臉等樣本作為負(fù)樣本對(duì), 增強(qiáng)模型對(duì)微表情的辨別能力。
3.2關(guān)鍵技術(shù)的研究構(gòu)想
3.2.1基于面部肌電信號(hào)的微表情機(jī)理的研究
面部肌電的一種常見(jiàn)用途就是研究與面部肌肉動(dòng)作相關(guān)的情緒反應(yīng)。與人為的主觀評(píng)估方法相比, 面部肌電是對(duì)面部肌肉活動(dòng)的測(cè)量, 是更加客觀的評(píng)估面部表情的方法。在本研究通過(guò)面部肌電對(duì)微表情的三個(gè)特征(呈現(xiàn)時(shí)間短、運(yùn)動(dòng)幅度小和不對(duì)稱性)進(jìn)行進(jìn)一步的量化考察, 為后續(xù)研究提供理論指導(dǎo), 研究框圖如圖3所示。
本文設(shè)計(jì)了一個(gè)心理學(xué)實(shí)驗(yàn), 以有效誘發(fā)微表情, 記錄肌電信號(hào)并以此研究微表情的機(jī)理。在刺激材料方面, 該實(shí)驗(yàn)使用高情緒效價(jià)的視頻片段作為誘發(fā)表情的刺激材料, 包括7種情緒(高興、厭惡、悲傷、恐懼、生氣、驚訝和中性)。每種情緒2~3個(gè)視頻, 每個(gè)視頻長(zhǎng)度為1~3分鐘。這些視頻均為CASME數(shù)據(jù)庫(kù)系列中所使用的誘發(fā)材料。為了盡量減少電極對(duì)微表情的影響, 本研究還針對(duì)不同的刺激材料, 制定不同的電極放置方案。該方案根據(jù)CAS (ME)3數(shù)據(jù)庫(kù)中已誘發(fā)和編碼后標(biāo)注出的AU統(tǒng)計(jì)結(jié)果來(lái)制定。比如:經(jīng)過(guò)統(tǒng)計(jì), 某個(gè)刺激材料誘發(fā)最多的是顴肌運(yùn)動(dòng)引起的AU12。那么, 在使用此刺激材料誘發(fā)微表情時(shí), 我們只在被試的顴肌上放置電極。
實(shí)驗(yàn)過(guò)程中, 被試被要求觀看刺激材料, 刺激材料由實(shí)驗(yàn)者按預(yù)定順序呈現(xiàn), 呈現(xiàn)順序在實(shí)驗(yàn)被試間進(jìn)行平衡。通過(guò)攝像機(jī)記錄下被試在觀看刺激材料時(shí)所產(chǎn)生的面部動(dòng)作, 同時(shí)記錄面部肌電。被試在實(shí)驗(yàn)過(guò)程中被要求盡可能保持中性表情, 眼睛不要離開(kāi)屏幕, 頭盡量保持不動(dòng)。被試還被告知, 他們的薪酬與表現(xiàn)直接相關(guān)。這些操作被用來(lái)增強(qiáng)被試隱藏真實(shí)面部表情的動(dòng)機(jī), 并減少無(wú)關(guān)的動(dòng)作。被試坐在一個(gè)顯示器前, 一臺(tái)攝像機(jī)被放置在顯示器后面, 記錄被試正面的全臉。主試根據(jù)刺激材料所誘發(fā)的情緒對(duì)應(yīng)AU選擇肌電電極的貼片位置。每段視頻結(jié)束1 s后, 被試需要對(duì)視頻刺激所誘發(fā)的情緒進(jìn)行二分評(píng)價(jià), 如果感覺(jué)這一段視頻是整體積極、正性就按下鍵盤(pán)中F鍵, 如果感覺(jué)視頻整體消極、負(fù)性就按下鍵盤(pán)中J鍵。基于內(nèi)心感受進(jìn)行的自我報(bào)告, 是情緒編碼的重要參考資料。被試對(duì)每個(gè)視頻都做完二分評(píng)價(jià)后, 顯示器會(huì)有500 ms空屏, 然后進(jìn)入下一段視頻。在整個(gè)實(shí)驗(yàn)過(guò)程中的任意時(shí)間, 要求被試密切注視屏幕并保持中立的表情, 一旦察覺(jué)到自己出現(xiàn)表情, 立刻按鍵記錄。實(shí)驗(yàn)流程如圖4所示。
該實(shí)驗(yàn)中, 面部電極的放置會(huì)造成部分面部會(huì)被一定程度遮擋的情況, 這種情況下如何進(jìn)行傳統(tǒng)的FACS編碼, 進(jìn)而確定是否有微表情的出現(xiàn), 即如何對(duì)部分遮擋的面部進(jìn)行微表情編碼, 這一直是微表情研究中要考慮的技術(shù)問(wèn)題。為解決這個(gè)問(wèn)題, 在本研究中, 我們對(duì)不同情緒刺激制定了不同的電極方案, 將電極對(duì)微表情編碼的影響盡可能降低。本研究引入肌電模態(tài)對(duì)微表情進(jìn)行分析, 確定微表情和肌電信號(hào)的對(duì)應(yīng)關(guān)系, 即研究面部表情表達(dá)肌肉的基線, 確定肌電信號(hào)的振幅、頻率等指標(biāo), 與微表情的呈現(xiàn)時(shí)間、運(yùn)動(dòng)幅度等的對(duì)應(yīng)關(guān)系。
3.2.2基于面部遠(yuǎn)端肌電的微表情自動(dòng)標(biāo)注的研究
微表情數(shù)據(jù)標(biāo)注的困難一直限制著微表情分析的發(fā)展。對(duì)于這種情況, 本文提出了基于面部肌電的微表情自動(dòng)標(biāo)注的研究。擬在不遮擋面部微表情采集的情況下, 把采集肌電的電極分布在面部周圍, 采集遠(yuǎn)端肌電信號(hào)來(lái)實(shí)現(xiàn)對(duì)微表情的自動(dòng)標(biāo)注, 研究框圖如圖5所示。
(1)采集設(shè)備的硬件設(shè)計(jì)與評(píng)測(cè)方案
針對(duì)面部區(qū)域的神經(jīng)、肌肉較多的情況, 我們自行設(shè)計(jì)了一款可以獲取更多面部肌肉的肌電信號(hào)的多通道肌電采集設(shè)備, 并將其用于采集面部周圍肌肉的串?dāng)_信號(hào)。本研究使用德州儀器生產(chǎn)的ADS1299作為肌電信號(hào)采集設(shè)備的信號(hào)采集芯片, STM32F429IGT6芯片作為控制器單元, ESP32芯片作為無(wú)線傳輸模塊。其中, ADS1299芯片具有8通道低噪聲、高分辨率同步采樣的ADC模數(shù)轉(zhuǎn)換器、內(nèi)置可編程增益放大器、輸入復(fù)用器、內(nèi)部基準(zhǔn)電壓、時(shí)鐘振蕩器、偏置放大電路、內(nèi)部測(cè)試源以及導(dǎo)聯(lián)脫落檢測(cè)電路, 內(nèi)部器件噪聲低于1 ?V, 具備肌電采集所需的全部常用功能。STM32F429核心板包含了更高性能的Cortex M4內(nèi)核, 其操作頻率最高達(dá)到180 Mhz, 同時(shí)擁有256 kB的片內(nèi)SRAM、6個(gè)串行外設(shè)接口(Serial Peripheral Interface, SPI)、兩個(gè)DMA控制器(共16個(gè)通道)等。此外, 板載32MB的SDRAM且又體積小巧, 僅65 mm × 45 mm, 方便應(yīng)用到各種項(xiàng)目里面, 滿足我們的數(shù)據(jù)緩存空間和數(shù)據(jù)快速轉(zhuǎn)換的需要。ESP32C3?MINI1芯片作為無(wú)線傳輸設(shè)備, 根據(jù)手冊(cè)指示重新對(duì)其進(jìn)行固件燒錄, 將wifi通信接口由串口更改為SPI接口, 可以達(dá)到更高的數(shù)據(jù)傳輸速度。在實(shí)際應(yīng)用中, 該無(wú)線傳輸器的最大穩(wěn)定數(shù)據(jù)傳輸速度可以達(dá)到3 M/s。此外該模塊具有尺寸小、功耗低等優(yōu)點(diǎn), 滿足無(wú)線數(shù)據(jù)傳輸?shù)男枨蟆榱吮苊馐须妼?duì)采集信號(hào)的干擾, 采集裝置配有電源管理模塊, 并采用鋰電池供電。本設(shè)備需要32通道, 所以本研究采用4塊ADS1299芯片進(jìn)行菊花鏈串聯(lián)成32通道。
對(duì)于自行設(shè)計(jì)的設(shè)備, 需要驗(yàn)證其性能指標(biāo)。本研究將自行設(shè)計(jì)的設(shè)備與Biopac生理多導(dǎo)儀的肌電模塊進(jìn)行比較。用兩套設(shè)備分別采集額肌、皺眉肌、眼輪匝肌、鼻唇提肌、顴大肌、口輪匝肌、降口角肌和頦肌的肌電信號(hào), 即最大肌肉收縮力量(maximal voluntary contraction, MVC)。為了度量?jī)蓚€(gè)設(shè)備記錄的MVC相似性, 本研究分別使用Spearman相關(guān)性(Spearmans correlation)、能量比(Energy ratio)、線性相關(guān)系數(shù)(Linear correlation coefficient)和互相關(guān)系統(tǒng)數(shù)(Cross-?correlation coefficient)。
在數(shù)據(jù)采集過(guò)程中, 通過(guò)數(shù)碼管的亮滅來(lái)同步肌電和視頻數(shù)據(jù)采集的開(kāi)始時(shí)間。由于肌肉間的信號(hào)傳播, 一個(gè)通道可能會(huì)包含多塊肌肉源的串?dāng)_信號(hào), 所以我們使用盲源分離算法進(jìn)行肌肉運(yùn)動(dòng)源成分的分離。為了得到更好的信號(hào)波形并且去除噪聲干擾, 進(jìn)行20~450 Hz的帶通濾波、去除直流電、全波整流等操作, 最后得到信號(hào)的線性包絡(luò)。此外, 我們?cè)O(shè)計(jì)了一個(gè)算法提取包絡(luò)信號(hào)發(fā)生波動(dòng)的開(kāi)始和結(jié)束時(shí)刻, 然后根據(jù)數(shù)碼管由暗變亮的時(shí)間, 就可以精準(zhǔn)地定位視頻中微表情發(fā)生的開(kāi)始時(shí)間和結(jié)束時(shí)間。最后, 我們整合這個(gè)過(guò)程, 設(shè)計(jì)一款自動(dòng)化標(biāo)注交互軟件, 可以極大地節(jié)約了微表情的標(biāo)注時(shí)間, 減少標(biāo)注人員的工作量, 且在一定程度上解決了微表情數(shù)據(jù)庫(kù)的小樣本問(wèn)題。
(2)基于情緒誘發(fā)的數(shù)據(jù)采集方案
微表情自動(dòng)標(biāo)注模型的建立需要大量面部肌肉運(yùn)動(dòng)時(shí)的肌電樣本, 所以在確定好采集設(shè)備與采集肌肉位置后, 我們需要采集這些部位運(yùn)動(dòng)狀態(tài)下的肌電信號(hào), 而面部肌肉運(yùn)動(dòng)有兩種誘發(fā)方式。第一種是通過(guò)指導(dǎo)語(yǔ)讓被試做面部指定肌肉的收縮, 這種方式容易引起指定肌肉周圍的肌肉的運(yùn)動(dòng), 而使得用于建模的肌電信號(hào)生態(tài)效度不高。另一種方式是通過(guò)誘發(fā)特定的情緒, 使得被試面部出現(xiàn)自發(fā)的表情, 從而獲得和特定情緒相關(guān)的面部肌電信號(hào), 其具有較高的生態(tài)效度。所以在本研究中使用心理學(xué)實(shí)驗(yàn)手段誘發(fā)出自發(fā)產(chǎn)生的表情。為采集到可供建立模型的肌電數(shù)據(jù), 我們用到了前文提到的情緒誘發(fā)的方式設(shè)計(jì)的心理學(xué)實(shí)驗(yàn)。即使用高情緒效價(jià)的視頻片段作為誘發(fā)表情的刺激材料, 每段視頻結(jié)束后, 被試填寫(xiě)量表, 對(duì)內(nèi)心感受進(jìn)行自我報(bào)告, 這被用作情緒編碼時(shí)的重要參考資料。由于本研究提前操縱控制了誘發(fā)材料本身的情緒類型, 因此所產(chǎn)生的面部動(dòng)作較為純粹且易于區(qū)分。
3.2.3基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注的研究
不同于單張表情圖片, 微表情的數(shù)據(jù)是以視頻片段的形式出現(xiàn)的。這就意味著微表情的標(biāo)注, 還需要在時(shí)間維度上標(biāo)注微表情視頻片斷的起始幀和終止幀。本研究要研究問(wèn)題是, 假設(shè)微表情視頻片斷有一幀已經(jīng)被標(biāo)為一種微表情, 那么如何去自動(dòng)的推斷該微表情片斷的起始幀和終止幀, 如圖6所示。
對(duì)于這個(gè)問(wèn)題, 本文提出一個(gè)基本解決思路和對(duì)應(yīng)的算法設(shè)計(jì), 即在一個(gè)包含微表情片段和背景幀的長(zhǎng)視頻中, 對(duì)每個(gè)視頻幀進(jìn)行分類, 確
定其是否為微表情幀、背景幀或未標(biāo)記幀。在初始階段, 每個(gè)微表情片段中只有一個(gè)幀的標(biāo)簽被標(biāo)記為1, 其余幀的標(biāo)簽記為0, 并隨機(jī)選擇一些不屬于任何微表情片段的幀標(biāo)記為?1, 即背景幀。然后, 使用深度學(xué)習(xí)網(wǎng)絡(luò)對(duì)已標(biāo)記幀進(jìn)行訓(xùn)練, 計(jì)算未標(biāo)記幀的微表情得分和背景得分, 并根據(jù)微表情動(dòng)作變化的局部時(shí)空模式推斷出其所屬類別。最后, 重復(fù)這個(gè)過(guò)程直到所有幀都被標(biāo)記為微表情幀或背景幀, 輸出每個(gè)視頻幀的標(biāo)簽。
算法中用到的深度學(xué)習(xí)模型:CS?Net網(wǎng)絡(luò)結(jié)構(gòu)如圖7所示, 其包括三個(gè)模塊:特征抽取模塊、分類模塊和得分模塊。特征模塊使用AlexNet網(wǎng)絡(luò)或ResNet網(wǎng)絡(luò)把幀抽取為特征向量, 其中AlexNet與ResNet網(wǎng)絡(luò)是基于深度學(xué)習(xí)的圖像分類任務(wù)常用的骨架模型。分類模塊把特征按微表情的類別進(jìn)行分類。得分模塊則計(jì)算其屬于微表情的得分![]() 和屬于背景的得分
和屬于背景的得分![]() 。
。
在算法結(jié)果的推斷中, 本研究不僅考慮CS?Net網(wǎng)絡(luò)的輸出結(jié)果, 另外還使用能夠體現(xiàn)微表情特征的局部時(shí)空模式(S?Pattern)來(lái)進(jìn)一步的加以約束。S?Pattern體現(xiàn)了微表情在面部局部區(qū)域的變化特征, 即從起始幀到峰值幀的區(qū)間內(nèi), 微表情的動(dòng)作模式呈現(xiàn)一個(gè)遞增的趨勢(shì), 而在峰值幀到終止幀這個(gè)區(qū)間, 由于受到頭部動(dòng)作或者表情不一定恢復(fù)原位等因素的影響, 動(dòng)作模式可能呈現(xiàn)下降趨勢(shì)或者趨于平緩。具體來(lái)講, 通過(guò)主成分分析的方法, 在時(shí)間維度上對(duì)人臉興趣區(qū)域視頻進(jìn)行特征分析。在保留前兩列的視頻主成分之后, 根據(jù)微表情的時(shí)間特征設(shè)定滑動(dòng)窗口, 計(jì)算窗口內(nèi)每一幀的歐式空間距離, 從而得到可以體現(xiàn)微表情動(dòng)作變化模式的特征, 即S?Pattern。
圖8顯示了一個(gè)微表情片斷的S?Pattern, 其曲線相對(duì)于時(shí)間(幀)具有單調(diào)性。這種單調(diào)性可以對(duì)CS?Net網(wǎng)絡(luò)的輸出結(jié)果加以進(jìn)一步的約束。相關(guān)的方案在SAMM微表情數(shù)據(jù)庫(kù)上預(yù)實(shí)驗(yàn)結(jié)果如圖9所示。
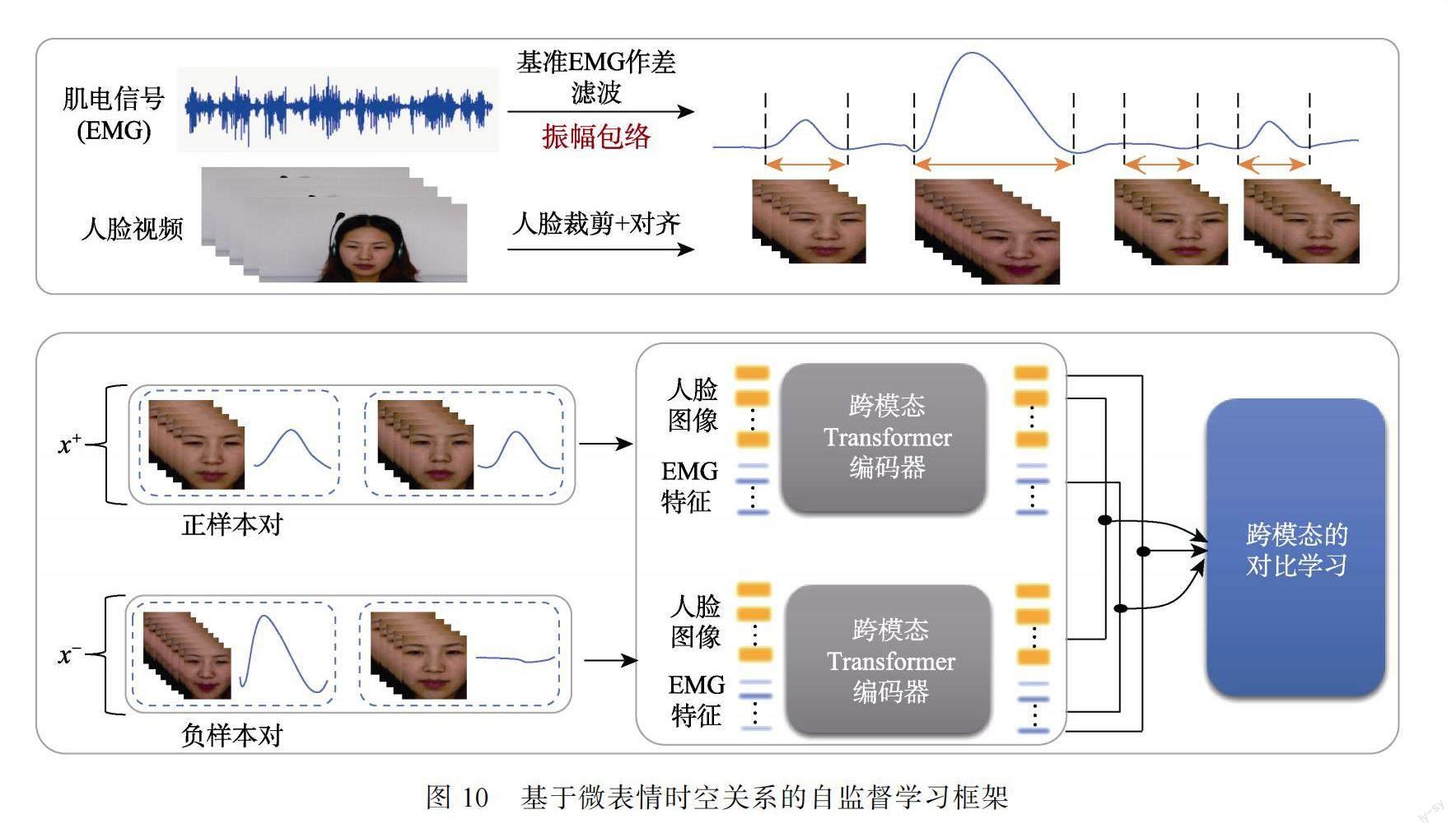
3.2.4基于肌電信號(hào)的跨模態(tài)自監(jiān)督學(xué)習(xí)算法
由于已標(biāo)注的微表情樣本有限, 本研究提出在大量的無(wú)標(biāo)注人臉及表情視頻中進(jìn)行自監(jiān)督學(xué)習(xí)。具體而言, 利用體現(xiàn)微表情的動(dòng)作信息的肌電信號(hào), 構(gòu)建肌電的跨模態(tài)自監(jiān)督學(xué)習(xí)模型, 通過(guò)Transformer和對(duì)比學(xué)習(xí)的結(jié)合, 學(xué)習(xí)針對(duì)微表情的動(dòng)態(tài)變化信息, 從而實(shí)現(xiàn)微表情檢測(cè), 網(wǎng)絡(luò)框架如圖10所示。其中, Transformer是一種基于注意力機(jī)制的深度學(xué)習(xí)序列模型, 可以較好地解決序列傳導(dǎo)問(wèn)題。
首先, 通過(guò)采集到的肌電信號(hào)與基準(zhǔn)肌電信號(hào)的差異來(lái)去除靜態(tài)狀態(tài)下的肌電噪聲, 然后對(duì)差分信號(hào)進(jìn)行濾波平滑和歸一化處理, 得到振幅隨時(shí)間變化的曲線。這個(gè)曲線即為面部動(dòng)作變化肌電信號(hào)的包絡(luò)信號(hào)。該信號(hào)在簡(jiǎn)化原始肌電信號(hào)波形變化的基礎(chǔ)上, 可以很好地體現(xiàn)面部動(dòng)作變化。
其次, 通過(guò)計(jì)算包絡(luò)信號(hào)每個(gè)時(shí)刻的斜率和波幅變化來(lái)確定區(qū)域信號(hào)變化時(shí)長(zhǎng)。由此, 將時(shí)間維度上連續(xù)的波形變化分割為符合微表情時(shí)域變化特征的片段和其他類型片段。同時(shí), 根據(jù)包絡(luò)信號(hào)的時(shí)刻劃分波形, 得到對(duì)應(yīng)不同面部動(dòng)作的視頻片段。這些符合微表情特征的肌電包絡(luò)信號(hào)和對(duì)應(yīng)視頻片段被用于構(gòu)建對(duì)比學(xué)習(xí)中的正樣本對(duì), 其余階段的視頻和肌電信號(hào)被用于構(gòu)建負(fù)樣本對(duì)。
隨后, 通過(guò)跨模態(tài)的Transformer編碼器, 以表情圖像特征和肌電信號(hào)特征作為T(mén)oken Embedding?(代表微表情的特征), 以上特征對(duì)應(yīng)的時(shí)刻作為Positional Embedding (代表序列的順序性)。傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)或者循環(huán)神經(jīng)網(wǎng)絡(luò)在提取時(shí)空特征的過(guò)程中, 往往關(guān)注的是相鄰區(qū)域或者相鄰時(shí)刻的特征。而Transformer通過(guò)自注意力機(jī)制, 關(guān)注不同位置的特征, 從而學(xué)習(xí)對(duì)應(yīng)不同肌電包絡(luò)信號(hào)波形的面部動(dòng)作模式。
在得到Transformer編碼器輸出的兩種模態(tài)的特征后, 根據(jù)正負(fù)樣本對(duì)兩兩組合, 本研究將跨模態(tài)的特征輸入到對(duì)比學(xué)習(xí)的模型中, 對(duì)4種模態(tài)組合方式的對(duì)比學(xué)習(xí)。通常情況下, 在涉及人臉?lè)治龅纳疃葘W(xué)習(xí)模型中, 模型往往會(huì)優(yōu)先學(xué)習(xí)到人臉的個(gè)體信息, 而忽略面部細(xì)小的動(dòng)態(tài)變化。因此, 微表情的類內(nèi)差異是在算法優(yōu)化中需要處理的一個(gè)問(wèn)題。通過(guò)對(duì)比學(xué)習(xí), 模型可以很好地縮小類內(nèi)差異, 增大類間差異, 使得模型具備區(qū)分微表情動(dòng)作特征和其他類型動(dòng)作特征的能力。同時(shí), 肌電信號(hào)的引入可以增強(qiáng)對(duì)比學(xué)習(xí)模型對(duì)面部時(shí)域微弱動(dòng)態(tài)變化的捕捉。
這種結(jié)合肌電信號(hào)的自監(jiān)督學(xué)習(xí)模型, 一方面可以增強(qiáng)模型對(duì)視覺(jué)特征的理解能力, 另一方面可以通過(guò)跨模態(tài)的學(xué)習(xí)使得模型學(xué)習(xí)到更加泛化的特征, 增強(qiáng)系統(tǒng)的魯棒性。
4??理論構(gòu)建與創(chuàng)新
自從1966年心理學(xué)家Haggard和Isaacs發(fā)現(xiàn)微表情以來(lái), 其心理學(xué)研究方法一般是通過(guò)FACS編碼對(duì)微表情進(jìn)行研究。隨著機(jī)器學(xué)習(xí)等技術(shù)的發(fā)展, 近十幾年來(lái)也開(kāi)始有計(jì)算機(jī)專家對(duì)智能化微表情分析進(jìn)行初步探索。10年前兩個(gè)微表情數(shù)據(jù)庫(kù)的公開(kāi)發(fā)表, 極大地推動(dòng)了微表情自動(dòng)分析的發(fā)展。雖然近10年來(lái)公開(kāi)發(fā)布的微表情數(shù)據(jù)庫(kù)已有7個(gè), 超過(guò)2600個(gè)樣本。隨著GAN的技術(shù)的推廣, 也有學(xué)者通過(guò)生成微表情樣本來(lái)緩解微表情小樣本的問(wèn)題。但目前為止的微表情樣本量還相對(duì)較少, 阻礙了微表情自動(dòng)分析進(jìn)一步的發(fā)展。這主要因?yàn)槲⒈砬閿?shù)據(jù)標(biāo)注十分耗時(shí)耗力。針對(duì)這個(gè)問(wèn)題, 本研究開(kāi)展多學(xué)科交叉研究, 主要?jiǎng)?chuàng)新點(diǎn)包括:
對(duì)心理學(xué)研究方法做出了變革性的創(chuàng)新。基于面部表情系統(tǒng)編碼的人為主觀評(píng)估方法已經(jīng)被廣泛用于微表情研究中, 其中多數(shù)是使用FACS系統(tǒng)對(duì)面部表情進(jìn)行編碼研究, 而本研究使用面部肌電信號(hào)去研究微表情, 使得對(duì)微表情研究更加精確, 更加客觀量化, 打破了微表情標(biāo)注方法完全依賴于人工編碼的制約, 極大地提高了建構(gòu)微表情數(shù)據(jù)庫(kù)的效率和可靠性。
在計(jì)算機(jī)科學(xué)方面, 本研究創(chuàng)新性地提出“基于面部肌電的微表情自動(dòng)標(biāo)注的研究”和“基于單幀標(biāo)注的微表情起止幀自動(dòng)標(biāo)注的研究”, 憑借客觀的面部肌電信號(hào), 優(yōu)化設(shè)計(jì)了“基于肌電信號(hào)的跨模態(tài)自監(jiān)督學(xué)習(xí)算法”。從樣本標(biāo)注層面上提出新問(wèn)題, 探索新方法, 來(lái)解決微表情小樣本的問(wèn)題。
參考文獻(xiàn)
李曉明, 傅小蘭, 鄧國(guó)峰. (2008). 中文簡(jiǎn)化版PAD情緒量表在京大學(xué)生中的初步試用. 中國(guó)心理衛(wèi)生雜志, 22(5), 327?329.
Ben, X., Ren, Y., Zhang, J., Wang, S.-J., Kpalma, K., Meng, W., & Liu, Y.-J. (2021). Video-based facial micro-?expression analysis: A survey of datasets, features and algorithms. In IEEE Transactions on Pattern Analysis and Machine Intelligence?(Vol. 44, pp. 5826?5846). Singapore.
Chao, Y.-W., Vijayanarasimhan, S., Seybold, B., Ross, D. A., Deng, J., & Sukthankar, R. (2018, June). Rethinking the faster r-cnn architecture for temporal action localization. Paper presented at the meeting of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1130??1139). Salt Lake City, UTAH.
Darwin, C. (1872). The expression of the emotions in man and animals. London, UK: John Marry.
Davison, A., Merghani, W., Lansley, C., Ng, C.-C., & Yap, M. H. (2018, May). Objective micro-facial movement detection?using facs-based regions and baseline evaluation. In 2018 13th IEEE international conference on automatic face & gesture recognition?(FG 2018) (pp. 642?649). China.
Davison, A. K., Lansley, C., Costen, N., Tan, K., & Yap, M. H. (2018). SAMM: A spontaneous micro-facial movement dataset. IEEE Transactions on Affective Computing, 9(1), 116?129.
Ding, J., Tian, Z., Lyu, X., Wang, Q., Zou, B., & Xie, H. (2019, September). Real-time micro-expression detection in unlabeled long videos using optical flow and lstm neural network. In International Conference on Computer Analysis of Images and Patterns?(pp. 622?634). Springer, Cham.
Doersch, C., Gupta, A., & Efros, A. A. (2015). Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE international conference on computer vision?(pp. 1422?1430). Chile.
Ekman, P. (2004). Emotions revealed. British Medical Journal, 328(Suppl. 5), 0405184.
Ekman, P., & Friesen, W. V. (1969). Nonverbal leakage and clues to deception. Psychiatry, 32(1), 88?106.
Fernando, B., Bilen, H., Gavves, E., & Gould, S. (2017, July). Self-supervised video representation learning with odd-one-out networks. In Proceedings of the IEEE conference on computer vision and pattern recognition?(pp. 3636?3645). Hawaii, Hawaii Convention Center.
Gao, Y., Vedula, S. S., Reiley, C. E., Ahmidi, N., Varadarajan, B., Lin, H. C., ... Hager, G. (2014, September). Jhu-isi gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling. Paper presented at the meeting of MICCAI workshop: M2cai (Vol. 3). New York, NY.
Gruebler, A., & Suzuki, K. (2014). Design of a wearable device for reading positive expressions from facial emg signals. IEEE Transactions on Affective Computing, 5(3), 227?237.
Hamedi, M., Salleh, S.-H., Astaraki, M., & Noor, A. M. (2013). EMG-based facial gesture recognition through versatile elliptic basis function neural network. Biomedical Engineering Online, 12, 73.
Hess, U. (2009). Facial EMG. Methods in social neuroscience?(pp.70?91). NY: The Guilford Press.
H?fling, T. T. A., Gerdes, A. B., F?hl, U., & Alpers, G. W. (2020). Read my face: Automatic facial coding versus psychophysiological indicators of emotional valence and arousal. Frontiers in Psychology, 11, 1388.
Jing, L., & Tian, Y. (2020). Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11), 4037?4058.
Larsson, G., Maire, M., & Shakhnarovich, G. (2017, July). Colorization as a proxy task for visual understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6874?6883). Hawaii, Hawaii Convention Center.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436?444.
Lee, P., Uh, Y., & Byun, H. (2020, April). Background suppression network for weakly-supervised temporal action localization. In Proceedings of the AAAI conference on artificial intelligence?(Vol. 34, pp. 11320?11327). Vancouver, Canada.
Lee, Y. J., Ghosh, J., & Grauman, K. (2012, June). Discovering important people and objects for egocentric video summarization. In 2012 IEEE conference on computer vision and pattern recognition?(pp. 1346?1353). Providence, USA.
Li, J., Dong, Z., Lu, S., Wang, S.-J., Yan, W.-J., Ma, Y., Liu, Y., Huang, C., & Fu, X. (2022). CAS (ME) 3: A third generation facial spontaneous micro-expression database with depth information and high ecological validity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3), 2782?2800.
Li, X., Cheng, S., Li, Y., Behzad, M., Shen, J., Zafeiriou, S., Pantic, M., & Zhao, G. (2022). 4DME: A spontaneous 4D micro-expression dataset with multimodalities. IEEE Transactions on Affective Computing Early Access, 1?18. https://doi.org/10.1109/TAFFC.2022.3182342
Li, X., Liu, S., de Mello, S., Wang, X., Kautz, J., & Yang, M.-H. (2019). Joint-task self-supervised learning for temporal correspondence. Advances in Neural Information Processing Systems, 32.
Li, X., Pfister, T., Huang, X., Zhao, G., & Pietik?inen, M. (2013, April). A spontaneous micro-expression database: Inducement, collection and baseline. In 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai, China. https://?doi.org/10.1109/fg.2013.6553717
Liong, S.-T., See, J., Wong, K., & Phan, R. C.-W. (2016, November). Automatic micro-expression recognition from long video using a single spotted apex. In Computer Vision?ACCV 2016 Workshops: ACCV 2016 International Workshops?(pp. 345?360). Taipei, Taiwan.
Liu, D., Jiang, T., & Wang, Y. (2019, June). Completeness modeling and context separation for weakly supervised temporal action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1298?1307). Long Beach, USA.
Long, F., Yao, T., Qiu, Z., Tian, X., Luo, J., & Mei, T. (2019, June). Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 344?353). Long Beach, USA.
Moilanen, A., Zhao, G., & Pietik?inen, M. (2014, August). Spotting rapid facial movements from videos using appearance-based feature difference analysis. In Proceedings-International Conference on Pattern Recognition?(pp. 1722?1727). Stockholm, Sweden. https://doi.org/?10.1109/ICPR.2014.303
Pan, H., Xie, L., & Wang, Z. (2021, October). Spatio-?temporal convolutional attention network for spotting macro-and micro-expression intervals. In Proceedings of the 1st Workshop on Facial Micro-Expression: Advanced Techniques for Facial Expressions Generation and Spotting?(pp. 25?30). New York, NY.
Pathak, D., Kr?henbühl, P., Donahue, J., Darrell, T., & Efros, A. A. (2016, June). Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2536??2544). Las Vegas, Nevada.
Perusquía-Hernández, M., Dollack, F., Tan, C. K., Namba, S., Ayabe-Kanamura, S., & Suzuki, K. (2021, December). Smile action unit detection from distal wearable electromyography and computer vision. In 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021) (pp. 1?8). Jodhpur, India.
Qu, F., Wang, S.-J., Yan, W.-J., Li, H., Wu, S., & Fu, X. (2018). CAS (ME)2: A database for spontaneous macro-expression and micro-expression spotting and recognition. IEEE Transactions on Affective Computing, 9(4), 424?436.
Rinn, W. E. (1984). The neuropsychology of facial expression: A review of the neurological and psychological mechanisms for producing facial expressions. Psychological Bulletin, 95(1), 52?77.
Sato, W., Murata, K., Uraoka, Y., Shibata, K., Yoshikawa, S., & Furuta, M. (2021). Emotional valence sensing using a wearable facial EMG device. Scientific Reports, 11(1), 5757.
Schultz, I., & Pruzinec, M. (2010). Facial expression recognition using surface electromyography (Unpublished doctoral dissertation). Karlruhe Institute of Technology.
Sun, B., Cao, S., Li, D., He, J., & Yu, L. (2020). Dynamic micro-expression recognition using knowledge distillation. IEEE Transactions on Affective Computing, 13(2), 1037??1043.
Torre, F. D. l., Simon, T., Ambadar, Z., & Cohn, J. F. (2011, October). Fast-FACS: A computer-assisted system to increase speed and reliability of manual FACS coding. In Affective Computing and Intelligent Interaction: 4th International Conference?(pp. 57?66). Springer Berlin Heidelberg.
Vishwakarma, S., & Agrawal, A. (2013). A survey on activity recognition and behavior understanding in video surveillance. The Visual Computer, 29(10), 983?1009.
Wang, S.-J., He, Y., Li, J., & Fu, X. (2021). MESNet: A convolutional neural network for spotting multi-scale micro-expression intervals in long videos. IEEE Transactions on Image Processing, 30, 3956?3969. https://doi.org/10.1109/tip.2021.3064258
Wang, S.-J., Li, B.-J., Liu, Y.-J., Yan, W.-J., Ou, X., Huang, X., Xu, F., & Fu, X. (2018). Micro-expression recognition with small sample size by transferring long-term convolutional neural network. Neurocomputing, 312, 251?262.
Wang, S.-J., Wu, S., Qian, X., Li, J., & Fu, X. (2017). A main directional maximal difference analysis for spotting facial movements from long-term videos. Neurocomputing, 230, 382?389.
Xia, B., Wang, W., Wang, S., & Chen, E. (2020, October). Learning from macro-expression: A micro-expression recognition framework. In Proceedings of the 28th ACM International Conference on Multimedia?(pp. 2936?2944). Lisbon, Portugal.
Yan, W.-J., Li, X., Wang, S.-J., Zhao, G., Liu, Y.-J., Chen, Y.-H., & Fu, X. (2014). CASME II: An improved spontaneous micro-expression database and the baseline evaluation. Plos One, 9(1), Article e86041.
Yan, W.-J., Wu, Q., Liang, J., Chen, Y.-H., & Fu, X. (2013). How fast are the leaked facial expressions: The duration of micro-expressions. Journal of Nonverbal Behavior, 37(4), 217?230.
Yan, W.-J., Wu, Q., Liu, Y.-J., Wang, S.-J., & Fu, X. (2013, April). CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Shanghai, China.
Yang, B., Wu, J., Zhou, Z., Komiya, M., Kishimoto, K., Xu, J., Nonaka, K., Horiuchi, T., Komorita, S., Hattori, G., Naito, S., & Takishima, Y. (2021, October). Facial action unit-based deep learning framework for spotting macro-and micro-expressions in long video sequences. In Proceedings of the 29th ACM International Conference on Multimedia?(pp. 4794?4798). Chengdu, China.
Yu, W.-W., Jiang, J., & Li, Y.-J. (2021, October). LSSNet: A two-stream convolutional neural network for spotting macro-and micro-expression in long videos. In Proceedings of the 29th ACM International Conference on Multimedia (pp. 4745?4749). Chengdu, China.
Cross-modal analysis of facial EMG in micro-expressions and data annotation algorithm
WANG Su-Jing1,2, WANG Yan1,2, Li Jingting1,2, DONG Zizhao1,2,ZHANG Jianhang3, LIU Ye2,4
(1?CAS Key Laboratory of Behavioral Science, Institute of Psychology, Beijing 100101,?China)?(2?Department of Psychology, University of Chinese Academy of Sciences, Beijing 100049, China)?(3?School of Computer Science, Jiangsu University of Science and Technology, Zhenjiang 212003,?China)?(4?State Key Laboratory of Brain and Cognitive Science, Institute of Psychology, Chinese Academy of Sciences, Beijing 100039,?China)
Abstract: For a long time, the issue of limited samples has been a major hindrance to the development of micro-expression analysis, and this limitation primarily stems from the inherent difficulty in annotating micro-expression data. In this research, we aim to address this challenge by leveraging facial electromyography as a technical approach and propose three solutions for micro-expression data annotation: automatic annotation, semi-automatic annotation, and unsupervised annotation. Specifically, we first present an automatic micro-expression annotation system based on distal facial electromyography. Second, we propose a semi-automatic annotation scheme for micro-expression onset and offset frames based on single-frame annotation. Finally, for unsupervised annotation, we introduce a cross-modal self-supervised learning algorithm based on electromyographic signals. Additionally, this research endeavors to explore the temporal and intensity characteristics of micro-expressions using the electromyography modality.
Keywords:?image annotation, micro-expression analysis, distal facial electromyography, micro-expression data annotation
