智能口語雙機評測模式在外語聽說機考評卷中的可行性研究
2023-12-12 06:43:47沈晨羅雙虎
考試研究 2023年3期
關鍵詞:中考
沈晨 羅雙虎
[摘要]基于現有英語聽說考試人機互評的評卷模式,探索雙機評測模式可行性,使用上海市初中外語聽說測試全真模擬數據試驗,對比3種獨立計算機智能評分算法的效果。結果顯示,機評分與報道分一致性達到96%以上,具備良好的效果,但存在1659份樣本雙機評后仍誤判的效果風險,綜合考慮雙機評測模式的評卷組織、機評評價機制仍不完備,暫不具備可行性,需要進一步的算法提升和應用方法研究;算力改變對比驗證結果表明,評分準確性幾乎不下降的情況下,采用GPU算力結構的評分算法的運算速度相當于CPU算力結構的6倍,這可以使得評分時間和硬件投入大幅度減少。
[關鍵詞]中考;外語聽說測試;計算機智能評分
[中圖分類號]G424.74[文獻標識碼]A
[文章編號]1673—1654(2023)03—075—016
一、研究背景
習近平總書記在2018年底的中央經濟工作會議上首次明確提出“加快5G商用步伐、加強人工智能、工業互聯網、物聯網等新型基礎設施建設”[1]。2019年2月,中共中央、國務院印發《中國教育現代化2035》,明確提出“大力推進教育理念、體系、制度、內容、方法、治理現代化,著力提高教育質量,促進教育公平,優化教育結構”[2]。在教育考試領域,現代化人工智能技術已在普通中高考、大學英語四六級等高利害考試評卷方面形成規模化、標準化應用,一方面,通過“人機雙評”模式有效降低教師評卷工作量,保障評卷公平;另一方面,通過“智能評分質檢”對教師評卷進行校準和質檢檢測,保障評卷質量。
隨著人工智能技術的發展[3],計算機智能評分技術(以下簡稱機器評分)日趨成熟[4]。上海市教育考試院從2017年新高考改革第一年開始,在高考外語聽說測試中采用機器評分技術,使用“人一評、機一評”的人機雙評模式進行,避免了大規模抽調教師評分帶來的一系列復雜的調度事宜,節省了大量人力,同時也避免了多人評卷帶來的標準難以統一等問題。
目前機器評分在上海高考外語聽說測試評卷中已經穩定應用了10次,在歷次效果驗證集上,機器評分效果已達到或超過人工評卷水平。基于高考外語聽說測試機器評分的經驗,在2021年上海新中考改革第一年首次開考的初中外語聽說測試中也使用了同樣的技術。實行計算機考試,使用人機雙評模式保障評卷質量。目前此項考試不包含聽力,既有的聽說部分,總分值為10分,由四個題塊構成,分別為朗讀、交際應答、復述、表達。從2015年以來上海市小學入學人口統計來看,預計2029年參加中考人數近19萬,相較2018年的約10萬增長90%,考生語音的人工評卷組織成本仍然較高。因此,本研究嘗試探索雙機評模式替代人機互評模式的可行性。
二、智能測評技術在語音評卷中的應用
(一)口語智能評測基本原理及方法
口語智能評測是指使用計算機對口語能力進行自動評分。依據對口語能力維度的劃分,口語智能評測包括發音評分和自然口語評分兩類評分任務,前者以限定文本的詞、句、篇朗讀為測試任務,后者以非限定文本的情景應答、口頭復述、看圖說話、觀點陳述等為測試任務。
口語智能評測從20世紀90年代開始得到廣泛研究,發展迅速。目前,主流的口語智能評測方法分為兩種:基于人工特征的評分方法[5]和基于深度學習的端到端評分方法[6]。基于人工特征的評分方法利用語音和語言處理淺層分析的結果構建特征(如音素發音錯誤率、語速、停頓頻率、詞匯多樣性等),將評分任務作為回歸任務,從而對口語作答進行評分。該方法應用廣泛,具備高度的可解釋性,但由于人工特征與人工評分考察的維度和深度相距較遠,如難以抽取內容語義特征,并不能完全適用于對評分準確性有高要求的大規模口語考試評測。近年來,基于深度學習的端到端評分方法開始應用于口語智能評測。該方法首先通過神經網絡將口語作答的語音和文本形式的識別結果抽象地表示為分布式向量,然后再學習分布式向量與分數之間的關系。近來一些研究成果顯示此類方法可以取得優于基于人工特征評分方法的效果,但存在可解釋性較差、對標注數據依賴性強的問題。
1.算法選取
為論證雙機評模式的可行性,本文采用當前已大規模應用的三套獨立的口語智能評測算法,在相同的有專家評分的定標集上進行定標學習,并經過驗證集的核驗后對相同的全集數據進行評分。評分結束后,將機器評分與報道分進行對比分析。最終通過分析實驗數據,探究多機器評分并行代替人工雙評的可行性。
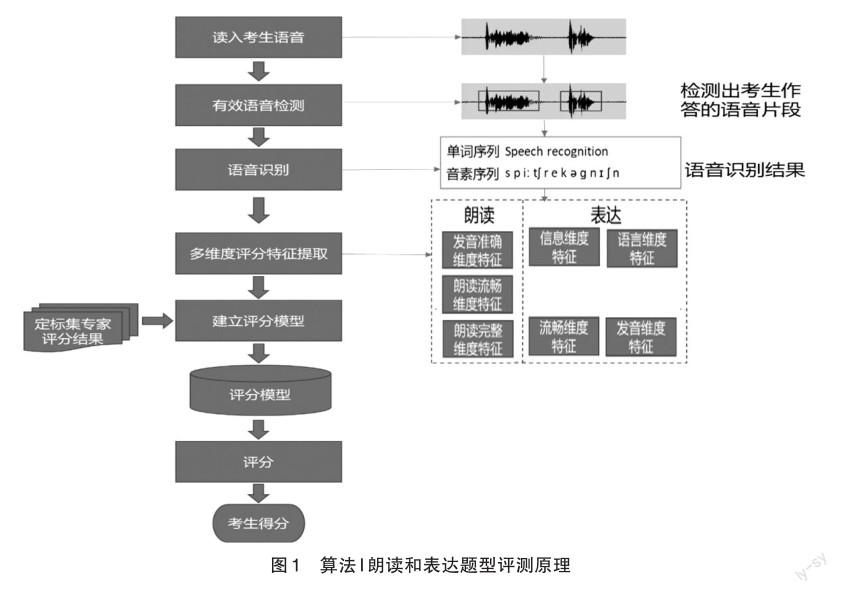
(1)算法I基本原理(如圖1):算法I分為朗讀類題型評測和表達類題型評測,采用非端到端方案和端到端方案相融合的方法,最大程度上利用兩者的優勢,保障評分準確性。在非端到端方案中,對于詞組和句子朗讀題型,基于語音識別結果,對考生朗讀進行漏讀、增讀、重復、不當停頓檢測,獲得完成度、流暢度維度的評分特征;通過發音檢錯技術,對考生朗讀內容進行音素級發音準確度評分特征提取。對于交際問答、復述和表達題型,基于語音識別結果,通過語義匹配技術計算與參考答案的相似度,以獲得信息完整度和正確度相關評分特征;通過語法檢錯技術提取詞匯及語法正確度評分特征;發音和流暢度則采用與朗讀題型一樣的評分特征。在端到端方案中,對于詞組和句子朗讀題型,端到端模型接受朗讀語音和朗讀文本作為輸入,直接預測專家分。對于交際問答、復述和表達題型,端到端模型接受考生語音和識別結果,直接預測專家分。在非端到端方案中,語音識別、發音檢錯、內容及語義表征是核心。為提升最終的評分效果,算法I采用基于注意力機制的端到端語音識別系統,識別性能顯著超過傳統的混合識別系統,極大地提升了評分準確率,特別是交際問答這類短語音題型。為提升發音分析的準確度和區分性,算法I開發了基于端到端框架的音素發音檢錯模型,檢錯效果顯著優于傳統的基于GOP(Goodness of Pronunciation,計算機實現英語發音評價的一種算法)[7]的檢錯模型。在內容和語義表示方面,除了計算學生回答與參考答案詞級的淺層相似度之外,算法I還融合了基于LSTM(Long Short Term Memory Network,長短期記憶人工神經網絡)[8]、BERT(Bidirectional Encoder Representations from Transformer,來自變換器的雙向編碼器表征量)[9]等預訓練語言模型的句子和段落級的矢量化方法,獲得了更好的穩定性和準確性。
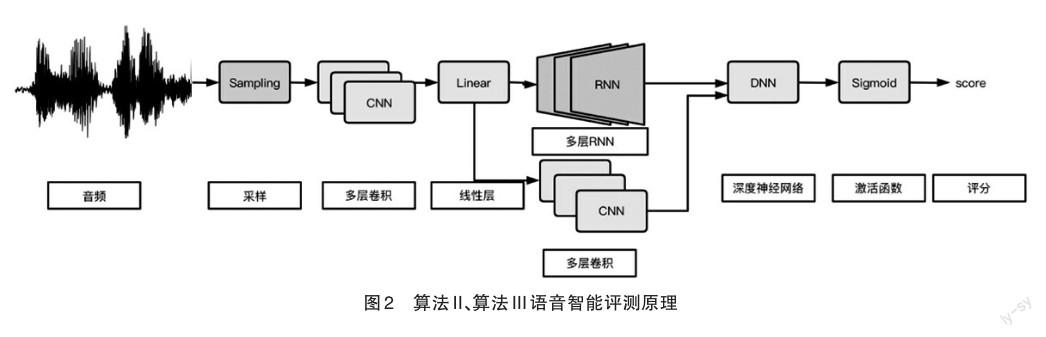
(2)算法II與算法III基本原理(如圖2):首先將原始語音信號輸入到模型中,對原始信號按照10ms的窗口進行采樣,在加快速度的同時,減少了信息的損失。將采樣后的信號輸入到卷積神經網絡[10],用卷積神經網絡進一步提取語音的局部不變性特征。經過卷積神經網絡得到的特征序列經過線性變換層,特征序列得到進一步映射。經過映射后的特征序列,被輸入到多層循環迭代神經網絡,提取完整的音頻上下文信息。同時,該特征序列輸入到多層卷積網絡,進一步捕獲局部不變形特征。將全局上下文信息與局部上下文信息進行拼接,得到最終的特征向量。該特征向量經過深度神經網絡,進行高維空間映射到一維。將一維分數經過sigmoid激活函數進行分數非線性變換,獲得最終的評分。
算法II與算法III的不同之處在于,兩類算法在語音識別準確性和內容特征矢量化方面均有所區別。在語音識別方面,以LSTM神經網絡為聲學模型,識別率已經達到90%以上,分別經過改寫和參數調整后,兩者差別不大。在內容矢量表示方面,基于 Word2vec[11]、LSTM、CNN(ConvolutionalNeural Network,卷積神經網絡)、Decoder-Encoder(解碼器和編碼器)[12]、RNN(Recurrent Neural Network,循環神經網絡)的內容表示分別部分融合使用,呈現出不同的結果,以進行研究和分析。
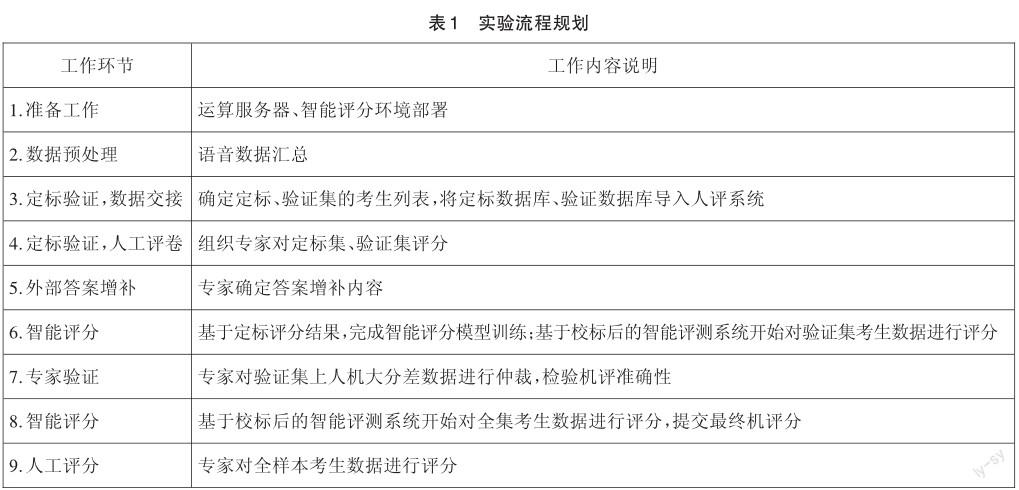
2.實驗流程規劃
如表1所示,整體實驗流程規劃確定了9個工作步驟,前7個工作步驟讓機器能真正學會理解評判的方法。
(二)設計思路
1.訓練評分方案
機器評分根據每個題型的特點選擇合適的特征,參考定標集人工評分的標準進行學習,然后用各個題型學習到的評分標準對全集數據進行評分。這樣就可以得到每個考生的小題機器分,然后按照各題的教師評卷規整方式(即教師評閱各題的最小顆粒度)進行規整,得到最終各個題型的機器分(見表2)。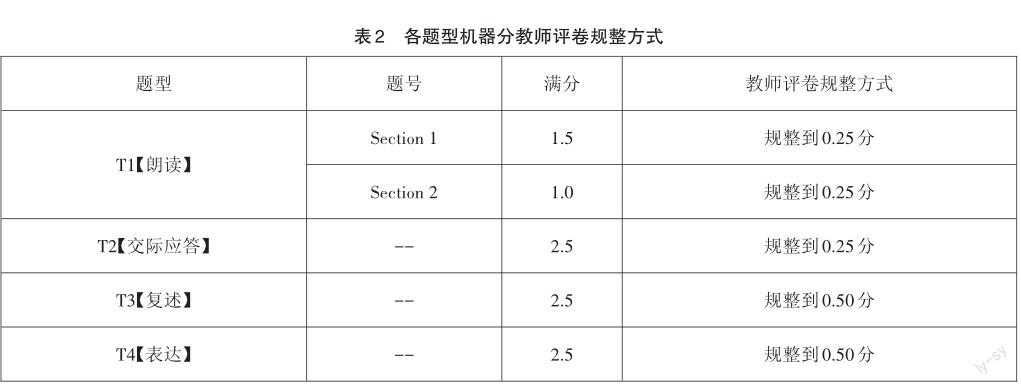
2.對比分析方案
本次實驗對比,基于上海市2021年度首次開考的初中外語聽說測試的全真模擬全部數據進行對比分析,以當次考試發布的報道分作為標準,三套算法基于同樣的定標集專家評分進行訓練出分,即算法 I、算法II、算法III的機評分,通過對比算法I、算法II、算法III與報道分的一致性,在確保機評分效果達到評卷要求的前提下,挑選最優效果算法作為機評主評,第二優效果算法作為機評副評,以報道分作為標準,探索雙機評模式的可行性,并同步驗證基于CPU(計算機中央處理器)運算的機評方案升級到基于GPU(高性能計算、深度學習訓練和推理的計算機處理器)運算的機評方案,所帶來的評分效果影響及效率提升情況。
實驗對比過程中涉及多個概念:報道分、機評分、專家仲裁等:
(1)報道分:外語聽說測試經過雙評+仲裁模式后,形成的對外發布的最終報道分,計算方式是:雙評分在分差閾值范圍內的采信雙評均分,超過分差閾值的交由專家仲裁,采信仲裁分。
(2)專家仲裁:經過雙評后,雙評分差超過分差閾值,由評卷組提交評卷專家進行人工仲裁。
(3)算法I:算法I的機評分。
(4)算法II:算法II的機評分。
(5)算法III:算法III的機評分。
3.評價指標定義
本次實驗中所需用到的評價指標定義如下:
(1)得分率
得分率為考生成績的平均分與滿分的比值換算成的百分數。它反映試題的難易程度,得分率越高說明題目越簡單,反之則越難。
(2)標準差
標準差是方差的算術平方根。標準差能反映一個數據集的離散程度。平均數相同的兩組數據,標準差未必相同。
(3)相關度

相關度的取值范圍介于-1~1之間,越接近1表示兩組評分的排序關系越接近。
(4)一致率
假設評分設定的仲裁閾值是m分,將一組評分與報道分之間誤差絕對值小于等于m分的數據占總評分數量的比例稱為一致率。一致率反映了在允許誤差范圍內評分的準確性,取值范圍介于0~1之間,越接近1越好。
(三)實驗結果分析
1.實驗數據集說明
本實驗中的數據為初中外語聽說測試全真模擬數據,所用的數據集包含定標集與驗證集,定標集是機器用于學習評分標準的數據集合,驗證集是用于檢驗機器評分性能的數據集合,機評全集是計算機能夠正常評卷的數據集合。由于本實驗已有全集報道分,故使用機評全集數據進行比對分析。表3列出了本次驗證各題的定標集和驗證集數量、全集數量、滿分以及仲裁閾值。仲裁閾值是根據專家組給定的雙評大分差上限,超過閾值則表示兩個評分之間誤差過大,兩評均不可信,會交由仲裁專家進行仲裁。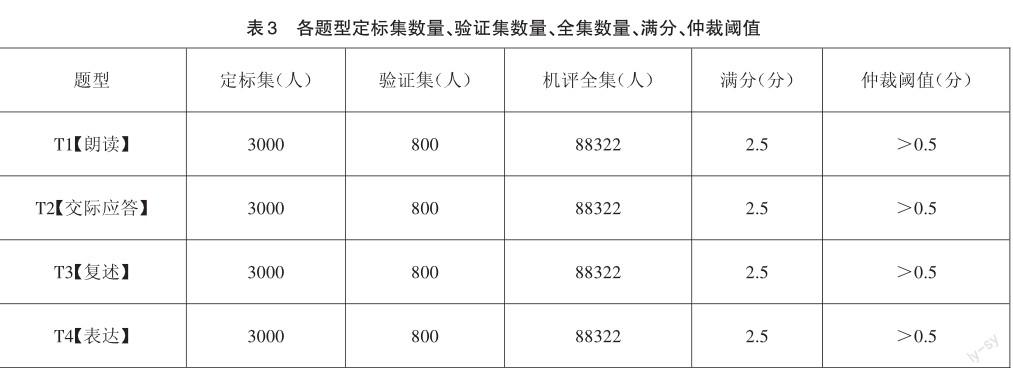
2.算法I、II、III與報道分的效果對比分析
在機評全集的88322份樣本上,以報道分為標準,分別對算法I、算法II、算法III的機器評分效果進行對比分析。T1【朗讀】、T2【交際應答】、T3【復述】、T4【表達】4類題型依據相關度、一致率指標對機器評分效果進行對比分析的結果如表4~8所示。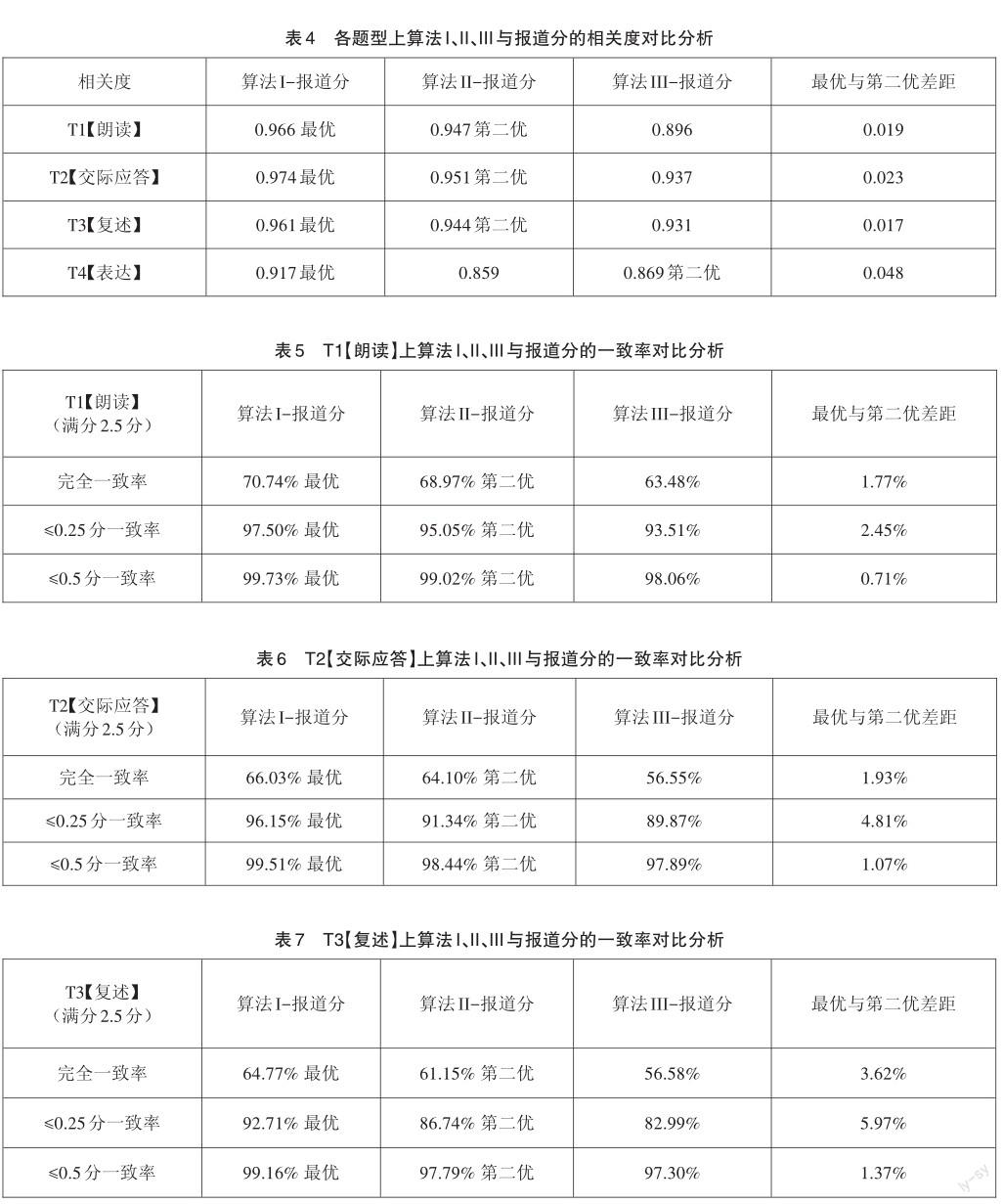
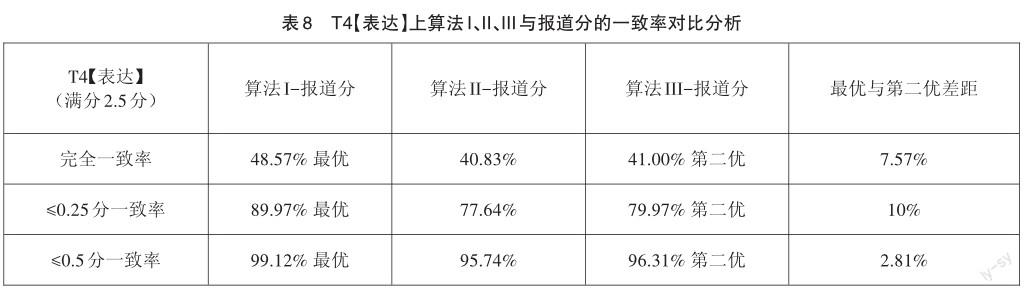
分析表4~8可以發現:
(1)從相關度、完全一致率、≤0.25分一致率和≤0.5分(滿分2.5分)一致率上看,T1【朗讀】、T2【交際問答】、T3【復述】、T4【表達】4類題型機器評分效果最優的均是算法I,T1【朗讀】、T2【交際應答】、T3【復述】題型效果排第二的是算法II,T4【表達】是算法III。
(2)從≤0.25分一致率指標來看,在T1【朗讀】題型,效果最優與第二的一致率差異為2.45%,且一致率均超過95%,效果較好;在T2【交際應答】、T3【復述】、T4【表達】題型,效果最優與第二差異為4.81%~ 10%不等,算法II、算法III在這些題型仍需持續優化效果。
3.雙機評可行性分析
依據算法I、算法II、算法III與報道分對比分析結果,擬采用效果最優的算法I作為機評主評(以下簡稱評1)、效果相對較優的算法II作為機評副評(以下簡稱評2),探索雙機評模式的可行性;雙機評模式下,評1與評2的分數在分差閾值范圍內,采信機器評分,取評1和評2的均分作為最終分;分數在分差閾值以外的,由評卷組安排專家仲裁,仲裁分作為最終分。
對T1【朗讀】、T2【交際應答】、T3【復述】、T4【表達】4類題型,評1和評2的分數進行對比如表9、表10所示,共計僅有2758份樣本需專家仲裁,教師評卷工作量顯著降低。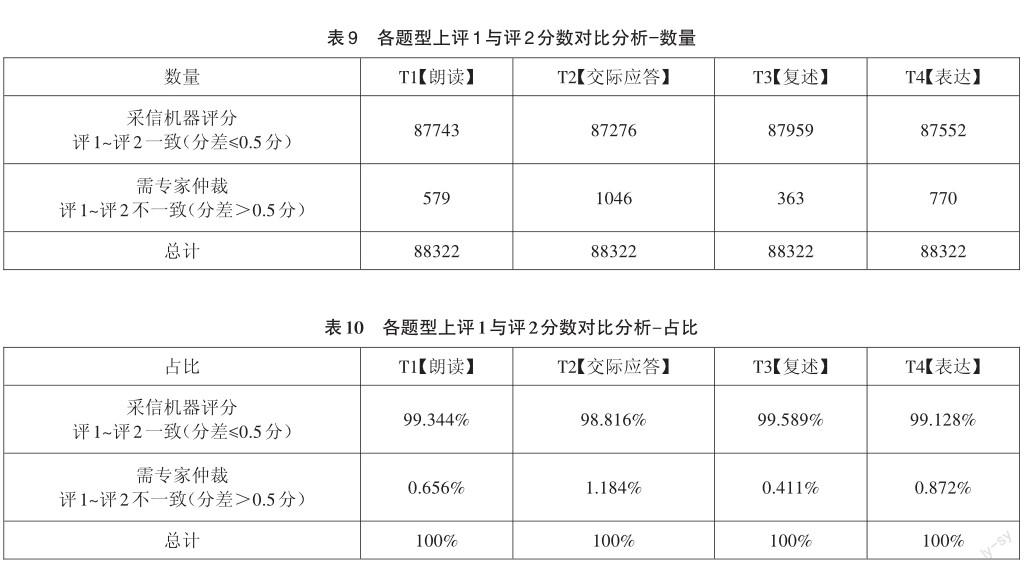
針對需專家仲裁樣本集,即評1與評2不一致(分差>0.5分),評卷組需按照專家進行仲裁評分,仲裁分作為最終分進行發布,該數據集上不存在效果風險。
在采信機器評分樣本集上,即評1與評2一致(分差≤0.5分)的樣本集上,取評1和評2的平均分(以下簡稱“均分”)與報道分進行對比分析,如表11、表12所示。從4個題型均分與報道分分差分布指標來看,存在1659份樣本均分與報道分相差超過0.5分,會造成評分偏誤;針對上述大分差樣本進行深度分析,對集合上報道分的評分分布進行統計如表13所示,無有效途徑對效果風險進行檢出。另外,從≤0.25分一致率指標來看,T3【復述】、T4【表達】題型上報道分與均分一致率較低。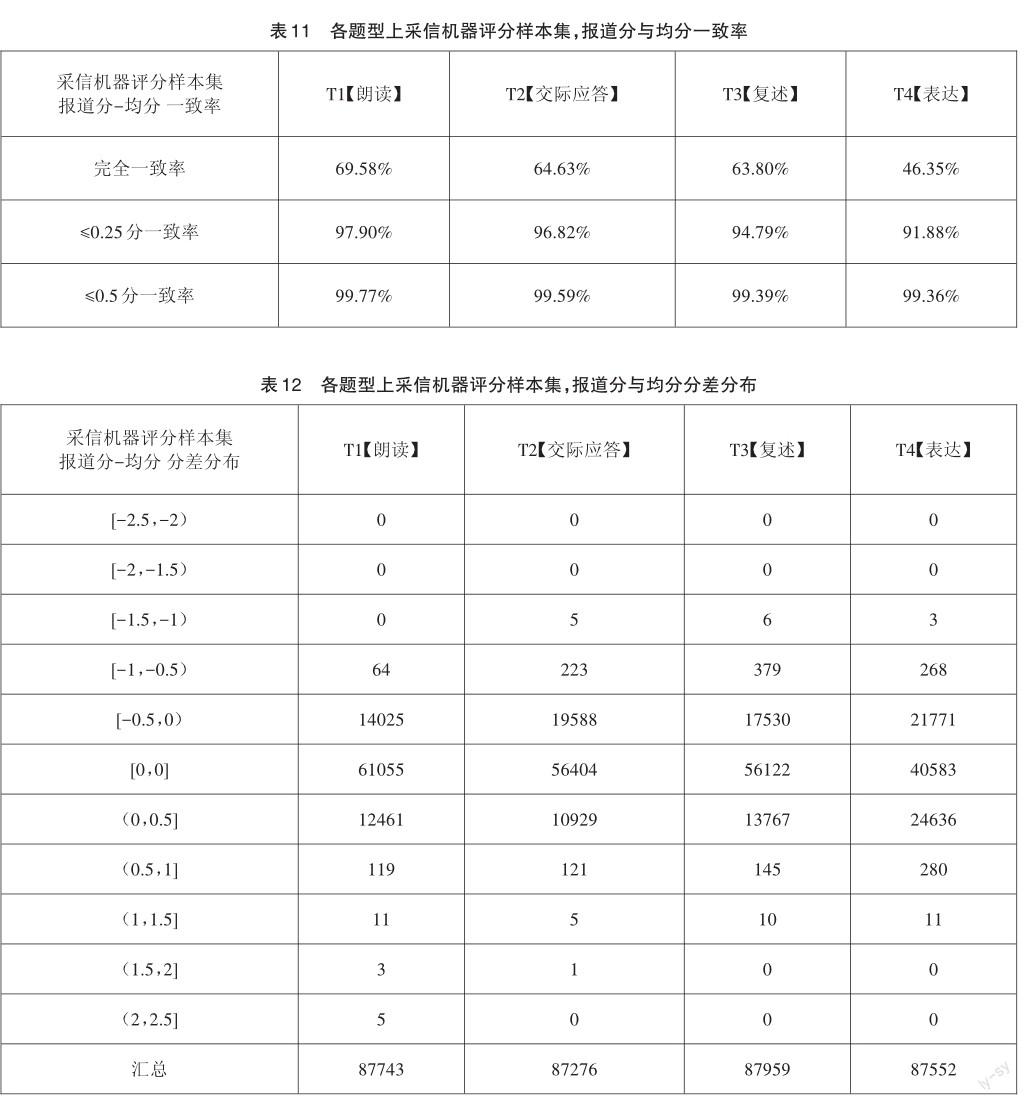
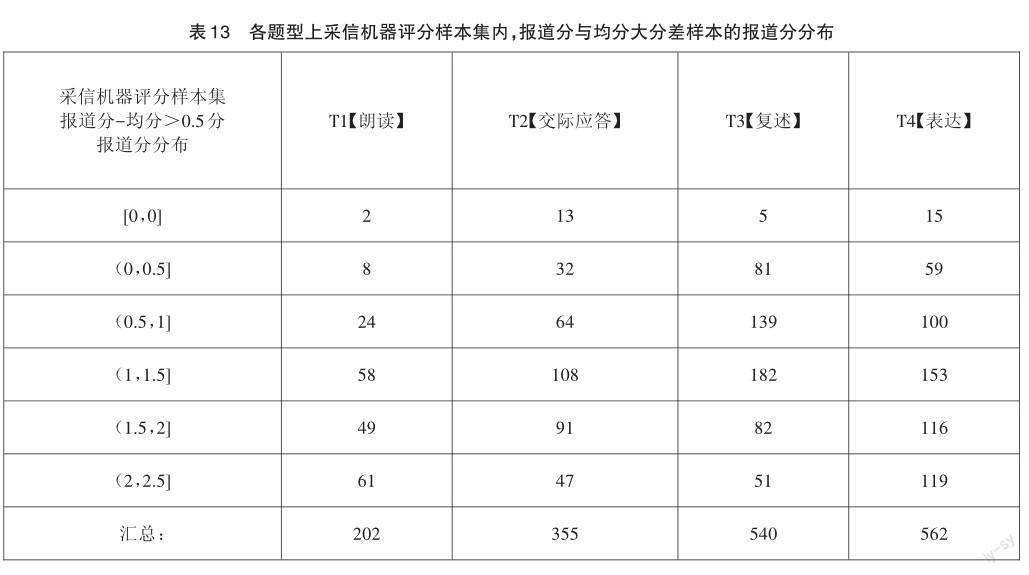
綜上所述,針對英語聽說測試場景的雙機評方案,從評卷組織上能夠極大地降低教師評卷工作量;但從評卷質量保障上,存在1659份樣本雙機評后與報道分產生大分差的效果風險,暫不具備可行性,仍需智能評分技術的持續進步以及評卷組織流程上針對性的完善,才能更好地推進方案執行落地。
4. GPU方案驗證分析
本次實驗,針對算法I,同步對機評全集數據進行CPU方案和GPU方案的對比分析論證。保證在相同的數據基礎上進行CPU與GPU不同版本的評分,針對這兩種評分方式的結果從時間效率、評分效果上進行了對比分析,其結果如下:
(1)時間效率對比:GPU評分效率遠遠優于CPU評分效率,一臺雙GPU顯卡服務器的運行效率相對于一臺CPU服務器的效率提升6倍。
本次考試參與口語評分的人數約8.8萬,在中考評測過程中使用了11臺CPU服務器,同步使用2臺GPU服務器進行驗證。為了直觀地呈現CPU服務器與GPU服務器在口語評分中的時間性能差異,對本次評分中涉及的主要時間進行了統計,如表14所示。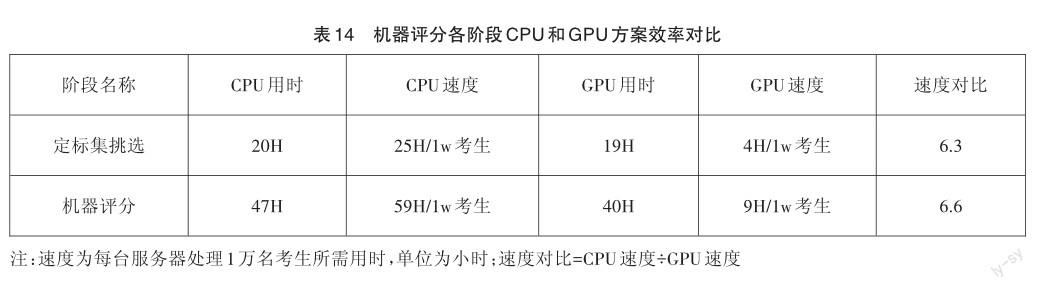
考慮到后期上海中考人數可能增加的情況,對服務器數量使用進行了估算。根據本次口語評分時間效率的統計,若保證目前的評分周期不變,對10萬名考生進行評分,所需要的CPU與GPU服務器配置和數量如表15、表16所示。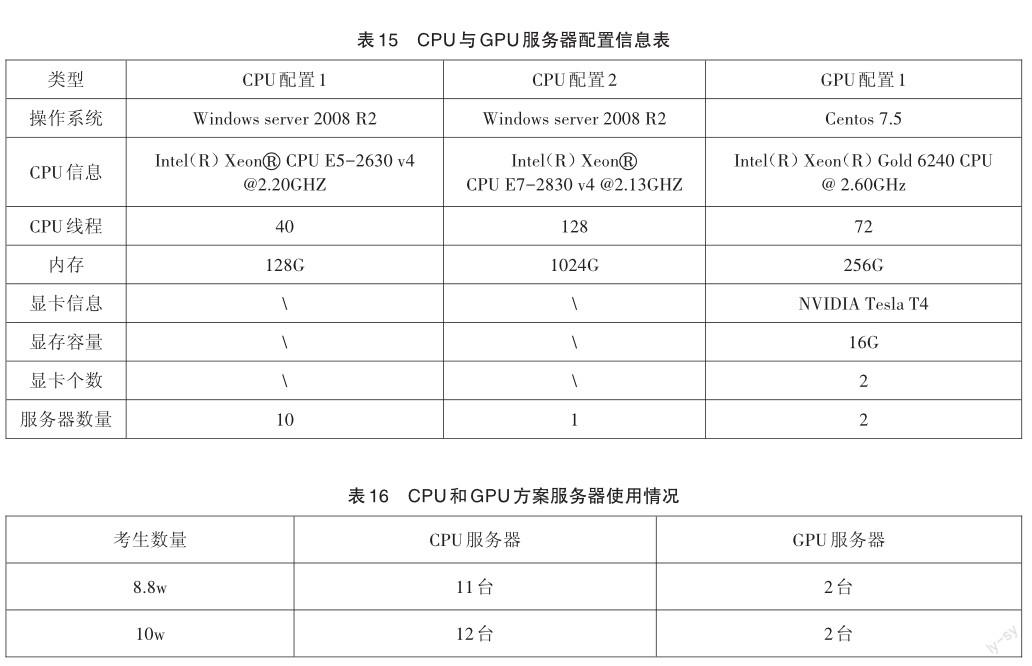
(2)評分效果對比:基于得分率、標準差、相關度、一致率等指標對兩次評分進行對比,證實GPU評分效果略低于CPU的評分效果。
表17分別基于得分率、標準差等指標對各題型得分與總分進行對比。可以看出:GPU分與報道分之間的得分率最大差異為0.03、標準差最大差異為0.06,效果基本相當;GPU分與CPU分得分率最大差異是0.01、標準差最大差異為0.05,基本一致。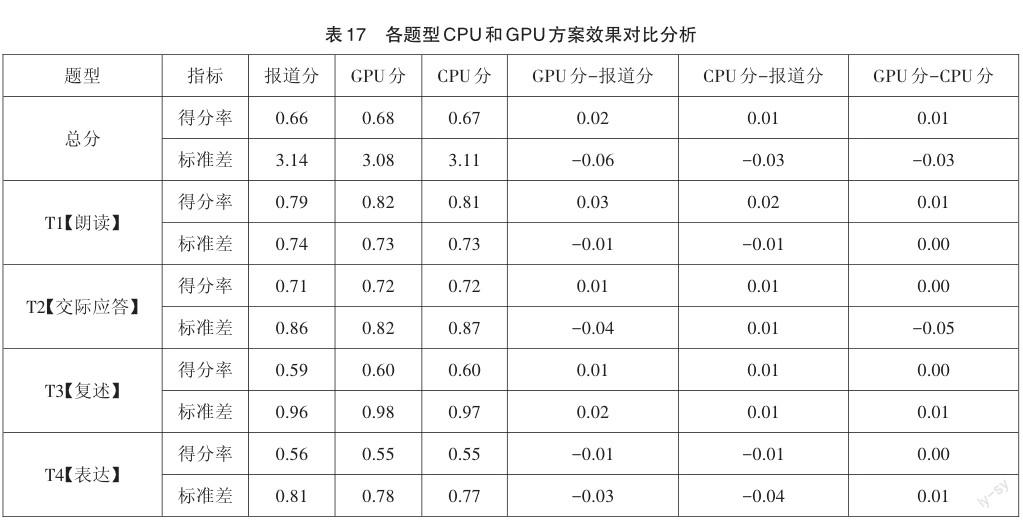
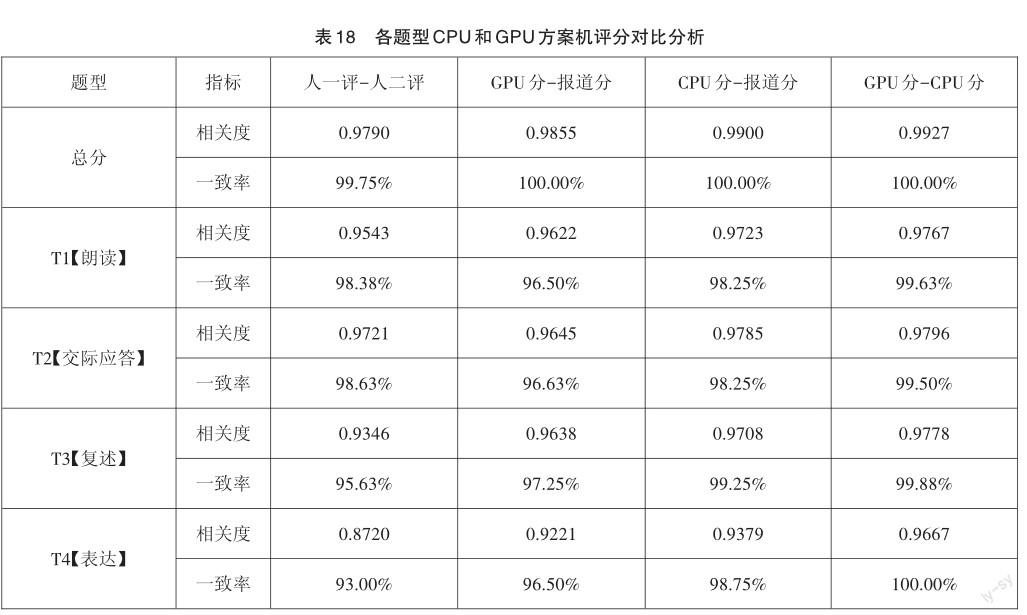
基于相關度、一致率(閾值范圍內)指標對驗證集上每個題型得分與總分進行對比,結果如表18所示:總分上,GPU分與報道分的相關度、一致率高于人一評和人二評之間的統計結果,而與CPU分和報道分的統計結果基本相當;復述題、表達題上,GPU分與報道分的相關度、一致率明顯高于人一評和人二評之間的統計結果,略低于CPU分和報道分;朗讀、交際應答上,GPU分與報道分的一致率略低于人一評和人二評,CPU分與報道分的相關度、一致率與人一評和人二評相當。
綜上,基于本次實驗結果分析,可以得出結論:
第一,GPU在評分效率上有明顯優勢,基于目前提供的評分設備,1臺搭載NVIDIA T4雙GPU卡服務器的性能相當于6臺搭載Intel Xeon 20核40線程CPU服務器。
第二,GPU評分效果在復述、表達題上與CPU評分效果相當,在朗讀、交際問答題上還有差距,有待進一步改進。
三、實驗總結及展望
人工智能是引領未來的新興戰略性技術,是驅動新一輪科技革命和產業變革的重要力量。習近平總書記多次作出重要指示,強調“要深入把握新一代人工智能發展的特點,加強人工智能和產業發展融合,為高質量發展提供新動能”。
此次針對上海市2021年度首次開考的初中外語聽說測試的全真模擬數據進行的計算機智能評分,是一次突破性的創新和實驗,更是一次智能閱卷替代人工閱卷的有益嘗試。其在評分過程中呈現的智能程度、算法的先進性、結果的準確性和極高的效率等,都代表著未來專業化考試機構人工智能的應用方向,也為今后計算機智能評卷從后臺走向前臺,由離線方式變為實時、動態應用方式奠定了良好的基礎。
(一)智能測評技術應用評分準確性
計算機智能評分已經形成了一套完善的“端到端”的識別處理方案。在語音識別方面,深度卷積神經網絡與隱馬爾科夫模型結合的(CNN-HMM)模型,構建一個狀態網絡并從中尋找與聲音最匹配的路徑,能夠準確進行語音識別。在英文識別方面,主要采用深度遞歸網絡識別算法(RNN),該算法已經成熟并廣泛應用于拉丁語系文字的識別中,且已被證明具有良好的識別效果。本次計算機智能評分中,對語音的識別率均已經達到了97%以上,能夠滿足自動評卷的要求。從最終人機對比結果可以看出,計算機智能評分與報道分的一致率達到了97%。另外,由于評卷教師在長時間、高強度的評分過程中,極易身心疲憊,一定程度上會影響評卷教師對評分尺度的把握和評分一致性的把控,甚至出現打保險分的現象,而計算機智能評分不會受到情緒、身心狀態、個人喜好等主觀因素的影響,能夠始終采用統一的標準進行評測,從而很大程度上保證了評分的客觀公正性。
1.算力效果提升評分效率
隨著上海初中考生人數的增加,在評分周期不變情況下如何減少智能評卷對硬件的要求顯得十分重要,使用GPU機評方案提升機評效率勢在必行。
從本次GPU機評驗證的結果看,在得分率、標準差、評分分布等基礎指標上,GPU機評分已經接近或達到人工評分水平,但整體效果略低于CPU評分,需要后期進一步的優化改進。可能的原因在于:第一次對于新考試的新題型進行機評,還需不斷地訓練,在避免過度擬合的情況下進行迭代。后期計劃對GPU評分策略做進一步改進,需經過多輪驗證,確保GPU評分達到與CPU一致的水平,才能最終使用GPU評分取代CPU評分。
2.三類獨立算法的改進方向
智能測評技術在語音評卷中還需不斷改進和優化,本文三類獨立算法在內容維度的評分特征均無法自主直接提取,目前業內其他各類智能測評的應用中,對于語音也無法全覆蓋地進行答案枚舉。存在的問題就是沒有標準答案,答案不可窮舉,機器不知道什么樣的作答是高分、中分和低分。雖然有人工定標訓練,靠人工提取定標得分特征,通過選取的包含高、中、低水平的數據,進行人工打分,機器依據人工打分學習高低分的回答模式三種途徑,但由于訓練集和驗證集均是機器選取的,選取的合理性、科學性、代表性還有待進一步研究。可見,智能測評技術通用性的研究還需持續進行,本次實驗中使用的算法還需不斷迭代,在防止過度擬合的前提下保證機器評閱得更加精準,但從實際使用的角度也只能保證機器在某一項考試或者某一種類別(即語音且是英語的作答)中進行評判,真正的廣泛性還需商榷。
(二)對未來考試評卷智能化應用的展望
近年來計算機智能評卷技術在大規模紙筆考試和計算機考試中的應用,已經驗證了智能評測技術的實用性和可靠性。當前針對外語聽說測試場景,使用人機互評+專家仲裁的評卷模式,已經能夠高效率、高質量地保障評卷工作;但是,使用雙機評模式,經過本輪實驗驗證,當前仍存在評卷質量風險;另外,以采信機器評分為主的雙機評模式,仍需要解決社會認可度、可解釋性、多套算法如何同步進行技術升級、評卷組織過程如何監控質量等具體問題。
在后續的研究中,需從三個方面持續推進評卷智能化進程。第一,智能評卷技術的持續優化迭代:歷年聽說外語測試積累的龐大數據集,以及語音識別、自然語義理解、多維度智能評測等技術上的持續進步,是智能評卷技術效果穩定的保障。第二,評卷組織流程上,需要針對雙機評模式設計完備的效果保障機制、運營監控機制以及應急預案:具體來說,仍需建立一套以人工評卷校驗為核心的效果保障機制,防范雙機評出現系統性評分偏誤,由此產生的人工評卷工作量及保障機制也需深入研究;仍需具備隨時切換人機互評的應急預案,保障機評出現系統性評分偏誤后評卷的正常開展;需要建立自動化、可視化的運營監管機制,保障機評效率及穩定性。第三,以采信機器評分為主(僅少量人工校驗)的雙機評模式需要完備的可解釋性,需要建立并完善對智能評分結果的評價機制。
總之,要充分抓住目前人工智能高速發展的大好機遇,加強每次大規模驗證和應用之后的數據分析工作,逐步建立一套完整的、科學的對評分結果的評價機制,全力推進人工智能向應用成果的轉換。
參考文獻:
[1]國家發改委,科技部,工信部,等.“互聯網+”人工智能三年行動實施方案[EB/OL]. [2023-01-11]. http://www.gov.cn/xinwen/2016-05/23/content_5075944.htm.
[2]中共中央,國務院.中國教育現代化2035[EB/OL].[2023-01-11].http://www.gov.cn/xinwen/2019-02/23/content_5367987.htm.
[3]中國信息通信研究院.人工智能白皮書(2022年)[C].2022.
[4]何屹松,徐飛,劉惠,等.新一代智能網上評卷系統的技術實現及在高考網評中的應用實例分析[J].中國考試,2019,(1):57-65.
[5] Mao S,Wu Z,Jiang J,et al. NN-based Ordinal Regression for Assessing Fluency of ESL Speech [C] // ICASSP 2019 - 2019 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP). IEEE,2019.
[6] B. Lin,L. Wang,X. Feng,and J. Zhang,Automatic Scoring at Multi-granularity for l2 Pronunciation [C] // Interspeech,2020.
[7] Witt S M,F S J Y. Phone-level Pronunciation Scoring and AssessmentforInteractiveLanguageLearning[J].Speech Communication,2000,30(2/3):95-108.
[8] Sundermeyer M,Schlüter R,Ney H. LSTM Neural Networks for Language Modeling [C] // Thirteenth Annual Conference of the International Speech Communication Association,2012.
[9] Devlin J,Chang M W,Lee K,et al. Bert:Pre-training of Deep Bidirectional Transformers for Language Understanding [J]. arXiv preprint arXiv:1810.04805,2018.
[10] Hori T,Watanabe S,Zhang Y,et al. Advances in Joint CTCattention Based End-to -end Speech Recognition with a Deep CNN Encoder and RNN-LM [J]. arXiv preprint arXiv:1706.02737,2017.
[11] Mikolov T,Chen K,Corrado G,et al. Efficient Estimation of Word Representations in Vector Space [J]. arXiv preprint arXiv:1301.3781,2013.
[12] Bahdanau D,Cho K,Bengio Y. Neural Machine Translation by Jointly Learning to Align and Translate [J]. arXiv preprint arXiv:1409.0473,2014.
Feasibility Study of Intelligent Dual-machine Speaking Assessment Mode in Computer-based Foreign Language Listening and Speaking Test
Shen Chen Luo Shuanghu
Shanghai Municipal Educational Examinations Authority,Shanghai,200433
Abstract:Based on the existing evaluation mode of human-computer mutual assessment of English listening and speaking test,the feasibility of dual-computer evaluation mode was tentatively explored,and three independent computer intelligent scoring algorithms were compared by using the full-real simulation data test of Shanghai junior high school foreign language listening and speaking test. The results show that the consistency between the machine score and the report score reaches more than 96%,which has good results,but there is a risk that the effect of 1659 samples is still misjudged after the dual-machine evaluation,and the evaluation organization and evaluation mechanism of the dual-machine evaluation mode are still incomplete,and the dual-machine evaluation mode is not feasible for the time being,and further algorithm improvement and application method research are needed. The comparative verification results show that the scoring speed of the scoring algorithm using the GPU computing power structure is equivalent to 6 times that of the CPU computing power structure without the decrease in scoring accuracy,which can greatly reduce the time and hardware spent on scoring.
Key Words:Junior Entrance Examination,Foreign Language Listening and Speaking Test,Computer Intelligence Scoring
附件:
初中外語聽說樣卷
I. Read aloud朗讀(5小題,共2.5分)
Section 1:
Directions:Read the following phrases. You will have 10 seconds to prepare and 15 seconds to read.
朗讀詞組。準備時間為10秒,朗讀時間為15秒。(3小題,共1.5分)
1. national flag
2. look after the children
3. surprised at the news
Section 2:
Directions:Read the following sentences. You will have 10 seconds to prepare and 20 seconds to read.
朗讀句子。準備時間為10秒,朗讀時間為20秒。(2小題,共1分)
1. Would you come to my birthday party?
2. John is talking about the TV programme with his friends.
II. Quick response交際應答(5小題,共2.5分)
Directions:You will hear five sentences. Make quick responses to the sentences you have heard. For each sentence,you will have 5 seconds to prepare and 10 seconds to answer.
根據你聽到的句子作出應答,每個句子準備時間為5秒,答題時間為10秒。
1.
2.
3.
4.
5.
III. Retell復述(1小題,共2.5分)
Directions:Retell what you hear with the given points. You will hear the recording twice. You will have 60 seconds to prepare and 60 seconds to retell.
你將聽到一段音頻,請根據所給要點進行復述。錄音播放兩遍。準備時間為60秒,答題時間為60秒。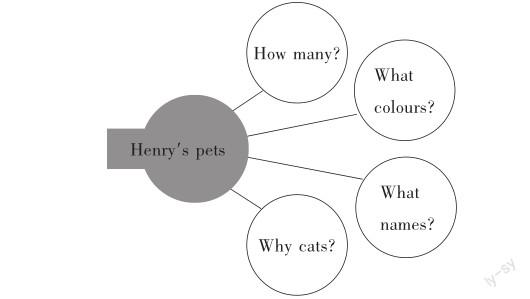
你的復述可以這樣開始:Henry keeps pets at home...
IV. Free talk表達(1小題,共2.5分)
Directions:Say at least five sentences according to the following information. You will have 60 seconds to prepare and 60 seconds to talk.
根據以下提示進行表達,至少講5句話。準備時間為60秒,答題時間為60秒。
你的表達必須包含以下要點:
1. What are the people in the picture doing?
2. What can you learn from the boy?
初中外語聽說樣卷參考答案及評分標準
I.朗讀
Section 1:
1. national flag辨音
清晰、正確朗讀2個單詞得0.5分
清晰、正確朗讀1個單詞得0.25分
清晰、正確朗讀0個單詞得0分
2. look after the children連讀
清晰、正確朗讀look after,the children 2個詞塊得0.5分
清晰、正確朗讀1個詞塊得0.25分
清晰、正確朗讀0個詞塊得0分
3. surprised at the news失爆
清晰、正確朗讀surprised,at the news 2個詞塊得0.5分
清晰、正確朗讀1個詞塊得0.25分
清晰、正確朗讀0個詞塊得0分
Section 2:
1. Would you come to my birthday party?(語調)
清晰、正確體現升調得0.25
清晰、正確朗讀句子得0.25,讀錯1個單詞不扣分(讀錯≥2個單詞扣0.25分)
2. John is talking about the TV programme with his friends.(意群和停頓)
意群和停頓不影響理解得0.25
清晰、正確朗讀句子得0.25,讀錯1個單詞不扣分(讀錯≥2個單詞扣0.25分)
II.交際應答
0.5分能對所給的句子進行恰當應答
0.25分能應答,但應答不完全符合英語表達習慣
0分不能應答或應答不符合英語表達習慣
1. Thanks. / Thank you./ ...
2. Once a week. / Twice a month. / Every day. / Never.
3. Its worth watching. / This is the most exciting film that Ive ever seen. / Boring. / Interesting. / Fantastic...
4. Of course/ Certainly./ No problem. / Sorry,Im using it myself. / Sorry,Ive just lent it to Alice. /Sure.
5. Congratulations! / Good for you! / Great! / Good job! / Im glad to hear that. / You must have put a lot of effort into it. / You must have worked hard for it. / How nice! / How marvelous!
III.復述
Key points:
1. Henry has two pet cats.(0.5)
2. One is a black cat named Tommy.(0.5)
3. The other is a white cat called Kitty.(0.5)
4. Cats can take care of themselves(but dogs need people to walk them every day).(0.5)
5. Cats are quiet(but dogs usually make a lot of noises).(0.5)
IV.表達
Key points:
1. What
do housework;wipe the window;clean the floor;stand on a chair to clean the upper part of the window…
2. Opinion
learn to keep ones home clean and tidy;learn to share housework;show love for;form the habit of…
參考答案:
The people in the picture are doing housework. The boy is wiping the window while his mother is cleaning the floor. The boy is not tall enough,so he is standing on a chair to clean the upper part of the window. We can learn from the boy that we should share housework with our parents. And we should form the habit of doing housework.
2.5分內容完整充實,表達流暢連貫,語言結構和用詞基本正確。
2分內容完整、較充實,表達較流暢連貫,語言結構和用詞基本正確。
1.5分內容較完整充實,表達基本流暢連貫,語言結構和用詞存在較多錯誤,但不影響理解。
1分內容不完整,表達欠流暢連貫,語言結構和用詞存在較多錯誤,但不影響理解。
0.5分僅能說出個別單詞。
0分無法表達或表達內容與所給提示完全不符。
只能講述4句,得分不高于2分
只能講述3句,得分不高于1.5分
只能講述2句,得分不高于1分
只能講述1句,得分不高于0.5分
(責任編輯:吳茳)
猜你喜歡
中學生數理化·中考版(2021年8期)2022-01-01 06:10:59
中學生數理化·七年級數學人教版(2021年12期)2021-12-31 05:16:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:50
中學生數理化·中考版(2021年5期)2021-11-22 07:50:26
中學生數理化·七年級數學人教版(2021年5期)2021-11-22 07:24:28
中學生數理化·中考版(2021年8期)2021-07-31 07:41:48
學生天地(2020年9期)2020-08-25 09:13:52
中學生數理化·中考版(2018年11期)2019-01-31 06:18:02
初中生世界·九年級(2017年10期)2017-11-08 16:44:15
中學生數理化·七年級數學人教版(2017年10期)2017-04-23 06:29:16
