基于多元概化理論的英語口語測試任務研究
2023-12-12 22:27:17吳泓霖
考試研究 2023年3期
[摘要]基于多元概化理論,對某次口語測試所包含的朗讀、聽后回答、回答問題、聽后復述四類常見的測試任務進行研究,重點關注不同類型測試任務的區(qū)分效果、測量精度和對總分的貢獻程度。研究結果表明,偏封閉型、內容導向的測試任務相比偏開放型、技能導向的測試任務,在區(qū)分效果、測量精度和對總分的貢獻上表現(xiàn)更好。
[關鍵詞]口語測試任務;多元概化理論;計算機化考試
[中圖分類號]G424.74[文獻標識碼]A
[文章編號]1673—1654(2023)03—051—008
一、引言
(一)口語測試任務
口語測試是語言測試研究和實踐的重要領域。根據考官的參與程度,一般可分為直接型、半直接型、間接型口語測試[1]。間接型口語測試現(xiàn)在已經很少使用,例如,早期的語音測試是讓考生在紙筆考試中選擇與對應音素發(fā)音不同的單詞,不需要進行口頭交流。直接型口語測試主要采用現(xiàn)場面試型口試的方式,由一位或多位考官對一位或多位考生進行面對面的口語測試,例如雅思(IELTS)、劍橋通用五級(Main Suite)和全國英語等級考試(PETS)各個級別的現(xiàn)場口試等。隨著信息技術的廣泛應用,目前最為主流的是半直接型口語測試,主要采用計算機化考試的實施方式。計算機化考試的研究和實踐開始于20世紀70年代[2],歷經多年探索,伴隨著計算機技術和語言測試理論的融合發(fā)展,其應用已經日漸成熟。目前,國外知名的語言類考試大多已經推出了計算機化考試,例如托福網考(TOEFL iBT)、雅思機考(IELTS CBT)、劍橋領思(Linguaskill)等。國內的語言類考試實行計算機化考試主要集中在口試的改革中,例如大學英語四、六級口語機考,以及部分省市(北京、上海、天津、廣東等)高考英語的口語機考。相關研究表明,實行口語機考對教學產生了良性的引導作用,促進了學生聽、說能力的發(fā)展[3]。
設計口語測試時,設定測試任務十分重要,它不僅是測試本身構念定義的直接反映,也會對語言學習產生反撥作用。口語測試任務可以理解為說話者在特定的口語交際場景下,為了實現(xiàn)某種交際目標而使用語言的活動[4]。口語測試任務可以有不同的分類維度,包括技能的綜合性、任務的開放性、交談內容是事實性還是評價性、任務設計是基于構念還是基于任務、所測能力屬于宏觀還是微觀等[5]。以計算機化口語測試為代表的半直接型口語測試中,最為常見的任務類型包括朗讀、情景問答、看圖說話、回答問題、聽后回答問題、故事復述等,這些任務已在相關省市的高考英語口語機考中被廣泛使用。
(二)多元概化理論
概化理論是現(xiàn)代心理測量理論之一[6],雖然出現(xiàn)較晚、統(tǒng)計要求比較繁瑣,但隨著計算機技術的發(fā)展,其應用范圍越來越大,包括常模參照性測驗、標準參照性測驗、非標準化測驗、表現(xiàn)性評價等,受重視程度日漸提升。
根據概化理論,傳統(tǒng)意義上測量信度的概念被概化系數或可靠性系數取代[7]。概化理論重點關注分數差異與相關影響因素(例如考生能力、試題難度等)之間的關系。在經典測量理論的基礎上,概化理論引進了實驗設計和方差分析技術[8],可以分離各類誤差的方差,并估算出不同方差成分的大小,用于探究不同因素對分數差異造成的影響和各個因素之間的交互作用,這個過程被稱為概化研究或者G研究。在此基礎上,概化理論還能通過實驗性研究估算出不同條件下概化系數的變化,尋找最佳的誤差控制方法,幫助考試設計者優(yōu)化試卷設計,這個過程被稱為概化理論的決策研究或D研究。
多元概化理論是概化理論的進一步發(fā)展,主要適用于具有多個全域分數等方面問題的研究,例如分析當總測驗被分解成多個分測驗時,分測驗的信度和試題數量變化對總測驗信度造成的影響[9]。近年來,多元概化理論被廣泛應用于高考等大規(guī)模高利害考試的評價中,可定量比較試卷中各個內容模塊和相關題型的區(qū)分度與內部一致性,為試卷質量研究提供了理論模型和方法依據,有助于考試命題質量的提高。基于多元概化理論對口語測試進行研究,可以分析各項測試任務的區(qū)分功能和測試信度,探究不同任務對總分的貢獻程度,便于考試設計者調整測試設計,進而更好地達到預期的測量效果。
二、研究設計
(一)研究問題
基于定量分析回答不同類型口語測試任務的三個問題:
1.區(qū)分效果分別是什么樣的?
2.測量精度分別是什么樣的?
3.對總分的貢獻程度分別是什么樣的?
(二)研究工具
基于高考英語學科對于關鍵能力中口語表達的界定[10],結合常見的口語測試任務類型,設計和實施了一次研究性英語口語測試,采用了計算機化考試的形式。如表1所示,本次口語測試滿分分值為10分,共11道試題,包含朗讀、聽后回答、回答問題、聽后復述四項任務,測試過程中允許考生做筆記。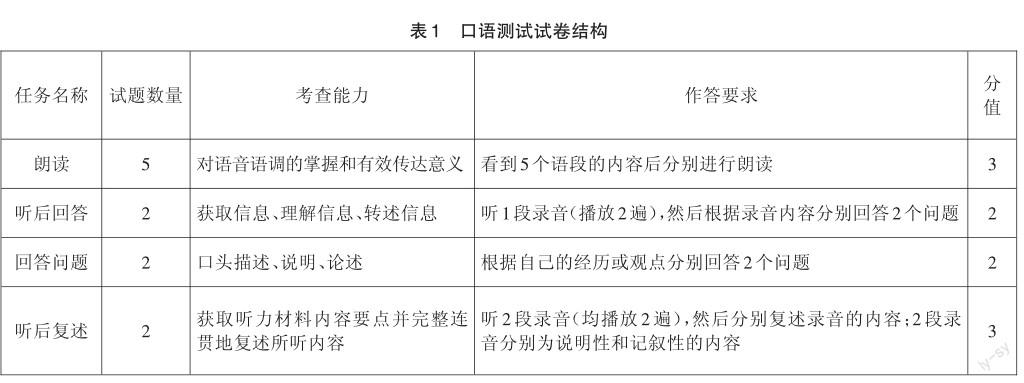
參加本次口語測試的受試者為華東某省2所中學的高二年級學生,有效樣本共725份,其中男生約占45%,女生約占55%,學生的英語口語水平基本覆蓋了好、中、差各個層次。
(三)評分設計

10名評分員均為來自高校的英語教師,具有大型考試的閱卷經驗。正式評分開始前,評分員接受了培訓,熟悉了評分標準并進行了試評分,以保證評分尺度的一致性。
(四)數據分析
采用mGENOVA 2.1程序進行多元概化分析全體有效樣本共725份。按照口語測試任務的結構,將全部試題劃分為“朗讀”“聽后回答”“回答問題”“聽后復述”4個分測試,使用了4因子單面交叉設計p×i多元概化模型,p代表受試者(測量目標),i代表試題(測量側面),分別計算各項口語測試任務和整個測試的概化系數(即信度)。在此基礎上,結合相關信息分析各項口語測試任務對整個測試的貢獻程度。
三、結果與討論
(一)描述性統(tǒng)計
各項測試任務的平均得分率從高到低依次為回答問題(68.18%)、朗讀(66.75%)、聽后回答(66.18%)、聽后復述(45.22%)。這表明,相比其他三項任務,聽后復述的平均得分率較低,任務難度相對較大。
(二)四因子模型的G研究
基于四因子概化模型的G研究,得到考生效應(p)、試題效應(i)及考生和試題之間的交互效應(pi)在四個因子上的方差與協(xié)方差分量的估計矩陣,如表2所示。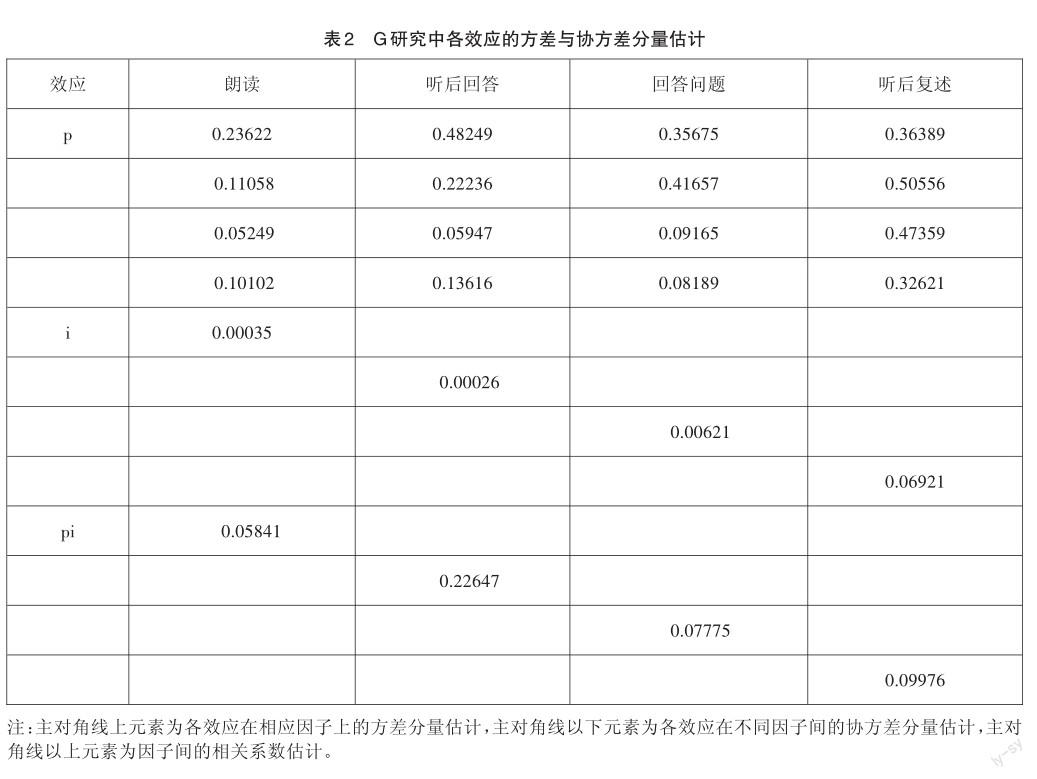
考生效應(p)反映由于考生水平差異導致的成績變異大小。從表2可以看出,四個因子中考生效應(p)方差分量從大到小依次為聽后復述(0.32621)、朗讀(0.23622)、聽后回答(0.22236)、回答問題(0.09165)。這表明,在本次口語測試中,聽后復述對不同水平考生的區(qū)分作用最大,朗讀和聽后回答的區(qū)分作用大致相當,回答問題的區(qū)分作用最小。可能導致這一現(xiàn)象的原因是:回答問題任務的開放性較大,考生發(fā)揮的空間也比較大,緊扣主題言之成理即可得到一定分數,因此比較難以區(qū)分不同水平的考生,而其他三項任務對考生作答的評判具有相對剛性的約束,更容易區(qū)分不同水平的考生。
此外,根據相關系數的估計值,四個因子之間的相關系數介于0.36和0.51之間,這表明考生在各項任務上的得分高低順序有所差異。其中可能原因是四項任務分別測量了考生口語表達能力的不同方面。
試題效應(i)反映出因試題難度差異導致的成績變異大小。從表2可以看出,聽后復述的方差分量(0.06921)最大,這表明在所有任務中,聽后復述任務由于試題難度差異造成的考生成績變異最大。換言之,這項任務的不同試題難度差異最為明顯。造成這個差異的可能原因在于聽后復述任務中聽力文本體裁對考生復述表現(xiàn)的影響。本次口語測試中,聽后復述的兩道試題分別使用了說明文和記敘文作為輸入內容,且兩種體裁的內容長度相當,但考生復述說明文的得分率明顯低于對記敘文的復述,在一定程度上表明,對于考生來說,聽取說明文并進行復述的難度大于記敘文,這與此前相關的研究結論一致[11]。
(三)四因子模型的D研究
1.各項任務全域分數的測量精度
通過D研究估計出考生在四項任務上的全域分數與相應誤差項的方差分量,并計算出概化系數、可靠性指數及信噪比等指標,如表3所示。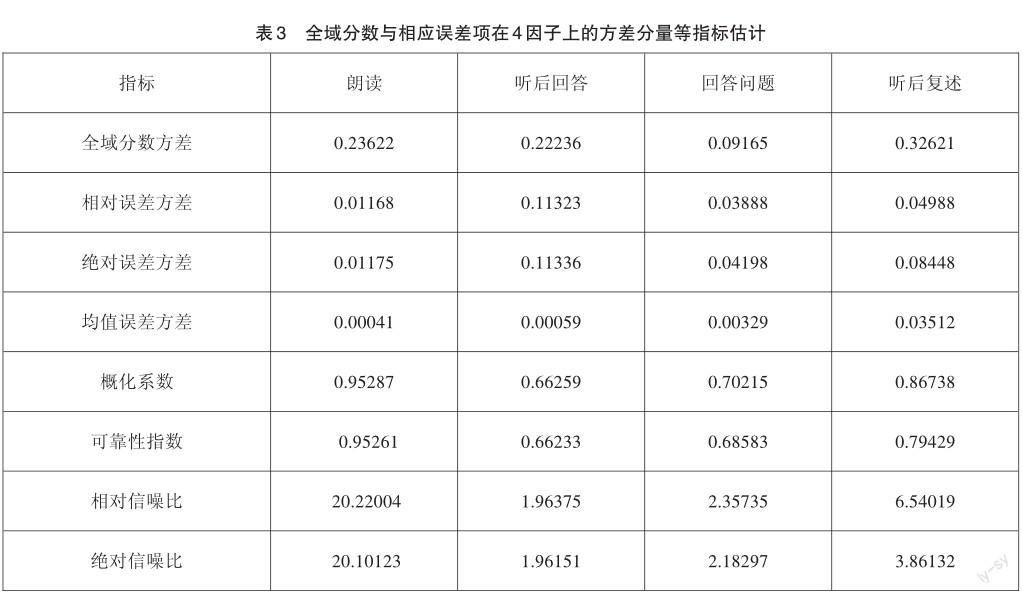
從表3可以看出,各項任務的概化系數(Gen Coefficient)均超過0.66,表明本次口語測試的試卷質量較高,各項任務具有良好的測量精度、測量誤差較小。各項任務按照概化系數從高到低排序,依次為朗讀(0.95287)、聽后復述(0.86738)、回答問題(0.70215)、聽后回答(0.66259),這表明朗讀相比其他任務測量精度更高,其中可能的原因是朗讀部分的試題數量多于其他任務,相當于對同一能力反復進行多次測量,因此效果更好。
2.全域總分的測量精度
根據各項任務的題目數量比例,對四個因子的全域分數進行合成,估計出全域總分與相應誤差項的方差分量,以及全域總分的概化系數、可靠性指數和信噪比等指標,如表4所示。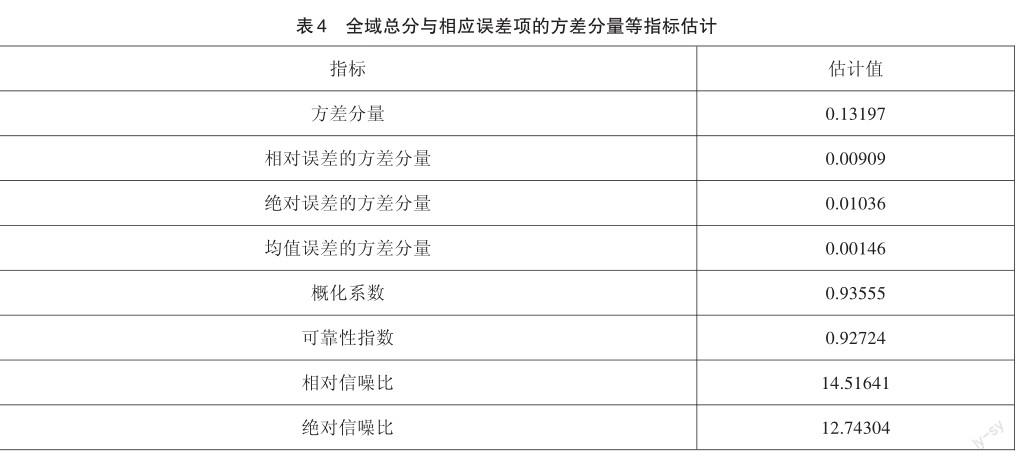
從表4可以看出,全域總分的概化系數達到了0.93555,相對誤差和絕對誤差的方差分量分別僅為0.00909和0.01036,表明本次口語測試的總體測量信度較好。
3.各項任務對總分方差的貢獻度
為進一步研究本次口語測試的四項任務對總分方差的實際影響程度,計算出各項任務對測試總分方差的實際貢獻度,如表5所示。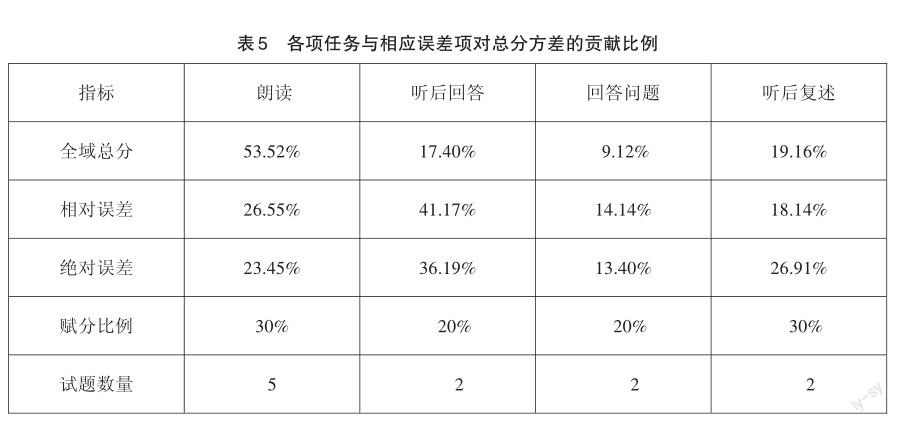
從表5可以看出,各項任務對總分方差的貢獻比例從高到低依次是朗讀(53.52%)、聽后復述(19.16%)、聽后回答(17.40%)、回答問題(9.12%)。各項任務對總分方差的貢獻比例與預先設定的賦分比例相比,存在一定差距。朗讀任務的貢獻比例高于賦分比例,聽后回答任務的貢獻比例大致相當于賦分比例,回答問題和聽后復述任務的貢獻比例低于賦分比例。其中可能的原因是:朗讀任務的題量相對較大,包含了5道試題,而且考生成績分布較為分散;而回答問題和聽后復述任務都只有2道試題,且考生成績分布相對集中。這表明,可以考慮進一步提高朗讀任務的賦分比例,或者增加回答問題和聽后復述任務的試題數量,以進一步提升考試的信度和區(qū)分效果。
4.各項任務題目數量對測量精度的影響研究
通過D研究計算出各項任務題目數量變化對口語測試整體測量信度的影響情況,結果如表6所示。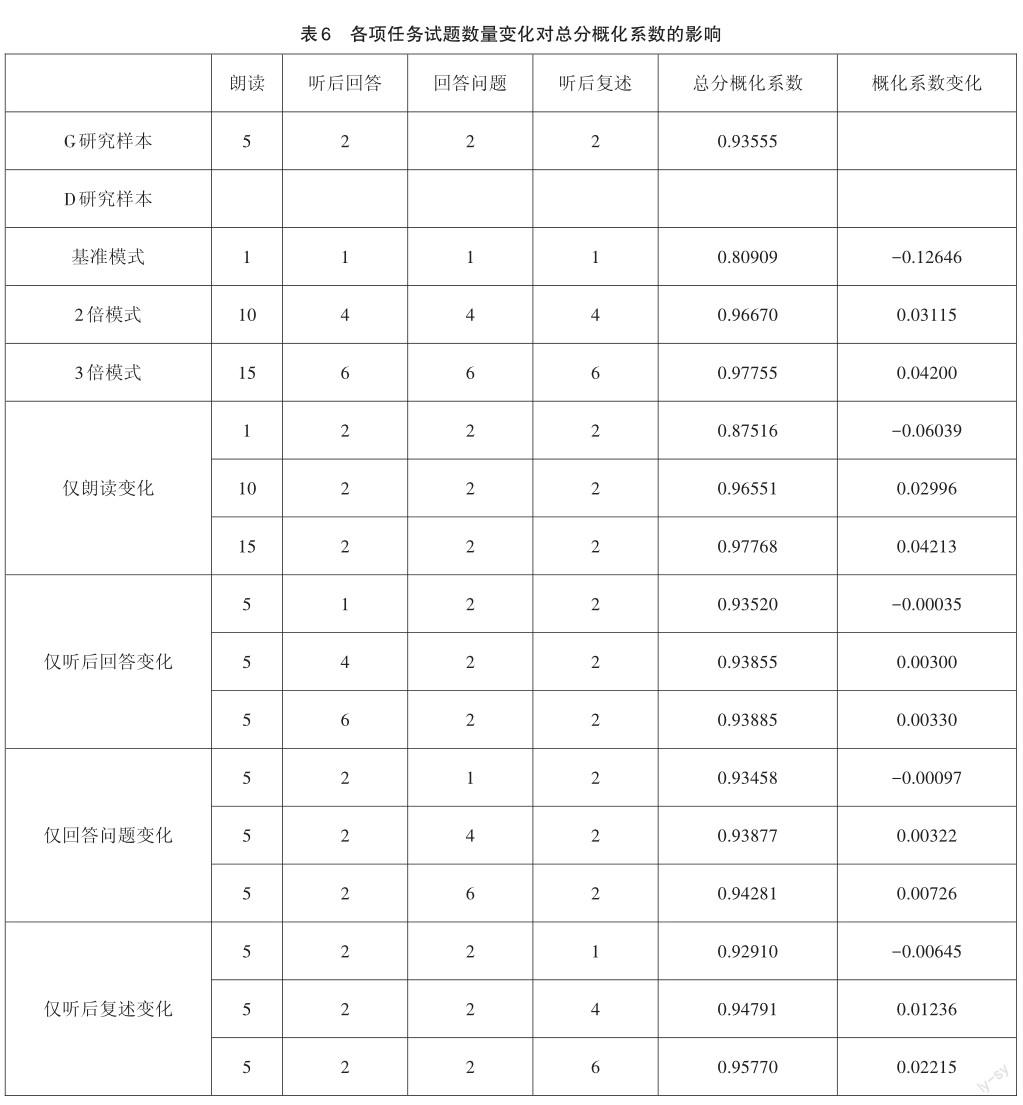
由表6可知,當各項任務的試題數量增加為2倍和3倍時,總分概化系數分別增加至0.9667和0.97755。此外,單獨增加某一項任務的試題數量,也可以提高總分概化系數,其中對提升整卷信度作用比較大的是增加朗讀和聽后復述的題目數量。
四、結論與啟示
(一)研究結論
采用四因子多元概化模型,對同一口語測試中的不同任務進行了分析,得到以下結論:
在測量信度方面,本次口語測試的全域總分概化系數為0.93555,總體測量信度高,達到了預期的測量目的。具體到任務上,朗讀的概化系數最高,聽后回答的概化系數最低。四項任務分別測量了考生不同方面的口語表達能力,這與考試的構念設計是一致的。
在區(qū)分效果方面,聽后復述和朗讀對不同水平考生的區(qū)分效果較好,而聽后復述由于不同試題難度差異對考生成績造成的影響最為明顯。這表明,需要注意聽后復述任務的難度控制,尤其是關注不同聽力體裁對任務難度的影響。
對總分的貢獻程度方面,朗讀對總分變異的貢獻最大且遠高于其他三項任務,而回答問題的貢獻最小。此外,朗讀對總分方差的貢獻比例高于其賦分比例,而回答問題和聽后復述對總分方差的貢獻比例低于各自的賦分比例。這表明,應該適當增加朗讀部分的分值,或者增加回答問題和聽后復述部分的試題數量。
試題數量變化對總分概化系數的影響方面,同時增加各項任務的題目數量可以提升總分概化系數,而單獨增加朗讀或聽后復述的題目數量對總分概化系數的提升效果最為明顯。
(二)研究啟示
基于上述結論,在口語測試任務設計方面可得到如下啟示。
Wright提出,根據交際潛質(communicative potential)不同,口語測試任務可以按照兩個維度進行分類:任務類型和導向[12]。在任務類型的維度上,口語測試任務從開放到封閉進行排列:開放性任務對考生作答不作限制,有多種可以接受的答案;封閉性任務則會對考生的作答進行限制,超出范圍的答案是不可接受的。在導向的維度上,口語測試任務從技能導向到內容導向進行排列:技能導向任務一般考查口語能力本身,答案往往比較開放;內容導向任務則將口語能力與具體的內容融合起來進行考查,答案的可控程度一般較高。
基于該分類依據,本次口語測試的四項任務中,朗讀、聽后復述、聽后回答屬于偏封閉型和內容導向的任務類型,回答問題屬于偏開放型和技能導向的任務類型。本次研究的結果表明,整體而言,偏封閉型、內容導向的測試任務比偏開放型、技能導向的測試任務在區(qū)分效果、測量精度和對總分的貢獻上表現(xiàn)更好。
從考試命題的角度,內容導向的口語測試任務有助于減少考生“押題”和“背模板”等應試現(xiàn)象。從考試評分的角度,封閉型的口語測試任務因為作答內容可控,有利于評卷人員把握評分標準、控制評分誤差,最終保障評分質量。從考試組織實施的角度,隨著人力成本的增加,大規(guī)模考試的評分工作和評卷人員的聘請日益成為考試組織機構面臨的一大挑戰(zhàn)。為了解決這個問題,一些大規(guī)模考試紛紛進行了機器自動評分的探索和應用[13]。相關研究表明,封閉型和半封閉型的口語測試任務機器評分與人工評分的一致性明顯高于開放型任務[14]。因此,在口語測試中采用相對封閉型的任務,有助于自動評分的應用、減少人工評分的組織成本。
本研究的主要不足在于考生樣本量偏少且僅限于高二年級學生,口語測試任務類型偏少。在今后類似的研究中,可考慮增加樣本數量和范圍,進一步豐富任務類型,基于更具代表性的受試者群體和更多樣的任務類型,進而對口語測試任務的特點進行更為全面的研究。
參考文獻:
[1] OLoighlin K. The Equivalence Of Direct And Semi-Direct Speaking Tests [M]. Cambridge University Press,2001:4.
[2]曾用強.對計算機化考試的幾點思考[J].外語電化教學,2010,(01):52-55.
[3]侯艷萍.外語高考聽說測試改革的反撥作用研究[J].外語電化教學,2018,(05):23-29.
[4] Luoma,S. Assessing Speaking [M]. Cambridge University Press,2004:31.
[5]李夢莉,范琳.機助口試理論模型、任務特征和評分標準研究——新托福網絡口試和PhonePass~(TM)SET口試對比分析[J].中國考試,2013,(08):22-27.
[6]劉遠我,張厚粲.概化理論在作文評分中的應用研究[J].心理學報,1998,(02):211-218.
[7]羅照盛,郭小軍.認知行為實驗研究中最佳素材容量的選擇與確定:多元概化理論應用[J].心理學報,2014,46(06):876-884.
[8]楊志明,張雷.測評的概化理論及其應用[M].北京:教育科學出版社,2003:18-20.
[9]趙軒,任子朝,陳昂.基于多元概化理論的高考數學文理科試卷質量分析與對比研究[J].數學通報,2018,57(01):25-30.
[10]陳康,吳泓霖,李新煜,等.基于高考評價體系的英語科考試內容改革實施路徑[J].中國考試,2019,(12):33-37.
[11]柳明明.高考英語聽后口頭復述任務效度論證研究[D].北京外國語大學,2015:114-115.
[12] Wright,T. Instructional Task And Discoursal Outcome In The L2 Classroom [J]. Lancaster Practical Papers in English Language Education,1987,(07):49.
[13]金艷,王偉,楊浩然.語言測試中的技術應用:基于大學英語四、六級考試的實踐分析[J].外語測試與教學,2021,(01):1-7+27.
[14]孫海洋.國內外英語口語自動評分研究綜述[J].外語教育研究前沿,2021,4(02):28-36+89-90.
Research on English Speaking Test Tasks Based on Multivariate Generalizability Theory
Wu Honglin
National Education Examinations Authority,Beijing,100084
Abstract:Speaking test tasks,which can be seen as activities that involve a speaker in using language for the purpose of achieving a particular communicative goal in a particular speaking situation,are important parts of the design of a speaking test. Based on Multivariate Generalizability Theory,this study analyzes four common tasks such as reading-aloud,listening-and-answering,answering questions and listening-and-retelling focusing on the effect of differentiation,precision of measurement and contribution to the composite score regarding different tasks. The result of the study shows that in general closed and content-oriented speaking test tasks perform better than open and skill-oriented ones do in terms of the effect of differentiation,precision of measurement and contribution to the composite score.
Key words:Speaking Test Tasks,Multivariate Generalizability Theory,Computer-based Testing
(責任編輯:吳茳)
