分布式數據庫發展綜述
2023-12-01 10:15:08蘇彥志蔣越維
數字通信世界 2023年10期
蘇彥志,陳 廣,蔣越維
(中國移動通信集團河北有限公司,河北 石家莊 050000)
1 分布式數據庫概述
分布式數據庫的特點主要包括以下幾點。
(1)透明性:分布式數據庫的透明性包括分片透明、復制透明、位置透明和邏輯透明等,其中分片透明是透明性的最高層次,邏輯透明層次最低。具體來說,透明性是指用戶在使用過程中,不必關心數據在數據庫管理系統內部是如何分片的,不必知道數據都分別存放在哪個節點以及各個網絡節點是怎樣完成數據復制的,用戶只需在使用時完成自己的相關操作即可。
(2)高可靠性:分布式數據庫會對數據采取多次備份存儲形成多副本來提高數據的可靠性。當某個節點出現故障時,其他節點可快速替代故障節點繼續工作,避免出現數據丟失現象。
(3)易擴展性:當數據庫現有容量和性能告急時,分布式數據庫可采取添加新節點和服務器的方法來實現擴展,相比于集中式數據庫的難擴展性可以更好地滿足用戶不斷增長的需求。如圖1所示。
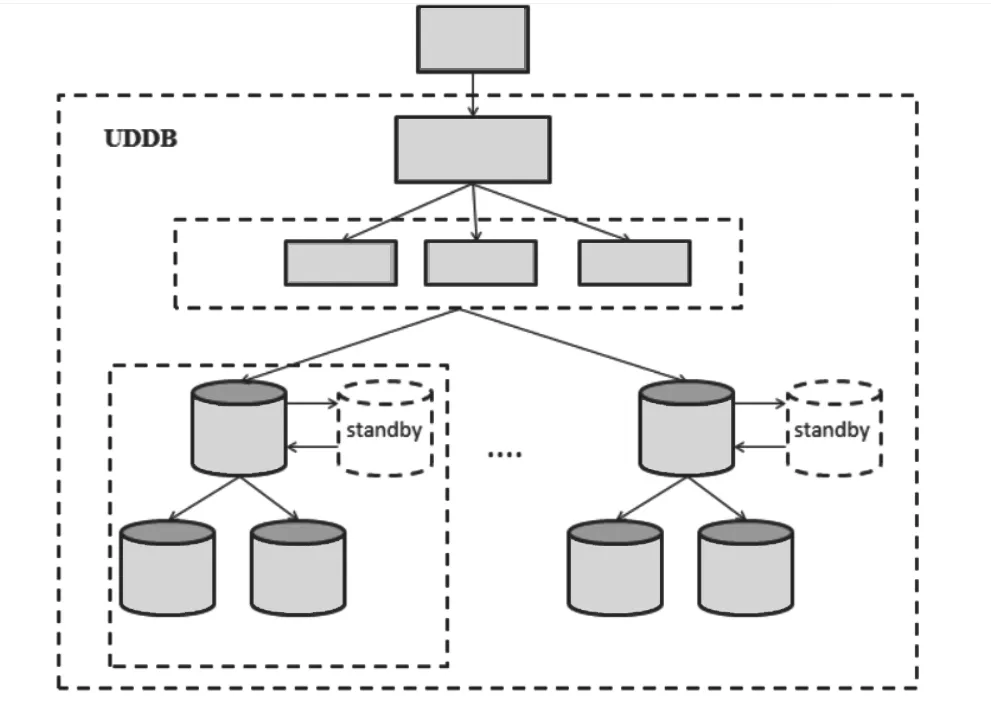
圖1 分布式數據庫[1]
2 分布式數據庫的發展歷程
21世紀以前,關系型商業數據庫可以滿足大部分用戶應用場景,但隨著互聯網應用的到來,數據呈現大容量、多樣性、流動性等特點,采取集中式架構的傳統關系型數據庫逐漸無法實現業務系統高并發的需求,于是分布式數據庫迎來了發展機遇。
2.1 第一代分布式數據庫——NoSQL
2009年初,NoSQL數據庫應運而生代表著第一代分布式數據庫的誕生。它專注于分布式場景下數據的存儲和查詢,不需要預先定義Schema,開發人員可以頻繁在線更改Schema,更高效滿足業務需求。NoSQL數據庫打破以前傳統商業數據庫多節點部署難度大、造價高的困境,易于擴展。但由于其是通過犧牲SQL和事務來實現可擴展的,甚至缺乏ACID,因此數據一致性問題難以解決,應用場景十分局限,不利于完成整個應用架構的搭建。最流行的兩個NoSQL系統分別是Amazon Dynamo和Google Bigtable。Dynamo系統因犧牲一致性而失敗。Bigtable雖實現了強一致性,但只支持單行事務,未達到高效的目的。如圖2所示。
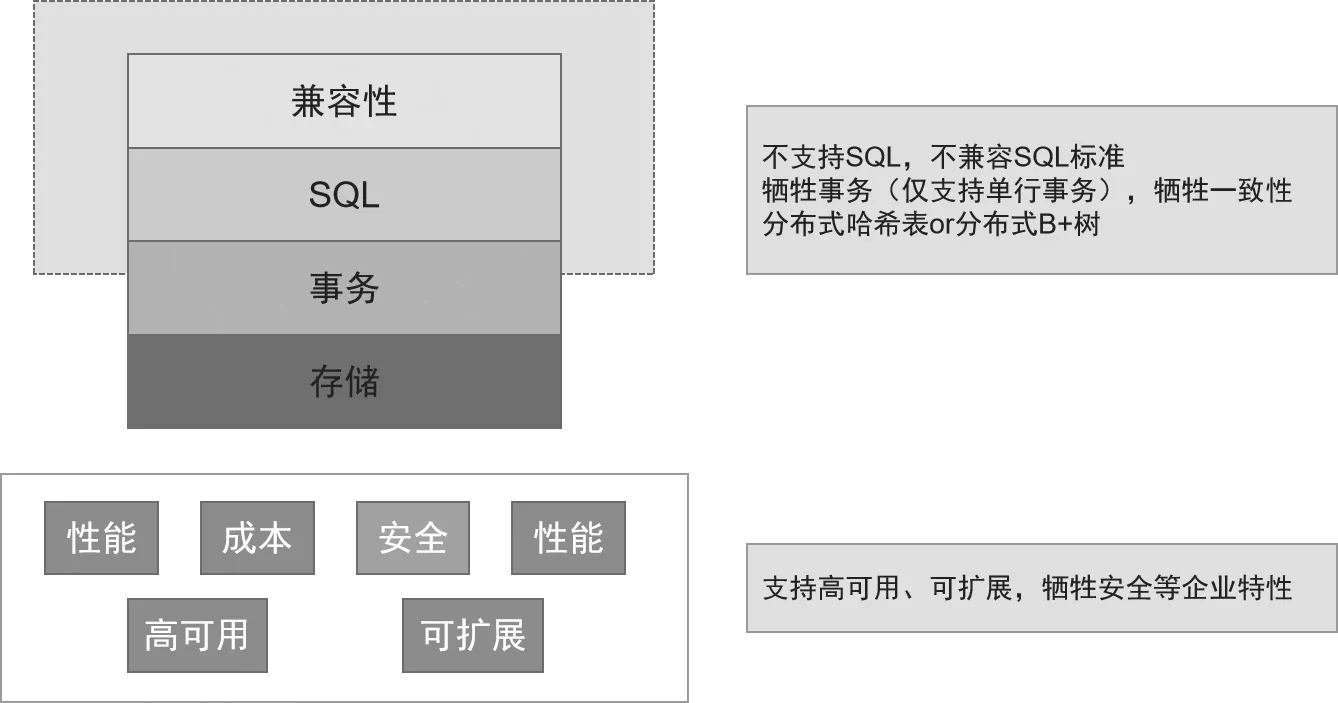
圖2 第一代分布式數據庫
2.2 第二代分布式數據庫——NewSQL
第一代分布式數據庫友好性欠缺,且無法支持SQL,于是第二代分布式數據庫采用搭積木的方式,在NoSQL的基礎之上引入了SQL支持,以Google Spanner為代表。Spanner支持大部分SQL,但不兼容SQL標準,通過Truetime實現全功能事務,保證了強一致性,但單次事務提交時延、單機性能犧牲度較大,這意味著其不符合性價比的特性,難以廣泛應用于傳統行業的業務場景。如圖3所示。
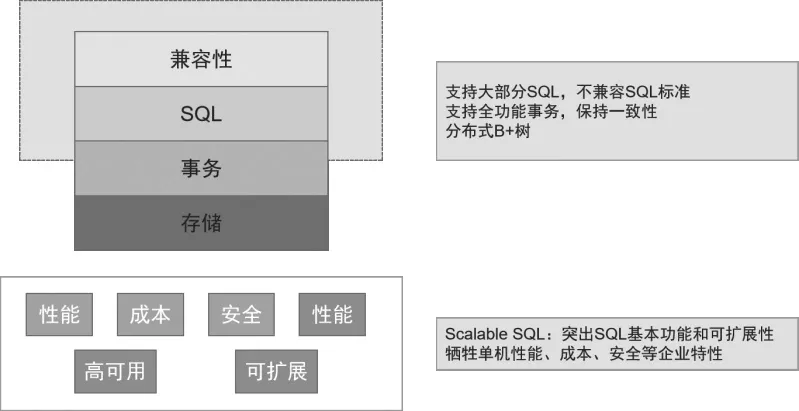
圖3 第二代分布式數據庫
2.3 第三代分布式數據庫——原生式
第三代是原生式分布式數據庫,充分享受分布式高可用、可擴展的技術紅利,在利用較低成本的前提下具備極致單機性能,是較為成熟的透明擴展企業級數據庫,如OceanBase。OceanBase的底層為可擴展的分布式架構,在同一套數據庫引擎中支持HTAP混合負載,支持SQL和Paxos高可用性,在眾多分布式數據庫中脫穎而出。如圖4所示。
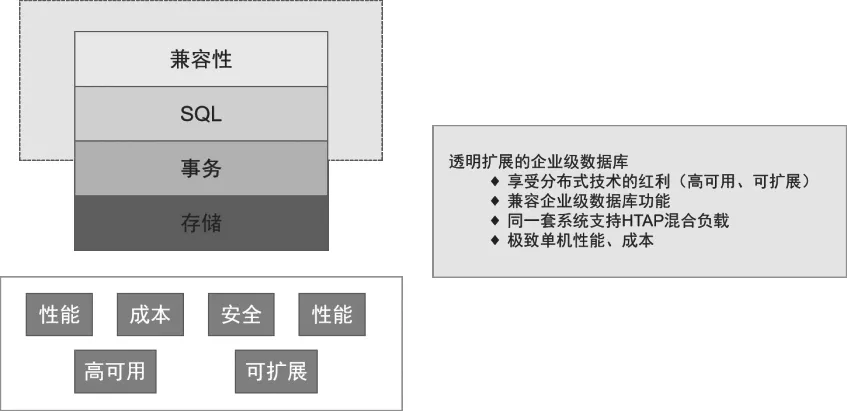
圖4 第三代分布式數據庫
3 分布式數據庫國內外發展現狀
3.1 在技術方面
數據分片、分布式事務處理和數據同步都是分布式數據庫的核心技術。數據分片技術是實現可擴展性和高可用性的核心技術。隨著數據量的增加,數據分片技術也在不斷發展,如基于哈希算法的分片、基于范圍的分片等;分布式事務處理技術的發展對保證事務的一致性和隔離性十分重要,常用的分布式事務處理技術[2]包括兩階段提交、三階段提交、Paxos算法等.數據同步技術是保證數據一致性和完整性的關鍵技術,常用的數據同步技術包括主從復制、主主復制、基于日志的同步等。
3.2 在市場方面
隨著社會科學技術的快速發展,分布式數據庫系統的市場需求和市場競爭都在日益增加。據統計數據顯示,2018年分布式數據庫系統市場規模僅為92億美元,到2022年已達161億美元,年復合增長率達14.1%。市場需求的增長吸引了國內外眾多企業開始參與到分布式數據庫系統市場的競爭中,如阿里云、華為云等。另外,開源分布式數據庫系統也在不斷涌現,如Hadoop、MongoDB等,其以開源和靈活性高等特點受到廣大企業和開發者的關注并被采用。
3.3 在應用方面
分布式數據庫系統在云計算、大數據、物聯網等領域得到了廣泛應用。分布式數據庫系統的高可用性、高擴展性和高性能性可滿足企業在云環境下的數據存儲和處理需求。云計算領域主要應用的分布式數據庫系統包括阿里云的AnalyticDB、亞馬遜的Aurora等。在大數據環境下,龐大的數據量需要分布式存儲和處理,該應用環境中的主要分布式數據庫系統包括Apache HBase、Apache Cassandra等。物聯網中,設備和傳感器產生數據量巨大,需要實時分析和處理,分布式數據庫系統可滿足其需求,應用的主要分布式數據庫系統包括InfluxDB、OpenTSDB等。
4 分布式數據庫發展面臨的問題
本節主要討論針對CAP理論的應用系統合理選擇問題、遺留系統遷移改造問題以及產品成熟度不足[3]的問題。
4.1 應用系統合理選擇問題
CA P理論是一個經典的分布式系統理論。已知一個分布式系統不可能同時滿足一致性(C:Consistency)、可用性(A:Availability)和分區容錯性(P:Partition tolerance)這三個基本需求,最多只能同時滿足其中的兩個。而在現實的分布式系統中,不可靠的網絡和宕機概率是一定存在的,因此分區容錯性是必選項而不是可選項,這樣用戶就需要在一致性和可用性之間進行取舍,這是困擾眾多開發人員的問題。在實際場景中,各企業結合自身不同的業務需求,做出的最終抉擇有所不同,但是做好一致性和可用性之間平衡是所有企業的共同訴求。如圖5所示。
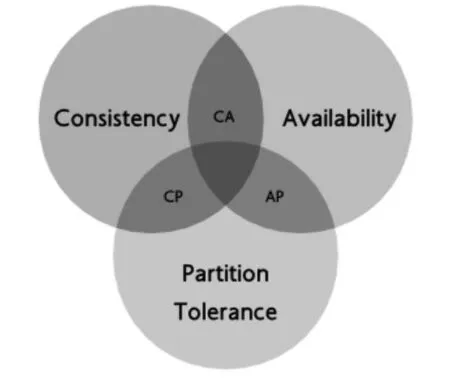
圖5 CAP理論[4]
4.2 遺留系統遷移改造問題
分布式數據庫與集中式數據庫工作機制的不同使得兩者的功能性也存在著一定差異,比如存儲過程、視圖、外鍵約束等功能,雖然分布式數據庫也具備上述功能,但執行效率會比集中式數據庫低,這樣使得上層業務遷移改造時需特別注意數據模型和實現邏輯。另外,還要考慮硬件開銷成本,分區計,充分利用分布式數據庫的高并發性和水平擴展特性[4]。
4.3 產品成熟度不足問題
分布式數據庫作為新興的數據庫技術,自身發展還處于初期,存在著技術體系、產品推廣和標準規范不成熟的情況。而傳統集中式數據庫經過幾十年的發展,已具備較為完善成熟的產品,甚至不斷衍生出許多特殊用法,這導致在遷移過程中會出現較大的困難,阻礙了分布式數據庫大面積推廣使用。
5 分布式數據庫發展前景與展望
(1)大規模數據處理:隨著互聯網和物聯網等新技術不斷革新,數據量將會持續呈現爆炸式增長。分布式數據庫依靠其良好的可擴展性和高性能的特點,能夠滿足大規模數據處理的需求,未來將會越來越受到關注。
(2)數據智能化:未來分布式數據庫將會越來越智能化,利用機器學習和人工智能等技術對海量數據進行分析和挖掘,從而為企業提供更加有價值的業務洞察和預測結果。
(3)區塊鏈技術:區塊鏈技術將會成為未來分布式數據庫的重要發展方向之一。區塊鏈技術依靠其去中心化、不可篡改、安全等特點,能夠為企業提供更加可信的數據存儲和訪問方式,因此將會成為分布式數據庫發展的重要趨勢[5]。
(4)云原生數據庫:云原生數據庫[6]將會成為未來分布式數據庫的趨勢。云原生數據庫采用微服務、容器化、自動化管理等技術,實現了高可用性、高可伸縮性和高安全性,能夠幫助企業更加高效地管理和維護數據。
總的來說,分布式數據庫未來的發展前景非常廣闊,同時也需要我們密切關注技術的發展趨勢,不斷學習新的技術和知識,從而為企業提供更加優質的服務。■
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
中國公共安全(2017年11期)2017-02-06 05:28:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
