基于用戶畫像的高校圖書館可視化系統的構建與實現
2023-12-01 10:15:08崔樂樂
數字通信世界 2023年10期
崔樂樂
(昆明醫科大學圖書館,云南 昆明 650500)
1 高校圖書館用戶畫像研究概述
用戶畫像的概念最早是由交互設計之父A la n Cooper在1998年提出的,是建立在現實生活中一系列真實數據上的用戶目標模型,是對真實用戶的虛擬化[1]。在國外,用戶畫像已經成為廣告、市場營銷和數據分析等領域的重要工具。例如,Facebook和Google等科技公司在個性化推薦、廣告投放和用戶體驗方面都充分利用了用戶畫像。此外,歐美一些圖書館也開始使用用戶畫像來提升服務質量[2]。在國內,隨著大數據和人工智能技術的快速發展,用戶畫像也逐漸被應用于多個領域,在圖書館領域,用戶畫像也成為提高管理效率和服務水平的一種重要手段[3]。
目前,圖書館領域的用戶畫像主要圍繞建立用戶畫像模型等展開研究,如何利用用戶畫像為讀者提供個性化服務模式是當前圖書館管理與服務重點關注的領域[4],而其中以構建多維度、多層次、立體化的用戶畫像模型,實施圖書的個性化推薦、個性化信息檢索、個性化借閱、個性化參考咨詢等個性化服務[5]成為提高圖書館服務效能的重要手段之一。隨著信息化、數字化和智能化的發展,基于大數據的用戶畫像模型及相關技術也在更新迭代中,基于此,本文以高校多維度用戶數據類型為依托,構建適應高校圖書館的用戶畫像模型,進而構建多樣化的高校圖書館可視化系統,圖書館可視化系統對用戶查詢意圖、興趣等進行推理和預測,為用戶及相關部門提供有效的調查結果,同時館員根據可視化系統對讀者服務及系統建設提供決策依據。
2 用戶畫像模型的構建流程
高校圖書館的用戶畫像模型構建流程是:首先收集高校圖書館用戶的各類信息數據進行預處理,去掉臟數據,使用戶的屬性數據和行為數據相關聯,然后對關聯后的用戶數據進行深入挖掘和分析后建立用戶標簽,初步建立用戶畫像模型,細分用戶形成個人用戶畫像和群體用戶畫像。
2.1 用戶畫像數據的采集與處理
圖書館用戶數據的獲取從自然屬性、用戶偏好屬性、交互行為屬性和社交行為屬性四個維度著手,一般可從圖書館后臺管理系統、閘機打卡系統或圖書館搜索引擎中獲取。其中,圖書館后臺管理系統中保存了用戶入學注冊時的身份信息、注冊信息和登錄信息等,這些用戶的自然屬性數據和交互行為數據均可通過系統數據庫直接導出。用戶偏好數據一般從圖書館檢索借閱系統和互聯網搜索引擎中獲取。用戶在線瀏覽、在線評論、留言等交互信息可以運用網絡爬蟲技術從用戶經常使用的操作頁面爬取、識別。
采集完用戶數據后,在充分保障用戶數據隱私的前提下,首先對用戶基本信息、借閱行為數據、圖書標簽數據、檢索數據、交互行為數據等進行清洗,過濾去除與用戶特征不相關的數據,然后利用數據挖掘算法對用戶數據進行深入挖掘和分析,形成真實可用的圖書館用戶畫像數據集。高校圖書館用戶畫像數據的構成如圖1所示。
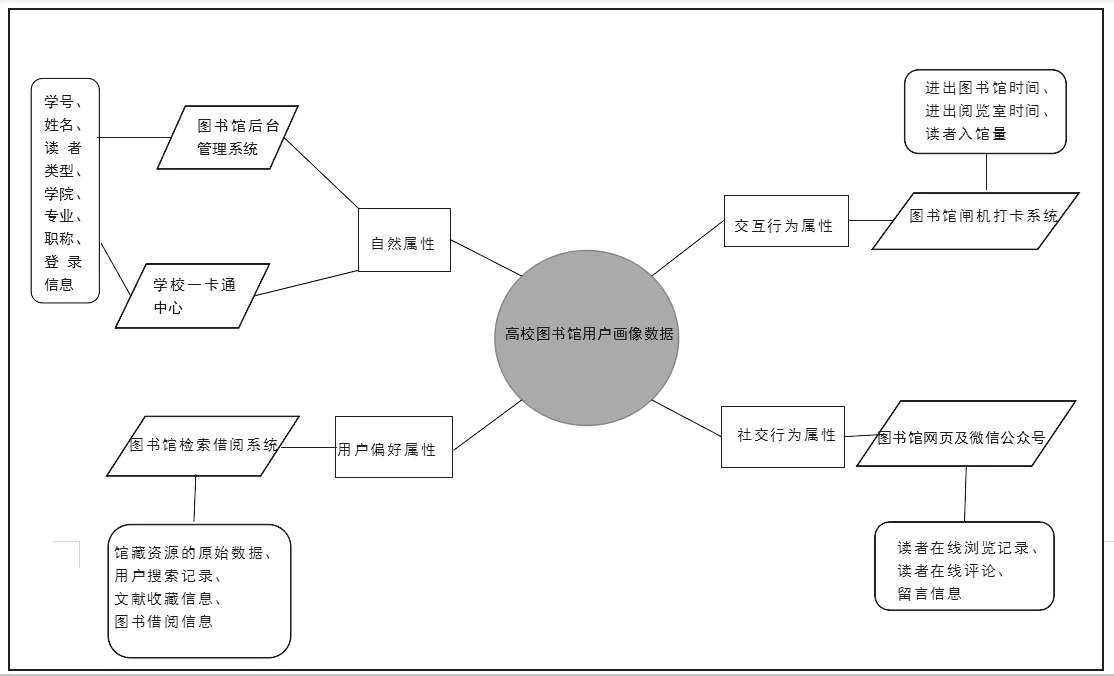
圖1 高校圖書館用戶畫像數據構成
2.2 建立用戶畫像數據標簽體系
構建準確的用戶畫像需要將用戶數據標簽化、向量化,為后續數據挖掘和數據分析提供可計算的數值信息[6]。針對圖書館數據,如偏好圖書類別——哲學、文學、工業技術、社會科學等可形成描述用戶興趣愛好的標簽。標簽體系的建立需要結合真實業務場景下的用戶需求,有目的性地提煉出能夠代表用戶特征的標簽,建立有需求偏向的標簽體系。針對圖書館數據的標簽提取,本文從收集高校圖書館用戶群體自然屬性數據、內容偏好數據、交互行為數據和社交行為數據四個維度的具體信息來構建用戶畫像的標簽體系。
2.3 構建用戶畫像模型
高校圖書館用戶畫像模型是一個描述讀者特征和行為的模型,由數據來源層、數據分析處理層以及數據標簽層3個層次構建而成。具體構建過程如圖2所示。
在構建用戶畫像模型時,需要注意以下幾個方面。
(1)數據質量:確保收集到的數據完整、準確、可靠,避免噪聲和異常值對模型訓練產生不利影響。
(2)標簽體系:建立起合理、完備、可擴展的標簽體系,以便對讀者特征和行為進行描述和識別。
(3)模型選擇:根據具體需求選擇合適的模型,避免過擬合或欠擬合等問題對模型應用產生不利影響。
(4)模型評估:對建立的模型進行準確性、魯棒性、穩定性等方面的評估和測試,以驗證其適用性和有效性。
3 基于用戶畫像的可視化系統的實現
用戶畫像模型建立后,我們通過設計通用技術框架構建可視化系統。該系統框架由用戶交互界面、服務接口層interfaceServer和數據適配器3個部分組成。
用戶交互界面通過可視化編程組件實現,內置多種可視化組件,如折線圖、柱狀圖、餅狀圖、氣泡圖、詞云等,并提供任務管理、可視化設計與UI編排、數據加載、可視化預覽和發布功能。
接口服務層interfaceServer通過從后臺獲得的數據為為前端提供restful接口。
數據適配器運用dataAdapter適配器和數據庫進行交互,并緩存、匯總數據然后通過interfaceServer提供給用戶交互界面使用。本文以高校圖書館應用的讀者興趣畫像、讀者閱讀報告、院系閱讀報告為例,具體實現內容如下。
(1)讀者興趣畫像。讀者興趣畫像包含讀者的基本信息、進館信息、借閱下載信息、使用學科、數據庫分析、熱點主題等內容,通過這6個方面形成的用戶畫像能夠對讀者的使用進行進行分析統計。界面實現如圖3所示。
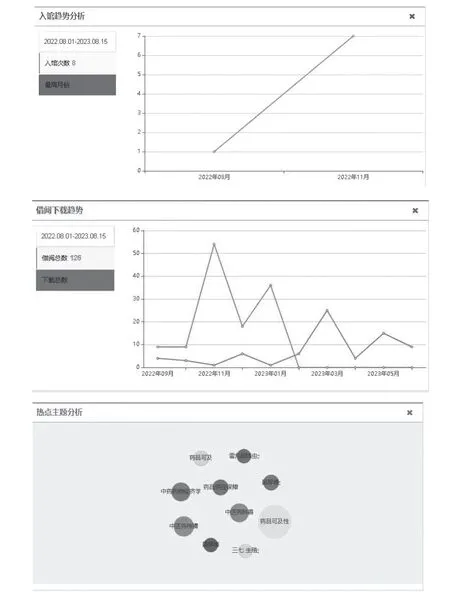
圖3 用戶興趣畫像界面
(2)讀者閱讀報告。讀者閱讀報告的展示以HTML5動畫展示,個人閱讀報告主要有借閱量、進館次數、進館時間、訪問圖書館門口網站、檢索下載文獻量等統計信息,其界面展示如圖4所示。

圖4 讀者閱讀報告界面
(3)院系閱讀報告。院系閱讀報告主要包括學院讀者入館趨勢、入館讀者類型、讀者借閱情況、熱門借閱TOP10統計、資源下載情況、熱門檢索關鍵詞等內容,旨在提高“學院-圖書館”互動頻率,提升二級學院對圖書館的滿意度。在此基礎上通過與各個二級學院交流工作,可發掘出更多有價值的數據和分析點,為圖書館讀者服務水平提升提供一定的數據支撐。其畫面展示如圖5所示。
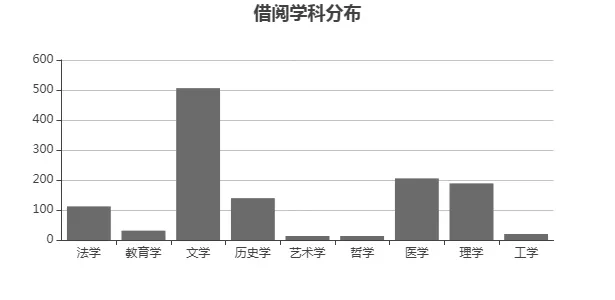
圖5 院系閱讀報告
4 結束語
本文面向高校圖書館,以圖書館用戶畫像的可視化構建與表達為研究重點,詳細探討了高校圖書館用戶畫像可視化系統的數據體系、系統框架、構建流程與技術實現,最后形成了一套高校圖書館的可視化系統,該系統以多種形式的用戶興趣畫像及圖書館閱讀報告的形式呈現,為讀者提供滿足其個性化需求的精準推薦服務,對智慧化的圖書館借閱服務及管理具有重要的參考及應用意義。■
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
小太陽畫報(2018年1期)2018-05-14 17:19:25
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
