基于ICEEMDAN和IMWPE-LDA-BOA-SVM的齒輪箱損傷識別模型*
2023-11-27 02:11:40張銳麗
機電工程 2023年11期
王 洪,張銳麗,吳 凱
(1.宜賓職業(yè)技術學院 智能制造學院,四川 宜賓 644003;2.成都理工大學 機電工程學院,四川 成都 610059)
0 引 言
齒輪箱是一種常用的傳動系統(tǒng)部件,目前已被廣泛應用于汽車、航空航天、化工等領域。由于齒輪箱的結構復雜,并且運行工況不穩(wěn)定,導致齒輪箱內部的零部件極易發(fā)生疲勞失效,導致整個設備的振動,不利于設備的安全運行[1]。
齒輪箱發(fā)生故障后,其振動信號中包含大量與故障特征無關的諧波信息,干擾其故障特征的提取[2]。因此,有必要采取信號分解方法對源信號進行處理,以降低噪聲的干擾[3]。
高淑芝等人[4]提出了一種基于集成經驗模態(tài)分解(ensemble empirical mode decomposition,EEMD)的故障診斷方法,采用該方法準確地識別出了滾動軸承的故障信息;然而EEMD的運行效率極為低下,且引入噪聲進行輔助分解,會導致分解分量殘留部分噪聲。為此,肖俊青等人[5]采用自適應噪聲完備集成經驗模態(tài)分解方法,對故障信號進行了處理,結果表明了其效果優(yōu)于EEMD,故障信號分解得更為精確;然而其分解的信號依然殘留少量噪聲。針對該問題,李銘等人[6]將改進自適應噪聲完備集成經驗模態(tài)分解(ICEEMDAN)用于處理滾動軸承振動信號,并進行了實驗,結果驗證了ICEEMDAN的優(yōu)越性,其能夠更好地去除信號中的噪聲。
基于此,筆者采用ICEEMDAN來剔除齒輪箱振動信號中的噪聲,以減少噪聲對后續(xù)分析的干擾。
齒輪箱振動信號為非線性的一維數據,通常需要采用基于熵值的非線性分析方法進行處理[7]。常見的熵值分析方法包括樣本熵、排列熵、多尺度熵等。排列熵(permutation entropy,PE)具有計算效率高、抗噪性強和性能優(yōu)異等特點,被廣泛用于故障診斷的研究中。
顧云青等人[8]提出了一種基于ICEEMDAN和PE的滾動軸承故障診斷方法,并將其用于軸承故障診斷,診斷結果驗證了排列熵的性能;然而PE忽略了信號的幅值信息。為此,ZHOU Shen-han等人[9]將加權排列熵(weighted permutation entropy,WPE)用于表征滾動軸承的健康狀態(tài),準確檢測和識別了滾動軸承的故障;然而WPE只是進行了單一尺度的分析。YUAN Xu-yi[10]提出了多尺度加權排列熵(multiscale weighted permutation entropy,MWPE),采用MWPE有效提取出了隔膜泵的故障特征;然而MWPE的粗粒化處理依賴于分析數據的長度,造成熵值偏差隨著尺度的增加而變大。為此,王振亞等人[11]對粗粒化方式進行了優(yōu)化,提出了改進多尺度加權排列熵,并將其應用于故障診斷,結果驗證了該算法的有效性;但是在分析某些信號時,基于方差改進的加權排列熵可能會失去有效性[12]。
針對上述問題,筆者采用均方根對改進多尺度加權排列熵進行改進,提出另一種形式的改進加權排列熵(IMWPE),以進一步增強算法的特征提取能力;在此基礎上,提出一種基于ICEEMDAN信號重構、IMWPE故障特征提取、線性判別分析(LDA)特征降維和蝴蝶優(yōu)化算法優(yōu)化支持向量機(BOA-SVM)的損傷識別模型(ICEEMDAN-IMWPE-LDA-BOA-SVM)。
首先,采用ICEEMDAN對樣本進行處理,篩選出核心組件,進行故障信號重構;隨后,利用IMWPE提取重構信號的故障特征,并采用LDA進行特征的降維;最后,采用基于蝴蝶算法優(yōu)化的支持向量機SVM進行故障識別。
1 ICEEMDAN信號重構
1.1 ICEEMDAN算法原理
ICEEMDAN利用數據的局部均值來獲取k階模態(tài),能夠進一步消除數據中的殘留噪聲和偽模態(tài),使得分解得到的本征模態(tài)函數(intrinsic mode function,IMF)分量具有更清晰的物理意義。ICEEMDAN對信號處理的詳細過程可參考逄英等人的研究[13]。
1.2 分量選擇原則
相關系數能夠準確地刻畫IMF分量與原始數據之間的緊密程度,根據相關系數,能夠據此保留信息量更多的IMF分量[14]。首先,筆者計算了歸一化處理后的原始數據自相關函數,以及各階IMF分量自相關函數之間的相關系數。
相關系數的定義如下:
(1)
式中:E(x)為數據序列xi的均值;E(y)為數據序列yi的均值;n為數據的采樣點數。
隨后,定義分量的選擇閾值。假設各樣本經過ICEEMDAN分解后得到的最少IMF分量數量為m,則閾值δ定義為:
(2)
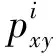
當IMF分量的相關系數大于閾值時,則將其視為有效分量;否則,將其剔除。
2 改進多尺度加權排列熵特征提取
2.1 加權排列熵算法
排列熵對時間序列的幅值不敏感,對幅值相等的時間序列無法進行有效的區(qū)分[15]。
受到基于方差的加權排列熵的啟發(fā),筆者采用均方根對排列熵進行改進,提出了加權排列熵的另外一種形式,其原理如下:
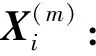
(3)
式中:m為嵌入維數;τ為時間延遲。
2)定義各子信號的權重ωi:
(4)
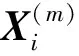
(5)
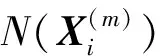
4)求解信號X的WPE值為:
(6)
2.2 多尺度加權排列熵算法
多尺度加權排列熵能夠有效地從多個尺度來表征非線性數據的復雜性。對于信號X={x1,x2,…,xN},多尺度加權排列熵的具體計算步驟如下:
1)對信號進行粗粒化處理,生成粗粒化序列Ys={ys(j)}。
(7)
式中:s為尺度因子。
2)提取不同尺度因子s下,各粗粒化序列Ys的加權排列熵值,則得到MWPE如下:
MWPE(X,m,τ,s)=WPE(Ys,m,τ)
(8)
2.3 改進多尺度加權排列熵
MWPE避免了WPE只能進行單尺度分析的不足,然而原始的粗粒化處理會造成熵值誤差隨著尺度因子的增加而增大。因此,筆者平均同一尺度下全部粗粒序列的WPE熵值,以避免由于粗粒序列變短而造成WPE熵值突變現(xiàn)象的出現(xiàn),使得復雜性分析更加準確[16]。
對于信號X={x1,x2,…,xN},改進多尺度加權排列熵的原理如下:
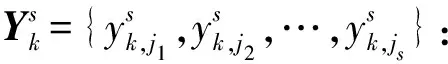
(9)
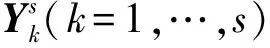
(10)
當尺度因子為s=3時,傳統(tǒng)的粗粒化處理和改進的粗粒化處理如圖1所示。
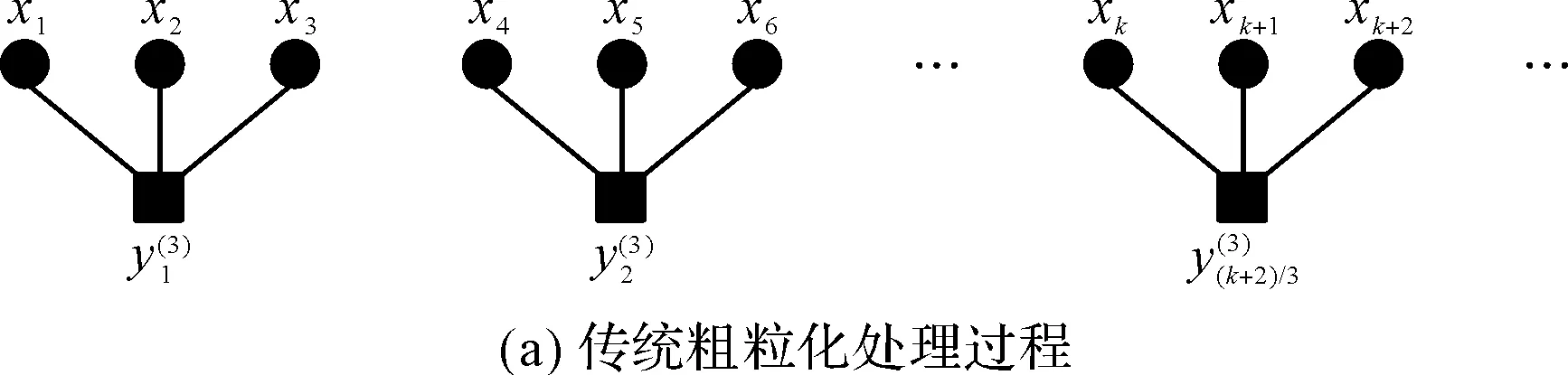
圖1 尺度因子s=3時的傳統(tǒng)粗粒化和改進粗粒化過程
由圖1可以發(fā)現(xiàn):在傳統(tǒng)的粗粒化過程中,粗粒序列中的元素數量會隨著尺度的增加而變少,導致熵值的不穩(wěn)定性。此外,傳統(tǒng)的粗粒化處理還忽視了部分相鄰樣本點之間的動態(tài)關系,如在圖1(a)中,x3和x4之間的信息就被忽略了;反之,在改進的粗粒化處理過程中,在相同尺度因子s下,改進的粗粒化處理能夠獲得s組粗粒序列,對這些序列進行平均處理,能夠有效解決熵值不穩(wěn)定的問題。
而且改進粗粒化處理通過滑動操作,充分考慮了相鄰樣本點之間的關系,數據的利用率更高。
IMWPE方法的性能與嵌入維數m、時間延遲τ和尺度因子s有關。m選擇得過小,重構向量的長度變短,算法無法有效探測信號的動力學突變;相反,m設置過大,不僅降低計算效率,而且無法有效表征信號的微弱波動。因此,通常設置嵌入維數的取值范圍在[4,7],筆者設置為m=5。
尺度因子s的設置沒有嚴格的要求,通常設置為s≥10,筆者設置為s=25。
時間延遲τ對IMWPE的影響幾乎可以忽略不計,筆者設置為τ=1。
3 LDA特征降維和BOA-SVM分類識別
3.1 LDA算法原理
LDA算法基于Fisher判別定理,定義子空間J,并將數據向子空間J做投影,生成低維樣本作為新的特征樣本,進而實現(xiàn)降維的目的[17]。
假定有C個樣本類別,而數據X={xi∈Rn,i=1,…,N}則是N個n維的訓練樣本,則基于Fisher定理對空間J進行定義為:
(11)
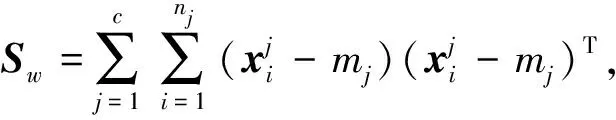
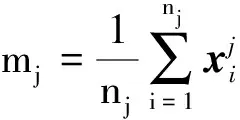
(12)
(13)
當Sw非奇異時,廣義特征方程的d(d≤C-1)個最大的特征值所對應的特征向量wi即為最佳投影矩陣W的列向量:
Sbwi=λSwwi
(14)
筆者將數據xi向子空間J進行投影,即yi=WTxi,則yi對應低維特征向量。
3.2 蝴蝶優(yōu)化算法
蝴蝶在飛行時,會在周圍散發(fā)一種氣味,其他蝴蝶聞到該氣味后,會基于香味的濃度而被吸引。當某只蝴蝶聞到最佳香味時,會朝著散發(fā)氣味的蝴蝶靠近,這個過程稱為全局搜索階段;而當蝴蝶無法聞到任何蝴蝶氣味時,將在全局搜索范圍內隨機選擇移動位置,這個過程稱為局部搜索階段[18]。
蝴蝶會在飛行時散發(fā)氣味,定義氣味濃度為:
f=cIa
(15)
式中:I為刺激強度;c為感知形態(tài);a為激勵系數。
蝴蝶的運動模型包含兩個階段:
1)全局搜索階段
蝴蝶在飛行中會散發(fā)氣味,其他蝴蝶會按照聞到的氣味濃度來搜索目標,模型定義如下:
(16)
式中:xi(t)為迭代t時蝴蝶i的位置;g*為全局最佳解;r1為[0,1]之間的隨機數;fi為蝴蝶i的氣味濃度。
2)局部搜索階段
若蝴蝶缺乏感知其他蝴蝶氣味的能力,則它將在搜索范圍內隨機移動,模型定義為:
(17)
式中:xj(t),xk(t)為任意選擇的蝴蝶;r2為[0,1]之間的隨機數。
BOA進行全局尋優(yōu)或局部尋優(yōu)的概率由閾值P決定,在每次迭代時會隨機生成隨機數r3,并與P進行對比,定義為:
(18)
4 ICEEMDAN-IMWPE-LDA-BOA-SVM方法
4.1 故障診斷流程
基于上述理論介紹,筆者提出了基于ICEEMDAN信號重構、IMWPE特征提取、LDA特征降維、BOA-SVM模式識別的齒輪箱故障診斷方法。
該方法的主要診斷步驟如下:
1)采集齒輪箱在多個常見工況下的振動信號,并將其分割為長度為2 048的多組樣本;
2)采用ICEEMDAN對振動信號進行分解,基于IMF分量選擇原則,篩選得到包含主要信息的IMF分量,并進行信號的重構;
3)利用IMWPE提取重構信號的故障特征,并采用LDA進行特征降維,得到低維敏感特征,并將其分為訓練樣本和測試樣本;
4)利用BOA算法對SVM模型中的參數進行優(yōu)化。其中,對于蝴蝶種群,適應度設置為SVM對訓練樣本的識別精度;
5)判斷是否符合迭代終止條件,若符合則輸出最佳參數的(C,g)組合,并將其代入至SVM模型中;
6)將測試樣本輸入至優(yōu)化后的SVM模型中,實現(xiàn)故障的識別。
4.2 故障診斷實驗
4.2.1 實驗平臺及數據
為了檢驗ICEEMDAN-IMWPE-LDA-BOA-SVM方法,筆者采用東南大學的齒輪箱故障數據進行實驗。
齒輪箱故障實驗平臺如圖2所示[19]。

圖2 齒輪箱實驗平臺
該平臺由驅動電機、電機控制器、行星齒輪箱、平行齒輪箱和制動器等組成。
振動信號由布置在行星齒輪箱表面的振動加速度計以5 120 Hz的頻率進行采集。轉速和負載分2兩種,分別是20 Hz/0 V和30 Hz/2 V,筆者選擇30 Hz的振動數據進行分析;每種工況均截取60個長度2 048的樣本,其中30組用于訓練,剩余30組用于測試。
齒輪箱故障及樣本的詳細信息如表1所示。

表1 齒輪箱樣本的詳細信息
齒輪箱振動信號的波形如圖3所示。
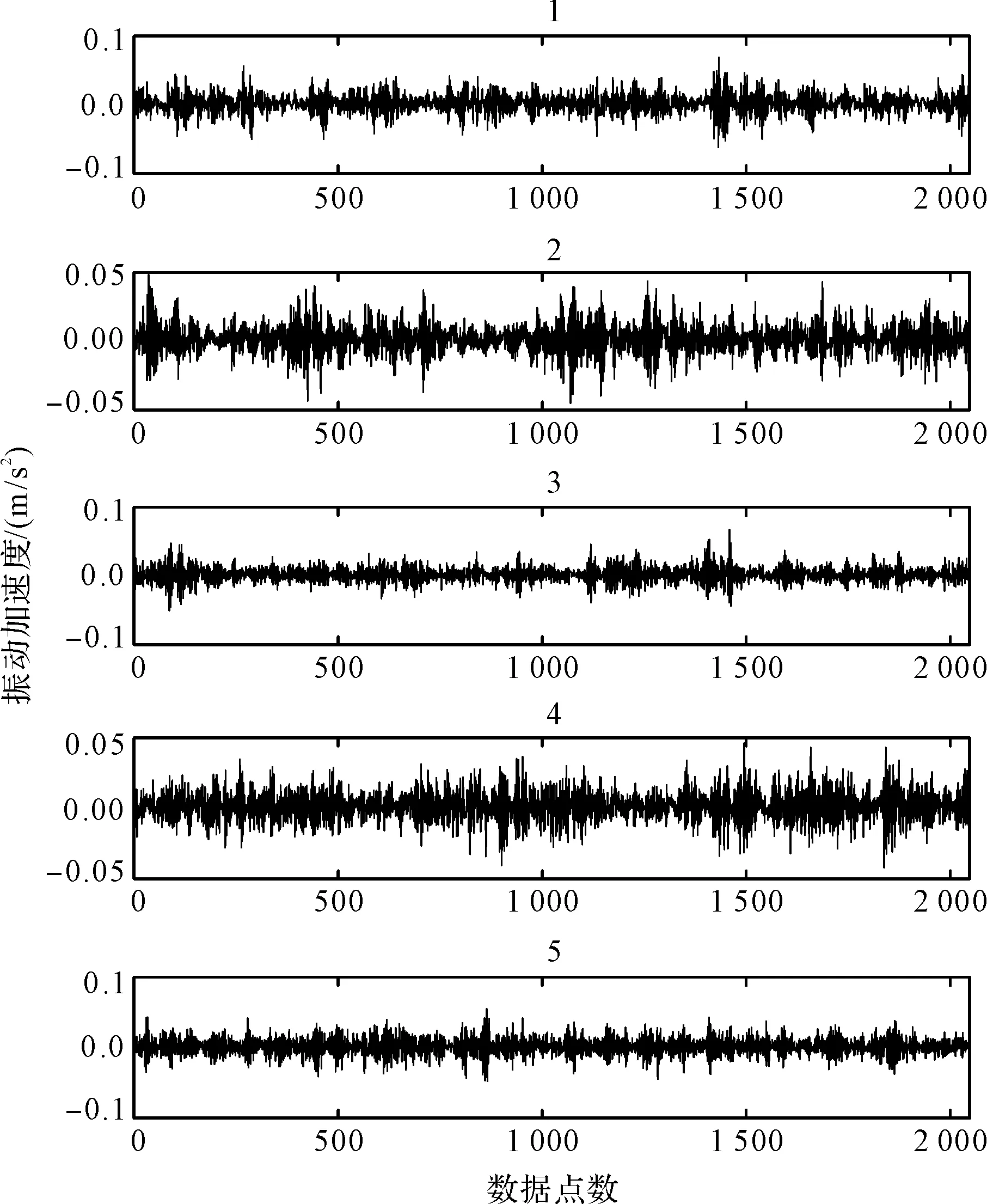
圖3 齒輪箱振動信號波形
4.2.2 結果與分析
首先,為了消除齒輪箱振動信號中的噪聲,筆者利用ICEEMDAN對振動信號進行分解,并進行信號的重構。
此處以健康齒輪振動信號為例,其ICEEMDAN的分解結果如圖4所示。
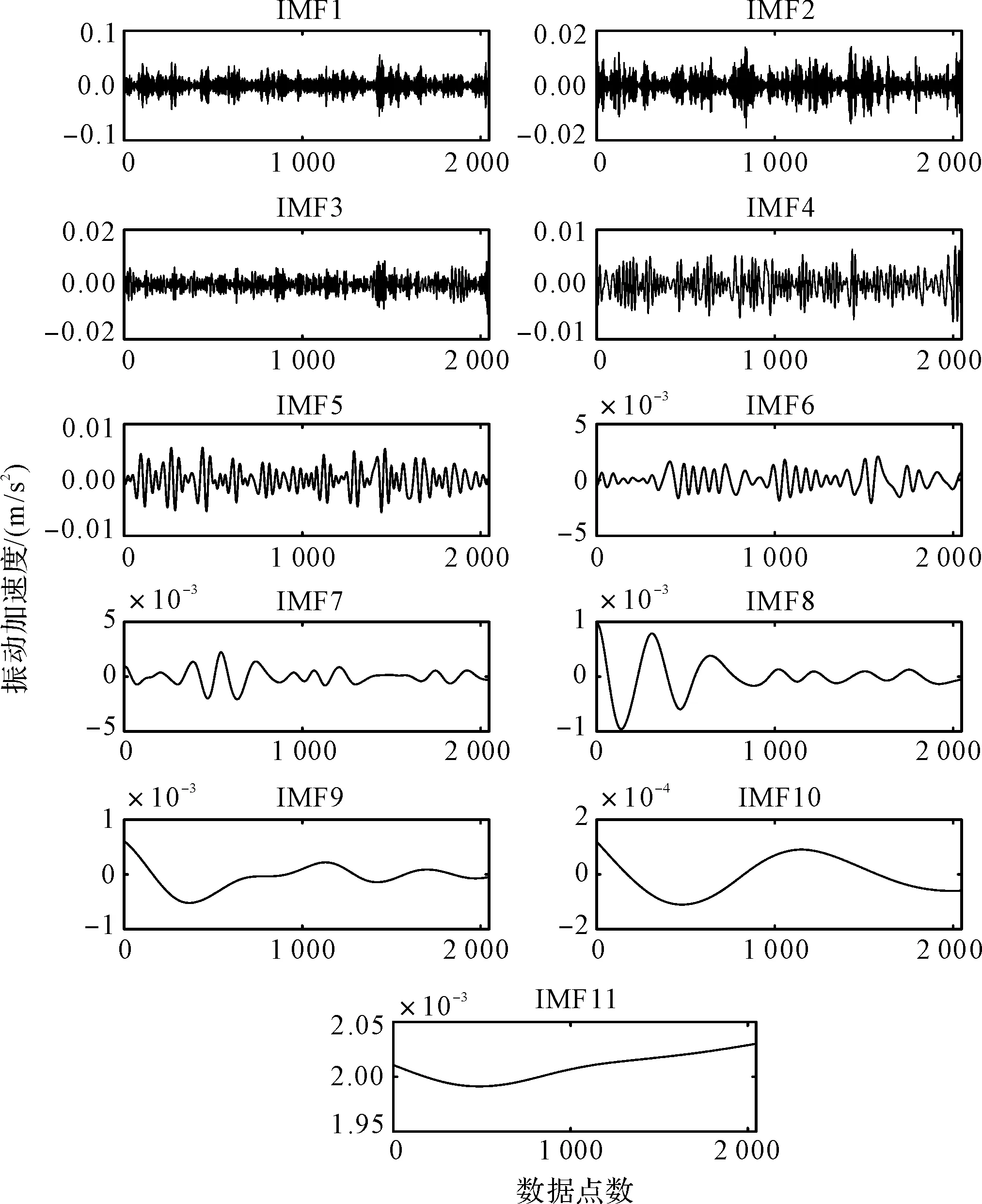
圖4 健康齒輪的ICEEMDAN分解波形
從圖4可以發(fā)現(xiàn):對于健康齒輪的振動信號而言,在經過ICEEMDAN分解后,不同頻率成分的特征信息實現(xiàn)了分離,但是高階IMF分量包含的信息較少,更多的是噪聲成分,有必要進行剔除。
為此,筆者基于相關系數,對IMF分量進行重要性評估。
所有樣本的相關系數如圖5所示。
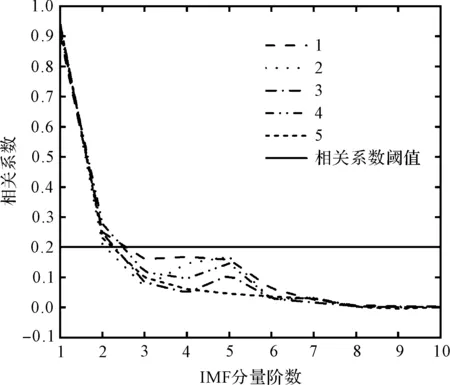
圖5 IMF分量與原始信號的相關系數
經過計算,5種工況樣本的相關系數閾值均近似為0.2,因此,筆者根據該閾值選擇IMF分量進行信號重構。
從圖5可以發(fā)現(xiàn):前兩階IMF分量的相關系數均大于閾值,即這兩個分量包含了原始信號的大部分故障信息,因此,筆者選擇這兩階分量進行信號重構。
重構信號如圖6所示。
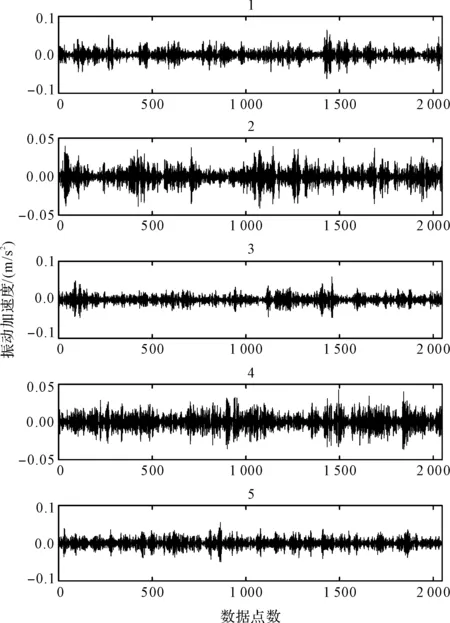
圖6 齒輪箱重構信號
從圖6可以發(fā)現(xiàn):經過信號重構后,部分的沖擊成分更加明顯(這是因為剔除的IMF分量中包含許多噪聲),可見,信號重構有利于突出核心的故障成分。
隨后,筆者利用IMWPE提取齒輪箱重構信號的故障特征,得到5種狀態(tài)下的IMWPE值,如圖7所示。
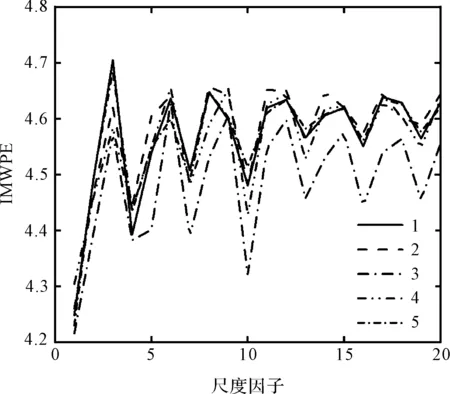
圖7 5種狀態(tài)下的IMWPE值
從圖7可知:5種狀態(tài)下的IMWPE值具有類似的趨勢,即熵值隨著尺度因子的變化而存在較顯著的波動,且在不同尺度下熵值存在明顯的交叉重疊,故不能直接將原始的故障特征輸入至分類器進行識別。
為了提高特征的準確率,筆者對IMWPE特征進行優(yōu)化,利用LDA對特征進行可視化降維,提取前2個故障特征進行分類識別。
5種工況樣本的LDA降維結果如圖8所示。
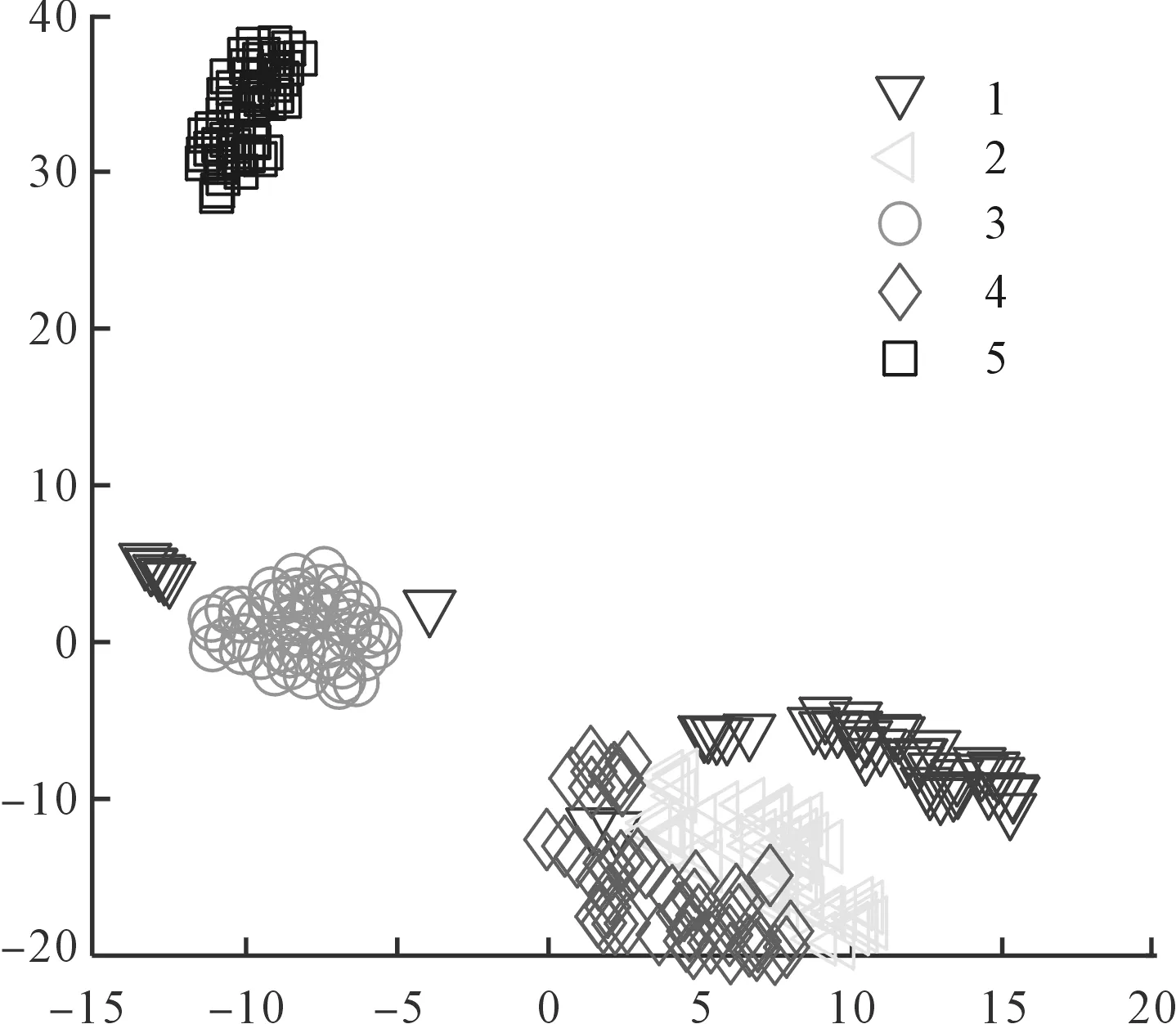
圖8 IMWPE特征的可視化
從圖8可知:基于ICEEMDAN-IMWPE提取的故障特征具有比較好的質量,可視化的結果表明,樣本5能夠實現(xiàn)完全的區(qū)分,而樣本4、樣本2、樣本1發(fā)生了較明顯的混疊,證明這3種樣本可能會出現(xiàn)錯誤識別的樣本。
筆者利用BOA方法,對支持向量機中的參數進行優(yōu)化,隨后對測試樣本進行識別。
ICEEMDAN-IMWPE-LDA-BOA-SVM的故障識別結果,如圖9所示。

圖9 ICEEMDAN-IMWPE-LDA-BOA-SVM的故障識別結果
從圖9可知:ICEEMDAN-IMWPE-LDA-LDA-BOA-SVM故障診斷方法僅錯誤識別了一個樣本,即將樣本3錯誤識別為樣本2,總的準確率為99.33%。
該結果證明,該方法能夠較為有效地識別齒輪箱的故障類型,具有一定的應用潛力。
為了驗證ICEEMDAN-IMWPE-LDA-BOA-SVM故障診斷方法相對于其他故障診斷方法的優(yōu)劣,筆者從3個維度開展對比分析。
1)特征提取維度對比
筆者將ICEEMDAN-IMWPE-LDA故障特征提取方法分別與EEMD-IMWPE-LDA故障特征提取方法、IMWPE-LDA故障特征提取方法和ICEEMDAN-IMWPE故障特征提取方法進行比較,利用上述幾種方法進行故障特征提取。
筆者將特征輸入到BOA-SVM中進行故障識別,識別結果如圖10所示。

圖10 不同故障特征提取方法的診斷結果
4種方法的詳細診斷結果如表2所示。

表2 4種特征提取方法的故障診斷結果
由表2可知:經ICEEMDAN-IMWPE-LDA故障特征識別后的準確率高于EEMD-IMWPE-LDA特征提取方法,ICEEMDAN算法在特征提取效果方面優(yōu)于EEMD的原因是,EEMD進行信號重構時無法完全去除信號中的噪聲和干擾。
ICEEMDAN-IMWPE-LDA和EEMD-IMWPE-LDA的準確率高于IMWPE-LDA,即對信號進行分解和重構的準確率高于對原始信號進行分析的準確率,這是因為原始信號中的噪聲會對分析結果造成極大影響。
而ICEEMDAN-IMWPE-LDA的結果高于ICEEM-DAN-IMWPE方法,這是因為LDA特征降維有效去除了冗余信息,突出了核心故障信息,從而提高了識別準確率。
2)熵值方法對比
為了證明IMWPE方法在特征提取中的優(yōu)越性,筆者利用改進多尺度排列熵(improved multiscale permutation entropy,IMPE)、MPE、多尺度加權排列熵(MWPE)、基于方差的多尺度加權排列熵(multiscale weighted permutation entropy based on variance,MWPE_rms)進行對比,并將采用上述5種方法提取的故障特征經過LDA降維,然后將其輸入至BOA-SVM中,進行故障的識別。
筆者重復10次上述操作,得到了故障診斷結果,如表3所示。
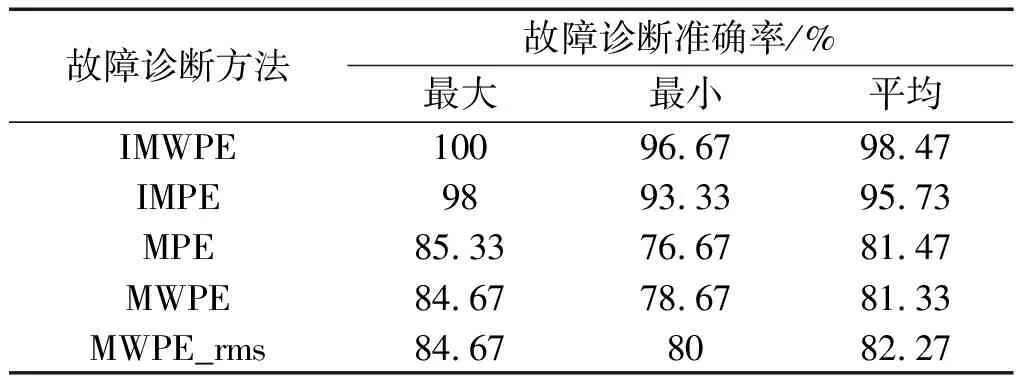
表3 故障診斷結果對比
由表3可知:基于IMWPE的故障診斷方法實現(xiàn)了98.47%的平均識別準確率,高于其他4種診斷方法;與其他4方法相比,該方法多次實驗的平均識別精度分別高了2.74%、17%、17.14%和16.20%,證明了其具有較好的穩(wěn)定性;同時,其最小準確率為96.67%,表明其能夠穩(wěn)定可靠地識別齒輪箱的不同故障類型。
3)分類模型對比
為了驗證BOA-SVM的可行性,筆者采用常見的遺傳算法優(yōu)化支持向量機(genetic algorithm optimized support vector machine,GA_SVM)、粒子群算法優(yōu)化支持向量機(particle swarm optimization optimized support vector machine,PSO_SVM)和差分算法優(yōu)化支持向量機(differential evolution optimized support vector machine,DE_SVM)進行故障診斷對比,得到的診斷結果如表4所示[20-22]。
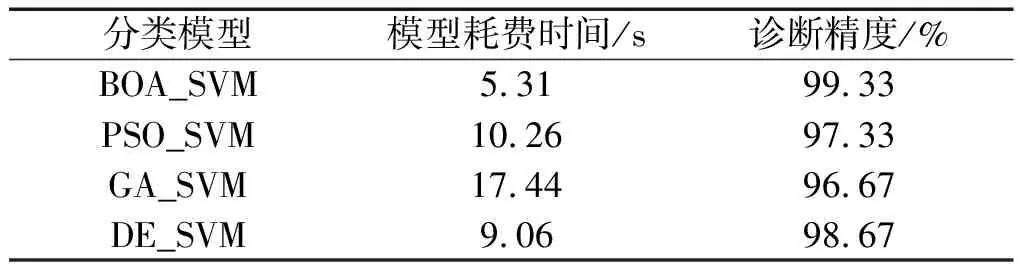
表4 故障診斷結果對比
由表4可知:相較于其他3種故障診斷模型,基于BOA優(yōu)化的SVM取得了最高的故障診斷準確率和效率,診斷精度為99.33%,用時5.31 s,比GA_SVM縮短了近三分之二的時間,比PSO_SVM縮短了近一半的時間,說明BOA優(yōu)化得到的參數最優(yōu),同時耗時最少,在故障診斷中最具有優(yōu)勢。
筆者基于多個維度開展了對比實驗,結果表明ICEEMDAN-IMWPE-LDA-BOA-SVM方法在效率和準確率方面均具有一定的優(yōu)越性。
5 結束語
綜上所述,筆者提出了一種基于ICEEMDAN信號重構、IMWPE特征提取、LDA特征降維和BOA-SVM故障識別的齒輪箱故障診斷方法,并利用東南大學齒輪箱數據集對其進行了實驗,以驗證該方法的有效性。
研究結論如下:
1)采用ICEEMDAN對信號進行處理,結合相關系數分量篩選準則能夠實現(xiàn)信號的降噪和重構。利用齒輪箱數據集對ICEEMDAN-IMWPE-LDA-BOA-SVM方法進行了驗證,得到的故障識別準確率為99.33%,證明了該方法的有效性;
2)在提取故障特征方面,基于均方根的IMWPE特征提取方法優(yōu)于IMPE、MWPE、MPE和MWPE_rms方法,多次實驗的平均識別精度也得到了不同程度的提高;
3)采用BOA對SVM的懲罰系數和核函數參數進行了優(yōu)化,減小了分類識別的不確定性,增加了分類精度,同時降低了模型的訓練時間;與其他3種分類模型相比較,其效率最高,診斷時間只需5.31 s,診斷精度為99.33%,在故障診斷中更具比較優(yōu)勢。
雖然該方法取得了不錯的損傷識別結果,但最低識別準確率為96.67%,證明診斷性能存在提升空間。后續(xù),筆者將進一步降低信號中的噪聲,提升故障識別精度。
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
