向量搜索在電商商品批量檢索的應用
2023-11-15 01:51:28朱俊
寶鋼技術 2023年4期
朱 俊
(歐冶工業品股份有限公司,上海 201900)
1 批量檢索背景介紹
在采購任務的背景下,企業或組織通常需要采購大量的工業品,以滿足生產和運營的需求。這些工業品可以包括原材料、零部件、設備和其他必要的物資。為了高效地完成采購任務,采購商經常依賴于工業品電商平臺,這些平臺提供了一個集中展示和銷售各種工業品的市場。
然而,傳統基于分詞索引的搜索方法在處理這類批量檢索任務時面臨許多困難,這些困難點限制了采購商在工業品電商平臺上的效率和準確性:
(1)大規模查詢:采購商需要查詢大量的商品以了解不同產品的特性、價格和供應商等信息。傳統的搜索方法在處理大規模查詢時往往效率低下,需要耗費大量時間和資源。
(2)搜索時間長:采購商需要盡快獲得關于大量商品的信息,以便做出及時的決策。然而傳統的搜索方法由于基于分詞索引和詞條匹配的方式,搜索時間較長,無法滿足采購商的快速查詢需求。
(3)意圖理解困難:傳統搜索方法無法理解采購商的意圖。它們只依賴于詞條匹配,而無法準確捕捉采購商的具體需求和意圖。這導致搜索結果可能不夠準確,使采購商在評估和比較商品時面臨困難。
(4)不準確的搜索結果:傳統方法的詞條匹配搜索可能產生不準確的結果,因為它們無法考慮商品的多維特征和相似性。這使得采購商在選擇合適的商品時可能遇到困難,增加了采購決策的風險。
綜上所述,批量采購任務在工業品電商平臺上存在一些挑戰和困難。為了解決這些問題,引入向量搜索技術可以提供快速、準確的商品檢索,同時能夠更好地理解采購商的意圖,提升搜索結果的準確性和效率。
2 向量搜索技術背景介紹
2.1 向量搜索框架和原理
向量搜索技術也被稱為近似最近鄰搜索(approximate nearest neighbor search,ANN),是一種針對海量高維數據進行快速查詢的算法技術。該技術的基礎是將復雜的對象或數據轉換成高維空間中的向量,通過計算向量之間的距離來進行相似性比較。在人工智能和機器學習領域,數據通常被表示為高維向量。例如,在自然語言處理中,詞語和句子可以被表示為高維向量,這就需要使用向量搜索技術來查找最相關的信息。
向量搜索技術可應用于較多場景,例如在推薦系統中,需要找出與用戶歷史行為最相似的物品來進行推薦,可以將用戶的行為和物品的屬性都轉化為向量,然后通過計算向量之間的距離來找出最相似的物品;在圖像和視頻搜索中,可以將圖像和視頻的特征提取出來,轉化為向量,然后通過向量搜索技術來找出最相似的圖像或視頻;在自然語言處理里,可以將詞語和句子轉化為向量(詞向量和句向量),然后通過向量搜索技術來完成諸如語義搜索,文本相似度計算,機器翻譯等任務。在生物信息學領域,基因序列、蛋白質序列等也可以被表示為高維向量,通過向量搜索技術快速找出具有相似特性的基因或蛋白質。
向量搜索能夠將語義信息映射到高維向量空間中,通過向量間的相似度計算,在檢索過程中找到與查詢條件相似的對象。向量搜索框架通常包括以下幾個部分:
(1)向量表示:利用深度學習模型(如Word2Vec、GloVe、BERT等)進行嵌入,將被搜索文本轉換成高維向量。這些模型通過對大量文本數據進行訓練,學習到每個詞匯(或短語)在語義空間中的表示,從而捕捉詞匯間的關系和上下文信息[1]。
(2)索引構建:以哈希表等數據結構構建好文本向量索引,并采用近似的搜索策略[2]。例如FAISS、Annoy、HNSW等都是流行的向量索引庫。
(3)查詢處理:將用戶的查詢轉換為相應的向量表示,然后在索引中檢索與該查詢向量相似的結果。相似性通過計算查詢向量與索引中向量之間的距離來實現。
(4)結果排序與優化:對檢索到的結果進行排序和優化,以提供更準確的檢索結果。
2.2 向量搜索用于批量檢索的優點
相較于傳統搜索方法,向量搜索在批量檢索方面支持批量快速運行,可高效地在大規模向量空間中查找最相似的結果。此外向量搜索方法能夠捕捉詞匯和語義信息,使得向量搜索能夠更好地理解用戶輸入的搜索語句,并在搜索結果中體現語義相關性。
3 基于向量搜索的批量檢索方案及試驗結果分析
3.1 基于FAISS的商品批量檢索方案
本文提出了一種基于FAISS的向量搜索方案,用于快速搜索大規模向量數據集中與給定向量最相似的項[3],具體步驟如下:
(1)商品的文本嵌入。
首先通過內部商品數據產生一個文本嵌入模型。這里采用Sentence-BERT模型作為文本嵌入工具,Sentence-BERT能夠結合人工整理后的商品專業詞庫按詞進行嵌入,相比BERT按token嵌入有更好的效果[4]。方案中采用1 790 100條商品數據進行微調,包含商品名稱、型號規格、品牌、技術屬性信息、商品類別信息等。
(2)建立FAISS索引。
通過微調后將每個商品嵌入768維的向量并建立FAISS indexFlatL2索引,即通過計算搜索文本與商品向量的歐幾里得距離進行索引(圖1)。

圖1 商品嵌入及FAISS索引建立
(3)搜索文本加強。
借助積累好的品牌、型號規格詞庫,通過對搜索文本進行處理以加強搜索文本的特征,處理內容包括:
① 基于型號規格詞庫,使用jieba分詞提取文本中的型號規格信息。
② 基于商品專業詞庫,使用Sentence-BERT分詞對搜索文本進行分詞。
③ 使用Sentence-BERT對搜索文本進行嵌入。
(4)FAISS召回。
使用FAISS對搜索文本進行召回,取相較于搜索文本向量的歐幾里得距離最近的1 000條商品作為召回結果,并對計算得到的歐幾里得距離進行歸一作為距離權重。搜索文本對第i個召回結果的距離權重S1i的計算方法為:
(1)
式中:Dmax為1 000個召回結果中的最大距離;Di為第i個召回結果的距離。
(5)型號規格權重計算。
對搜索文本中提取出來的型號規格進行切詞,得到一系列切開的型號規格,并去除空格、逗號等無意義符號。計算搜索文本對第i個召回結果的型規權重S2i:
(2)
式中:Ci為搜索的型號規格切詞在第i個召回結果中出現的個數;L為搜索文本切詞的數量。
(6)加權排序。
將距離權重S1i和型規權重S2i加權相加,得到第i個召回的排序權重Si(圖2):
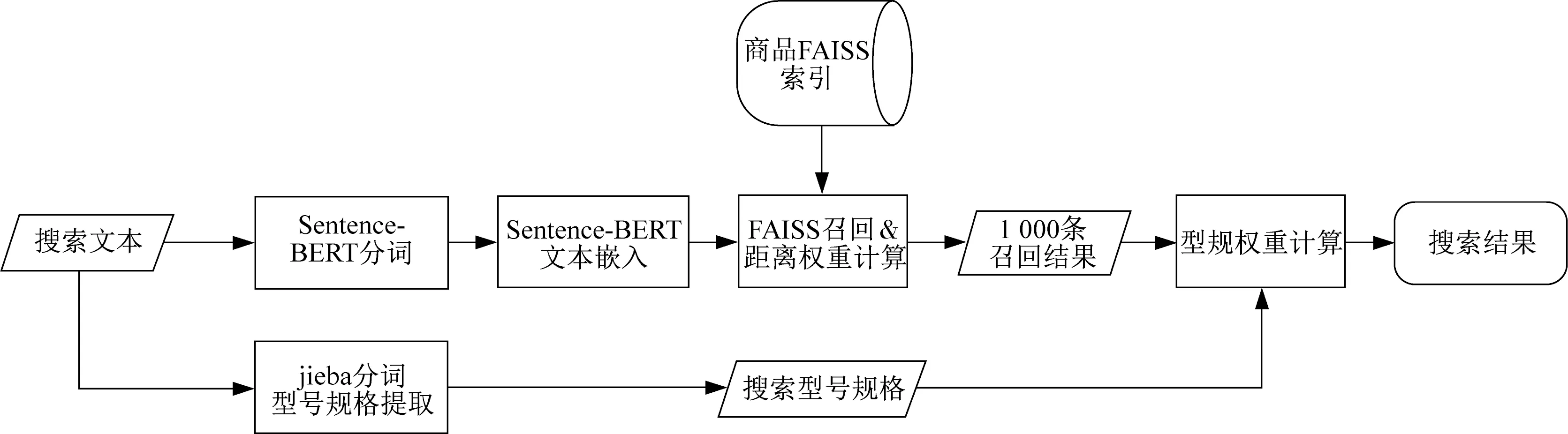
圖2 搜索文本召回及排序
Si=0.3S1i+0.7S2i
(3)
因為應用場景中對型號精確匹配有較高的要求,故此處經人工試驗后距離權重S1i的加權設置為0.3,型規權重S2i的加權設置為0.7,加權可以根據實際場景需求進行調整。計算每個商品的排序權重后,根據排序權重進行降序排序,取前五個結果作為匹配結果。
上述步驟為針對單條搜索文本的處理過程,在批量搜索的場景中,采用FAISS的批量索引方法進行批量召回及距離權重計算,再針對每條搜索文本進行常規權重計算和加權排序即可。
3.2 試驗結果對比
基于FAISS的向量搜索方案與傳統基于分詞索引的ES搜索從如下兩個方面進行對比:
(1)準確率Precision。
取Precision@20、Precision@10、Precision@5,即分別取20、10、5個返回結果,判斷它們是否都符合搜索意圖,若有不符合的則認為此條結果不準確,取正確結果數量/n作為準確率。
(2)搜索耗時。
以100條商品搜索信息(包含搜索商品名稱與主要型號規格信息,且每條商品均有5條以上可匹配商品)為輸入,從170 W商品集合中進行數據匹配,此外,ES搜索和FAISS向量搜索部署在同一臺服務器上,算力及網絡環境相同。本次采用FAISS-CPU模式,未使用GPU資源進行加速。搜索準確率對比如表1所示。
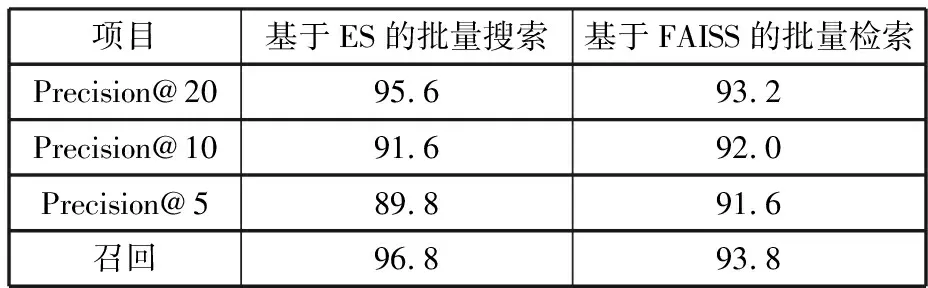
表1 基于ES和FAISS的批量檢索準確率對比
試驗結果表明,在搜索速度上向量搜索有較大優勢,在100條搜索文本下向量搜索僅需4.40 s就能完成搜索,而ES需要耗時約18.21 s。但FAISS相對ES搜索的召回率略低,經結果分析發現,主要問題在于文本嵌入模型無法很好地學習一些低頻專業詞的語義,尤其是型號規格,而當搜索文本僅包含型號規格時,向量搜索無法召回全部正確結果,此問題后續可以通過針對這些語義理解效果差的詞進行數據增強,并再次微調Sentence-BERT以優化語義嵌入表現。這仍將導致FAISS檢索在Precision@20的準確率略低于ES搜索。但由于FAISS檢索在召回階段后可以加入更精細的排序策略,因此排序效果優于ES搜索,在Precision@10以及Precision@5上均高于ES搜索。
4 結語
本文針對電商商品批量檢索場景,提出了一種基于FAISS的向量搜索方案。相較于傳統搜索方法,該方案具有搜索速度快、能夠理解搜索語義及針對召回結果進行精確排序的優勢。本文提出的方案仍有改進空間,例如可嘗試更多的預訓練模型,以及在后處理排序階段可以考慮更多的特征進行加權。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
甘肅教育(2020年8期)2020-06-11 06:10:02
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
制造技術與機床(2019年10期)2019-10-26 02:48:08
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
電子制作(2018年18期)2018-11-14 01:48:06
兒童繪本(2018年5期)2018-04-12 16:45:32
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
