基于深度學習技術的青銅鼎分期斷代研究
2023-11-02 16:04:06李春桃戚睿楊溪周日鑫
出土文獻 2023年3期
李春桃 戚睿 楊溪 周日鑫


摘 要:分期斷代是青銅器研究的重要基礎,但銅器斷代工作具有較高的專業門檻,一直依賴少數專家人工完成。人工智能的迅速發展,使青銅器智能斷代成為可能。本文以青銅鼎為對象,提出利用人工智能深度學習技術對先秦時期青銅器進行斷代的方法,并從數據處理、模型搭建、具體實驗、結果分析等多個角度展開研究。實驗結果表明,人工智能模型能夠準確判斷絕大多數青銅鼎的時代。同時,研究成果也已轉換成實際應用,模型已經部署于微信小程序。
關鍵詞:青銅器 斷代 人工智能 應用
青銅器在中國先秦時期具有舉足輕重的地位,所以夏商周三代又被稱作“青銅時代”。青銅器研究對于考古學、歷史學、文字學都有著積極的意義,而青銅器的分期斷代又是青銅器研究的重要部分。只有在分期斷代基礎上,青銅器才能成為有效的史料。郭沫若對此曾有專門討論:“時代性沒有分劃清白,銅器本身的進展無從探索,更進一步的作為史料的利用尤其是不可能。就這樣,器物愈多便愈感覺著渾沌。”(郭沫若: 《青銅器時代》,《青銅時代》,北京: 科學出版社,1957年,第301頁。)其說甚是,這充分說明了分期斷代在青銅器研究中的重要性。
追溯歷史,漢代便有青銅器出土,但數量極少,尚不具備深入研究的條件。宋代金石學興起,青銅器的研究也開始起步,宋人更多集中于青銅器的搜羅與著錄,研究水平并不突出。清人在這一領域的認識已頗為深入,然而他們更重視金文,對于青銅器本身,尤其青銅器年代的討論較少,沒有形成一定的規模。真正科學的青銅器分期斷代研究是從20世紀30年代開始的,郭沫若在《兩周金文辭大系》中提出“標準器斷代法”,即先根據銘文內容確定某件器物的年代,以此作為標準器,再去系聯和推定那些與標準器在銘文內容、器物形制、花紋特點等方面相關的器物的時代。(郭沫若: 《兩周金文辭大系》,手寫影印本,1932年,第7頁。)此方法的提出為青銅器的斷代奠定了科學的基礎,也被當時的學者廣泛接受。其后陳夢家、唐蘭等人又作了進一步的闡發。(陳夢家: 《西周銅器斷代》(一至六),《中國考古學報》1949年第9—10冊(合訂本)、《考古學報》1956年第1—4期,后連同未發表稿被整理成《西周銅器斷代》,北京: 中華書局,2004年;唐蘭: 《西周青銅器銘文分代史征》,北京: 中華書局,1986年。)隨著考古學的逐步發展、完善,又出現了綜合運用類型學與地層學對青銅器進行分期斷代的方法,即在某一類青銅器內劃分出“型”和“式”,總結出每期銅器的器形、花紋特點,再結合相伴出土的陶器,并與考古單位中的地層關系的分析相互對應,進而確定青銅器的年代。(鄒衡: 《試論殷墟文化分期》,《北京大學學報(人文科學)》1964年第4—5期;李豐: 《黃河流域西周墓葬出土青銅禮器的分期與年代》,《考古學報》1988年第4期。)
上述兩種方法各有特點,在遇到具有長篇銘文且記載時代明確的器物時,第一種方法更為有效,有時甚至能夠確定器物的絕對年代。而面對只有短篇銘文或無銘的青銅器時,后一種方法更為適合。當然,兩種情況不是絕對的,很多時候是兩種方法并用。若想對青銅器進行準確的分期斷代,既需要掌握專業的考古學知識,也需了解專門的古文字學知識。再加上青銅器的類別多、數量大,青銅器斷代難度非常大,導致只有少數專家才精通這一研究領域,普通大眾想要快速了解某件器物的時代頗為不易;外專業研究者若要使用某件銅器作為參考資料,也需花費大量時間去翻查相關書籍。
近年來人工智能發展迅速,尤其是深度學習技術具有學習、分析、總結的能力,能夠對文字、圖像和聲音等數據進行識別、歸納與分類。鑒于深度學習技術已經具備了分析圖像的能力,所以已有學者將人工智能運用到文物研究當中,如利用人工智能技術綴合甲骨殘片,(莫伯峰、張重生、門藝: 《AI綴合中的人機耦合》,《出土文獻》2021年第1期,第19—26頁。)開展陶瓷器物斷代工作等。(馮金牛等: 《基于卷積神經網絡的中國古陶瓷智能斷代研究》,《陶瓷學報》2022年第1期,第145—151頁。)同樣,也可考慮利用人工智能技術開展青銅器的分期斷代工作。上文介紹的標準器斷代法和類型學與地層學結合法,兩者的共同點是都需要根據青銅器的客觀外在形態將器物系聯起來,器物的形狀、花紋等外在特征是建立系聯的關鍵所在。而深度學習技術擅長發現樣本的內在特征、挖掘樣本的變化規律,進而完成數據的辨識與分類,這與專家根據器物的特征進行斷代在方法上具有一致性。可見,利用人工智能深度學習技術開展青銅器的分期斷代研究在方法上是可取的。
在明確了可行性后,經過近兩年的努力,我們收集并標注了大量數據,搭建了深度學習智能模型,完成了實驗,并推出了可實際應用的智能斷代程序。目前已經完成鼎、簋等食器部分的工作。篇幅所限,下面先就青銅鼎的情況展開介紹。此處需要說明的是,本文面向的群體主要是人文學科研究者,行文時會盡量采用文科論文的表述方式,一些繁瑣的計算公式和人工智能層面的技術研究詳參另文。下面便從科學研究和應用實現兩個方面展開討論。
一、 科學研究
鼎是青銅器中數量最多的器類之一,其發展貫穿整個先秦時期: 在數量方面,具備交叉研究的基礎;在時代跨度方面,具有交叉研究的空間。我們主要利用基于深度學習模型的圖像識別和細粒度分類方法,提取并分析樣本特征相似度,融合青銅器的專業知識開展研究。對于人工智能技術而言,青銅器分期斷代本質上是一項分類任務,但與其他分類任務也存在區別,即青銅器數據是一個專業性較強的數據集,其中很多細微特征需要依靠專業知識才能分辨清楚。因此我們在數據處理、屬性標注、模型搭建等方面都盡量考慮到青銅器數據自身的特殊性。
1. 數據收集與標注
在數據收集方面我們目前使用的是青銅鼎的二維圖像。數據均取自正式的出版書籍或發掘報告,還有一些來源于公開的數據庫資源。其中大型著錄文獻包括《中國青銅器全集》(中國青銅器全集編輯委員會編: 《中國青銅器全集》,北京: 文物出版社,1994—1998年。)《商周青銅器銘文暨圖像集成》《商周青銅器銘文暨圖像集成續編》《商周青銅器銘文暨圖像集成三編》(吳鎮烽編著: 《商周青銅器銘文暨圖像集成》,上海: 上海古籍出版社,2012年,以下簡稱“《銘圖》”;吳鎮烽編著: 《商周青銅器銘文暨圖像集成續編》,上海: 上海古籍出版社,2016年;吳鎮烽編著: 《商周青銅器銘文暨圖像集成三編》,上海: 上海古籍出版社,2020年。吳鎮烽先生編著的這三部著作有配套的電子檢索系統《金文通鑒》,本文多數青銅鼎的照片取自該系統。)《中國出土青銅器全集》(李伯謙主編: 《中國出土青銅器全集》,北京: 科學出版社、龍門書局,2018年。)等,以及其他一些青銅器圖錄與考古發掘報告。另外,“中研院”歷史語言研究所金文工作室研發的《殷周金文暨青銅器資料庫》中有的青銅鼎圖版存在不同副本,(“中研院”歷史語言研究所金文工作室: 《殷周金文暨青銅器資料庫》。)若有不見于其他著錄文獻的副本,也予以收錄。這部分材料在數據集中所占比例雖然不大,但是卻可呈現出同一件器物的不同角度,頗為重要。為了尊重、彰顯收藏單位或整理者所做的工作,我們在所開發的應用程序中為使用的每一件器物都標注了出處(詳后文)。
在圖像類別的選用上,收錄范圍包括器物的彩色照片、黑白照片、線圖摹本、全形拓等多種形式。其中,彩色照片占絕大多數。線圖摹本主要取自宋人、清人的著錄。由于多數線圖存在較大程度的失真,我們對線圖進行了篩選,選取其中效果較好、摹寫相對準確的圖像。全形拓圖像使用得最少。線圖摹本和全形拓在一定程度上會對人工智能模型造成干擾和障礙,影響模型的準確性。由于研究成果終會轉化成實際應用,考慮到實際使用情況,我們仍將這兩類圖像收錄其中。
目前共收集青銅鼎圖片樣本3690個,每一個樣本都結合學界的研究成果作了時代標注。共分為11個時代,具體包括商代早期、商代晚期、西周早期、西周中期、西周晚期、春秋早期、春秋中期、春秋晚期、戰國早期、戰國中期、戰國晚期。很多著錄對所收器物已給出了斷代意見,其判斷無誤者,我們直接承襲;其中明顯有誤者,我們對其做了校正,徑直給出正確的年代;而年代存在爭議的器物,我們擇善而從。某些書籍并未對器物的年代進行詳細劃分,如《中國出土青銅器全集》一書,多數情況下只是給出器物的模糊年代。面對這種情況,我們會進一步給出更為詳盡的判斷。如該書第一卷第18號收錄的一件圓鼎(見封三圖1),時代標注為“西周”,(李伯謙主編: 《中國出土青銅器全集》,第1卷,第17頁。)據其器形、花紋可知此鼎時代為西周早期,所以此器的年代標簽為“西周早期”。總之,收錄數據過程中會盡量結合學界已有的研究,為每一張青銅鼎的圖片標注出時代信息。
器物形制是分期斷代的基礎,所以我們也對青銅鼎的形制特征進行了標注。不同學者對青銅鼎的器形分類不同,對器物花紋的稱呼也存在差異。參考已有的青銅器研究,(上海博物館青銅器研究組: 《商周青銅器文飾》,北京: 文物出版社,1984年;王世民、陳公柔、張長壽: 《西周青銅器分期斷代研究》,北京: 文物出版社,1999年;彭裕商: 《西周青銅器年代綜合研究》,成都: 巴蜀書社,2003年;朱鳳瀚: 《中國青銅器綜論》,上海: 上海古籍出版社,2009年;彭裕商: 《春秋青銅器年代綜合研究》,北京: 中華書局,2011年;彭裕商: 《戰國青銅器年代綜合研究》,成都: 巴蜀書社,2018年。)我們將青銅鼎的形狀概括為29種,將花紋概括成67種。在具體標注時,口沿、腹部、足部等不同部位的花紋分別標注。將鼎耳的類型分為5種,鼎足的類型分為8種,另扉棱、蓋鈕等也分別進行了劃分,并利用工具進行了標注。例如伯鼎(見封三圖2),(《銘圖》,第2卷,1006號。)該器的標簽共15個: 鼎足4個,標簽為“鳥形扁足”;鼎耳2個,標簽為“立耳”;腹部紋飾共兩組,第一組標簽2個,為“獨體獸面紋”(一在正面,一在側面),第二組標簽2個,為“直身夔龍紋”(均在正面);扉棱共5組,標簽為“F形扉棱”。再如師湯父鼎(見封三圖3),(中國青銅器全集編輯委員會編: 《中國青銅器全集》,第5卷,北京: 文物出版社,1997年,第26頁,29號。)該器的標簽共12個: 其中足部3個,標簽為“蹄足”;耳部2個,標簽為“立耳”;腹部紋飾共兩組,標簽為“大鳥紋(回首)”;頸部紋飾共兩組,標簽為“長尾鳥紋”;頸部扉棱共兩組,標簽為“平直扉棱”。我們對目前所收集的全部青銅器都做了如上標注。
在數據分配方面,我們按照4∶1∶5的比例將整個數據集劃分為訓練集、驗證集、測試集。此處需要說明的是,在我們的劃分比例中,訓練集的數據占比較低,而測試集的占比較高。更少的訓練數據、更多的測試數據會增加模型的學習難度,不過能夠更全面準確地檢測模型的斷代效果,從而更有效地測試出該方法的有效性以及局限性。
2. 數據擴充與增強
為了使模型得到足夠的訓練,我們在研發過程中對數據進行擴充與增強。增強方式主要包括去除背景、灰度化、線條化和翻轉圖片等(見封三圖4)。限于篇幅,此處僅略述灰度化與線條化兩種方式。首先介紹灰度化的處理過程,任何顏色都由紅、綠、藍三原色組成,這三種顏色分別對應三個通道,而三個通道的每個數值取值在0—255之間。將彩色圖轉化為灰度圖,也就是將原本的紅綠藍三色通道合并為一個通道,最終將彩色圖版變成質量較高的灰度圖版,實現擴充數據的目標。將彩色圖版進行灰度處理,除了可以增大數據量外,對于那些本身只公布過灰度圖片的青銅鼎的時代判斷也有較大幫助。
線條化處理的關鍵在于識別圖版中的線條,也就是找出圖片中物體的輪廓和花紋信息。輪廓和花紋部位的像素值與其他部位的不同,非輪廓和非花紋部分的像素值是連續的,可以用高斯模糊的方法得到非線條部分。在原始圖片中減去非線條部分,即可得到原始圖片的線條,進而實現數據的擴充(見封三圖5)。通過彩色圖版的線條化,除了可以增大數據量外,對于判斷那些只存在線圖摹本的青銅鼎的時代也有一定的幫助。
通過以上方法,我們成功地對數據進行了增強與擴充,進而增加了訓練的數據量。同時,利用這些增強后的數據進行訓練也可提高模型的泛化能力,使其可以處理更為復雜的問題。
3. 模型搭建與實驗
針對青銅器的特殊性,我們搭建了一個用于分類斷代的深度學習模型。斷代模型如圖1所示,在模型中使用ResNet50作為骨干網絡,然后將ResNet50編碼后的特征向量輸入四個頭: 朝代頭、時期頭、器形頭、特征頭。其中朝代頭和時期頭作為多粒度分類的輸出,分別預測輸入青銅器所屬的朝代和時期。器形頭和特征頭分別預測輸入青銅器的單標簽器形和多標簽特征。同時,通過聯合朝代、時期、器形、特征等標注信息,我們建立一個知識引導的關系圖結構,使朝代和時期之間可以相互輔助學習,以將器形和特征等類型學上作為斷代依據的重要信息嵌入學習過程中。因為要依據器形和特征等綜合因素進行斷代,我們改進了概率分類的損失函數,從而最大化實現器形、特征與時代間的對應關系。(關于模型的搭建等技術問題此處僅略作交代,詳參: Rixin Zhou, Chuntao Li, Xi Yang, et al, MultiGranularity Archaeological Dating of Chinese Bronze Dings Based on a KnowledgeGuided Relation Graph,CVPR2023。)
在建立模型之后,便可利用數據對模型展開訓練。(為了對比效果,我們首先訓練的是只有時代標簽的圖像數據,其他標簽如器形、花紋等均未放入,訓練結束后進行了測試;隨后我們又訓練了既有時代標簽,同時也有器形、花紋特征標簽的數據,訓練結束后同樣進行了測試。結果顯示,按粗略時代劃分,后者較前者的準確率高出1.94%;按詳細時代劃分,后者較前者的準確率高出1.78%。可見,加注多種標簽的數據測試結果更優。所以我們在研發過程中使用的是加注多種標簽的數據。在實際應用中,標注并顯示出青銅器的器形以及花紋等特征更便于使用和參考。 )如圖2所示,基于深度學習的青銅器斷代過程可分為訓練和預測兩個步驟。首先,將完成標注的青銅器數據分成訓練集、驗證集、測試集三個部分。在訓練過程中,使用訓練集和驗證集對深度學習模型進行訓練和選擇。利用之前已經設計好的嵌入知識的深度學習模型,實現青銅器的斷代任務。通過輸入訓練數據,不斷優化和反復迭代更新模型的參數,得到可以充分提取青銅器斷代特征的已訓練模型。此后,在預測過程中,將待預測的青銅鼎圖像輸入已訓練模型,就可以得到智能模型所做出的判斷結果。
4. 測試結果
經過測試,我們發現經過訓練的模型已經具備獨立的斷代能力。在利用測試集進行測試時,在絕大多數情況下模型都能給出準確的斷代意見。我們可以通過粗略時代和詳細時代兩種劃分方式觀察測試結果: 粗略時代劃分,即把所有器物按照商代、西周、春秋、戰國四個大的時代進行區分,按照這種方式,模型的總體精度(Overall Accuracy)為88.79%;詳細時代劃分,即按前文所述的11個時代劃分,按照這種方式,模型的總體精度為78.83%(以上詳細數據參表1);這說明了利用人工智能技術可對青銅器進行分期斷代,而且深度學習模型還展現出較強的學習與斷代能力。為了說明模型的斷代能力,我們對比了其他12種最新的分類模型,利用同樣的測試集、訓練集、驗證集對這些模型進行訓練、測試,得出的對比結果如表1。(表中各項結果為百分數,%省略。下同。深色陰影數值者排名第一,淺色陰影者排名第二。人工智能領域更多使用“精度值(precision)”來體現模型的預測能力。為了便于文科讀者理解,我們此處使用“召回率(recall)”來衡量模型對每一類樣本的預測能力,即每一類預測準確的數值除以相應的數據總量所得出的百分比,也就是我們通常所說的準確率。表格中的數值即由此得出。)按照粗略時代測試,我們的模型在商代、西周、春秋、戰國四個時代上的準確率都排在了第一。按照詳細時代劃分,我們的模型有2個時代的準確率排在第一;有3個時代的準確率排在第二,在平均準確率上,我們的模型也排在第一。而在總體精度(Overall Accuracy)和AU(PRC)方面,我們的模型也均處于第一的位置。這充分說明我們構建的模型獲得了最好的斷代結果。
5. 結果分析
從總體上看,人工智能模型對青銅鼎的分期與斷代能夠給出很好的判斷。與此同時,對相關結果進行分析會給我們帶來更多的啟發與思考。經過分析與總結,我們發現影響模型準確率的因素包括訓練數據量的多少、圖版的清晰度、圖片的完整度、東周時期不同地域器形發展快慢差異、相鄰時代器形相似程度等幾個方面。
從表1所列數據不難看出,人工智能模型對不同時代的數據測試結果存在差異。其中,準確率最低的是戰國早期和戰國中期,其最主要的原因就是訓練數據總量少,兩者數據中訓練集數量分別只有31張和34張圖版,較其他時代的數量少很多。這使得模型可學習的樣本不夠豐富,測試結果準確率偏低。如果后期對數據進行進一步補充和增強,測試結果應該會得到明顯提升。
當然,如果訓練數據不夠充分,但是數據中的器形具有明顯的區別特征,模型完全能夠給出準確的判斷。如商代早期的訓練集數量是37張圖版,但是測試的準確率高達87.23%,結果并未受到訓練數據不足的影響。這是由于商代早期青銅鼎器形特征十分明顯,例如商代早期青銅鼎的尖錐足(圖3a)、方體深腹直壁(圖3b)等特征是其他時代的青銅鼎很少具備的,而模型能夠捕捉到這些特征并以此為依據進行分類。相對而言,戰國早期和中期的青銅鼎在器形上與相鄰時代的器物有很多相似性,加上訓練集中這兩個時代的數據本就不多,能提取到的特征也會受到限制,而這些特征有的還與其他時代的器物相近,這就使得這兩個時代的準確率偏低。
紋飾的風格及清晰度對模型測試準確率可能也造成了一定的影響。分析實驗結果可以看出: 自商代至春秋早期這六個時段較春秋中期至戰國晚期這五個時段人工智能模型的準確率高出很多。前者的平均準確率為83.69%,后者為59.28%,相差20多個百分點。推敲其原因,應當與鼎的花紋變化有著密切關系。商代至春秋早期青銅鼎上所施加的花紋圖3
圖像往往較大,如較早流行的獸面紋(圖3c)、鳥紋(圖3d)。稍晚流行的環帶紋、(李零先生據新出霸伯器銘文將環帶紋稱作山紋。參李零: 《山紋考——說環帶紋、波紋、波曲紋、波浪紋應正名為山紋》,《中國國家博物館館刊》2019年第1期。)竊曲紋、重環紋,整體上圖畫性更強,智能模型也更容易辨識。而自春秋中期開始,流行的是蟠螭紋(圖3e)、蟠虺紋(圖3f),這兩種花紋或呈帶狀,或布滿于器表,而不像獸面、鳥形那樣在器表上呈獨立的圖案,所以智能模型不易捕捉到這類紋飾的特征。如果數據集中圖像清晰度稍差,蟠螭紋與蟠虺紋甚至都無法體現出來。所以,智能模型對春秋中期以后青銅鼎的判斷準確率不如春秋中期以前的時段高。
青銅鼎圖片的清晰度會對模型測試準確率產生影響。如器形模糊,尤其是測試集數據中有的圖版與背景顏色區分不夠明顯(如圖3g),會形成辨識障礙,智能模型可能會把某些背景誤認作器物的一部分。除此之外,器物的拍攝角度也會對辨識產生影響,如俯視拍攝與直視拍攝會使同一件鼎在圖版上呈現出不同的效果,俯視拍攝的圖版鼎足往往會顯得略短,與數據集中絕大多數的正面拍攝照有所不同,所以在一定程度上造成器形失真,進而影響模型的識別準確率。
圖版中器物的完整性也會影響模型測試準確率。在收集數據時,為了保證數據的多樣性、全面性,我們將部分器形殘缺的青銅鼎圖版也收錄在數據集中。一旦這些殘缺器形被劃分到測試集中,由于殘缺器形的數據總量極少,模型無法得到充分訓練,可能會對模型判斷形成干擾。例如曾子倝鼎(圖3h)被劃分到測試集中,(此鼎著錄于《銘圖》2388號。)從器形上看,屬于典型的春秋早期的曾國青銅鼎。該器三足殘缺,導致與其他常規鼎的形制略異,測試時模型將其判斷成西周晚期,其錯誤原因或許與器足缺失有很大關系。為了證明這一點,我們結合曾國早期其他青銅鼎的形制,試著將該器的三足加以復原,(復原過程中主要參考了曾國早期同類青銅鼎的形制,三足取自曾子仲GF9A8鼎(《銘圖》2214)。曾國此類青銅鼎有著極為鮮明的地域特色,相關討論參王恩田: 《上曾太子鼎的國別及其相關問題》,《江漢考古》1995年第2期;張昌平: 《曾國青銅器研究》,北京: 文物出版社,2009年,第127頁。)形成一幅器形完整的圖版(圖3i),重新利用模型進行測試。結果顯示,模型將其準確地判斷為春秋早期,器形的完整程度對模型分類的影響由此可見一斑。
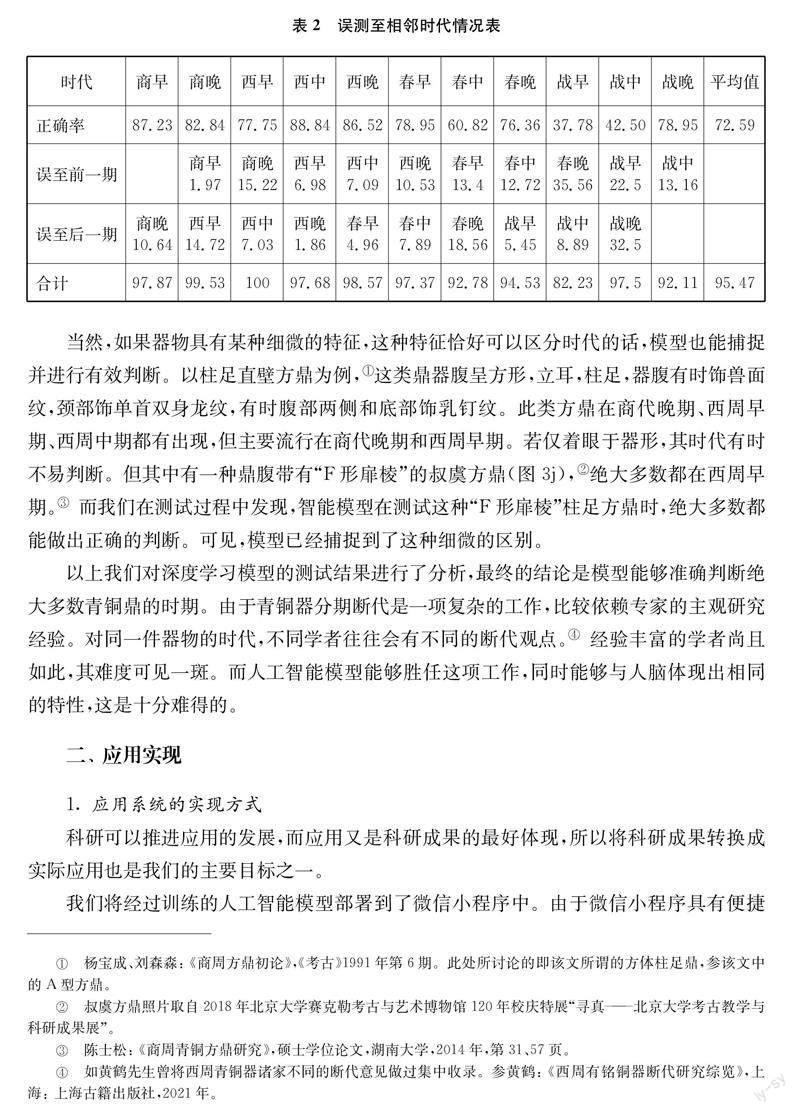
相鄰時代器形的相似程度是影響模型準確率的最大因素。我們知道不同時代的青銅鼎在器形、花紋等特征上存在差異。然而,器形及花紋的演變不是一蹴而就的,而是漸變的,這就導致相鄰時代之間器物的外在特征有很多相似之處。如商代晚期和西周早期某些青銅鼎極其相似,專家在判斷時,也容易出現誤差,人工智能模型同樣如此。我們注意到西周早期青銅鼎樣本數量在訓練集中占比較大(340件),比西周中期(171件)、西周晚期(111件)的訓練數據分別多出一倍或兩倍。但預測準確率為77.75%,反倒不如西周中期的88.84%、西周晚期的86.25%高。其主要原因就是西周早期和商代晚期部分青銅鼎十分相似,有很多特征是兩個時代所共有的,專家在判斷時即使結合銘文或者墓葬信息及伴出器物,有時仍無法給出確定的意見。對某些器物只能模糊處理,判定為“商末周初”。(如吳鎮烽先生在《銘圖》中將這部分器物標注為“商代晚期或西周早期”。)所以人工智能模型僅憑借器物外部特征進行斷代,也會出現誤差。我們提取后臺測試數據進行總結,發現西周早期青銅鼎的準確率為77.75%,而有15.22%預測為商代晚期,后者正好屬于兼具商代晚期與西周早期兩種特征的數據。如果把這些算入,西周早期的準確率就達到了92.97%,無疑是相當高的。同時,從這一點也看出: 模型對于商周之際的部分青銅鼎與人腦一樣難以作出準確區分,兩者的出錯點是相同的。這也從另一方面說明,經過專業訓練的模型能夠具有同專家相仿的能力。為了說明問題,我們把預測到相鄰時代的錯誤數據進行了統計,得出結果可參表2。若把誤測到相鄰時代的情況也算入的話,平均準確率可達95.47%,可見模型所預測的錯誤數據,多數都誤判入相鄰時代,這說明模型是能夠捕捉并獲取器物主要特征的。
當然,如果器物具有某種細微的特征,這種特征恰好可以區分時代的話,模型也能捕捉并進行有效判斷。以柱足直壁方鼎為例,(楊寶成、劉森淼: 《商周方鼎初論》,《考古》1991年第6期。此處所討論的即該文所謂的方體柱足鼎,參該文中的A型方鼎。)這類鼎器腹呈方形,立耳,柱足,器腹有時飾獸面紋,頸部飾單首雙身龍紋,有時腹部兩側和底部飾乳釘紋。此類方鼎在商代晚期、西周早期、西周中期都有出現,但主要流行在商代晚期和西周早期。若僅著眼于器形,其時代有時不易判斷。但其中有一種鼎腹帶有“F形扉棱”的叔虞方鼎(圖3j),(叔虞方鼎照片取自2018年北京大學賽克勒考古與藝術博物館120年校慶特展“尋真——北京大學考古教學與科研成果展”。)絕大多數都在西周早期。(陳士松: 《商周青銅方鼎研究》,碩士學位論文,湖南大學,2014年,第31、57頁。)而我們在測試過程中發現,智能模型在測試這種“F形扉棱”柱足方鼎時,絕大多數都能做出正確的判斷。可見,模型已經捕捉到了這種細微的區別。
以上我們對深度學習模型的測試結果進行了分析,最終的結論是模型能夠準確判斷絕大多數青銅鼎的時期。由于青銅器分期斷代是一項復雜的工作,比較依賴專家的主觀研究經驗。對同一件器物的時代,不同學者往往會有不同的斷代觀點。(如黃鶴先生曾將西周青銅器諸家不同的斷代意見做過集中收錄。參黃鶴: 《西周有銘銅器斷代研究綜覽》,上海: 上海古籍出版社,2021年。)經驗豐富的學者尚且如此,其難度可見一斑。而人工智能模型能夠勝任這項工作,同時能夠與人腦體現出相同的特性,這是十分難得的。
二、 應用實現
1. 應用系統的實現方式
科研可以推進應用的發展,而應用又是科研成果的最好體現,所以將科研成果轉換成實際應用也是我們的主要目標之一。
我們將經過訓練的人工智能模型部署到了微信小程序中。由于微信小程序具有便捷性、兼容性、易安裝、易傳播等優勢,所以我們將其作為青銅器智能斷代程序的首選載體。微信小程序后端的實現方式多種多樣,考慮到與人工智能模型的一致性,我們采用Python語言作為后端語言并基于Flask框架加以實現,從而完成了小程序的部署。
2. 應用系統的組織結構
本系統具有兩個主要功能: 一是青銅器智能辨類與斷代;(“辨類”指辨識青銅器的類別。如用戶分別上傳青銅鼎、青銅簋的圖片,模型會自動辨識出圖片對應的器類。)二是青銅器數據庫(功能示意圖可參圖4)。前者智能斷代部分包括對青銅器的自動斷代和對青銅器特征部位的自動檢測。我們使用兩個不同的智能模型來實現上述兩種功能: 一個是上文已經討論的深度學習模型,在經過訓練之后,能夠自主判斷青銅器的年代;另一個模型則專門用來檢測青銅器的特征,并給出相應的名稱,如紋飾、器形等。
青銅器數據庫方面,本系統提供了我們所收集并標注的數據集,并且做了分類與斷代,使用者可分別按照器類或者時代瀏覽相關器物圖像。為了便于用戶核對圖像出處,也為了尊重器物的收藏單位及材料發布者,我們為每張圖像做了信息表,標明了器物的著錄書籍、名稱、時代、出土地、現藏地等相關信息。以上信息可為使用者提供很大的便利。
3. 應用系統的顯示說明
系統初始界面由“程序名稱”“拍照/上傳照片”“數據庫”“研發說明”組成(參圖5a)。其中“吉金識辨·青銅器智能斷代與辨類”是本程序的名稱,在微信小程序中搜索名稱中的關鍵字可以檢出本程序并進行使用。
“拍照/上傳照片”是上傳待測試圖版的兩種途徑。前者針對現實場景中的青銅器圖版,可供拍照上傳;后者針對客戶終端設備中已經存儲的青銅器圖版,可供選擇上傳。
“數據庫”是我們搜集并標注的青銅器數據,可分別按照時代或者類別進行瀏覽。目前僅上傳了青銅鼎數據。每一件器物的圖版都有相關信息介紹,根據實際情況列出器物名稱、著錄出處、器物時代、出土墓葬、現藏地等(參圖5b)。
“研發與說明”是關于研發團隊的介紹,以及使用書籍的簡稱等。
在具體使用時,如果上傳的圖版較大,速度會略有延遲。上傳后智能模型會進行類別和時代的判斷。其中的斷代結果,模型會給出一個最優結果和兩個次優結果,以供參考。結果下面都給出“可信度”,以百分數表示,按智能模型的判斷可信度由大至小排列。如以近年新出土的曾侯諫鼎(圖5c)為例,將該形上傳到本系統中,系統會給出識別結果(參圖5d)。其中最上面的圖像為識別器形,框內為智能模型自動檢測的器形、花紋特征。“器類”的結果是“鼎”。下面的“斷代結果”中,“西周早期”是最佳結果,可信度達91%,而“商代晚期”和“西周中期”是參考結果,可信度分別為9%和0%。那么毫無疑問,“西周早期”是人工智能模型為曾侯諫鼎做出的斷代結果。同時,小程序還設置有“反饋”功能,使用者可以輸入自己的意見,提交并反饋給后臺,我們收到后會進行相應處理。
為了給使用者足夠的參考信息,充分發揮本系統的學術價值,我們特意設置了“相似器型推薦”功能。該功能會提供5個與用戶所上傳的青銅鼎圖版器形、紋飾均相似的器物,展示這些參考器物的出處、器名、時代、出土地、現藏地等信息,使用者可根據相關信息,核對原始資料,并加以引用。每件器物都可以點擊進入,查看詳細信息。仍以曾侯諫鼎的斷代為例,圖5d下部有“相似器型推薦”,為用戶智能推薦了5個與測試圖版相似的青銅鼎器形,其中上面右數第二張圖版就是曾侯諫鼎本身,因為之前的數據集中收錄了該器,所以會被推薦出來。這5個相似器形圖版都可以點擊后進一步查看,如點擊圖5d下部相似推薦器形中的下面右數第二張圖版,即可查看其詳細信息(參圖5e)。此鼎器形的圖版上方,我們為該器標注的形制特征都會通過標簽顯示出來。如兩個“立耳”、三個“柱足”、兩組“獸面紋”等。此器的其他信息會在圖版下部列出,如“名稱: 伯鼎(伯作寶彝鼎)”;“年代: 西周早期”;“出土地: 1985年平頂山應國墓地M48∶1”;“現藏地: 平頂山博物館”;“出處: 出土全集9.230”。(“出土全集”在本系統中是《中國出土青銅器全集》一書的簡稱。此圖版參李伯謙主編: 《中國出土青銅器全集》,第9冊,第218頁,230號。)通過器物名稱及出處,便可直接進行核實與引用。“相似器型推薦”中每一件器都標注了如上信息。(部分傳世器物出土地或現藏地不明確者除外。)
4. 應用系統的功能作用
下面從具體使用的角度談一談本系統的價值。首先,“數據庫”可以按照器類、時代等分類進行瀏覽,為用戶了解和熟悉青銅器提供便利。使用者想要了解某一種器類或某一時代的器物都可通過“數據庫”實現。將來我們還會逐步提供檢索功能,包括通過器名、出土地、花紋或器形等關鍵詞檢索,盡可能為用戶提供最大的便利。
其次,為器物的斷代提供幫助。本系統的核心包括青銅器數據的搜集標注和深度學習模型的研發,其最終目的是使深度學習模型具有像人腦一樣的專業判斷能力,能夠對青銅器進行自動的分類與斷代。目前從青銅鼎、青銅簋等器類的研發來看,這項工作已經達到預期目標。系統既能夠給普通用戶提供幫助,也能為專業研究者提供參考。當遇到新見的青銅器時,可以使用本系統進行斷代,本系統中經過訓練的智能模型會給出斷代結果,并檢測出器物的主要形制特征。同時,“相似器型推薦”功能所推薦的相似數據,也具有一定的學術參考價值。
再次,為青銅器的信息核查提供幫助。過去學者對青銅器信息的掌握主要依靠記憶。例如,當面對一件已被著錄的青銅器圖版,而器物缺少著錄信息,想要知道此器出自哪一座墓葬,在哪一部書中曾有著錄,過去只能依靠學者的記憶力。而本系統可提供直接幫助,前提是待核查的器物在我們所收集的數據范圍之內。絕大多數情況下,只要人工智能模型利用了某些數據做了訓練,當同一張青銅器圖版再一次出現,上傳到本系統后,在“相似器型推薦”功能中基本都可將相同器物推薦出來。因為我們對推薦器形的相關信息做了詳細標注,使用者可直接找出器物的相關信息。在保證準確的同時,還能提高效率。
下面我們以一個具體的例子來說明本系統的功用。吳鎮烽先生《銘圖》966號著錄一件“后母辛鼎”,其附有器形、銘文圖版(參圖6a、6b),(《銘圖》,第2卷,第237頁,966號。)據該書“出土時地”介紹,此器的出土信息是“1976年河南安陽市小屯村(今屬殷都區)殷墟婦好墓(M5.809)”。核查此鼎的著錄文獻如《殷墟婦好墓》(中國社會科學院考古研究所: 《殷墟婦好墓》,北京: 文物出版社,1980年,第37頁。)、《考古學報》(中國社會科學院考古研究所安陽工作隊: 《安陽殷墟五號墓的發掘》,《考古學報》1977年2期,圖4.3、圖版18。)可知,安陽殷墟婦好墓(M5.809)確實是“后母辛鼎”,銘文也與《銘圖》966號(圖6d)相同,但是其正確的器形卻是圖6c,與圖6a完全不同。據此可知《銘圖》一書配圖有誤,吳鎮烽先生在后來編著的《金文通鑒》檢索系統已經將器形圖進行了替換更正。(需要說明的是,《金文通鑒》更正的配圖也是有問題的。下面略作介紹,殷墟婦好墓一共出土了兩件大方鼎,第一件編號為789,第二件編號為809。《銘圖》966號著錄的是編號為809的那件;而《銘圖》965號著錄的是編號為789的那件。《銘圖》966號誤配婦好方鼎圖版,《金文通鑒》更正成了編號為789的圖版,所以《金文通鑒》的修改也不正確。同時,由于《金文通鑒》誤用了編號789的圖版(即《銘圖》965),相應地又把965的器形錯配成了司母戊鼎的圖版。)那么圖6a這張青銅鼎圖版出自哪里呢?為何會被錯配呢?吳先生的《金文通鑒》并未交代。其實利用“吉金識辨·青銅器智能斷代與辨類”即可解決此問題。通過微信小程序打開本系統,將圖6a上傳到系統中,智能模型會自動給出器物的時代并推薦出五件相似器形(參圖6e)。從推薦的器形中可以發現,最左和右上角兩件器物與檢測的青銅鼎十分相似。點擊打開詳細信息可知,這兩個圖版對應同一件器,都是婦好方鼎,只是著錄書籍不同,所用的圖版也存在差異,前者著錄于《銘圖》503號(圖6f),后者著錄于《全集》2.40(圖6g),(“《全集》”在本系統中是《中國青銅器全集》的簡稱。此鼎圖版參中國青銅器全集編輯委員會編: 《中國青銅器全集》第2卷,北京: 文物出版社,1997年,第40—41頁,40號。)對比可知,圖6a即是婦好方鼎無疑。因為該器與“后母辛鼎”兩者都出土自殷墟婦好墓,所以圖版才被誤配。
結論
人工智能發展迅速,已經參與到很多科研工作當中,但是將人工智能與青銅器的分期斷代研究結合起來尚屬首次。(在工作的進展方面,目前我們對青銅鼎、青銅簋的斷代工作已經完成,并實現了應用轉化。其他食器也已經完成智能斷代工作,將會在近期完成應用實現。與此同時,我們也正在開展酒器、水器、樂器、兵器的斷代工作,計劃在未來一段時間完成全部器類的研發。)通過實驗我們發現,經過訓練后的人工智能模型可以對青銅鼎的時代進行獨立的判斷,并且能夠保證較高的準確率。與此同時,我們也把科研成果直接轉換成了實際應用,希望可以對青銅器的研究提供便利與幫助。
(責任編輯: 姜慧)
本文為“古文字與中華文明傳承發展工程”資助項目“基于人工智能技術的青銅禮器斷代研究”(G1903)階段性成果,并得到吉林大學“學科交叉融合創新”項目(JLUXKJC2021ZY04)、“學科交叉青年創新團隊”項目“基于視覺智能的青銅器綜合研究”的資助。)
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
考試周刊(2016年76期)2016-10-09 08:45:44
科技視界(2016年20期)2016-09-29 14:22:00
科技視界(2016年20期)2016-09-29 12:03:12
科技視界(2016年20期)2016-09-29 11:47:01
科技視界(2016年20期)2016-09-29 11:02:20
大眾理財顧問(2016年8期)2016-09-28 13:45:18
