改進YOLOv5的多車輛目標實時檢測及跟蹤算法
2023-10-14 08:19:58蒲玲玲楊柳
科學技術與工程 2023年28期
蒲玲玲, 楊柳
(1.西南交通大學唐山研究生院, 唐山 063000; 2.西南交通大學綜合交通大數據應用技術國家工程實驗室, 成都 611756; 3.西南交通大學信息科學與技術學院, 成都 611756)
對于車輛的跟蹤研究屬于目標跟蹤問題中的多目標跟蹤問題,多目標跟蹤的解決步驟一般為兩步,目標檢測和目標數據關聯。先使用目標檢測算法將感興趣的目標進行定位和分類,再使用目標數據關聯算法,將不同幀之間的相同目標進行關聯,以確定不同幀中的目標是否為同一目標。在多目標跟蹤問題上,除了目標檢測算法的性能對跟蹤性能影響大以外,前后幀之間的目標數據關聯也同樣影響著跟蹤的性能。多目標跟蹤發展到現在,根據Re-ID(re-identification)模塊是否融入目標檢測網絡,可分為DBT(detection-based tracking)和JDT(joint detection tracking)兩類[1],前者將目標檢測和Re-ID模塊分為兩個網絡實現,具有較高的準確率,是當前基于深度學習的視覺多目標跟蹤的主流方法;后者將DBT兩模塊聯合,具有較高的運行速度,是近兩年發展的新趨勢。
如何提高多目標跟蹤的推理速度一直是近年來研究的熱點。Wojke等[2]提出了DeepSORT算法來進行多目標跟蹤。毛昭勇等[3]使用EfficientNet作為YOLOv3的骨干網以提高檢測速度,將推理耗時的骨干網替換為輕量級網絡,減小目標檢測網絡的推理時間。武明虎等[4]將YOLOv3的損失函數和網絡結構進行改進后,與SORT算法相結合進行目標跟蹤,跟蹤速度最快可達14.39 fps。Zuraimi等[5]將YOLO和DeepSORT用于道路上的車輛檢測和跟蹤,權衡精度和時間后,證明了使用YOLOv4要好于YOLOv3,在GTX 1600ti上的以YOLOv4為目標檢測網絡的DeepSORT的總體跟蹤速度為14.12 fps。Zhang等[6]提出了FairMOT算法,該算法在大小為輸入圖像的1/4的高分辨率特征圖上使用無錨框的方式進行目標檢測和目標外觀特征提取,使特征圖上的目標中心更準確地對齊到原圖上,獲取更準確的目標外觀特征。Liang等[7]為避免使用JDT方式進行目標跟蹤時,兩個學習任務在一個網絡中出現惡性競爭問題,提出了CSTrack模型,以推動每個分支更好地學習不同的任務。CSTrack模型在單GPU上推理速度為16.4 fps,有較高的多目標跟蹤速度。
YOLO發展至今已有多個版本,YOLOv5基于他的靈活性和較低的推理時延,多位學者將其應用在目標檢測和跟蹤領域。趙桂平等[8]以YOLOv5框架為基礎,借鑒了兩步法的優點,在邊框生成方面進行改進,提高了YOLOv5的檢測精度。Wang等[9]使用YOLOv5s進行目標檢測,使用SiamRPN進行單目標跟蹤,綜合跟蹤速度為20.43 fps。Neupane等[10]使用YOLOv5進行檢測,使用質心算法進行跟蹤,跟蹤速度最高可達38 fps,但是僅在手工繪制的一小塊跟蹤框內進行跟蹤,不進行長時間跟蹤。黃戰華等[11]使用YOLOv5m進行檢測,使用位置+聲源信息進行跟蹤,在平均2個目標的情況下跟蹤速度達到34.23 fps,但在跟蹤時只能定位一個聲源,多聲源情況下會存在干擾,多目標跟蹤時,跟蹤精度差。張文龍等[12]使用EfficientNet、D-ECA(DCT-efficient channel attention module)注意力模塊、AFN(associative fusion network)改進YOLOv5,平均跟蹤速度為10.84 fps。張夢華等[13]為解決多個行人交錯運動時出現跟蹤錯誤的問題,在使用YOLOv5+DeepSORT對目標進行跟蹤后,再引入ReID(re-identification)技術去糾正行人的運動軌跡,提高跟蹤的精度。此方法在YOLOv5+DeepSORT跟蹤方式上額外增加了ReID網絡,雖然提高了跟蹤精度,但由于引入更多的神經網絡,故需要消耗更多的推理時間。以上基于YOLOv5的檢測+跟蹤算法,均有較快的跟蹤速度,但可能更適用于少目標或單目標跟蹤,用于多目標跟蹤時跟蹤精度和推理速度還需再提高。
基于上述方法啟發,提出ReID特征識別模塊,將該模塊添加到YOLOv5網絡中,使YOLOv5網絡在輸出目標邊界框的同時輸出目標的特征信息,以代替DeepSORT中的特征提取網絡,從而提高目標跟蹤的推理速度。同時提出一種基于動態IOU(intersection over union)閾值的非極大值抑制算法,該算法根據每個邊框的置信度為每個邊框設置不同的IOU閾值,以提高目標彼此覆蓋場景下的跟蹤精度,對較多目標進行更準確的實時跟蹤。
1 基于YOLO的多目標跟蹤算法
對于車輛的多目標跟蹤為目標檢測和目標跟蹤兩步。目標跟蹤主要是將目標的位置和表觀特征等信息進行關聯,得出相鄰幀之間那些目標是同一個目標。目標檢測的工作主要是在圖像中找出感興趣的目標對其進行定位和分類。基于深度學習的目標檢測模型發展到現在,可以分為以R-CNN(region-CNN)為代表的基于候選框(two-stage)的算法模型和以YOLO為代表的基于回歸(one-stage)的算法模型兩類[14],前者算法模型在精度上高于后者,后者在推理時間的表現上好于前者。使用目標檢測算法對道路上車輛的檢測,除了對算法的精度有要求外,還需對其推理時間有一定要求。故選擇基于回歸的一步式YOLO目標檢測算法來保證較小的推理時間。
1.1 YOLO目標檢測算法
YOLO網絡發展至今已有多個版本,其結構一般分為骨干網、特征融合層、3個不同大小的預測頭。其用3個不同大小預測頭分別檢測不同大小的目標,以在追求速度的同時保證精度。
YOLOv4基于YOLOv3網絡結構進行改進,在提高精度的同時也提升了推理速度。YOLOv4為降低主干網的推理時間,在殘差網絡的基礎上組合成CSP(cross-stage-partial)模塊,CSP模塊能夠在加快模型推理速度的同時盡可能的保持精度性;使用SPP(spatial pyramid pooling)結構將不同大小的特征進行融合,增加網絡的感受野,有利于檢測出圖像中不同大小的目標;為將特征進行充分融合,設計PANet(path aggregation network)特征融合網絡,相比于YOLOv3采用的FPN(feature pyramid networks)自頂向下單向特征融合方法,PANet采用自底向上再自頂向下的雙向融合方法,獲得更豐富的目標特征信息。
YOLOv5同YOLOv4一樣使用CSPDarknet、Neck和3個輸出頭的網絡結構,模型架構與YOLOv4相似。YOLOv5有s、m、l、x 4種大小的結構相同,但寬度和深度不同的模型可供使用,4種模型推理速度依次降低,推理精度依次升高。在訓練時YOLOv5使用Mosaic數據增強將4張圖片合并為一張圖片進行輸入,減小訓練花費的時間同時變相增大batch_size;使用自適應錨框計算,能在小目標的檢測上有更好效果;在主干網中使用focus結構,起到減少計算量和提高速度的作用。YOLOv5有兩種CSP結構,在主干網中使用CSP1結構,在Neck網絡中使用CSP2結構,以此加強特征融合能力和減少計算量。且CSP結構深度隨模型的深度變化而變化。
1.2 改進YOLOv5的多目標跟蹤網絡結構
JDE(joint detection and embedding)算法[15]通過在YOLOv3的3個預測頭中添加特征層,將對目標特征的輸出也交給YOLO網絡,提高了多目標跟蹤的推理速度,但在3個不同分辨率的特征層上面進行特征提取,當相鄰幀中同一目標大小變化明顯時,可能檢測結果是不同的預測頭輸出的,由于檢測頭的分辨率不同,從而導致同一目標在相鄰幀獲取到的特征相差過大,導致跟蹤失敗。FairMOT[6]算法為了提取到更準確的目標特征,將輸入圖片設置為1 088×608,在1/4原圖大小的特征圖上進行目標位置預測和特征提取,跟蹤精度得到了提升,但輸入圖片分辨率大且在較大特征圖上預測和特征提取會非常耗時,導致跟蹤速度過慢。基于此,將YOLOv5模型進行改進,使YOLOv5在輸出目標位置信息的同時輸出目標的特征信息。改進后的YOLOv5網絡結構如圖1所示,在YOLOv5網絡中添加ReID模塊,該模塊由特征輸出模塊和ID(identity)分類模塊共同模塊組成。
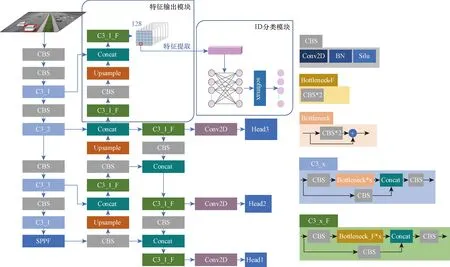
圖1 改進后的YOLO網絡結構Fig.1 Structure of improved YOLO
1.2.1 特征輸出模塊
神經網絡學習過程中,低層特征分辨率更高,包含更多的位置、細節、顏色等信息,但由于經過的卷積較少,其語義信息含量低,噪聲更多;高層特征包含更多的語義信息,但其分辨率低,對細節的感知能力較差。且如果在較小的特征圖(1/8、1/16、1/32)上提取表觀特征,會因為特征圖分辨率太小,導致特征圖上的目標中心不能很好地與原圖中心對齊,出現表觀特征提取粗糙的問題;如果在較深層特征層上提取特征,會獲得更多的語義信息,較少的顏色和細節等淺層信息,導致不同目標的提取到的特征不能很好地區分。
以上兩種提取方式均容易造成目標跟蹤錯誤。故特征輸出模塊為使目標能夠提取到較為精細準確的特征,將PANet繼續自底向上進行上采樣到1/4原圖大小,再與主干網中1/4原圖大小的特征進行融合,最后輸出原圖1/4大小的128維的特征圖,作為提取目標特征的特征池。與淺層1/4原圖大小的特征層進行融合后,特征池不僅包含豐富的語義信息,也包含豐富的顏色細節等信息,可為不同目標提供有區別的特征。且得益于特征池的高分辨率,能為鄰近目標提供精準的特征。
在訓練階段使用標簽直接定位到特征池128維特征,如圖1所示的網絡框架圖中檢測圖上的用紅色框框出的車輛位置,對應到特征池中的紅色框框出的單位128維特征;在推理階段提取目標特征時需結合YOLO輸出的目標位置信息,定位到特征池單位128特征。使用目標的位置信息在特征池中定位目標特征,提取到和目標唯一對齊的單位128維特征作為該目標的特征。
1.2.2 ID分類模塊
ID分類模塊用以訓練網絡的目標特征識別能力,使網絡能夠輸出正確的和不同目標有區別的目標特征,其僅在訓練模型時使用。ID分類模塊設計為兩層的全連接層,設計128個節點進行輸入,ID總數個節點進行輸出,將特征識別問題轉換為ID分類問題。在訓練模型時,將目標的真實框中心定位到特征池上,從特征池中提取該定位處的128維特征,將該128維特征作為全連接層的輸入,將ID總數數量的節點作為全連接層的輸出,并且采用softmax對輸出的數據進行歸一化,獲得該目標的類別概率。然后使用交叉熵損失函數計算ID損失。softmax函數表達式為
(1)
式(1)中:zi為第i個節點的輸出值;zc為第c個節點的輸出值;C為輸出節點的總數。
1.3 動態IOU閾值的非極大值抑制算法
公路監控安裝并非總是正對車輛,如果攝像頭安裝在公路邊側,離攝像頭較遠的哪一方公路上的車輛在視頻里會很容易出現彼此覆蓋的情況。對于彼此覆蓋的目標檢測,針對不同的問題有不同的解決方法。其中,針對覆蓋場景構建對應數據集,直接進行訓練,但是由于覆蓋的多樣性和數據的難收集性這種方式非常困難;如果是神經網絡提取的特征不充分,可以針對損失函數和網絡結構進行改進;如果是網絡特征提取充分但是在覆蓋場景下仍表現不好,可以考慮是非極大值抑制(non-maximum suppression,NMS)將相鄰的檢測框過濾了。
車輛經過目標檢測網絡檢測后,非極大值抑制會基于邊框置信度和IoU(intersection over union)閾值抑制重疊的邊框。當相鄰目標的檢測框彼此重疊面積較大,會出現只留下一個目標的檢測框,另一個目標的檢測框被抑制的情況,導致對其中一個目標檢測失敗,進而導致跟蹤失敗。為此,提出一種基于動態IoU閾值的非極大值抑制(dynamic non-maximum suppression,DNMS)算法。DNMS算法對YOLO預測到的邊框賦予一定的信任,根據每個邊框的置信度得分,對每個邊框設置不同的IoU抑制閾值。對邊框置信度得分越大的置于更多的信任,設置更大的IoU過濾閾值,來保留相互大面積覆蓋的正確邊框。
DNMS算法中引入兩個超參數supC和supT,分別用作過濾掉置信度較低的邊框和根據置信度設置IOU閾值,兩個參數的數值可根據數據集等實驗因素自由確定。當計算出的IOU閾值小于0.35時,設置為0.35,以避免不同車輛邊框覆蓋面積很小就被抑制掉。DNMS算法偽代碼如下,其中Ni為第i個邊框的IOU閾值。

DNMS算法Input: The list of initial detection boxes, B = {b1,b2,…, bN}; The list contains corresponding detection scores, S = {s1,s2,…, sN};Output: The list of remaining detection boxes after DNMS, D = {b1,b2,…, bn}; The list contains corresponding detection score C={s1,s2,…, sn}1: D = {}; C = {}2: while (B ≠ Empty) do3: m = Max(S)4: M = bm; N = sm5: D = D∪M; C = C∪N; B=B-M; S=S-N6: forbi inB do7: Ni= (si -supC) * supT8: if 0.35> Ni > 0 then9: Ni = 0.35 10: end if11: if IoU (M, bi)> Nithen12: B = B -bi; S = S -si13: end if14: end for15: end while16: returnD, C
1.4 損失函數設計
對于ID分類模塊,采用交叉熵損失函數進行損失計算,其余損失函數采用YOLOv5原設計損失函數。
ID分類模塊損失函數為
(2)
式(2)中:M為類別的數量;當樣本i真實類別為c時yic取1,否則取0;pic為樣本i屬于類別c的概率;N為樣本總數。
對于目標檢測的置信度損失Lconf,為二元交叉熵損失,可表示為
(3)
對于目標檢測的類別損失Lcls,為二元交叉熵損失,可表示為
(4)

對于目標檢測的位置損失Lloc,為GIoU損失,可表示為
(5)
式(5)中:IoU為預測框和真實框的交并比;Ac為同時包含預測框和真實框最小矩形面積;U為預測框和真實框的并集。
目標檢測的損失和可表示為
Ldet=Lconf(o,c)+Lcls(o,c)+Lloc
(6)
最后,總的損失函數可表示為
(7)
式(7)中:wdet和wid分別為通過任務的獨立不確定性自動學習方案[16]學習得到的目標檢測損失權重和ID類別損失權重。
1.5 多目標跟蹤
基于改進YOLO的多車輛場景目標跟蹤的跟蹤流程圖如圖2所示。視頻流輸入后,會先使用改進后的YOLO算法檢測出每幀中目標的位置和特征信息。然后將目標的位置信息采用卡爾曼濾波進行預測,預測目標的下一幀位置,使用當前幀目標位置和上一幀目標預測位置進行馬氏距離計算,得到目標和軌跡的位置距離;使用當前檢測的特征和軌跡近100個特征進行余弦距離計算,取最小的距離作為目標和軌跡之間的特征距離。之后將獲得的兩個距離進行數據匹配來判斷相鄰幀的目標是否為同一目標。匹配算法主要使用匈牙利匹配和IOU匹配,先使用匈牙利對目標和軌跡之間的位置信息和特征信息進行匹配,若匹配成功則將該目標直接加入到軌跡,若匹配失敗,則再進行IOU匹配,匹配成功則加入軌跡,匹配失敗則創建新軌跡。

圖2 跟蹤流程圖Fig.2 Flow chart of tracking
提出的多目標跟蹤算法未特別說明處均使用多目標跟蹤流程進行跟蹤。
2 實驗結果與分析
2.1 實驗環境
實驗操作系統為64位Windows10;硬件環境主要包括:Intel(R) Xeon(R) W-2223 CPU@3.60 GHz、內存32 GB、訓練環境中顯卡型號為NVIDIA TITAN xp,驗證環境顯卡型號為NVIDIA Quadro P2200、深度學習框架為pytorch。訓練的數據集采用UA-DETRAC[17]公開數據集。在訓練改進后的YOLOv 5 m時采用在coco數據集上訓練好的權重結果作為預訓練權重,訓練批次(batch_size)設置為16,訓練輪數(epoch)設置為50個。
2.2 數據集與評判指標
數據集采用UA-DETRAC公開數據集,該數據集是車輛檢測和跟蹤的大規模數據集,數據集主要拍攝于北京和天津的道路過街天橋,并手動標注8 250個車輛和121×104個目標對象外框[17]。車輛分為:轎車、公共汽車、廂式貨車和其他車輛。天氣情況分為:多云、夜間、晴天和雨天。在使用該數據集前將原始數據的xml格式標簽轉換為YOLOv5所需的標簽格式,因為需要進行ID識別,故需要在標簽中包含類別和位置的同時添加目標的ID。YOLOv5修改后的標簽格式定義為:<目標類別、目標x坐標中心、目標y坐標中心、目標寬、目標高、ID>。
為評價跟蹤的性能,采用Dendorfer等[18]提出的多目標跟蹤算法評價指標進行評價,主要選取多目標跟蹤精度(multiple object tracking accuracy,MOTA)、MT(mostly tracked)、ML(mostly lost)、IDs(ID switch)、假陽性(false positive,FP)、假陰性(false negative,FN)作為評估指標,另添加每秒幀數(frame per second,FPS)評估模型每秒處理的幀數。其中MOTA用于評價多目標跟蹤的精準度,用以統計在跟蹤過程中誤差的積累情況,其表達式為
(8)
式(8)中:FNt、FPt、IDst、GTt分別為第t幀時FN、FP、IDs、GT指標的數值;t為幀數。
2.3 結果與分析
2.3.1 YOLOv5+ReID跟蹤實驗
為提高多目標跟蹤模型的推理速度,在目標檢測網絡上選擇推理速度更快的YOLO。YOLO有多個版本,將ReID模塊添加到YOLOv4和YOLOv5上,與使用YOLOv4和YOLOv5為目標檢測網絡的DeepSORT算法(分別簡寫為YOLOv4和YOLOv5)對比,實驗結果如表1所示。結果表明,將ReID模塊添加到YOLOv4上,與以YOLOv4為目標檢測網絡的DeepSORT相比,MOTA指標下降了4個百分點,但推理速度有一定的提升。將ReID添加到YOLOv5上,與以YOLOv5為目標檢測網絡的DeepSORT對比,MOTA指標值不變,但推理速度卻明顯快于后者。YOLOv5相對于YOLOv4有更快的推理速度,并且在添加ReID模塊后,得益于YOLOv5豐富的特征提取能力,MOTA指標并沒有下降,故選擇YOLOv5作為多目標跟蹤網絡。
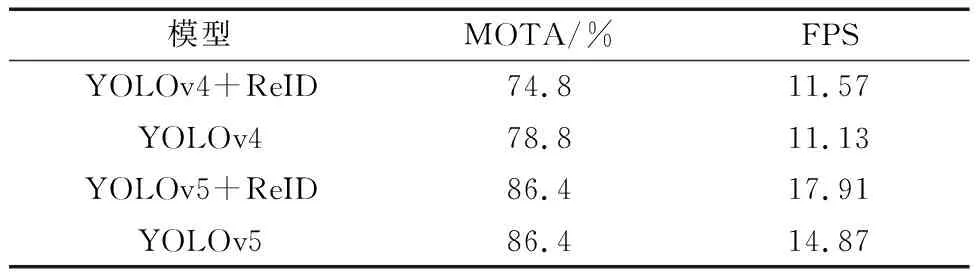
表1 ReID模塊應用Table 1 ReID module application
多目標跟蹤算法的推理時間主要花費在目標檢測和特征提取上,經過本文方法將目標檢測模型進行優化,使目標檢測模型在輸出目標位置信息的同時輸出目標的特征信息,從而提升模型在進行多目標跟蹤時的推理速度。特別是在目標多的情況下,與原算法的推理時間對比越明顯。以使用YOLOv5作為目標檢測網絡的DeepSORT[2]和YOLOv5+ReID為例,如表2所示的兩種模型在不同目標數量下的推理時間對比,可以看出,在2~4個目標的情況下,所提出的YOLOv5+ReID算法和DeepSORT算法的推理時間差值為3.83 ms,在14~16個目標的情況下,推理時間差值達到17.97 ms,推理時間差隨目標的增多而增大。

表2 不同目標數量下的推理時間對比Table 2 Comparison of reasoning time under different number of targets
JDE[15]算法在3個不同分辨率的特征層上面進行特征提取,當相鄰幀中同一目標大小變化明顯時,可能檢測結果是不同的預測頭輸出的,由于檢測頭的分辨率不同,從而導致同一目標在相鄰幀獲取到的特征相差過大。如圖3(a)所示,在左側圖像上兩車輛ID分別為67和68,右側圖片上則為69和70,發生ID切換,對同一車輛跟蹤失敗。所提出的YOLO+ReID算法中,不同預測頭預測的目標均在同一個特征池中提取特征,在相鄰幀中目標大小變化明顯時,無論檢測結果是那個輸出頭輸出的,都根據輸出頭輸出的目標位置信息在同一個特征池中定位特征。如圖3(b)所示,在左側圖像上兩車輛ID分別為42和43,右側圖片上仍為42和43,沒有發生ID切換,對同一車輛跟蹤成功。

圖3 IDs對比Fig.3 IDs comparison
采用IDs指標來評判JDE算法和YOLOv5+ReID算法對目標ID切換的數量。驗證數據采用UA-DETRAC數據集中6個不同場景的視頻段:MVI_20011、MVI_30761、MVI_40192、MVI_40241、MVI_63544、MVI_63563進行驗證。實驗結果如表3 所示,JDE算法的IDs為399,YOLOv5+ReID算法的IDs為65,兩者相比,YOLOv5+ReID的目標ID切換量明顯較JDE少。

表3 IDs數量對比Table 3 Comparison of IDs quantity
2.3.2 DNMS算法檢測實驗
為驗證DNMS算法對彼此遮擋目標的檢測有效性,選取UA-DETRAC數據集中攝像頭傾斜于車道布設所獲得的視頻段:MVI_63544和MVI_40241作為驗證數據,其中MVI_40241視頻段中的車流量相對MVI_63544視頻段中的車流量大,車輛總數也遠高于MVI_63544視頻段。使用NMS算法、DIOU-NMS[19]算法、Soft-NMS[20]算法和DNMS算法進行對比,采用FN(false negative)和FPS指標來評判算法在兩個視頻段上漏檢的車輛數量。表4為非極大值抑制算法對比結果。在對車輛的漏檢上,本文算法在MVI_40241上漏檢量為1 021,明顯少于對于其他3種算法,在MVI_63544視頻段中的漏檢數為172,與其他算法持平。在推理速度上,所提出的DNMS算法相對于NMS算法,由于計算量更大,故在推理速度上會比較慢,但相對于DIoU-NMS和Soft-NMS算法,本文算法更有優勢。

表4 非極大值抑制算法對比Table 4 Comparison of non maximal suppression algorithms
針對彼此覆蓋的目標,采用DNMS算法代替原有的NMS算法。分別在所提出的YOLOv5+ReID算法和JDE[15]算法上驗證DNMS對彼此遮擋目標檢測的有效性。實驗結果如圖4所示,其中,圖4(a)、圖4(c)使用NMS算法進行邊框抑制,圖4(b)、圖4(d)使用本文提出的DNMS算法進行抑制。可以看出,在圖4(a)和圖4(c)中的紅色橢圓框中,框出的車輛里,有一個車輛無檢測框,而在圖4(b)和圖4(d)中,該車輛的檢測框得以出現。實驗結果表明,使用本文提出的DNMS算法能夠檢測到NMS算法不能檢測到的車輛。

圖4 DNMS實驗結果Fig.4 DNMS experimental results
采用FN指標來評判使用DNMS的模型分別在MVI_40241視頻段和MVI_63544視頻段,漏檢的車輛數量。實驗結果如表5所示。YOLOv5+ReID使用DNMS算法后在兩個視頻段上漏檢分別減少312和5;JDE使用DNMS算法后在兩個視頻段上漏檢數量分別減少22和2。實驗結果表明,將所提出的DNMS算法用在其他模型上也仍然有效。

表5 漏檢數量對比Table 5 Comparison of missing inspection quantity
2.3.3 改進YOLOv5的目標跟蹤實驗
使用以YOLOv5為目標檢測網絡的DeepSORT[2]和JDE[15]、FairMOT[6]算法和本文算法,在UA-DETRAC數據集上6個不同場景的視頻段,共9 389幀上進行推理精度和速度的對比。
實驗結果如表6所示。FPS指標在每張圖的跟蹤數量為7~16上計算得到。由表6可知,將YOLOv5網絡結構加上ReID模塊,和基于無錨點預測邊框和在1/4原圖大小上直接進行目標預測的FairMOT算法對比,在UA-DETRAC數據集上,本文算法的FPS為17.91,明顯高于該算法的5.71。和JDE算法相比,所提的YOLOv5+ReID算法的IDs為65,明顯小于JDE算法的399。和DeepSORT算法相比,本文的YOLOv5+ReID的平均推理時間減少了11.41 ms。

表6 多目標跟蹤算法的性能對比Table 6 Performance comparison of multi-target tracking algorithms
將DNMS算法運用在YOLOv5+ReID模型上,相對于YOLOv5+ReID模型,跟蹤精度MOTA提升了3.9個百分點。實驗結果表明,所提出的YOLOv5+ReID+DNMS算法相對于其他算法,在保證推理速度的情況下,在跟蹤精度上有明顯的優勢。
3 結論
為將多目標跟蹤模型應用在多車輛場景下,從而設計低推理時延高精度的跟蹤模型。針對多目標跟蹤推理時間長的問題,在YOLOv5網絡結構上進行改進,設計了ReID模塊,該模塊將YOLOv5的PANet繼續上采樣,獲得一個特征池,使改進后的YOLOv5模型在輸出目標位置信息的同時輸出特征信息。針對車輛間彼此覆蓋的情況,為提高跟蹤精度,提出一種基于動態IOU閾值的非極大值抑制算法,該算法根據每個邊框的置信度得分,對每個邊框設置不同的IOU抑制閾值,以此減少車輛密集場景下對車輛的漏檢。實驗結果表明,在YOLO網絡中添加ReID模塊能明顯地減少目標跟蹤的推理時間;使用基于動態IOU閾值的非極大值抑制能明顯的增加目標跟蹤精度。將ReID和基于動態IOU閾值的非極大值抑制用在YOLOv5模型中,與FairMOT、JDE、DeepSORT算法進行對比,改進后的模型有較好的跟蹤精度和實時性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
