高鐵隧道接觸網(wǎng)號牌定位與識別
2023-10-12 01:11:08張建州
計算機工程與設計 2023年9期
關鍵詞:方法
王 凡,張建州,邊 昂
(四川大學 計算機學院,四川 成都 610065)
0 引 言
接觸網(wǎng)安全巡檢裝置[1](catenary-checking video monitor device,CCVM)是提高動車組供電安全性和可靠性的重要手段,支柱號作為高鐵接觸網(wǎng)支柱的唯一身份標識可在巡檢裝置檢測到接觸網(wǎng)異常時進行準確定位。因此,如何準確快速確定接觸網(wǎng)支柱編號是接觸網(wǎng)安全巡檢系統(tǒng)的基礎之一。
目前,學者們對接觸網(wǎng)號牌定位和識別進行了大量研究,提出了許多可行算法。郭瑞等[2]利用方向梯度直方圖特征和支持向量機(support vector machine,SVM)實現(xiàn)支柱號牌的定位和識別。楊梅等[3]利用上下文特征和模板匹配實現(xiàn)了不同形狀和大小的號牌自適應識別。徐可佳等[4]基于Faster R-CNN,直接定位到單字符進行分類識別。劉旭松[5]通過級聯(lián)兩個Faster R-CNN網(wǎng)絡,分別用于號牌定位和字符識別,最后再使用連續(xù)桿號數(shù)據(jù)對識別結果進行修正來保證結果的準確性。吳鏡鋒等[6]使用改進LeNet-5神經(jīng)網(wǎng)絡進行遷移學習,在使用少量樣本的情況下實現(xiàn)了號牌定位。Wang等[7]以YOLOv2為基礎引入可堆疊注意力模型,通過多尺度信息融合實現(xiàn)了號牌的檢測定位。侯明斌[8]對YOLOv2網(wǎng)絡進行改進,通過目標檢測實現(xiàn)號牌定位;并設計基于卷積循環(huán)神經(jīng)網(wǎng)絡的輕量支柱號序列識別網(wǎng)絡,實現(xiàn)了不定長編號的識別。上述方法均以良好光照為前提,劉家軍等[9]提出基于對比度受限直方圖均衡化的夜間接觸網(wǎng)號牌識別方法,通過對夜間圖像增強,在光線不佳的情況下保持了較高的識別率。但該算法中對夜間圖像的增強方法并不適用于隧道低光圖像。
鑒于現(xiàn)有增強方法很難對隧道低光圖像進行有效增強,因此本文在充分考慮圖像特點的情況下,首先使用改進Ostu算法和特征篩選完成號牌粗定位;然后利用邊緣補償和形態(tài)學運算實現(xiàn)號牌的二次定位;最后通過分類處理實現(xiàn)號牌的精確提取。實驗結果表明該定位方法準確有效。對于低光號牌,本文首先用基于多尺度高斯拉普拉斯(Laplacian of Gaussian,LoG)算子的零交叉二值化算法對號牌二值化;然后使用改進的字符分割算法提取編號字符;最后使用SVM實現(xiàn)字符識別。實驗結果表明,本文提出二值化算法和改進的字符分割算法在提取和分割隧道低光號牌字符時準確、有效、魯棒性高。
1 號牌定位
隧道接觸網(wǎng)圖像亮度低,灰度值93%集中在0~2之間,平均灰度值為1.8。由于光照低,吊柱邊緣細節(jié)丟失,部分圖像中號牌和背景融合,因此無法通過增強的方法來預處理圖像,以降低定位難度。同時隧道接觸網(wǎng)號牌表面附有高逆反射系數(shù)的反光膜,號牌成像后在圖像中像素值最高,該特點有助于對號牌的定位。本文給出的號牌定位算法流程如圖1所示,其中“粗定位+精提取”的定位方法是本文創(chuàng)新點之一。
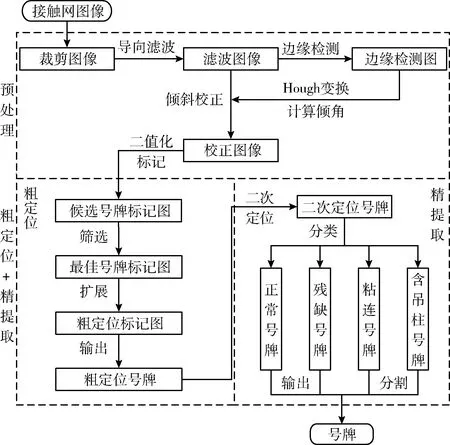
圖1 號牌定位算法流程
1.1 預處理
本文接觸網(wǎng)圖像分辨率為2048×2048,為了降低計算量,可在保證號牌不被漏檢的前提下,對輸入圖像進行裁剪,減小圖像尺寸。然后使用引導濾波對圖像進行降噪處理,可平滑噪聲的同時避免圖像邊緣被破壞。最后為避免因號牌傾斜影響號牌定位和字符分割的準確度,需進行傾斜校正,本文采用Hough變換對圖像LoG邊緣檢測圖進行直線檢測,計算傾角并完成傾斜校正。
1.2 號牌粗定位
1.2.1 候選號牌標記
號牌為隧道接觸網(wǎng)圖像中最亮部分,使用合適方法將圖像二值化,背景為0,號牌候選區(qū)為1,即可完成候選號牌標記。實驗發(fā)現(xiàn),使用Ostu算法[10]標記效果較好,但對號牌亮度較低圖像,會將吊柱誤標注,導致粗定位失敗,如圖2(b)虛線框所示,因此需對算法改進。

圖2 Otsu與改進Otsu算法標注號牌候選號牌對比
統(tǒng)計發(fā)現(xiàn),號牌區(qū)灰度集中在裁剪后圖像所有像素最亮的0.3%~1.5%之間,將這部分像素稱作前景,剩余像素稱為背景。二值化前將兩者分離,分離方法如下
(1)
式中:Ic為預處理后圖像,G為按灰度值大小找到占比r的最亮像素的灰度值,本文r取0.3%和1.5%的中間值0.9%。Ix為分離后的圖像。分離后使用大律法對Ix二值化,得到候選號牌標記圖,如圖2(c)所示。改進后算法對號牌區(qū)域用二值化標記精確度更高,誤標記面積極小,不會導致粗定位失敗。
1.2.2 號牌篩選
高鐵隧道中號牌編號采用4個字符垂直排列,號牌大小固定,因此本文以寬高比ψ(ψ=h/w,h和w分別為最小外接矩形高度和寬度)為特征對候選標記圖中的號牌進行篩選,剔除誤標記區(qū)和缺失面積超過50%的號牌。
選取質量較好的號牌,統(tǒng)計發(fā)現(xiàn)它們的最小外接矩形高寬比ψ∈[3,3.5]。 受拍攝距離和彎道等因素影響,號牌會出現(xiàn)橫向粘連、縱向粘連和右側缺失,此時ψ發(fā)生改變。下面討論在實際場景中號牌ψ可能的取值范圍。
考慮下限,兩號牌發(fā)生水平粘連,此時ψ=h1/(w1+w2)≥h1/(2*w1)≥1.5, 其中w1為較寬號牌的寬度。考慮上限,發(fā)生垂直粘連,此時ψ=(h1+h2)/w1≤(2*h1)/w1≤7, 其中h1為較高號牌的高度。當拍攝距離過近,號牌出現(xiàn)缺失,當缺失面積達50%且出現(xiàn)垂直缺失時ψ
1.2.3 擴展與輸出
篩選后將最小外接矩形最大的候選號牌定為最佳號牌,并輸出為粗定位號牌。但受光照或號牌污染等影響,部分號牌亮度降低,其標記圖殘缺,直接定位會使號牌不完整,因此求得最佳號牌的最小外接矩形后,需要進行擴展,保證粗定位號牌完整。本文中,上下和左右分別擴展高度和寬度的0.25倍。
1.3 號牌精提取
通過粗定位可得到包含完整號牌的圖像,為提高定位精度,需對粗定位號牌進行精提取。
1.3.1 號牌二次定位
形態(tài)學運算常用于低質量車牌或號牌的定位。本文亦使用形態(tài)學運算對號牌進行二次定位,處理流程如圖3所示。首先利用邊緣圖對粗定位號牌進行邊緣補償;然后使用形態(tài)學運算獲取號牌主體,其中閉操作(kernel為長度等于3的水平直線)用于連接斷裂的邊緣,開操作(kernel為半徑等于3的菱形結構)用于清除填充主體四周細小噪聲項;最后通過求最小外接矩形得到二次標記圖,進而得到二次定位號牌。
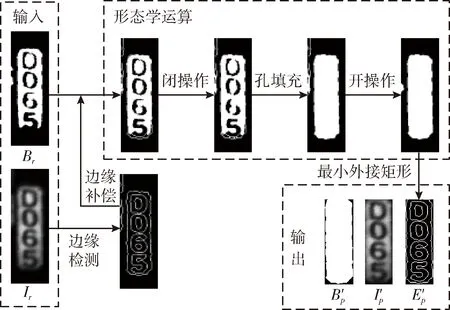
圖3 二次定位算法流程
圖3中Br為粗定位號牌標記圖,Ir為粗定位號牌;B′p為二次標記圖,I′p為二次定位號牌,E′p為I′p的邊緣圖。可以看出,較之于粗定位圖Ir,I′p在保證號牌完整的同時四周冗余圖像更少,定位精度更高。
1.3.2 分類與處理
二次定位后多數(shù)定位結果可作為精提取號牌輸出(如圖4(a)所示)。但部分結果出現(xiàn)號牌粘連或包含吊柱(如圖4(b)和圖4(c)所示),需要切除粘連號牌或者包含的吊柱。為達到上述目的,需對二次定位結果分類。另有殘缺號牌(如圖4(d)所示)不用再做處理即可輸出,但考慮后續(xù)處理需求,需將其區(qū)分出來。

圖4 二次定位結果
為方便描述,現(xiàn)定義以下概念:
定義1 有效像素比V,即二值圖中邏輯值為1的像素數(shù)量與圖像面積的比值。計算方法如下
(2)
式中:B為二值圖,wB和hB分別為B的寬度和高度。
對于圖4中4類圖像,依次將其定義為PA、PB、PC和PD這4類,分類方法如下:①計算B′p的有效像素比V和號牌高寬比ψ,分別記為Vp和ψp;②判斷B′P在接觸網(wǎng)圖像中的位置,若B′p右邊緣與接觸網(wǎng)圖像右邊緣距離小于B′p的寬度,則記R=1,否則記R=0;③對于R=1的號牌,若ψp≤3.5則為PA類,否則為PD類;④對于R=0的號牌,若ψp>4則為PC類,否則判斷Vp的大小,若Vp>0.7為PA類,否則為PB類。
完成分類后,直接將PA和PD類二次定位號牌I′p輸出為精提取號牌Ip,B′p和E′p輸出為Ip的標記圖Bp和邊緣圖Ep;PB和PC類則需通過對B′p分割得到Bp,然后利用Bp定位得到Ip和Ep。對于PB類,首先劃分象限并比較象限子圖的V確定號牌主體位置,然后通過行列擴展完成分割;對于PC類,首先確定圖像質心位置,然后通過行擴展完成分割。上述兩種方法均在擴展行(列)的V小于當前Vp時停止擴展完成分割。
2 編號識別
字符識別技術已較為成熟,模板匹配和特征匹配常用于印刷體字符識別,但隧道中號牌字符質量差,上述方法并不適用。本文首先篩選出具備識別條件的號牌;然后使用基于多尺度LoG算子的零交叉方法對號牌二值化;再通過改進現(xiàn)有分割算法,實現(xiàn)字符的分割提取;最后使用SVM對單字符識別,完成編號識別,具體過程如下。
2.1 號牌篩選
受光照和距離影響,部分號牌無法識別(如圖5方框中所示)需剔除。對多組同一編號的連續(xù)幀號牌分析發(fā)現(xiàn),無法識別號牌邊緣檢測圖的字符邊緣缺失嚴重(如圖5(b)所示),其二值圖不具備識別條件(如圖5(c)所示),因此考慮以字符邊緣缺失情況為指標對號牌進行篩選。
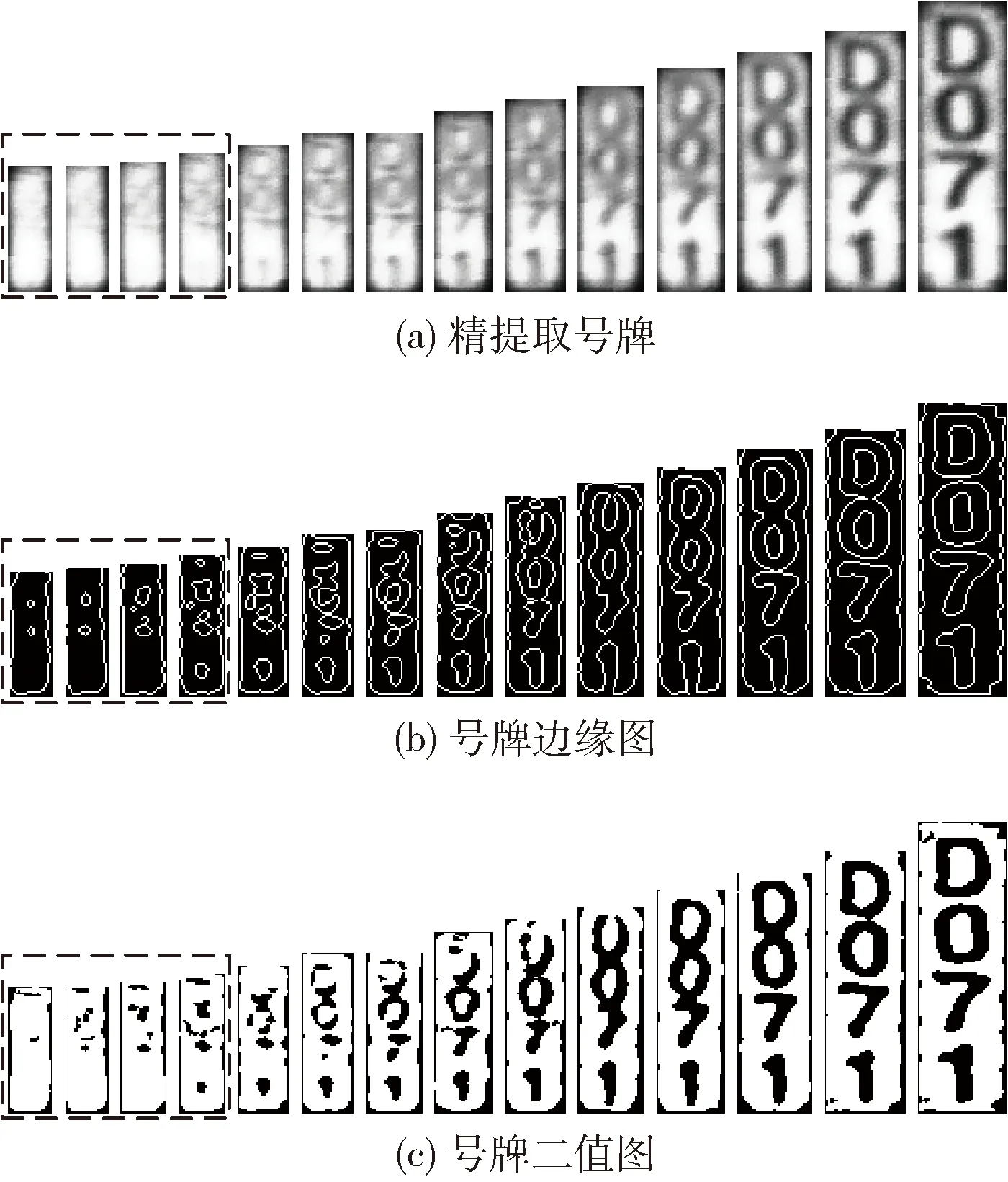
圖5 連續(xù)幀號牌及其邊緣圖和二值圖
為對字符邊緣進行定量分析,現(xiàn)定義以下概念:
定義2 號牌圍線質量Wf,號牌圍線即號牌邊緣圖Ep中四周非字符邊緣,用Ef表示,Wf即Ef中邏輯值為1的像素數(shù)。計算方法如下
(3)
定義3 字符結構質量Wp,即Ep中字符邊緣像素邏輯值為1的總數(shù)。計算方法如下
(4)
定義4 字符結構密度ρ,即Wp與Bp中有效像素的比值。計算方法如下
(5)
式(3)~式(5)中,w和h分別為圖像寬度和高度,Ep和Bp分別為精提取號牌Ip的邊緣圖和標記圖,Ef為Ep的圍線,Ef求取方法簡單,這里不再累述。
在每組編號一樣連續(xù)幀的精提取號牌中選取一張最右側且完整的號牌,共計16張。此時號牌字符最清晰且無粘連和缺失,對它們進行字符分割并利用式(3)~式(5)計算各字符結構密度ρ,定量分析結果見表1。
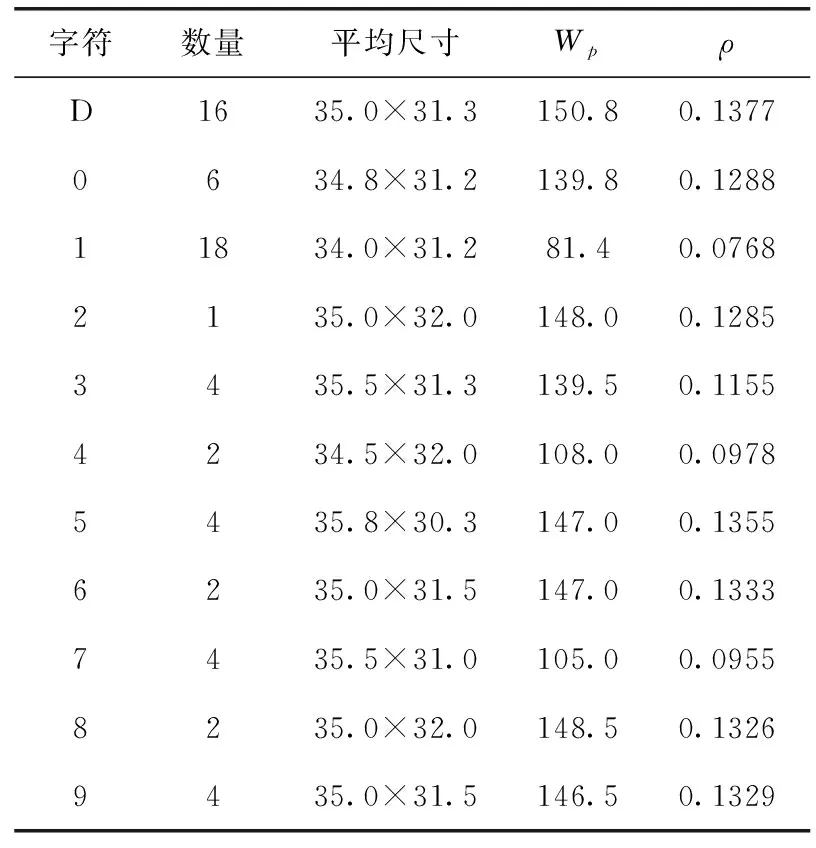
表1 號牌字符邊緣結構質量和結構密度定量分析
由于字符“1”、“2”和“7”書寫簡單,邊緣點少,它們的結構密度均小于0.1。單個號牌包含1個字母和3個數(shù)字,因此單號牌的結構密度ρ∈[0.0920,0.1360], 其中下限ρlow=0.0920是在編號為D111時產(chǎn)生,上限ρhigh=0.1360是在編號為D555時產(chǎn)生。通過實驗發(fā)現(xiàn)當號牌字符邊緣缺失30%時號牌無法識別,同時為保證“1”、“2”和“7”不會被誤剔除,因此篩選閾值設為ρlow×(1-0.3), 即0.0644;對在2.3.2節(jié)中標記R=1殘缺號牌,篩選閾值設為ρlow×(1-0.5), 即0.0460。
對628張隧道接觸網(wǎng)圖像進行號牌定位得到號牌628張,通過篩選,剔除不可識別號牌266張,保留可識別號牌362張。對可識別號牌,利用Ep和Ef對號牌邊緣切割,切除四周的冗余圖像,處理流程如圖6所示。其中“-”表示“減”運算,即E′s“等于”Ep“減”去圍線Ef后僅包含字符邊緣的邊緣圖,Es為切除E′s四周冗余后的邊緣圖,Is為利用Es定位后的號牌。利用該方法切割后號牌定位精度更高。
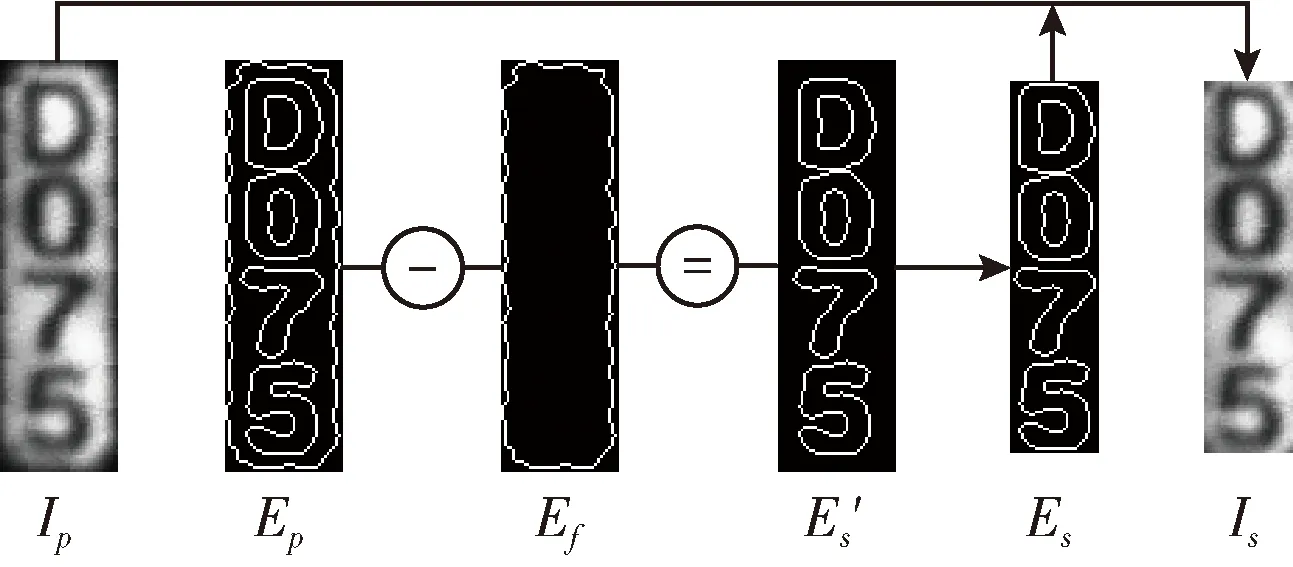
圖6 冗余邊緣切割流程
2.2 二值化
隧道接觸網(wǎng)號牌圖像質量差,傳統(tǒng)二值化算法[10,11]難以將字符與背景有效分離。使用Otsu、Bernsen和Niblack算法對號牌二值化,結果如圖7(b)~圖7(d)所示,效果均不理想。針對低光照接觸網(wǎng)號牌識別,用基于多尺度LoG算子的零交叉方法二值化,結果如圖7(e)所示,可以看出該方法對低光照號牌圖像二值化效果更好。

圖7 號牌二值化對比
二維LoG算子計算表達式如下
(6)
式中:σ為高斯濾波器的標準差。對于離散圖像,常使用一個大小為n×n的LoG離散濾波器來近似LoG算子,其寬度n是一個大于等于6σ的最小奇數(shù)。
本文所提二值化算法流程為:①選擇3個尺度的σ(本文分別取σ1=0.7、σ2=1.7和σ3=2),計算對應的LoG濾波器;②利用3個濾波器分別對號牌圖像進行濾波,得到3張零交叉圖并使用最大尺度對應的零交叉圖求取邊緣圖Emax;③對3張零交叉圖進行二值化,閾值取0,得到3個二值化結果B1、B2和B3;④將Emax、B1、B2和B3進行或運算得到B0;⑤對B0進行形態(tài)學操作,將所有4連通像素數(shù)小于8的連通圖賦值為0,得到最終二值化結果。
2.3 字符分割
常用字符分割方法包括連通域分割法和投影分割法,它們對存在斷裂和粘連字符的號牌分割效果不佳。文獻[12]將號牌二值圖的投影矩陣的極小值視為候選分割點,通過將不同分割點組合,計算平均分割高度、變異系數(shù)和判斷系數(shù)實現(xiàn)了字符的分割。該方法泛化能力較強,但在處理低質垂直號牌時,會因字符斷裂距離過大或者粘連的字符包含“1”和“7”而無法找到極小值,導致字符分割失敗。本文通過在距離過大的極值點之間插入人工點改進了文獻[12]的所提方法,解決了上述問題。改進后的字符分割算法包含3個主要環(huán)節(jié):①構造分割點集合;②分割點組合分析;③字符分割。
2.3.1 構造分割點集合
對號牌二值圖進行孔填充,再計算每行像素值為0的像素個數(shù)即可獲得水平投影矩陣,然后尋找投影矩陣的局部極小值(波谷)來確定潛在的字符分割點并構造分割點集合Ps。
本文在文獻[12]構造的Ps基礎上添加人工點,添加方法如下:①在波谷,若谷底是平的,則將谷底的起點和終點加入Ps。如果谷底區(qū)域包含號牌四等分點,則將四等分點也加入Ps;②遍歷新的Ps,如果兩個分割點間距離超過,則將兩點間的號牌四等分點加入Ps。本文中取值為一個字符的高度。由于本文方法提取的號牌上下冗余很少,因此單字符高度hs∈[0.2h,0.25h], 考慮算法魯棒性取值0.2h,其中h為號牌IS的高度。
加強項目建設,提升技術支撐能力。2011年以來,在濮陽市局的推動下,各級財政共投資9637萬元,用于市局食品藥品檢驗能力建設、兩個縣域食品檢驗檢測中心建設和市、縣、鄉(xiāng)三級執(zhí)法裝備建設。
2.3.2 分割點組合分析
得到候選分割點集合后,需要根據(jù)待分割字符數(shù)量對分割點進行組合,計算各組合的變異系數(shù)[12]確定最佳分割點組合,具體方法如下:①根據(jù)字符數(shù)量找出所有的分割點組合;②對每個組合,計算所有字符高度和平均字符高度;③計算每個組合的變異系數(shù);④選出變異系數(shù)最小的組合作為最佳分割點組合。其中本文所用變異系數(shù)計算方法如下
(7)
在實際應用中,為了提高算法的魯棒性,我們在組合分析后對與最小變異系數(shù)數(shù)量級一樣的組合進行了額外分析。首先計算組合中平均高度最大值hmax,然后對與hmax相近(差值小于3)的組合計算分割行灰度和,最后將灰度和最小的組合作為最佳分割點組合。
2.3.3 字符分割
獲得最佳分割點組合后,即可根據(jù)該組合中的分割點對號牌進行字符分割。圖8為部分號牌分割結果及對應的二值圖。

圖8 號牌字符分割結果
2.4 字符識別
由于沒有隧道接觸網(wǎng)號牌字符數(shù)據(jù)集,需要自建數(shù)據(jù)集進行模型訓練。通過2.3.3節(jié)字符分割得到數(shù)字字符1086個,字母字符362個,對它們大小進行歸一化處理(歸一化為30×30的尺寸)。由于殘缺號牌(PD類號牌)字符數(shù)量較少,因此將50%的殘缺字符作為訓練集,其它號牌字符取70%作為訓練集,共計1013個訓練樣本。另外由于各字符數(shù)量差異較大,因此需對訓練集進行擴充,本文通過平移字符在圖像中的位置對訓練樣本進行擴充,將數(shù)量少于100個的字符樣本擴充至100。擴充后的訓練集樣本包含數(shù)字和字母共計1405個。
得到訓練集后使用SVM訓練。本文使用抗干擾性較強的C-SVC[13]進行多分類,使用RBF作為核函數(shù),損失函數(shù)參數(shù)設置為2,Gamma參數(shù)設置為0.005。通過訓練得到模型后即可用于單字符的識別,得到接觸網(wǎng)號牌編號。
3 實驗與分析
為了測試本文提出的號牌定位算法﹑字符分割算法和編號識別算法的性能,分別開展號牌定位實驗﹑字符分割實驗和編號識別實驗。其中,對于字符分割結果使用主觀對比來評價,號牌定位結果和字符識別結果使用準確率來評價,準確率計算方法如下
(8)
式中:A為準確率,T為測試樣本總數(shù),c為正確的樣本數(shù)。
3.1 實驗環(huán)境與數(shù)據(jù)
本文實驗圖像均采集自西成線(西安-成都)廣元段隧道,由接觸網(wǎng)安全巡檢裝置(臨時安裝于司機室內(nèi)的便攜式視頻采集設備)采集,共計圖像628張,圖像分辨率為2048×2048。本實驗在臺式電腦上進行,機器安裝Windows 7系統(tǒng),內(nèi)存16 GB,CPU為Intel(R)Core(TM)i7-9000K,主頻4.3 GHz。使用Matlab R2019a進行編碼、實驗和數(shù)據(jù)分析,并使用libSVM3.4作為庫支持。
3.2 號牌定位實驗與分析
對于粗定位號牌,本文通過定性評估來確認號牌是否定位成功,即判斷輸出結果是否包含完整號牌,包含則為定位成功,否則為定位失敗;對于精提取號牌,通過計算輸出號牌高寬比ψ來判定是否定位成功,當ψ<3(該值由特征統(tǒng)計得出)時認為定位的號牌出現(xiàn)缺失,判定為定位失敗。
使用本文定位算法對628張樣本圖像進行號牌定位實驗,628張圖像粗定位結果均正確,粗定位準確率100%;在精提取結果中,號牌定位準確圖像共計618張,定位錯誤10張,定位準確率為98.4%。圖9(a)為隧道接觸網(wǎng)圖像示例,圖9(b)為部分號牌粗定位結果,圖9(c)為對應的精提取結果。定位錯誤號牌如圖10(a)和圖10(b)所示,均為號牌缺失。

圖9 高鐵隧道接觸網(wǎng)圖像及部分號牌定位結果

圖10 號牌定位錯誤結果
其中編號為D093的號牌共計14幀,前9幀精提取錯誤,均為第一個字符“D”上半部缺失;編號為D105的號牌共計14幀,最后1幀定位錯誤,為第四個字符“5”下半部缺失。通過查看粗定位圖發(fā)現(xiàn),編號D093定位錯誤的9張粗定位圖上部因光照不足,在原始圖像號牌已缺失(圖10(c)左側所示);編號D105定位錯誤的粗定位圖下部因光照不足,在原始圖像中號牌已缺失(圖10(c)右側所示)。可見定位錯誤號牌均為光照嚴重不足的客觀原因導致,所以本文提出的定位方法是準確可靠的。
3.3 字符分割實驗與分析
使用本文方法和文獻[12]方法進行字符分割對比實驗,以驗證本文方法改進的有效性。當分割對象是質量較好的號牌時,兩種方法分割結果無區(qū)別,當分割的號牌質量較差出現(xiàn)字符粘連或者字符斷裂時,分割結果如圖11所示。

圖11 文獻[12]與本文方法字符分割結果對比
圖11(a)為字符粘連號牌的分割結果對比,圖11(b)為字符斷裂號牌的分割結果對比。其中各子圖上方為本文方法分割結果及其二值圖像,下方為文獻[12]分割結果及其二值圖像。可以看出,較之于文獻[12],本文方法在處理斷裂和粘連字符效果更好,能夠滿足隧道接觸網(wǎng)號牌字符的分割。但是由于添加了人工點,導致集合的組合數(shù)增多,造成一定的性能損失。
3.4 編號識別實驗與分析
為驗證識別效果,我們對分割出的字符分別使用模板匹配法[14]、Lenet-5[15]網(wǎng)絡和本文方法進行識別對比實驗。其中模板匹配法從2.3節(jié)中的訓練樣本中選取質量好的字符充當模板;Lenet-5使用與本文算法相同的訓練集。從每個字符類別中取30%作為測試樣本(殘缺號牌字符取50%),測試樣本共計435個字符,部分樣本如圖12所示。

圖12 部分號牌字符樣本
各字符識別統(tǒng)計結果見表2,本文總體識別正確率為95.4%,高于模板匹配法(70.1%)和LeNet-5網(wǎng)絡識別算法(87.1%)。從單字符識別結果來看,除字符“1”識別率小于模板匹配法外,其它字符識別率均優(yōu)于對比算法。
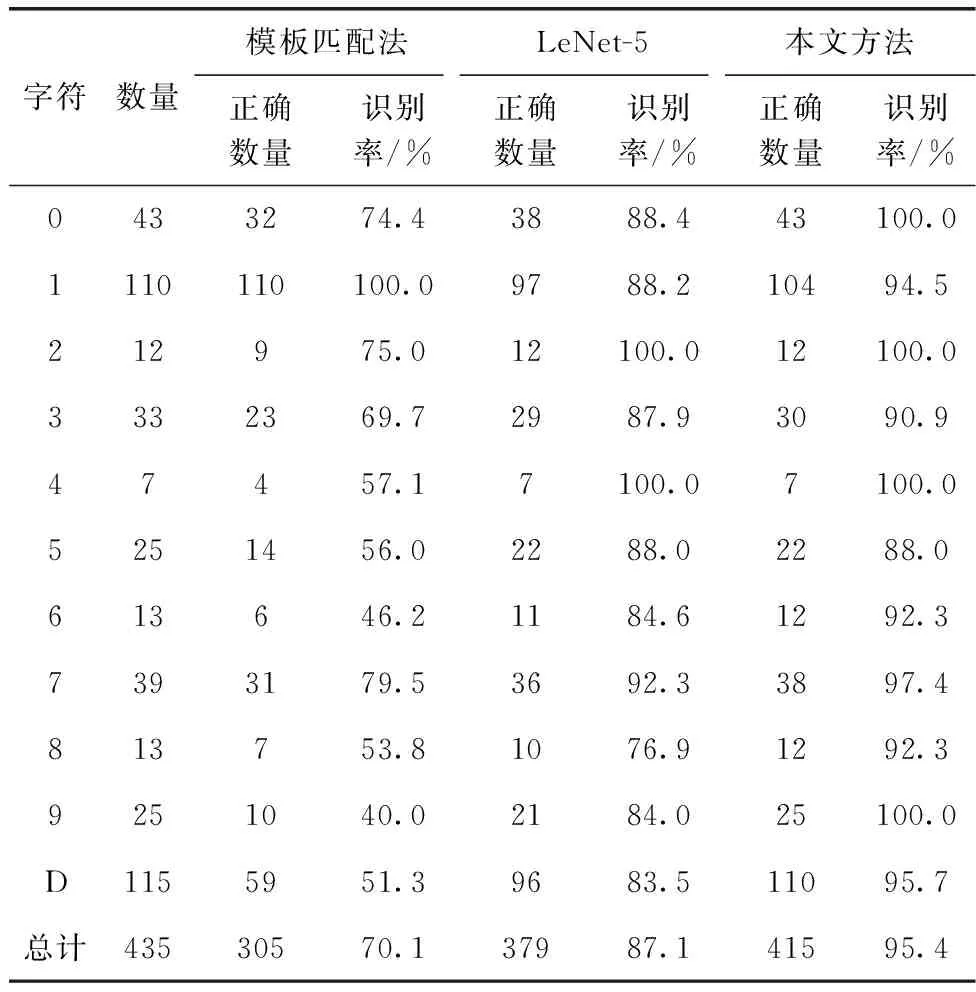
表2 識別對比實驗結果
在本文算法識別結果中,數(shù)字“5”識別率僅88%,錯誤樣本如圖13(a)所示,錯誤的主要原因是筆畫粘連﹑缺失和號牌自身缺失。圖13(b)給出了數(shù)字“1”的錯誤樣本,錯誤的主要原因是與“3”和“4”的部分訓練樣本相似,如圖13(c)和圖13(d)所示。可見,由于拍攝質量差,不同樣本已相互影響。

圖13 部分識別與訓練樣本圖像
雖然個別字符的識別率較低(<90%),但考慮該字符測試樣本數(shù)量較少,存在偶然因素,且結合表2結果,可以認為基于SVM并使用隧道字符圖像進行訓練和分類的字符識別方法對于高鐵隧道接觸網(wǎng)號牌的識別方法是可行的。
4 結束語
在隧道低光圖像無法有效增強的情況下,本文給出的號牌定位算法能夠準確有效對接觸網(wǎng)號牌進行定位,實驗結果表明本文的定位算法可行性強,準確率高。在識別過程中,本文給出基于多尺度LoG算子的零交叉二值化算法有效地解決了低光號牌二值化難題,并通過對現(xiàn)有字符分割算法進行改進,對垂直號牌中的粘連和斷裂字符進行了有效分割。最后,識別對比實驗結果表明,本文識別方法可靠性高,能夠滿足隧道場景中的接觸網(wǎng)編號識別需求,具有工程應用價值。但是本文仍存在對部分低質量號牌識別效果不佳的問題,下一步我們擬通過前置分類,先將低質量號牌區(qū)分出來,再對低質量字符進行單獨識別,來解決上述問題。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
