基于用戶行為的長短期序列推薦模型
2023-10-12 01:28:26王晨星雒曉輝
計算機工程與設計 2023年9期
王晨星,吳 云+,雒曉輝
(1.貴州大學 公共大數據國家重點實驗室,貴州 貴陽 550025;2.貴州大學 計算機科學與技術學院,貴州 貴陽 550025)
0 引 言
序列推薦系統(sequence recommendation system,SRS)[1]已成為推薦系統領域的研究熱點。基于傳統的推薦模型,如KGNCF[2](knowledge graph enhanced neural collaborative filtering)和UILCF[3](user identity lda collaborative filtering),這些模型關注用戶和項目之間的靜態聯系,忽略了用戶興趣的衰減以及偏好的動態變化。基于Markov鏈的序列推薦模型,如RF-MC[5](factorizing Markov chains),可以學習順序模式,但存在一定的缺陷:一方面該模型只能捕獲點級別的依賴,而忽略了前幾個用戶行為作為一個整體對下一時刻行為產生的影響。另一方面該模型沒有考慮用戶在較長時間域內的興趣對推薦結果產生的影響。基于深度學習的推薦模型如GRU4Rec[5](gate recurrent unit4 recommendation),該模型利用循環神經網絡進行序列推薦。然而隨著序列長度的增加導致模型無法記憶過長的序列。此外,基于循環神經網絡的推薦模型缺乏對局部關聯關系進行深層挖掘,這將導致一些重要的行為關系的損失。基于注意力機制[6,7]的推薦模型如NARM[8](neural attentive recommendation machine),該模型忽略了歷史交互項之間的局部交互關系以及用戶歷史點擊序列對目標物品的影響。
為了解決以上模型存在的問題,我們提出了一個基于用戶行為的長短期序列推薦模型(long and short term sequence recommendation model based on user behavior,UBLSR)。本文主要的貢獻如下:①設計了一種多路空洞卷積網絡,該網絡可以挖掘序列中的局部和全局行為關系,從而提高推薦精度。②利用自注意力網絡建模用戶短期興趣在序列內的動態轉移,同時考慮目標候選物品對推薦的影響。③設計一個基于鄰居用戶行為的長期興趣建模方案,同時融入注意力機制,動態調整每個用戶對最終排名的貢獻置信度,減少無用特征的干擾。
1 相關工作
1.1 基于RNN序列推薦
大量的RNN(recurrent neural network)被用于序列推薦[9,10]。例如GRU4Rec模型,該模型受到循環神經網絡結構的限制,假設任何相鄰的用戶點擊行為都一定存在依賴關系,缺乏對噪聲用戶行為的有效鑒別,因此可能學習到錯誤的依賴關系。這種限制使得個性化序列推薦表現欠佳,因為在序列推薦問題中,并不是所有相鄰的操作都有依賴關系。除此之外GRU4Rec模型無差別地對待所有交互行為,忽略了當前行為中用戶的主要意圖,導致推薦準確性不高。循環神經網絡通過串行的運算方式來學習序列中的時序關系,因此阻礙了模型的并行化,從而降低模型的計算速度。
1.2 基于CNN序列推薦
卷積神經網絡(convolutional neural networks,CNN)不假設用戶有很強的前后時序關系,并且可以學習特定區域內的局部特征和不同區域之間特征的關系。以往模型重點利用卷積網絡來挖掘輔助信息如圖像信息、文本信息,而我們的工作著眼于利用卷積捕獲訪問過的項目的序列信息。Tang等[11]提出了Caser(convolution al sequence embedding recommendation)模型,該模型使用CNN一維水平卷積和垂直卷積在一定程度上解決了以往模型在捕獲點級、聯合級順序模式的缺陷,但該模型的水平卷積和垂直卷積都是單組的,掃描到的特征缺乏表示能力。且該模型只適用于淺層網絡結構,在建模遠程依賴關系或注入大規模數據流時將出現推薦性能下降的問題。而本文設計的多路空洞卷積網絡經過不同卷積路徑得到的特征圖之間的耦合性較低,關注的主要特征不同,可以得到互為補充的特征圖,以更完整地表示序列信息,在大規模數據下表現突出。
1.3 基于注意力機制的推薦
Yu等[12]提出AFM(attentional factorization machines)模型,該模型通過引入注意力機制,來判斷不同特征之間交互的重要性。然而該模型忽略了用戶點擊順序信息的重要性,通常會隨著物品和用戶興趣的動態變化而失敗。Li等提出NARM模型在循環神經網絡的基礎上借助注意力機制對序列行為中用戶的主要意圖進行建模。具體的:NARM包含編碼器-解碼器結構。在編碼器中利用門控循環單元對序列特征進行編碼,同時借助注意力機制挖掘用戶在當前序列中的主要意圖,將得到的用戶主要意圖和序列特征聯合送入解碼器中計算物品的最終得分。然而該模型忽略了用戶點擊序列背后潛在歷史興趣跟目標物品之間的關聯。
2 本文方法
2.1 問題定義
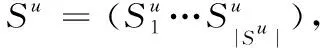
2.2 模型描述
本文提出了一個基于用戶行為的長短期序列推薦模型UBLSR。模型結構如圖1所示,該模型主要包括序列信息挖掘模塊(sequence information mining module,SIMM)、用戶短期興趣建模模塊(user short term iterest module,USTIM)、用戶長期興趣增強模塊(user long term interest enhancement module,ULIEM)和輸出推薦模塊(output recommendation module,ORM)。

圖1 基于用戶行為的長短期序列推薦模型(UBLSR)
首先將目標物品項和用戶歷史行為的原始特征送入嵌入層轉換為嵌入向量,然后將嵌入向量輸入序列信息挖掘模塊,利用多路空洞卷積網絡來挖掘深層用戶行為信息;接著將得到用行為信息按長度劃分分別送入用戶短期興趣建模模塊和用戶長期興趣增強模塊中;在用戶短期興趣建模模塊中,利用自注意力網絡[13]對歷史序列和目標物品的動態交互進行建模;在用戶長期興趣增強模塊中,利用基于鄰居用戶的注意力機制建模用戶長期興趣偏好;最終將用戶短期興趣建模模塊和長期興趣增強模塊的結果聯合送入輸出推薦模塊,預測下一時刻的用戶行為。
2.3 序列信息挖掘模塊
將用戶歷史序列和物品的嵌入向量輸入到神經網絡中來捕獲時序特征。模塊結構如圖2所示,包含聯合卷積層、垂直卷積層、連接層。聯合卷積層包含膨脹率為1的空洞卷積層1和膨脹率為2的空洞卷積層2。
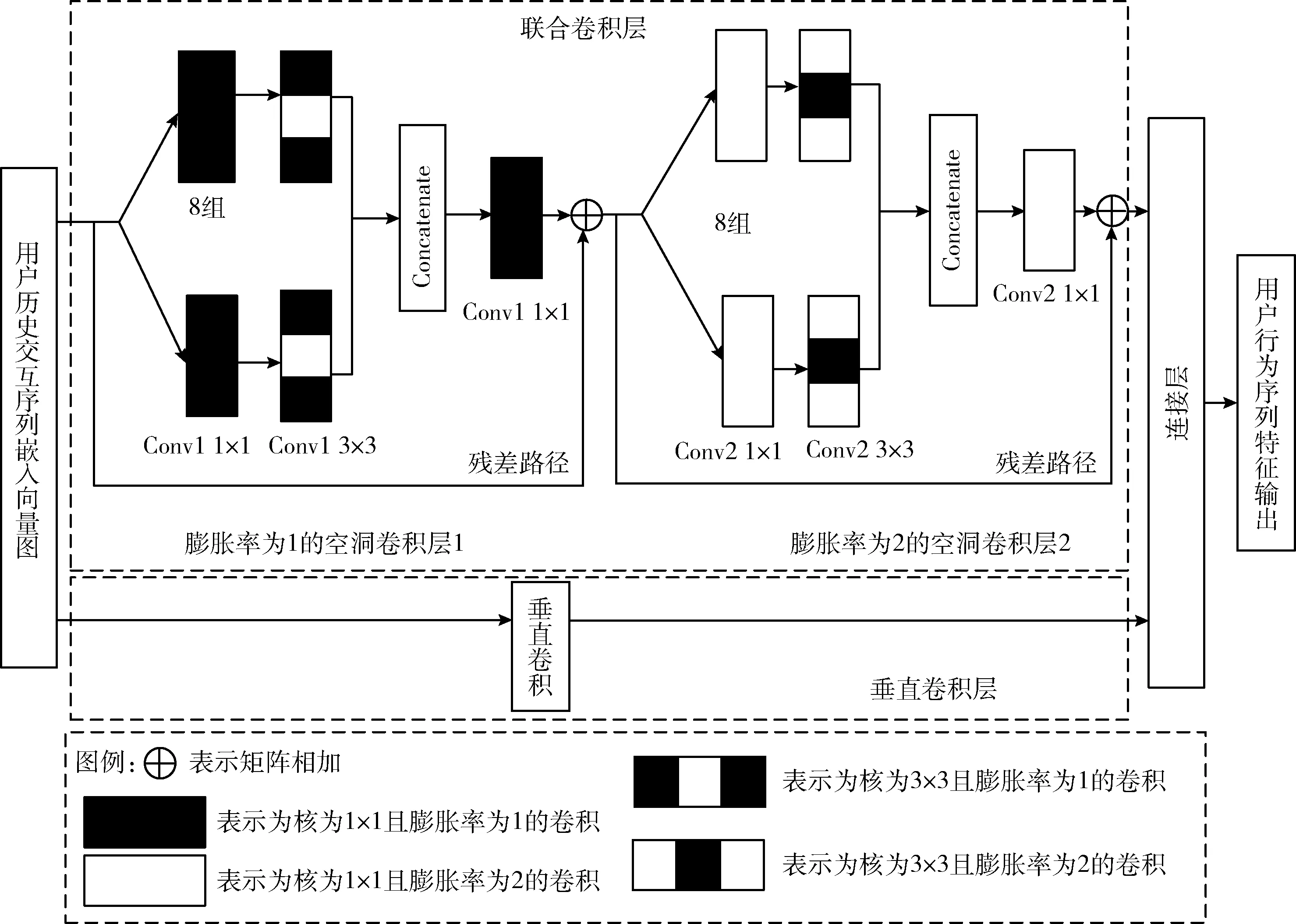
圖2 序列信息挖掘模塊(SIMM)
接下來分別介紹網絡的各個部分:
(1)第一層左側是聯合卷積層:本層設計了一種多路空洞卷積網絡(multi-channel dilated convolution network,MDCN)對序列信息進行局部感知,實現聯合級別序列關系的挖掘。
針對傳統ResNet[14]網絡在采樣和池化過程中的信息丟失問題,我們使用空洞卷積[15]代替普通卷積,相比傳統CNN,空洞卷積具有較寬的感受視野和較短距離的梯度傳播可以在保持卷積核參數大小不變的同時,增大感受野,從而挖掘到點擊序列下更長距離的序列信息。聯合卷積層共兩層,在網絡的第一層和第二層分別用膨脹率為1、2的空洞卷積代替普通卷積。
針對傳統ResNet網絡在單通路結構下挖掘表現力不足的問題,我們將網絡擴展成多通路結構,每層通路條數C設置為8。這種結構使得模型在不增加參數復雜度的前提下學習到更廣泛的序列信息,同時增加模型的可擴展能力。模型主要參數見表1。

表1 多通路空洞殘差網絡主要參數
本文采用殘差結構優化信息傳遞路徑,目的是為防止訓練過程中的梯度消失。同時參考了Inception[16]的split-transform-merge(分支-改變-合并)思想。
(2)與聯合卷積層并列的結構是垂直卷積層:垂直卷積核的橫向寬度默認為1,對歷史交互序列進行垂直卷積運算,來挖掘點級別的序列關系。
(3)第二層是連接層:將聯合卷積層和垂直卷積層的輸出向量拼接,聯合輸入到一個完全連接的神經網絡層,以獲得更多抽象的表示信息,序列信息挖掘模塊的輸出公式為
(1)
式中:σ(x) 表示sigmoid函數,W和b表示要學習的參數,E1表示聯合卷積層的輸出,E2表示垂直卷積層的輸出,O表示序列信息挖掘模塊的輸出。
2.4 用戶短期興趣建模模塊
用戶歷史點擊的順序信息可以很好地反映一段時間內用戶興趣的動態變化。首先給序列中每個歷史交互的向量表示加上位置編碼,然后利用自注意力網絡來建模用戶短期興趣在序列內的復雜動態轉移,這樣可以很好地弱化順序關系同時提升推薦效果。網絡結構如圖3所示:本文的自注意力網絡的查詢向量Query的輸入為目標物品嵌入向量,關鍵字向量Key、值向量Value的值均為經序列信息挖掘模塊處理后的得到的用戶行為信息嵌入向量,短序列層在掃描歷史交互序列信息的同時,將目標商品和歷史行為序列的關系納入衡量范圍。
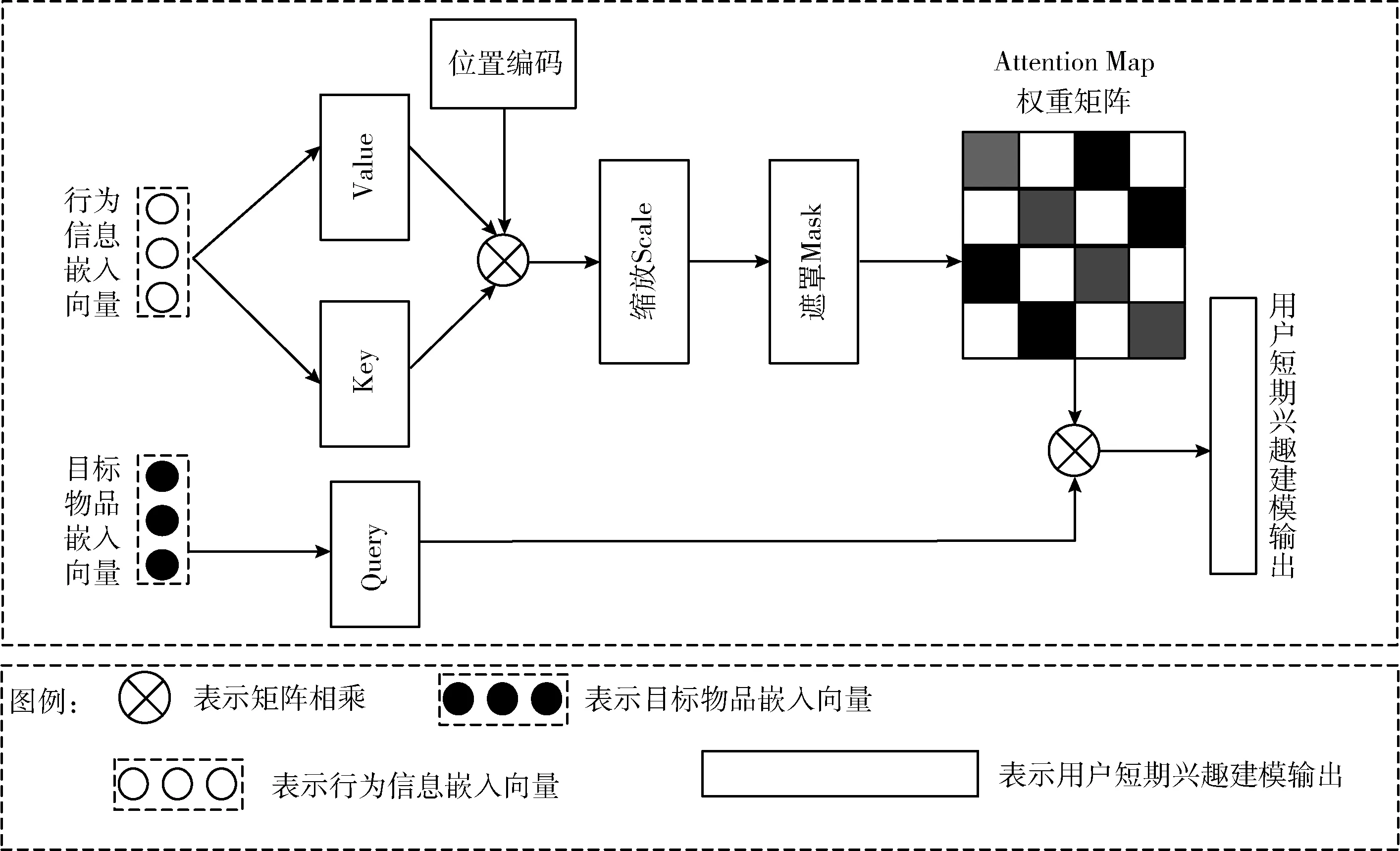
圖3 用戶短期興趣建模模塊(USTIM)
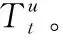

(2)
(3)
(4)
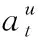
(5)
2.5 用戶長期興趣增強模塊
我們用記憶網絡[17]來表示基于鄰域的組件,以捕獲用戶和項目之間的高階復雜關系,提出了一個用戶長期興趣增強模塊,這一層的核心是記憶網絡和注意力機制的結合。外部記憶允許編碼豐富的特征表征,而注意力機制從交互社群中推斷相關物品的特定貢獻。記憶組件允許讀寫操作對內存中復雜的用戶和項目關系進行編碼。設計一個考慮鄰居用戶的用戶長期偏好表示方案。在以上基礎上,借助注意力機制對具有相似偏好的特定用戶子集給予更高的權重,形成一個集體鄰域摘要。
用戶記憶組件:由用戶記憶矩陣S、歷史交物品記憶矩陣I組成,每個用戶u的記憶矩陣su∈S內部存儲了特定的用戶隱含信息,每個歷史交互項目k的記憶矩陣ik∈I內部存儲了特定項目的隱含信息。我們設計一個用戶偏好向量puk, 其中每個維度pukv是目標用戶u和與u具有相似歷史交互記錄k的鄰居用戶v之間的相似度
(6)
式中:?v∈N(k), 其中N(k) 表示為物品k提供隱式反饋的所有用戶(鄰居)的集合。
基于鄰居用戶的注意力機制:傳統的鄰居選擇算法在初始化階段需要指定用戶的個數,而在實際場景中,每個用戶的社群鄰居個數是變化的,因此我們利用注意力機制對相似性更高的鄰居用戶施加更大的權重。通過注意力機制學習用戶鄰域的自適應非線性加權,并融合鄰居用戶的外部記憶矩陣來構建最終的鄰域表示
(7)
(8)
其中,在經典的記憶網絡中,用戶v的嵌入向量cv表示外部記憶。通過加權求和的方式可以得到用戶在相關鄰域中的長期用戶興趣信息。用戶u最終的長期興趣表示Zuk如下
Zuk=W1yuk+W2(su⊙ik)+b
(9)
式中:⊙是元素乘積,W1、W2和b是我們要學習的參數。
2.6 輸出預測模塊
我們設計的UBLSR模型同時對用戶的短期興趣和長期興趣進行建模,該模型最終將短期興趣建模模塊和長期興趣增強模塊的輸出向量整合,如式(10)所示
(10)
其中輸出層的權重矩陣用W∈R|I|×2d表示,輸出層的偏置項用b表示。最終將拼接好的結果送入sigmoid函數進行預測,結果概率如下所示
(11)
式中:σ(x) 表示sigmoid函數。
3 實 驗
3.1 實驗設置
所有實驗均在Intel Core(TM)i5-4690 CPU @ 3.5 GHz和16 G內存Ubuntu系統中完成。本文模型基于Tensorflow 2.0編寫,其中用戶和物品的向量維度設置范圍如下 {20,30,50,100}, 學習率的探索范圍如下 {1,10-1…10-4}, 馬爾可夫階數來自 {1,…,9} 批次大小為 512,dropout率為0.5。
3.2 數據集
本文在MovieLens(ML)、Gowalla數據集上進行實驗,來驗證本文設計的模型效果。
MovieLens:一個廣泛用于評估協作過濾算法的基準數據集。在實驗中使用Movielens-1M(ML-1M)版本。
Gowalla:一個基于位置的社會交流網站,用戶通過簽到來分享他們的位置,并貼有時間戳的標簽。我們遵循與Caser相同的預處理過程:我們將評審或評級的存在視為隱式反饋(即用戶與項目交互),用戶交互的時序性由時間戳標定,并對ML-1M和Gowalla分別丟棄少于5和15個操作的用戶和項目。訓練和驗證取每個用戶序列中前80%的行為,評估模型性能的測試集取其余20%的行為。
3.3 評價指標

我們報告了所有用戶的這些值的平均值。N∈{1,5,10}。 其中,當中的第N項為R,Recall(N)=1 時,平均精度(MAP)為所有用戶的AP平均值,平均精度(AP)的定義如下
(12)
(13)
(14)
3.4 實驗對比基準模型介紹
(1)KGNCF[2]:利用圖神經網絡技術挖掘知識圖譜中復雜的用戶關系,同時利用神經網絡和矩陣分解兩者結合的方式進行非時序推薦。
(2)UILCF[3]:利用LDA主題模型緩解傳統協同過濾推薦中的冷啟動問題,同時利用海明距離建立相似用戶評價指標以提高推薦效果。
(3)RF-MC[4]:利用隨機森林對用戶興趣標簽進行分類以解決個性化推薦過程中的冷啟動問題,同時利用一階馬爾可夫鏈進行序列推薦。
(4)GRU4Rec[5]:利用RNN來建模順序依賴關系,同時借助用戶歷史點擊行為對下一時刻行為進行推薦預測。
(5)Caser[12]:利用CNN一維水平卷積和垂直卷積挖掘點級、聯合級順序依賴關系,是一種先進的短期序列推薦模型。
(6)NARM[8]:利用兩個GRU分別學習用戶行為序列的全局和局部信息,并將注意力機制與GRU模型結合進行用戶短期興趣建模。
3.5 結果分析與比較
3.5.1 實驗結果比較
對于每種方法,都尋找超參數的最優設置。嵌入層的維度設置范圍如下 {20,30,50,100}, 學習率的探索范圍如下 {1,10-1…10-4}。 對于Caser和GRU4Rec,馬爾可夫階數來自 {1、…、9}。 對于Caser模型,水平過濾器的高度范圍來自 {4,8,16,32 }, 目標數物品數來自 {1,2,3}, 激活函數來自 {sigmod,tanh,Relu}。 以上基準模型和本文模型在評價指標上的對比結果見表2。
江西六國擁有“施大壯”“貴化”“群星”“田園豐”等四大品牌近80種規格的產品,產能達到80余萬噸,2012年以來,先后興建了年產10萬噸工業級磷酸一銨和年產4萬噸硫酸鉀復合肥裝置,是業內規格品種最齊全的復合肥生產企業。
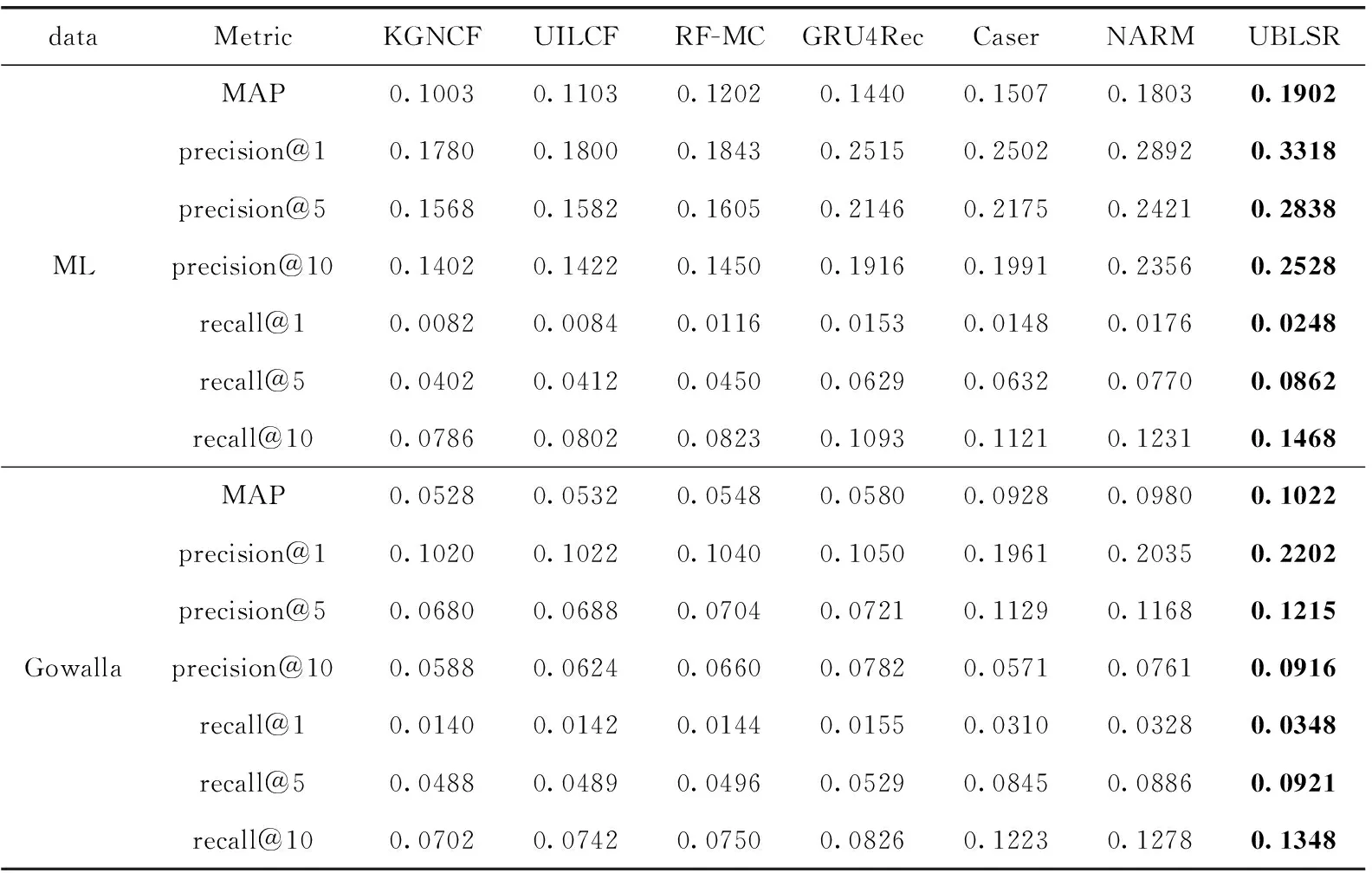
表2 模型在兩個數據集上的性能比較
通過對數據進行分析得到如下結論:
(1)在MovieLens數據集上,本文設計的UBLSR模型相對對比模型中表現最好的NARM模型,MAP提高了5.5%;precision最大提高了17.22%;recall最大提高了40.9%;在Gowalla數據集上,本文設計的UBLSR模型相對對比模型中表現最好的NARM模型,MAP提高了4.3%;precision最大提高了20.37%;recall最大提高了6.1%。該結果表明本文設計的UBLSR模型可以有效提升模型的推薦精度。
(2)本文設計的UBLSR在推薦過程中將時間序列信息納入到特征考慮范圍,相比非時序推薦模型KGNCF、UILCF表現出更優秀的性能,結果表明用戶點擊選擇的順序信息至關重要,用戶歷史交互的順序信息可以更好地反映用戶在一段時間內興趣的動態變化。
(3)本文提出的UBLSR模型在MovieLens數據集上的MAP值相比于RF-MC提升了58.2%;在Gowalla數據集上的MAP值相比于RF-MC提升了86.5%。原因如下:UBLSR模型在序列推薦的過程中兼顧考慮了序列中出現的單個物品與多個物品分別對用戶對下一物品的喜好程度的影響,從而挖掘序列模式下更復雜的關系,而RF-MC模型僅對一階馬爾可夫鏈進行學習。
(4)本文提出的UBLSR模型在MovieLens數據集上的MAP值相比Caser模型提升了26.2%,在Gowalla數據集上的MAP值相比Caser提升了10.1%。因為Caser無區別地對待所有歷史交互物品,而UBLSR在底層模型的基礎上添加注意力機制,區別對待歷史交互行為。
(5)本文提出的UBLSR模型在MovieLens數據集上的MAP值相比GRU4Rec和NARM模型分別提升了32.1%、5.5%;在Gowalla數據集上的MAP值相比GRU4Rec和NARM分別提升了76.2%、4.3%。原因如下:GRU4Rec算法僅使用循環神經網絡生成序列向量。循環神經網絡在每次迭代中選取局部最優解,致使模型無法挖掘序列中全局信息。NARM 模型在循環神經網絡結構的基礎上融合了注意力機制,然而交互過程中的局部信息仍然通過循環神經網絡迭代生成,易受到用戶短期偏好波動的影響,無法充分捕捉更穩定的長期偏好。而UBLSR通過自注意力網絡建模局部動態偏好,同時考慮了目標物品對注意力機制得分的影響,除此之外UBLSR借助長期興趣增強模塊感知用戶長期偏好,使得學習到的用戶行為信息更加豐富,從而提升推薦效果。
3.5.2 探究向量維度對實驗的影響

圖4 在Movielens-1M上探究向量維度對MAP的影響
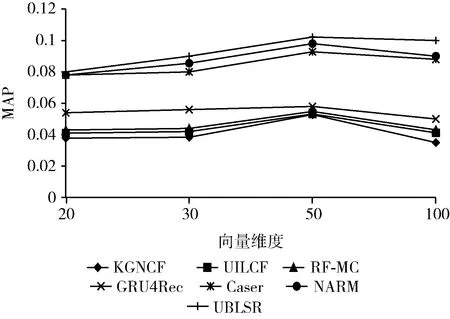
圖5 在Gowalla上探究向量維度對MAP的影響
3.5.3 探究歷史交互序列長度對實驗影響
保持其它最優超參數不變的情況下,改變歷史交互長度,觀測MAP值的變化,此時MAP衡量了模型從高階信息中挖掘潛在信息的能力。歷史交互長度對推薦效果的影響如圖6和圖7所示:在相同序列長度下相比對比模型,UBLSR提取信息的能力更強。更長的歷史交互序列可以提供更多交互信息,然而當長度超過5時,模型推薦性能反而開始下降。這是合理的,因為早期的歷史行為和當前時刻的用戶行為相關性較小,可能引入額外的信息和更多的噪聲。除此之外,歷史序列長度越大,序列中包含的用戶無意圖行為越多,用戶意圖越發散,導致物品在注意力機制計算過程中分配的權重趨于平均。最終導致模型難以挖掘用戶的主要意圖,推薦性能隨之下降。
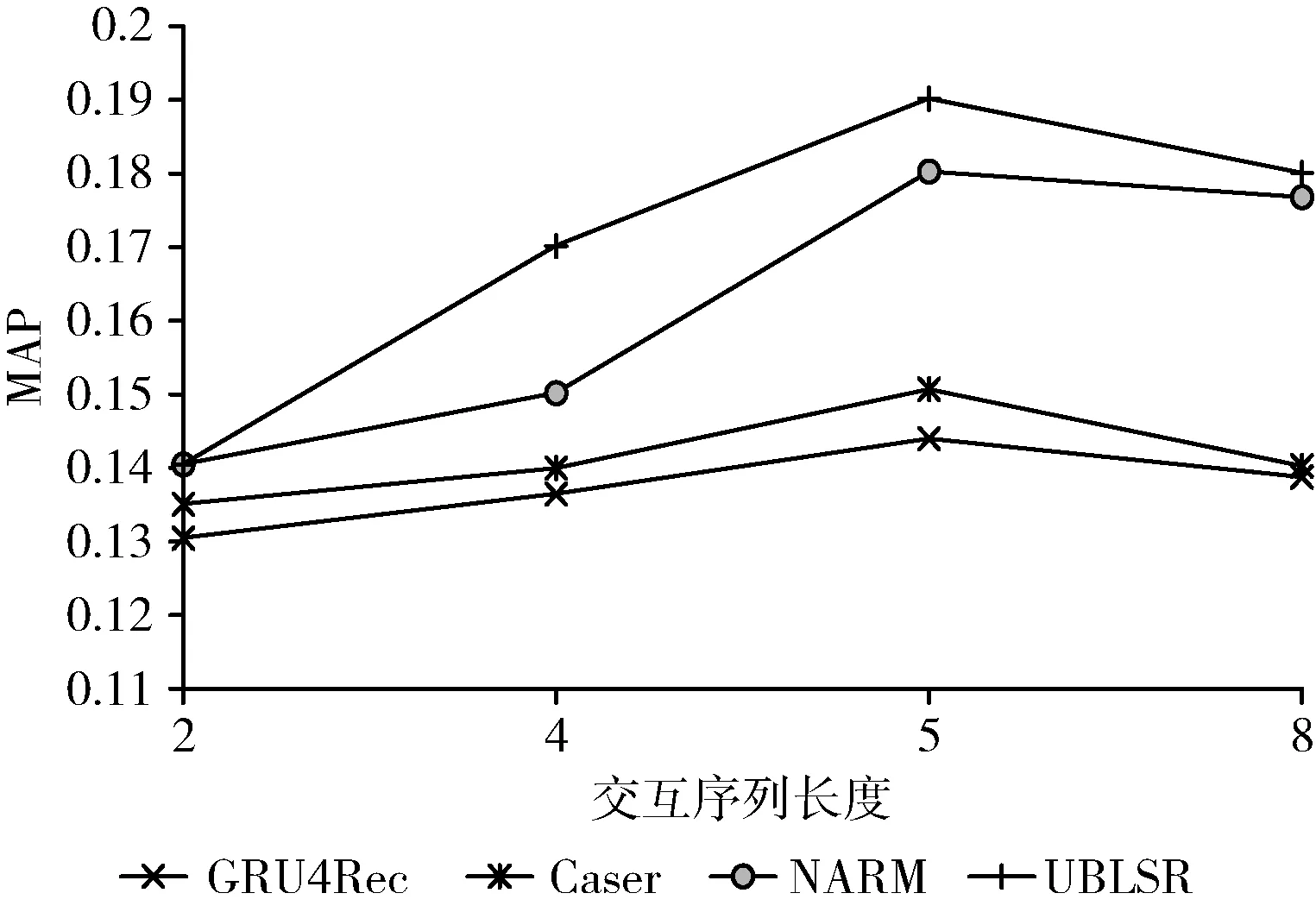
圖6 在Movielens-1M上探究歷史交互序列長度對MAP的影響
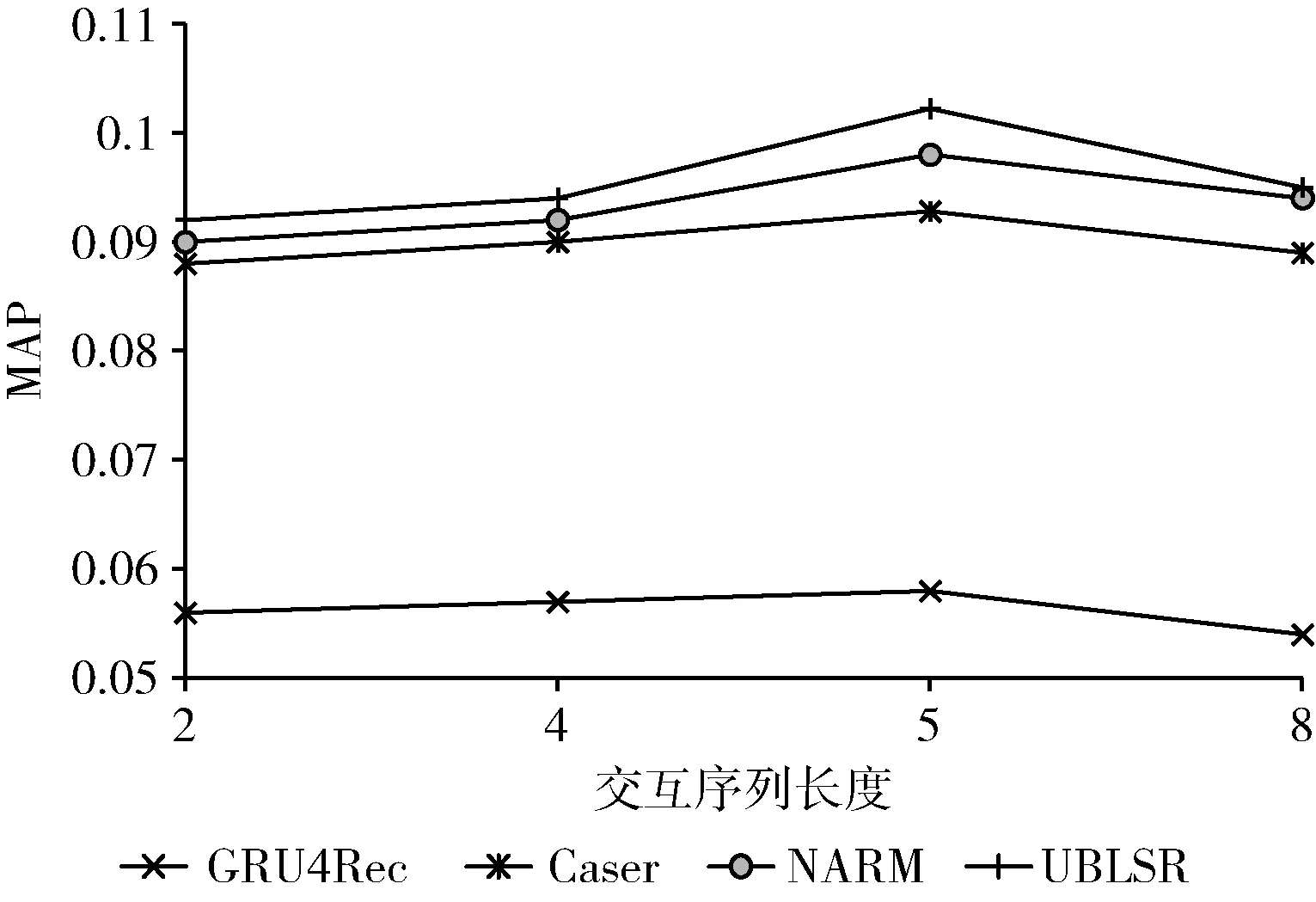
圖7 在Gowalla上探究歷史交互序列長度對MAP的影響
3.5.4 模型方法的消融實驗
為驗證本文提出的每個模塊的有效性,保持所有超參數在最佳設置下進行對比驗證。對于x∈{ u、v、w},X-x表示啟用了組件x的UBLSR模型。u為序列信息挖掘模塊,v為用戶短期興趣建模模塊,w為用戶長期興趣增強模塊,Base表示未組裝列信息挖掘模塊、用戶短期興趣建模模塊和用戶長期興趣增強模塊的基礎推薦模型。例如,X-uv表示組裝序列信息挖掘模塊和用戶短期興趣建模模塊的推薦模型。各個模型在數據集MovieLens-1M上的MAP指標的表現見表3。
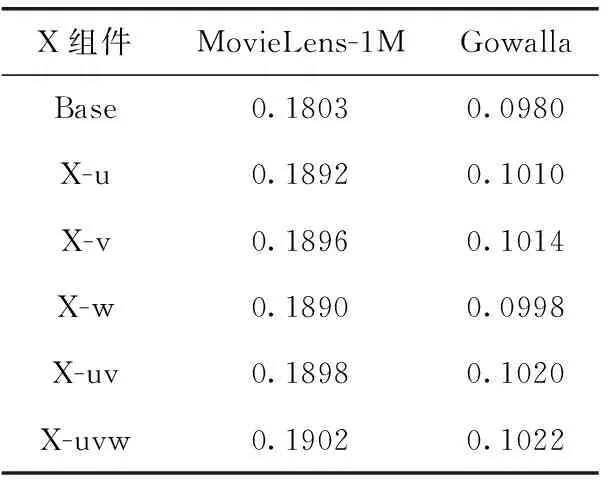
表3 組件的有效性分析結果
通過結果得出:
(1)使用了序列信息挖掘模塊的推薦模型在MovieLens-1M數據集的MAP指標上對比Base模型最大提升了4.9%,在Gowalla數據集上提升了3.1%。本文設計的多通路空洞殘差網絡經過不同卷積路徑得到的特征圖之間的耦合性較低,關注的主要特征不同,可以得到互為補充的特征圖,以更完整表示歷史序列特征,得到豐富的特征語義表達。由實驗可以得出本文提出的序列信息挖掘模塊可以解決以往模型在捕獲用戶歷史行為交互過程中表征能力不足的缺陷問題,從而提升序列推薦的性能。
(2)使用了用戶短期興趣建模模塊的推薦模型在MovieLens-1M數據集的MAP指標上對比Base模型最大提升了5.2%,在Gowalla數據集上提升了3.5%。本文設計的短期興趣建模模塊可以建模用戶點擊序列下更深層短期興趣,設計的自注意力層不但有效建模用戶短期歷史興趣,而且考慮了目標候選物品的和歷史行為的交互,由實驗可以得到本文提出的自注意力,可以解決傳統模型建模用戶歷史興趣序列無法有效關聯目標候選物品的問題,從而提升序列推薦的性能。
(3)使用了用戶長期興趣增強模塊的推薦模型在MovieLens-1M數據集的MAP指標上對比Base模型最大提升了4.8%,在Gowalla數據集上提升了1.9%。本文設計的長期興趣增強模塊可以利用所有對項目進行了評級的用戶來獲得關于現有用戶和項目關系的額外見解。其次,借助神經注意力機制根據特定項目調整每個用戶對最終排名的貢獻置信度,從而提升序列推薦的性能。
對比Base模型,本文設計的UBLSR在MAP指標上最大提升了5.4%,驗證UBLSR模型可以有效提升推薦效果。
4 結束語
為提升推薦系統的推薦精度,本文提出了一種基于用戶行為的長短期序列推薦模型(UBLSR)。首先,設計了一種多路空洞卷積網絡,用來挖掘序列信息下的深層行為特征;接著,利用自注意力網絡建模用戶短期興趣在序列內的復雜動態轉移。然后,設計了一個考慮鄰居用戶行為的長期興趣建模方案,同時融入注意力機制,動態調整每個用戶對最終排名的貢獻置信度,減少無用特征的干擾。實驗結果表明,UBLSR模型在推薦精度上比基準模型有顯著的提升,驗證了模型方法的有效性。此外,我們的模型也適用于其它相關的序列預測任務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
