基于樣本分布的類別均衡化方法
2023-10-12 01:27:04李國和陳桂婷鄭藝峰洪云峰周曉明潘雪玲
計算機工程與設計 2023年9期
李國和,陳桂婷,鄭藝峰,洪云峰,周曉明,潘雪玲
(1.中國石油大學(北京)石油數據挖掘北京市重點實驗室,北京 102249;2.中國石油大學(北京)克拉瑪依 信息科學與工程學院,新疆 克拉瑪依 834000;3.閩南師范大學 計算機學院,福建 漳州 363000;4.杭州拾貝知識產權服務有限公司 應用研究院,浙江 杭州 310010;5.廈門瀚影物聯網 應用研究院,福建 廈門 361021)
0 引 言
獲取知識精度不僅與機器學習算法有關,還深受數據質量的影響,如樣本類別的不均衡性,導致機器學習獲取的分類模型把少數類樣本誤判為多數類,從而影響了分類模型有效性[1-3]。樣本均衡化方法分為算法層面[4]和數據層面[5]。前者改進學習算法,樣本不發生變化;后者對樣本本身增加或減少。欠采樣容易丟失多數類樣本的分類信息,因此過采樣是主流的均衡化方法,得到廣泛研究和應用。
啟發式的SMOTE[6]算法隨機選擇少數類樣本的近鄰樣本,通過線性插值生成新樣本,但未考慮近鄰樣本的空間分布。G-SMOTE[7]算法先對少數類樣本聚類,為每個類簇分配合成樣本數量,在少數類樣本的超球體區間合成新樣本,重構了樣本空間。GJ-RSMOTE[8]算法采用高斯混合模型和JS散度共同控制合成樣本的數量和分布,但凹分布考慮不足。SMOTE-LOF[9]算法通過添加局部異常因子LOF對SMOTE算法進行改進,避免噪聲樣本的生成。基于最優路徑森林的無監督過采樣算法[10]先通過聚類獲取少數類樣本的內部分布,然后使用均值和協方差矩陣合成新樣本,保證了樣本的多樣性。K-means SMOTE[11]通過K-means聚類,根據給定閾值刪除少數類與多數類樣本數占比低的少數類樣本簇,有效抑制新少數類樣本落入多數類區域,但沒考慮少數類內部的分布。
針對過采樣算法存在的問題,提出類別均衡化方法(label-balancing method based on sample distribution,LBMSD),主要包括凈化少數類分布邊界;確定少數類合成樣本數和平衡少數類類簇間的樣本數量;分配少數類簇樣本權重,決定類簇內生成少數類樣本及其合理分布。
1 相關概念
1.1 信息系統與信息決策系統

如果集合div(X)滿足X=∪?xi∈div(X)Xi且Xi≠Xj,Xi∩Xj=?,稱div(X) 為X的劃分。對于IS,屬性集A?S, 存在劃分div(X) 滿足?a∈A,?Xi∈div(X),?u,v∈Xi,a(u)=a(v), 稱div(X) 為基于屬性集A的等價劃分,記為X/A。 如果?a∈A為連續或數值型,樣本相似度simA(u,v)≤δ, 稱div(X) 為基于屬性集A的聚類劃分,記為cluA(X)。 對于DT,決策屬性?d∈D為離散型,存在基于D′?D的等價劃分,記為X/D′。 |X/D′| 為決策類別數(|.|為集合元素個數)。條件屬性?c∈C為連續或數值型,存在基于C′?C的聚類劃分,記為cluC′(X)。
對于DT,?Xi,Xj∈X/D,|Xi| 與 |Xj| 差異較大,稱DT為類別不均衡決策信息系統。當 |X/D|=2時,如果 |X1|>|X2|, 則X1為多數類樣本集,記為N(負例樣本集);X2為少數類樣本集,記為P(正例樣本集)。DT可分解為Kp=
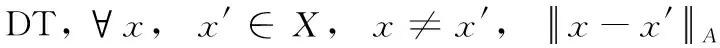
1.2 單類支持向量機
單類支持向量機One-class SVM[12]采用核函數把樣本映射到高維特征空間,將零點作為負樣本點,其它樣本作為正樣本點,最大化零點和其它樣本點之間的距離并構建最優超平面。對于N={x1,x2,…,xn} 負例樣本集,One-class SVM優化目標如式(1)所示
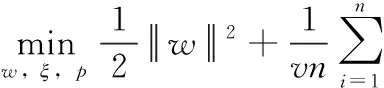
(1)
式中:v∈(0,1) 為調節松弛程度,控制異常樣本比例的上界,w是超平面法向量,ρ是超平面截距,φ() 為原始空間到特征空間的映射。ξ是松弛變量,允許一定誤差的存在。
1.3 DBSCAN算法
對于Kp=
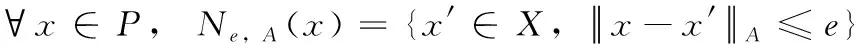
定義2 核心點:?x∈P,Ne,A(x)≥φ時,其中φ為e鄰域中樣本數閾值,x為基于屬性集A、φ的核心點,記為CNe,A,φ(x)。
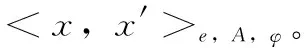
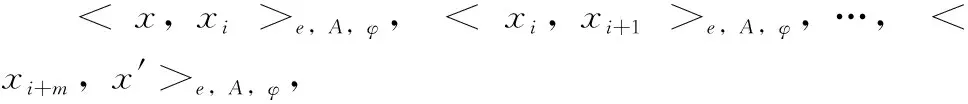
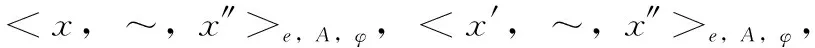
由上述概念構成密度聚類DBSCAN算法核心,可實現Kp的聚類劃分cluA(P)。
2 類別均衡化過采樣方法LBMSD
類別均衡化過采樣方法過程:①判斷信息決策系統DT的不平衡度,根據不平衡度的大小選擇不同的方法清洗數據;②利用DBSCAN對P得到聚類劃分cluA(P), 計算類簇密度和邊界樣本數確定類簇生成樣本數;③區分類簇的邊界和非邊界樣本集,并分別確定樣本分布概率;④根據分布概率選取種子樣本,使用SMOTE算法生成新樣本。
2.1 數據清洗
為了防止過擬合和類別重疊問題出現的概率,應要過濾異常樣本進行數據清洗。本算法首先判斷信息決策系統DT的不平衡度,當不均衡度大于特定閾值t時在DT中使用近鄰法識別異常樣本;小于t時利用訓練One-class SVM模型來識別Kp, 并刪除Kp中KN識別為正常數據的樣本得到Kp=
近鄰法是通過統計樣本的k個最近樣本的類別個數n,如果k等于n,就判定樣本為異常樣本。
2.2 類簇過采樣數量
由于在樣本空間中每個類簇中的樣本分布各不相同,會造成類別內部分布不均衡,因此使用DBSCAN密度聚簇算法對正例樣本進行劃分,針對不同類簇的密度和邊界樣本的數量,自適應為其分配一定的權重。對于密度稀疏的類簇采樣較多的樣本以提高識別率,對邊界樣本數量多的類簇采樣較多的樣本以擴充樣本的空間分布。
定義6 類簇密度和采樣倍率:Kp=
(2)
過采樣倍率為歸一化類簇密度倒數,如式(3)所示
(3)
WD表明類簇的采樣數與類簇密度成負相關。
定義7 邊界樣本占比:類簇Xi?cluA(P) 的邊界樣本集borderk(Xi)={x|?x∈Xi,|KNNA,k(x)∩N|>k/2}。 邊界樣本占比表明正例類簇歸一化的邊界樣本比例,如式(4)所示
(4)
WB表明正例類簇歸一化的邊界樣本比例。
定義8 類簇權重:類簇Xi?cluA(P) 的權重為過采樣倍率和邊界樣本占比的加權和,如式(5)所示
Authorityk,λ(Xi)=λ×WBk(Xi)+(1-λ)×WDk(Xi)
(5)
式中:λ為調節因子。類簇權重Authorityk,λ(Xi) 綜合考慮類簇密度和邊界分布。當λ>0.5時,更關注邊界分布;當λ=0.5時,邊界樣本占比和密度分布的重要性相同。類簇權重函數綜合考慮了類簇密度和邊界分布情況,合理控制新樣本的分布,為新樣本選取安全區域。
合成正例樣本數量numsum,δ=(|N|-|P|)×δ。 其中δ∈[0,1] 為均衡化程度,控制合成正例樣本的數量。當δ值為1時,正例樣本數量與負例樣本數量相同。
每個類簇的過采樣數量計算如式(6)所示
numk,δ,λ(Xi)=Authorityk,λ(Xi)×numsum,δ
(6)
式中:Authorityk,λ(Xi) 控制不同類簇生成不同數量的樣本,不同的類簇根據上述公式合成不同數量的樣本。
2.3 分布概率生成與種子樣本選取
采用樣本的k個近鄰情況可將每個類簇分為邊界樣本集和非邊界樣本集,并分別計算集合中合成正例樣本的數量;然后根據樣本的相對密度自適應生成分布概率,并通過樣本的分布概率選取種子樣本;最后采用SMOTE算法進行樣本合成,以提高識別精度。分布概率大被選為種子樣本的幾率就大,保證了樣本分布的多樣性,重構了樣本的總體分布。
對于?Xi?cluA(P) 中borderk(Xi) 邊界種子數量計算如式(7)所示
(7)
Xi-borderk(Xi) 非邊界種子數量計算如式(8)所示
num_nobork,δ,λ(Xi)=numk,δ,λ(Xi)-num_bork,δ,λ(Xi)
(8)
?x∈P, 對于Kp和KN, 相對密度為類簇中正例樣本數與負例樣本數之比。相對密度表示了樣本的近鄰情況,當樣本的近鄰樣本中正例樣本數小于負例樣本數時,則樣本的相對密度小,反之相對密度大。計算如式(9)所示
(9)
其中為了避免樣本的k近鄰樣本中沒有負例樣本的情況,上述公式使正例樣本數與負例樣本數分別加1。
邊界樣本x∈borderk(Xi) 分布概率如式(10)所示
(10)
非邊界樣本x∈Xi-borderk(Xi) 分布概率如式(11)所示
(11)
樣本的分布概率決定了樣本被選為種子樣本的可能性。若一個樣本的分布概率越大,此樣本被選為種子樣本的幾率越大;反之,此樣本被選為種子樣本的幾率越小。具體過程如算法1所示。
算法1:P_SMOTE
輸入:正例集P,樣本集X,樣本個數M,分布概率pC,k, 近鄰數k
輸出:生成正例樣本集P′
(1)P′=? //生成樣本集
(2) fori=1 toMdo: //生成樣本個數
(3)xl=random.choice(X,pC,k) //根據分布概率選取樣本種子
(4)P′=P′∪SMOTE(P,xl,k) //生成樣本
(5) end for
(6) returnP′
2.4 LBMSD算法流程
LBMSD主要流程包括以下3個部分:①使用近鄰法和單類支持向量機進行數據清洗;②使用DBSCAN聚簇并計算每個類簇的密度和邊界樣本數量,自適應地生成樣本數量;③根據計算分布概率選取種子樣本并使用SMOTE算法生成新樣本。完整流程如算法2所示。
算法2:LBMSD
輸入:決策信息系統DT,近鄰個數k,樣本e鄰域中樣本數閾值φ,均衡化程度δ,類簇權重調節因子λ,均衡度閾值t
輸出:均衡化后樣本集
(1)Ptemp=? //新增正例集
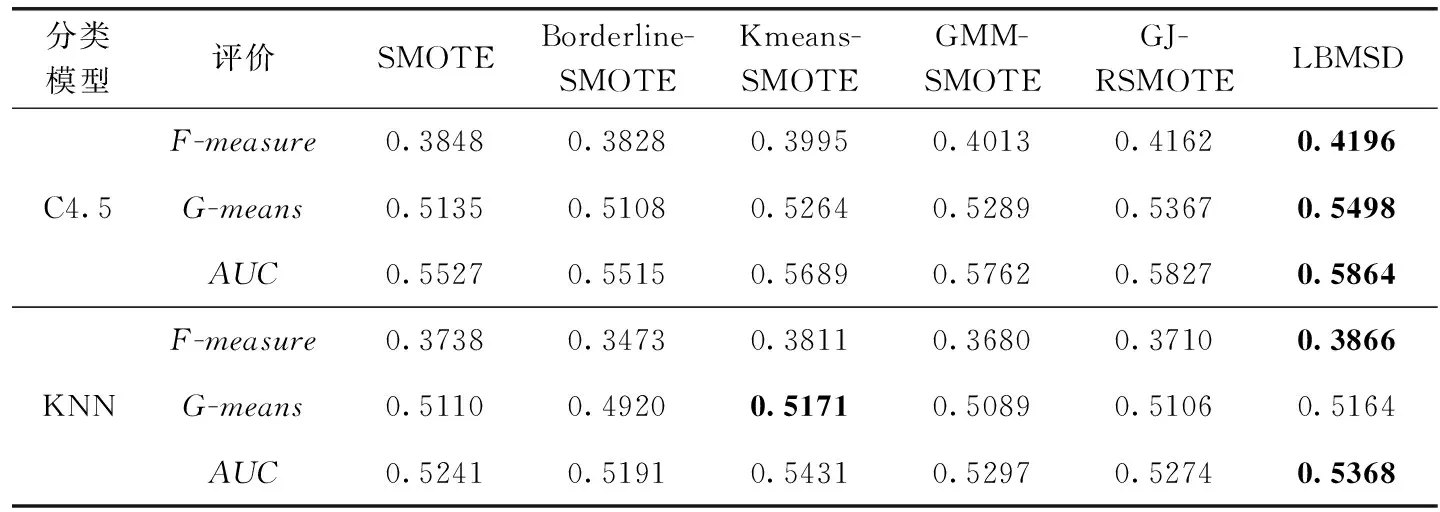
(2) if |N|/|P| (3) model=One-class SVM.fit(N) //訓練負例樣本 (4)P=P-model.predict(P) //刪除異常樣本 (5) end if (6) else then //不均衡度高于t (7) for ?x∈Nthen (8) ifKNNA,k(x)∩P==k//k近鄰法判定異常樣本 (9) deletex (10) end for (11)cluC(P)=DBSCAN.fit(P,φ) //正例樣本聚類 (12)numsum,δ=(|N|-|P|)×δ//總過采樣數 (13) for ?Xi?cluC(P) then //遍歷正例類簇 (14)X′=borderk(Xi) //邊界樣本集 (15)M′=num_bork,δ,λ(Xi) //邊界樣本集生成樣本數 (16)P′=P_SOMTE(P,X′,M′,bor_pA,k,k) //邊界新樣本集 (17)X″=Xi-borderk(Xi) //非邊界樣本集 (18)M″=num_nobork,δ,λ(Xi) //非邊界樣本集生成樣本數 (19)P″=P_SOMTE(P,X″,M″,nobor_pA,k,k) //非邊界新樣本集 (20)Ptemp=Ptemp∪P′∪P″ //新增正例樣本集 (21) end for (22) returnP∪N∪Ptemp//均衡化樣本集 對9組UCI數據集進行實驗(如表1所示),其中不平衡度為負例樣本與正例樣本的數量比值。 表1 數據集信息 本文分類器性能評價參數是基于表2所示的混淆矩陣定義所得到。 表2 混淆矩陣 分類模型評價的精確度(precision)、召回率(recall)計算如式(12)、式(13)所示 (12) (13) 精確度高表示負類判斷為正例的比例低,召回率高表示正例判斷為負例的比例低。 F-measure為召回率和精確率的調和均值,計算如式(14)所示 (14) G-mean為召回率和真負率TNR的幾何平均值,綜合了兩個類別的準確率,計算如式(15)所示 (15) ROC曲線分別以TPR、TNR為縱軸和橫軸,AUC是ROC曲線下的面積,評估分類模型性能。AUC的取值范圍為[0.5,1],AUC越接近1說明算法的真實性越高。本文采用F-measure、G-mean、AUC為分類模型的評價標準。 LBMSD參數包括近鄰k值和均衡化程度δ值。 (1)近鄰k值 實驗參數的設定在一定程度上影響算法的性能,k值的大小決定了類簇邊界樣本集的劃分,從而影響到均衡化效果。針對不同k值,采用KNN(k=5)分類器以及AUC評價指標進行實驗,結果見表3。實驗結果表明,對于不平衡度低的數據集,k為5時均衡化效果最優;對于不平衡度高的數據集,k為8時均衡化效果最優。由此可知,k的取值對不同數據集的分類性能的影響程度不同。 表3 不同k值使用KNN分類器的AUC值對比 (2)均衡化程度δ值 針對不同均衡化程度,設置均衡化程度值的大小從0.6到1,采用KNN分類模型及其AUC評價進行實驗(如表4所示)。實驗結果表明,對于數據集不平衡度較低時,δ值為1時分類器的性能表現較好;對于數據集不平衡度較高時,δ小于1時分類器的性能表現較好。實質上,樣本類別均衡化是重構正例樣本的合理分布,使本該不同類別有些差異的樣本均等化后,反而不符合原有分布規律。樣本類別不均衡也是客觀事實,均衡化也不可“矯枉過正”,導致原有類別分布仍然不合理,所以在均衡化過程中要分析數據中正例樣本與負例樣本的分布,根據樣本的特性合理地選擇均衡度。 表4 不同均衡化程度使用KNN分類器的AUC值對比 采用SMOTE、Borderline-SMOTE、Kmeans-SMOTE、GMM-SMOTE、GJ-RSMOTE和LBMSD進行對比實驗。設置樣本鄰域k為6,均衡度為1,DBSCAN半徑e為1,最小包含點數φ為5,不平衡度閾值t為6。采用C4.5,KNN(k=5)分類模型進行五折交叉驗證,使用F-mea-sure、G-mean、AUC評價指標。實驗結果如表5至表10所示。從實驗結果分析,達到均衡度為1時,LBMSD都可以取得較好效果,尤其原始數據集均衡度很差時,如Page、Yeast-02579,LBMSD均衡化效果更加明顯。LBMSD綜合考慮了分布邊界清晰化、不同類簇的分布,有效提高了識別精度。 表5 不同算法使用C4.5分類器的Kmeans-SMOTE、F-measure值對比 表6 不同算法使用C4.5分類器的G-mean值對比 表8 不同算法使用KNN分類器的F-measure值對比 表9 不同算法使用KNN分類器的G-mean值對比 表10 不同算法使用KNN分類器的AUC值對比 隨著計算機技術的快速發展,在人們生產生活中能源變成一種必不可少的物質。雖然太陽能、風能等新能源技術越來越成熟,但是像石油、天然氣等傳統能源的儲備也是不可或缺的。對地震相分析并進行巖性識別是油氣勘探認識地層構造、儲層性質的重要內容[14]。巖性信息能夠反映出油氣儲存位置以及流體特征,在地層儲層預測和油氣勘探中具有重要作用。由于在同一區域的地層數據反映了同一個巖性信息,所以可以根據同一區域的巖性信息來預測這一地區的儲油情況,極大地減少了人力物力資源。 根據地層中巖石的成分、顆粒大小、結構、孔隙度等參數表征可以把地層分為不同的巖性[15]。巖性作為地層巖石的主要特征,可將巖石劃分為砂巖、泥巖和其它巖性。巖性不同,構成顆粒大小不同,孔隙度也不同,因此儲存油氣的能力也不同。砂巖的特點是強度低,顆粒粗,吸水率高,所以油氣等資源易存儲于孔隙度相對大的砂巖地層中[16]。在對地震相巖性識別研究時,主要關注點是可以儲存油氣的砂巖地層,然而砂巖在地層中所占比例很少,造成數據的類別不均衡問題。當機器學習算法預測巖性時可能會導致識別精度不理想,所以在地震相巖性識別之前對數據進行均衡化處理尤為重要。 地震數據來自華北油田某地區,共1956道,501個采樣點,采樣率為2 ms,構成數據集(如表11所示)。對于地震數據,當均衡度設置為1時,識別精度最高(如表12所示)。采用C4.5和KNN分類模型分別進行十折交叉驗證,使用F-measure、G-mean、AUC作為算法評價指標,實驗結果見表13。從實驗結果分析可知,與其它過采樣算法相比,LBMSD過采樣算法在多個評價指標中表現優異,有效提升了分類模型的性能。 表11 地震相數據集 表12 不同均衡度對應的KNN識別效果 表13 地震相巖性識別效果 樣本類別均衡化核心是合理控制新生成樣本合理的數量及分布,并真實反映了樣本的分布。LBMSD均衡化主要包含4個過程:通過單分類支持向量機和近鄰法刪除噪聲樣本,優化正例樣本分布邊界;密度聚類正例樣本,通過每個類簇的密度和邊界樣本數量,確定每個類簇需要生成的樣本數;通過每個類簇邊界和非邊界分割,并確定各自分布的生成樣本數;根據樣本分布概率確定生成的樣本數并選取種子樣本進行樣本合成。樣本類別均衡化不同于樣本類別均等化,下一步工作是研究自動確定均衡度,獲得最佳均衡化效果。3 實驗結果與分析
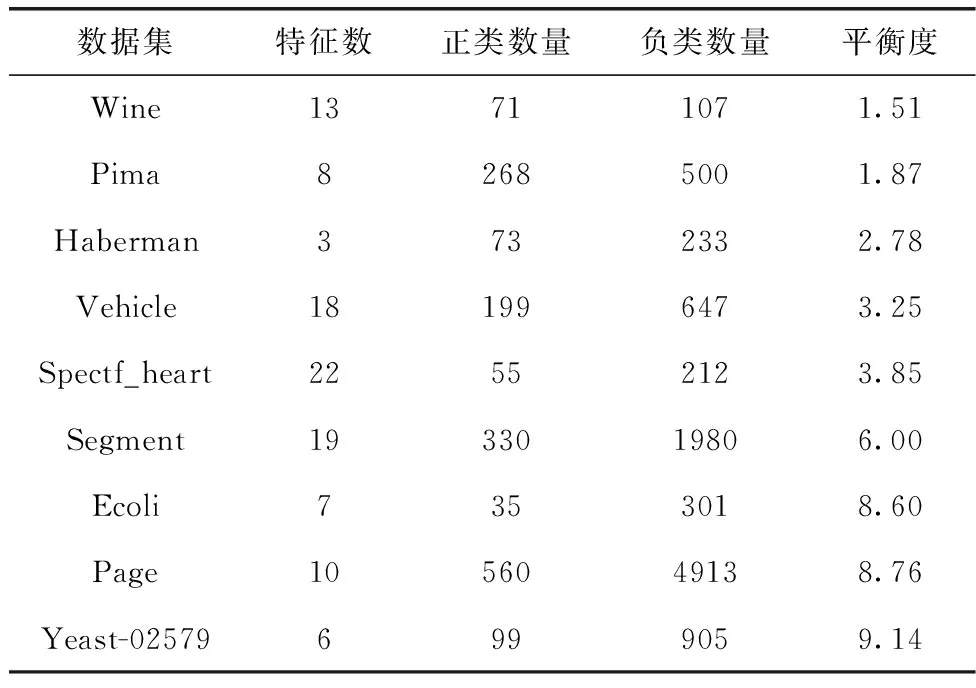
3.1 數據集與評價指標

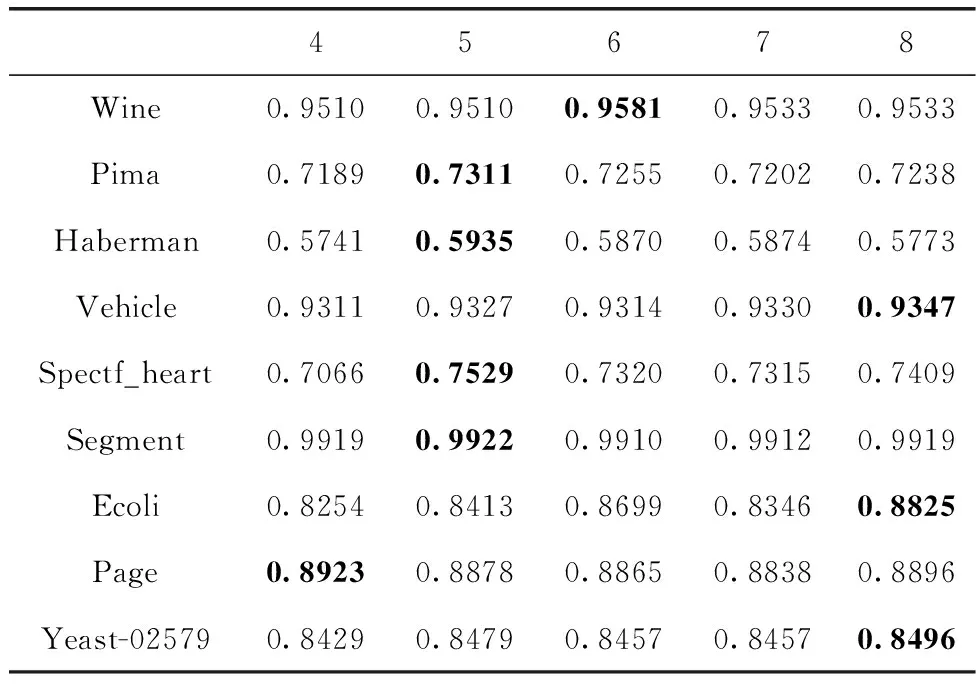
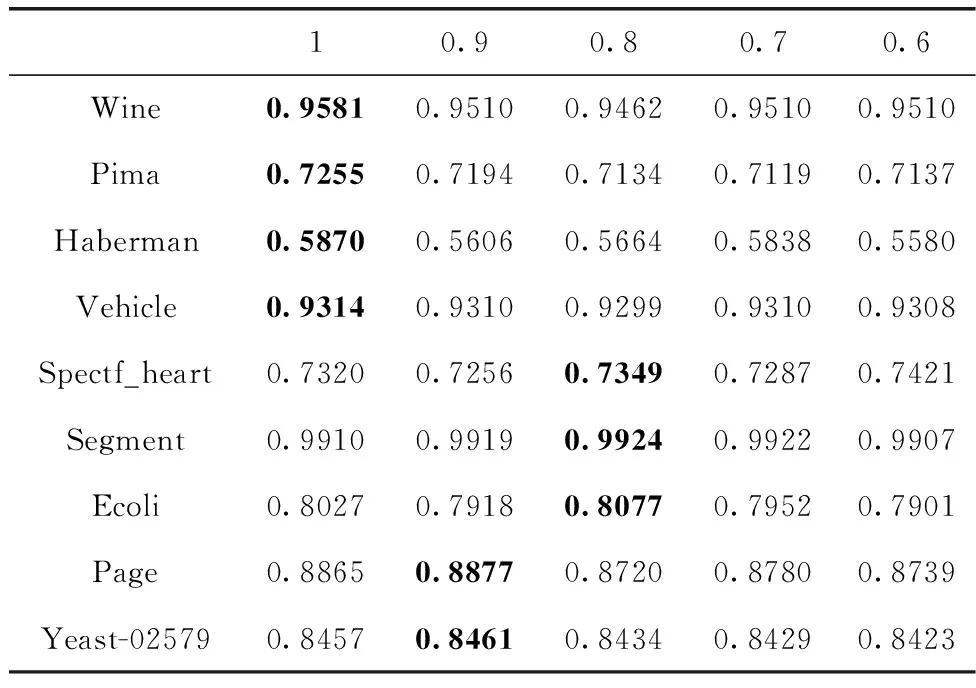
3.2 實驗參數設定
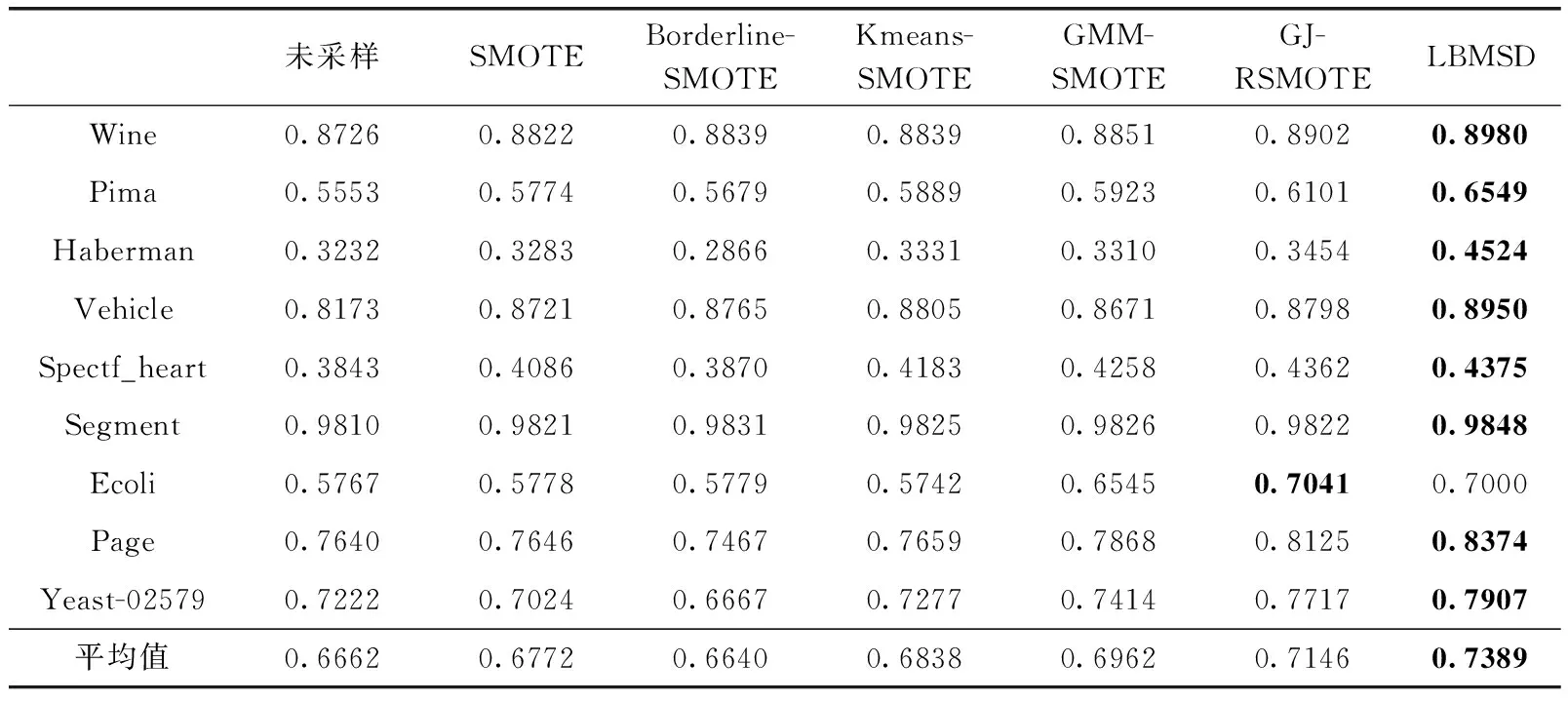
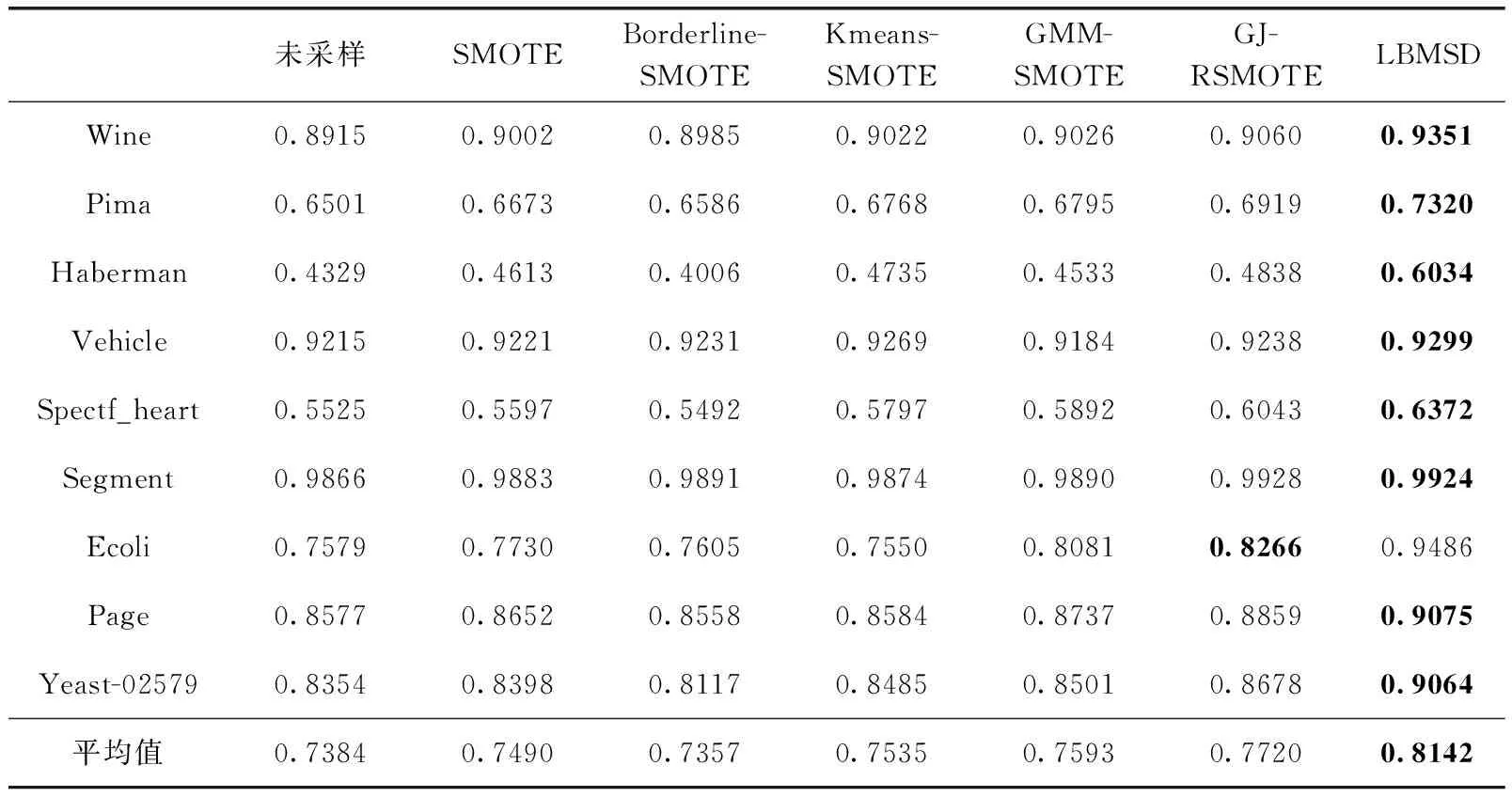
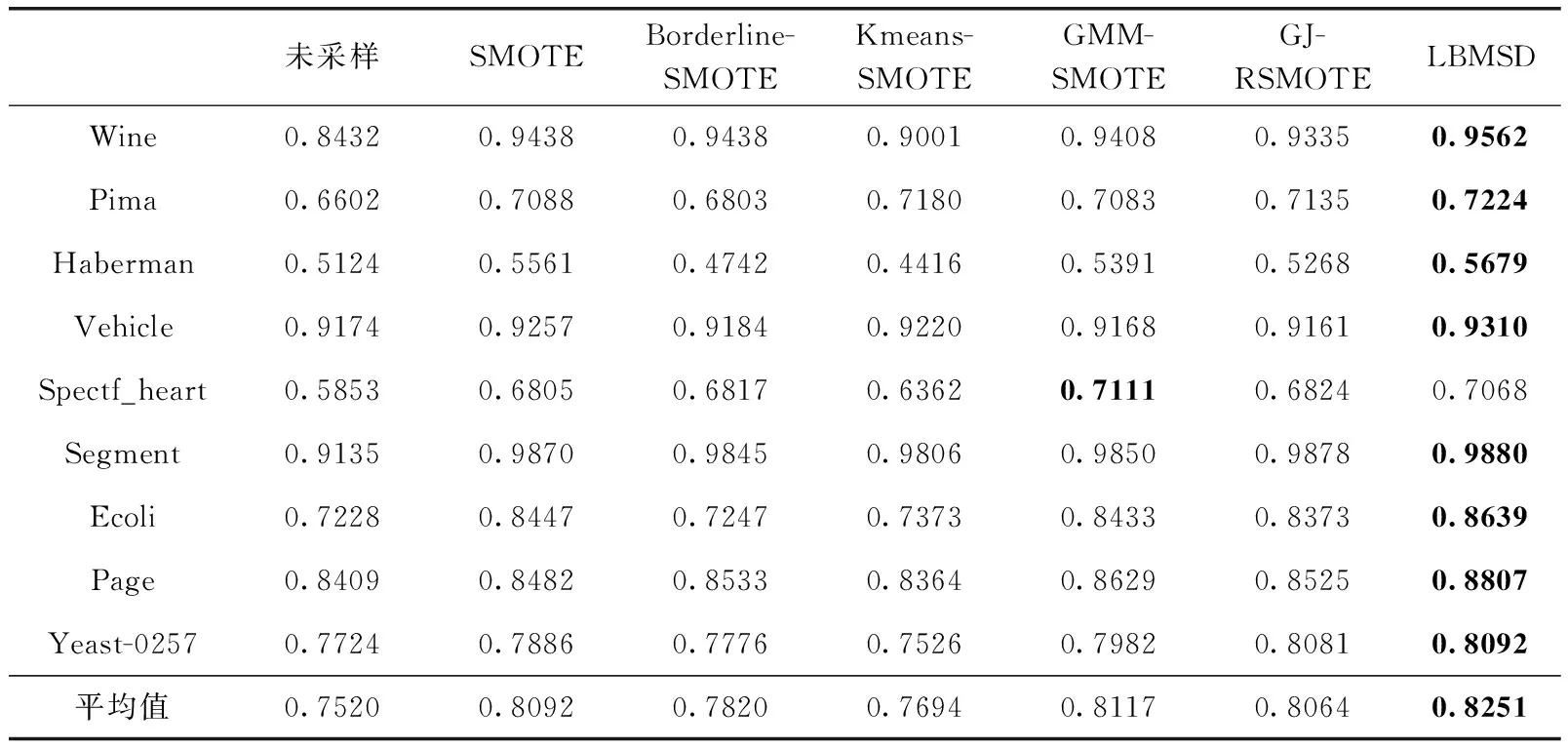
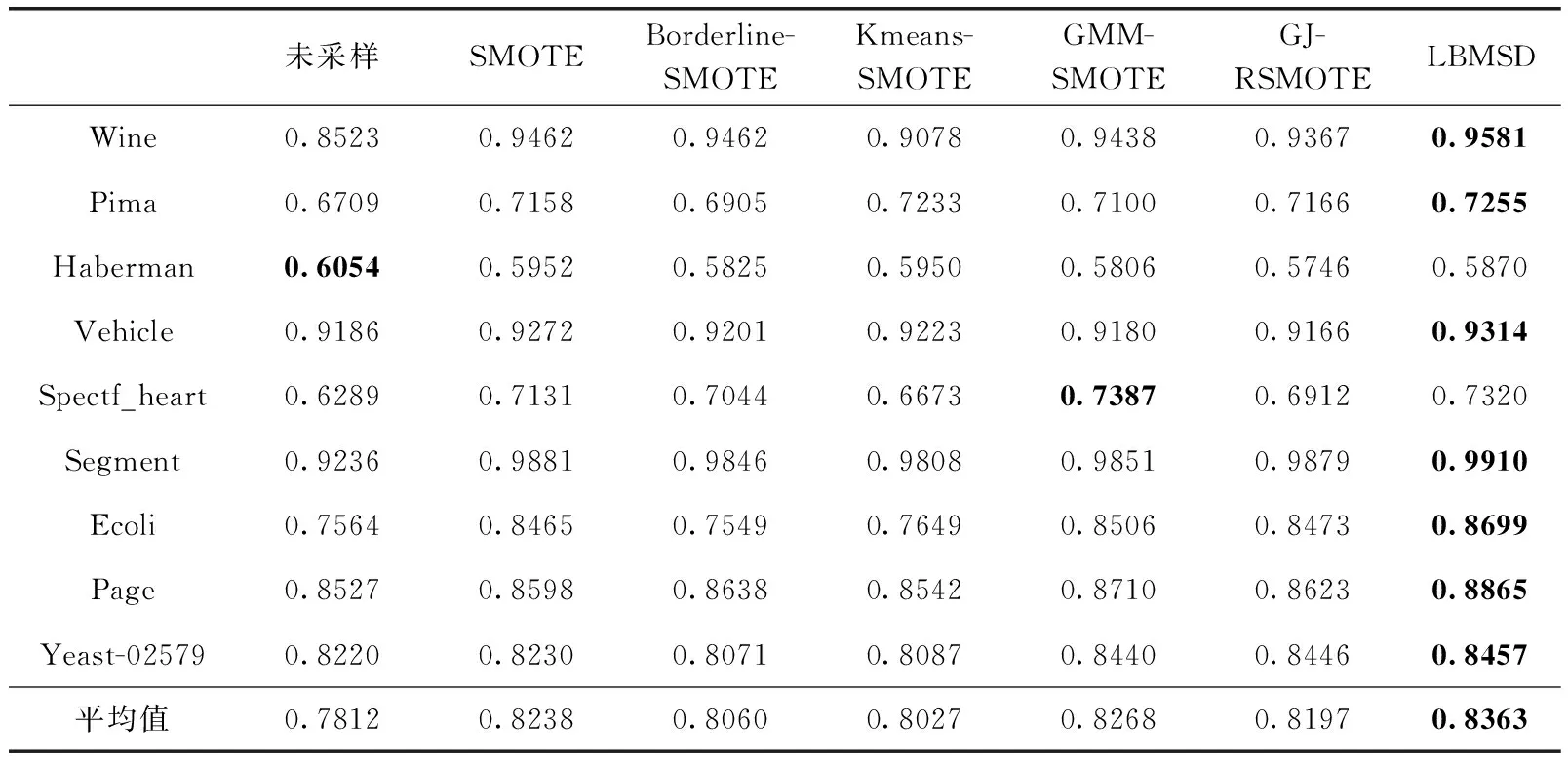
3.3 不同均衡化方法實驗對比

3.4 地震相巖性識別應用


4 結束語
