基于CNN-DE-SVM的滾動軸承故障診斷研究
2023-10-12 10:41:16梁川陳雪軍
微型電腦應用 2023年9期
梁川, 陳雪軍
(華潤江中制藥集團有限責任公司,江西,南昌 330096)
0 引言
隨著科學技術的不斷進步,人類社會的生產力水平也發展到了一個新的階段。現代工業體系相比傳統工業體系有著更高的生產效率,但高度的集成化也導致現代工業體系中每一件機械甚至每一個部件都與整體的生產息息相關。因此,為了保證工業系統的正常運作,故障診斷技術已然成為現代工業體系中的關鍵組成部分[1]。
滾動軸承作為工業系統中使用最為廣泛的機械部件之一,一旦在運行過程中出現故障,輕則影響自身所在的機械設備,重則傳導至整個生產線。因此,對滾動軸承開展故障診斷研究有重要的工程意義。
張柯等[2]提出了一種基于多模態注意力機制的卷積神經網絡,并利用小波變換對原始數據進行處理,結果表明此模型可以有效地識別變工況下的各類軸承故障,在實際應用中也取得了較好的結果。LIU等[3]提出了一種改進的傅里葉變化,并利用此方法結合多尺度排列熵提取故障特征,最后利用BP神經網絡實現故障狀態的識別。
滾動軸承故障大致歸類為內圈、外圈、滾動體和保持架四大類典型故障。因此,本文基于滾動軸承的典型故障開展研究,以公開滾動軸承數據集為對象,使用本文所提出的故障診斷模型進行驗證,從而表明此模型具有推廣企業滾動軸承自測數據集的潛力。
文獻[2-3]給出的研究都是以人工智能算法為基礎的故障診斷研究,這是目前的主流方法,但上述故障診斷模型在特征提取能力或診斷精度上都存在一定的短板。首先,特征提取是故障診斷中的關鍵步驟,決定了診斷精度的上限。現有診斷模型大多都是利用信號分析方法進行特征提取,如短時傅里葉變化、功率譜、小波包變換等[4]。但這些信號分析方法都有一定的局限性,如短時傅里葉變換不適用于頻率變化較大的信號、小波包變換需要預先選擇基函數等問題,從而影響整個診斷模型的適用性。其次,人工智能算法如支持向量機、隨機森林和聚類算法等,都包含需要調節的參數。這些超參數的設置如果不恰當,將會極大地降低模型的性能。如果利用人工手動調節這些參數,需要花費更多的人力成本,同時也降低了模型的魯棒性。
針對上述問題,本文提出一種基于CNN-DE-SVM的故障診斷模型。首先,利用CNN強大的特征提取能力,從原始的軸承數據中提取出抽象特征,再將此特征輸入DE-SVM故障診斷模型中。其次,利用差分進化算法自適應調節SVM中關鍵的2個參數懲罰因子C和核函數參數γ,從而使得SVM擁有更高的診斷精度。最后,設置一組對比實驗,驗證CNN的特征提取能力與DE算法的優化效果,從而表明所提出的CNN-DE-SVM模型擁有更高的工程應用價值,擺脫了現有模型需要人工參與的缺點,在節約人力成本的同時提高了模型的診斷精度。
1 卷積神經網絡
卷積神經網絡是目前使用最為廣泛的神經網絡模型之一,在姿態識別和圖像分析等領域都有應用[5-6]。CNN的優異性能主要得益于其強大的特征提取能力,原始數據輸入CNN后,會經過反復的卷積和池化操作,將原本可解釋的原始數據轉換為不可解釋的抽象特征。雖然人工無法識別抽象特征所具有的意義,但CNN的全連接層可以從中獲取特征與標簽所存在的關系,進而建立分類模型實現對應的功能。但全連接層的分類能力較弱,因此本文將卷積層和池化層所提取出的抽象特征輸入SVM中,從而實現故障診斷的功能。
卷積神經網絡的核心就是卷積層,由多個卷積核組成,通過卷積運算,卷積核會得到新的特征圖,然后進行非線性計算[7]。在進行卷積操作之前,CNN首先會將數據的結構進行重組。本文使用二維CNN模型進行特征提取,因此需要將原始數據重構為數據矩陣的形式,再利用卷積核掃過這個數據矩陣,進行乘法運算后得到特征圖并通過激活函數激活輸出至下一層[8],數學公式如下:
(1)
式(1)中,?為卷積運算,xi為輸入卷積核的特征向量,ki為卷積核的權值,bi為卷積核對應的偏置,Mi為卷積層的輸出,i為對應的層數。計算出來的特征圖還需要經過非線性激活,本文選用Sigmoid函數進行激活。
通過卷積層得到的特征圖再輸入池化層中,用于降低數據維度,同時也能減少過擬合的風險。池化層的具體降維方法有許多,本文使用最大值池化法,即從所框定的范圍內選擇數值最大的特征,數學表達式如下:
R=maxMi
(2)
式(2)中,max為池化運算,R為池化層的輸出。
2 DE-SVM模型
2.1 SVM基本原理
支持向量機是在統計學的基礎上所形成的一種人工智能算法,本質上是一種二分類方法,利用超平面使兩類樣本分開。它的主要優勢表現在收斂速度和性能上,在小樣本、高維度的情況下仍具有較強的泛化能力。
為了使得此超平面有最好的魯棒性,SVM需要樣本中距離超平面最近的向量與超平面的距離最遠。如此一來便可以最大程度上保證超平面設置的合理性。懲罰因子C和核函數參數γ對SVM最終的分類結果有著直接的影響。因此,合理且高效地確定出它們的取值對于提高SVM的工程應用價值有著關鍵的作用。
2.2 DE-SVM模型的構建
差分進化算法是一種進化算法,最早是由STORN等[9]于20世紀90年代所提出的。與其他類似的算法相比,DE算法最顯著的特點是控制參數較少,僅有兩個。因此,算法的可操控性強,且尋優能力優異。本文利用DE算法尋優SVM參數的取值,其具體的模型構造流程如下。
(1) 初始化種群
DE算法的第一步為構造初始化種群,即在搜索空間中隨機生成一系列的初始個體向量,可表示為
(3)
式(3)中,qi代表初始種群中的第i個個體向量,個體向量的維度為2,由SVM中的超參數C和γ所組成。Uc和Vc為懲罰因子取值范圍的上限和下限,Uγ和Vγ為核函數參數取值范圍的上限和下限。文獻[10]指出取值范圍在(0,100)的區間內為宜,因此本文設置Uc=Uγ=100,Vc=Vγ=0.01。rand(0,1)為隨機生成的0至1上的實數。本文設置初始種群中個體向量的個數為30,即依據式(4)隨機生成30個個體向量。
(2) 變異
變異操作是DE算法中的核心步驟,可以讓個體向量在保證一定的多樣性的同時,向著一個或多個近似最優點收斂。本文所使用的變異算子如下:
vi,g=q1,g+K(qbest,g-q1,g)+F(q2,g-q3,g)
(4)
式(4)中,q1,g、q2,g和q3,g為第g代種群中互不相同的3個個體向量,qbest,g為第g代種群中適應度值最好的個體向量,在本文中為使得SVM診斷精度最高的個體向量,vi,g為變異向量,K為隨機生成的0至1上的隨機數,F為縮放因子,作用是控制種群的進化速度,其數值一般不超過1,本文參考文獻[10]設置F=0.8。
(3) 交叉
交叉操作是DE算法的第三步,其作用是增加種群的多樣性。本文所選用交叉策略的數學表示式為
(5)
式(5)中,oi,k,g代表實驗向量,i、k和g分別代表向量的個數、向量的維度和進化代數,個體向量q和變異向量v同理,CR代表交叉概率,本文依據文獻[10]設置CR=0.6。
(4) 選擇
DE算法的選擇策略在本質上屬于一種貪婪學習,即從實驗向量和個體向量中選擇最優的一個進入到下一代,其數學表達式為
(6)
式(6)中,g( )代表適應度函數值。在本文中適應度函數為1減去向量中的C和γ代入SVM模型中所取得的診斷精度。
3 故障診斷實驗
3.1 數據來源
所選用的滾動軸承數據來自公開大學滾動軸承數據中心[11],以此數據集為基礎驗證所提故障診斷模型的有效性,進而在一定程度上表明此模型推廣應用至某企業生產基地滾動軸承自測數據集時的可行性。某企業生產基地中監測的機械設備有電機和齒輪箱等,基本都包含滾動軸承。滾動軸承在實際使用過程中所發生的典型故障有內圈剝落、外圈剝落、滾動體磨損等,因此本文同樣選用公開大學滾動軸承數據集中的內圈故障、外圈故障、滾動體故障等數據開展故障診斷研究。具體所選用的數據如表1所示。
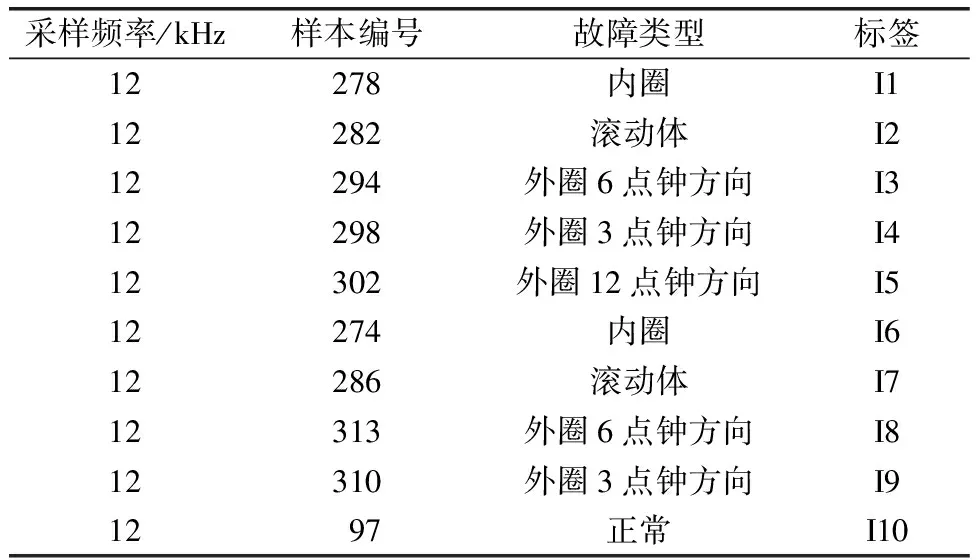
表1 數據介紹
本文使用的編程框架為TensorFlow2.0,計算機硬件配置為8 GB的運行內存,CPU型號為i5-4300U。
3.2 CNN特征提取
利用二維CNN提取滾動軸承振動數據的特征。以I1內圈故障的樣本為例,該樣本中一共包含121 535個連續采樣的樣本,選用其中前51 200個樣本,將其重構為16×16的數據矩陣,一共可以得到200個16×16的數據矩陣。再將這200個數據矩陣輸入CNN中進行特征提取,示意圖如圖1所示。
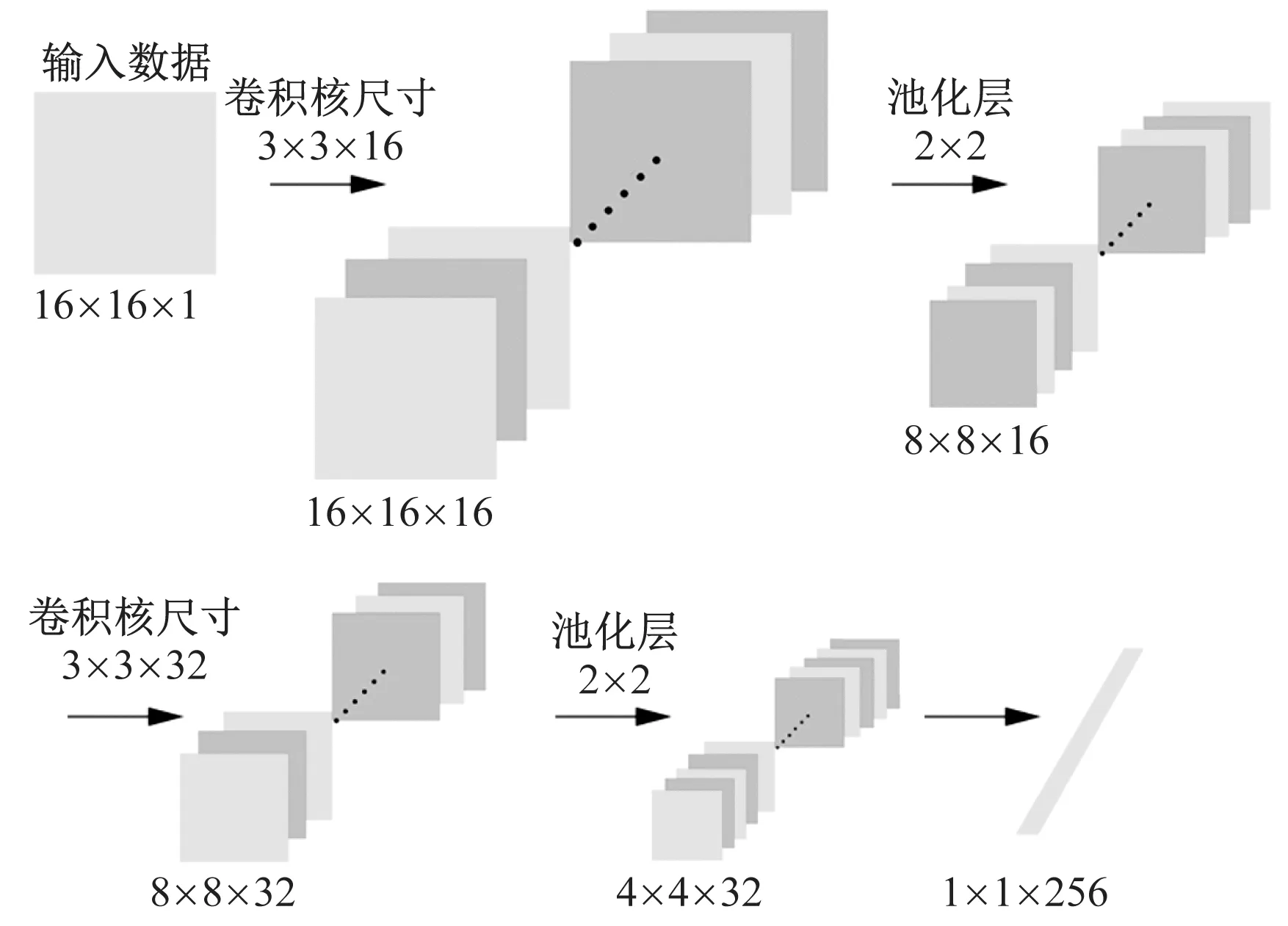
圖1 CNN特征提取流程
觀察圖1,以任意1個數據矩陣為例,其結構為16×16×1,首先經過16個3×3的卷積核,從而得到16×16×16的卷積特征圖;再經過2×2的最大值池化層,數據結構變為8×8×16;再經過32個3×3的卷積核,數據結構變為8×8×32;再經過2×2的最大值池化層,數據結構變為4×4×32;最后只經過一層全連接層,數據結構變為1×1×256,即為CNN所提取出的特征。
重復上述步驟,將每一類軸承數據都輸入CNN,最后一共可以得到2000組樣本,每一個樣本所包含特征個數為256,即2000×256的輸入矩陣。對于SVM等機器學習模型,256個特征過多,容易導致算法模型出現過擬合的情況。因此,使用主成分分析法(PCA)[12]對其進行降維。依據PCA的基本原理并計算出數據矩陣主要的特征值,最后將其降至三維。
為了直觀地體現CNN結合PCA特征提取的能力,同時考慮到過多的特征在單一視角下容易出現重疊,僅選擇4類數據并將其可視化,如圖2所示。
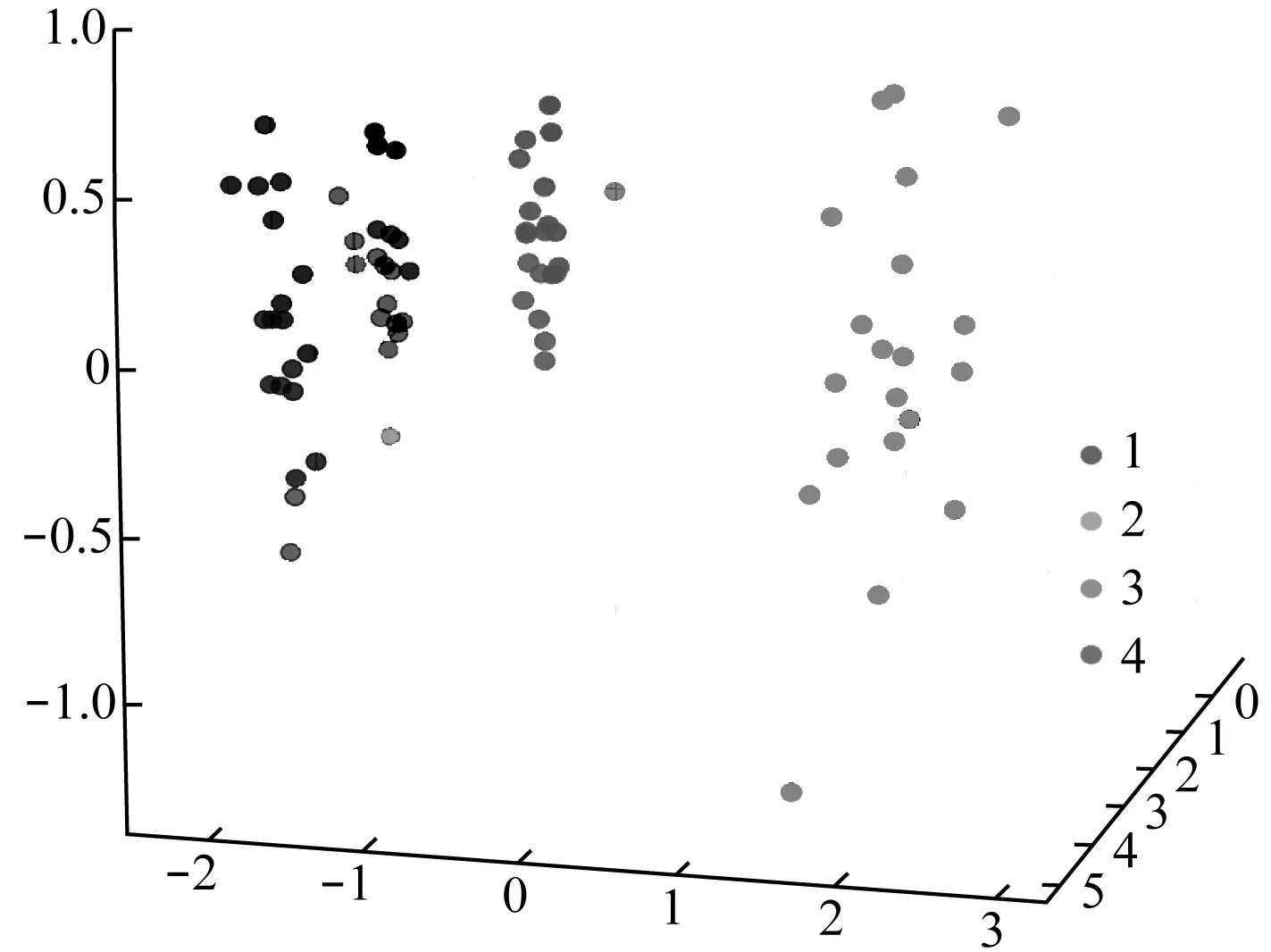
圖2 特征提取效果
觀察圖2可知,4類不同的數據相互分隔,表明特征工程有效地將振動數據與標簽的抽象關系提取出來了,有助于提高算法模型的精度上限。
原始數據經過CNN結合PCA的特征提取之后,隨機劃分其中的70%作為訓練數據,30%作為測試數據,再輸入DE-SVM模型中實現故障診斷的功能。
3.3 故障診斷實驗
設置DE算法的迭代次數為50,設置初始種群中所包含的個體向量的個數為30。DE-SVM優化曲線如圖3所示。

圖3 DE-SVM優化曲線
從圖3可以觀察到,SVM經過優化之后,最后的精度可以達到99.80%。
為了進一步表明本文所提故障診斷模型的有效性,設置一組算法對比實驗。
在特征提取方面,使用小波包分解(WPD)與CNN進行對比。在診斷模型方面,使用未經優化的SVM進行對比。對比結果如表2所示。

表2 診斷結果對比
分析表2可知:由于WPD在特征提取能力上存在一定的不足,從而導致故障診斷模型的精度上限較低,利用DE-SVM模型只能取得91.32%的診斷精度,使用標準SVM則只能取得85.78%的精度;利用CNN進行特征提取,即便是標準SVM模型也能取得96.57%的診斷精度;而利用DE-SVM進行故障診斷則能取得上述4類算法的最高精度99.80%。這進一步表明了CNN特征提取的有效性和DE算法的優化性能。同時,上述分析也表明CNN-DE-SVM模型具有推廣至華潤江中藥谷生產基地滾動軸承自測數據集的應用潛力。
4 總結
本文以公開軸承數據集為研究對象,使用CNN結合PCA的特征提取方法從振動數據中提取出更加有效的抽象特征,再將此特征輸入DE-SVM的故障診斷模型當中,進而實現滾動軸承振動數據從特征提取直至故障診斷的全過程智能化,無須進行繁瑣的信號分析以及人工參數調優。最后,通過算法對比表明本文所提出的CNN-DE-SVM故障診斷模型還擁有更高的診斷精度。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年23期)2014-02-27 14:19:15
