基于卷積神經網絡的跨站腳本攻擊檢測模型*
2023-10-10 02:48:26胡乙丹
艦船電子工程 2023年6期
胡乙丹
(南京理工大學自動化學院 南京 210018)
1 引言
跨站腳本攻擊已成為各種網站的主要攻擊媒介之一。根據開放式Web 應用程序安全項目(Open Web Application Security Project,OWASP)在2017年與2021年進行的統計調查中顯示,跨站腳本攻擊一直位列前十名內。跨站腳本攻擊仍然是目前危害比較大的網絡攻擊之一,現在的注入漏洞省略了單純的SQL 注入,范圍變得更廣,在2021年的調查中,注入漏洞不僅僅指單純的SQL 注入,還包括文件注入、XML 注入、命令注入以及類似于XSS這樣的前端代碼注入[1]。
如何提高對XSS攻擊檢測的效率與準確率,已成為目前信息安全領域的研究熱點。為避免XSS對Web應用的攻擊產生的危害,需要對XSS攻擊進行定期、有效的檢測,一旦發現了XSS 攻擊就立即修復相應的漏洞。因此,許多專家與學者提出了面向XSS攻擊的檢測方法,這些方法大部分都是檢測網站代碼,其所用方式主要有靜態測試[2]、動態測試[3]與機器學習的方法[4~6]。傳統的這三種XSS 攻擊檢測方法在應對多樣化的攻擊載荷時,效果可能不盡人意,像機器學習進行漏洞檢測分析時也會遇到模型跨項目、數據集難以獲取的問題[7~8],因此,本文的研究對象是Web 安全中常見的一種攻擊—XSS 攻擊。文中借鑒人工智能領域的深度學習技術與自然語言處理技術,構建面向XSS攻擊的一維卷積神經網絡檢測模型,克服已有檢測方法效率與準確率不高的問題,從而快速、準確地發現Web 應用中潛在的XSS攻擊,具有較好的應用價值。
2 相關理論
2.1 一維卷積神經網絡
一維卷積神經網絡(one-dimensional convolutional neural networks,1D-CNN)是深度神經網絡里的一種常用算法[9~10],它是帶標簽的監督學習算法,通常用于類似列表、元祖、字符串這樣的序列類數據處理,經過對輸入數據進行一系列堆疊的卷積、池化操作,實現輸入特征的精確提取,從而確保數據分類的質量,常見的一種1D-CNN 基本結構如圖1所示。
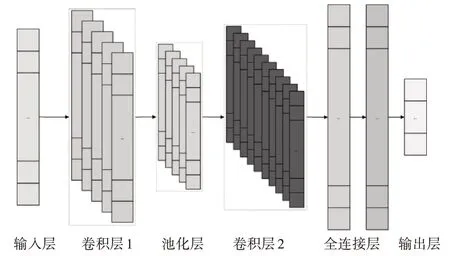
圖1 一維卷積神經網絡基本結構
1)輸入層:輸入一維向量input={inputi|i=1,2,…,k}。其中,input為一維特征序列,這里的k代表特征數。
2)卷積層1:主要作用在于提取特征,并獲得相應的特征序列。假設Sl是第l個卷積層的特征序列,如果l=1,則Sl=input,是第l個卷積層的第j個特征序列,這里的f(·)代表激勵函數,將其設置成ReLU函數,那么的產生如下所示:
3)池化層:作用在于信息的降維,這里是對卷積層1 的輸出特征序列進行降維操作,消除其冗余特征。設是第l個池化層的第j個特征序列,那么每個輸出特征序列對應相應的加性偏置和乘性偏置,最后的的計算方法如下所示:
其中,MaxPool1d(·)是最大池化函數,池化核大小為2,步長為2;如果第l-1 層特征序列中的特征數為Fs,則經池化層降維處理后的對應的特征數。
4)卷積層2:進一步的特征提取處理,提取從上一層傳遞過來的池化層輸出特征序列,獲得相應的特征序列,其計算方法如式(1)所示,其對應的特征數計算為。
5)全連接層:將之前的特征信息綜合起來,這里體現在對輸入的卷積層2所對應的特征序列映射為多個獨立的特征。設全連接層第D1層的輸出函數為,那么第D2層的輸出為
6)輸出層:通過分類函數Softmax()得到類別的預測概率P(x),其中0 <P(x)<1,且,即:
其中,x為類別數,outputx是全連接層的分類類別的對應值,即output=[output1,output2,…,outputk]T
本文的損失函數Loss 采用的是多類別交叉熵損失函數對模型的預測性能進行衡量。這里設目標的實際概率分布函數為Q(x),類別的預測概率P(x),那么兩者間的損失值Loss(P,Q)即:
2.2 基于Word2Vec的詞向量
Word2Vec[11~12]是Google 公司設計的一款將自然語言轉換為計算機能夠理解特征向量的工具。其主要作用在于將單詞轉換成向量形式,并區分出感情色彩、非同義詞與同義詞。Word2Vec 通常關注文本上下文信息,在語料數據與大量文本中通過無監督學習方法來生成語義信息[13]。Word2Vec 的實現方式主要包括Skip-gram與CBOW兩種[14]。本文使用Skip-gram 模型將詞轉換為相應的詞向量。
設模型的輸出與隱藏層權值為一個V×N的矩陣W,W中每行為一個N維向量,那么詞典V里的第i個特征詞wi在W中記為νwi,輸入層輸入x∈Rν,若x≠x',xk'=0,xk=1,那么隱藏層表示為
記輸出層有C個V維向量,則wc,j代表第c個向量的第j個特征詞,而uc,j對應隱藏層到輸出層的第j個單元的線性和,yc,j對應經過softmax操作后的概率值。目標函數定義為如下:
隱藏層與輸出層間共享同樣的權值W,可以得到:
其中,ν'wj表示特征詞wj對應的輸出向量。
目標函數此時可以更新為
如果語料庫vocab 與文檔di={w1,w2,…,wi}經Word2Vec 訓練語料后,得到的單詞詞向量可以表示為
式中,Word2Vec(t)為詞匯t所對應的Word2Vec詞向量。
3 一維卷積神經網絡的跨站腳本攻擊檢測模型
3.1 模型框架
圖2 是本文基于卷積神經網絡檢測XSS 攻擊腳本的整體模型框架結構。通過卷積神經網絡模型最終將網頁中的數據分成兩類:non-XSS(正常腳本)與XSS(攻擊腳本)。主要分為以下幾個步驟實現:數據采集,特征提取,構建模型,訓練卷積神經網絡進行腳本的分類。
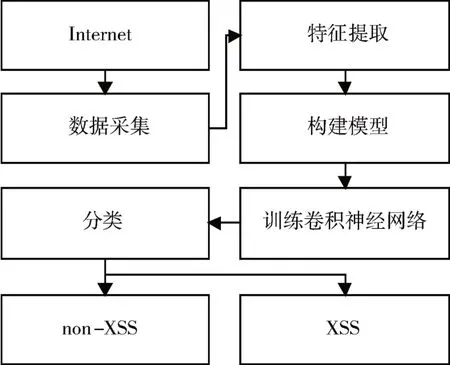
圖2 系統模型框架
3.2 特征提取
特征提取是本文模型的前置步驟,對最終結果起著決定性的作用。其主要目的在于將采集到的帶有惡意和正常的URL 頁面數據轉為向量形式建立具有正反樣本的數據集。考慮到跨站腳本攻擊的一些特殊性,采集到的數據通常也是類似于字符串這樣的文本形式,需要采用自然語言的手段對其進行特征提取處理,提取過程分為以下三個步驟:解碼與范化、分詞與向量化,如圖3所示。
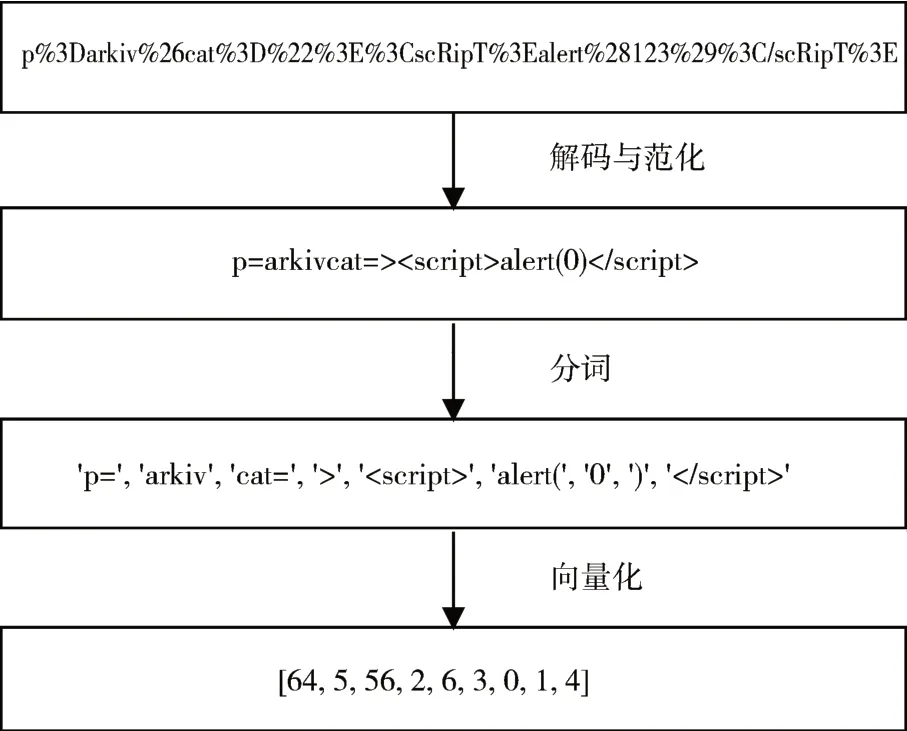
圖3 特征提取過程
3.3 一維卷積神經網絡模型
本文所使用的一維卷積神經網絡模型所設計的結構如圖4所示,左側為層的名字,右側是此層的輸入與輸出的數據形狀。我們可以看出輸入層是一個batch為20,長度為532,維度為10的三維張量,緊接著是第一個卷積層對其進行了卷積操作,得到了類似圖像處理中的64 個feature map。這里的64 是指卷積層有64 個卷積核,即有64 套參數,每個卷積核都能夠將原始輸入通過卷積得到一個feature map,64 個卷積核對應64 個feature map。這里的卷積核是可以自由設定的,因為它是一個超參數。在經過了第一個卷積層操作后,再進行了第二次卷積操作,其卷積核個數同樣為64,然后進行了最大池化的下采樣操作,將長度降為原來的一半。再接著就是比例為0.5的Dropout操作,其目的在于斷開訓練時的一些神經元,防止過擬合操作。后面的操作類似之前的卷積層到Dropout層一系列的結構又循環了一次,不同在于使用的卷積核由64 變為了128 個。通過兩次卷積-池化-Dropout 操作后,再連接一個平化層以及兩個全連接層,實現這個批次的分類。
4 實驗環境與結果分析
4.1 數據集
為了讓數據集更加的合理、全面,通過Scrapy框架對數據進行爬取,構建原始正常腳本數據集與XSS 攻擊數據集。正常數據來源于各網絡平臺的5000 條正常網絡請求,如Dmoz 網站。攻擊數據來源于Xssed網站的16974條惡意攻擊樣本,Xssed是最大的在線Xss攻擊網站。最終共有21974條數據作為XSS數據集。實驗中,將正常數據與惡意樣本數據放在一起,從樣本里以6:4 的比例隨機選擇訓練集與測試集。負樣本為正常數據集,標簽用0 表示,而正樣本表示惡意樣本,標簽用1表示。
4.2 實驗設置
本文的實驗環境是在聯想R9000P 筆記本的Windows 11 系統中,處理器為AMD Ryzen 7 5800H with Radeon Graphics 3.2GHz,內存為32G,顯卡為NVIDIA GeForce RTX 3070 Laptop GPU,使用Python語言在Keras框架上實現。
4.3 評估標準
本文模型的正類為XSS注入樣本,負類為正常樣本,其分類性能評估標準分別為:召回率、準確率、精確率與F1值。詳細的計算公式如下:
其中,TP 為正類樣本預測為正類的數量,即把XSS攻擊腳本預測為XSS 攻擊的數量;TN 為負類樣本預測為負類的數量,即把正常腳本判定為正常類別的數量;FP 為負類樣本預測為正類的數量,即把正常腳本判定為XSS 攻擊的數量;FN 為正類樣本預測為負類的數量,即把XSS 攻擊腳本預測為正常類別的數量。
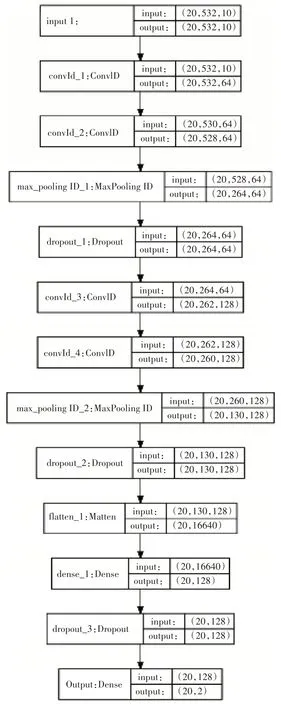
圖4 卷積神經網絡結構圖
4.4 結果分析
4.4.1 模型訓練
卷積神經網絡的輸入向量維度通常是固定的,若樣本中的維度不同,就需要選取一個合理的維度作為輸入,這樣才可以更好地利用樣本信息。不考慮向量維度產生的不好情況在于:如果向量維度太長,那么會大幅度提高訓練時間,這樣就會降低檢測的實時性;反之,向量維度太短,會導致有效信息的遺失,影響檢測準確率。為得到一個合適的向量維度,本文設置了若干種不同維度的超參數(令維度分別為2,5,10,20,50,100,150),在這些不同設置影響下的訓練時間與準確率的關系見圖5。
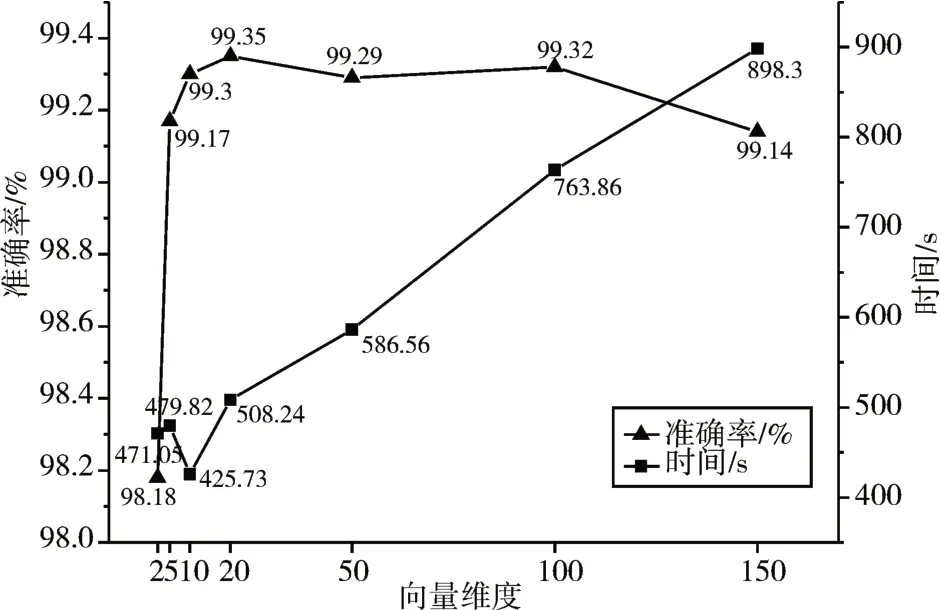
圖5 不同向量維度下準確率與訓練時間消耗
實驗結果表明,維度超過10 時,準確率變化不明顯,但是訓練時間幾乎成線性增長趨勢,維度為20 時精度最高,達到了99.35%,其訓練時間消耗為508.24s,而維度為10 時,精度為99.3%,稍稍低于維度為20 時的精度,其訓練時間是所有維度中最低的,僅425.73s,結合精度與訓練時間兩方面,選擇10作為向量維度。
模型參數的設置會影響模型的分類效果,本文最終選擇的超參數見表1。
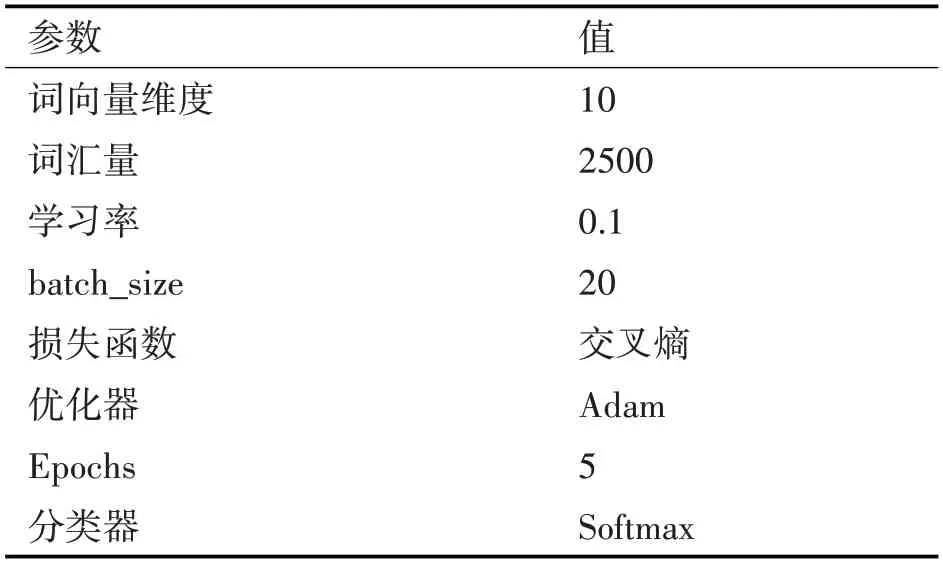
表1 本文一維卷積神經網絡模型參數。
4.4.2 模型測試
為了驗證本文模型的優勢與有效性,本文進行了相應的對比實驗,即本文所提出的一維卷積神經網絡模型(1D-CNN)與目前常見的檢測方法,如多層感知機(MLP)[15]、長短期記憶網絡(LSTM)[16]以及支持向量機(SVM)模型[17]。結果如表2所示,與其它三種方法相比,本文模型的召回率、準確率與F1 值均是最優,表明了本文方法在檢測精度上要好于以往的跨站腳本攻擊檢測識別方法,同時也說明了相比較淺層的機器學習方法中采用人工提取特征而言,深度學習模型可以很好地提取出跨站攻擊樣本的特征,從而具備較好的識別能力。
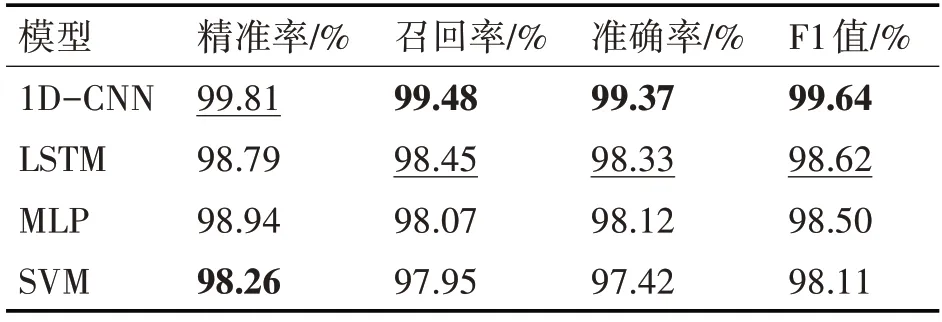
表2 四種模型的對比數據
因為深度學習模型一般會比較耗時,在提高精度的同時也會增加相應的時間,圖6 是四種模型的準確率與測試時間關系。可以看出,SVM的測試時間是最短的,但是其是以犧牲一定的準確率為代價,1D-CNN 模型的測試時間相比其它另外兩個模型的時間更短,結合準確率指標,1D-CNN 模型可以在保證檢測精度的同時減少檢測時間。
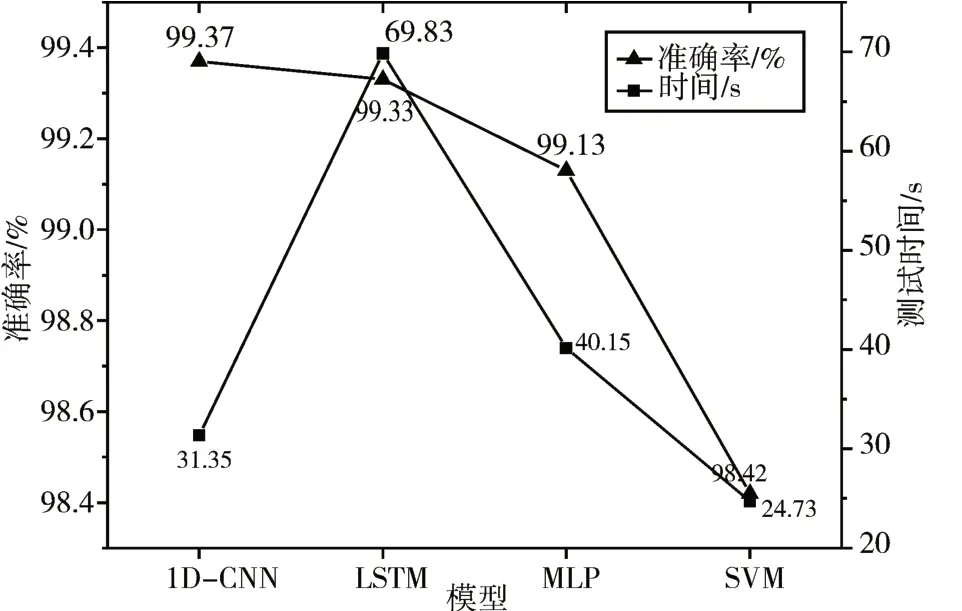
圖6 模型準確率與測試時間對比結果
5 結語
針對傳統的跨站腳本攻擊檢測工具效率不高、準確率不高的問題,本文提出一種基于一維卷積神經網絡的跨站腳本攻擊檢測方法。該方法考慮到XSS 攻擊為避開檢測進行了相應的編碼處理,因此采用反向解碼與范化處理,同時進行分詞以及借鑒Word2Vec 工具進行向量化處理,然后輸入到本文所設計的一維卷積神經網絡模型進行二分類處理。通過相關對比實驗比較,得出本文方法對XSS攻擊具有較高的檢測效率與準確率。
本文只是使用一維卷積神經網絡模型對跨站腳本攻擊這種漏洞進行檢測,后期的研究將會考慮面向其他Web漏洞進行相應建模,例如跨站請求偽造、緩沖區溢出、SQL注入等。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
