基于指數核函數高斯過程回歸的短期徑流預測研究
2023-08-28 01:54:40何中政遲英凡王永強付吉斯
中國農村水利水電 2023年8期
何中政,方 麗,劉 萬,遲英凡,王永強,付吉斯,熊 斌
(1. 南昌大學工程建設學院,江西 南昌 330031; 2. 長江水利委員會長江科學院,湖北 武漢 4 30010;3. 南昌大學 鄱陽湖環境與資源利用教育部重點實驗室,江西 南昌 330031)
0 引 言
流域徑流過程受眾多因素的相互作用與影響,使得徑流時間序列表現出復雜的非線性特性[1],具有顯著的非平穩、高維度和模糊性等復雜特征[2,3],研究預測精度高和穩定性好的徑流預測模型仍是當前水文水資源研究領域熱點問題之一。而目前水文預測方法主要可分為過程(機理)驅動和數據驅動模型兩大類:過程驅動模型以水文過程的物理機制或規律為基礎[4],需要大量且可靠的水文數據來建立模型,從而進行流域徑流模擬或預測,但由于水文模型對水循環過程的簡化處理,往往難以精準刻畫非線性的徑流過程,且由于部分水文數據資料缺失或可靠性差等因素影響,過程驅動模型在實際徑流預報中存在局限性[5];而隨著計算機硬件、軟件和理論技術的發展,數據驅動模型依托統計學或其他人工智能技術,無需考慮水文過程物理機制[6],通過對時間序列進行分析從而建立對預測對象和預測因子間復雜非線性關系刻畫更為完備的模型,使得數據驅動模型在水文數據資料缺少或復雜非線性的徑流過程將具有更好的適用性[2]。近年來,學者們將多種常見的人工智能模型引入到水文預測中,如前饋式神經網絡[7](Back-Propagation neural network,BP)、多元線性回歸[8](Multiple Linear Regression,MLR)、支持向量機[9](Support Vector Machine,SVM)等,相關研究均取得了較好的效果[10],如何應用人工智能技術開展流域徑流預測已經成為未來發展的重要研究方向之一[11]。
高斯過程回歸(Gaussian Process Regression,GPR)作為一種新型的機器學習方法,采用高斯過程對先驗數據進行回歸分析,以統計學理論為基礎,在處理高維、非線性、小樣本等復雜的回歸問題時都具有很強的泛化能力,因而在各類研究領域得到應用[12]。黃亞等人[3]采用GPR 模型在廣西天峨水文站進行短期徑流預測;孫斌等人[13]采用GPR 模型在進行短期風速預測;李成宇[14]采用GPR 模型進行了土石壩沉降預測研究;周靖楠等人[15]采用GPR 模型與MI-KPCA 結合在北汝河進行中長期徑流預測。劉龍龍等人[16]采用GPR 模型與蜻蜓算法結合對居民社區時用水量動態實時區間預測。GPR 模型已在非線性回歸分析問題中得到成功應用,GPR 回歸分析能力不僅取決于模型參數,還受核函數影響,但目前核函數的影響還未得到進一步研究。Scholkopf 和Smola[17]指出支持向量機和高斯過程兩種算法的核函數是等價的,并提出幾種高斯過程中可選擇的核函數類型。因此,本文分析了不同核函數作用下GPR 預測模型效果,并提出了一種基于指數核函數GPR 的流域短期徑流預測模型,以江西省贛江流域吉安水文站徑流過程為對象例開展實例分析。
1 研究方法
1.1 高斯過程回歸預測模型基本原理
高斯過程(Gaussian Process,GP)是概率論和數理統計中隨機過程的一種,是一系列服從正態分布的隨機變量的組合。GP繼承了正態分布的諸多性質,其特征主要由數學期望和協方差函數決定。GPR 則是對數據進行回歸分析,來建立服從GP 先驗信息的非參數模型[18]。假設一個含有n對相互獨立觀測數據的學習樣本{,y},其中是由n個輸入向量組成的輸入集,而y={y1,y2,…,yn}是由n個相對應的一維輸出組成的輸出集。那么GP 的均值μ(x)和方差k(x,x′)可由下式確定:
式中:x,x′代表樣本中任意隨機變量,E代表數學期望。
因此GP可定義為:
而在實際應用中,通常會進行數據預處理使得均值函數為0,故GP即也表示為:
對于實際工程中的回歸問題,還應考慮輸出y受噪聲影響:
式中:y是受到噪聲污染的觀測值,f為函數值,x為輸入向量,噪聲ε服從均值為0、方差為σ2n的高斯分布。
從而可以推求得到y的先驗分布,見公式(6);以及y和f(x*)的聯合先驗分布,見公式(7)。
式中:x*為測試輸入向量,I是n維單位矩陣,是n×n階的GP 協方差矩陣,是輸入集與測試輸入向量x*之間的n× 1階協方差矩陣,K(x*,)同理可知,k(x*,x*)為x*自身的協方差。
由此可知預測值f(x*)的后驗分布:
其中:
1.2 高斯過程回歸的核函數與超參數優化
GPR 使用GR 作為先驗,其訓練結果與預先設定的核函數有關。在隨機樣本均值為0 的前提下,核函數就與協方差函數的實際意義相近,可進行樣本間相關性的描述。不同核函數作用下的高斯過程回歸特征各不相同,高斯過程模型常用的核函數主要有以下幾種:
(1)徑向基核函數:
式中:r=‖X1-X2‖,σ為超參數,表征了學習樣本間的相似度。徑向基核函數也被稱為高斯核,常被應用于SVM和GPR等各類機器學習算法中,參數簡單,但在處理樣本數量大或特征多時效果一般。
(2)二次有理核函數:
式中:α,l為超參數。二次有理核函數可以理解為是無窮個徑向基核函數的線性疊加,當α→∞時,二次有理核函數等價于σ=l的徑向基核函數。與徑向基核函數相比,更為省時,作用域廣,但是對參數十分敏感。
(3)馬頓核函數:
式中:l,ν為超參數,Kν為修正貝塞爾函數。當ν→∞時,相當于以l為特征尺度的徑向基核函數。
(4)指數核函數:
指數核函數是馬頓核在ν= 0.5的特殊形式,這樣的變動減少對參數的依賴性降低,使得模型的訓練學習難度大大降低,適用情景相對狹窄。
而核函數中的超參數一般可依據極大似然法,建立基于學習樣本條件概率的對數似然函數,見式(15);然后可通過非線性規劃方法或群智能搜索方法尋找出超參數的近似最優解。
1.3 預報因子篩選
由于徑流預測往往是采用輸入多個預測因子對預測量進行輸出,研究采用多重相關系數來篩選預報因子。多重相關系數是測量單個因變量與其他多個自變量之間線性相關程度的指標。多重相關系數無法直接計算,可采用預測量y和其他多個預測因子x1,x2,…,xk線性組合的簡單相關系數進行測算。
首先,根據預測量y和其他多個預測因子x1,x2,…,xk進行回歸,建立如式(16)的回歸方程,然后進一步計算簡單相關系數,即為預測量y和多個預測因子x1,x2,…,xk之間的多重相關系數R。
式中:β0,β1,β2,…,βk為回歸系數。
2 實例研究
2.1 研究區域與資料概況
贛江是江西省內第一大河流,地理位置為113.58°~116.63°E,24.52°~28.75°N。其發源于贛閩邊界武夷山西麓,主河道長約823 km,干支流自南向北貫穿整個江西省,地貌多以山地、丘陵為主,豐水期為3-8月,枯水期為9月-次年2月。
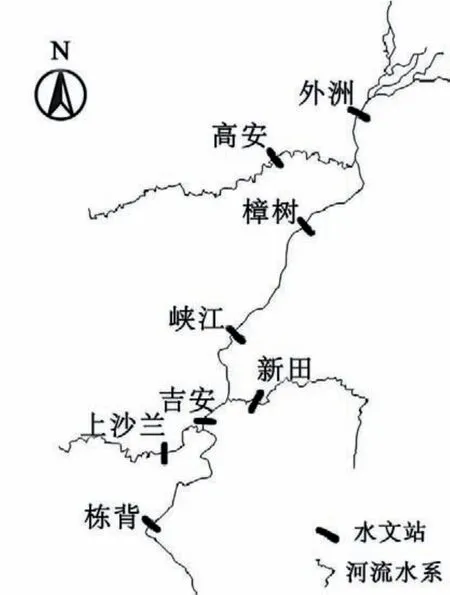
圖1 贛江中下游控制斷面分布示意圖Fig.1 Distribution diagram of control section in the middle and lower reaches of Ganjiang River
研究選取了贛江中游棟背、吉安關鍵斷面開展實例分析。棟背站位于江西省萬安縣棟背村,控制流域面積約4.02 萬km2;吉安站是贛江中游主要控制站,控制流域面積約5.62 萬km2;棟背站到吉安站的時滯約為18~24 h,棟背站對吉安站的流量過程有較大的影響。研究收集整理了兩個水文站點從2010 年1月1 日0∶00 至2018 年4 月14 日18∶00 的實測徑流數據,時段間隔為6 h,共計20 000 個數據。
2.2 基于高斯過程回歸的徑流預測流程
依托項目研究收集得到的數據資料,開展基于GPR 模型的徑流預測研究。具體實施步驟為:① 整編收集得到的徑流數據資料,將前80%作為預測模型訓練期,后20%作為預測模型檢驗期;②根據率定期徑流資料,計算預報因子-預測量的多重相關系數,開展相關性分析,從而選定預報因子;③選取評價指標,便于直觀表現模型的預測效果;④采用GPR 對預報因子和預報變量進行建模,用訓練期資料進行參數率定;⑤將訓練好的GPR模型用于檢驗期的徑流預報,檢驗模型預報效果。
2.3 評價指標選取
為評價預測結果的綜合表現,選取了均方根誤差(Root Mean Squared Error,RMSE)、平均絕對誤差(Mean Absolute Error,MAE)、確定性系數(Deterministic coefficient,DC)和合格率(Qualified Rate,QR)評價指標,具體計算公式如下:

圖2 基于高斯過程回歸的徑流預測流程圖Fig.2 Flow chart of runoff prediction based on Gaussian process regression
式中:Si為模擬值;Oi為實測值;為實測值的均值;k為樣本中相對誤差小于20%的樣本個數;n為測試樣本個數。評價指標中,RMSE和MAE取值范圍為(0,∞),其值越小表明模型預測誤差越小;DC取值范圍為[0,1],其值越大表明預測值和真實值的相關性越大;QR取值范圍為[0,100%],其值越大表明模型預測精度越高。
2.4 預測因子篩選
建立短期徑流預測模型首先需要篩選預測因子,記T為當前時段,OT和IT分別表示本站點和上游站點T時段徑流量。采用IBM SPSS Statistics 26.0 軟件開展見2.3 小節中的多重相關系數分析,多重相關性分析結果如表1和表2所示。

表1 僅考慮吉安站的多重相關性分析結果Tab.1 The multiple correlation analysis results of Ji'an Station
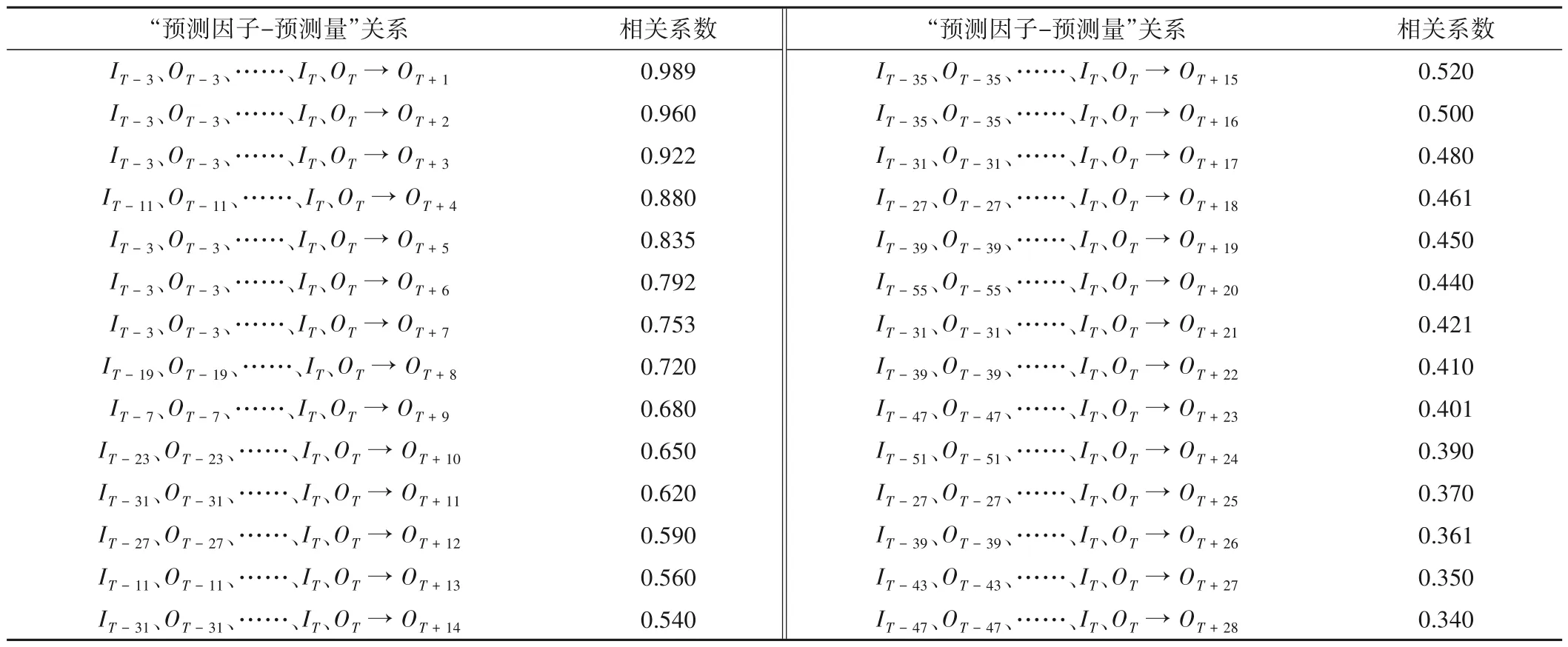
表2 考慮棟背站和吉安站的多重相關性分析結果Tab.2 The multiple correlation analysis results of Dongbei station and Ji'an station
表1 和表2 僅列出了與吉安徑流多重相關性系數最大,且預測因子時段最短的組合。對比表1 和表2 可知,增加棟背徑流信息對“預測因子—預測量”復相關性系數增益較為明顯,因此研究選擇表2中預測因子開展短期徑流預測。
2.5 徑流預測實例分析
采用數據留出法[19]進行評估,將樣本數據的前80%作為模型訓練樣本,后20%作為模型檢驗樣本,即訓練期為2010 年1月1 日0∶00 至2016 年11 月19 日18∶00 的實測徑流數據,時段間隔為6 h;檢驗期為2016 年11 月19 日18:00 至2018 年4 月14日的實測徑流數據,時段間隔為6 h。根據表2 中的預測因子,建立28 個基于GPR 的短期徑流預測模型,分別對面臨T+1~T+28 時段的吉安徑流進行預測。為分析不同核函數對GPR 短期徑流預測模型的作用效果,研究分別選用了有理二次、徑向基、馬頓和指數核函數建立不同的GPR 短期徑流預測模型,還加入了MLR、回歸樹(Regression Tree,RT)、SVM、BP 等模型方法的預測結果作為對比。以上模型的訓練以及檢驗均采用MATLAB R2020b 進行處理,GPR、MLR、RT 和SVM 模型訓練基于Regression Learner 模塊,BP 模型訓練基于采用的Neural Net Fitting模塊。
圖3 給出了吉安站不同模型短期徑流預測在檢驗期的結果,見T+1~T+27 時段4 種評價指標的熱力圖。4 張熱力圖均為顏色越深,檢驗期預測效果越差。相關實驗結果表明:①從4種指標綜合來看,研究建立的4 種GPR 模型和RT 模型均優于MLR、SVM、BP 模型,在DC指標上差異最為顯著,4 種GPR 模型和RT 模型的DC均在0.9以上,而MLR、SVM、BP 模型DC前2個時段大于0.9,隨預見期增長DC銳減至不足0.4;②從4 種GPR模型對比來看,有理二次、指數GPR 優于徑向基和馬頓GPR,結合核函數表達式(11)~(14)來看,徑向基和馬頓核函數明顯比有理二次、指數核函數更復雜,這表明復雜的核函數形式不一定能提升GPR 模型非線性回歸分析能力;③隨著預測期的增加,MLR、SVM、BP 模型的4種評價指標均呈現劣化的趨勢,4種GPR 模型和RT 模評價指標有略微波動,但整體較為穩定;④綜合各項評價指標來看,有理二次、指數GPR 模型結果最為突出,而指數GPR 模型的RMSE、MAE、QR明顯優于有理二次GPR,指數GPR 模型在28個時段的QR中僅有1處合格率不足100%,明顯少于有理二次GPR 的22 處。綜上所述,本文提出的指數GPR在吉安站短期徑流預測中顯著優于其他6種模型方法。

圖3 吉安站檢驗期各模型評價指標熱力圖Fig.3 Heat map of each model evaluation index for the testing period at Ji'an Station
圖4和表3分別給出了吉安站不同模型短期徑流預測T+28時段的預測結果和4 種評價指標統計結果,7 種模型方法在訓練期和檢驗期4 項評價指標變化不大。此外,研究發現4 種GPR 模型檢驗期4項評價指標在T+1到T+9時段逐漸劣化,4項評價指標隨后在T+10到T+28時段變好并趨于穩定。結合多重相關性分析結果,可知T+10 時段以后預測模型輸入信息激增,有助于數據驅動的GPR 模型開展回歸預測分析。這也說明應用多重相關性系數分析篩選出的“預測因子—預測量”關系,并不能完全反映自身和上游站點徑流的非線性關系。

表3 吉安站T+28時段訓練期和檢驗期結果評價指標Tab.3 Evaluation indexes for the results of the training and testing period of the T+28 period at Ji'an Station
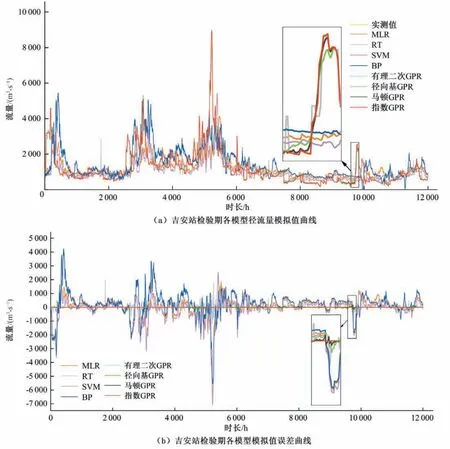
圖4 吉安站檢驗期T+28時段預測結果Fig.4 Forecast results for the T+28 period of the testing period at Ji'an Station
3 結 論
(1)以贛江流域吉安水文站為對象的預測步長為6 h 預見期為7 d 的實例分析為例,應用不同核函數的GPR 模型預測結果表現存在明顯差異,不同方法預測表現由好到差分別為指數GPR、有理二次GPR、RT、馬頓GPR、徑向基GPR、SVM、MLR、BP。指數GPR 預測效果最好,28 個時段的DC和QR均分別接近1和100%。
(2)從4 種GPR 模型對比來看,徑向基和馬頓核函數表達式比有理二次、指數核函數更復雜,但預測結果不如有理二次、指數核函數的GPR 模型,說明復雜的核函數形式不一定能提升GPR模型非線性回歸分析能力。
(3)4 種GPR 模型檢驗期預測精度在T+1 到T+9 時段逐漸降低,但在T+10 到T+28 時段,隨預測模型輸入因子信息激增,預測精度提高并趨于穩定。
(4)多重相關性系數分析篩選出的“預測因子—預測量”關系,主要依據線性關系,并不能反映自身預測量和上游站點預測因子的非線性關系。在未來的研究中,需探究能夠精準描述預測因子與預測量復雜非線性關系的分析方法,從而更為準確的篩選預測因子。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
