基于生成對抗網絡的電動汽車電池數據增強和故障診斷*
2023-08-24 06:51:46李潔張震豪董亞冰陳旭迎
汽車技術 2023年8期
李潔 張震豪 董亞冰 陳旭迎
(1.湖南大學,長沙 410082;2.河南省新融高速公路建設有限公司,洛陽 471000)
主題詞:動力電池 數據增強 生成對抗網絡 故障診斷
1 前言
鋰離子電池具有使用壽命較長、能量密度高、自放電率低等優點,是當前應用最廣泛的電動汽車動力電池[1-2]。電池組電壓是動力電池的關鍵參數,電壓異常故障可能導致電池的熱失控[3],甚至引發燃燒、爆炸事故。及時、準確的電動汽車動力電池故障診斷方法可以提高電動汽車的整體安全性,增加公眾對電動汽車的信賴程度[4],進而推動傳統交通向綠色低碳交通的轉變。
近年來,國內外學者使用機器學習[5]、信息融合[6]等方法針對動力電池故障診斷展開了廣泛的研究,取得了系列成果。Yang 等[7]基于電動汽車電池組的真實運行數據,使用組內相關系數分析電池的端電壓,對比充、放電過程中單體電池電壓的排序差異,確定發生故障的單體電池,探究故障形成的原因。Hong 等[8]結合天氣、車輛和駕駛員信息,利用長短期記憶神經網絡對電動汽車電池系統的電壓進行預測,實現對動力電池安全性能的評估。劉鵬等[9]根據實車運行數據,采用快速傅里葉變換和異常系數評估方法對動力電池的電壓故障進行診斷。宋哲等[10]使用主成分分析法、支持向量機模型和粒子群優化算法,對鋰離子電池的健康狀態進行了預測。Li等[11]將經驗模態分解法和樣本熵相結合,根據提取到的汽車動力電池電壓信號,實現對電池故障的識別和定位。
當前的電動汽車動力電池故障診斷方法大都基于海量的車輛歷史運行數據構建模型,很少有研究關注此類數據集中故障異常數據樣本占比過少的現象。樣本的不均衡可能影響模型的有效性和普適性[12]。針對這一問題,本文提出一種基于生成對抗網絡(Generative Adversarial Networks,GAN)的電動汽車電池數據增強方法。根據增強后的數據,采用隨機森林(Random Forests,RF)模型進行故障診斷,使用貝葉斯優化(Bayesian Optimization,BO)方法對模型的超參數進行優化,提出GAN-RF-BO 電動汽車電池故障診斷框架,并將其與常用的故障診斷模型在真實的電池故障數據集上進行對比,驗證其有效性。
2 電動汽車數據分析
本文的研究數據是上海市新能源汽車公共數據采集與監測研究中心提供的20輛純電動汽車的真實運行數據,采樣時間為2021年7月至12月,采樣間隔為10 s。
2.1 電壓異常故障占比
本文使用的20 輛純電動汽車的運行數據共有14 787 935 條,其中電壓異常故障數據有5 376 條,占數據總量的0.35‰。20 輛車中電壓異常故障發生數量最多的車輛有643 條故障數據,占該車輛全部數據的0.82‰。統計分析20輛純電動汽車發生電壓異常故障數量的分布情況,大部分車輛在采樣期間發生故障的數量在100~400起范圍內,如圖1所示。

圖1 電壓異常故障分布
2.2 電壓異常故障診斷關鍵因素提取
本文采用的純電動汽車真實運行數據集包括38個數據字段,其中一些字段(如擋位、溫度探針數量等)與電池電壓異常故障沒有直接聯系,不宜引入數據增強和故障診斷模型。本文采用隨機森林算法從38個特征變量中篩選出導致動力電池電壓異常故障的關鍵因素。
隨機森林模型[13]從分類回歸樹(Classification and Regression Tree,CART)擴展而來,由多棵決策樹組成,適合進行分類和回歸分析。隨機森林模型在建立決策樹時,利用自助重抽樣方法(Bootsrap)構建數據集。
自助重抽樣方法從給定的包含m個樣本的數據集合D中隨機選取1個樣本放入采樣集Di,再把該樣本放回原數據集D中。如此經過m次操作,可以得到包含m個樣本的采樣集Di。每次抽樣未被選擇的數據稱為袋外數據(Out-Of-Bag,OOB),用于對決策樹的性能進行評估,以OOB 作為測試集進行分類預測的錯誤率稱為袋外數據誤差。計算特征重要性時,對OOB 中相應特征變量加入噪聲,再次計算袋外數據誤差。根據2次袋外數據誤差可以計算對應特征的重要度:
式中,Ii為特征i的重要度;N為隨機森林中決策樹的總數量;OT為決策樹T的袋外數據誤差;為決策樹T中特征i加入噪聲干擾后計算的袋外數據誤差。
特征重要度反映了特征變量與電池電壓故障的關聯性,重要度越高則關聯性越強。對于數據增強和故障診斷模型,輸入維度較低的特征變量難以提取關鍵信息,影響模型的魯棒性,過高的特征變量維度又會帶來冗余特征,增加模型的復雜度。篩選出關聯性較強的特征變量,能夠減少計算量,提高模型的精度和效率[14]。為保證數據增強和故障診斷模型的性能,本文以特征重要度0.05 為閾值,從38 個潛在特征變量中篩選出11 個關鍵特征變量,即電壓異常故障診斷關鍵影響因素,如圖2所示。

圖2 關鍵特征變量
3 數據增強模型
20輛純電動汽車中動力電池電壓異常故障數據占比不足0.1%,是典型的稀缺數據。針對電動汽車真實運行數據集中動力電池電壓異常故障數據的樣本不均衡問題,本文使用生成對抗網絡進行數據增強。
3.1 生成對抗網絡
生成對抗網絡是Goodfellow 等[15]根據零和博弈思想在2014 年提出的一種生成模型,已經應用于圖像生成[16]、交通標志識別[17]以及交通事故檢測[18]等多個領域。GAN的基本結構如圖3所示,主要由生成器和判別器組成。生成器的主要作用是學習真實數據的分布,判別器根據輸入的數據判斷該數據是真實數據或是生成器生成的數據。根據判別結果,生成器G和判別器D不斷優化,最終達到納什均衡,即判別器D 無法判斷輸入數據是真實數據還是生成數據。

圖3 GAN基本結構
GAN優化過程的目標函數為:
式中,E為下標中指定分布的數學期望;Pdata(x)為真實數據x的分布;Pz(z)為生成數據的分布;D(x)為判別器的判別函數;G(z)為生成器生成的數據。
生成器G 的優化目標是使生成數據的分布無限近似于真實數據,判別器D的優化目標是最大可能地判別真實數據和生成數據。
本文中GAN的生成器和判別器均采用全連接神經網絡,激活函數為修正線性單元(Rectified Linear Unit,ReLU)函數,ReLU 函數能有效緩解梯度消失問題[19]。生成器和判別器使用Adam優化器[20]優化,Adam優化器具有計算高效、適用于不穩定的目標函數等優點。
3.2 數據增強結果
本文保留由隨機森林算法得到的11個關鍵特征數據字段。從14 787 935 條車輛真實運行數據中按照不同車輛的數據占比隨機抽樣獲取2 010條電壓異常故障數據和18 090 條正常運行數據,得到故障數據占比為10%的原始數據集。使用Python 和Pytorch 庫構建生成對抗網絡,輸入原始數據集進行電壓異常故障數據的數據增強。模型批次大小,即每次訓練選取的樣本數量設置為64 個。生成器和判別器的學習率設置為0.01,生成器和判別器隱藏層的神經元數量設置為128 個。迭代訓練100 000輪,最終得到包含8 040條電壓異常故障數據和12 060條正常運行數據的GAN擴充數據集。為了檢驗本文提出的GAN 的性能,使用歸一化方法處理GAN 擴充數據集和原始數據集以消除量綱影響,方便比較兩類數據集中數據的分布。歸一化處理公式為:
式中,xi、yi分別為歸一化處理前和處理后的數據。
歸一化處理能夠將數據縮放至[0,1]范圍內,且不改變數據的分布情況。本文中歸一化處理后的原始數據集和GAN擴充數據集的分布如圖4所示。

圖4 兩類數據集中的數據分布
箱型圖中從上至下的5 條橫線分別代表數據的最大值、上4分位數、中位數、下4分位數和最小值,三角形標識符代表數據的均值。由圖4可知,GAN擴充數據集與原始數據集僅在關鍵特征11 上存在細微差別,其余特征數據分布情況基本一致。本文提出的GAN數據增強模型能學習原始數據的分布情況,可以應用于電動汽車動力電池電壓異常故障數據的數據增強。
4 故障診斷模型
根據增強后的數據,使用隨機森林分類模型進行動力電池電壓異常故障診斷,采用貝葉斯優化方法優化模型的超參數。
4.1 隨機森林
隨機森林分類模型的結構如圖5 所示。隨機森林模型可以有效處理高維數據,對數據噪聲具有較高的容忍度,且不易出現過擬合,常用于分類和回歸分析。對于回歸問題,隨機森林模型采用平均法進行預測;對于分類問題,隨機森林模型采用投票法得出最終結果。本文使用隨機森林分類模型對電動汽車動力電池的電壓異常進行故障診斷。

圖5 隨機森林基本結構
隨機森林分類采用投票法獲得結果,假設隨機森林模型包含n個決策樹模型{h1,h2,…,hn},m個類別集合{C1,C2,…,Cm}。為保證分類的可靠性,根據絕對多數投票法輸出結果,即當某個類別在所有決策樹中得到超過半數投票,則預測為該類別,否則拒絕分類預測:
式中,H(x)為投票結果;(x)表示決策樹hi對輸入x的類別判斷為Cj;reject表示拒絕進行分類預測。
4.2 貝葉斯優化
搭建故障診斷模型時,需要對模型的超參數進行設置,但是人工設置的超參數不一定能使模型的性能達到最優,需要選擇合適的模型超參數搜索方法。貝葉斯優化屬于全局優化算法,是近年來機器學習領域中常用的超參數優化方法之一[21]。貝葉斯優化由概率代理模型和采集函數2 個部分構成。概率代理模型用于代理復雜的未知目標函數,以最大化采集函數為目標選擇下一個評估點[22]。本文使用高斯過程作為貝葉斯優化的概率代理模型,概率改進函數作為采集函數,對隨機森林分類模型中的決策樹的數量、決策樹的最大深度、節點拆分時考慮的特征數量以及節點拆分所需的最小樣本數進行超參數優化,提高故障診斷模型的性能。貝葉斯優化的流程如圖6所示。
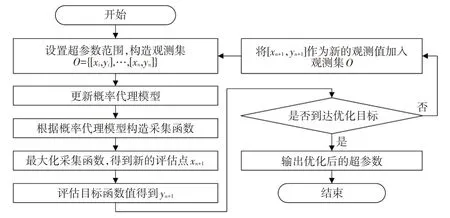
圖6 貝葉斯優化流程
4.3 故障診斷結果
本文采用Python 構建隨機森林分類模型進行電動汽車動力電池電壓異常故障診斷,分別在故障數據占比為10%的原始數據集和故障數據占比為25%的GAN 擴充數據集上進行訓練。使用準確率(Accuracy)作為模型的評價指標,準確率是所有診斷正確的類(包括正類和負類)樣本數量占正類和負類樣本總數的比例:
式中,A為診斷準確率;TP為正類判定為正類的樣本數量;TN為負類判定為負類的樣本數量;P為正類的樣本數量;N為負類的樣本數量。
訓練模型時,按照6∶2∶2的比例將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練故障診斷模型,驗證集用于調試模型的超參數,測試集用于檢測模型的精確度。隨機森林分類模型的待優化超參數取值區間為:決策樹的數量[100,1 000],決策樹的最大深度[50,250],節點拆分時考慮的特征數量[1,11],節點拆分所需的最小樣本數[2,8]。以最大故障診斷準確率為優化目標,經貝葉斯優化迭代150 輪,最終得到優化后的超參數為:決策樹的數量為456,決策樹的最大深度為96,節點拆分時考慮的特征數量為3,節點拆分所需的最小樣本數為2。
為了驗證本文提出的RF-BO故障診斷模型的有效性,從車輛真實運行數據集(除去用于訓練和數據增強的原始數據集)中按比例抽樣得到真實故障數據集,此數據集包含2 010條故障數據和6 030條正常運行數據,故障數據占比為25%,用于評價故障診斷模型的泛化能力。選擇故障診斷領域常用的多層感知機(Multilayer Perceptron,MLP)模型、支持向量機(Support Vector Machine,SVM)模型和梯度提升決策樹(Gradient Boosting Decision Tree,GBDT)模型,在同樣的數據集上訓練,在同一個真實故障數據集上對比各模型的泛化性能,結果如圖7所示。
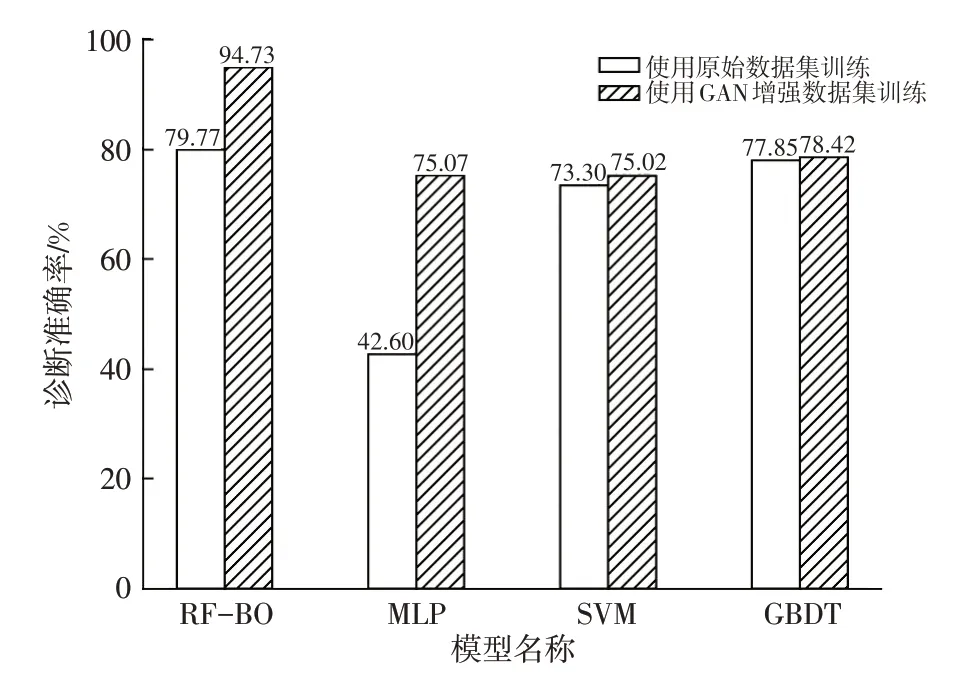
圖7 模型泛化性能對比
圖7中,RF-BO模型使用GAN擴充數據集訓練后,故障診斷準確率可達94.73%,對比使用原始數據集訓練的模型,診斷準確率提升14.96 百分點。MLP 模型、SVM 模型、GBDT 模型使用GAN 擴充數據集訓練后,在真實故障集上驗證的準確率均有不同程度的提升,證明采用GAN增強動力電池電壓異常故障稀缺數據可以提高故障診斷模型的準確性。RF-BO的模型診斷準確率較MLP 模型、SVM 模型及GBDT 模型分別提升19.66 百分點、19.71 百分點和16.31 百分點,體現了GAN-RFBO故障診斷框架的優越性。
5 結束語
本文基于20 輛純電動汽車的真實運行數據,利用生成對抗網絡對動力電池故障數據進行數據增強,采用隨機森林模型結合貝葉斯優化進行電池故障診斷。利用隨機森林算法計算38 個特征數據字段的重要度,保留了11 個顯著特征變量進行數據增強和故障診斷,降低了模型的復雜度,縮短了運行時間。針對數據集的數據不均衡現象,提出使用生成對抗網絡對動力電池電壓異常故障數據進行數據增強。將擴充后的數據集與原始數據集進行比較,數據分布基本一致,說明GAN數據增強方法能夠對稀缺數據樣本進行有效擴充,提高故障診斷模型的準確率。
使用隨機森林模型進行故障診斷,通過貝葉斯優化得到最優超參數組合。對比驗證結果表明,本文提出的RF-BO模型在診斷準確率和泛化性能上明顯優于MLP模型、SVM模型和GBDT模型。
動力電池故障與駕駛行為、天氣條件、道路工況等多方面因素相關,且不同類型故障之間存在一定聯系,本文僅根據實車運行數據對動力電池電壓異常故障展開分析,未來將重點探究不同類型電池故障之間的耦合關系,并結合駕駛行為、天氣信息等多源數據,深入研究電動汽車電池故障的形成機理,提高駕駛安全性與交通安全性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
