基于殘缺值的模糊偏好關系多屬性大群體決策方法
2023-08-01 18:19:23馮曉靜
上海管理科學
2023年4期


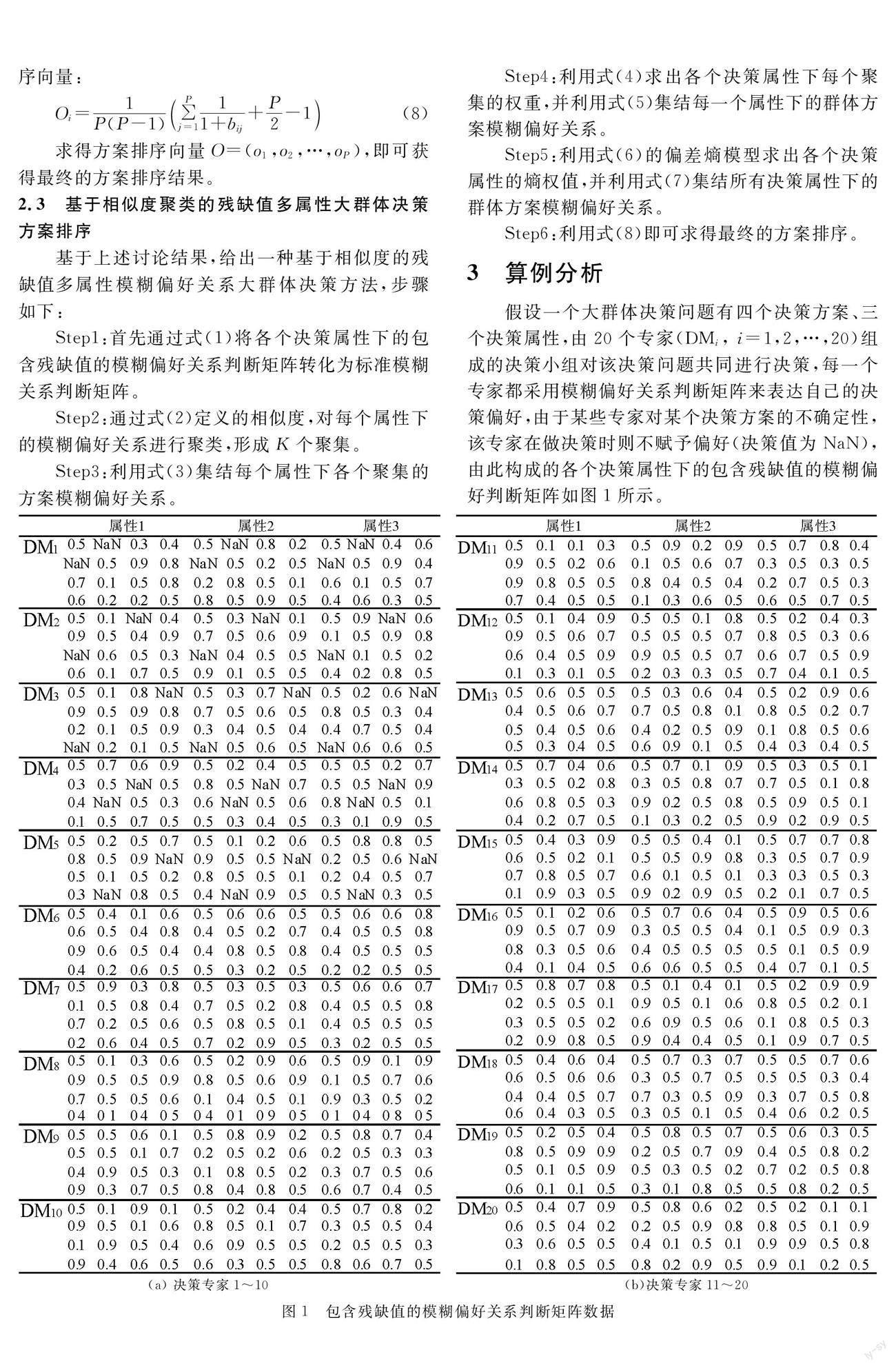
摘 要: 在多屬性大群體決策環境下,針對決策者給出關于決策方案兩兩比較且可能包含殘缺值的模糊偏好關系的決策問題,提出了一種基于相似度聚類的殘缺值模糊偏好關系大群體決策方法。此方法首先通過標準化殘缺值矩陣,然后定義判斷矩陣之間的相似度對大群體進行聚類,再對各個屬性下的群體偏好進行集結,通過偏差熵模型確定各個決策屬性的權重,集結所有決策屬性下的群體偏好,最后得到決策方案的排序結果。文章最后給出了一個算例分析以驗證此方法的有效性。
關鍵詞: 殘缺值;模糊偏好關系;聚類;多屬性決策;大群體決策
中圖分類號: C 934
文獻標志碼: A
Multi-Attribute Large Group Decision Making Method Basedon Incomplete Fuzzy Preference Relation
FENG Xiaojing
(Institute of Western China Economic Research, Southwestern Universityof Finance and Economics, Chengdu 611130, China)
Abstract: In the environment of multi-attribute large group decision-making, aiming at the decision-making problem that the decision-maker gives the fuzzy preference relation of pairwise comparison of decision-making schemes and may contain residual value, a large group decision-making method based on similarity clustering of fuzzy preference relation of residual value is proposed. This method firstly standardizes the incomplete value matrix, then defines the similarity between judgment matrices to cluster large groups, and then aggregates the group preferences under each attribute; Next, it determines the weight of each decision attribute through the deviation entropy model, and aggregates all decisions Group preferences under attributes, and finally get the ranking results of decision-making schemes. A numerical example analysis is given to illustrate the effectiveness of the method developed.
Key words: incomplete value; fuzzy preference relations; clustering; multi-attribute decision making; large group decision making
0 引言
近年來,決策這一研究領域得到了廣泛關注和研究,眾多學者在決策領域提出了多種決策方法,并將它們應用到管理科學的各個方面。現有的決策方法主要集中在多屬性群決策、模糊數決策、語言信息決策、多階段決策等領域。群體決策一直都是決策領域研究的重要范疇,然而現有的群體決策方法卻局限在小群體范圍內。隨著現代網絡信息的迅猛發展以及信息資源的暴增,決策問題變得越來越復雜,因此需要更多的不同領域的專家來參與決策。鑒于此,徐選華等學者對此類問題進行了研究并提出了一些大群體決策方法,但是這些大群體決策方法卻局限在決策信息為實值的決策中。
由于人類認識事物的主觀性以及客觀事物的復雜性,決策者往往更喜歡用模糊偏好來表達自己的決策信息,而模糊偏好關系正是模糊偏好的一種,由此徐選華進一步提出了基于模糊偏好關系的大群體決策方法。……
登錄APP查看全文
