融合多維特征與興趣漂移的虛擬學術社區(qū)群推薦模型
2023-07-20 10:25:28魏玲權(quán)晨雪
現(xiàn)代情報
2023年7期
魏玲 權(quán)晨雪
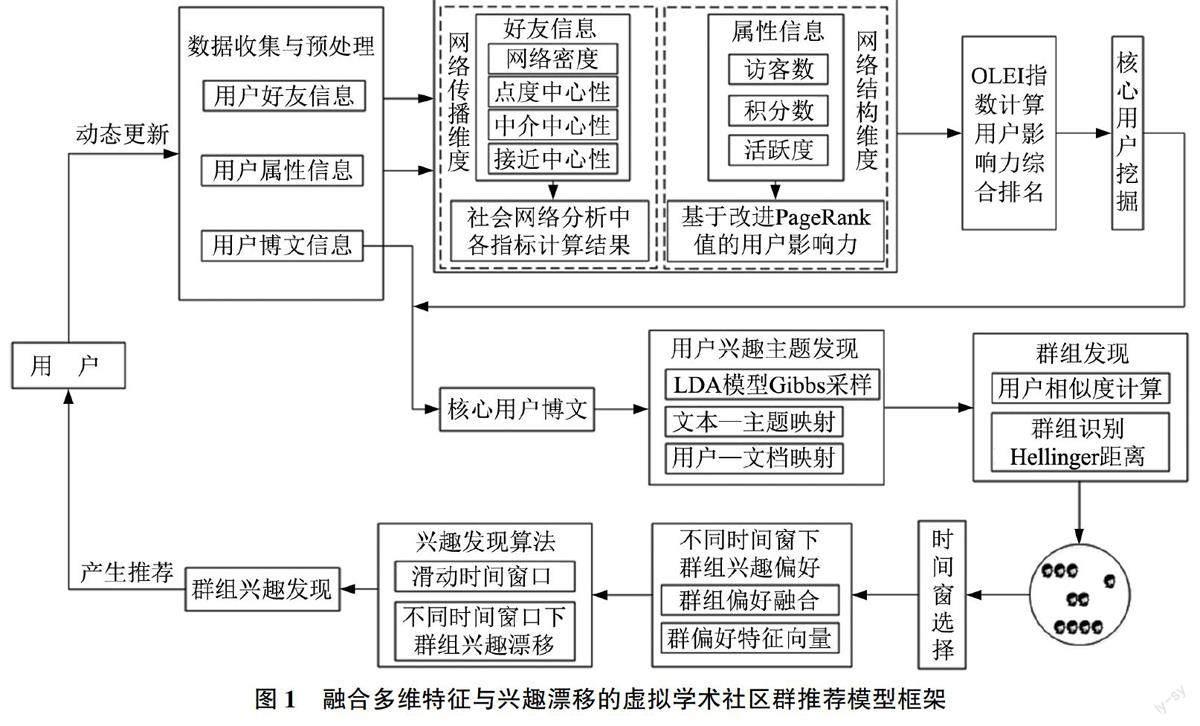
關鍵詞:虛擬學術社區(qū);核心用戶;偏好融合;興趣漂移;群推薦
DOI:10.3969/j.issn.1008 -0821.2023.07.006
[中圖分類號]TP391.3 [文獻標識碼]A [文章編號]1008-0821(2023)07-0048-16
知識經(jīng)濟時代,學科間的交流與互動越來越頻繁,不同實體通過知識媒介在分解、共享、轉(zhuǎn)移、整合的過程中極大地促進了知識間的交叉協(xié)同與融合發(fā)展。虛擬社區(qū)是為用戶提供在線交流與互動的平臺,其中知識的流動與共享決定了虛擬社區(qū)的競爭力、生命力與創(chuàng)新力,問答社區(qū)、在線健康社區(qū)、虛擬學術社區(qū)中社交網(wǎng)絡與知識網(wǎng)絡相互交織,共同推動個人、學術機構(gòu)或商業(yè)組織前進。虛擬學術社區(qū)作為一種新興學術交流平臺,將具有相似興趣的科研人員聚集在一起,拓寬了學術交流的渠道,豐富了學術交流的形式與內(nèi)容。隨著用戶逐漸成為虛擬社區(qū)的核心,有研究表明在虛擬學術社區(qū)中用戶呈現(xiàn)差異化及中心化的特征,表現(xiàn)為社區(qū)中存在不同群體的區(qū)分,并且用戶群體出現(xiàn)逐漸中心化的動態(tài)演變,這種動態(tài)演變能夠促進交互行為的增加,其中核心用戶群體在知識交流中擔任信息級聯(lián)傳播的角色,實現(xiàn)對核心用戶的信息推薦服務有助于推動知識傳播速率。除此之外,虛擬學術社區(qū)中存在個體信息匱乏、用戶網(wǎng)絡稀疏以及缺乏資源整合等缺陷,在個性化推薦時難免會出現(xiàn)因用戶信息較少以及數(shù)據(jù)稀疏導致推薦工作量大且效率不佳的問題,又由于虛擬學術社區(qū)內(nèi)信息分散并且知識質(zhì)量良莠不齊,極大地影響用戶間的知識交流,從而激發(fā)了知識服務方式的創(chuàng)新和高效知識發(fā)現(xiàn)策略的需求。……
登錄APP查看全文
