NLP“消失”之后
2023-07-18 15:46:10吳洋洋
第一財經 2023年7期
吳洋洋

ChatGPT的發布改變了很多人的工作,首先就是那些處理自然語言的工程師。
正在清華大學電子信息專業讀研二的蔡紫宴3年前決定換掉自己的專業,從經濟學轉到人工智能相關專業—“自然語言處理”(Natural L anguageProcessing,NLP)。
這是一個當時聽起來十分時髦的研究領域。非計算機專業的人對這個領域或許陌生,但只要你曾與蘋果的Siri等聊天機器人互動過,或是使用過Google翻譯、輸入法中的關鍵詞聯想功能,那么你就或多或少地接觸過NLP。
然而研究生入學一年多后,蔡紫宴就發現,他在課堂和比賽中學到的自然語言處理技術,正在快速迭代。
易變的前沿
“我們看到NLP領域很多研究都被ChatGPT‘消滅了。”四川大學神經網絡方向副研究員郭泉說,如果說此前學校里的學生、研究員們還在試圖通過不同的模型使機器更準確地完成分詞、提取人名等傳統N L P任務,那么ChatGPT已經可以跳過這些中間環節,直接生成結果,而且做得很好。
NLP是個古老的領域,但技術迭代周期在以翻倍的速度縮短。早在1940年代,工程師們就嘗試用提前設定好的規則(比如語法),訓練機器理解語言。1990年代,基于統計的技術開始應用到NLP中。2010年之后,深度學習成為主流。然后就來到了2020年,當年3月,OpenAI發布了其第3代大語言模型(LargeLanguage Model,LLM)GPT-3(基于Transformer)。
從時間跨度來看,NLP領域的技術迭代時間從最早的30年、20年減少到了10年—差不多是一位在這一領域求學的學生從大學入學到博士畢業的時長。
蔡紫宴擔心,再過兩年,他在學校和實踐中所學的技術都會被淘汰,“你對一些自然語言的理解可能被完全顛覆,在考試、實習時你當作定理來背的很多東西都沒意義了。”蔡紫宴說,他3年前開始學習自然語言處理的相關知識,當時主要與預訓練語言模型相關,雙向編碼的BERT模型更被看好,而如今GPT模型表現出了更好的潛力。
“這就像一棵進化樹,在一個分支十分輝煌后突然走向盡頭,另一個分支逐漸登上舞臺。”蔡紫宴說,如果早些年N L P 的研究類似于純手工的作坊,在2 017年G oogle提出Transformer和后來預訓練語言模型一統天下后,NLP領域的研究就像擁有了自動縫紉機的紡織工—現在,則進一步轉向全自動化底座的流水線。
學術期刊和會議對收錄論文的要求也一夕之間發生改變。蔡紫宴發現,但凡論文涉及模型效果,只要論文沒有理論性創新,就必須考慮“大模型”。不然,審稿人基本都會問“你的研究結果與ChatGP T相比表現如 何”。
進入“大模型時代”以來,技術的演進速度并沒有慢下來,而是更快了。從本科開始就在做自然語言處理研究的李然告訴《第一財經》雜志,2 019年到2021年,基于Transformer的語言處理模型主要還集中在BERT、GPT-2這類規模較小的模型上,但從2022年年末開始,GPT-3、GPT-4這類更大規模的預訓練處理模型能夠生成更長文本序列、具有更高的語義理解和生成能力。很快,李然就發現,實驗室里幾乎所有人都開始討論大模型。
2022年下半年,語言處理技術全面從傳統NL P轉入大模型的時候,李然結束了他的本科學習,進入研究生階段。
“那時就感覺地球要結束了。”李然說,之前的研究到底要不要繼續做下去、已有的技術積累是不是應該被推翻了、如果堅持的話堅持的意義是什么、之前研究的東西在未來還有沒有深入應用的價值……李然每天都在思考這些問題,但沒有答案。
不停奔跑,才能留在原地
蔡紫宴、李然所在的實驗室都開始嘗試轉型,從傳統NLP轉向“大模型”。不過這種轉向并非簡單改變研究興趣就能實現,而是涉及從芯片資源到數據資源的整體硬件改造。
李然稱,他所在的實驗室只能做一些參數量在10億到100億之間的模型訓練。而像擁有1750億個參數的GPT-3就“絕對做不了”。有消息稱,GP T-4的參數量已經達到1萬億。
蔡紫宴有相同的擔憂。在沒有GPT-3、GPT-4這些“大模型”的時候,單個實驗室甚至單個學生利用實驗室的普通服務器都可以做自然語言處理的研究,但只要想研究“大語言模型”(Large Language Models,L LMs),就需要聯合不同實驗室,甚至要帶著老師、實驗室的資源與校外公司合作,依靠對方提供的數據來做研究。即使是在清華,能做這種“龐大工程”的實驗室都不多,首先在算力上就有很高的門檻。
自然語言處理技術發展歷程
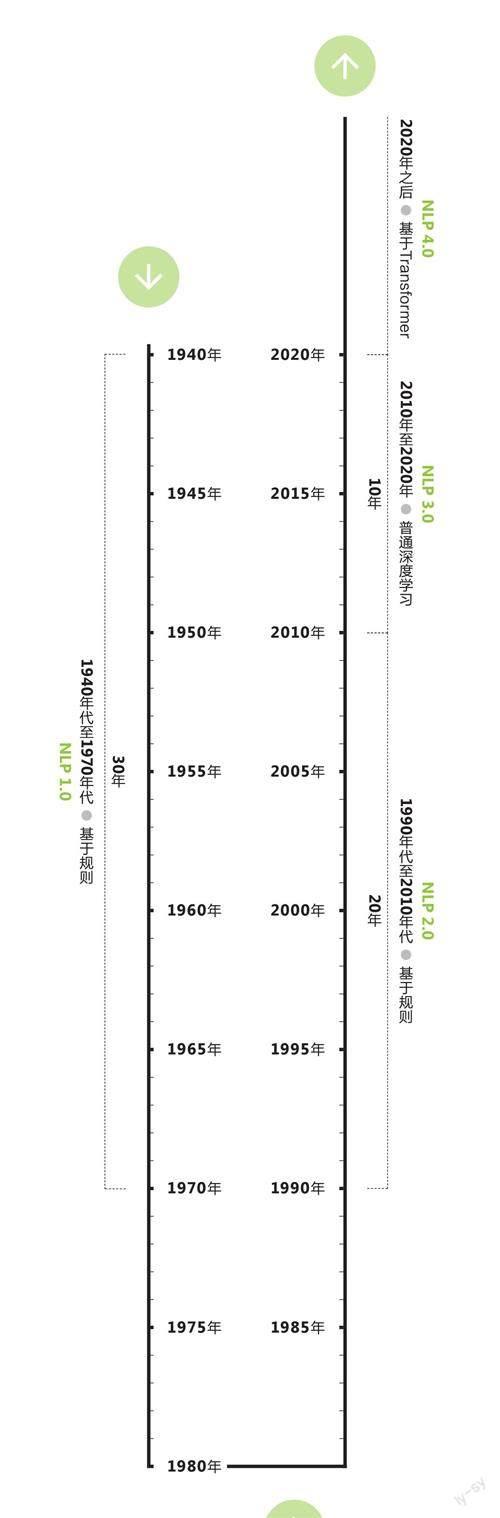
數據來源:根據公開資料整理注:GPT-3在2020年3月發布
大模型熱潮下,NLP領域變得更“卷”了。李然發現,自己好幾次冥思苦想找到的點子還沒付諸實踐,就已經被掛在了ArXiv(arxiv.org)上—該網站的論文通常是未經同行評審的預印本,但先發布就意味著先占坑。前幾天,李然做了半年的研究正要收尾,檢索ArXiv了解最新的研究進展和趨勢時,發現又有人做過了。
蔡紫宴相對“幸運”一些。他感興趣的是大語言模型如何與人類的價值觀對齊,使大模型輸出的內容更加安全并符合人類偏好。剛開始做研究時,這還是一個關注度不是很高的方向,畢竟當時的模型離“電子鸚鵡”相去甚遠,更談不上關注大模型的倫理與治理問題,業內一個月或者一個季度才會更新幾篇有重要貢獻的論文。但現在,ArXiv上不到兩天就會有一篇新的相關論文。
“論文更新的速度,普通研究者完全跟不上,大家都瘋狂往這個領域卷,羊駝、原駝……各種動物的名字都被用來命名大模型,從3月到現在新論文已經數不勝數。”蔡紫宴說。
被改變的職業路徑
技術大轉身,畢業后的去向成為NLP研究生們需要重新思考的問題。
蔡紫宴發現,身邊一些原本“很厲害”的同學都已經放棄讀博。他們一方面想要趕一趕“行業風口”,抓緊投身于這個急需算法工程師的行業,以快速積累經驗—以及財富。另一方面,蔡紫宴發現他們也擔心“如果四五年后讀完博士,可能技術通過迭代又發生了革命性的改變”。
“最糟糕的情況是你已經在NLP讀博一或者博二,研究目的是提高算法效率,但研究內容與大模型無關,那可能就要調整研究方向了。”蔡紫宴說。
本來想讀博的李然也開始迷茫。他發現,隨著技術前沿的劇烈變化,開展前沿研究的門檻越來越高,成本也越來越高,因此前沿研究更傾向于去工業界和企業做,而不是在高校實驗室里,高校學生想在算法研究領域發表論文越來越難,“我也不是天才”。李然說,他打算在前沿研究領域就此打住,去行業里面做一些落地的工程化應用。
蔡紫宴也看到了算法工程化—而非基礎研究方面—的學術和就業機會。
“大模型應用肯定會在近幾年徹底革命各類應用和系統,到時候所有的應用都可能被替換,這需要大量的工程師來維護,解決各種優化迭代、運營維護,或者是信息安全等問題。很多公司也有定制化模型的需求。”蔡紫宴說,比如,如果在移動設備端編譯運行大語言模型,工程師就可以通過編譯優化和壓縮模型權重,用低精度的方式來減少算力需求。
重新思考教育
2018年,國內共有35所高校獲得人工智能專業建設資格,其中多數為985、211院校。某種程度上,人工智能專業的設置體現了高校的前瞻性,但其學習和研究速度仍然遠遠趕不上技術迭代的速度。如果這群處在技術前沿專業的學生,在面臨技術拐點時都如此脆弱,那教育的價值到底是什么?
郭泉不需要像李然和蔡紫宴那樣焦慮自己的職業前景,他已經是四川大學神經網絡方向的副研究員。在ChatGPT發布之后,他進一步思考教育到底應該教什么這個問題。
他仍然贊同本科生和研究生要有不同的教學模式這種傳統。比如對于本科生,就要教他們打好學科基礎,高等代數、線性代數、概率論、機器學習、神經網絡等課程需要長期留在教學方案中。
“不需要跟著行業走,看行業里出現了自動駕駛、語音識別,課程就跟著調整,而是要看學生的思維構成需要哪些知識,要培養他們在一個領域思考的能力,前沿的行業應用只作為擴展和了解內容。”他對《第一財經》雜志說。
但是到了研究生階段,就要強調“提出問題的思維能力和解決問題的思維能力以及科研過程中的的動手能力”。
“我們不能把計算機當成理學來教,這必須是一個工程實踐相關的科學,所以我們要培養學生‘提出問題并解決它的能力。”郭泉說。這一點可以類比化學實驗,一個實驗需要某種特殊形狀的試管,但市面上沒有賣,如果學生有很好的實踐能力,就可以用酒精噴燈把實驗室里的試管燒成實驗需要的形狀。燒試管這件事情不會被發成論文,但燒試管后做出的實驗有可能產生重要的科研成果。
作為研究者,郭泉也反思了他對“問題”的定義。ChatGPT發布以前,他一直覺得“涌現”是偽科學,但現在,ChatGPT的出現讓他開始認為“涌現”是一個可以被提出、需要被思考的問題(注:ChatGPT發布后,很多人將神經網絡大到一定程度、喂養足夠規模的數據后出現的智能躍升現象,稱作“涌現”)。他對這個問題還沒有答案,但已將其列入自己的下一個研究課題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
電子競技(2019年22期)2019-03-07 05:17:26
電子競技(2019年21期)2019-02-24 06:55:52
電子競技(2019年20期)2019-02-24 06:55:35
電子競技(2019年19期)2019-01-16 05:36:09
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
