機器學習在新生兒壞死性小腸結腸炎診療中的研究進展
2023-07-17 07:17:40崔承陳飛龍綜述李祿全包蕾審校
中國當代兒科雜志 2023年7期
崔承 陳飛龍,2 綜述 李祿全 包蕾 審校
(1.重慶醫科大學附屬兒童醫院新生兒科/國家兒童健康與疾病臨床醫學研究中心/兒童發育疾病研究教育部重點實驗室/兒科學重慶市重點實驗室,重慶 400014;2.重慶郵電大學計算機科學與技術學院,重慶 400065)
新生兒壞死性小腸結腸炎(neonatal necrotizing enterocolitis,NEC)是新生兒期嚴重的消化道疾病,根據美國國家衛生統計中心數據,NEC 是2019 年美國新生兒死亡的十大原因之一,其病死率為0.094‰,高于2018年的0.079‰[1]。面對病死率增加和發病機制不明,動態監測、早期診斷治療是減少NEC 發生、改善預后的關鍵[2],目前多采用修正版Bell分級作為診斷標準[3],其診斷需結合癥狀、生化指標和腹部影像學動態評估,其中癥狀評估和影像學報告存在主觀性[4],且NEC 難以與食物蛋白誘發的小腸結腸炎和缺血性腸壞死區分,易誤診,導致非NEC 患兒接受額外的檢查和治療,延長住院時間,給家長帶來心理和經濟負擔[5]。漏診則會影響患兒預后。機器學習(machine learning)技術的發展為消除主觀性因素、減少漏診誤診提供了可能。
機器學習是人工智能(artificial intelligence,AI)的分支,其通過算法學習樣本數據以完成特定任務。近年來已廣泛用于醫療保健、電子商務、農業等領域[6],在判斷垃圾郵件[7]、預測企業風險中的成功應用[8],表明機器學習在診斷NEC,預測NEC風險方面具有潛力。
1 機器學習的分類和在醫療領域中的應用
機器學習算法可分為監督學習、半監督學習、無監督學習和強化學習等分支[9]。監督學習依據特征標簽進行分類,可用于疾病診斷、腹部X線片(abdominal radiograph,AR)分析等[10]。無監督學習側重根據特征對樣本進行聚類,如根據電子病歷數據對患者進行分組[11]。半監督學習介于上述二者之間,使用數量有限的標記數據訓練模型。強化學習通過獎懲機制和環境交互進行訓練,如根據糖尿病患者動態血糖水平調整胰島素劑量[12]。評價機器學習模型性能指標包括特異度、靈敏度、受試者操作特征曲線 (receiver operating characteristic curve,ROC 曲線)、曲線下面積(area under the curve,AUC)等[13]。
2 傳統機器學習在NEC診療中的應用
2.1 邏輯回歸
邏輯回歸(logistic regression,LR)是主要研究因變量(分類結果)及自變量(預測因子)之間相關性的監督學習算法。LR 通過預測每個預測因子變化時分類結果改變的概率,從而定量評估某疾病與各預測因子之間的關系[14]。
Cho等[15]對包括704例NEC患兒在內的10 353例極低出生體重兒進行統計分析,納入胎齡、出生體重、性別、出生年份和季節等74個預測因子,比較了人工神經網絡(artificial neural network,ANN)、決策樹(decision tree,DT)、LR、樸素貝葉斯、隨機森林(random forest,RF)和支持向量機(support vector machine,SVM)6 種算法,結果表明RF 和LR 準確率和ROC 曲線最優,在進一步分析NEC 危險因素中,LR 選出的可能預測因子為敗血癥、出生體重、妊娠糖尿病、動脈導管未閉(patent ductus arteriosus,PDA),RF 選出的可能預測因子是出生體重、出生體重Z值、產婦年齡和胎齡。但LR 處理胎齡和低出生體重等共線性因素時[16],會使方差增大,影響置信區間和假設檢驗[17]。
LR 在回溯NEC 高危因素時能展示權重,可解釋性強,有助于監測有早產、感染等高危因素的重點新生兒。但基于LR的回顧性研究尚未就危險因素達成完全共識。此外,人工篩選預測因子可能遺漏關鍵預測因子或納入共線性因子,從而影響LR結果[18],而納入無關變量會夸大預測結果的有效性[19],因此,未來篩選預測因子需避免納入共線性因子或遺漏關鍵預測因子,以充分發揮LR在NEC高危因素溯源中的價值。
2.2 DT
DT 是包含根節點、內部節點和葉節點,基于條件進行篩選的倒置樹結構算法[20](圖1)。可采用熵、Gini指數等作為內部節點篩選依據。葉節點中樣本種類越豐富,熵越大。DT 通過增加樹的深度讓熵快速下降從而聚類,具有天然可解釋性[21]。但隨著葉節點數量的增加可能導致過擬合。因此通常采用限制深度、修剪、增加驗證集等方法減少過擬合[22]。
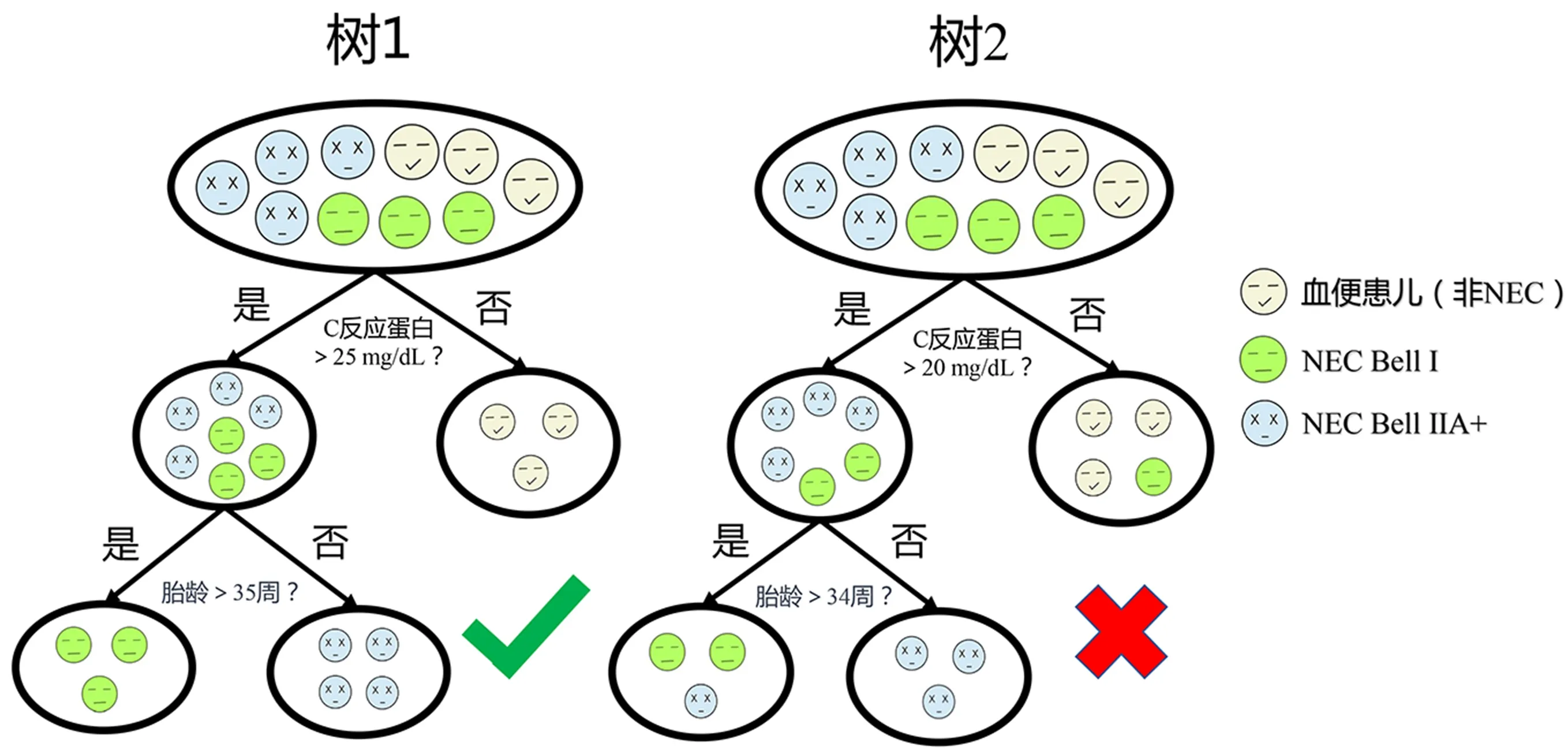
圖1 決策樹簡化模型 葉節點中樣本純度越高,熵、Gini指數越小。通過計算機計算近似所有可能結果后選擇最佳的樹。
Lueschow 等[23]收集了219 例NEC 患兒數據,比較7 種NEC 不同定義,通過DT 算法歸納出9 個NEC重要定義特征(呼吸暫停、嗜睡、糞便隱血、腹脹、胎齡、發病日齡、喂養量、彌散性血管內凝血、隱匿性直腸出血),發現修正版Bell 分級和英國NEC定義[24]在診斷NEC時,特異度較低(分別為0.402和0.504),但靈敏度較高(分別為0.706和0.745),更現代的定義(佛蒙特州牛津網絡定義[25]、國際新生兒聯合會定義[26]和“三選二”原則[27])具有更高的特異度(分別為0.667、0.897、0.880),但靈敏度較低(分別為0.314、0.225、0.294)。基于此,作者指出非Bell-NEC定義可能診斷NEC更準確。
2.3 RF
RF 通過從數據集中隨機選擇樣本和特征來構建多個DT,并聚合其結果進行預測[28]。其優點包括抗過擬合、快速處理高維數據、無需選擇特征,而局限性在于分類效果受樣本量影響較大。隨著樣本量增加,每棵樹中同類數據越多,分類效率越高[29]。
NEC 發生可能與腸道菌群、喂養方式有關[30-32],因此Masi 等[33]針對14 例NEC 患兒和34例對照組,通過宏基因組學測序644 個糞便樣本,整合喂養方式、胎齡等特征,用RF構建了母乳低聚糖和腸道微生物群組合的NEC 預測模型,成功地將87.5%的樣本分類為健康新生兒或NEC患兒。
2.4 SVM
SVM 是用于分類或回歸的監督學習算法,其通過最大化數據點在空間內類別與平面之間的距離,即找到最佳邊界(或超平面)。使每個類別在空間中的數據點到分類邊界的距離之和最大,因此也稱支持向量[34](圖2)。
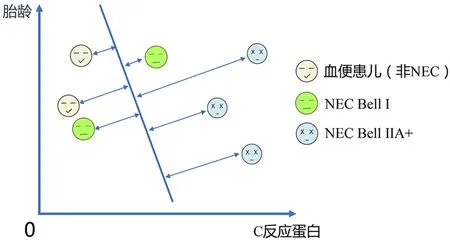
圖2 支持向量機簡化模型 樣本距最佳邊界越遠可信程度越高。通過計算機計算出最佳邊界,讓每類樣本距離最佳邊界盡可能遠。
李振宇[35]收集了564 例疑似NEC 早產兒的臨床和影像學數據,包括264 例NEC 組和300 例非NEC組,使用LR篩選與NEC相關的危險因素并建立回歸方程。然后使用遞歸特征消除、最大相關最小冗余、彈性網3種特征選擇方法篩選特征,并取特征交集(腸道擴張、門脈積氣、腸壁積氣等7個特征)和特征并集(腸道擴張、腸壁積氣、門脈積氣、妊娠糖尿病、PDA、腸鳴音減弱、血便等32個特征),使用SVM、多層神經網絡、XGBoost 3種算法建立NEC 診斷模型并進行性能評價。SVM在取交集時性能最優(AUC為0.919);多層神經網絡在取并集時性能最優(AUC 為0.933)。然而,Martin[36]認為,腸道擴張和門脈積氣等特征在NEC 定義中已發揮作用,因此不宜將這些特征再作為自變量,否則可能影響模型性能。
SVM適合處理數據特征較多的高維數據,但在處理大型數據集時需要大量計算資源和內存來儲存模型。且當樣本數據不足或存在過量特征時,高維空間的數據可能面臨維數災難,導致模型性能下降[37]。設置核函數可使SVM 處理線性和非線性數據,但如何設置核函數及超參數是SVM優化的難點。
2.5 梯度提升
梯度提升(boosting)是一類通過迭代訓練多個弱分類器來構建強分類器的集成學習算法,這類算法包括AdaBoost、XGBoost、LightGBM 等[38]。其在訓練過程中會根據先前分類器錯誤情況來調整樣本權重以訓練更準確的分類器。XGBoost基于梯度提升決策樹算法改進,引入正則化技術和自定義損失函數,支持并行計算提高預測速度并降低過擬合的風險,從而提高模型精度。
Weller[39]提取MIMIC Ⅲ數據庫中電子健康數據記錄,根據Bell 分期標準或臨床證據,確定了116 例NEC 患兒和464 例對照組。收集抗生素使用情況、出生體重、分娩方式、性別等48 個特征構建數據集并賦予相應分值,之后使用XGBoost訓練預后預測模型,并提前預警NEC可能發生的時間。
高文靜等[40]比較了3 個NEC 診斷模型,將248例符合腹瀉、腹脹、嘔吐、呼吸暫停和肌張力下降中任意一項的患兒作為數據集,通過五重交叉驗證,分為198 例樣本集和50 例測試集,統計了白細胞計數、血小板計數、心率、血壓等9個指標。采用DT、XGBoost 和ANN 構建預測模型,并對測試集50 例樣本進行分類預測。結果表明,XGBoost 算法在靈敏度、特異度和AUC 方面優于DT和ANN。
Gao 等[41]還開發了基于LightGBM 的多模態系統,LightGBM 是基于梯度的單邊采樣算法和排他性特征捆綁算法的樹模型,前者從樣本縮減角度出發,保留具有大梯度的樣本,同時通過單邊采樣降低計算成本,后者從特征約簡角度出發,捆綁互斥特征,減少樹的深度,提高模型泛化能力。作者收集了1 823例疑似NEC患兒的4 535張AR和年齡、心率等臨床數據,進行遷移學習并選出最優深度學習(deep learning,DL)模型SENet-154。然后使用827例疑似NEC患兒和379例確診NEC患兒的AR 進行訓練,篩選出AR 影像學重要特征,最終利用LightGBM 對診斷和手術預測數據進行學習,構建多模態AI系統。并對25例待確診病例進行分類診斷和手術預測,在雙盲下與低年資、高年資醫生進行外部驗證。該系統對診斷NEC 的AUC 為0.934,對手術預測的AUC 為0.941,與高年資醫生判斷結果相當。
Boosting 在多特征稀疏數據集和小規模數據集中表現欠佳,易導致過擬合,需引入正則項控制模型復雜度,但該算法準確性高,可解釋性好,有一定應用潛力。
3 DL在NEC診療中的應用
DL 是有多層次隱藏結構的機器學習方法,通過學習數據特征和規律,從而高效處理和精準預測各種任務,如圖像分類、自然語言處理、語音識別等。 DL 包括ANN、 卷積神經網絡(convolutional neural network,CNN)、生成對抗網絡等形式。
3.1 ANN
ANN 通過人工神經元模擬了大腦神經網絡中樹突的接收功能和軸突的信號輸出功能[42](圖3~4)。
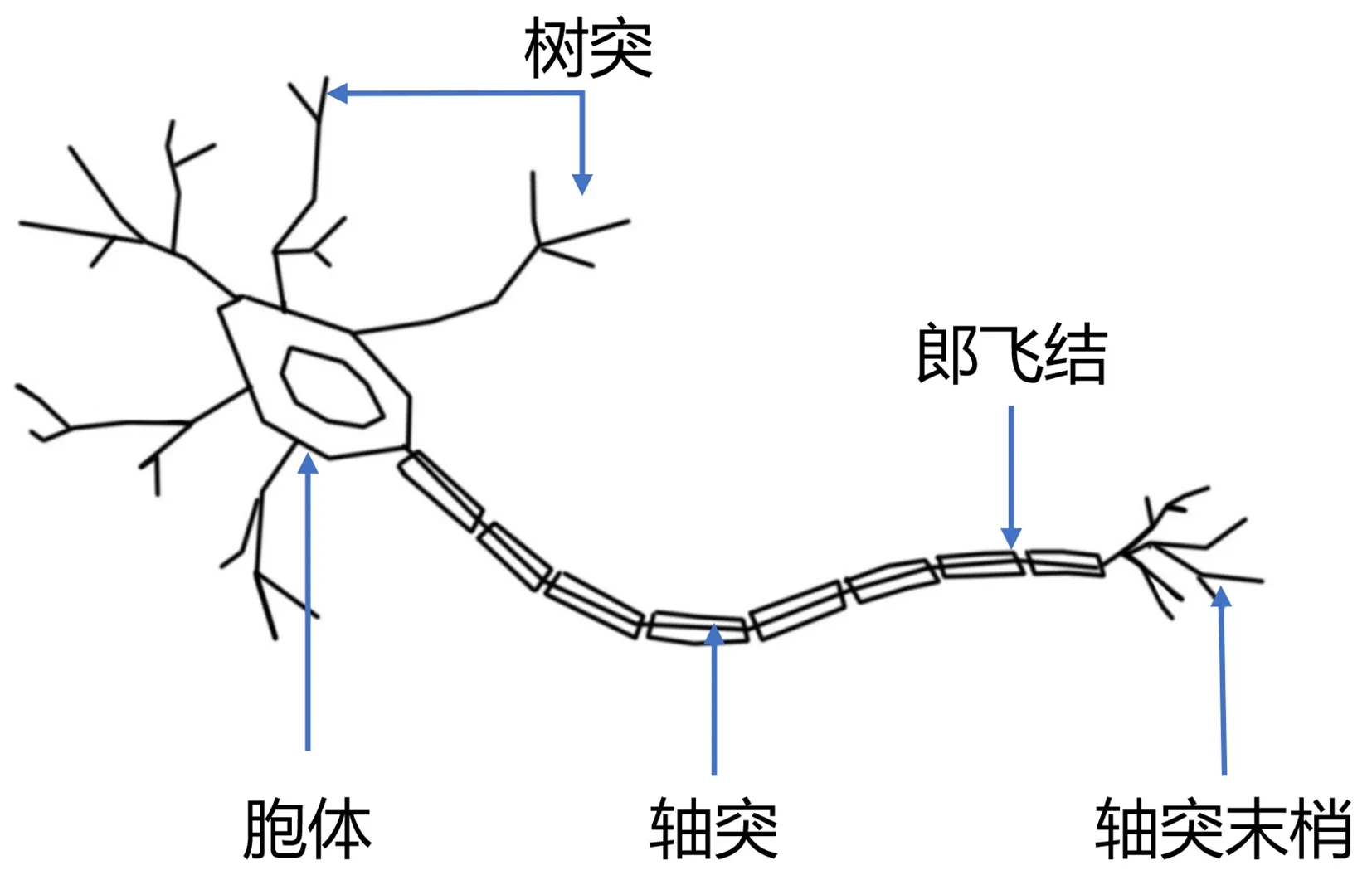
圖3 神經元示意圖

圖4 神經網絡簡化模型 每個人工神經元接受多個輸入信號經計算機處理后作為下層神經元的輸入信號,最終輸出結果。
Irles 等[43]使用ANN 從76 例NEC 和腸穿孔患兒數據中學習,構建了包括23 個特征的出生時ANN 模型和包括35 個特征的住院期間ANN 模型,特征包括產婦年齡、絨毛膜羊膜炎、胎齡、性別、出生體重、血氣分析等,作者使用反向傳播算法構建了三層神經網絡,認為在生后24 h 內,動脈血氣(二氧化碳分壓和碳酸氫根離子)是預測NEC的重要因素,而對于住院期間患兒,PDA、使用母乳強化劑、早發敗血癥、低血壓等是導致NEC腸穿孔的重要因素。
Son 等[44]基于ANN 算法改良,開發了用于早產兒腸穿孔的早期預測模型,作者使用了12 555例患兒數據,包括521 例NEC 腸穿孔患兒、208 例NEC 自發性腸穿孔患兒和一個無NEC 對照組,預測因子包括胎齡、低出生體重、呼吸窘迫綜合征、使用糖皮質激素、低血壓、膿毒血癥和PDA 等,作者通過引入批歸一化和隨機失活技術,分別建立了預測NEC 和NEC 腸穿孔的兩分支。經內部驗證,該模型優于傳統算法。
3.2 CNN
CNN是一種模擬動物視覺皮質的DL 算法,采用卷積層和池化層來提取圖像特征,并使用多個全連接層來實現圖像分類和識別[45]。由于NEC 患兒可出現腸壁積氣、門脈積氣、氣腹等影像學表現[2],因此有學者采用CNN 對NEC 患兒臨床特征和AR圖像進行自動分類。通過卷積核和池化層來提取AR或腹部超聲的特征,與NEC病理學活檢結果對比,最終生成特定顏色熱圖以突出AR圖像中病理學特征。綜合臨床表現和AR特點,評估患兒是否診斷NEC及是否需要手術干預[10]。
3.3 多示例學習
多示例學習(multi-instance learning,MIL)是一種能夠在缺乏固定標記的情況下學習實例集的框架。Lin等[46]開發出一個基于注意力機制的門控MIL 系統,收集糞便微生物群以門綱目科屬分類,產生高維度、低信號強度數據進行風險識別。對患兒的臨床指標及微生物菌群數據預處理后,注意力池化模塊為每個實例分配注意力權重,以動態調整NEC 風險評分,并對最有用的微生物菌群分類特征進行解釋,實現了早期、精確的NEC 預測。此外,引入“增長袋分析”,將MIL 應用于縱向臨床樣本,將MIL模型中置信度分數轉為動態風險分數,結合新生兒日齡及既往評分動態評估,從而量化患NEC的可能性。當風險評分為0.35時,總體靈敏度為86%,特異度為90%。但有研究認為嬰兒腸道菌群與分娩方式存在相關性,如剖宮產的嬰兒腸道菌群更接近母體皮膚定植細菌,感染、喂養方式、使用抗生素等因素也能改變腸道菌群[47]。這可能影響該算法預測NEC的準確性。
DL可以從大量數據、圖片中提取到復雜關系,在NEC 研究中應用廣泛。然而,DL 缺點明顯,例如輸出層通過算法從數據集中提取,模型內部結構和計算過程不可見,因此可解釋性差,又稱黑盒[48]。這可能導致錯誤的診斷或治療決策[49]。
4 挑戰和展望
機器學習在NEC應用上面臨4個技術問題,即數據通用性、模型可用性、模型可解釋性和模型精度不足。單中心、小樣本研究可能導致數據通用性不足,樣本過小易產生選擇偏倚和過擬合,因此需要大型多中心研究。
構建可用的NEC 診斷模型需收集多個特征,但設計過多特征,現實中可能導致數據收集不及時或數據缺乏時效性,反之,特征過少將影響模型性能。因此,未來設計模型中,需平衡特征數量以確保模型可用性。
DL 和SVM 具有黑盒結構,缺乏可解釋性,這將導致模型可信任度不高,且糾正模型困難[49]。有學者通過降維、靈敏度分析和可視化輔助工具來解釋模型[50],也有學者認為高性能機器學習模型,無需可解釋性即可循證[51]。但即便如此,現有算法模型仍存在性能不足問題,未來可能的研究方向之一是引入時間維度,考慮特征出現的先后順序和變化趨勢對NEC 診斷的影響。因此,循環神經網絡、長短期記憶遞歸神經網絡等時間序列算法應得到重視,這些算法在文本識別、語音識別等領域已取得不錯成績,也許有望在NEC 研究中發揮重要作用。
機器學習算法在NEC 應用中還涉及倫理和法律問題,即如何處理醫生與NEC 模型的沖突和預測模型的法律責任問題。雖然目前NEC 預測模型已在回顧性研究中進行廣泛探討,但所有研究均未能指出如何解決醫生經驗與模型結果之間的沖突。隨著NEC 預測模型的發展,模型和醫生決策孰更可靠,可能困擾患兒家長,加劇醫患間不信任感[52]。在法學界,AI的法律責任問題仍有爭議,但無論是獨立責任理論還是代理責任理論都沒有回答AI 是否具有法律地位及其如何承擔法律責任的問題[53],這也將是NEC模型應用的障礙。
5 小結
機器學習算法可應用于NEC的病因回溯[15,43],預測診斷[10,41]和定義研究[23]。但迄今仍缺乏可被廣泛接受的NEC機器學習預測模型。
在未來,完善和優化AI 相關法律、納入高質量大型多中心數據集、構建高精度算法模型或解決黑盒問題,將為機器學習在NEC 診療中的應用提供更好支持。
利益沖突聲明:所有作者聲明無利益沖突。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
