基于雙向長短期記憶網絡的醫院電子病歷數據挖掘
2023-07-07 03:10:10倪凌
計算機應用與軟件 2023年6期
倪 凌
(江蘇省第二中醫院 江蘇 南京 210000)
0 引 言
大型醫院在每天診療過程中產生了大量的醫療數據,包括門診病歷、臨床醫療數據、患者意見等[1]。這些數據大多以文本形式存儲于數據庫中,若通過人工對此類文本信息進行歸檔和分析,將耗費龐大的人力成本。隨著人工智能技術的飛速發展,對醫療文本信息進行智能提取、識別和分析成為了可能[2]。在實際的臨床治療過程中,存在許多實驗性質的藥物治療方案[3],一方面可通過醫學指標數據判斷藥物的效果,另一方面也可通過電子病歷觀察治療的結果,因此對電子病歷進行分析具有重要的應用價值。
觀點挖掘技術已經得到了深入的研究,大多關注于電影評論[4]、圖書評論[5]、社交網絡[6]和短新聞[6]等文本數據的挖掘,這些文本內容大多滿足語法約束,且詞匯的分布較為集中,傳統的n-gram、CBOW和skip-gram等詞嵌入模型即可較好地學習文本的特征,再通過分類器對用戶觀點進行標注。此類方法包括基于n-gram的Youtube觀點挖掘算法[7]、基于CBOW的方面級情感信息提取技術[8]和基于skip-gram的語義聚類技術[9],這些技術均達到了令人滿意的性能。
醫療領域的文本數據存在兩大特殊之處:(1) 醫生專家往往輸入大量的專業名詞和短語,而其中一部分名詞和短語不符合常規的語法或語義;(2) 患者描述的文本內容非常口語化且不滿足醫療系統規范,導致語義實體的邊界較模糊。依然有學者對醫療文本數據完成了有效的研究,文獻[10]將卷積神經網絡、雙向長短期記憶網絡和條件隨機場結合,先利用卷積層捕獲詞語之間的邊界特征,把特征傳遞給長短期記憶網絡進行訓練和預測,再由條件隨機場模型對序列進行標注,該方法對臨床文本的復合實體識別具有突出的優勢。其他針對醫療文本的研究大多針對英文文本,如基于概率模型的生物醫學文本分析[11]和基于頻繁項集挖掘的醫學自動摘要技術[12],而中文與英文的語義本體之間存在較大的差異,因此很難把英文文本分析技術直接應用到中文文本分析問題上。
為了進一步完善醫院信息化建設的進程,對電子病歷數據實現智能且高效的分析,設計基于循環神經網絡的臨床大規模文本數據分析算法。首先,對詞嵌入模型進行修改,使其更加適合醫療領域,提高所提取方面項的性能。然后,把提取的方面項作為標記數據訓練Bi-LSTM網絡,雙向LSTM學習詞語的正向與反向方向上下文信息。以句子“吃完藥后非常有精神!”為例,如果是沒有注意力機制的原LSTM,那么提取的目標詞語為“藥物”,顯然未能全面捕捉到句子的語義。本文在Bi-LSTM中設計了注意力機制學習方面項之間的長期依賴關系,包含注意力機制的LSTM所提取的目標詞語則為“藥物”和“精神”,這兩個詞能夠更好地表達該句子的語義。最終通過Softmax層對方面項的情感進行標記。本文系統主要有三點貢獻:(1) 設計了醫療領域名詞處理技術,過濾與醫療領域相關性高的名詞;(2) 通過雙向長短期網絡學習詞語的前文、后文語義,并設計注意力機制學習目標詞語之間的長期關聯性;(3) 把提取的方面項作為詞語的標簽,與其他語法特征一起送入Bi-LSTM模型學習,提高了特征的豐富性。
1 問題模型
圖1所示是一個出院患者的評價實例,患者給出的評價內容為“劉醫生很有耐心,診斷精準有效”。觀點對象為劉醫生,方面項為服務態度和醫術,兩個方面項的情感極性均為正面。電子病歷數據挖掘系統的目標是對病歷中的文本進行分析,提取出每個方面項,并通過深度學習技術智能地識別每個方面項的觀點(情感極性)。
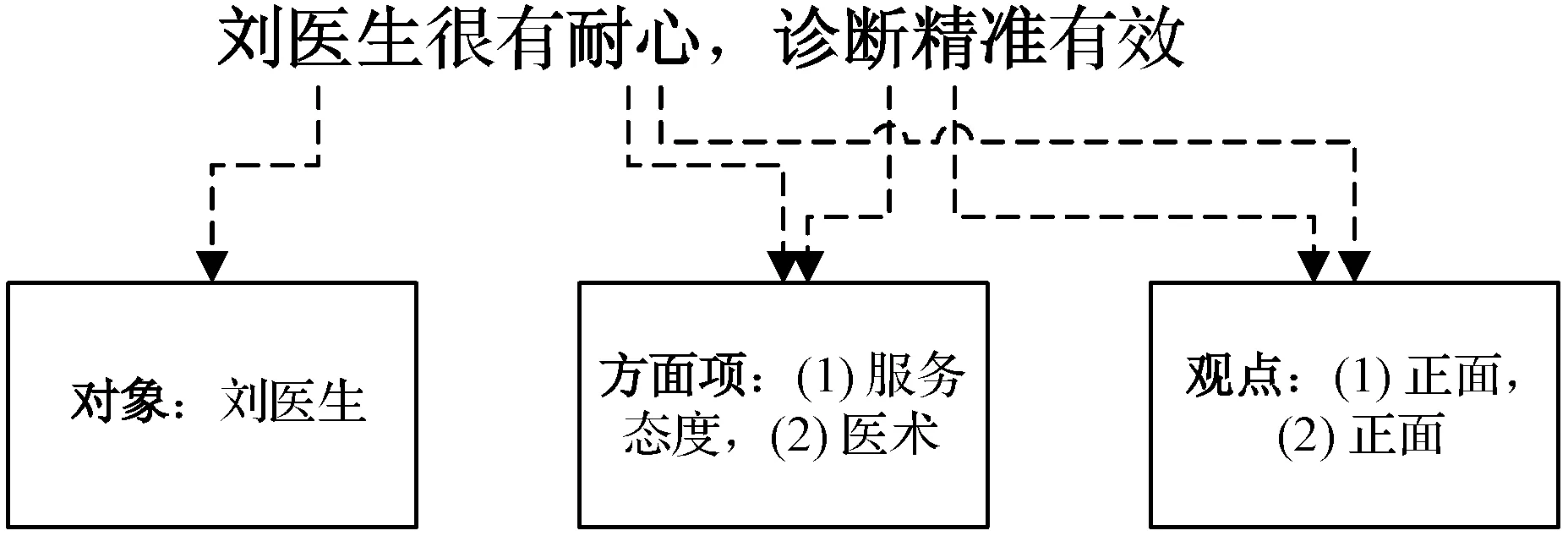
圖1 醫療文本觀點的本體劃分
2 總體框架與相關技術設計
本文提出一個兩步驟的方法來實現文本的方面項提取,流程如圖2所示。第1步提取細粒度名詞或短語,第2步借助臨床醫療語料庫對細粒度名詞進行過濾和重組。
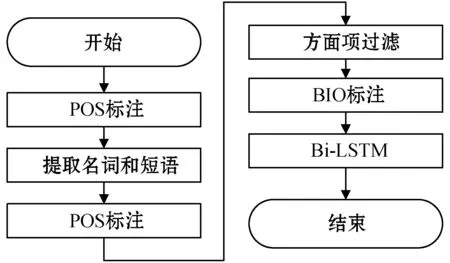
圖2 臨床文本數據方面級觀點識別的算法流程
2.1 提取方面項
電子病歷包含大量的醫學名詞和短語,采用Stanford Parser的chinese-distsim.tagger模塊工具[13]提取中文的方面項。該工具在處理不符合語言規范的文本內容時錯檢率和漏檢率均較高,例如:“吃了感冒藥第二天感覺好了很多”,Stanford Parser的分割結果為感冒//藥//好。該句子的方面項應該是“感冒藥”,但Stanford Parser把“感冒藥”識別成了兩個方面項“感冒”和“藥”。因此Stanford Parser生成的POS標記名詞無法準確地識別語義層面的名詞和短語,本文對Stanford Parser進行了擴展,提高對醫療文本方面項提取的效果。
采用Stanford Parser的chinese-distsim.tagger模塊工具將句子分解,標注每個名詞的細粒度token,將這些細粒度名詞稱為潛在方面項。以“吃了感冒藥第二天感覺好了很多”為例,Stanford Parser處理后的結果為“吃了(VB)|感冒(NNP)|藥(NNP)|第二天(DT)|感覺(VB)|好了(JJ)/很多(RB)”,具體如圖3所示。
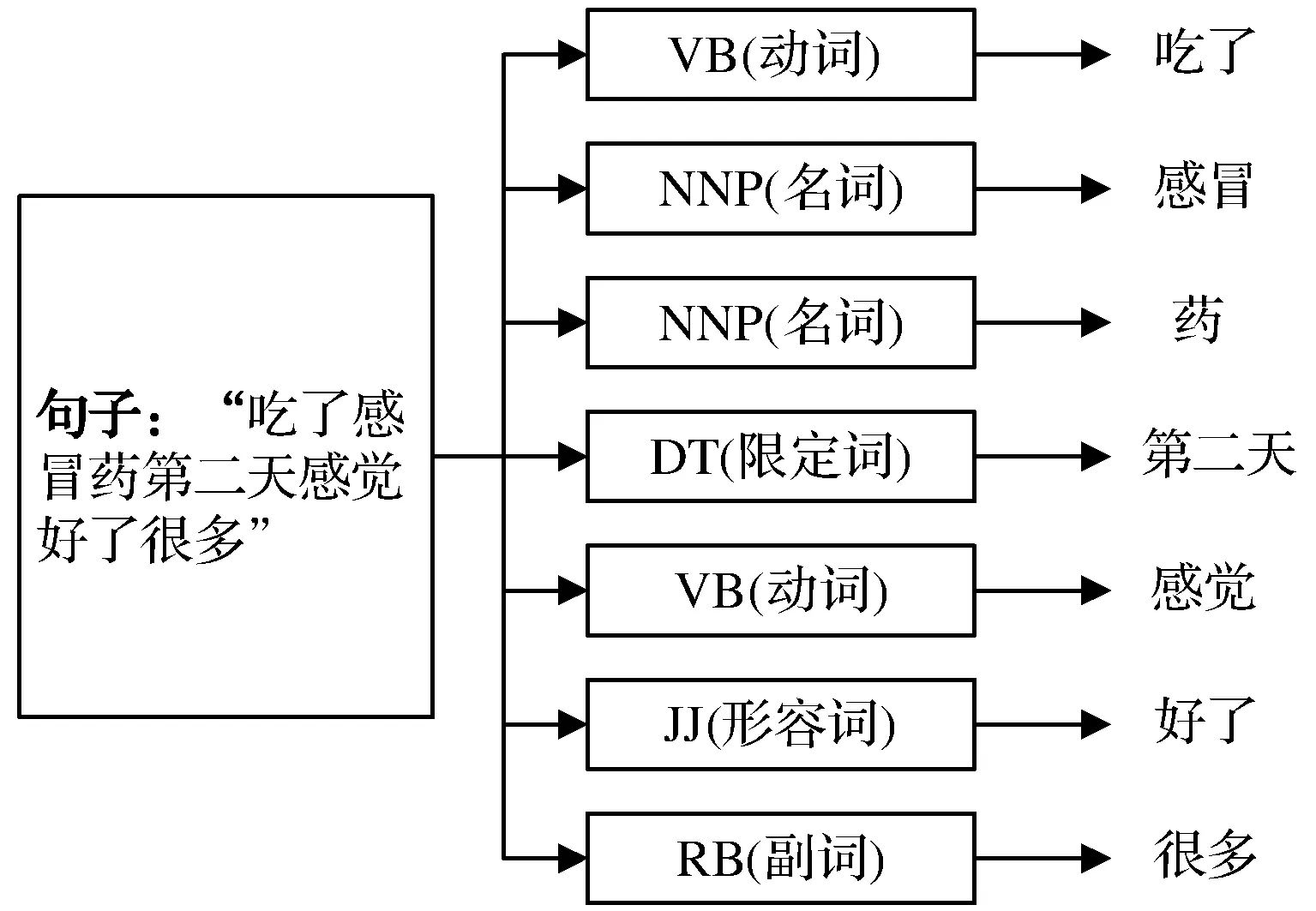
圖3 Stanford Parser細粒度token標注實例
2.2 醫療領域名詞處理
上一部分提取了所有文本的潛在方面項,其中一些方面項與醫療領域無關。例如:“病人是南京大學的一名學生”,潛在方面項“大學”與醫療領域的相關性較低,因此設計了方面項過濾技術排除與醫療領域不相關的潛在方面項。圖4所示是醫療領域名詞處理的流程,利用收集的臨床醫療語料庫訓練詞嵌入模型Word2Vec[14]或者GloVe[15],再利用訓練的模型把輸入文本轉化成向量形式。
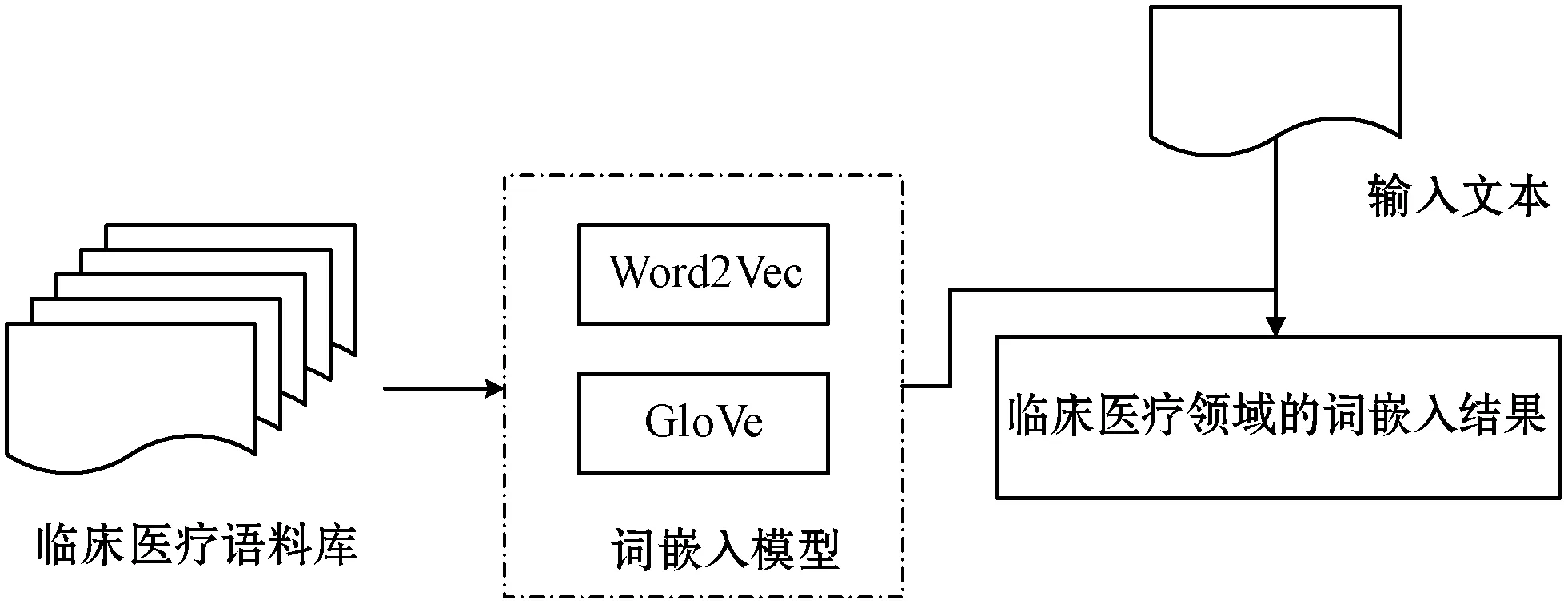
圖4 醫療領域名詞處理的流程
首先計算輸入文本A中所有潛在方面項ni詞wi的詞頻fi,把詞頻較低的名詞刪除,根據預處理實驗的結果,將過濾不相關詞的詞頻閾值設為(lenth/30),其中lenth為文本的句子數量。基于剩余的名詞建立頻繁詞集W和詞頻集F,然后采用余弦相似性度量名詞與語料庫之間的語義相似性,相似性越高說明該名詞與醫療領域的相關度越高。we(ni)與we(D)的相似性定義為:
(1)
式中:we(ni)表示詞wi的權重,we(D)=1表示醫療領域預分配的權重。
3 基于Bi-LSTM的觀點識別算法
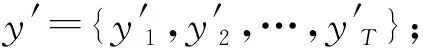
3.1 句子標記
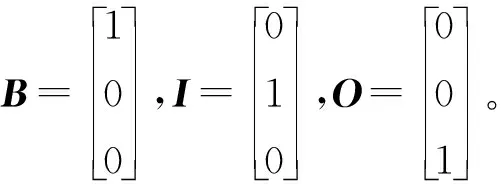
3.2 特征提取
采用詞嵌入提取方面項特征,采用POS標注提取觀點特征。
(1) 方面項特征提取:Word2vec是構建連續詞向量表示的常用方法,Word2vec包括Skip-gram和CBOW兩個模型。通過預處理實驗訓練Skip-gram和CBOW兩個模型,最終兩個模型的超參數選定如下:向量維度D為300,上下文窗口為20,negative_sample_size為10,下采樣值為1×e-3,學習率為0.05。Skip-gram和CBOW為每個詞生成一個300維的向量。GloVe模型的超參數選定如下:向量維度D為200,窗口大小為15,verbose參數為2,最大迭代次數為45。
(2) 觀點特征提取:首先把輸入句子S={X1,X2,…,XT}表示成token序列,例如:“感冒”是第232個詞,那么pv等于232,將句子表示為索引序列ps=[pv(X1),pv(X2),…,pv(XT)]。設wt表示第t個詞在句子中的嵌入向量,將wt和Xi間的關系定義為:wt=E[pv(Xn)],將輸入句子表示為詞嵌入向量的序列W={w1,w2,…,wT}。
由于方面項大多為名詞,所以將POS標注作為每個詞Xi的附加特征。采用獨熱編碼將POS標注編碼成K維向量,再使用Stanford POS標注器把POS向量編碼成6維的二值向量。假設輸入句子每個詞的POS標注向量為P={p1,p2,…,pT},那么最終輸入句子每個詞的特征向量定義為:
X={x1,x2,…,xT}=
{(w1,p1)T,(w2,p2)T,…,(wT,pT)T}
(2)
3.3 Bi-LSTM的網絡結構
將式(2)的序列傳入Bi-LSTM,提取句子的方面項。圖5所示是包含注意力機制的Bi-LSTM網絡結構。
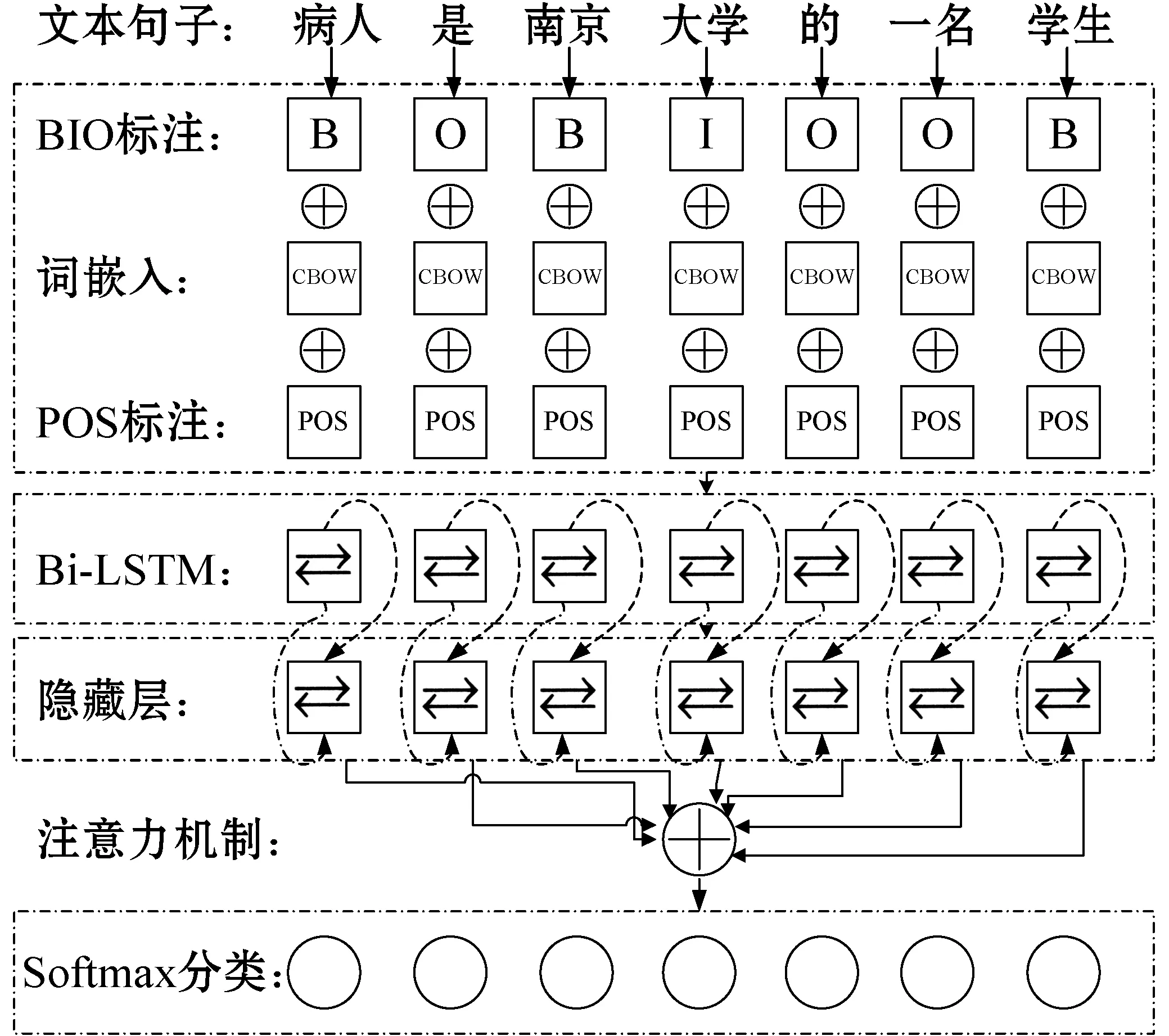
圖5 Bi-LSTM網絡的拓撲結構
Bi-LSTM的嵌入層參數dropout設為0.5以防止過擬合。編碼器讀入序列X學習隱藏層響應H,將時間步t輸入詞在Bi-LSTM中的隱藏響應向量ht表示為:
ht=bi_LSTM(ht-1xt;θen)
(3)
式中:ht-1為上一個狀態的隱藏層激活;xt為輸入數據;θen為網絡參數集。
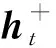
bi_LSTM+(ht-1,xt;θen)⊕bi_LSTM-(ht-1,xt;θen)
(4)
Bi-LSTM網絡從時間步t-1到時間步t的更新過程可建模為:
it=sigmoid(Wi[ht-1,xt]+bi)
(5)
ft=sigmoid(Wf[ht-1,xt]+bf)
(6)
ot=sigmoid(Wo[ht-1,xt]+bo)
(7)
(8)
(9)
ht=ot⊙tanh(ct)
(10)
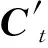
由于句子每個詞對觀點挖掘的重要性不同,并且句子不同方面項之間存在關聯性,常規的Bi-LSTM網絡無法識別詞的重要性。因此為Bi-LSTM增加注意力機制,通過該機制區分每個詞對觀點感情的影響,然后將詞向量及其權重組成一個密集向量。圖6所示是所設計注意力機制的結構。
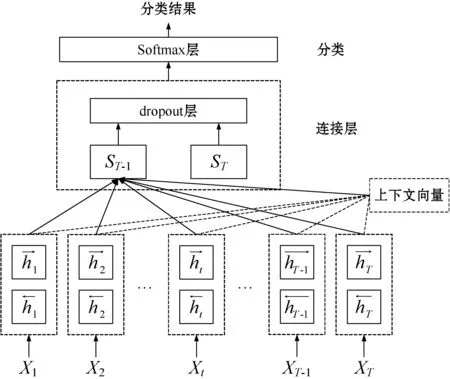
圖6 實現注意力機制的結構
假設在時間步t輸入注意力機制的句子為X={x1,x2,…,xT},Bi-LSTM隱藏層響應ht傳入前饋網絡,經過注意力機制處理,產生的解碼響應st可定義為:
st=f(st-1,yt-1,ct)
(11)
式中:st-1為上一個時間步的解碼響應;yt-1為上一個時間步的輸出;ct為上下文向量。
解碼器網絡根據上下文向量ct和句子X預測下一個時間步的標簽yt,然后以相同的方式預測之前的標簽序列[y1,y2,…,yt-1]。
上下文向量ct的計算方法為:
(12)
式中:αti={αt1,αt2,…,αtT}為注意力權重。
假設網絡的輸入為st-1和hi,前饋網絡Bi-LSTM計算出注意力能量集eti:
eti=Bi_LSTM(st-1hi)
(13)
假設激活函數為tanh(),方面項嵌入向量為eva,權重矩陣為W和U,那么注意力能量集eti可計算為:
eti=eva·tanh(Ust-1Whi)
(14)
目標序列的聯合概率可定義為:
(15)
將每個詞概率最高的標注作為Bi-LSTM預測的IOB2標注,每個時間步t預測的標注作為一個情感分類,將最小化分類交叉熵損失函數H()作為訓練網絡的代價函數:
(16)
式中:qi為詞的IOB2標注;pt為期望概率分布;K={I,O,B};pt(k)∈{0,1};qt(k)∈[0,1]。
注意力機制輸出第i個標簽的概率,再經過softmax函數計算注意力的權重ati,計算方法為:
(17)
4 實驗與結果分析
編程環境為Java JDK 1.6,軟件環境為Windows 10操作系統。PC處理器為i7-10750H,主頻為2.60 GHz,內存大小為8 GB。
4.1 實驗數據處理
在江蘇省第二中醫院的數據庫中收集了500份臨床電子病歷和500份門診病歷,使用NLTK工具箱[17]對句子進行分割和標點符號預處理。由助理醫師對每份病歷的方面項和情感類型進行標注,最終共產生約30 000個不同詞匯,這些詞匯作為醫療領域語料庫,用于訓練Skip-gram、CBOW和GloVe三個詞嵌入模型。采用五折交叉檢驗方法完成驗證實驗,隨機選擇800份病歷作為訓練集,剩下的200份病歷作為測試集。
4.2 性能評價標準
采用三個常用指標評價觀點挖掘系統的性能,分別為精度P、召回率R、F1-measure。
精度P定義為真正例數量占真正例和假正例總和的比例,計算公式為:
(18)
式中:TP表示真正例數量;FP表示假正例數量。
召回率R定義為真正例數量占真正例和假反例總和的比例,計算公式為:
(19)
式中:FN表示假反例數量。
F1-measure定義為精度與召回率的調和平均值,計算公式為:
(20)
4.3 參數實驗
式(1)計算的相似性值是過濾醫療領域相關名詞的關鍵參數,因此首先通過實驗觀察不同相似性閾值對醫療觀點識別精度的影響,將余弦相似性閾值分別取值0.65、0.7、0.75、0.8、0.85,結果如圖7所示。Skip-gram與CBOW兩個詞嵌入模型的最優相似性閾值為0.75,GloVe模型的最優相似性閾值為0.8。當相似性閾值較小時,數據集中包含了較多與醫療領域不相關的方面項,而這些方面項對Bi-LSTM網絡產生干擾,導致Bi-LSTM的精度下降。當相似性閾值較大時,一些與醫療領域相關的方面項被誤刪,導致了Bi-LSTM的精度下降。下文實驗將Skip-gram與CBOW兩個模型的相似性閾值設為0.75,GloVe模型的相似性閾值設為0.8。
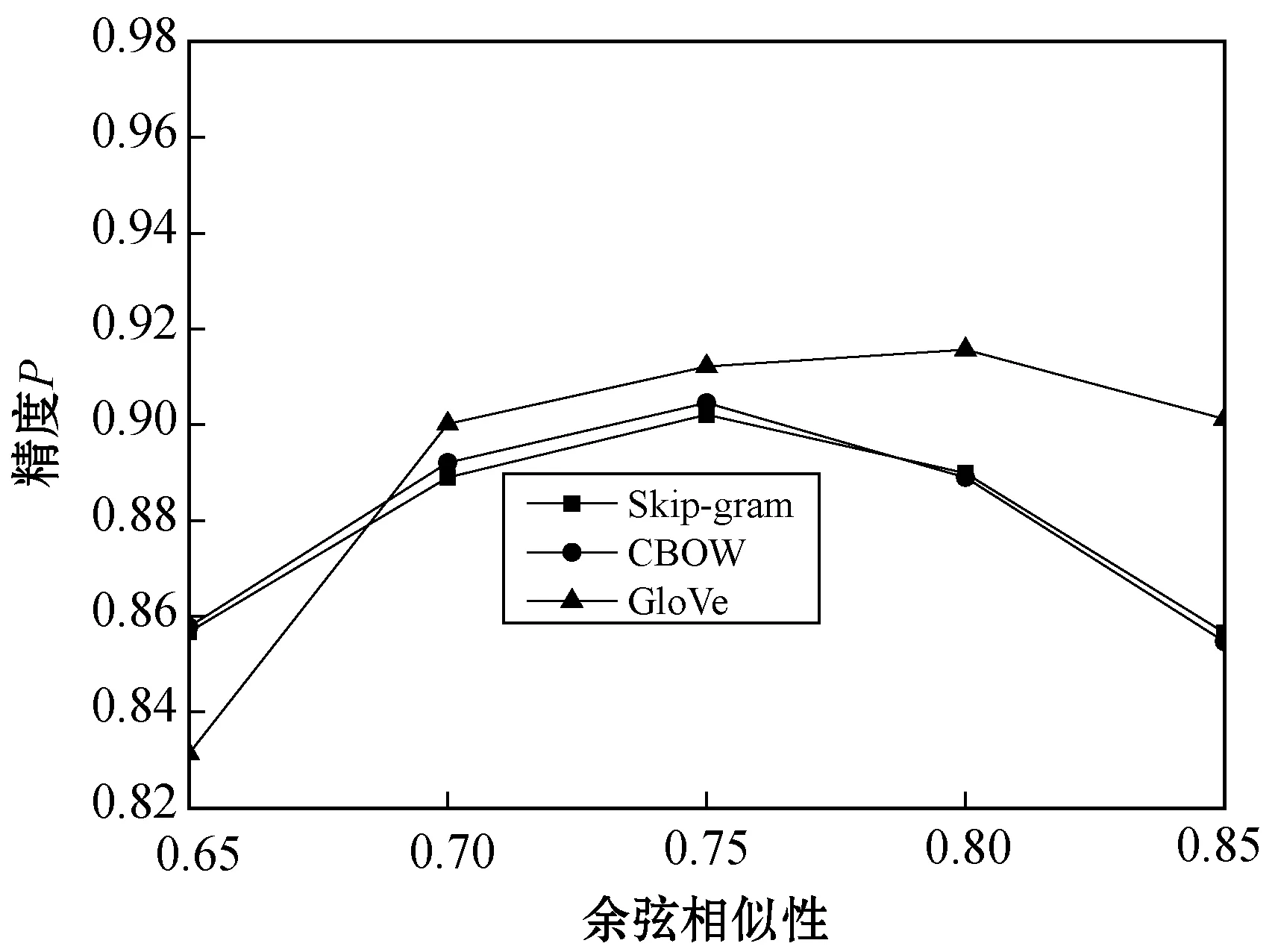
圖7 不同相似性閾值對觀點識別精度的影響結果
4.4 對比實驗分析
目前尚未出現專門針對醫療領域觀點挖掘的有效技術,大多是針對電影評論、圖書評論等日常生活文本的觀點挖掘技術,因此選擇了5個觀點挖掘算法與本文算法完成對比實驗。所選取的5個對比算法均支持不同的語料庫,分別為基于多特征融合和LSTM的方面級觀點挖掘算法LSTM-CRF[18]、基于雙向LSTM的兩分類方面級觀點挖掘算法BiLSTM[19]、基于循環神經網絡的評論觀點挖掘算法RNN[20]、基于雙向卷積門控循環單元的觀點挖掘算法C-GRU[21]、基于自然語言多語法特征融合的觀點挖掘算法NLP[22]。其中BiLSTM與RNN僅支持兩個情感分類,即積極(positive)和消極(negative),其他算法均支持三個情感分類,即積極(positive)、消極(negative)和中性(neutral)。LSTM-CRF先對每個詞進行語法標注,提取上下文感知的特征集,再通過Bi-LSTM實現對觀點情感的識別,該模型在LSTM之外通過提取上下文特征實現對語義的識別,而本文算法則在LSTM內部通過注意力機制實現對上下文語義的識別,由此可觀察兩種策略的有效性。BiLSTM、RNN和C-GRU三個算法則是分別通過長短期記憶網絡、循環神經網絡和門控循環單元識別詞語的上下文語義,通過這三個算法可觀察不同深度學習網絡的性能差異。上述5個觀點挖掘算法在本文收集的醫療領域語料庫上再次進行訓練,在相同的實驗條件下與本文算法進行比較。本文算法分別采用Skip-gram、CBOW和GloVe三種嵌入模型完成實驗,分別簡記為LSkip、LCB和LGl,觀察不同詞嵌入模型對算法性能的影響。
圖8所示是不同算法的方面級觀點識別精度結果,可以看出,本文算法采用GloVe詞嵌入模型的性能優于Skip-gram與CBOW兩個模型。深度雙向C-GRU網絡是一種可兼容不同語料庫的觀點挖掘模型,因此不僅在圖書評論問題和電影評論問題上取得了理想的效果,在醫療文本挖掘領域也明顯優于其他幾個模型。本文算法考慮了BIO標注、詞嵌入向量、POS標注,因此能夠更加全面地提取每個方面項在文本中的上下文特征,再結合注意力機制能夠關注于語義重要性高的方面項。此外,本文算法通過2.2節的“醫療領域名詞處理”過濾了非醫療領域名詞,提高了所提取方面項的專業性。
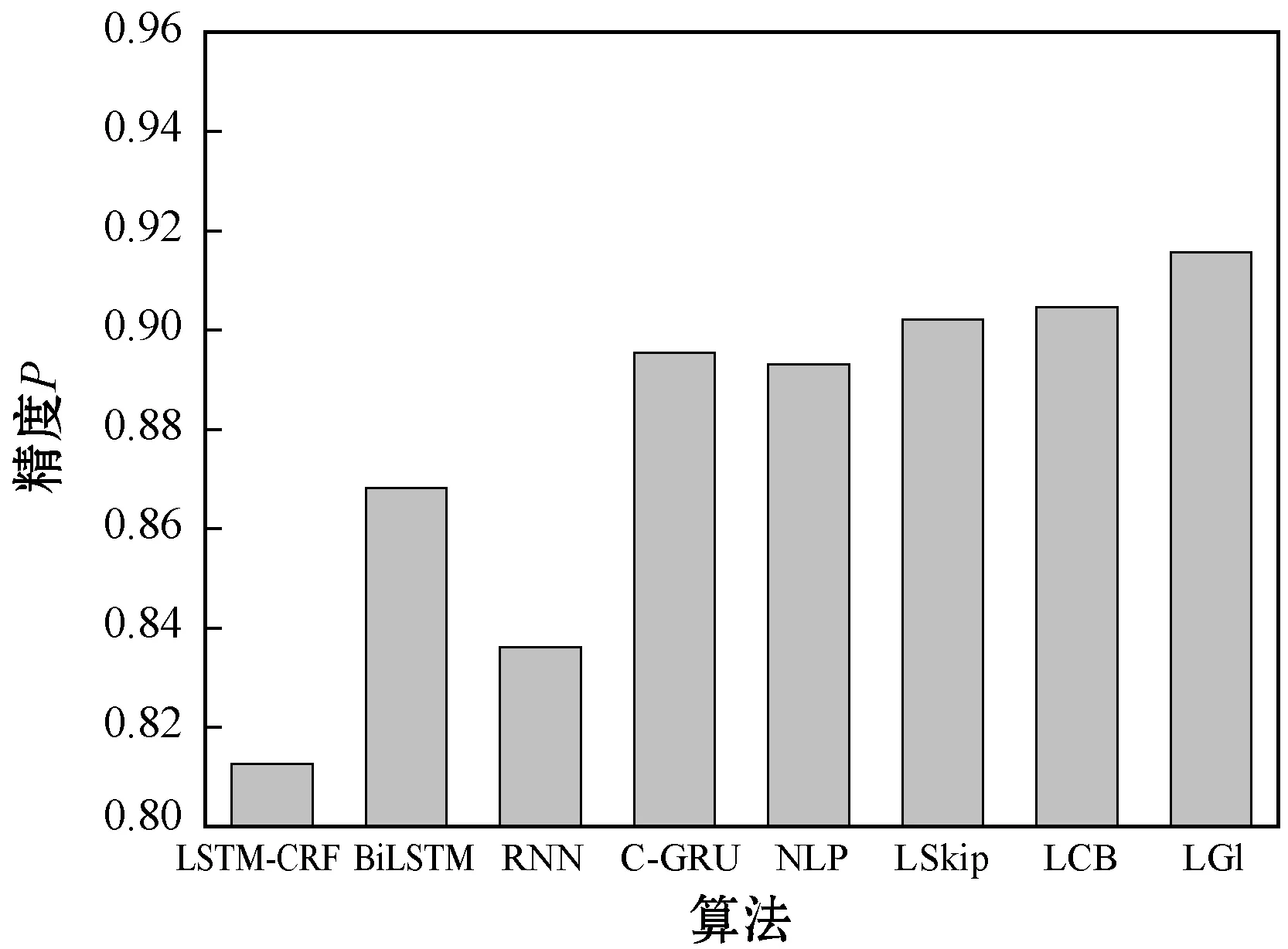
圖8 不同觀點挖掘算法的情感識別精度
圖9所示是不同算法的方面級觀點識別召回率結果,可以看出,本文算法采用GloVe詞嵌入模型的召回率也優于Skip-gram與CBOW兩個模型。NLP的召回率結果優于Skip-gram與CBOW兩個模型下的本文算法,NLP算法具有較高的識別覆蓋率。雖然C-GRU模型實現了較好的觀點識別精度,但召回率略低于NLP算法。
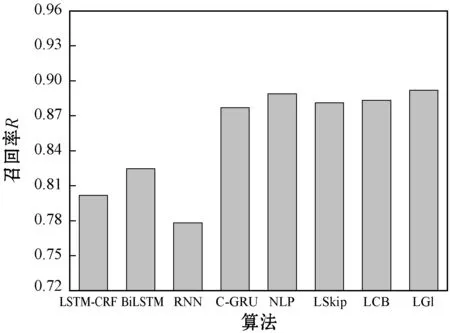
圖9 不同觀點挖掘算法的情感識別召回率
圖10所示是不同算法的方面級觀點識別F1-measure結果,可以看出,本文算法采用GloVe詞嵌入模型的性能優于Skip-gram與CBOW兩個模型。NLP算法的綜合識別性能優于C-GRU模型,本文算法考慮了BIO標注、詞嵌入向量、POS標注,因此能夠更加全面地提取每個方面項在文本中的上下文特征,再結合注意力機制能夠關注于語義重要性高的方面項。此外,本文算法通過2.2節的“醫療領域名詞處理”過濾了非醫療領域名詞,提高了所提取方面項的專業性。
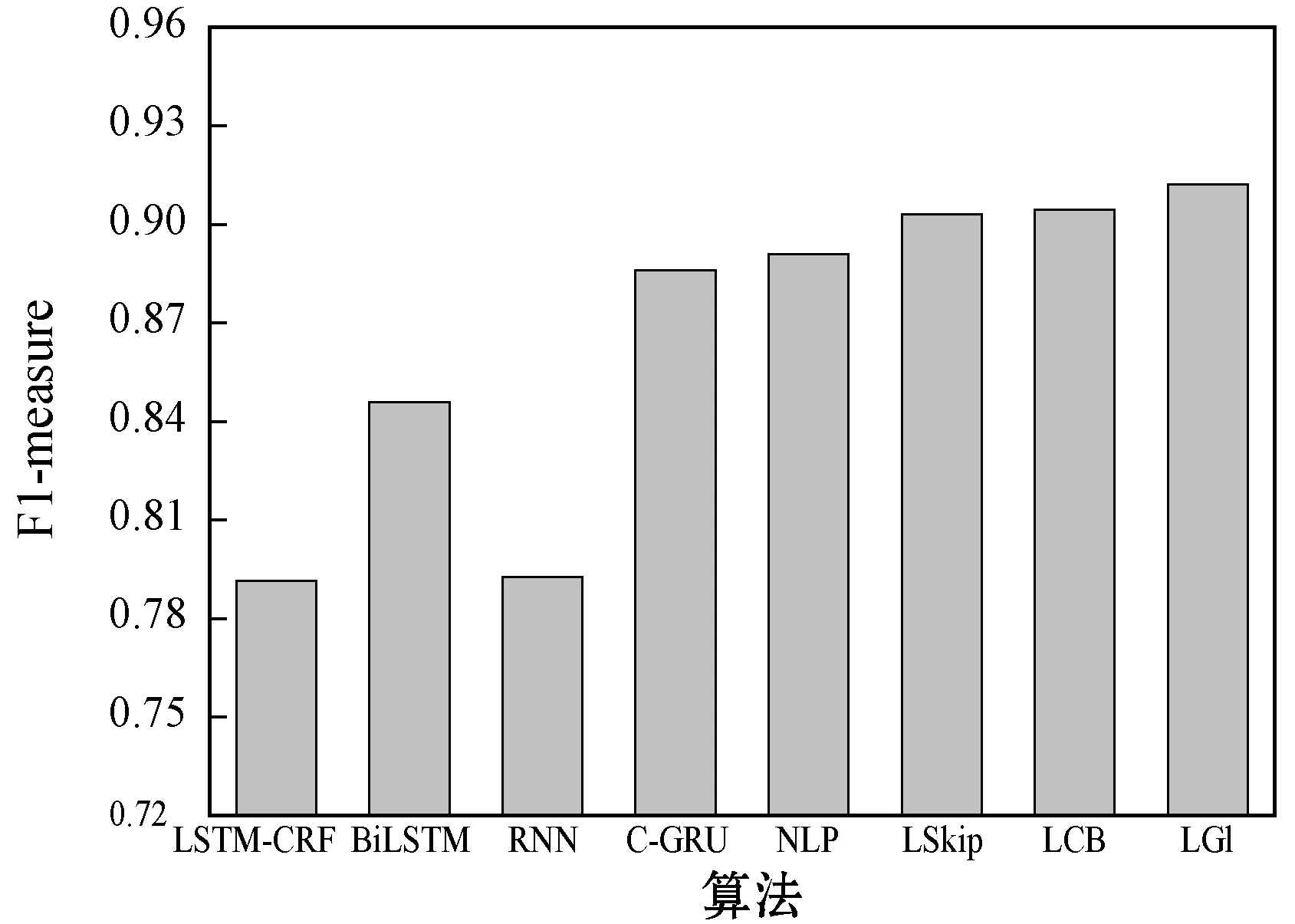
圖10 不同觀點挖掘算法的情感識別F1-measure
5 結 語
為了進一步完善醫院信息化建設的進程,實現對臨床文本數據智能且高效的分析,設計基于循環神經網絡的臨床大規模文本數據分析算法。首先,對詞嵌入模型進行修改,使其更加適合醫療領域,提高所提取方面項的性能。然后,把提取的方面項作為標記數據訓練bi-LSTM網絡。最終,利用Softmax層對方面級觀點的情感進行分類。本文算法考慮了BIO標注、詞嵌入向量、POS標注,因此能夠更加全面地提取每個方面項在文本中的上下文特征,再結合注意力機制能夠關注于語義重要性高的方面項。此外,本文算法通過 “醫療領域名詞處理”過濾了非醫療領域名詞,提高了所提取方面項的專業性。
本文算法目前僅研究了積極、中性和消極共三種情感極性,未來將關注于細粒度的觀點分析研究。借鑒推薦系統的評分方法,進一步深化醫院的信息化建設。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
