基于深度學(xué)習(xí)的分心駕駛行為檢測方法
2023-06-23 04:07:16曹立波楊灑艾昌碩顏京才李旭升
汽車技術(shù) 2023年6期
曹立波 楊灑 艾昌碩 顏京才 李旭升
(1.湖南大學(xué),汽車車身先進(jìn)設(shè)計(jì)制造國家重點(diǎn)實(shí)驗(yàn)室,長沙 410082;2.毫末智行科技有限公司保定分公司,保定 071000)
主題詞:分心駕駛 目標(biāo)檢測 數(shù)據(jù)集標(biāo)注 輕量化模型
1 前言
在“人-車-路”復(fù)雜道路交通系統(tǒng)中,駕駛員行為是影響交通安全的重要因素之一。中國社科院與某保險(xiǎn)機(jī)構(gòu)的相關(guān)調(diào)查結(jié)果表明,34%的受訪者在駕駛過程中存在分心駕駛的行為[1]。此外,美國高速公路安全管理局的報(bào)道顯示,美國的交通事故中25%~30%的案例與分心駕駛行為有關(guān)[2]。因此,如果能夠?qū)崟r監(jiān)測駕駛員的分心駕駛行為并進(jìn)行預(yù)警,將對提升道路交通安全具有重要意義。
目前,分心駕駛檢測方法主要分為間接檢測法和直接檢測法。間接檢測法即通過傳感器檢測車輛的行駛狀態(tài)特征,如加速度、運(yùn)行軌跡和轉(zhuǎn)向盤轉(zhuǎn)角變化等,從而間接獲取駕駛員的分心狀態(tài)。間接檢測法的成本相對較低,且不影響駕駛員的操作行為,但檢測精度易受駕駛條件和駕駛員駕駛習(xí)慣等影響,研究方法和準(zhǔn)確性均需改進(jìn)[3-4]。直接監(jiān)測法即利用駕駛員生理參數(shù)或視覺特征直接獲取其狀態(tài)數(shù)據(jù)。基于生理參數(shù)的監(jiān)測方法通過穿戴醫(yī)療設(shè)備獲取駕駛員的心電信號、腦電信號和肌電信號,提取分析信號信息,獲取駕駛員狀態(tài)[5],該方法準(zhǔn)確率較高,但相關(guān)設(shè)備成本較高,且可能影響正常駕駛,實(shí)際應(yīng)用難度較高。
隨著計(jì)算機(jī)視覺和深度學(xué)習(xí)技術(shù)的發(fā)展,可以通過輸入圖像進(jìn)行端到端的分心駕駛行為檢測[6-8]。黃向康[9]采用改進(jìn)后的多任務(wù)級聯(lián)卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行駕駛員人臉檢測,得到人臉檢測框和5個特征點(diǎn),根據(jù)檢測結(jié)果進(jìn)行分心行為判別,其中包括通話和吸煙2種行為,檢測準(zhǔn)確率分別為93.3%和92.4%。龐再統(tǒng)[10]針對圖像分類網(wǎng)絡(luò)MobileNetV3 進(jìn)行改進(jìn),提出輕量化模型SMobileNet,對分心駕駛行為進(jìn)行識別以實(shí)現(xiàn)實(shí)時監(jiān)測。
本文采集分心駕駛數(shù)據(jù)集,包括駕駛員飲水、使用手機(jī)和吸煙3 種分心駕駛行為的圖像,利用預(yù)訓(xùn)練的Yolov5[11](You Only Look Once)模型得到分心駕駛行為對應(yīng)目標(biāo)物的標(biāo)注文件,最后,采用一種輕量化的目標(biāo)檢測網(wǎng)絡(luò)NanoDet[12]進(jìn)行訓(xùn)練,以便在移動端進(jìn)行部署。
2 數(shù)據(jù)集獲取及標(biāo)注
2.1 數(shù)據(jù)集圖像獲取
數(shù)據(jù)集圖像來源包括多視角、多模態(tài)和多光譜駕駛員行為數(shù)據(jù)集(Multiview,Multimodal and Multispectral Driver Action Dataset,3MDAD)和駕駛員監(jiān)測數(shù)據(jù)集(Driver Monitoring Dataset,DMD),采集19 位駕駛員飲水、使用手機(jī)和吸煙的視頻,對視頻進(jìn)行裁剪并逐幀輸出以便得到圖像集合。其中,3MDAD 數(shù)據(jù)集共包含16類駕駛行為,本文提取駕駛員使用右手發(fā)短信、使用左手發(fā)短信、使用右手通話、使用左手通話、拍照、使用右手飲水、使用左手飲水、吸煙類別的圖像。其中,使用右手發(fā)短信、使用左手發(fā)短信、使用右手通話、使用左手通話、拍照統(tǒng)一為使用手機(jī)類行為;使用右手飲水、使用左手飲水統(tǒng)一為飲水類行為。整理后的數(shù)據(jù)集包括駕駛員不同角度的飲水、使用手機(jī)和吸煙3類圖像,如表1和圖1所示。

圖1 分心駕駛行為圖像示例
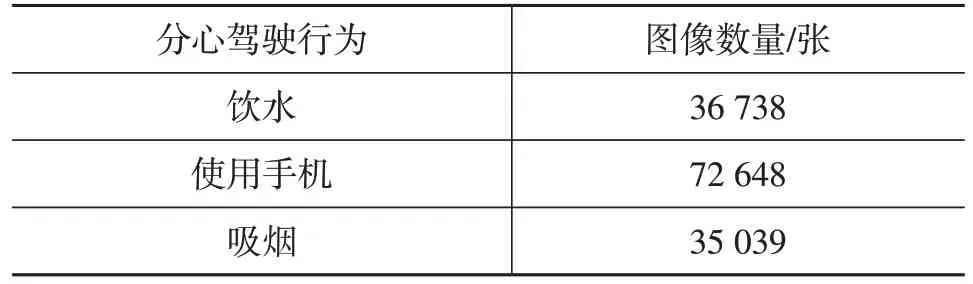
表1 數(shù)據(jù)集圖像數(shù)量
2.2 數(shù)據(jù)集標(biāo)注
本文采用基于COCO[13]數(shù)據(jù)集預(yù)訓(xùn)練的Yolov5 快速標(biāo)注方法對數(shù)據(jù)集圖像進(jìn)行標(biāo)注。
具有不同網(wǎng)絡(luò)深度和寬度的5 種Yolov5 模型在COCO val2017 數(shù)據(jù)集上的性能如表2 所示。綜合考慮檢測精度和推理速度,選取Yolov5l 作為推理時的權(quán)重文件。

表2 Yolov5的5種網(wǎng)絡(luò)模型
COCO數(shù)據(jù)集共包含80個數(shù)據(jù)類別,本文只需檢測瓶子(Bottle)、高腳杯(Wine glass)、茶杯(Cup)和手機(jī)(Cellphone)共4 類目標(biāo)物。將瓶子、高腳杯、茶杯統(tǒng)一為水瓶類數(shù)據(jù),用于得到駕駛員飲水行為目標(biāo)檢測物的標(biāo)注文件;手機(jī)用于得到駕駛員使用手機(jī)行為目標(biāo)檢測物的標(biāo)注文件。此外,COCO 數(shù)據(jù)集不包含香煙類別,需要對香煙類別進(jìn)行單獨(dú)預(yù)訓(xùn)練,用于得到駕駛員吸煙行為目標(biāo)檢測物的標(biāo)注文件。
Yolov5模型推理得到的txt文件包括目標(biāo)物的種類信息、檢測框中心點(diǎn)歸一化坐標(biāo)信息和檢測框歸一化寬高信息。需要對推理過程中出現(xiàn)的冗余檢測、錯誤檢測和遺漏檢測等情況進(jìn)行剔除、修正或重復(fù)推理,如圖2所示。

圖2 數(shù)據(jù)圖像推理結(jié)果示例
最終整理得到的正確推理的圖像數(shù)量如表3 所示。將數(shù)據(jù)集的每一類駕駛行為隨機(jī)分為訓(xùn)練集和驗(yàn)證集。其中,訓(xùn)練集占數(shù)據(jù)集總量的96%,驗(yàn)證集占數(shù)據(jù)集總量的4%。之后對正確的txt 文件進(jìn)行格式轉(zhuǎn)換得到j(luò)son格式的數(shù)據(jù)集標(biāo)注文件。

表3 帶有標(biāo)注的分心駕駛行為數(shù)據(jù)集
3 模型訓(xùn)練及結(jié)果分析
3.1 NanoDet輕量化模型
Yolo、單次多邊框檢測器(Single Shot Multibox Detector,SSD)、區(qū)域卷積神經(jīng)網(wǎng)絡(luò)(Region-based Convolutional Netural Network,R-CNN)等目標(biāo)檢測模型可以實(shí)現(xiàn)較好的精度和速度,但模型相對較大,不適合在移動端嵌入式設(shè)備上進(jìn)行部署。而輕量級目標(biāo)檢測模型NanoDet分別對主干網(wǎng)絡(luò)、特征融合網(wǎng)絡(luò)和檢測頭網(wǎng)絡(luò)進(jìn)行輕量化,具有檢測速度快、模型文件小等優(yōu)點(diǎn),并且提供了新卷積神經(jīng)網(wǎng)絡(luò)(New Convolutional Netural Network,NCNN)推理框架下的C++代碼,可直接在移動端進(jìn)行部署。NanoDet 模型和Yolo 系列模型在COCO val2017數(shù)據(jù)集上的性能對比如表4所示,NanoDet 模型具有參數(shù)量小、模型尺寸小和推理速度快的優(yōu)勢。因此,本文選用NanoDet作為訓(xùn)練模型。
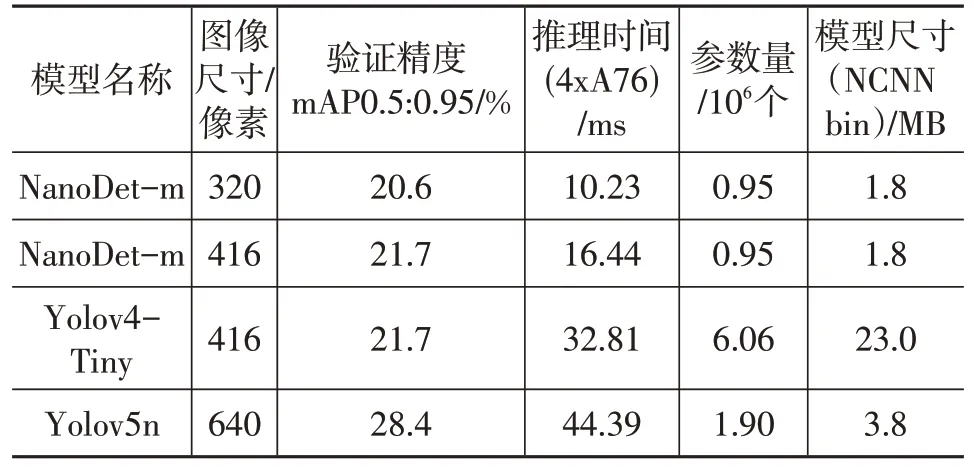
表4 NanoDet模型和Yolo模型性能比較
NanoDet 是單階段的無錨框檢測模型,該設(shè)計(jì)基于全卷積單階段(Fully Convolutional One-Stage,F(xiàn)COS)檢測算法,NanoDet模型結(jié)構(gòu)如圖3所示。
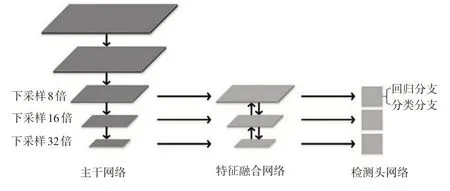
圖3 NanoDet模型結(jié)構(gòu)
NanoDet 的主干網(wǎng)絡(luò)使用ShuffleNetV2[14],去掉了最后一層卷積,并且抽取8倍、16倍、32倍下采樣的特征輸入特征融合網(wǎng)絡(luò)。ShuffleNetV2 通過通道拆分操作,將通道均分為2 個分支,一個分支進(jìn)行卷積操作,并使輸入和輸出通道數(shù)量相等,可以最小化內(nèi)存訪問成本,另一個分支進(jìn)行恒等映射,之后將2 個分支的通道連接,最后進(jìn)行通道重組操作,增加通道間的信息交流。
NanoDet 的特征融合網(wǎng)絡(luò)使用路徑聚合網(wǎng)絡(luò)(Path Aggregation Network,PANet)[15]進(jìn)行淺層特征與深層特征的融合。卷積網(wǎng)絡(luò)中,高層特征感受野大、語義信息豐富,有利于分類;相反,低層特征細(xì)節(jié)信息豐富、目標(biāo)位置準(zhǔn)確,有利于定位。因此,特征金字塔網(wǎng)絡(luò)(Feature Pyramid Networks,F(xiàn)PN)[16]采用自下而上、自上而下以及橫向連接來構(gòu)造特征。自下而上是卷積網(wǎng)絡(luò)前向傳播的過程,選取每個階段的最后一層特征圖構(gòu)建特征金字塔;自上而下是將上層特征圖進(jìn)行上采樣得到新的特征圖,新的特征圖尺度需要與下層特征圖保持一致;橫向連接是將新的特征圖和原始的下層特征圖中每個對應(yīng)元素相加,實(shí)現(xiàn)上層特征和下層特征融合。最后,對融合后的每層特征圖進(jìn)行卷積處理,從而得到融合更加充分的特征圖。PANet在FPN后增加了自底向上的通路,從而縮短了低層與頂層特征之間的信息路徑。此外,NanoDet 為了使模型更加輕量化,使用插值替代卷積進(jìn)行特征圖尺度的縮放。
Nanodet 基于FCOS 系列的共享權(quán)重檢測頭進(jìn)行優(yōu)化,由于移動端模型推理由CPU 進(jìn)行計(jì)算,共享權(quán)重并不會加速推理過程,而且在檢測頭非常輕量化的情況下,共享權(quán)重使得其檢測能力進(jìn)一步下降,因此每一層特征使用一組卷積。并且使用批歸一化(Batch Normalization,BN)替代組歸一化(Group Normalization,GN)作為歸一化的方式,BN 在推理時能夠?qū)⑵錃w一化的參數(shù)直接融合進(jìn)卷積中,可以省去這一步計(jì)算。此外,為了將其輕量化,選擇使用深度可分離卷積[17]替換普通卷積減少參數(shù)量,并將卷積堆疊的數(shù)量減少到2組。
損失函數(shù)分為2 個部分。一部分是廣義交并比損失(Generalized Intersection over Union Loss,GIoULoss)[18]對應(yīng)目標(biāo)預(yù)測框的輸出,GIoULoss 相對于交并比損失(Intersection over Union Loss,IoULoss),在解決預(yù)測框和真實(shí)框不重合的問題時,能夠更好地反映預(yù)測框和真實(shí)框的關(guān)系,可在目標(biāo)檢測任務(wù)中取得更好的結(jié)果:
式中,A為預(yù)測框;B為真實(shí)框;C為框A和框B的最小包圍框。
另一部分是廣義焦點(diǎn)損失(Generalized Focal Loss,GFL)[19],可細(xì)分為分布焦點(diǎn)損失(Distribution Focal Loss,DFL)和質(zhì)量焦點(diǎn)損失(Quality Focal Loss,QFL)。DFL對應(yīng)目標(biāo)預(yù)測框的輸出,考慮到真實(shí)的分布通常與標(biāo)注位置接近,使網(wǎng)絡(luò)能夠快速地聚焦到標(biāo)注位置附近的數(shù)值。QFL 對應(yīng)目標(biāo)類別輸出,QFL 對焦點(diǎn)損失(Focal Loss)[20]進(jìn)行改進(jìn),聯(lián)合表示類別和定位質(zhì)量,即將焦點(diǎn)損失中的離散類別標(biāo)簽轉(zhuǎn)換為0~1 范圍內(nèi)的連續(xù)質(zhì)量標(biāo)簽:
式中,y為0~1范圍內(nèi)的質(zhì)量標(biāo)簽值;σ為預(yù)測值;β為縮放因子的超參數(shù),用于控制降權(quán)的速率。
3.2 訓(xùn)練環(huán)境及超參數(shù)
訓(xùn)練過程中圖像的尺寸為320像素×320像素;設(shè)置訓(xùn)練輪次數(shù)(Epochs)為300;批訓(xùn)練大小(Batach-Size)為128;優(yōu)化器使用帶動量的隨機(jī)梯度下降法,如果當(dāng)前收斂效果好,即可加速收斂,如果收斂差,則減慢其步伐,其中動量設(shè)為0.9,權(quán)值衰減設(shè)為0.000 1;使用多步長調(diào)整學(xué)習(xí)率,對于不同的訓(xùn)練階段使用不同的學(xué)習(xí)率,一方面可以加快訓(xùn)練的過程,另一方面可以加快網(wǎng)絡(luò)收斂,其中初始學(xué)習(xí)率為0.14,衰減系數(shù)為0.1。此外,訓(xùn)練環(huán)境設(shè)置如表5所示。
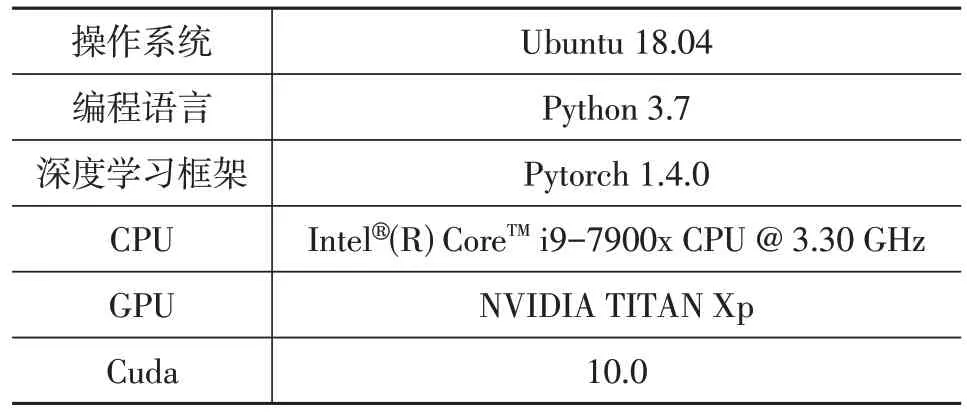
表5 訓(xùn)練環(huán)境設(shè)置
3.3 試驗(yàn)結(jié)果分析
對訓(xùn)練過程進(jìn)行可視化分析,在訓(xùn)練集和驗(yàn)證集上的損失曲線如圖4所示。
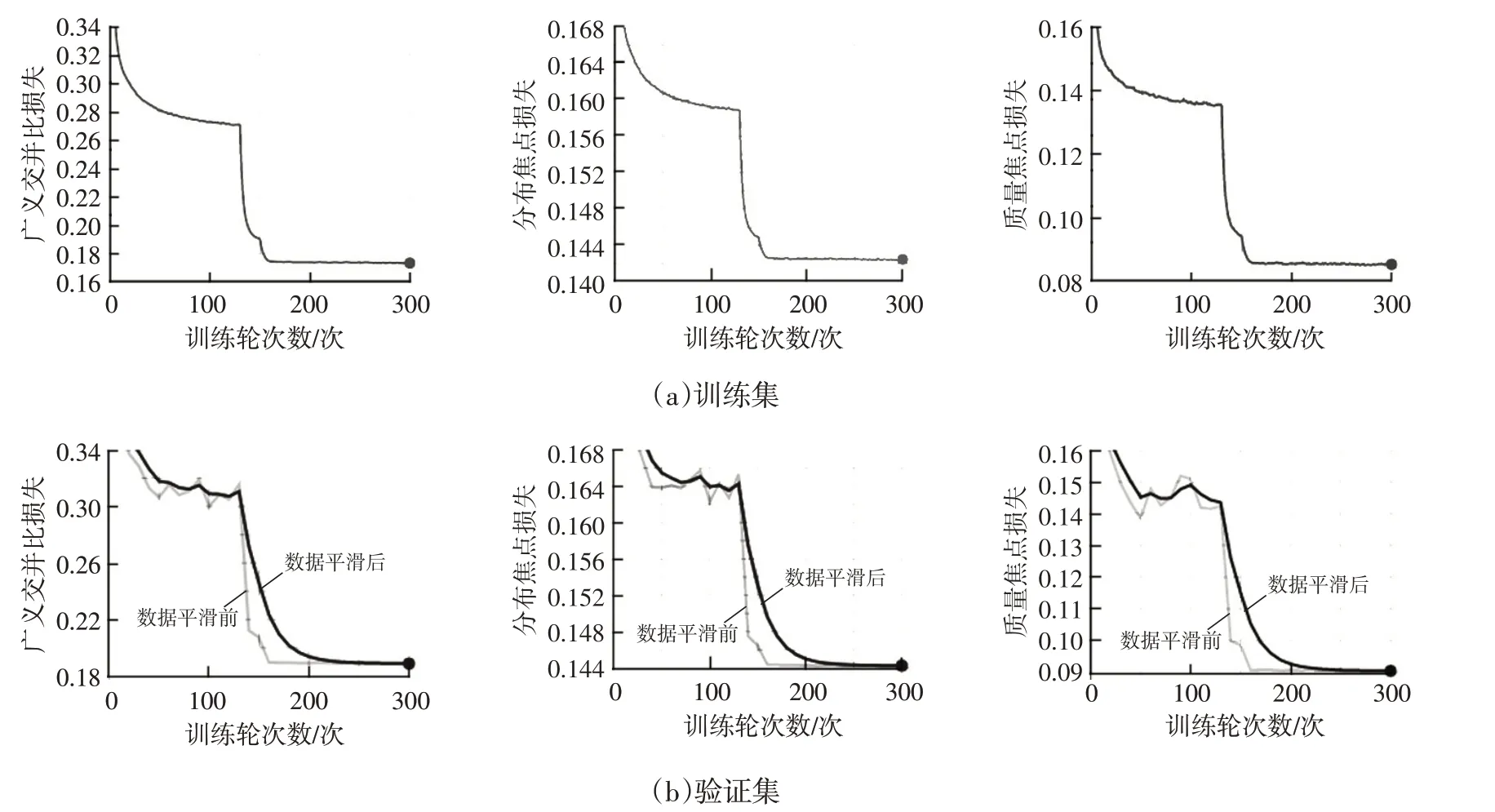
圖4 模型在訓(xùn)練集和驗(yàn)證集上的訓(xùn)練損失曲線
為了評價(jià)模型的目標(biāo)檢測性能,本文采用mAP 作為評價(jià)指標(biāo),mAP 是對每類的平均精度(Average Preci?sion,AP)求均值:
其中,AP是精準(zhǔn)率-召回率(PR)曲線下的面積,PR曲線以不同置信度閾值下的召回率(Recall)R為橫坐標(biāo),精準(zhǔn)率(Precision)P為縱坐標(biāo)得到:
式中,NTP為真正例數(shù)量;NFP為假正例數(shù)量;NFN為假反例數(shù)量;p(r)為PR曲線;C為目標(biāo)類別數(shù)量。
NanoDet模型在驗(yàn)證集上的mAP可達(dá)到0.833 9,如圖5所示。
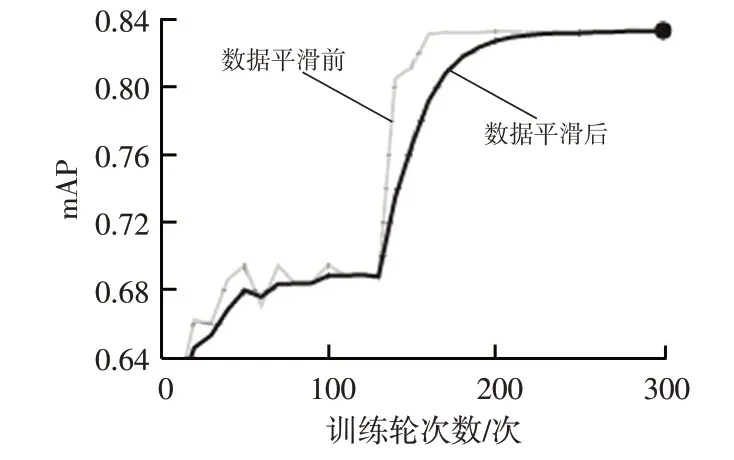
圖5 模型驗(yàn)證集mAP曲線
此外,對模型的檢測效果和推理速度進(jìn)行測試,檢測效果如圖6所示,測試速度如表6所示。

圖6 分心駕駛檢測效果示例
4 結(jié)束語
本文采集駕駛員分心駕駛行為的數(shù)據(jù)集,包括飲水、使用手機(jī)和吸煙,利用在COCO 數(shù)據(jù)集上預(yù)訓(xùn)練的Yolov5 模型得到分心駕駛行為對應(yīng)目標(biāo)物的標(biāo)注文件代替人工標(biāo)注,采用輕量化的目標(biāo)檢測網(wǎng)絡(luò)NanoDet進(jìn)行訓(xùn)練,在驗(yàn)證集上的平均精度均值達(dá)到0.833 9,且推理速度和測試準(zhǔn)確率皆能達(dá)到較好的效果。
猜你喜歡
汽車實(shí)用技術(shù)(2022年14期)2022-07-30 06:13:42
汽車實(shí)用技術(shù)(2022年4期)2022-03-07 06:07:20
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
公民與法治(2016年4期)2016-05-17 04:09:26
